- The paper introduces GEditBench v2, a benchmark for general image editing that covers 1,200 user queries across 23 tasks, including an open-set category to stress-test models.
- It presents PVC-Judge, an open-source evaluation model achieving 81.82% accuracy by leveraging region-decoupled data synthesis for robust visual consistency assessment.
- The study demonstrates that pairwise evaluation methods yield high correlation with human judgment, setting a new standard for instruction-based image editing evaluation.
GEditBench v2: A Human-Aligned Benchmark for General Image Editing
Motivation and Contributions
Instruction-based image editing has rapidly advanced with the introduction of high-capacity generative models that can process natural language prompts and enact fine-grained visual modifications. However, the evolution of robust and exhaustive evaluation methodologies has lagged behind. Most prevailing benchmarks focus on narrow task sets, with evaluation metrics—especially for visual consistency—often failing to capture subtle artifacts, spurious changes to unintended image regions, or identity distortions. The field lacks comprehensive datasets and human-aligned automatic assessment models that generalize to both predefined and open-ended (open-set) editing instructions.
"GEditBench v2: A Human-Aligned Benchmark for General Image Editing" (2603.28547) directly addresses these gaps through three core contributions:
- GEditBench v2 Benchmark: A dataset spanning 1,200 real-world user queries across 23 diverse editing tasks, including a pioneering open-set category specifically designed to stress-test editing models on out-of-distribution instructions beyond any predefined taxonomy.
- PVC-Judge Model: An open-source, pairwise visual consistency judge tuned on a large-scale synthetic preference dataset produced via novel region-decoupled data pipelines, yielding strong human alignment and outperforming proprietary evaluators such as GPT-5.1.
- VCReward-Bench: A large meta-evaluation set of 3,506 expert-annotated preference pairs, across 21 tasks, that rigorously assesses the correlation between human judgment and automated scoring models.

Figure 1: GEditBench v2 benchmarks 23 heterogeneous image editing tasks, including complex and open-set real-world instructions.
Task Taxonomy and Data Collection
GEditBench v2 systematically structures the evaluation set across four primary categories—Local Editing, Global Editing, Reference Editing, and Hybrid Editing—with an additional open-set category capturing unconstrained natural editing needs.
- Local Editing covers granular image manipulations such as object addition/removal, size changes, color/material alterations, semantic text modifications, relation changes, and portrait beautification. Notably, it includes in-image text translation and chart-specific editing.
- Global Editing addresses holistic changes; background substitutions, style/tone transfers, enhancement across multiple forms of degradation, simulated camera movement, and sketch-to-image synthesis.
- Reference Editing tests the accurate transfer of identity and style from external references (person, object, or style).
- Hybrid Editing assesses multi-operation compositional instructions within a single prompt.
- Open-Set Editing introduces 100 hand-curated real-world prompts not mappable to standard categories, explicitly challenging models’ compositional generalization and flexibility.
The dataset is filtered for privacy and diversity, standardized to single-image editing because multi-image evaluation remains unreliable for current open-source VLMs (as empirical analysis demonstrates significant model performance gaps under such settings).

Figure 2: Input/output examples for Relation Change tasks, showcasing non-trivial spatial reasoning demands.

Figure 3: Text Editing samples, covering both semantic content changes and complex typographic layouts.

Figure 4: Chart Editing tasks, designed for high-fidelity transformation and refinement.
Evaluation Protocol: Dimensions and Paradigm Selection
GEditBench v2 adopts a human-aligned, tripartite evaluation framework:
- Instruction Following (IF): Prompt adherence and conceptual correctness.
- Visual Quality (VQ): Perceptual realism, artifact minimization, and aesthetics.
- Visual Consistency (VC): Integrity of the non-target regions—notably, identity, structure, and semantics—relative to the original image.
A core empirical finding is that pairwise comparison evaluations yield significantly higher agreement with human judgments across all three dimensions compared to conventional pointwise rating schemes. This is consistent under diverse VLMs, and holds true for both fine-tuning and evaluation phases.
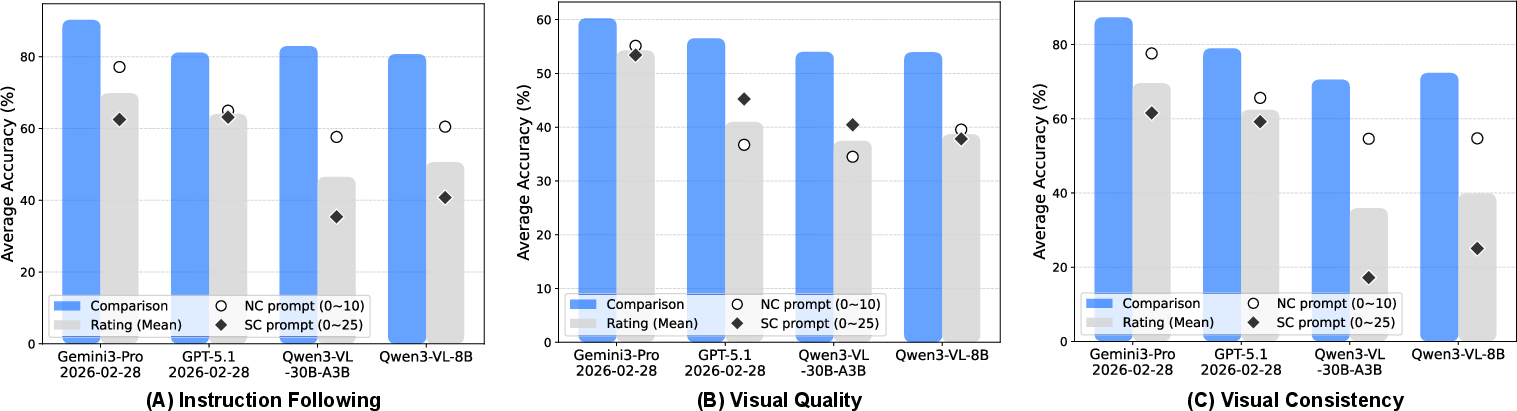
Figure 5: Pairwise human preference agreement outperforms pointwise scoring across instruction following, visual quality, and consistency.
To address reproducibility, cost, and alignment limitations of previous VLM-as-a-Judge paradigms that depend on closed, opaque APIs, the study introduces PVC-Judge—a fully open-source assessment model.
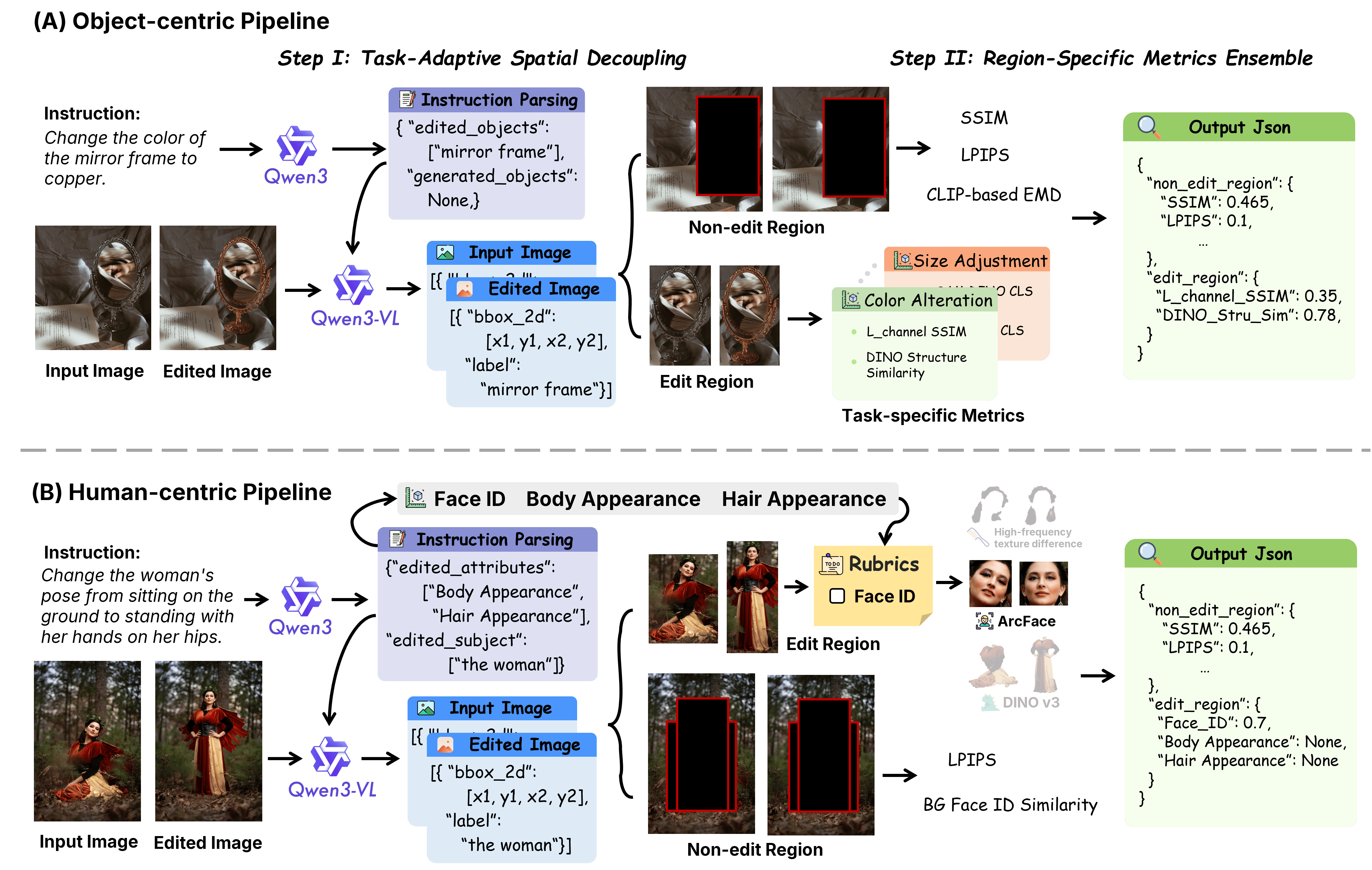
Region-Decoupled Pairwise Data Synthesis & PVC-Judge
Constructing high-signal visual consistency supervision at scale is nontrivial, especially as precise spatial decoupling is needed to avoid penalizing legitimate edits while uncovering spurious, unintended artifacts.
To this end, two pipelines are developed for preference data synthesis:
Preference pair synthesis employs task-wise z-normalization, strict Pareto filtering on regional primary metrics for winner/loser identification, and majority auxiliary validator voting—yielding a curated, high-diversity set of ∼128k preference pairs.
PVC-Judge, instantiated as a Qwen3-VL-8B-Instruct LoRA fine-tuning (rank 64), is trained for accurate binary discrimination, achieving 81.82% accuracy on human-labeled VCReward-Bench, exceeding GPT-5.1 (76.89%).
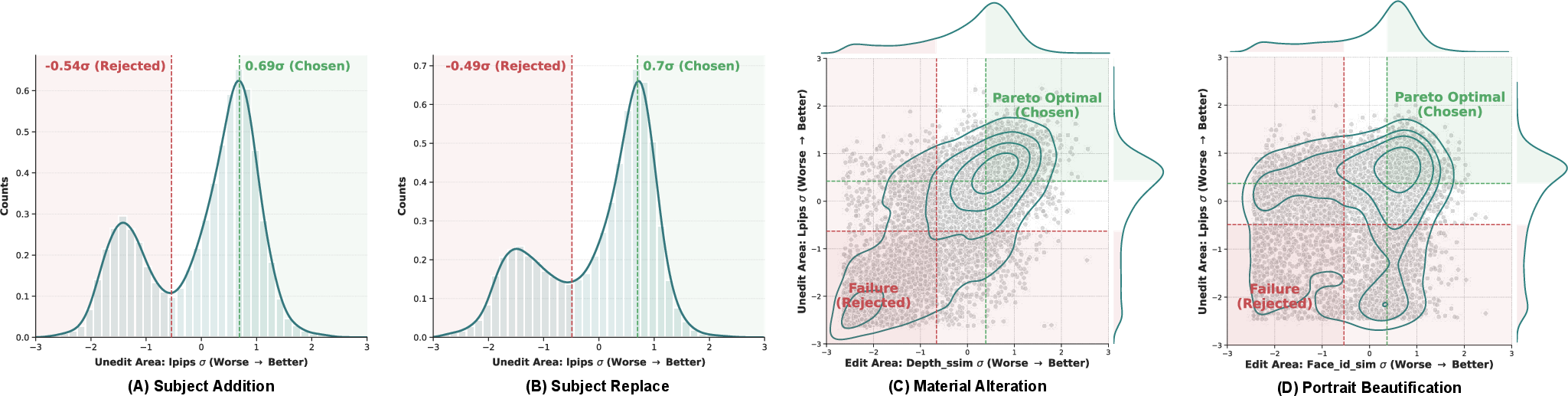
Figure 7: Task-wise score distributions and margin-based winner/loser selection for preference synthesis.
VCReward-Bench, annotated by expert raters using a rigorously controlled interface, evaluates pair preferences across IF, VQ, VC, and Overall dimensions. It enforces a Pareto filtering to ensure discrimination is primarily driven by visual consistency. The result is a fine-grained, noise-reduced ground-truth set that robustly tests not only PVC-Judge but all reward models against human consensus.
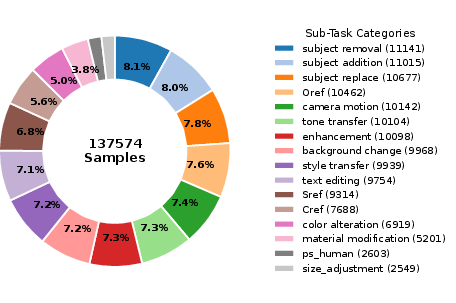
Figure 8: Preference dataset allocation; coverage across 16 editing tasks ensures generalizable training.

Figure 9: Annotation interface for controlled VCReward-Bench labeling.
Results: Multi-Model Benchmarking and Human Alignment
A large-scale benchmarking exercise covering 16 editing models (including top closed and open-source entrants) is conducted. Each dimension is evaluated by the best-aligned judge (PVC-Judge for VC; GPT-4o for IF/VQ).
The Bradley-Terry model is employed to estimate latent scores, with ELO-transformation for intuitive comparison. GEditBench v2 Overall ELO scores show extremely high rank correlation to independent human-Arena results (ρ=0.929, p<2e−7).
- Top-scoring closed models: Nano Banana Pro, Seedream 4.5, GPT Image 1.5.
- Best open-source: FLUX.2 [klein] 9B and Qwen-Image-Edit-2511, which approach proprietary model performance.
- A strong trade-off is observed: models with deficient instruction following can receive artificially high visual consistency scores by simply under-editing the image.
Empirical VCReward-Bench and EditReward-Bench results further confirm PVC-Judge's superior human-alignment relative to all existing open and closed reward models.
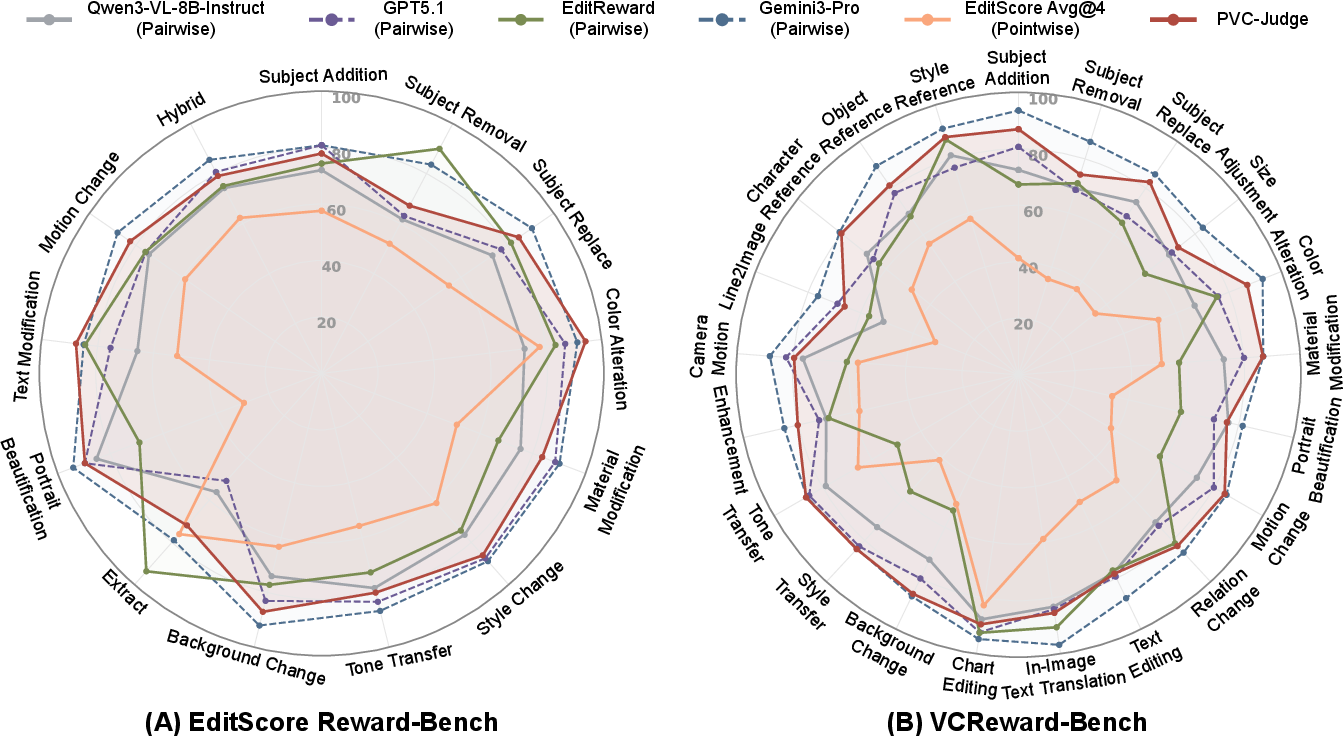
Figure 10: PVC-Judge delivers state-of-the-art task-wise human alignment, surpassing both open-source and proprietary baselines.
Qualitative Analyses: Open-Set and Extreme Cases
Open-set evaluations reveal that many open-source models inadequately interpret implicit and compositional instructions, frequently releasing incomplete or inconsistent edits. Even strong closed-source models can produce identity misalignments—especially on fine detail or small faces—highlighting limitations in current generative systems’ capacity for robust visual consistency under challenging, real-world prompts.

Figure 11: Open-set editing exposes latent weaknesses in handling ambiguous or mixed instructions across representative models.

Figure 12: Relation change tasks visualize stark performance differences in spatial reasoning between open and closed-source models.

Figure 13: Fine-grained detail generation remains a persistent challenge for all models, especially background or small regions.
Implications and Future Directions
The GEditBench v2 protocol establishes a new standard for comprehensive, human-aligned evaluation in instruction-based image editing. The robust performance of PVC-Judge—especially its human alignment and open-source reproducibility—positions it as a foundational tool for RLHF reward modeling, online tuning, and reliable benchmarking.
Theoretically, the region-decoupled, attribute-aware data curation framework offers a blueprint for large-scale, fine-grained supervision for any task involving spatially localized and compositional edits. Practically, the introduction of open-set scenarios pushes the community toward models that can flexibly adapt beyond rigid, closed ontologies.
Anticipated next steps include integrating PVC-Judge as an RL reward signal in model training, tight closure of the gap in multi-image understanding, and extending open-set coverage to broader generative tasks. The approach also signals a path for future benchmarks in multimodal editing domains, where precise instruction boundaries and visual consistency are critical.
Conclusion
GEditBench v2 provides a rigorously curated, task-diverse benchmark accompanied by a pairwise visual consistency judge that closely tracks human preference on challenging compositional and open-ended image editing instructions. Comprehensive ablations, robust human-aligned evaluation pipelines, and strong empirical results underscore its value as a testbed for both academic research and practical deployment in high-precision generative image editing systems.