- The paper presents Kiwi-Edit, a unified framework that integrates multimodal instructions and reference images to achieve precise video editing.
- It leverages the large-scale RefVIE dataset, consisting of 477K quadruplets, to train models that maintain high temporal and structural fidelity.
- Experimental results show a 20% improvement on OpenVE-Bench and robust performance on both local edit and background replacement tasks.
Kiwi-Edit: Instruction and Reference-Guided Video Editing at Scale
Introduction
"Kiwi-Edit: Versatile Video Editing via Instruction and Reference Guidance" (2603.02175) addresses two critical challenges in instruction-based video editing. First, it introduces RefVIE, the largest open-source dataset for instruction-reference guided video editing, which provides the requisite quadruplets for training models capable of precise visual control. Second, it proposes a unified architecture that effectively integrates multimodal conditions (instructions and references) via a Multimodal LLM (MLLM) and a Diffusion Transformer (DiT). This dual focus advances controllable video editing in both methodological rigor and empirical performance.
RefVIE: Scalable Reference Data Synthesis
Precise reference-guided editing has been hindered by the absence of large-scale quadruplet datasets, consisting of source video, instruction, reference image, and target video. The RefVIE curation pipeline systematically transforms existing text-instruction editing pairs into quadruplets.
The workflow begins by aggregating millions of open-source instructional editing pairs, then progressively removes low-quality examples via EditScore filtering, region grounding, and segmentation using advanced MLLMs and segmentation models. For each edit, the edited region or object is grounded in the target, then a high-fidelity reference image is synthesized using a state-of-the-art image editing model. Quality control and de-duplication ensure dataset rigor, resulting in 477K high-quality quadruplets spanning local edits and background replacement tasks.
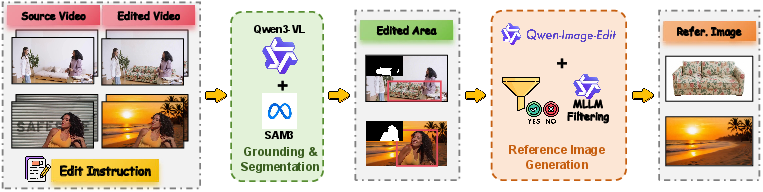
Figure 1: Workflow of the reference image synthesis pipeline for RefVIE.
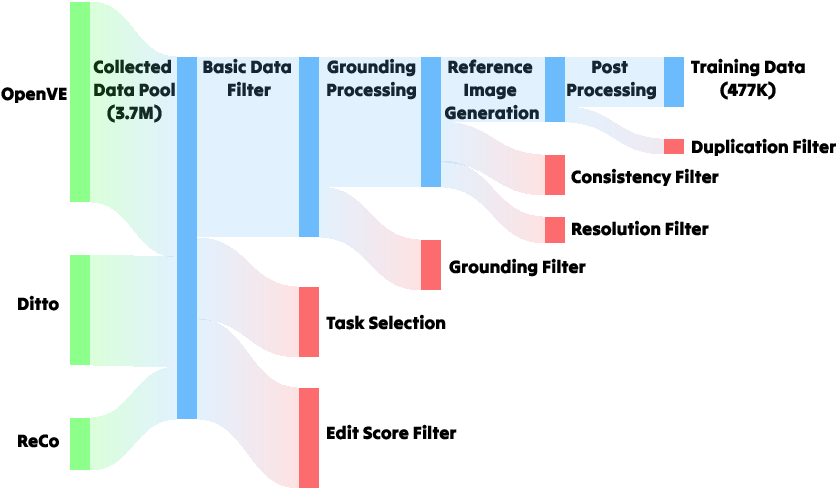
Figure 2: Pipeline describing the four-stage curation process from 3.7M samples to 477K quadruplets.
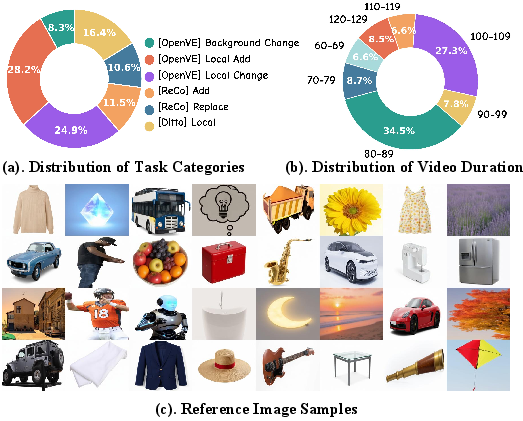
Figure 3: Dataset statistics and visualizations highlighting task balance, duration distribution, and diverse reference examples.
This pipeline sets a new benchmark for reference-guided video editing dataset scale and quality, surpassing previous instruction-driven video editing corpora.
Unified Editing Framework: Kiwi-Edit Architecture
Kiwi-Edit introduces a modular, compositional architecture for instruction- and reference-guided editing. At its core, a frozen Qwen2.5-VL-3B MLLM encodes interleaved frames, instructions, and references. Conditioning signals flow to the DiT backbone via two parallel connectors:
- Query Connector: Projects a variable number of learnable queries, extracting the editing intent from the instruction and video context.
- Latent Connector: Projects visual features extracted from reference images for semantic guidance.
A hybrid latent injection strategy controls the generative process within DiT: source video latents are added element-wise (modulated by a learnable scalar), ensuring temporal and structural fidelity; reference latents are concatenated, delivering dense visual priors for fine-grained content synthesis.
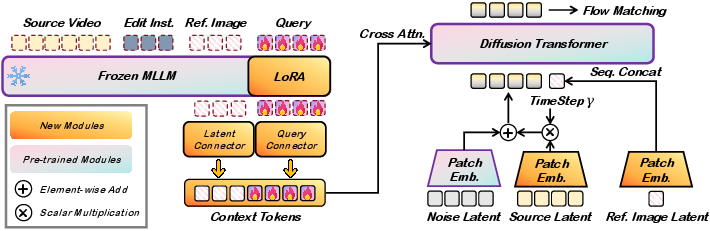
Figure 4: Overview of the unified editing framework: multimodal instruction encoding, dual-projector semantic injection, and structure-preserving DiT generation.
This combination enables seamless transition between instruction-only, reference-only, and mixed-control video editing. A three-stage curriculum—alignment, instructional tuning, and reference fine-tuning—ensures progressive, stable training of the composite system, leveraging both text-only and reference-based supervision.
Empirical Results and Benchmarking
On both open-source and proprietary benchmarks, Kiwi-Edit demonstrates robust improvements across all editing paradigms.
- Instruction-based Editing: On the OpenVE-Bench, Kiwi-Edit achieves a 20% relative improvement (Overall Score: 3.02 vs. previous SoTA 2.50) and exhibits strong background change performance, outperforming even closed models such as Runway Aleph for this task type.
- Reference-guided Editing: On the RefVIE-Bench, the method scores 3.31 Overall, matching or slightly surpassing commercial systems like Runway Aleph and establishing a verifiable state-of-the-art for open-source models.
Performance breakdowns by edit type confirm the system’s high identity consistency and reference similarity, especially on local edit and object replacement tasks. Ablations reveal the necessity of dual projection conditioning and the progressive curriculum for maximizing both spatial coherence and instruction adherence.
Qualitative results illustrate marked fidelity in local and background edits, with the system producing reference-aligned and temporally stable sequences, preserving both global context and fine details.

Figure 5: Qualitative results on OpenVE-Bench and VIE-Bench, confirming semantic and structural accuracy.

Figure 6: Qualitative results on RefVIE-Bench, demonstrating high reference fidelity and temporal consistency.
Ablations and Model Design Insights
Experiments confirm that element-wise source video latent injection with learnable timestep scaling is critical for structure preservation. Channel concatenation or shared embeddings significantly degrade both editability and temporal coherence. Moreover, combining learnable instructional queries with dense reference latents ensures high-fidelity transfer of visual priors and semantic intent—a single-source conditioning paradigm underperforms on fine-grained tasks.
Progressive curriculum learning is essential; omitting early-stage semantic alignment or image co-training yields catastrophic failures in structure-sensitive tasks and significantly lowers overall benchmark scores.
Implications and Future Directions
This work delivers a scalable and reproducible data-centric approach for video editing with controllable granularity, democratizing reference-guided video editing research. The RefVIE dataset and Kiwi-Edit model jointly expand the frontier of multimodal, compositional generation, equipping the community with open high-fidelity resources.
Practically, deploying such models can enable user-driven content creation with interpretable, fine-grained control in social media, virtual production, and entertainment. Theoretically, the dual-connector DiT framework offers a template for more generalized, interpretable, and modular generative architectures across modalities.
Ongoing challenges include further optimizing model parameter efficiency, scaling to even longer videos, relaxing the reliance on synthetic reference images, and exploring more abstract forms of visual-semantic alignment (e.g., style, dynamics). The modular structure of Kiwi-Edit is amenable to rapid integration with larger MLLMs and more expressive video diffusion priors as they become available.
Conclusion
Kiwi-Edit delivers substantial advances in scalable, controllable video editing by providing both the requisite dataset (RefVIE) and a flexible, high-performing architecture. These contributions set a foundation for future multimodal generative modeling—enabling more precise visual control and improved alignment with user intent for both research and real-world applications.

