SpaceControl: Introducing Test-Time Spatial Control to 3D Generative Modeling
Abstract: Generative methods for 3D assets have recently achieved remarkable progress, yet providing intuitive and precise control over the object geometry remains a key challenge. Existing approaches predominantly rely on text or image prompts, which often fall short in geometric specificity: language can be ambiguous, and images are cumbersome to edit. In this work, we introduce SpaceControl, a training-free test-time method for explicit spatial control of 3D generation. Our approach accepts a wide range of geometric inputs, from coarse primitives to detailed meshes, and integrates seamlessly with modern pre-trained generative models without requiring any additional training. A controllable parameter lets users trade off between geometric fidelity and output realism. Extensive quantitative evaluation and user studies demonstrate that SpaceControl outperforms both training-based and optimization-based baselines in geometric faithfulness while preserving high visual quality. Finally, we present an interactive user interface that enables online editing of superquadrics for direct conversion into textured 3D assets, facilitating practical deployment in creative workflows. Find our project page at https://spacecontrol3d.github.io/









































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces SpaceControl, a new way to guide 3D object generators so they make shapes the way you want. Instead of relying only on text like “a wooden chair,” SpaceControl lets you sketch simple 3D shapes (like blocks and rounded forms) or use existing 3D models, and the generator will follow that structure. Best of all, it works with powerful existing models and doesn’t need any retraining.
What was the paper’s main goal?
The researchers wanted to make 3D generation both easy to control and high quality. Their big questions were:
- Can we add clear, precise shape control to pre-trained 3D models without retraining them?
- Will this control work with many kinds of input, from rough sketches (simple 3D primitives) to detailed meshes?
- Can users adjust how strongly the generator follows their input shape versus how realistic it looks?
- Does this method beat existing approaches in how closely the generated shape matches the input?
- Can it be used interactively by artists and designers?
How did they do it? (Methods explained simply)
Think of the 3D generator as a two-part artist:
- Structure first (the object’s shape),
- Appearance second (textures, colors, materials).
SpaceControl adds a “shape steering wheel” to the first part.
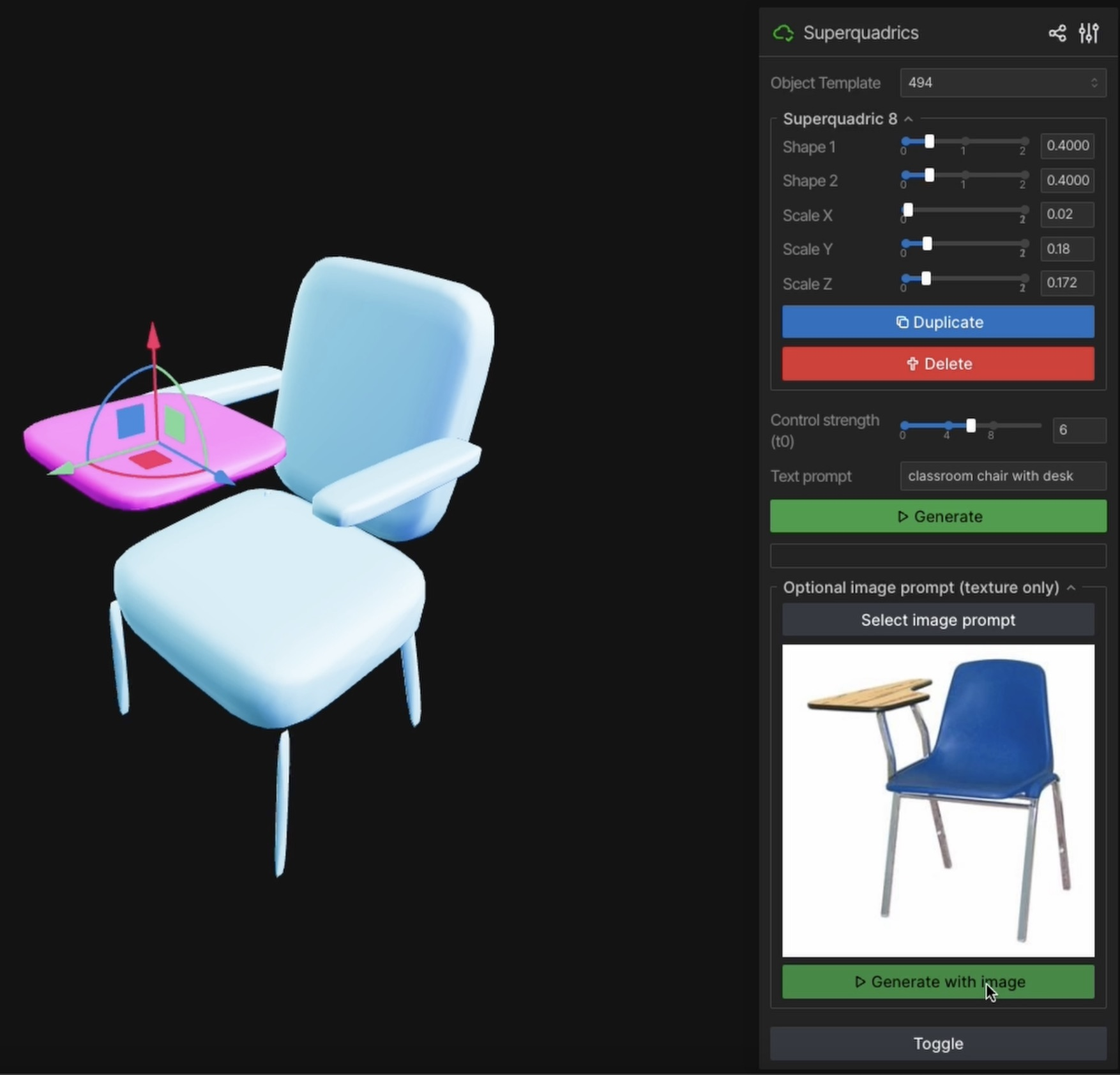
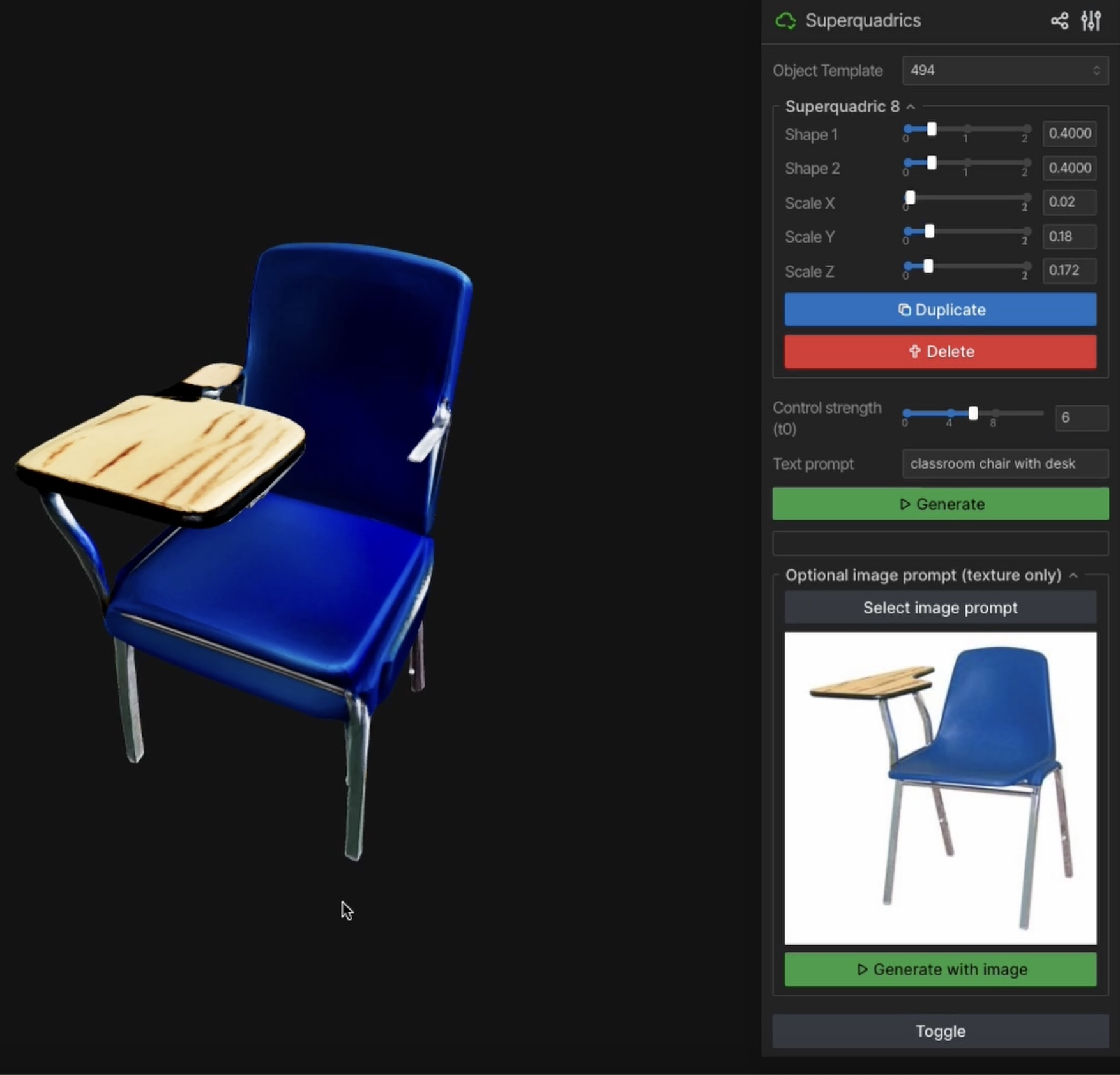
- Simple shapes as controls: The method uses “superquadrics,” which are basic 3D forms like squished cubes and rounded cylinders defined by just a few numbers (size and roundness). You can also use full 3D meshes.
- Grid of 3D pixels: Your input shape is turned into a 3D grid of tiny blocks (voxels), like Minecraft but smaller.
- Latent space guidance: The model normally starts from random noise and “cleans” it step by step to form a believable object. SpaceControl encodes your shape into the model’s hidden code (“latent space”), blends it with noise at a chosen point in time, and then lets the model do its usual cleaning from there. This is like starting a painting from a sketch that’s been lightly smudged, instead of from a blank canvas.
- A simple control knob (τ₀): This knob decides how much the model should stick to your input shape versus how much it should rely on its training to look realistic. Lower values = more realism, less strict shape matching. Higher values = closer to your input shape, sometimes slightly less natural-looking.
- Appearance stage: After the structure is set, the model adds textures and colors. You can guide this with text (“a floral chair”) or even an image to get a specific style. The final result can be a mesh, a radiance field, or 3D Gaussians—different ways of representing 3D for various tools.
Importantly, SpaceControl doesn’t retrain the model. It adds guidance during generation (test time), so it’s fast and flexible.
What did they find and why is it important?
- Better shape matching: SpaceControl produced objects that more closely follow the input shapes than other methods that required retraining (like Spice-E) or heavy optimization (like Coin3D). They measured this with the Chamfer Distance, which is a score for how close two shapes are; SpaceControl consistently had lower (better) scores.
- Similar realism: Even while matching shapes more closely, SpaceControl kept visual quality high, measured by scores like FID (for textures) and P-FID (for geometry). It was usually comparable to the best alternatives.
- People preferred it: In a user study with 52 volunteers, SpaceControl was chosen more often for overall quality and faithfulness to the input shape.
- Flexible control: The τ₀ knob lets you tune the balance between accuracy to your input and realism. The paper shows how changing τ₀ affects quality, and suggests mid-range values often work well.
- Strong alignment: SpaceControl aligned objects correctly even when the input shapes were rotated or not axis-aligned, which other methods sometimes failed to do.
- Practical tool: They built an interface where you can edit superquadrics live and instantly generate textured 3D assets, which is great for design workflows.
This matters because artists, designers, and game developers often start with rough 3D sketches and need precise control. SpaceControl makes that easy without sacrificing visual quality.
What does this mean for the future?
SpaceControl could speed up creating 3D content for games, VR, simulations, and product design:
- Faster iteration: Start from simple 3D sketches and quickly get detailed, realistic assets.
- Precise edits: Adjust parts like a chair’s backrest or add armrests and see the changes immediately.
- Multi-modal styling: Use text and images to push textures and looks while keeping the shape you want.
The authors note a couple of limitations and future ideas:
- Choosing τ₀ is manual right now; automatic tuning could make it even smoother.
- The control strength is uniform across the object; part-specific control (stronger in some regions, looser in others) could add more creative freedom.
Overall, SpaceControl shows that we can guide powerful 3D generators with simple, clear spatial inputs—no retraining required—making 3D creation more accessible and efficient.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open questions that remain unresolved and could guide future research:
- Automatic control-strength selection: tau0 is manually set per instance; develop data-driven or optimization-based procedures to select tau0 automatically given the prompt/control geometry and desired realism/faithfulness targets.
- Spatially varying adherence: the method enforces a uniform adherence level over the whole object; design part-aware or region-weighted guidance (e.g., per-voxel/part masks or schedules) to tightly constrain some regions while allowing freedom elsewhere.
- Dynamic guidance schedules: current control uses a single start time t0; investigate time-dependent guidance schedules tau(t) and adaptive strategies that modulate guidance during denoising to improve realism-faithfulness trade-offs.
- Backbone generality: although claimed to be compatible with SAM 3D, results are only shown with Trellis; rigorously evaluate portability to other 3D generative backbones (e.g., SAM 3D, GET3D variants, mesh-native diffusion/flow models) and identify required adaptations.
- Encoder dependence: the approach relies on Trellis’ structure encoder E, which is not used at inference in the base model; analyze sensitivity to encoder calibration and out-of-distribution (OOD) control geometries, and compare against alternative encoders or training-free encoders (e.g., errors from voxelization vs SDF/point encoders).
- Representation bottleneck: structure is constrained in a 64×64×64 occupancy grid; quantify fidelity loss for thin structures and high-frequency details, and explore multi-resolution/hierarchical or higher-resolution structure representations (≥1283) to reduce aliasing.
- Input modality breadth: control geometry is voxelized meshes or parametric superquadrics; extend to other inputs (point clouds, SDFs, NURBS/CAD, partial scans) and compare their robustness and fidelity after encoding.
- Robustness to imperfect control: evaluate behavior under noisy, partial, misaligned, or scale-mismatched control geometries; develop canonicalization and uncertainty-aware guidance that tolerates imperfect inputs.
- Conflict resolution: study failure modes when text/image semantics conflict with control geometry (e.g., geometry of a chair with “airplane” prompt) and propose principled conflict-handling strategies or constraints.
- Diversity under fixed control: quantify and control sample diversity (appearance and permissible geometric variations) for a fixed spatial control; propose diversity-aware sampling or conditioning schemes that preserve adherence.
- Appearance disentanglement: image conditioning is only used in the appearance stage and mainly affects texture; investigate stronger, controllable disentanglement of geometry/material/lighting and enable explicit material/BRDF and lighting controls beyond text/image prompts.
- Realism degradation at high tau0: high adherence settings degrade FID; design realism-preserving regularizers (e.g., discriminator guidance, priors, or hybrid losses) that maintain plausibility while retaining control.
- Metric coverage and granularity: current metrics (CD, FID, P-FID, CLIP-I) overlook part-level alignment, normals/curvature, topology/manifoldness, watertightness, and multi-view consistency; introduce and report richer 3D metrics and automatic part-level alignment scores against the control.
- Conversion quality across output formats: the paper lists GS/RF/mesh decoders but evaluates mainly meshes; systematically compare quality, artifacts, and consistency across formats, including manifoldness and editability of meshes for downstream pipelines.
- Computational performance: claims of efficiency vs optimization-based methods lack runtime/memory benchmarks; report wall-clock latency, GPU memory, and throughput for different tau0 and resolutions, and compare to baselines.
- Category and domain coverage: evaluations focus on ShapeNet chairs/tables and Toys4K; assess generalization to complex/topology-rich categories (e.g., bicycles, plants), real-world scans, and out-of-domain assets.
- Scene-level control: the method targets single-object assets; extend to multi-object scenes with compositional spatial constraints (layout, collisions, occlusions) and evaluate scene realism and controllability.
- Alignment and coordinate handling: aside from a qualitative example, there is no systematic study of pose/scale alignment errors; benchmark and improve alignment robustness, including automatic normalization of input control to model coordinates.
- UI and usability evidence: the interface is presented but user-centered evaluation (latency, learning curve, time-to-target, iteration count, satisfaction) is missing; conduct formal HCI studies and integrate with DCC tools (e.g., Blender, Unreal) via plugins.
- Training-free limits: analyze when latent injection fails (e.g., extreme OOD controls, very sparse primitives) and whether lightweight adapters or minimal fine-tuning could expand the controllable regime without sacrificing generalization.
- Theoretical understanding: provide analysis of why/when latent-space seeding at t0 yields controllable flows; study the geometry of rectified flows under injected seeds and characterize stability/convergence vs guidance strength.
- Benchmarking standardization: the custom evaluation uses SuperDec decompositions and Gemini-generated text; release the derived controls/prompts and establish standardized, open benchmarks for spatially controlled 3D generation to enable fair comparisons.
- Perceptual-grounded evaluation: the user study measures preference but not task-oriented success; add perceptual tests targeting spatial accuracy (e.g., just-noticeable differences in part placement) and realism thresholds with statistically powered sample sizes.
- Extension to dynamics: investigate whether the approach extends to non-rigid/animated assets (4D), enabling test-time spatial control over motion trajectories and articulated parts.
Practical Applications
Overview
Below are practical, real-world applications that follow directly from the paper’s findings and innovations in SpaceControl—a training-free, test-time spatial control method for 3D generative modeling. Each item specifies sector alignment, concrete use cases, potential tools/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
These applications can be deployed now using the released Trellis/SAM‑3D-based SpaceControl workflow, the provided superquadrics UI, and standard DCC (digital content creation) tools.
- Game and VFX asset authoring — Software/Entertainment Accelerate “blockout-to-hero asset” workflows by turning coarse 3D sketches (superquadrics or rough meshes) and short prompts into high‑quality, textured meshes. Potential tools/workflows: SpaceControl Blender/Unreal/Unity plugins; “Sketch‑to‑Asset” microservice returning glTF/FBX; τ₀ knobs for realism‑faithfulness control; batch asset variant generation. Assumptions/dependencies: Requires pre‑trained Trellis/SAM‑3D weights, GPUs, and domain coverage in training data; voxelization (64³) may limit small details; licensing for commercial use.
- AR/VR scene building and prototyping — Software/AR/VR Rapidly populate immersive environments from simple spatial scaffolds while retaining precise placement and dimensions (chairs, tables, props). Potential tools/workflows: In‑editor parametric superquadrics gizmos; image‑conditioned texture transfer for brand fidelity; exports to meshes, radiance fields, or 3D Gaussians. Assumptions/dependencies: Consumes platform‑specific decoders; texture realism primarily driven by appearance stage; performance tuning for runtime constraints.
- Product and furniture design configurators — Manufacturing/Retail/E‑commerce Let designers or customers specify dimensions and silhouette via superquadrics and generate photoreal variants (e.g., add armrests, adjust backrest height). Potential tools/workflows: “Parametric Furniture Studio” web app; CAD handoff via mesh export; τ₀ presets for “exact geometry” vs “stylized concept.” Assumptions/dependencies: Structural validity not guaranteed; requires downstream checks for manufacturability, tolerances, and watertight meshes for CAD/3D printing.
- Interior design visualization — Architecture/Design Convert massing models into textured furniture/fixtures consistent with design language using image‑conditioned appearance; precisely control footprint and arrangement. Potential tools/workflows: SketchUp/Rhino integration; reference image mood boards driving textures; quick A/B scene variants via τ₀ sweeps. Assumptions/dependencies: Scale and code compliance must be handled downstream; realism vs faithfulness trade‑offs need designer oversight.
- E‑commerce 3D content production — Retail/Marketing Generate product 3D assets with accurate silhouettes and brand‑consistent textures from product photos and dimensional specs. Potential tools/workflows: “3D Asset Factory” microservice; CLIP‑prompt catalog; image‑conditioned texture consistency across SKUs; glTF/WebGL delivery. Assumptions/dependencies: IP ownership of training/reference images; alignment to real‑world dimensions requires QA.
- Synthetic data creation for vision — AI/ML Produce labeled, geometry‑controlled assets for training object detectors/segmenters; tune τ₀ for diversity vs shape precision; use CLIP‑I/P‑FID for automated QA. Potential tools/workflows: Dataset generator that emits meshes plus renderings and masks; programmatic primitive generation for coverage. Assumptions/dependencies: Domain shift vs target environment; requirement to annotate materials or affordances separately.
- Robotics simulation assets — Robotics Quickly generate obstacles and manipulables with precise shape constraints for physics simulators (e.g., cluttered environments, furniture layouts). Potential tools/workflows: “World Builder” that ingests primitive layouts and outputs textured meshes; τ₀ presets for “strict geometry” worlds. Assumptions/dependencies: Physical properties (mass, friction, articulation) not modeled; must pair with physics parameterization.
- Texture/style transfer for 3D assets — Design/Branding Use reference images to transfer appearance while holding geometry fixed; ideal for brand look consistency across generated variants. Potential tools/workflows: Batch texture pipeline using image‑conditioned appearance stage; look‑book driven styling. Assumptions/dependencies: Image conditioning primarily affects texture, not geometry; reference image rights required.
- Education and onboarding to 3D modeling — Education Lower barrier for novices: edit superquadrics, add a short prompt, generate a textured model; teach realism‑faithfulness trade‑offs via τ₀. Potential tools/workflows: “SpaceControl Classroom” sandbox; rubric based on CD/CLIP‑I/FID for constructive feedback. Assumptions/dependencies: Requires accessible hardware or cloud; curated prompt/reference libraries; content safety filters.
- Rapid prototyping for 3D printing (concept stage) — Maker/DIY Move from conceptual shapes to printable meshes for early evaluation; enforce strict geometry via higher τ₀. Potential tools/workflows: STL export; auto‑watertight and thickness checks via downstream tools. Assumptions/dependencies: Structural integrity and tolerances must be validated; post‑processing for printability needed.
Long-Term Applications
These use cases require further research, scaling, or development (e.g., part‑aware control, physical validity, automatic τ₀ tuning, higher‑resolution geometry).
- CAD co‑pilot with constraint‑aware generation — Manufacturing/Engineering Generate parametric solids respecting dimensions, tolerances, and mating constraints; per‑part control to lock critical regions while stylizing others. Potential tools/workflows: SpaceControl‑for‑CAD with per‑region τ₀ maps; constraint solver integration; STEP export. Assumptions/dependencies: Requires part‑aware control, solid modeling kernels, and manufacturability checks.
- Interior layout optimization and compliance — Architecture/Policy Auto‑generate room layouts meeting accessibility and building codes while preserving designer’s spatial scaffolds. Potential tools/workflows: Constraint‑driven τ₀ tuning; rule‑checking engines; BIM integration. Assumptions/dependencies: Formal encoding of regulations; accurate scale and metadata; human review.
- Industrial digital twins and asset libraries — Energy/Industrial IoT Build large, faithful 3D libraries of equipment with controlled geometry for simulations and operator training. Potential tools/workflows: Domain‑specific fine‑tuning or adapters; PBR material pipelines; provenance tags. Assumptions/dependencies: Industry‑specific datasets; physics/material correctness; lifecycle management.
- Autonomous driving simulation world synthesis — Automotive Generate varied, constraint‑controlled urban assets (street furniture, signage) for simulation and testing coverage. Potential tools/workflows: Procedural primitive layouts + SpaceControl; scenario parameter sweeps; sensor rendering pipelines. Assumptions/dependencies: Dynamic behavior and traffic rules not covered; large‑scale asset QA.
- Healthcare prosthetics and aids (concept design) — Healthcare Create patient‑specific conceptual shapes respecting anatomical constraints; later refined into clinically valid devices. Potential tools/workflows: Scan‑to‑primitive decomposition + SpaceControl; clinical approval workflows. Assumptions/dependencies: Medical validation, biocompatibility, and regulatory compliance; high‑resolution geometry needed.
- Object synthesis with affordances for robot manipulation — Robotics Generate objects with graspable regions and tool interfaces based on spatial constraints and task goals. Potential tools/workflows: Affordance‑guided per‑part τ₀; physics simulators; grasp planners. Assumptions/dependencies: Requires physical property modeling and semantic part labeling; task‑specific training.
- On‑device real‑time generation for AR — Mobile/AR Deliver interactive, spatially constrained 3D generation on phones/glasses (e.g., interior preview in situ). Potential tools/workflows: Model compression/distillation; streaming decoders; low‑latency voxelization. Assumptions/dependencies: Compute and memory limits; privacy/security for reference images.
- Marketplace for parametric, controllable 3D assets — Platforms Offer user‑generated assets with provenance tags and adjustable geometry controls; embed licensing and watermarking. Potential tools/workflows: SpaceControl API; content moderation; provenance standards. Assumptions/dependencies: Clear IP frameworks, dataset transparency, and trust mechanisms.
- Automatic realism‑faithfulness tuning — AI/Optimization Learn τ₀ selection from task objectives (e.g., minimize CD under realism constraints) or user preferences. Potential tools/workflows: Bayesian optimization or reinforcement learning over τ₀; multi‑objective scoring. Assumptions/dependencies: Reliable objective metrics; sufficient compute for iterative tuning.
- 4D dynamic asset generation — Animation/Simulation Extend spatial control to time‑varying shapes (articulation, deformation) with consistent appearance. Potential tools/workflows: Temporal flow models; sequence decoders; per‑frame part‑aware control. Assumptions/dependencies: New training regimes; increased compute; temporal coherence constraints.
- Reverse engineering from partial scans — AEC/Industrial Decompose LiDAR/RGB‑D scans into primitives and regenerate faithful, textured models that fill missing data. Potential tools/workflows: Robust superquadric decomposition; completion via SpaceControl; QA tools for accuracy. Assumptions/dependencies: Scan quality; domain‑specific priors; tolerance to noise and occlusion.
- Standards and policy for synthetic 3D content — Policy/Compliance Establish provenance, disclosure, and quality benchmarks for generated assets used in commerce, safety‑critical simulations, or public communications. Potential tools/workflows: Asset watermarking; audit trails; standardized metrics (CD, P‑FID, CLIP‑I) in QA pipelines. Assumptions/dependencies: Cross‑industry coordination; regulatory adoption; transparent dataset documentation.
Notes on Assumptions and Dependencies
- Pretrained model reliance: SpaceControl depends on models like Trellis/SAM‑3D, their encoders/decoders (CLIP, DINOv2), and their training domain coverage.
- Geometry resolution: Current voxelization (64×64×64) and latent sizes may miss very fine details; exporting to high‑res meshes may require post‑processing.
- Human‑in‑the‑loop: The τ₀ parameter is manually tuned; automated selection and per‑part control are future work.
- Physical validity: Outputs are visually realistic but do not guarantee structural integrity or physical properties; downstream validation is needed for manufacturing/simulation.
- IP and licensing: Use of training/reference images and model weights must respect licensing and provenance requirements; content moderation may be required.
- Compute constraints: Real‑time workflows need GPUs; mobile/on‑device scenarios require model compression and optimization.
- Integration readiness: DCC/CAD/BIM pipelines require format compatibility (glTF/FBX/STL/STEP) and potential custom decoders; QA with metrics (CD, FID, P‑FID, CLIP‑I) should be built into pipelines.
Glossary
- 3D Gaussians (GS): Point-based 3D representation using Gaussian primitives for rendering and downstream decoding. "3D gaussians (GS), radiance fields (RF), and meshes (M) via specific decoders ."
- Appearance Flow Model: The second-stage rectified-flow denoiser in Trellis that generates per-voxel appearance features conditioned by text or images. "denoised by the Appearance Flow Model (FM), using either text or image conditioning."
- Binary occupancy grid: A discrete 3D voxel volume with 0/1 values indicating empty or occupied cells, representing object structure. "decoded by a decoder into a binary occupancy grid "
- Chamfer Distance (CD): A symmetric distance between two point sets used to measure geometric alignment or faithfulness. "Faithfulness to the spatial control is quantified using the L2 Chamfer Distance (CD) between vertices sampled from the input superquadric primitives and the generated mesh decoded by ."
- CLIP similarity (CLIP-I): A metric measuring alignment between image renderings and textual prompts using CLIP embeddings. "Faithfulness to the textual control is quantified with the CLIP similarity (CLIP-I) between the renderings of generated assets and the textual prompts."
- CLIP text encoder: The text feature extractor from CLIP used to condition generative models. "text conditions are encoded via the CLIP~\citep{radford2021learning} text encoder"
- Coin3D: A guidance-based 3D generation pipeline that uses 2D single-view synthesis, multi-view diffusion, and SDS to reconstruct 3D. "Coin3D~\citep{dong2024coin3d} uses the shape-guidance to first generate a single view of the desired 3D asset, then leverage a Multi-View-Diffusion model to generate consistent multiple views, and finally extract the 3D representation using a volumetric-based score distillation sampling."
- ControlNet: A method that adds a trainable control branch connected by zero convolutions to enable conditional guidance without forgetting pretrained knowledge. "ControlNet~\citep{zhang2023adding, bhat2024loosecontrol} which add conditional control to a section of the network by introducing a trainable copy connected to the original via zero convolutions."
- Diffusion Transformer: A transformer architecture that predicts denoising dynamics (velocity fields) in diffusion/flow models. "the vector field is predicted for example by a Diffusion Transformer~\citep{peebles2023scalable} as in Trellis~\citep{xiang2024structured} or SAM 3D~\citep{sam3dteam2025sam3d3dfyimages}."
- DINOv2: A pretrained vision transformer used to encode image conditioning for generative models. "image conditions are encoded via DINOv2~\citep{oquab2024dinov2}"
- Fréchet Inception Distance (FID): A distributional distance between sets of images assessing visual realism via Inception features. "Fréchet Inception Distance (FID)~\citep{heusel2017gans} on image renderings"
- Latent space intervention: Injecting control by modifying model latents during inference to steer generation. "conditions a powerful pre-trained generative model (Trellis) on user-defined geometry via latent space intervention, enabling geometry-aware generation without the need for costly fine-tuning."
- LatentNeRF: A guidance-based method that performs test-time optimization using latent diffusion and NeRF-style rendering. "guidance-based methods such as LatentNeRF \citep{metzer2023latent}"
- Multi-View-Diffusion model: A diffusion approach that generates consistent multiple 2D views of an object for 3D reconstruction. "then leverage a Multi-View-Diffusion model to generate consistent multiple views"
- P-FID: A point-cloud analogue of FID that evaluates geometric realism using point-based features. "P-FID~\citep{nichol2022point}, the point cloud analog for FID."
- PointNet++: A hierarchical neural network for extracting features from point clouds. "PointNet++~\citep{qi2017pointnet++} features"
- Radiance fields (RF): Implicit volumetric representations modeling color and density for view synthesis. "3D gaussians (GS), radiance fields (RF), and meshes (M)"
- Rectified flow models: Flow-matching generative models that use a linear interpolation forward process and learn a velocity field to invert noise. "Rectified flow models use a linear interpolation forward (diffusion) process where for a specific time step , the latent can be expressed as "
- SAM 3D: A recent two-stage rectified-flow 3D generative framework analogous to Trellis. "as in Trellis~\citep{xiang2024structured} or SAM 3D~\citep{sam3dteam2025sam3d3dfyimages}"
- Score distillation sampling: An optimization technique that distills diffusion model gradients to fit 3D representations. "using a volumetric-based score distillation sampling"
- SDEdit: A training-free editing method that restarts denoising from a partially noised input to follow coarse guidance. "SDEdit~\citep{meng2021sdedit} which uses stroke paintings to condition the generation of SDE-based generative models for images"
- Shap-E: A neural generative model for 3D shapes that supports various output formats and can be fine-tuned for control. "by finetuning Shap-E~\citep{jun2023shap} separately on chairs, tables and airplanes from ShapeNet~\citep{chang2015shapenet}."
- Spatial control: Explicit conditioning that constrains geometry during 3D generation. "introduce SpaceControl, a training-free test-time method for explicit spatial control of 3D generation."
- Structure Flow Model: The first-stage rectified-flow denoiser in Trellis that generates occupancy structure from noise. "employing the original Structure Flow Model."
- Superquadrics: A compact parametric family of shapes defined by scales and exponents, suitable as geometric primitives for control. "Superquadrics \citep{Barr1981SuperquadricsAA} provide a compact parametric family of shapes capable of representing diverse geometries."
- Trellis: A two-stage 3D generative model that separately synthesizes structure and appearance using rectified flows. "Trellis~\citep{xiang2024structured} is a recent 3D generative model which employs rectified flow models to generate 3D assets from either textual or image conditioning."
- Velocity field: The time-dependent vector field that drives the denoising trajectory in rectified flow models. "The backward (denoising) process is represented by a time dependent velocity field ."
- Voxel grid: A structured, discrete 3D grid of voxels used to represent object occupancy or features. "outputs the voxel grid "
- Voxelization: The process of converting geometric input into a voxel grid for encoding and guidance. "we voxelize it to obtain $x_c\in\{0,1\}^{64\times64\times64\}$"
Collections
Sign up for free to add this paper to one or more collections.