- The paper introduces a unified benchmark that evaluates complex multi-object and game-world image editing tasks using dual textual and ground-truth references.
- It details a scalable data synthesis pipeline producing over 100,000 annotated samples for supervised training of reasoning and image generation models.
- Experimental results show that UniREdit-Bagel significantly outperforms competitors, especially in multi-step planning and rule-based manipulation.
UniREditBench: A Unified Benchmark for Reasoning-Based Image Editing
Motivation and Problem Statement
Recent progress in multimodal generative models has significantly advanced instruction-conditioned image editing. However, existing benchmarks for image editing predominantly focus on single-object attribute transformations in realistic scenarios, neglecting complex multi-object interactions and game-world scenarios governed by explicit rules. Furthermore, current evaluation protocols rely almost exclusively on textual references, which can result in systematic misjudgments, particularly in tasks requiring implicit or multi-step reasoning. UniREditBench addresses these limitations by introducing a comprehensive benchmark that systematically evaluates reasoning-based image editing across both real-world and game-world scenarios, and by proposing a dual-reference evaluation protocol that leverages both textual and ground-truth (GT) image references.
Benchmark Design and Evaluation Dimensions
UniREditBench comprises 2,700 meticulously curated samples, organized into a scenario-to-category hierarchy spanning 8 primary dimensions and 18 sub-dimensions. The benchmark covers both real-world and game-world scenarios, each presenting unique reasoning challenges.
This broad coverage enables systematic assessment of models' abilities to perform implicit reasoning, multi-step planning, and rule-based manipulation, which are underrepresented in prior benchmarks.
Dual-Reference Evaluation Protocol
A key innovation in UniREditBench is the dual-reference evaluation protocol. For each editing task, both a textual reference and a GT image reference are provided. This enables vision-LLM (VLM) evaluators to perform direct, fine-grained comparisons at both the semantic and visual levels, mitigating the risk of misjudgment inherent in text-only evaluation.
- Instruction Following: Measures the alignment between the generated image, the instruction, and both references.
- Visual Consistency: Assesses preservation of instruction-irrelevant content.
- Visual Quality: Evaluates realism and perceptual integrity.
Scores are aggregated via a weighted sum, prioritizing instruction following. The evaluation pipeline employs GPT-4.1 as the VLM judge, with each dimension scored on a 1–5 scale.

Figure 2: Comparison between text-reference-only and dual-reference evaluation, demonstrating improved reliability with the latter.
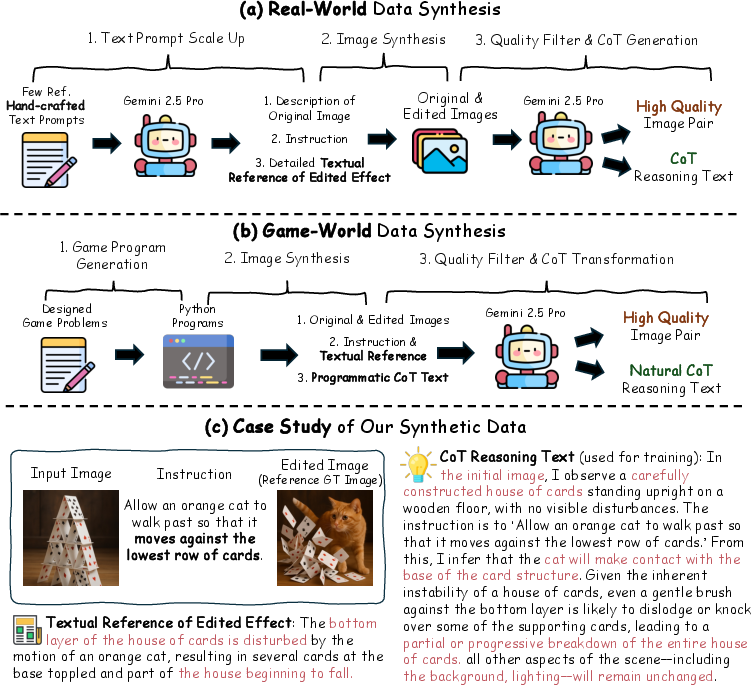
Multi-Scenario Data Synthesis Pipeline
To support both benchmark construction and model training, the authors introduce a scalable data synthesis pipeline tailored for real-world and game-world scenarios.
This pipeline produces both the UniREditBench benchmark and UniREdit-Data-100K, a large-scale synthetic dataset with high-quality CoT annotations.
UniREdit-Data-100K and Model Fine-Tuning
UniREdit-Data-100K contains over 100,000 samples, balanced across all reasoning categories. Each sample includes the original image, editing instruction, stepwise CoT reasoning, and the target edited image. The dataset supports supervised training of both reasoning and image generation components.
The Bagel model is fine-tuned on UniREdit-Data-100K, resulting in UniREdit-Bagel. The training objective combines negative log-likelihood for CoT text and a flow-matching loss for image generation in VAE latent space, with explicit supervision for both reasoning and visual fidelity.
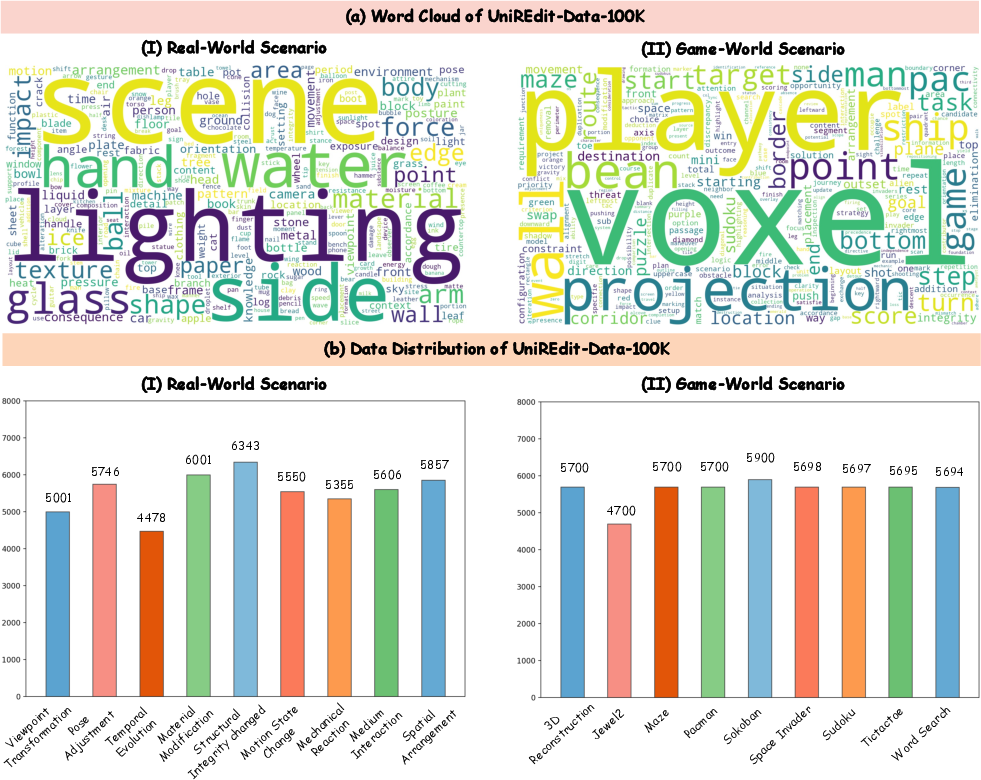
Figure 4: Visualization of word clouds and data distribution in UniREdit-Data-100K, highlighting vocabulary diversity and balanced category coverage.
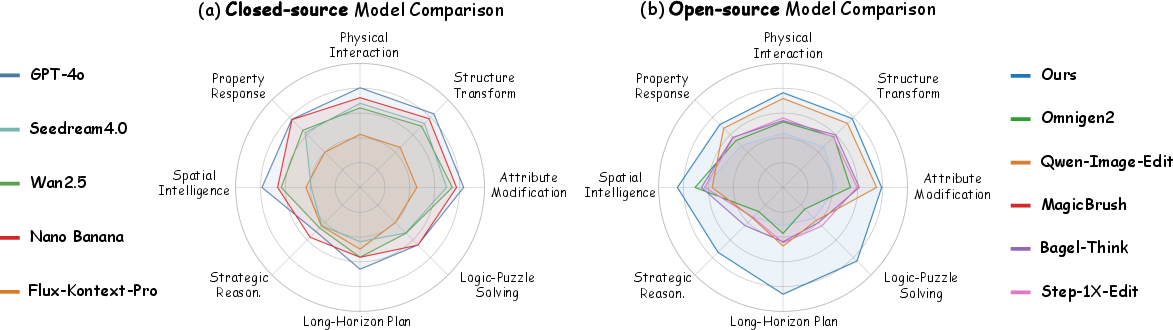
Experimental Results and Analysis
In-Domain Performance
Comprehensive benchmarking on UniREditBench reveals that:
Out-of-Distribution Generalization
On RISEBench and KRISBench, UniREdit-Bagel achieves the strongest open-source results, outperforming previous Bagel variants and even surpassing some closed-source models in several categories. This indicates improved generalization to unseen reasoning-based editing tasks.
Qualitative Analysis
Qualitative comparisons show that UniREdit-Bagel excels in both instruction following and visual quality, particularly in tasks involving physical effects, multi-step planning, and rule-based manipulation. Competing models often fail to preserve instruction-irrelevant content or to realize complex reasoning objectives.

Figure 6: Qualitative editing result comparison, demonstrating UniREdit-Bagel's superiority in instruction following and visual quality.
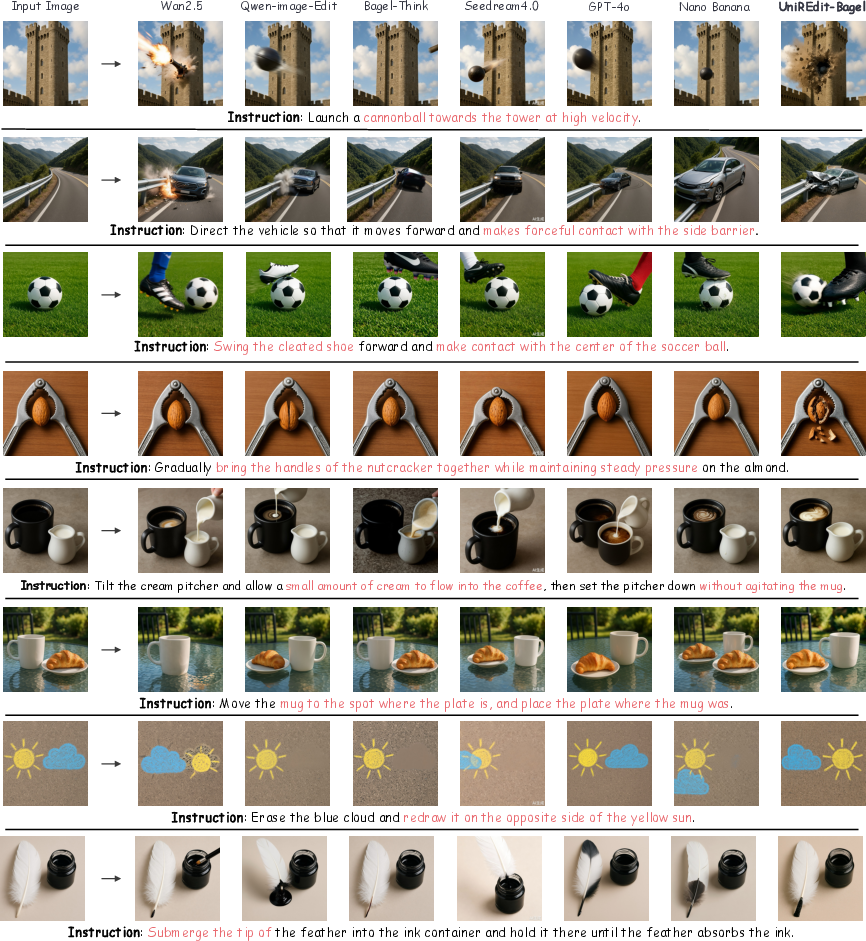
Figure 7: Additional qualitative comparisons on UniREditBench, highlighting UniREdit-Bagel's strengths in diverse scenarios.

Figure 8: Qualitative editing result comparison on RISEBench, showing robust generalization of UniREdit-Bagel.
Data Filtering and Human Inspection
A multi-stage filtering pipeline ensures data quality, including exact-match and semantic deduplication, VLM-based quality filtering across six dimensions, and final manual inspection via web interfaces.
Figure 9: Web interface for the initial filtering stage.
Figure 10: Web interface for the manual correction stage.
Implications and Future Directions
UniREditBench establishes a new standard for reasoning-based image editing evaluation, addressing critical gaps in scenario coverage and evaluation reliability. The dual-reference protocol and large-scale reasoning-annotated dataset enable more robust training and assessment of generative models. The strong performance of UniREdit-Bagel, particularly in complex reasoning tasks, suggests that explicit reasoning supervision and diverse scenario coverage are essential for advancing image editing capabilities.
Future research directions include:
- Extending benchmarks to cover additional reasoning types (e.g., causal, counterfactual).
- Developing more sophisticated VLM-based evaluators with explainable judgments.
- Exploring reinforcement learning and preference-based fine-tuning for further alignment with human reasoning.
- Investigating transferability of reasoning skills across modalities and tasks.
Conclusion
UniREditBench provides a unified, comprehensive benchmark for reasoning-based image editing, introducing a dual-reference evaluation protocol and a scalable data synthesis pipeline. The accompanying UniREdit-Data-100K dataset and UniREdit-Bagel model demonstrate substantial improvements in both in-domain and out-of-distribution settings. This work offers a robust foundation for future research on reasoning-driven generative models and sets a new baseline for systematic evaluation in this domain.