MotionEdit: Benchmarking and Learning Motion-Centric Image Editing
Abstract: We introduce MotionEdit, a novel dataset for motion-centric image editing-the task of modifying subject actions and interactions while preserving identity, structure, and physical plausibility. Unlike existing image editing datasets that focus on static appearance changes or contain only sparse, low-quality motion edits, MotionEdit provides high-fidelity image pairs depicting realistic motion transformations extracted and verified from continuous videos. This new task is not only scientifically challenging but also practically significant, powering downstream applications such as frame-controlled video synthesis and animation. To evaluate model performance on the novel task, we introduce MotionEdit-Bench, a benchmark that challenges models on motion-centric edits and measures model performance with generative, discriminative, and preference-based metrics. Benchmark results reveal that motion editing remains highly challenging for existing state-of-the-art diffusion-based editing models. To address this gap, we propose MotionNFT (Motion-guided Negative-aware Fine Tuning), a post-training framework that computes motion alignment rewards based on how well the motion flow between input and model-edited images matches the ground-truth motion, guiding models toward accurate motion transformations. Extensive experiments on FLUX.1 Kontext and Qwen-Image-Edit show that MotionNFT consistently improves editing quality and motion fidelity of both base models on the motion editing task without sacrificing general editing ability, demonstrating its effectiveness.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
MotionEdit: A simple explanation
Overview
This paper is about teaching image editing AI to change how people or objects are moving in a picture—like raising a hand or turning toward a dog—while keeping everything else the same. The authors build a new dataset and test, called MotionEdit and MotionEdit-Bench, to measure how well AIs handle these “motion edits.” They also introduce a training method, MotionNFT, that helps AIs follow motion instructions more accurately.
What questions did the researchers ask?
- Can we build a high-quality dataset that focuses on motion changes (actions, poses, interactions) rather than just looks (color, style, add/remove objects)?
- How can we fairly test whether an AI’s motion edit matches what was asked?
- Do current image-editing models handle motion edits well?
- Can we improve these models so they change motion correctly without breaking the person’s identity or the scene?
How did they study it?
Building the MotionEdit dataset
Most editing datasets focus on looks (like “make the sky pink”) and include few or messy motion changes. Instead, MotionEdit collects “before” and “after” frames from high-quality videos where a motion naturally happens (for example, “not drinking → drinking,” “arm down → arm up”). This gives realistic pairs where only the action changes and the person and background stay consistent.
- Where the data comes from: sharp, stable text-to-video sources (Veo-3 and KlingAI), not shaky real-world clips.
- How they filtered the pairs: a multimodal AI (an MLLM) checks each pair to keep only those with:
- Stable background and viewpoint
- Clear, meaningful motion change
- No weird artifacts or missing subjects
- Clean instructions: another AI rewrites the motion change into a simple edit command like “Make the woman turn her head toward the dog.”
The final dataset has 10,157 “before → after” pairs, split into training and testing. It covers six kinds of motion edits: pose/posture, locomotion/distance, object state/formation, orientation/viewpoint, subject–object interaction, and inter-subject interaction.
Checking how good models are (MotionEdit-Bench)
To evaluate models on motion edits, the authors use three types of measures:
- Generative ratings (by an MLLM): scores for Fidelity (does it look real?), Preservation (does the person and scene stay consistent?), and Coherence (does the change make sense?). They also average these into an Overall score.
- Motion Alignment Score (MAS): a science-y but simple idea—compare motion in the model’s edited image to the motion in the ground-truth “after” image. Think of “optical flow” like tiny arrows over every pixel showing where it moved and by how much; MAS checks if the model’s arrows match the real arrows.
- Preference (Win Rate): in head-to-head comparisons, how often does one model’s edit look better than another’s?
Teaching models to do motion edits (MotionNFT)
Many models are good at changing looks (colors, styles), but weak at changing motion (poses, interactions). The authors propose MotionNFT, a way to fine-tune models using motion-aware rewards:
- Core idea: reward models when the motion in their edited image matches the ground-truth motion in both direction (which way things moved) and size (how far they moved).
- How they measure motion: optical flow (the “arrows” idea). If the model’s motion arrows line up with the ground truth, it gets a higher reward.
- Balanced training: combine motion rewards (50%) with general image-editing quality rewards from an MLLM (50%), so the model learns motion edits without forgetting how to do other edits.
MotionNFT works as a kind of coach: it gives points when the model changes motion correctly and nudges it away from bad changes, helping it learn to move arms, bodies, and objects in the intended way while keeping faces, styles, and backgrounds consistent.
What did they find?
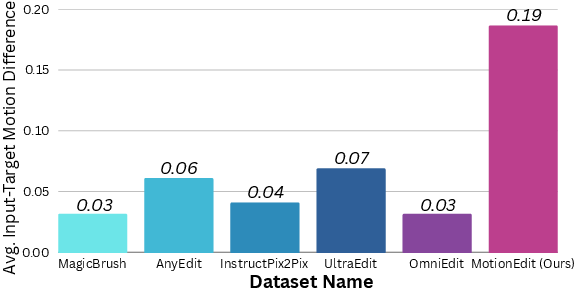
- MotionEdit is truly motion-heavy: compared to popular editing datasets, MotionEdit’s before/after pairs show much bigger and clearer motion changes (about 3–6× more), which makes it a better, more challenging testbed.
- Most models struggle with motion edits: many state-of-the-art editors keep the original pose or only tweak appearance, failing to execute instructions like “turn to face the camera” or “bring the cup to the mouth.”
- MotionNFT improves motion editing:
- On FLUX.1 Kontext, Overall quality rose from 3.84 to 4.25 (about +11%), and motion alignment (MAS) improved from 53.73 to 55.45.
- On Qwen-Image-Edit, Overall quality rose from 4.65 to 4.72, and MAS improved from 56.46 to 57.23.
- Win rates (how often people prefer the edits) also went up (e.g., FLUX.1 Kontext +MotionNFT: 57.97% → 65.16%).
- No trade-off: MotionNFT kept or improved general editing skills on a broader benchmark, so getting better at motion didn’t make models worse at other edits.
- Better than using MLLM rewards alone: adding motion-aware rewards beat training that relied only on MLLM scoring.
Why it matters
- Smarter image edits: Changing motion correctly is key for believable photos, comics, and character stills—especially when you must keep the same person and scene.
- Stronger building block for video: If you can precisely control motion frame by frame, you can produce cleaner, more realistic videos and animations.
- Fair testing and faster progress: MotionEdit and MotionEdit-Bench give the community a standard way to train and measure motion edits, accelerating research on pose changes, interactions, and action realism.
- Real-world uses: animation, filmmaking, game development, virtual try-ons, sports analysis, and creative tools can all benefit from accurate motion editing.
In short, this paper shows that motion edits are hard but solvable. By providing the right data (MotionEdit) and the right training signal (MotionNFT’s motion-aware rewards), image editing AIs can learn to change actions and poses in a natural, consistent way—opening the door to better animations, smarter video tools, and more expressive creative apps.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of what remains missing, uncertain, or unexplored in the paper, phrased to be directly actionable for future research.
- Dataset domain gap: MotionEdit is sourced entirely from synthetic T2V videos (Veo-3, Kling-AI), not real-world footage; generalization to real photographs and in-the-wild videos with camera motion, noise, blur, and complex occlusions is untested.
- Limited scene dynamics: MLLM-based filtering explicitly favors stable backgrounds/viewpoints, potentially biasing the dataset against realistic camera motion and dynamic environments; robustness to camera motion and background changes remains open.
- Instruction fidelity: Editing prompts are auto-generated by an MLLM rewrite without human verification; no measurement of prompt-target semantic alignment, ambiguity handling, or inter-annotator agreement is provided.
- Category coverage and balance: The distribution of the six motion categories (pose, locomotion, object state, orientation, subject–object, inter-subject) is not reported; coverage of rare actions (fine-grained hand manipulation, subtle facial gestures, crowded scenes) is unknown.
- Scale and diversity: 10k pairs may be small for the breadth of motion types and subject/object variability; diversity across domains (humans vs animals vs mechanical objects; indoor vs outdoor; stylized vs photorealistic) is insufficiently characterized.
- Temporal context: The task is single-image editing and ignores temporal continuity; extending to multi-frame editing, enforcing temporal consistency, and leveraging video trajectory cues are unexplored.
- Sampling bias: Using first/last frames in 3-second segments may bias toward larger motions or unintended viewpoint changes; alternative frame selection strategies (motion-aware keyframes) are not evaluated.
- Optical flow reliability: MAS and MotionNFT rely on optical flow computed between generated and ground-truth images, but flow reliability under large appearance changes, generative artifacts, occlusions, specularities, and textureless regions is not analyzed.
- Flow estimator dependence: Only UniMatch is used; sensitivity to different optical flow estimators (RAFT, GMFlow, PWC-Net, newer transformers) and their calibration on synthetic versus real data is untested.
- MAS validity: Correlation of MAS with human judgments of motion correctness is not measured; the metric’s semantic blindness (contact changes, intent of interaction, physical plausibility) is unaddressed.
- MAS normalization details: The choice and computation of d_min/d_max, per-dataset vs per-prompt normalization, and its effect on comparability and reproducibility are unspecified.
- Occlusion handling: The reward/metric does not incorporate occlusion masks or forward–backward flow consistency; handling disocclusions and hidden limbs/objects during motion edits is unresolved.
- Subject-centric weighting: Flow-based reward is applied over the whole image; focusing the reward on subjects/objects of interest (via segmentation, detection, or pose priors) to avoid background bias is not explored.
- Small motion calibration: The movement regularization term may penalize correct subtle motions; calibration of τ and thresholds to avoid over-penalizing valid small edits remains open.
- Object state/deformation: Flow may not capture internal state changes (e.g., grasping, contact formation, deformation) or discrete interaction state (holding vs drinking); metrics capturing contact and affordance semantics are missing.
- Identity preservation metrics: Beyond MLLM ratings, no objective identity/appearance preservation metrics (face ID verification, CLIP similarity, LPIPS/SSIM) are reported; failure cases of identity drift need quantification.
- Physical plausibility: The method claims plausibility but does not include explicit physics or 3D body constraints; integrating 3D pose estimation, kinematic limits, contact dynamics, and collision checks is an open direction.
- Language-to-kinematics grounding: The approach does not explicitly model mapping from verbs/relations to spatial constraints; leveraging structured parsers, semantic role labeling, or 3D priors for instruction grounding is unexplored.
- Reward mixing: MotionNFT fixes a 50% optical-flow reward and 50% MLLM reward; ablations on reward weight schedules, curriculum learning, and prompt-dependent weighting are missing.
- Reward quantization: MotionNFT discretizes a continuous score into 6 levels; the impact of quantization vs continuous rewards on learning stability and sample efficiency is not analyzed.
- Hyperparameter sensitivity: No sensitivity studies for α, β, λ_move, q, τ (and NFT β mixing) are provided; automatic tuning or adaptive normalization for robust training is an open need.
- RL stability and theory: NFT’s negative-aware updates under noisy, non-stationary rewards (online MLLM + flow) lack convergence analysis; comparisons to PPO/GRPO or offline RL variants are limited.
- Computational cost: Online MLLM scoring adds significant training overhead; efficiency strategies (reward distillation, proxy models, caching, offline scoring) are not investigated.
- Multi-agent interactions: MAS does not capture interaction correctness (who moves, coordinated motion, social cues); designing multi-subject structural metrics (pose graphs, contact pairs) is an open challenge.
- Viewpoint vs orientation: Distinguishing subject reorientation from camera rotation in evaluation/reward is not handled; incorporating depth/pose to disambiguate viewpoint effects is needed.
- Depth scaling: Flow normalization by image diagonal ignores perspective scaling; depth-aware normalization using monocular depth could improve comparability across scenes.
- Robustness/stress testing: No adversarial/edge-case evaluation for ambiguous instructions, conflicting edits, occlusions, or cluttered backgrounds; benchmarks for failure modes are missing.
- Statistical significance: Reported gains (e.g., MAS +1–1.7, Overall +0.07–0.41) lack statistical tests; confidence intervals, bootstrap analyses, or per-category significance are absent.
- Human evaluation: Preference/win rates rely on MLLM judgments; rigorous human studies, inter-rater reliability, and alignment of MLLM evaluators with human preferences are not presented.
- Closed-source dependence: Dataset filtering and generative evaluation use Gemini; replicability under model/version drift and open-source evaluator replacements are not addressed.
- Reproducibility: The paper promises release upon acceptance; current unavailability of data, code, prompts, and evaluator configurations (including Gemini instructions) limits reproducibility.
- Fair comparison to closed-source baselines: Case studies show failures but no quantitative head-to-head comparisons with commercial models; standardized evaluation across APIs remains open.
- Cross-dataset generalization: Performance on existing motion-related editing or real-world action benchmarks (e.g., human action datasets, sports frames) is not reported.
- Motion magnitude analysis: The 100-sample-per-dataset motion magnitude comparison is small; comprehensive, category-stratified comparisons and variance reporting are missing.
- Safety and ethics: No analysis of potentially harmful edits (e.g., violence, misrepresentation), dataset content filters, or usage restrictions; policy and ethical guidelines are unspecified.
- Licensing and provenance: T2V video dataset licensing, redistribution rights, and consent for derived frame pairs and prompts are not clarified.
Practical Applications
Overview
This paper introduces three practical assets:
- MotionEdit: a high-quality dataset and benchmark for motion-centric image editing (modifying actions/poses/interactions while preserving identity and scene).
- MotionEdit-Bench: an evaluation suite combining MLLM-based generative scores and an optical-flow–based Motion Alignment Score (MAS).
- MotionNFT: a post-training framework that adds motion-aware, optical-flow rewards to diffusion/flow-matching image editors, improving motion fidelity without degrading general editing.
Below are specific, real-world applications that leverage these contributions, grouped by deployment timeline and linked to relevant sectors. Each item includes tools/workflows that could emerge and key dependencies or assumptions.
Immediate Applications
The following can be piloted with current models, the released dataset/benchmark, and standard GPUs.
- Motion-centric image editing in creative tools (industry: media/advertising/design/software)
- Use case: Precisely change a subject’s pose, orientation, or interaction in a photo (e.g., “turn the model’s head toward the product,” “make the athlete bend knees more”) while preserving identity and background.
- Workflow/products: Plugins for Photoshop/GIMP; After Effects/Blender add-ons; web UIs for “motion edits” alongside color/replace/style operations using MotionNFT-finetuned FLUX.1 Kontext or Qwen-Image-Edit.
- Dependencies/assumptions: Base editor supports in-context editing; compute for inference; content rights; UI affordances for pose/interaction instructions.
- Frame-controlled video production from key images (industry: film/animation/social media/video)
- Use case: Edit keyframes to enforce target actions/poses, then generate in-between frames with a separate T2V/V2V engine; fix continuity errors by adjusting actors’ postures between shots.
- Workflow/products: “Key-pose corrector” stage that edits frame pairs; MAS-based QA to approve edits before downstream video synthesis.
- Dependencies/assumptions: Integration with existing T2V/V2V tools; consistent character identity; handling camera motion.
- Ad creative and e-commerce imagery at scale (industry: marketing/e-commerce/fashion)
- Use case: Adjust model stance/hand placement around a product; change product state (open/close, fold/unfold) without reshoots; ensure on-brand pose catalogs.
- Workflow/products: Batch pipelines with MotionNFT-finetuned editors and MLLM-based QC; brand-specific pose templates.
- Dependencies/assumptions: Legal clearance for edits; domain shift from synthetic video–sourced pairs to studio photography.
- Rapid storyboard and comic/manga iteration (industry: publishing/entertainment)
- Use case: Repose characters panel-by-panel while keeping identity and background; refine interactions among characters.
- Workflow/products: Storyboard editors with motion-edit controls; MAS-assisted checks for motion plausibility across panels.
- Dependencies/assumptions: Complex interactions and occlusions may need manual touch-ups.
- Educational visuals for motion/kinematics (academia/education/daily use)
- Use case: Create before/after diagrams illustrating posture changes, mechanical state transitions, or viewpoint changes for physics/PE classes.
- Workflow/products: Lightweight web app that applies motion edits with text prompts; library of canonical motion transformations.
- Dependencies/assumptions: Appropriateness for minors/education; accurate depiction of biomechanics.
- Sports coaching and form feedback content (industry: sports/fitness/education)
- Use case: Generate illustrative “correct form” images from a user’s photo (e.g., “tilt torso forward,” “align knees over toes”) for personal training materials.
- Workflow/products: Coaching apps that generate corrected snapshots; MAS-based filter to flag negligible or implausible edits.
- Dependencies/assumptions: Not a medical device; must avoid unsafe biomechanical suggestions; liability considerations.
- Synthetic data augmentation for perception and action understanding (industry/academia: robotics/autonomous systems/CV)
- Use case: Create controlled pose/action variations while preserving background for training detectors, keypoint estimators, or interaction classifiers.
- Workflow/products: Data engines that apply label-preserving motion edits to curated image sets; MAS as a label-consistency gate.
- Dependencies/assumptions: Labels remain valid post-edit; bias from T2V-derived motions; occlusions may degrade ground-truth.
- Scenario design for AV/robotics edge cases (industry: automotive/robotics)
- Use case: Alter pedestrian/vehicle motion in traffic images to synthesize rare cases (e.g., “pedestrian starts to step onto crosswalk”).
- Workflow/products: Scenario authoring tools integrating motion edits for rare-event training or HIL testing.
- Dependencies/assumptions: Domain realism; regulatory posture on synthetic training data; careful validation.
- Benchmarking and diagnostics for motion editing models (academia/industry R&D)
- Use case: Evaluate new editing or T2V models on motion-following ability using MotionEdit-Bench, MAS, and preference metrics.
- Workflow/products: Standardized leaderboards; ablation tooling for reward shaping; continuous integration checks for motion regressions.
- Dependencies/assumptions: Reproducibility and access to dataset; optical-flow estimator choice impacts MAS.
- Production QA for AIGC pipelines (industry: AIGC/software)
- Use case: Automatic checks that motion edits follow instructions and remain physically plausible before content is published.
- Workflow/products: MAS + MLLM composite gate in CI/CD for image/video pipelines; dashboards for human review.
- Dependencies/assumptions: Threshold tuning per brand; failure modes for heavy occlusions or large camera motion.
- Ethical audits and media forensics training aids (policy/academia/security)
- Use case: Train analysts on spotting motion-edited imagery; use MAS-like motion-consistency checks to flag suspicious edits in QA contexts.
- Workflow/products: Forensic training sets from MotionEdit; internal detectors that penalize implausible motion flows.
- Dependencies/assumptions: Not a robust deepfake detector alone; adversaries may adapt to metrics; ethical review required.
Long-Term Applications
These require further research, scaling, safety guardrails, or deeper integrations.
- Physics-aware, constraint-driven motion editing (industry/academia: VFX/robotics/simulation)
- Vision: Edit actions while enforcing kinematic constraints and contact dynamics (no limb interpenetrations, physically valid grasps).
- Emerging tools: Editors that combine MotionNFT with differentiable physics or pose/mesh priors; constraint solvers in the reward loop.
- Dependencies/assumptions: High-quality 3D/body models; physics engine integration; reliable self-consistency checks.
- End-to-end controllable video generation with precise motion tracks (industry: film/gaming/AR)
- Vision: Author shot-level motion through text, pose strokes, or keypoints, then synthesize temporally consistent videos.
- Emerging tools: Hybrid pipelines—motion-edited keyframes + trajectory-conditioned T2V; timeline editors with MAS-derived motion curves.
- Dependencies/assumptions: Robust identity preservation across frames; scalable reward models; multi-frame optical flow reliability.
- 4D scene and character editing from a single image prompt (industry/academia: graphics/telepresence)
- Vision: Expand a still image into consistent short clips where requested actions occur with the original subject and environment.
- Emerging tools: Single-image-to-4D expanders with motion-aware rewards; pose graph editors.
- Dependencies/assumptions: Strong priors for geometry and appearance; view synthesis; occlusion handling.
- Interactive pose/interaction authoring UIs (software/HCI/education)
- Vision: Users drag joints, draw arrows, or manipulate skeletons to specify motion; system renders edited images/video clips.
- Emerging tools: Skeleton-aware frontends; joint-level constraints; two-way links between text prompts and pose widgets.
- Dependencies/assumptions: Reliable 2D/3D pose extraction; UX for collisions/occlusions; latency constraints.
- Robotics imitation and affordance learning from motion-edited exemplars (industry/academia: robotics)
- Vision: Generate paired “before/after” images demonstrating task steps for pretraining visual policies (e.g., grasp → lift → place).
- Emerging tools: Affordance-label propagation after edits; reward signals from optical-flow alignment embedded in policy learning.
- Dependencies/assumptions: Sim-to-real gap; multi-view data; causal correspondence between edited visuals and executable actions.
- Standardization and compliance frameworks for motion edits (policy/standards/media)
- Vision: Disclosure taxonomies for motion edits; provenance metadata for motion transformations; safe-use guidelines.
- Emerging tools: Motion-edit capability benchmarks for procurement; watermarking/provenance tags for action edits.
- Dependencies/assumptions: Multi-stakeholder adoption; regulation harmonization; privacy and IP concerns.
- Medical rehab and telehealth motion guidance (healthcare/education)
- Vision: Generate personalized, stepwise motion instructions for exercises from patient photos, ensuring correct posture depiction.
- Emerging tools: Clinician-in-the-loop authoring; biomechanical plausibility checks; sequence generation from edited keyframes.
- Dependencies/assumptions: Clinical validation and regulatory approval; risk management to avoid harmful guidance.
- Procedural content generation with motion-aware control (gaming/AR/VR)
- Vision: PCG pipelines that re-pose NPCs, adjust interactions, and stage dynamic scenes from stills or concept art.
- Emerging tools: Motion-edit controllers tied to narrative beats; MAS as reward for scene coherence.
- Dependencies/assumptions: Engine integration (Unreal/Unity); consistent multi-character interactions.
- Advanced misinformation risk mitigation (policy/security)
- Vision: Counter-motion-edit misuse via detection models trained on MotionEdit variants; establish red-team benchmarks for motion manipulations.
- Emerging tools: Motion-consistency anomaly detectors; audit trails for editorial workflows.
- Dependencies/assumptions: Adversarial arms race; legal/ethical boundaries for detection and disclosure.
- Cross-modal motion control (speech/gesture → motion edits) (software/HCI)
- Vision: Speak or gesture to direct motion edits (“raise the right arm slightly,” “rotate toward me”).
- Emerging tools: Multimodal interfaces mapping voice/gesture to pose deltas; RL with motion rewards for alignment.
- Dependencies/assumptions: Robust ASR/gesture recognition; disambiguation in multi-subject scenes.
Notes on Feasibility and Dependencies
- Technical dependencies:
- MotionNFT assumes availability of a compatible diffusion/flow-matching editor, optical-flow estimator (e.g., UniMatch/RAFT), and an MLLM scorer for composite rewards.
- Training cost and data: Finetuning requires GPUs (FSDP, checkpointing), and data rights for MotionEdit’s sources; domain shift from T2V-derived pairs to real photos must be addressed with additional curation.
- Metrics sensitivity: MAS depends on optical flow quality; failures under large camera motion/occlusion may require masking or camera-motion compensation.
- Ethical and legal considerations:
- Potential for misuse (e.g., altering apparent actions). Production systems should include provenance, disclosure, and moderation (policy alignment, watermarking).
- Sector-specific regulations (healthcare, advertising truth-in-image) may limit deployment without human oversight.
- Productization assumptions:
- Integration with creative suites and T2V pipelines; user education for motion-specific prompts; robust identity preservation across edits.
- UI affordances for multi-character interactions and object contacts are likely necessary for non-expert users.
These applications leverage the paper’s core insight: motion-aware supervision (via optical flow) plus negative-aware finetuning meaningfully improves action/pose editing while maintaining general editing quality, enabling more reliable motion control in both still-image workflows and video pipelines.
Glossary
- Ablation Studies: Systematic removal or modification of components to assess their impact on performance. "Ablation Studies"
- Articulated constraints: Physical limits and joint constraints of articulated bodies that ensure plausible poses. "respects articulated constraints"
- Composite distance: An aggregate measure combining multiple error terms into a single scalar for optimization. "We aggregate the three terms into a composite distance"
- Cosine-based directional error: A measure of angular mismatch between predicted and ground-truth motion directions using cosine similarity. "We compute cosine-based directional error between the unit flow vectors"
- Denoising Diffusion Probabilistic Models (DDPMs): A class of generative models that iteratively denoise samples to produce data distributions. "Denoising Diffusion Probabilistic Models (DDPMs)"
- Diffusion Negative-aware Finetuning (NFT): A training scheme that contrasts positive and negative generations to steer diffusion models via reward signals. "Diffusion Negative-aware Finetuning (NFT)"
- Flow Matching Models (FMMs): Generative models that learn a velocity field transporting noise to data via an ODE. "Flow Matching Models (FMMs)"
- Fully Sharded Data Parallelism (FSDP): A distributed training technique that shards model parameters across devices to reduce memory footprint. "we use Fully Sharded Data Parallelism (FSDP) for text encoder"
- GRPO: A reinforcement learning algorithm variant for policy optimization in generative models. "GRPO~\citep{shao2024deepseekmath,liu2025flow} have been explored for improving image generation."
- Gradient checkpointing: A memory-saving technique that recomputes intermediate activations during backpropagation. "apply gradient checkpointing in training for GPU memory usage optimization"
- Kinematics: The study of motion without regard to forces, used to describe changes in position and orientation. "grounded in video kinematics"
- MAS (Motion Alignment Score): A discriminative metric quantifying alignment between predicted and ground-truth motion fields. "Motion Alignment Score (MAS)"
- MLLM (Multimodal LLM): LLMs that process both text and images to score or guide generation. "Multimodal LLM (MLLM)-based metrics"
- Motion direction consistency: Evaluating how well the direction of predicted motion matches the ground truth. "Motion direction consistency."
- Motion magnitude consistency: Evaluating how well the magnitude of predicted motion matches the ground truth. "Motion magnitude consistency."
- MotionNFT: A motion-aware post-training framework that integrates optical-flow–based rewards into NFT. "We further propose Motion-guided Negative-aware FineTuning (MotionNFT), a post-training framework"
- Movement regularization: A penalty to discourage trivial edits by enforcing sufficient motion. "Movement regularization."
- Optical flow: Per-pixel displacement fields between two images representing apparent motion. "Modern approaches rely on optical flow, which predicts per-pixel displacement between two images"
- Optimality reward: A normalized reward used to classify samples as positive or negative for NFT training. "DiffusionNFT transforms them into an optimality reward:"
- Ordinary Differential Equation (ODE): A differential equation defining continuous-time evolution used for model inference. "inference for FMMs reduces to the ODE "
- Pairwise win rate: Preference-based measure of how often a model’s output is chosen over a baseline in head-to-head comparisons. "pairwise win rates through head-to-head comparisons"
- Policy model: The parameterized decision function being optimized under a reinforcement learning objective. "update the policy model "
- Policy-gradient methods: RL algorithms that update policies by estimating gradients of expected rewards. "Policy-gradient methods such as PPO~\citep{schulman2017proximalpolicyoptimizationalgorithms,ren2024diffusion} and GRPO~\citep{shao2024deepseekmath,liu2025flow} have been explored for improving image generation."
- Preference-based metrics: Evaluation measures based on comparative human or automated preferences. "generative, discriminative, and preference-based metrics."
- Prompt refinement: Procedures to rewrite raw analyses into clean, imperative editing instructions. "following the prompt refinement procedure of \citet{wu2025qwenimagetechnicalreport}."
- Stereo tasks: Vision tasks involving depth estimation from paired images, related to optical flow. "unified with stereo tasks."
- Text-to-Image (T2I): Models that generate images conditioned on text prompts. "text-to-image (T2I) diffusion models"
- Text-to-Video (T2V): Models that generate videos conditioned on text prompts. "Text-to-Video (T2V) models"
- UniMatch: An optical flow estimator that frames flow as global matching unified with stereo. "Recent work such as UniMatch~\citep{xu2023unifying} further advances large-displacement estimation"
- vLLM: A high-throughput serving system for LLMs. "via vLLM on a separate node"
- Velocity field: A vector field indicating direction and speed of transport in flow matching. "estimates a deterministic velocity field that transports toward its clean counterpart"
- Video-driven data construction pipeline: A method that mines frame pairs from videos to build editing datasets. "we propose a video-driven data construction pipeline that mines paired frames from dynamic video sequences"
Collections
Sign up for free to add this paper to one or more collections.

