- The paper introduces a novel FED-Score that evaluates editing fidelity, semantic alignment, and relative expression gain using decoupled metrics.
- It details a multi-stage pipeline for constructing a high-quality dataset of 747 in-the-wild facial expression triplets covering seven emotion classes.
- It benchmarks 18 state-of-the-art models, revealing trade-offs between identity preservation, expression accuracy, and background integrity.
FED-Bench: A Cross-Granular Benchmark for Disentangled Evaluation of Facial Expression Editing
Motivation and Limitations of Prior Work
Precise facial expression editing with strict identity and background preservation remains a non-trivial challenge for generative and editing models. Existing benchmarks and metrics are fundamentally ill-suited for this problem domain due to three main constraints: (1) inadequate and small-scale datasets with insufficiently paired ground-truth (GT) for fine-grained evaluation, (2) systemic biases in evaluation metrics whereby fidelity-oriented metrics (e.g., DINO, ArcFace) incentivize models toward lazy editing (minimal modifications), and alignment-oriented metrics (e.g., CLIP) promote overfit editing (overexaggerated changes at the expense of visual fidelity), and (3) the lack of disentangled multi-dimensional protocols that reflect the multi-objective nature of expression editing. These deficiencies collectively stifle methodological progress and impair objective model evaluation.
FED-Bench: Data Construction, Design, and Coverage
FED-Bench responds to these limitations through a comprehensive multi-stage pipeline for benchmark construction and a cross-granular evaluation framework. The authors curated 747 high-quality in-the-wild image triplets, each comprising a source image, a carefully crafted editing instruction, and a GT reference image, covering seven basic emotion classes. The selection process incorporates (1) source image filtering from SFEW 2.0 and DFEW to ensure diversity and visual quality; (2) candidate generation via state-of-the-art diffusion models; (3) novel coarse-grained groupings of emotions to mitigate fine-grained recognition inaccuracies from MLLMs; (4) ensemble-based voting from multiple MLLMs for robust expression verification; (5) dual-metric fidelity ranking using ArcFace-based identity similarity and RMSE-based background preservation; and (6) human-in-the-loop verification with systematized decision processes.
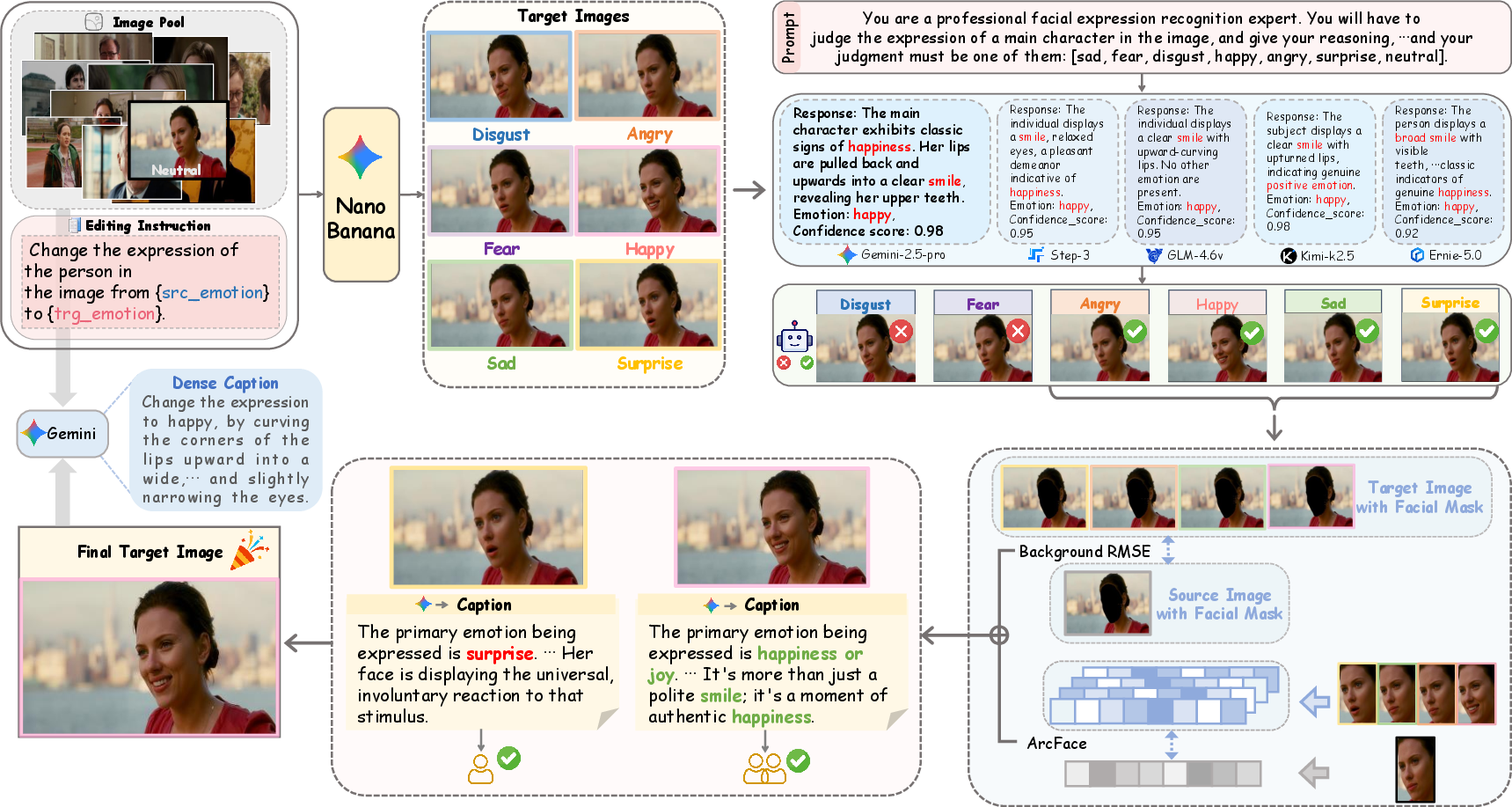
Figure 1: FED-Bench pipeline showing data acquisition, expression filtering, ensemble verification, dual-metric fidelity scoring, and human verification steps.
This rigorous construction paradigm yields a dataset amenable to robust, nuanced, and objective assessments while enabling comprehensive error analysis. Moreover, the pipeline is designed for scalability and was used to construct a 20k+ paired training set, empirically shown to improve model fidelity and expression accuracy during fine-tuning.

Figure 2: FED-Bench overview with representative samples illustrating the seven basic emotions used in the benchmark.
FED-Score: Cross-Granular, Multi-Dimensional Evaluation Protocol
Moving beyond conventional monolithic fidelity or alignment scores, FED-Score constitutes a decoupled, three-axis assessment protocol:
- Fidelity (ID, BG, PQ): Assesses preservation of subject identity (ArcFace cosine similarity), non-expression background integrity (RMSE outside facial region, normalized), and perceptual quality (MLLM-based artifact evaluation).
- Alignment (SC, GTA): Measures text-instruction following (MLLM-based semantic matching) and direct visual alignment with GT reference (MLLM-based GT expression comparison).
- Relative Expression Gain (REG): Quantifies the relative magnitude of editing by normalizing the perceptual (LPIPS) change against the GT-perceived change, using a Gaussian penalty to simultaneously penalize lazy editing (insufficient change) and overfit editing (excessive modification).
These axes are aggregated multiplicatively, ensuring that failure in any dimension precludes a high overall FED-Score. This design enforces multi-objective balance and is validated against human double-blind pairwise preferences, demonstrating dominant agreement (0.77 FED-Score vs 0.68 for best baseline metric).
Benchmarking SOTA Editing Models and Experimental Findings
Comprehensive evaluation of 18 state-of-the-art models under both coarse-grained and fine-grained editing instructions reveals consistent, robust patterns:
Practical and Theoretical Implications
Practically, FED-Bench and FED-Score set the new evaluation standard for facial expression editing by enforcing objective, multi-faceted, and reference-guided comparisons. The explicit mitigation of lazy and overfit editing via REG and cross-dimensional multiplicity elevates the evaluation granularity for downstream applications in entertainment, digital avatars, and affective computing where expression subtleties and identity faithfulness are critical.
Theoretically, the observed fidelity-alignment trade-off underscores inherent bottlenecks in current architectures and suggests that further progress hinges on innovations in controlled generative modeling capable of disentangled manipulation and robust linguistic grounding. Moreover, the adoption of MLLM-based assessment, validated against human preferences, signals a methodological shift toward learned, reference-based perceptual metrics for subjective generation tasks.
Conclusion
FED-Bench systematically addresses the core deficits in current facial expression editing evaluation by introducing both a high-quality, scalable benchmark and a cross-granular, three-axis scoring protocol. The benchmark not only enables more disentangled and reliable performance measurements but also empowers the community to pinpoint model weaknesses and drive architectural advances targeting the multi-objective foundation of facial editing. Future developments in AI editing must thus attend to multi-criteria optimization with comprehensive, reference-guided protocols as exemplified by this work.
