- The paper introduces DeepStack, a unified DSE framework that integrates fine-grained chip-level 3D DRAM modeling with system-level parallelism exploration for distributed AI accelerators.
- The paper employs detailed memory and parallelism models, achieving sub-5% error in cycle-accurate emulation and under 12.2% MAPE for end-to-end LLM inference.
- The paper demonstrates energy and throughput co-design insights, revealing non-monotonic stacking tradeoffs and up to 9.5× speedup over traditional DSE approaches.
DeepStack: Scalable and Accurate Design Space Exploration for Distributed 3D-Stacked AI Accelerators
Introduction and Motivation
The exponential growth in LLM parameters, along with increasing memory and bandwidth requirements, has made single-accelerator solutions for LLM inference fundamentally inadequate. This work presents DeepStack, a hierarchical modeling and Design Space Exploration (DSE) framework, targeting distributed 3D-DRAM-stacked AI systems, motivated by advanced packaging trends such as high-density hybrid bonding and vertical integration. These platforms must address compounded complexity: the design space involves tightly coupled choices at the chip, interconnect, and system scale (∼2.5×1014 configurations), spanning per-chip resource allocation, 3D memory hierarchy (DRAM stacking/connection), distributed parallel scheduling, and interconnect topology.
DeepStack distinguishes itself by unifying fine-grained chip-level 3D DRAM and system-level parallelism modeling. At the memory level, it incorporates transaction-aware bandwidth models, bank activation constraints, buffer sizing (Little’s Law), and thermal-power constraints. System-level search spans all relevant parallelism dimensions (TP, PP, DP, EP, SP, CP, FSDP), collective implementation, and hierarchical communication topology. The framework is cross-validated against in-house 3D cycle-accurate emulation (Cadence Palladium) and production LLM serving (vLLM), achieving low MAPE (<12.2%) across real-world workloads.
Fine-Grained 3D Memory and Parallelism Modeling
3D memory stacking, as implemented in DeepStack, provides a decisive advantage over conventional 2.5D interposer-based architectures, particularly in decoding-dominated inference. Each DRAM layer contributes bandwidth and capacity, but power, area, and thermal constraints bound feasible stacking depth. Notably, effective bandwidth often saturates before the maximum physical stack due to on-chip buffer and interconnect limitations (Little's law), and excessive stacking introduces thermal infeasibility and diminishing marginal capacity.
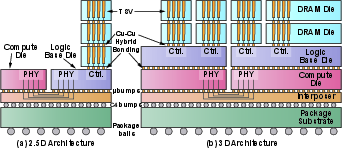
Figure 1: 2.5D hardware and 3D-stacked architecture, illustrating direct vertical DRAM integration and bandwidth improvements.
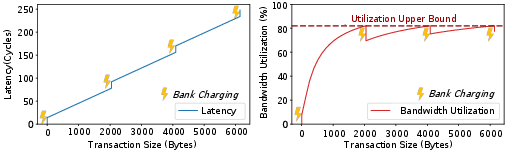
Figure 2: Achievable bandwidth and latency depend acutely on DRAM transaction size and bank concurrency; small/fine-grained access patterns result in poor amortization and significant underutilization of TSV bandwidth.
DeepStack further supports direct versus interleaved connectivity, allowing exploration of non-uniformly active layers/banks to quantify the tradeoff between logical bandwidth, physical area, and sustained power dissipation. The tile-level memory access model explicitly assigns tensors to banks and tracks transaction size, bank-level conflicts, and data layout effects, all integrated with the software scheduler and parallelism mapping.
On the parallelism axis, DeepStack enables comprehensive search across TP, PP, DP, EP, SP, CP, and FSDP, supporting both monolithic and per-module strategies. Empirical results show that restricted search (e.g., omitting EP or SP) fundamentally misleads chip architectural conclusions, demonstrating up to 5× throughput differences for MoE LLMs and permanent divergence in optimal stacking and compute resource allocation.
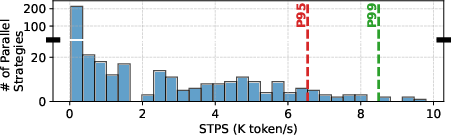
Figure 3: Enumerated parallelism strategies yield a highly skewed distribution of system-level throughput; a minority achieve near-optimal performance, underscoring the necessity of exhaustive search.
Hierarchical System-Level Modeling and Exploration
DeepStack's system abstraction encompasses hierarchical (multi-level) NoC models, supporting various topologies (Switch, Torus, Mesh, Ring) and modular bandwidth/latency scaling. The core innovation is a dual-stage model: communication is abstracted as a logical traffic matrix, which is then mapped to the underlying physical interconnect with traffic-aware routing and link contention analysis. The network model matches the fidelity of NS-3-based simulation (ASTRA-sim NS-3), but at 100,000× speedup, crucial for tractable exploration of massive design spaces.
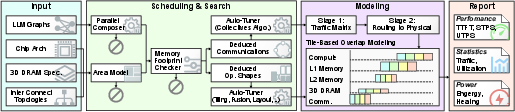
Figure 4: Overview of the DeepStack DSE framework, highlighting modular analysis stages linking computation, hardware topology, and distributed scheduling.
The compute-communication overlap model operates at the tile level, balancing arithmetic intensity and available pipelining depth. The end-to-end execution schedule explicitly considers wave-based tiling, communication latency, and resource contention, providing accurate performance prediction for diverse LLM architectures and parallelism mappings.
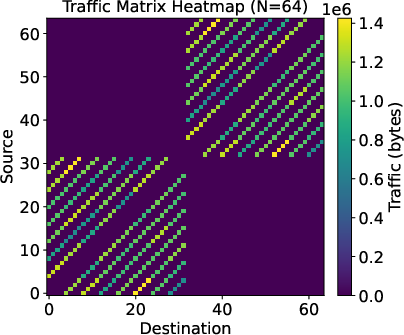
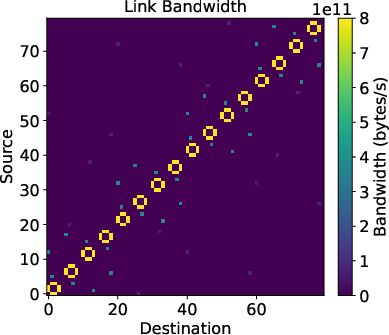
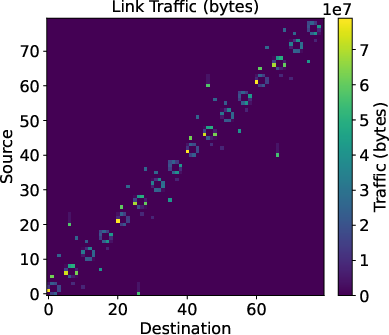
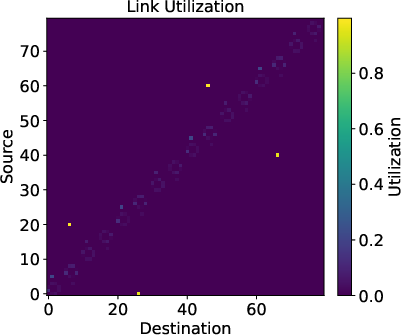
Figure 5: Example tile traffic matrix for distributed collective, mapping to physical link utilization for a 3-level torus-mesh-mesh topology.
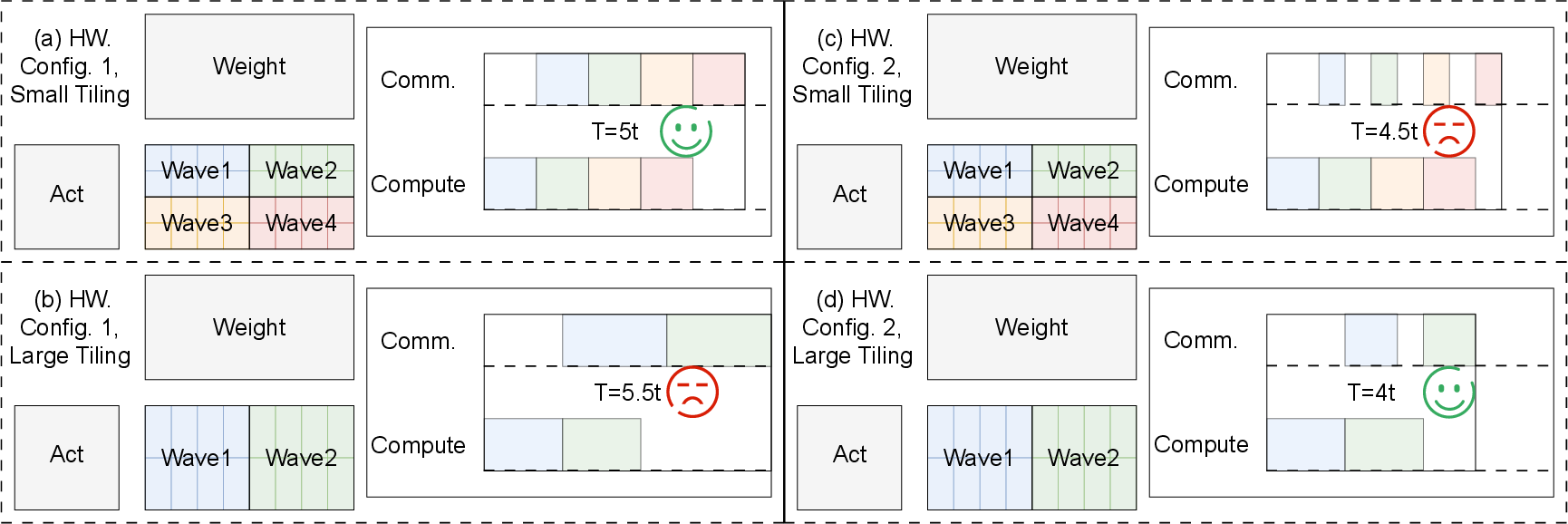
Figure 6: Tile-level compute–communication overlap visualization: optimal tile size shifts from overlap-oriented (smaller wave count) to compute-oriented (large tiles) as NoC bandwidth changes.
Evaluation: Accuracy, Co-Design Insights, and Quantitative Analysis
Modeling Fidelity
DeepStack's predictive modeling is validated against multiple implementations:
- Sub-5% error versus cycle-accurate emulation for representative dense and sparse LLM operator kernels.
- Under 12.2% MAPE for end-to-end distributed inference on vLLM—with diverse batch sizes, models, and parallel strategies.
- 1.6–2.1% error relative to event-driven NS-3 network simulation for hierarchical interconnects, outperforming existing analytical frameworks (up to 58% error in alternatives).
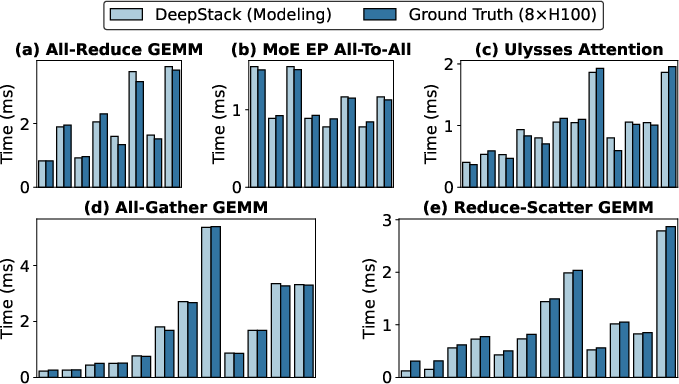
Figure 7: DeepStack modeling accuracy compared to 8×H100 GPUs across a spectrum of distributed Triton kernels.
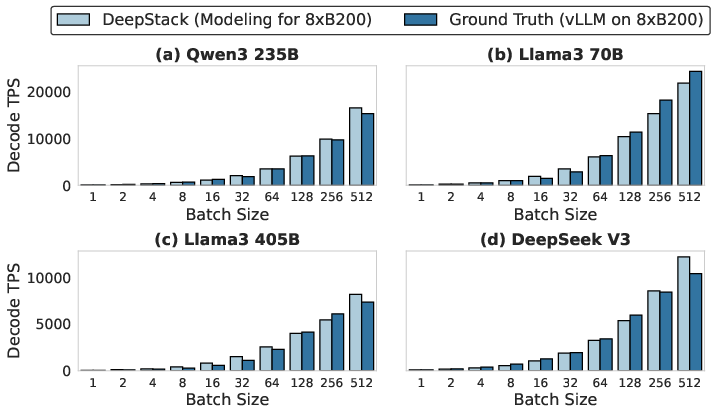
Figure 8: Modeling accuracy for MoE decode on B200 with TP8/EP8, comparing DeepStack and vLLM.
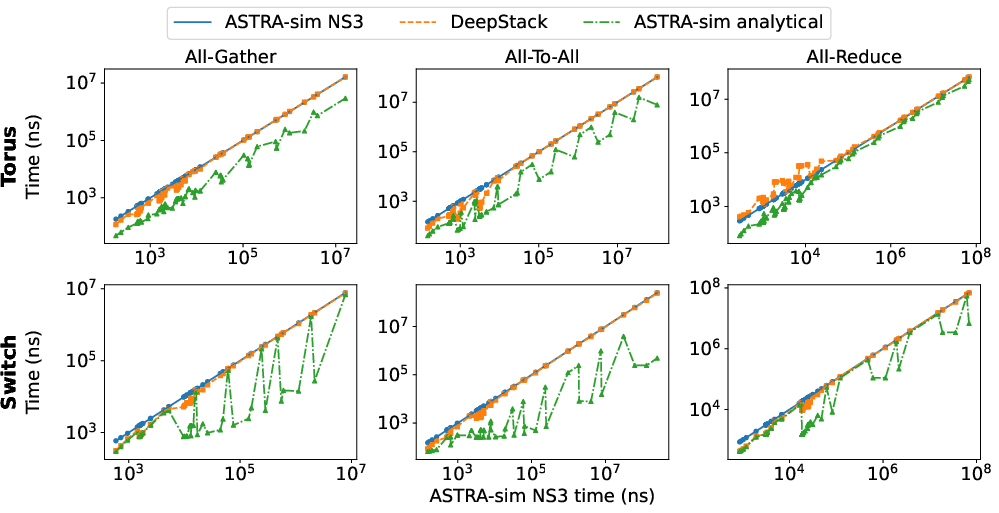
Figure 9: DeepStack matches NS-3 network simulation fidelity for various topologies, within a 0.1s evaluation window.
System–Hardware Co-Design Results
Pareto analysis of a million-point co-search reveals:
- Compute-bound prefill optimally utilizes high-throughput matrix configurations, with NoC topology as a secondary axis.
- Memory-bound decode is highly sensitive to NoC and DRAM choices: optimal batch size, stacking depth, and parallelism can shift the best design by up to 2.8× in throughput.
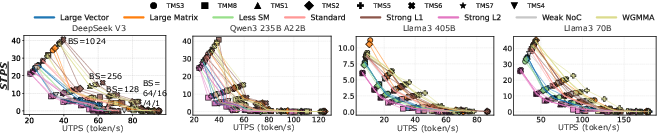
Figure 10: Pareto frontiers across architectural settings, revealing strong interaction between model, batch size, and optimal hardware/software co-design.

Figure 11: 3D-stacked architectures exhibit 1.3–2.8× STPS advantage for decoding over 2.5D baselines; gains are maximized at small batch sizes where memory bandwidth dominates.
Crucially, throughput-optimal stacking depth exhibits an inverted-U trend: more layers increase theoretical bandwidth but effective throughput peaks at 6–9 active layers (depending on batch size, buffering, and power budgets), then declines due to limitations in buffering and added thermal resistance.
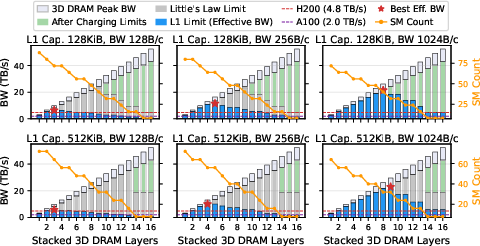
Figure 12: Effective DRAM bandwidth as a function of stacking/connection count demonstrates diminished returns and eventual decline from over-stacking.
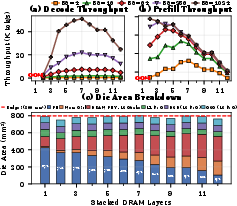
Figure 13: End-to-end throughput for DeepSeek-V3 by stacking configuration and batch size; the optimal configuration is tightly workload-dependent.
Energy efficiency and throughput optimization yield divergent architectures: energy-optimal designs consistently leverage more stacked but fewer connected (idle) layers, favoring larger on-chip buffers and energy-aware data placement, shifting the ideal parallel distribution toward EP in MoE workloads.
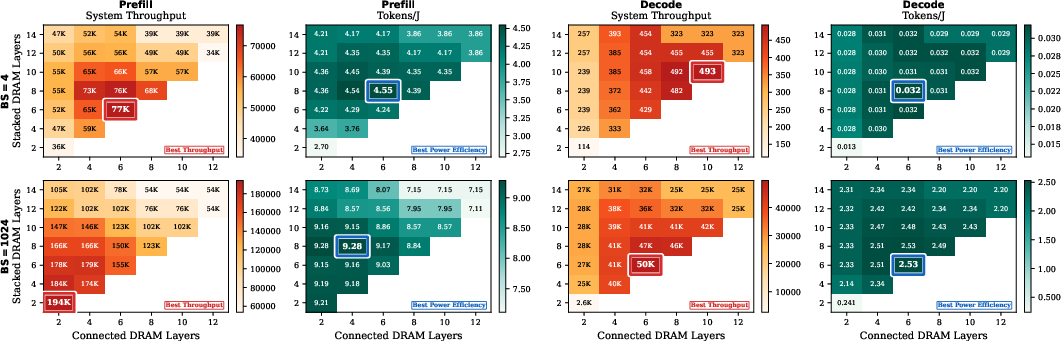
Figure 14: Heatmaps for throughput- and energy-optimal DRAM stacking/connection; architectural differences are substantial and workload/optimization-objective specific.
Full-system thermal analysis demonstrates that large-batch decode is the power-density bottleneck: while high-throughput designs exist within a liquid-cooled envelope (<0.8 W/mm2), thermal limits actively prune the feasible search space, mandating early-stage thermal modeling in DSE.
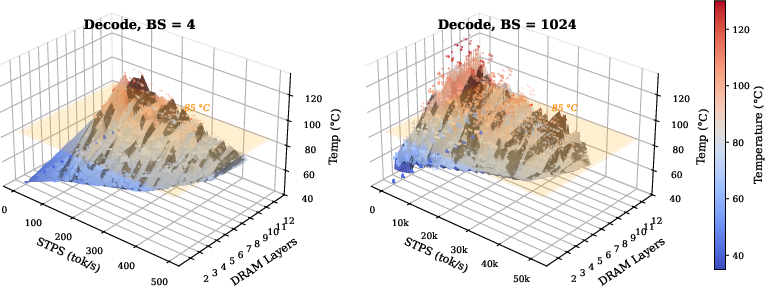
Figure 15: Thermal profile of 3D DRAM die area under decoding; optimal solutions cluster within the 85∘C limit, but many apparent high-bandwidth designs are thermally infeasible.
NoC analysis (area/bandwidth tradeoff) further reveals that moderate reductions in bandwidth can fund more compute (e.g., SMs), yielding non-obvious throughput improvements, particularly in memory-bound and small-batch regimes.
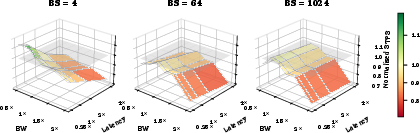
Figure 16: NoC bandwidth/hop-latency sensitivity: At moderate reductions in NoC bandwidth, area is better allocated to additional compute.
Ablation Study and Parallelism Search
Incremental ablation (Table 1) quantifies that enabling full parallelism search (especially EP, SP, CP), flexible per-module assignment, comprehensive on-chip arch, compute-communication overlap, and stacking DSE, collectively yield up to 9.5× speedup over traditional frameworks. Notably, omitting ANY axis (e.g., disabling EP for MoE) drives architectural search toward fundamentally suboptimal and irrecoverable chip designs.
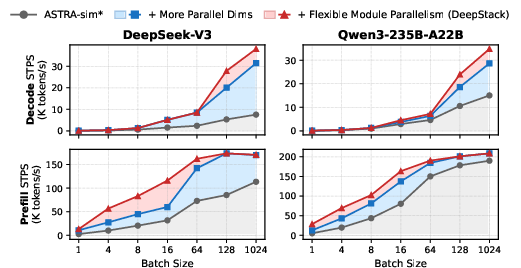
Figure 17: Expanded parallelism search in DeepStack outperforms ASTRA-sim’s restricted TP/PP/DP space by factors up to 5× in MoE.
Theoretical and Practical Implications
These findings have both immediate and long-term implications:
- Co-search is mandatory: Chip design and system-level schedule are non-separable. Partial search (or fixing parallelism to TP/DP/PP-only) produces silicon mismatches irrecoverable by post-tapeout software.
- Stacking tradeoff is non-monotonic: Maximum capacity and bandwidth are not always optimal; area, power, and buffer efficiency drive a nontrivial optimum in stacking depth and connection policy.
- Batch size supersedes inference phase: The batch size, not merely prefill or decode, is the principal architectural pivot, demarcating optimal regimes for compute vs. memory resource distribution.
- Energy and throughput arch divergence: Distinct scheduling, bank connection, and tiling strategies become optimal depending on whether energy or throughput dominates the objective.
The framework’s unprecedented modeling speed (<0 faster than NS-3), combinatorial search, and demonstrated predictive accuracy create new opportunities for automated hardware-software co-optimization and early-stage architecture planning for petascale LLM deployment.
Conclusion
DeepStack presents a robust advancement for early-stage system–hardware co-design of large-scale, distributed 3D-stacked AI accelerators. Its unified treatment of 3D DRAM semantics, hierarchical hardware-system parallelism modeling, and thermal/area-aware DSE enables accurate and rapid exploration of vast architectural search spaces. By revealing critical couplings—between parallelism, batch size, stacking depth, and power/thermal budgets—DeepStack provides actionable insights for silicon architects and systems researchers targeting next-generation LLM/cloud inference and training infrastructure (2604.04750).