- The paper introduces DWDP, offloading MoE weights across GPUs to replace collective synchronization with asynchronous expert fetching.
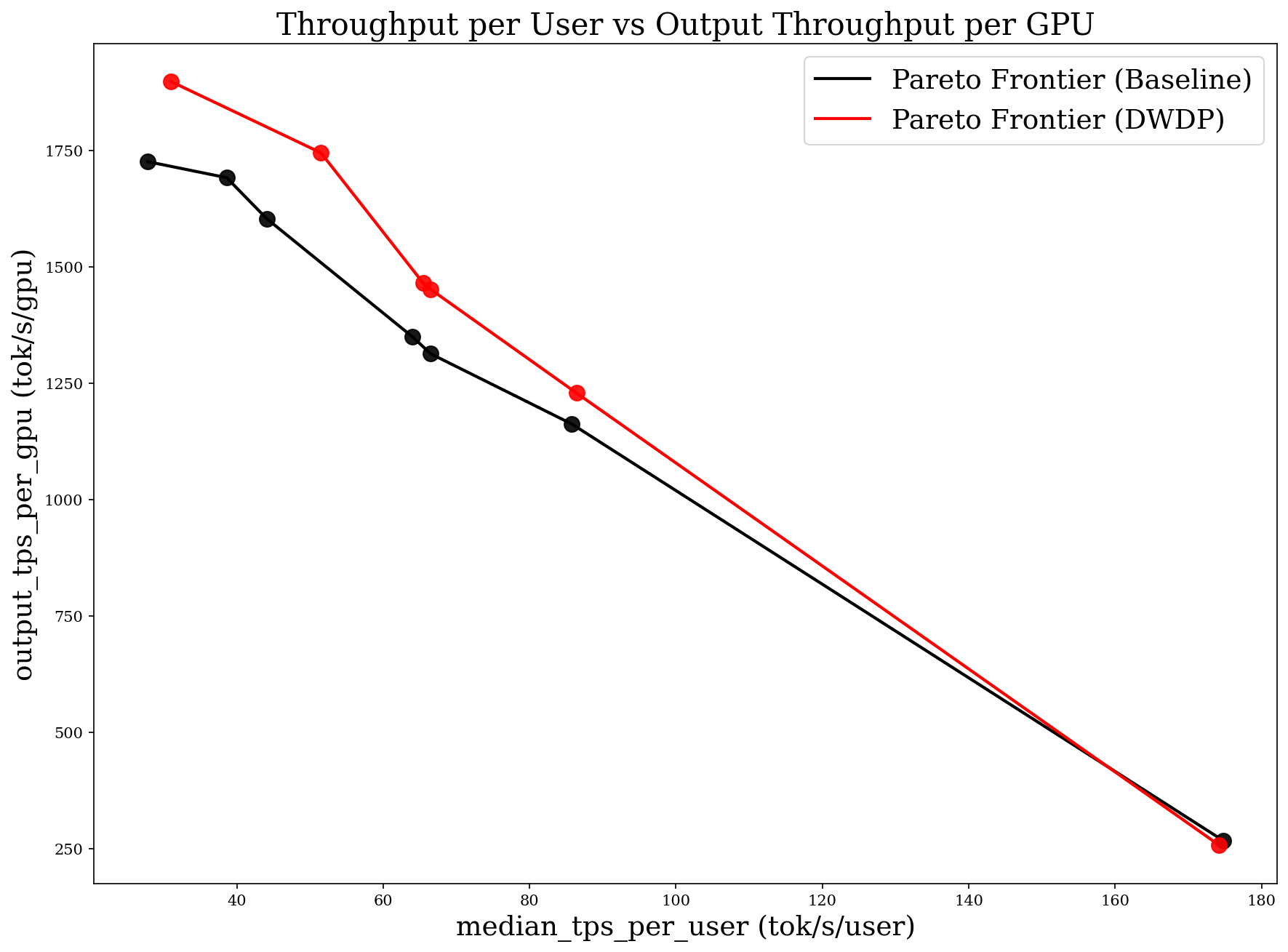
- The paper demonstrates 8–11% TPS/GPU speedup and improved resource efficiency through layered prefetching and chunked, pipelined communication.
- The paper provides a rigorous roofline analysis and system-level kernel optimizations, addressing communication-compute overlap and contention challenges.
Introduction: Motivation and Problem Statement
As LLM deployments scale, model capacity exceeds single-GPU memory and inference workloads are distributed across many accelerators. The predominant parallelization paradigms—expert parallelism, tensor parallelism, and pipeline parallelism—require synchronized inter-rank communication, typically all-to-all or all-gather, at layer boundaries. In real-world serving, input/request properties and dynamic expert routing induce workload imbalance; heterogeneity in sequence lengths and expert activation results in straggler effects, where end-to-end throughput is bottlenecked by the slowest rank. The analysis in this work shows synchronization overheads can reach 12% of end-to-end iteration latency under realistic (20% coefficient of variation) workload imbalance.
Existing strategies to mitigate this imbalance focus on improved scheduling (e.g., cache or load-aware routing) and expert load balancing, which optimize synchronization but do not eliminate it. The persistent synchronization requirement fundamentally caps attainable throughput and system efficiency in heterogeneous serving regimes.
DWDP: Method and Algorithmic Structure
DWDP (Distributed Weight Data Parallelism) is proposed to address these limitations by offloading MoE weights across peer GPUs and fetching missing experts on-demand, thereby removing collective inter-rank synchronization during inference. Each rank executes in a fully data-parallel fashion, storing local experts and retrieving remote experts asynchronously as required for each MoE layer.
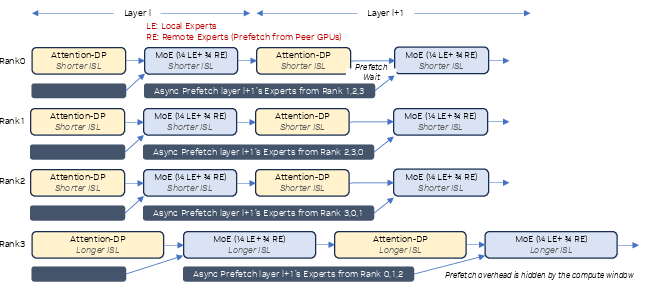
Figure 1: Overview of DWDP with a group size of 4, illustrating replicated attention weights on each rank and partitioned expert weights fetched on demand.
Contrary to NCCL all-gather communication, DWDP uses copy-engine-driven cudaMemcpyAsync peer-to-peer pulls for fetching weights. Notably, these transfers do not occupy SM resources, circumventing additional interference with compute. Layer-forward execution prefetches remote weights for layer ℓ+1 asynchronously during the compute window provided by the MoE block of ℓ and the attention block of ℓ+1. Prefetches are double-buffered and only block at the precise layer invocation when required experts may not have arrived.
DWDP also relaxes expert-to-GPU placement constraints. Group sizes need not evenly divide the expert count, supporting redundancy or partial overlap, enabling finer-grained resource provisioning. This flexibility is particularly valuable for tailored hardware configurations and maintaining high GPU utilization.
Analytical Justification and Roofline Analysis
A layer-wise roofline model is employed to rigorously characterize DWDP's regime of advantage over DEP. The per-layer latency for DEP is synchronous (Tcompute+Tall2all), whereas DWDP is bounded by the slower of compute and prefetch. For batch size one, empirical measurements show that when input sequence length (ISL) surpasses approximately 16K tokens, DWDP can fully hide prefetch, overtaking DEP. For shorter sequences, insufficient computation prevents full communication amortization. The non-monotonic speedup trend with ISL is explained: the utility of removing communication bottlenecks diminishes as compute cost dominates at very large sequences.
Implementation Challenges and System-Level Optimizations
The asynchronicity of DWDP introduces several system bottlenecks:
- Split-Weight Merge Overhead: Naive implementation forces merging local and remote expert buffers, incurring D2D memory copies. This is eliminated by extending groupedGEMM kernels (CuTeDSL) to natively accept split weight buffers, enabling direct kernel execution over local and remote shards with negligible indexing overhead.
- Many-to-One Communication Contention: Asynchrony can result in several ranks concurrently pulling expert weights from the same source, serializing transfers and creating compute bubbles.
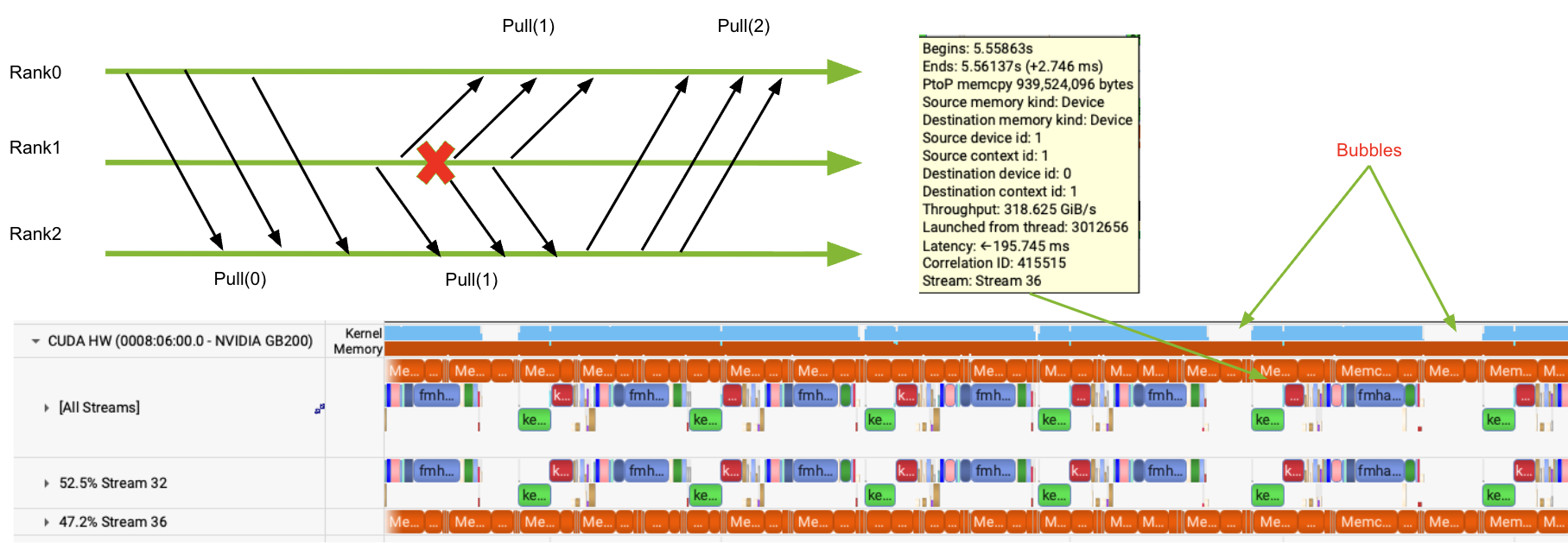
Figure 2: Nsight Systems trace shows multiple destination ranks introducing many-to-one contention at the copy-engine of the source GPU, stretching communication windows.
This is addressed through a time-division multiplexing mechanism: remote expert transfers are chunked into small slices and pipelined round-robin from a source GPU to all requesting destinations, leveraging the hardware's ability to pipeline concurrent small transfers (see copy engine path in Figure 3).
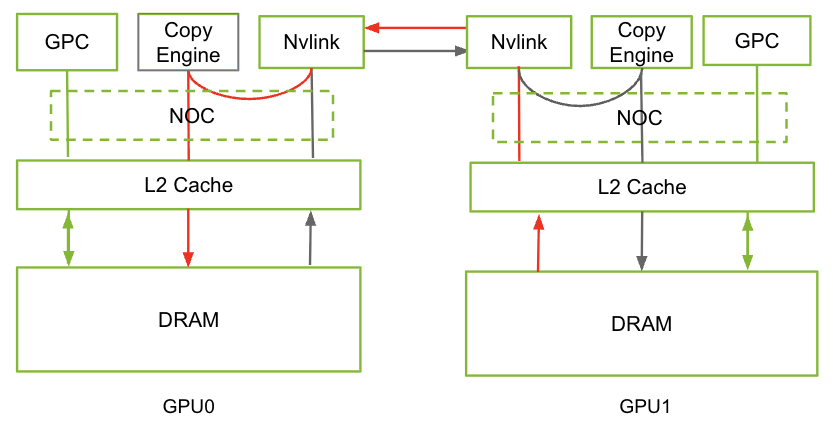
Figure 3: Copy-engine-mediated remote weight transfer highlighting shared use of NoC, L2 cache, and DRAM across GPUs; communication-computation interference arises at all levels.
This chunking—if slices are sized below copy engine concurrency depth—makes the system robust to low-order contention that is statistically predominant (e.g., 44–50% chance of dual contention in group sizes 3–4). Only higher-order contentions see significant slowdowns, which are rare. Profiling reveals that maximum achievable benefit is closely tied to optimizing for this low-order contention scenario.
Overlapping Communication and Compute: Resource Contention
DWDP’s remote-weight prefetches, though SM-external, share the NoC, L2, DRAM bandwidth, and GPU power/thermal headroom with compute kernels. Detailed profiling isolates two primary contention modes:
- For memory-bound kernels (e.g., quantization/copy), up to 22% slowdowns arise from DRAM bandwidth sharing, matching NVLink’s share of total DRAM bandwidth.
- For compute-bound kernels (e.g., attention), the chief bottleneck is power-induced frequency throttling when CE-based communication overlaps with heavy SM computation, reducing attainable clock and increasing kernel latency by up to 22%.

Figure 4: Three communication pattern types for analyzing communication-computation overlap: Intermittent Compute (no overlap), Long-Duration Overlap, and realistic Short-Duration Overlap as in DWDP.
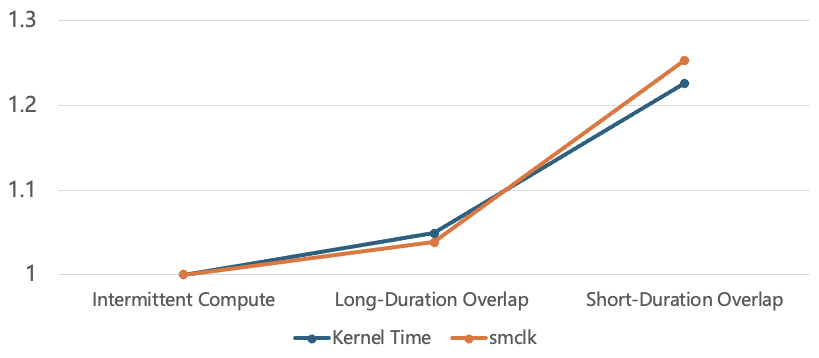
Figure 5: Empirical curves show close tracking between normalized attention-kernel time and GPU frequency for each overlap strategy, confirming power-limited operation.
This evidence motivates maximizing the compute window and minimizing frequent power peaks, strengthening the case for scheduling-aware communication overlap and chunk sizing.
Experimental Evaluation
DWDP was implemented in TensorRT-LLM and evaluated on DeepSeek-R1 running on GB200 NVL72 clusters. The performance was analyzed both in context-only (prefill) and end-to-end deployment scenarios.
Context-Only Results:
- With fixed 8K ISL and 32K max context tokens, DWDP achieves 8–11% TPS/GPU speedup over DEP, with higher gains as workload imbalance increases.
- Split-weight merge elimination yields ~3% further speedup.
- Time-division multiplexed copy brings performance to parity or superior to DEP in communication-constrained regimes, with net improvement when compute and prefetch windows are closely matched.
End-to-End Serving:
Practical and Theoretical Implications
DWDP’s synchronization-elimination is specifically well-matched to highly multi-GPU domains with high intra-domain bandwidth (e.g., GB200 NVL72). The method is system/fabric-aware: its efficacy depends on the ability to hide communication via sufficient compute, and the hardware topology’s ability to tolerate pipelined, many-to-one transfer patterns.
From a theoretical standpoint, DWDP’s relaxation of synchrony enables more flexible scheduling, supports non-uniform expert placement, and allows hardware-resource-efficient scaling and rate matching across disaggregated serving pipelines. Critically, its chunking-based prefetch avoids pathologies of long-tail communication and provides robustness against variance in workload and communication fabric.
DWDP’s co-design requirements (runtime, kernel, communication) and explicit chunked scheduling model point toward future work in communication-aware serving schedulers, adaptive chunk-size negotiation, and even finer-grained context-generation phase coordination.
Conclusion
DWDP introduces a new parallelization strategy for LLM inference, removing the fundamental synchronization bottleneck present in current expert parallelism strategies. By enabling asynchronous expert fetching and eliminating all-to-all synchronization, DWDP realizes substantial improvements in serving throughput under realistic, imbalanced, and system-constrained LLM serving workloads. System-level kernel and communication optimizations are necessary to realize its gains. DWDP’s architecture-aware design is especially relevant for current and next-generation high-bandwidth multi-GPU inference platforms.
ArXiv Reference: "DWDP: Distributed Weight Data Parallelism for High-Performance LLM Inference on NVL72" (2604.01621)