- The paper presents a hardware-software co-design that achieves up to 7.4× reduction in KV cache memory, enabling efficient scaling of large language models.
- It introduces the DeepSeekMoE framework, activating only 37B of 671B parameters per token, thereby drastically reducing per-token computation.
- Multi-token prediction and FP8 mixed-precision training together boost inference throughput by 1.8× while lowering overall resource demands.
DeepSeek-V3: Hardware-Software Co-Design for Efficient LLM Scaling
Introduction
The DeepSeek-V3 project provides a comprehensive hardware-aware blueprint for efficiently scaling LLMs under stringent resource constraints. By integrating architectural advances in model structure (such as Multi-head Latent Attention, Mixture-of-Experts, and multi-token prediction) with aggressive adoption of low-precision computation and a co-designed interconnection infrastructure, DeepSeek-V3 demonstrates that practical, state-of-the-art LLMs can be achieved with an order-of-magnitude reduction in computational footprint compared to conventional dense models at similar parameter scales. This essay discusses the main system, architectural, and hardware co-design innovations in DeepSeek-V3, with a focus on practical scaling, performance implications, and anticipated future directions.
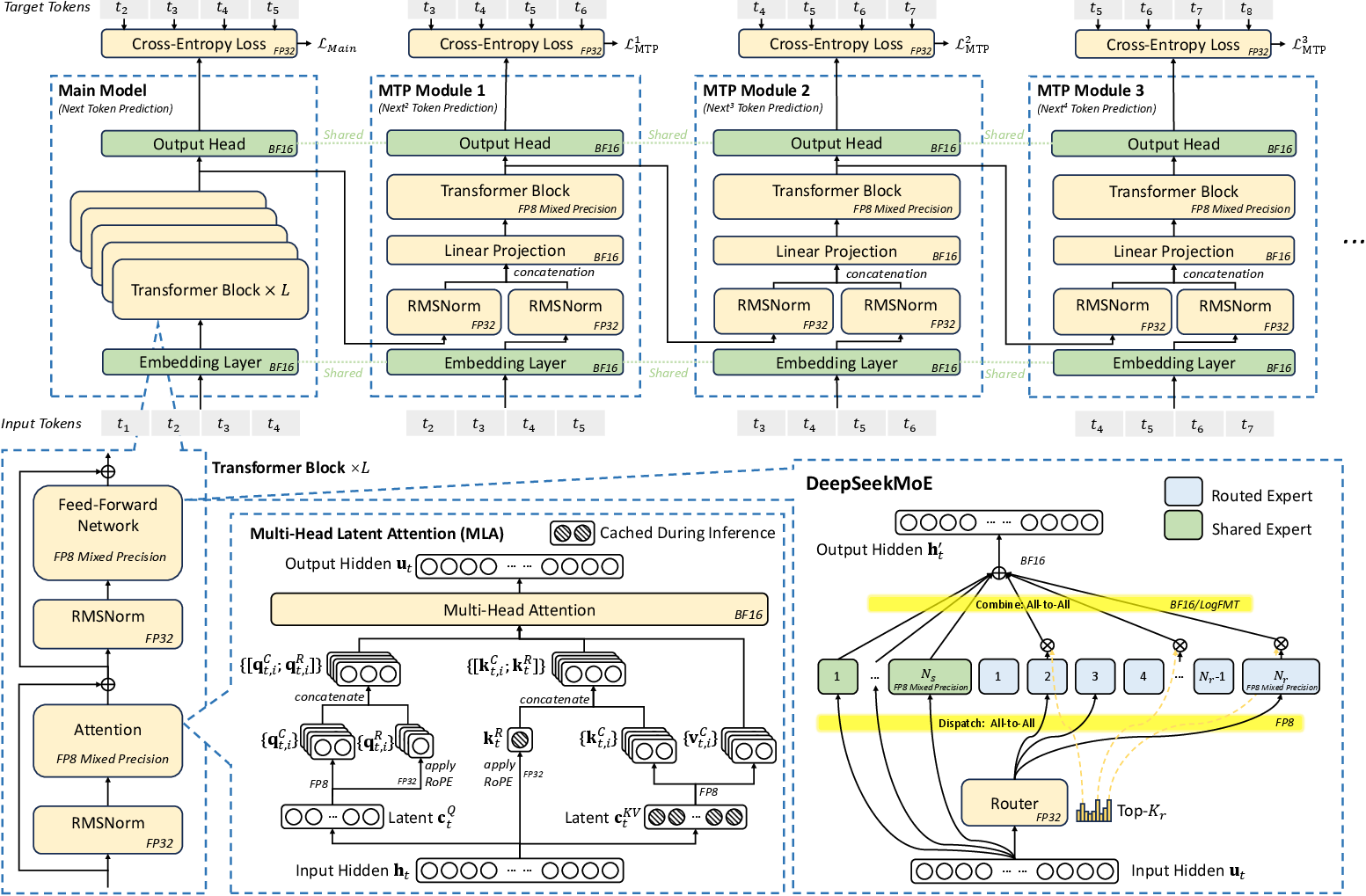
Figure 1: Overview of DeepSeek-V3 architecture including MLA, DeepSeekMoE, Multi-Token Prediction, and FP8 mixed-precision training. All components operate in BF16 at input/output.
Hardware-Aware Model Architecture
Memory Wall Avoidance and Multi-Head Latent Attention (MLA)
Memory bandwidth bottlenecks increasingly dominate LLM deployment, particularly for long-context inference where the quadratic complexity of autoregressive attention and size of the Key-Value (KV) cache rapidly saturate HBM and interconnect bandwidth. DeepSeek-V3 aggressively compresses the memory footprint using MLA. Unlike GQA/MQA, which reduce the per-token KV cache size by sharing Keys/Values across heads, MLA projects all heads into a compact latent vector using a trainable projection. For the DeepSeek-V3 671B parameter MoE model, this achieves KV cache requirements per token of 70 KB—a 7.4× reduction compared to LLaMA-3.1 405B and a 4.7× improvement over Qwen2.5-72B (both using GQA). This enables cost-effective inference for long input sequences without sacrificing reasoning fidelity or model capacity.
Sparse Computation: DeepSeekMoE
The DeepSeekMoE framework enables control over computation-communication trade-offs at scale. At typical batch sizes and device counts, only a small (top-K) subset of experts is activated per token, with the remainder routed to a shared global expert. For DeepSeek-V3, only 37B of 671B parameters are activated per token, reducing per-token computation by an order of magnitude (250 GFLOPs for DeepSeek-V3 vs 2,448 GFLOPs for LLaMA-3.1-405B). This approach not only yields SOTA results on open and proprietary benchmarks but also enables commodity-grade hardware (e.g., single AI PC, low-cost servers) to deliver 20+ tokens/sec for high-capability LLMs.
Multi-Token Prediction (MTP) and Inference Acceleration
Sequential autoregressive decoding fundamentally limits LLM throughput. DeepSeek-V3 integrates multi-token prediction—using a lightweight speculative head to propose and validate multiple next tokens per step, following principles close to the speculative decoding family (cf. [DBLP:conf/icml/GloeckleIRLS24], [DBLP:conf/icml/CaiLGPLCD24]). Empirically, the acceptance rate for the second subsequent token reaches 80–90% with MTP, yielding a 1.8× increase in generation throughput under practical workloads.
Low-Precision Training and Hardware Considerations
The DeepSeek-V3 infrastructure exploits FP8 mixed-precision training, enabled by NVIDIA Hopper architecture support but with modifications for large-scale MoE models. The FP8 path includes:
- Tile-wise quantization (1×128 for activations, 128×128 for weights)
- Fine-grained selection of scaling factors
- Hardware-aware custom implementation of GEMM (see DeepGEMM)
While FP8 reduces both memory footprint and communication load, several bottlenecks remain: limited accumulation precision (e.g., 13-bit mantissa addition in Hopper Tensor Cores), and the overhead due to dequantization when mixing FP8 and BF16 in compute-communication overlap.
This motivates hardware roadmap recommendations, including:
- FP32-precision accumulation or configurable register/accum precision in future accelerator designs
- Native support for quantization scaling and dequantization inside the accelerator core (cf. NVIDIA Blackwell’s microscaling)
- Compression-native NICs for network data movement
LogFMT and Network Compression
Beyond standard FP8, DeepSeek-V3 explored block-wise Logarithmic Floating-Point Formats (LogFMT-nBit) for communication and potential in-activation compression. This approach matches or outperforms E5M2/E4M3 at the same bit-width in accuracy preservation at 8–10 bits. However, lack of hardware log/exp acceleration in GPUs and register pressure precludes direct deployment—demonstrating an opportunity for future hardware-level compression primitives.
Cluster Interconnect and Expert Parallelism
Infrastructure
DeepSeek-V3 was trained on 2,048 H800 Hopper-SXM GPUs. Each H800 node features eight GPUs (with a degraded 400 GB/s NVLink) and eight 400 Gbps IB NICs for scale-out, connected in a two-layer, eight-plane Fat-Tree topology.
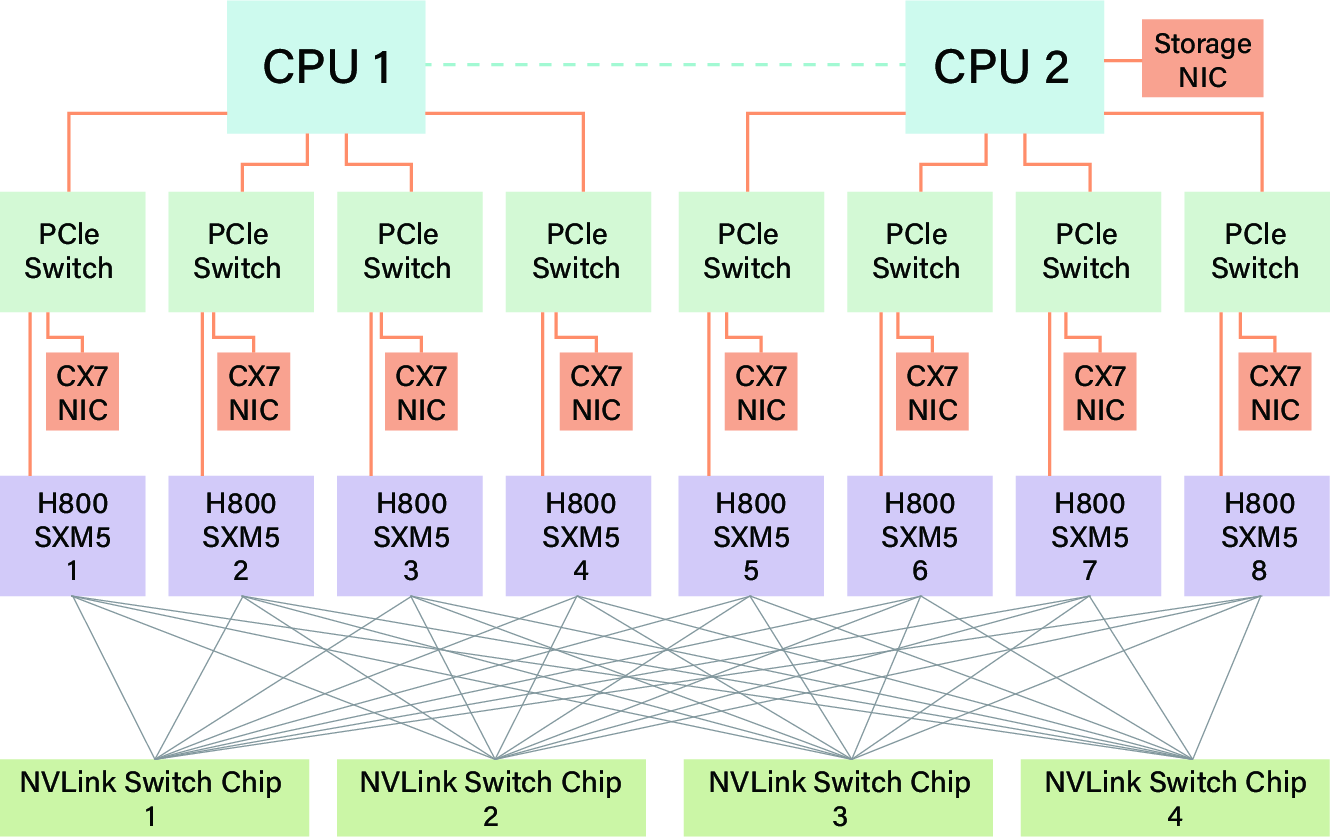
Figure 2: H800 node interconnection showing limited NVLink bandwidth and multiple NICs per node for interconnect scaling.
Multi-Plane Fat-Tree Network
The eight-plane, two-layer Fat-Tree (MPFT) scales cost-effectively, supporting up to 16,384 GPUs with efficient routing and fault isolation. Each GPU-NIC pair operates on a distinct physical plane, minimizing intra-plane congestion and isolating failures or overloads.
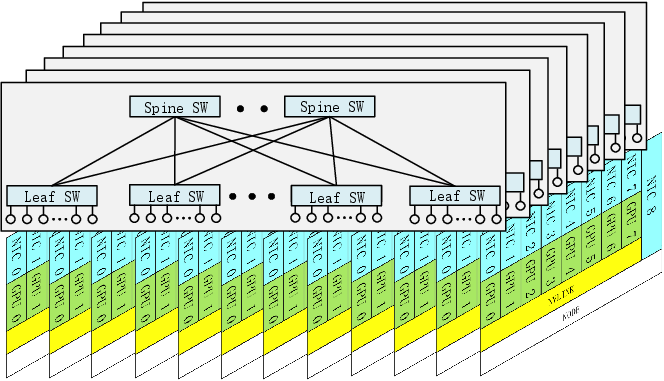
Figure 3: Multi-plane Fat-Tree network for large-scale AI workload distribution and robust all-to-all communication. Each GPU–NIC pair is mapped to a plane, with cross-plane traffic routed using PCIe/NVLink intra-node forwarding.
MPFT's synergy with the communication libraries (e.g., NCCL's PXN) ensures nearly identical all-to-all bandwidth and latency compared to multi-rail single-plane topologies, as shown in the benchmarking results.
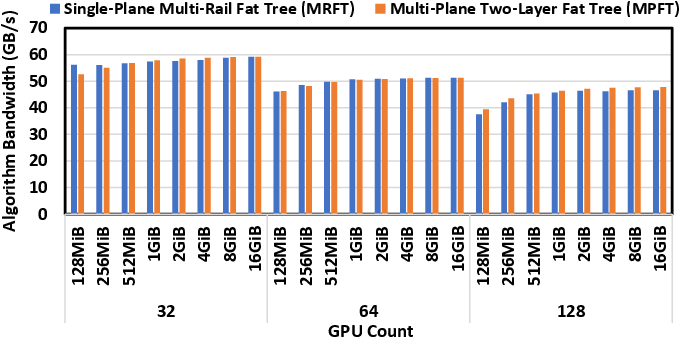
Figure 4: Empirical NCCL all-to-all bandwidth from 32 to 128 GPUs comparing MRFT and MPFT—showing near-parity in throughput.
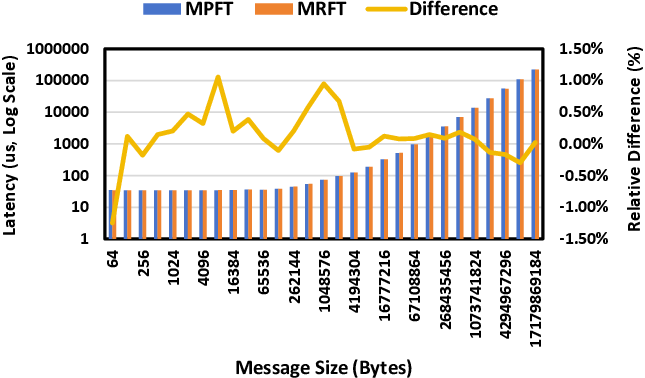
Figure 5: Latency comparison between MPFT and MRFT networks showing negligible difference for the all-to-all operation.
In expert-parallel MoE regimes, DeepEP enables all-to-all dispatch and combine across up to 128 GPUs, saturating the available network bandwidth for 4K-token batch sizes:
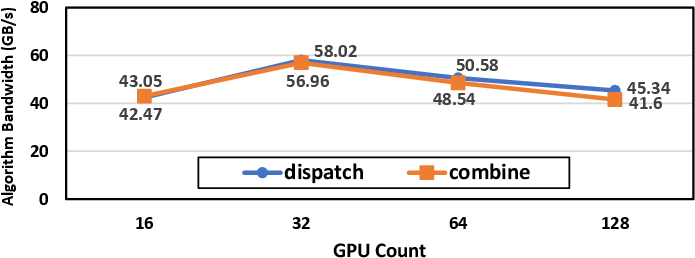
Figure 6: DeepEP expert-parallel throughput on MPFT, nearly saturating per-NIC bandwidth with increasing scale.
Adaptive routing and explicit traffic isolation are advisable to maintain allreduce and reduce-scatter efficiency in mixed pipeline/data/expert parallel workloads, as validated in the RoCE/IB experiments.
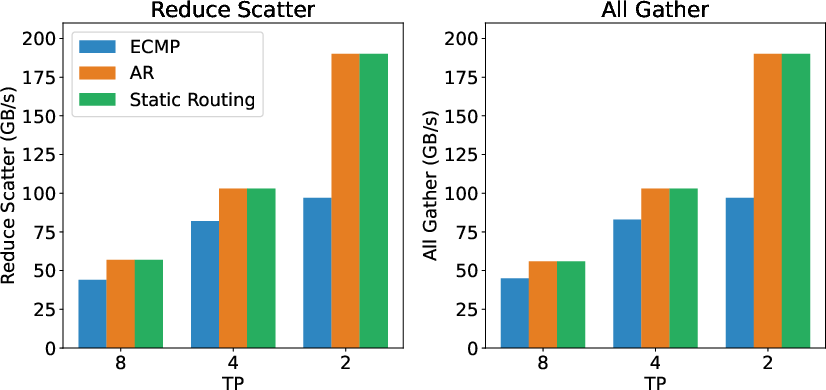
Figure 7: RoCE AllGather/ReduceScatter bandwidth in various routing modes (ECMP, Adaptive Routing, Static Routing) and tensor parallelism configurations, illuminating the advantages of adaptive routing for collective communication.
Node-Limited Routing and Expert Sharding
To optimally utilize the available interconnect bandwidth, DeepSeek-V3 adopts a node-limited routing strategy where expert shards are grouped such that each token’s experts are preferentially co-located within a limited node set. This reduces IB network duplication and leverages intra-node NVLink bandwidth for final expert redistribution, lowering inter-node communication volume by up to 2× depending on the deployment configuration.
Beyond DeepSeek-V3: Challenges and Hardware Blueprint
Robustness and Fault Tolerance
The paper identifies critical reliability bottlenecks, including:
- Intermittent disconnections in IB/NVLink
- Node failures and ECC errors
- Silent data corruption undetected by ECC
Comprehensive diagnostics, hardware-level CRCs, and packet-level bitmap tracking (including memory-semantic communication with region-acquire/release primitives) are recommended for future large-scale deployments.
Scale-Up/Scale-Out Convergence
The lack of interface unification between intra-node (scale-up) and inter-node (scale-out) increases both kernel and hardware complexity. To maximize hardware utilization and software simplicity, future high-performance clusters should provide:
- Unified NICs or I/O dies spanning both domains with packet forwarding and virtual queue support
- Hardware-offloaded communication/reduction for expert parallelism
- In-network compression and aggregation primitives to optimize MoE dispatch/combine patterns
Memory-Centric Computing
Memory bandwidth scaling lags behind compute by a significant margin. Proposals such as DRAM-stacked accelerators (e.g., SeDRAM, SoW architectures) and on-die memory integration (cf. Cerebras) are necessary to sustain next-generation model context lengths and inference bandwidth requirements.
Implications and Future Directions
DeepSeek-V3 extends beyond efficient LLM implementation; it defines the contours for the next generation of AI hardware software co-design:
- Low-Precision Native Training: FP8 (and below), if fully supported in MAC and accumulation units, enables not only memory and communication savings but also opens the door for pervasive low-bit inference workflows, critical for local/edge deployment.
- Memory-Aware Architecture: KV cache compression (e.g., MLA) will be essential for future LLMs as prompt/context lengths move into the tens or hundreds of thousands, with further algorithmic advances (Mamba, Lightning Attention) required to break the O(N2) bandwidth wall.
- Communication Fabric Unification: Hybrid and programmable interconnect fabrics (integrating NVLink/PCIe/IB/Ethernet/photonic) with hardware-offloaded collective primitives will be a de-facto requirement as AI clusters break the 10,000–100,000 GPU barrier.
The principles established in DeepSeek-V3—algorithmic and infrastructural co-design, pervasive quantization, traffic isolation, speculative decoding, and robust expert sharding—will drive efficient, fault-tolerant LLM scaling and serve as a template for both researchers and system architects moving into the exascale AI era.
Conclusion
DeepSeek-V3 demonstrates that principled hardware-software co-design, memory-centric model compression, and communication infrastructure alignment provide a practical and scalable path toward efficient, robust, large-scale LLM deployment. By rigorously characterizing and addressing existing bottlenecks—whether at the level of quantization, memory hierarchy, interconnect topology, or algorithmic efficiency—the system delivers SOTA accuracy at dramatically reduced cost and resource requirements. DeepSeek-V3’s blueprint sets a high watermark in both practical implementation and the architectural perspective required for the next generation of AI accelerators and distributed training systems.