Scalable Training of Mixture-of-Experts Models with Megatron Core
Abstract: Scaling Mixture-of-Experts (MoE) training introduces systems challenges absent in dense models. Because each token activates only a subset of experts, this sparsity allows total parameters to grow much faster than per-token computation, creating coupled constraints across memory, communication, and computation. Optimizing one dimension often shifts pressure to another, demanding co-design across the full system stack. We address these challenges for MoE training through integrated optimizations spanning memory (fine-grained recomputation, offloading, etc.), communication (optimized dispatchers, overlapping, etc.), and computation (Grouped GEMM, fusions, CUDA Graphs, etc.). The framework also provides Parallel Folding for flexible multi-dimensional parallelism, low-precision training support for FP8 and NVFP4, and efficient long-context training. On NVIDIA GB300 and GB200, it achieves 1,233/1,048 TFLOPS/GPU for DeepSeek-V3-685B and 974/919 TFLOPS/GPU for Qwen3-235B. As a performant, scalable, and production-ready open-source solution, it has been used across academia and industry for training MoE models ranging from billions to trillions of parameters on clusters scaling up to thousands of GPUs. This report explains how these techniques work, their trade-offs, and their interactions at the systems level, providing practical guidance for scaling MoE models with Megatron Core.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper explains how to train a special kind of large AI model called a Mixture‑of‑Experts (MoE) quickly and efficiently on many GPUs (powerful graphics processors). Instead of having every part of the model work on every word, MoE models pick just a few “experts” (small sub‑networks) to handle each word. That saves a lot of compute per word, but it creates new problems for memory, communication between GPUs, and keeping the GPU cores busy. The paper shows how NVIDIA’s Megatron‑Core software solves these problems so very large MoE models (billions to trillions of parameters) can be trained at high speed.
What questions were they trying to answer?
They focused on a few simple but tough questions:
- How can we train huge MoE models fast without running out of GPU memory?
- How can we cut the “talking time” between GPUs so they’re not waiting on each other?
- How can we keep GPU cores busy when MoE splits work into lots of small pieces?
- How can we mix and match different ways of splitting work across GPUs so both attention layers and MoE layers run well?
- Can we use lower‑precision numbers (like FP8 or FP4) to go faster without breaking training?
- How do we make all this practical for real training, long text contexts, and even reinforcement learning?
How did they approach the problem?
Think of an MoE model like a big school with many teachers (experts). For each word (token), a smart “router” picks the top‑k teachers best suited to help. Only those teachers do the work for that word. This saves time but creates tricky logistics across many computers. Here’s how they tackled it.
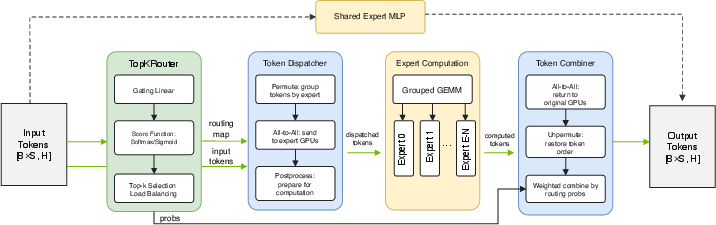
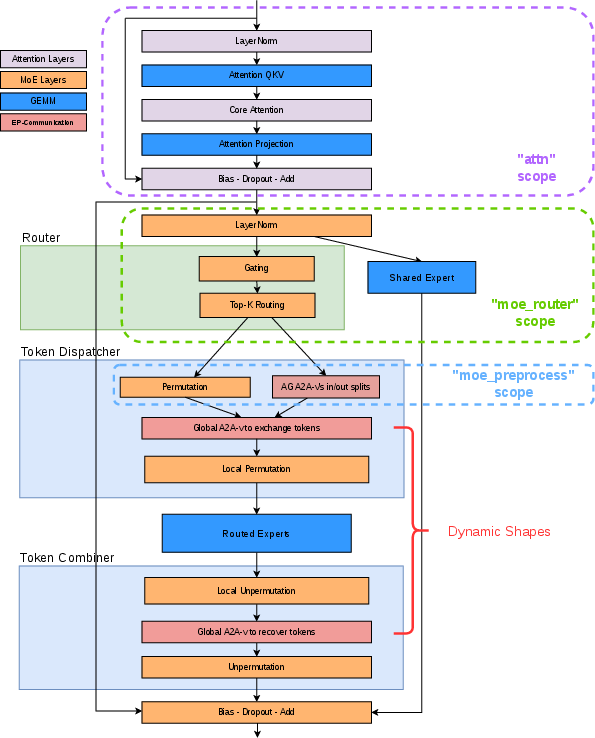
The MoE layer, in simple steps
For each group of words going through a layer:
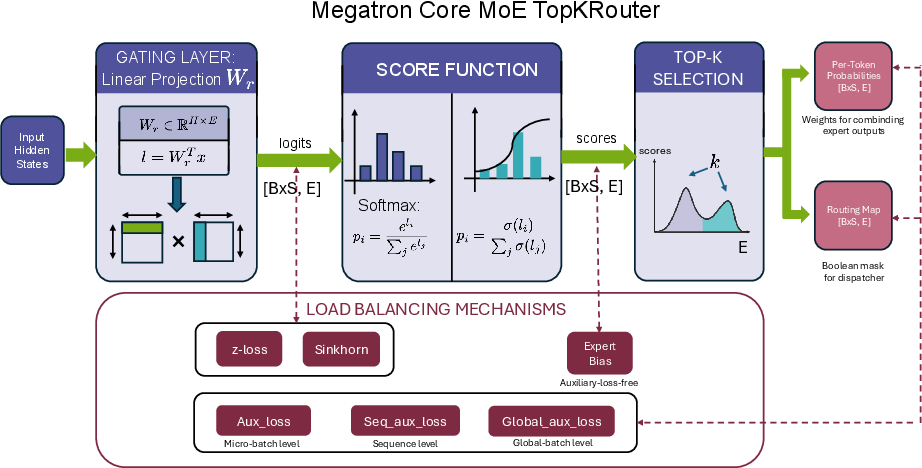
- Route: A small network (the router) scores which experts fit each word best and picks the top‑k.
- Dispatch: Words are shuffled and sent to the GPUs that host those chosen experts.
- Compute: Each GPU runs its local experts. To keep GPUs busy, many small expert computations are bundled together in one go (Grouped GEMM).
- Combine: The processed words are sent back and put back in their original order.
Analogy: It’s like a mailroom (router) sorting letters (words) to the right departments (experts), sending them around the building (dispatch), having departments work on them (compute), then sending results back (combine).
The “three walls” they had to break
- The Memory Wall: All expert weights need to be stored even though only a few are used for each word. This eats GPU memory fast.
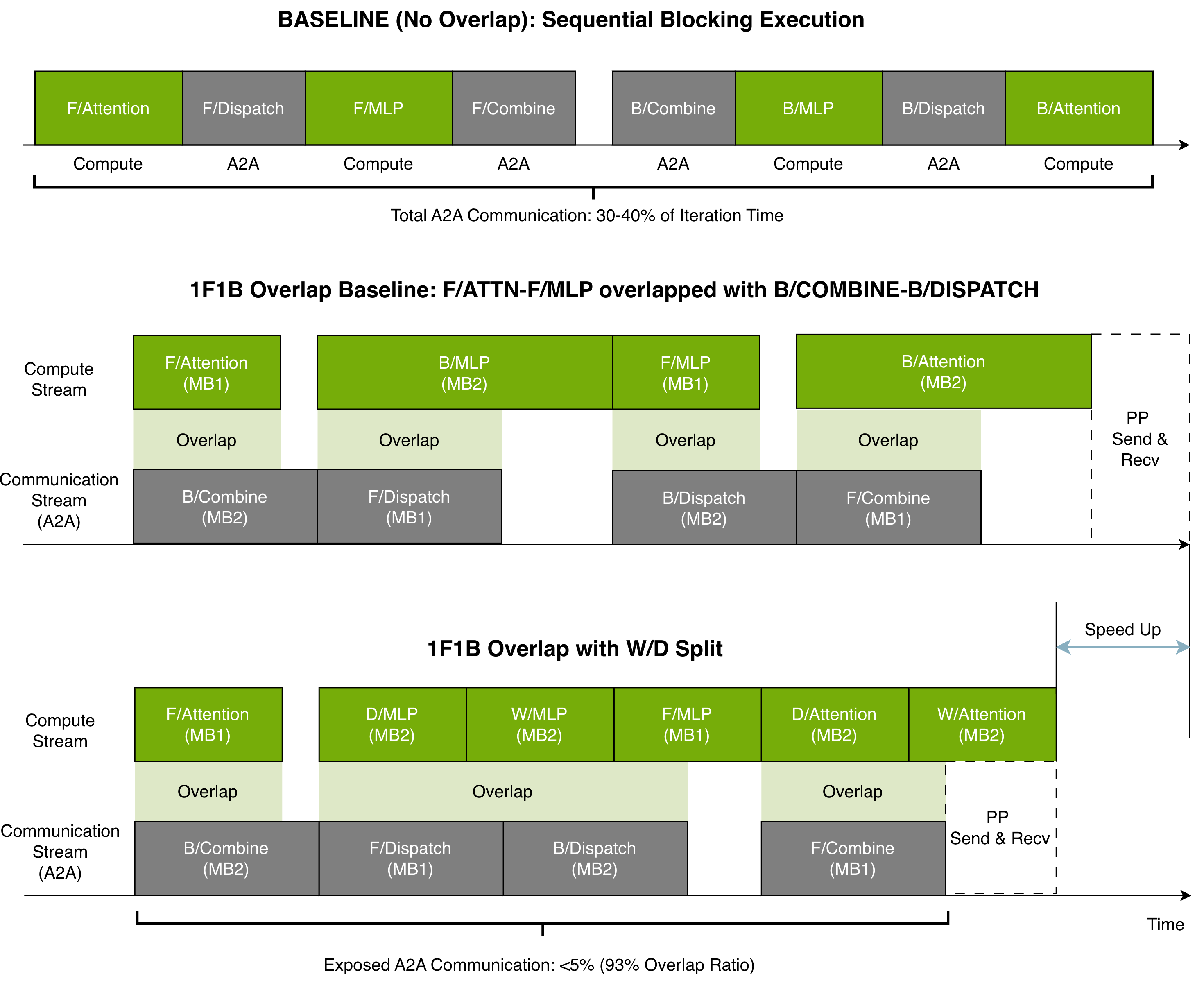
- The Communication Wall: Moving words to and from experts across GPUs (all‑to‑all transfers) can take a lot of time and bandwidth.
- The Compute Efficiency Wall: Many small expert jobs underuse the GPU’s math units, plus extra steps like routing and reshuffling add overhead.
System‑wide solutions (co‑design across memory, communication, and compute)
They combined several techniques so fixing one problem wouldn’t make another worse:
- Memory-side
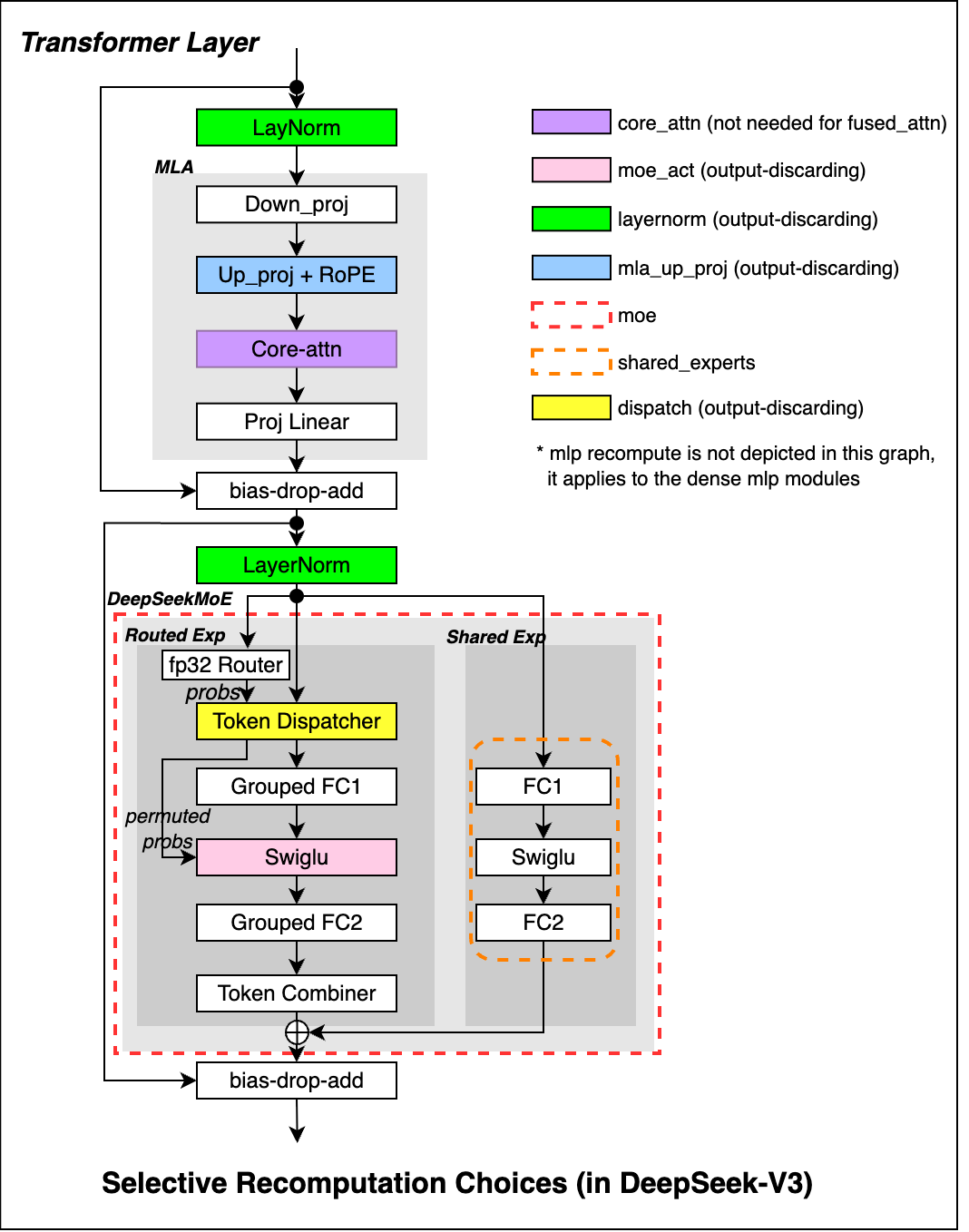
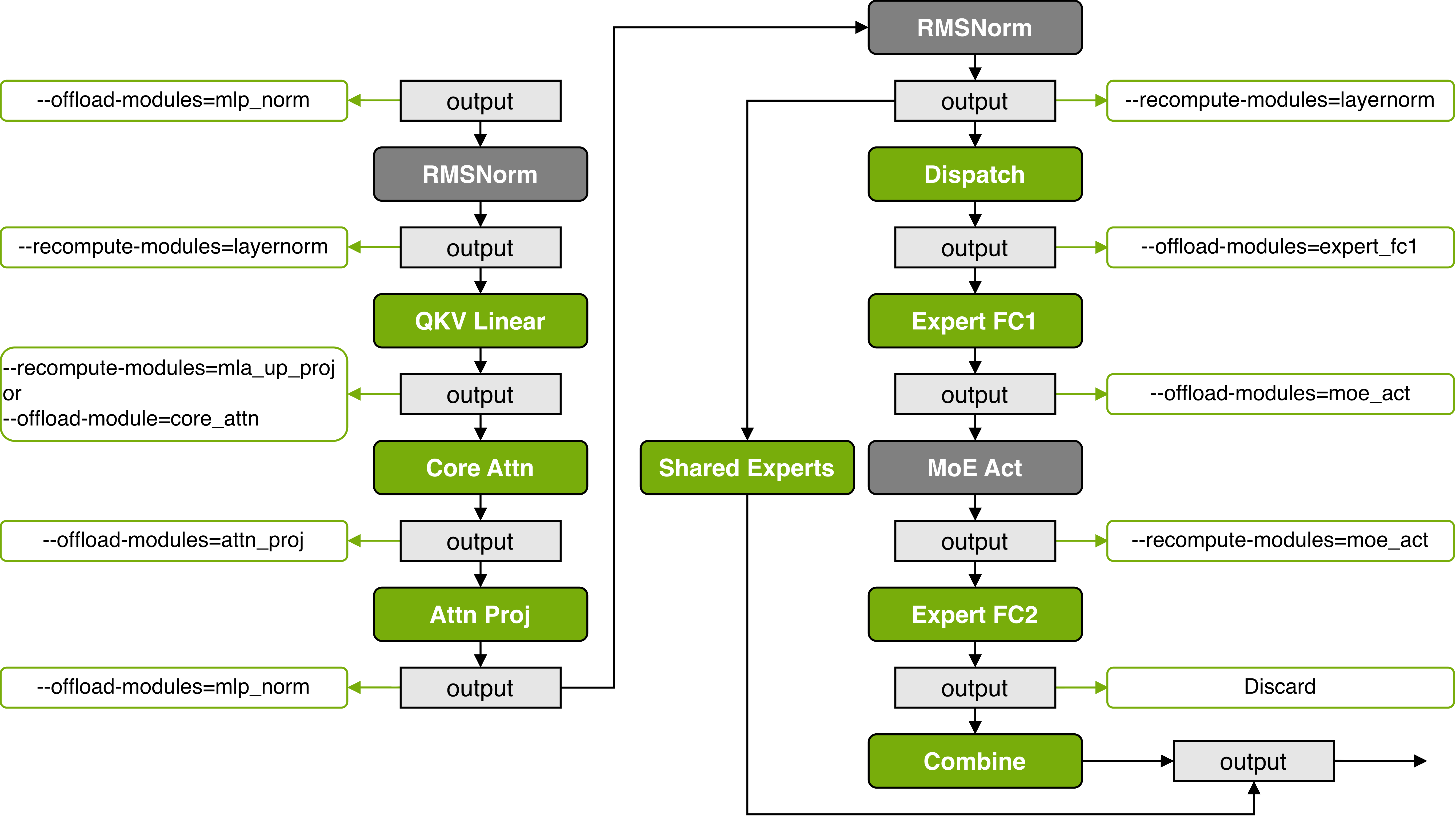
- Recompute activations instead of storing all of them (trade a bit of extra math for less memory).
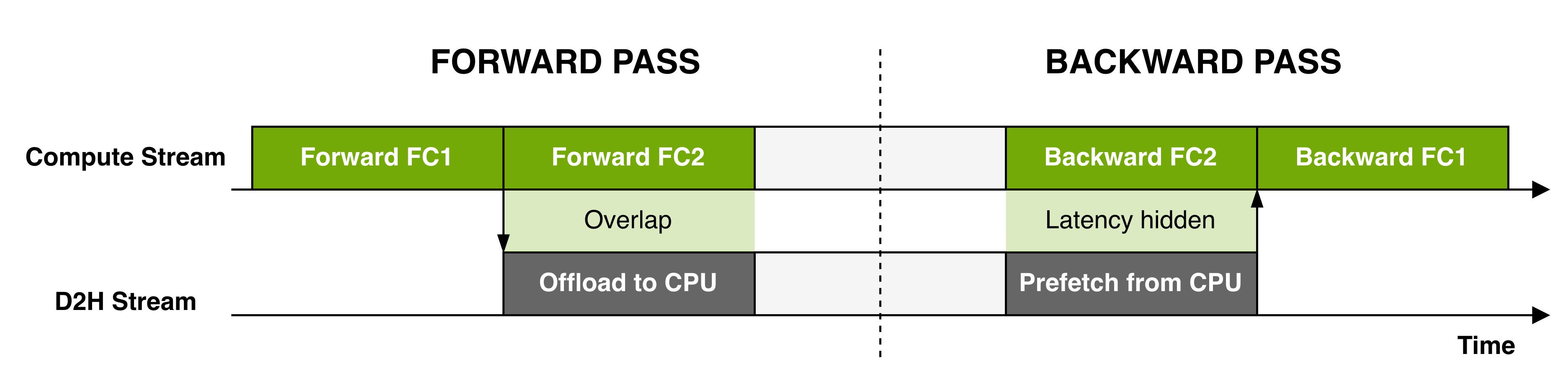
- Offload some data to host memory when needed.
- Use reduced precision (FP8, FP4) to shrink activations and speed up math where it stays stable.
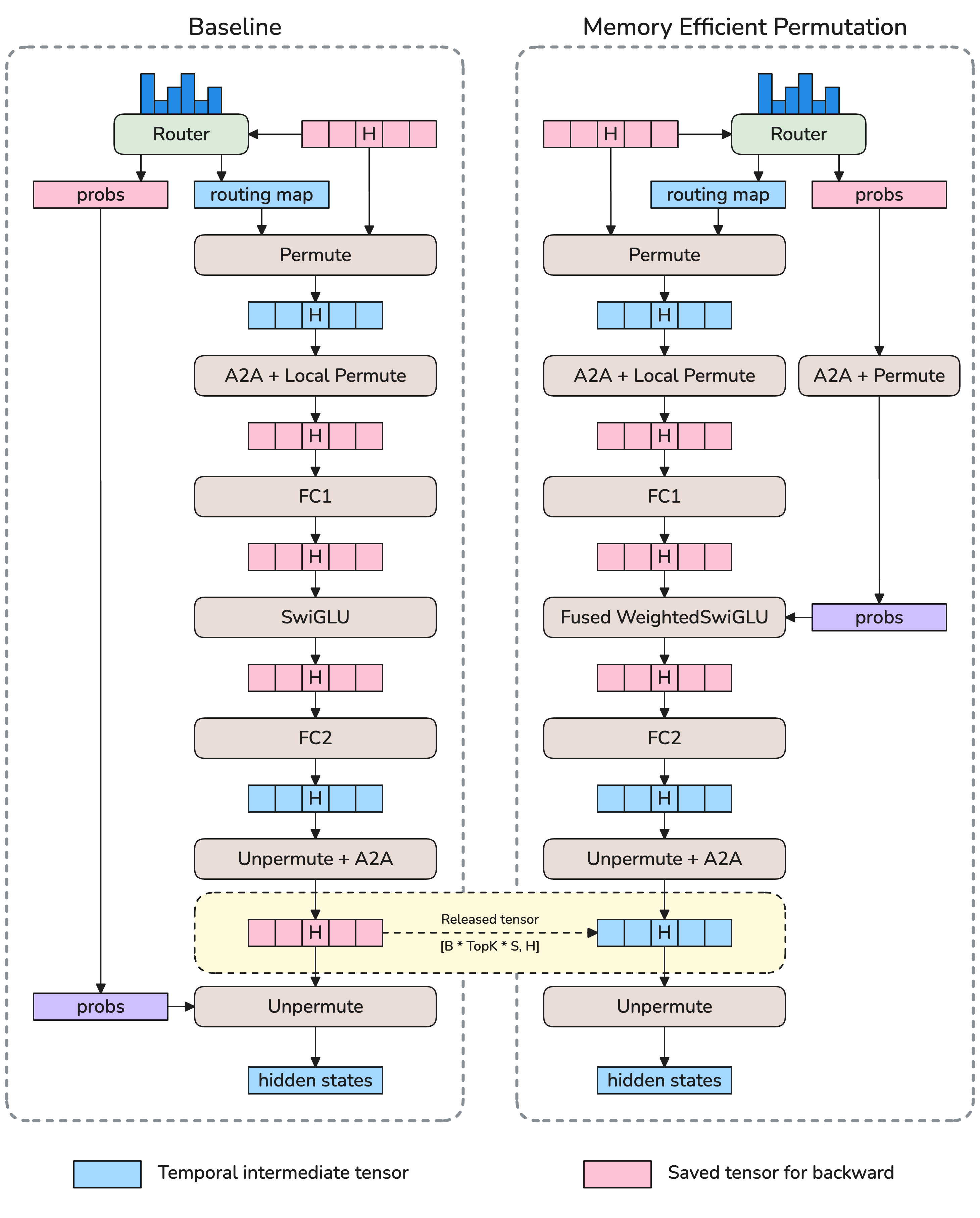
- Smarter optimizers and memory‑efficient ways to permute data.
- Communication-side
- Faster token “dispatchers” (DeepEP, HybridEP) that better use high‑speed links.
- Overlap communication with expert computation so GPUs don’t sit idle waiting for data.
- Compute-side
- Grouped GEMM: batch lots of small expert matrix multiplies into bigger ones the GPU loves.
- Kernel fusion: merge small GPU steps into fewer, faster steps.
- CUDA Graphs: reduce CPU overhead by “recording” and replaying the whole sequence of GPU work.
- Sync‑free tricks to avoid slowdowns when shapes change at runtime.
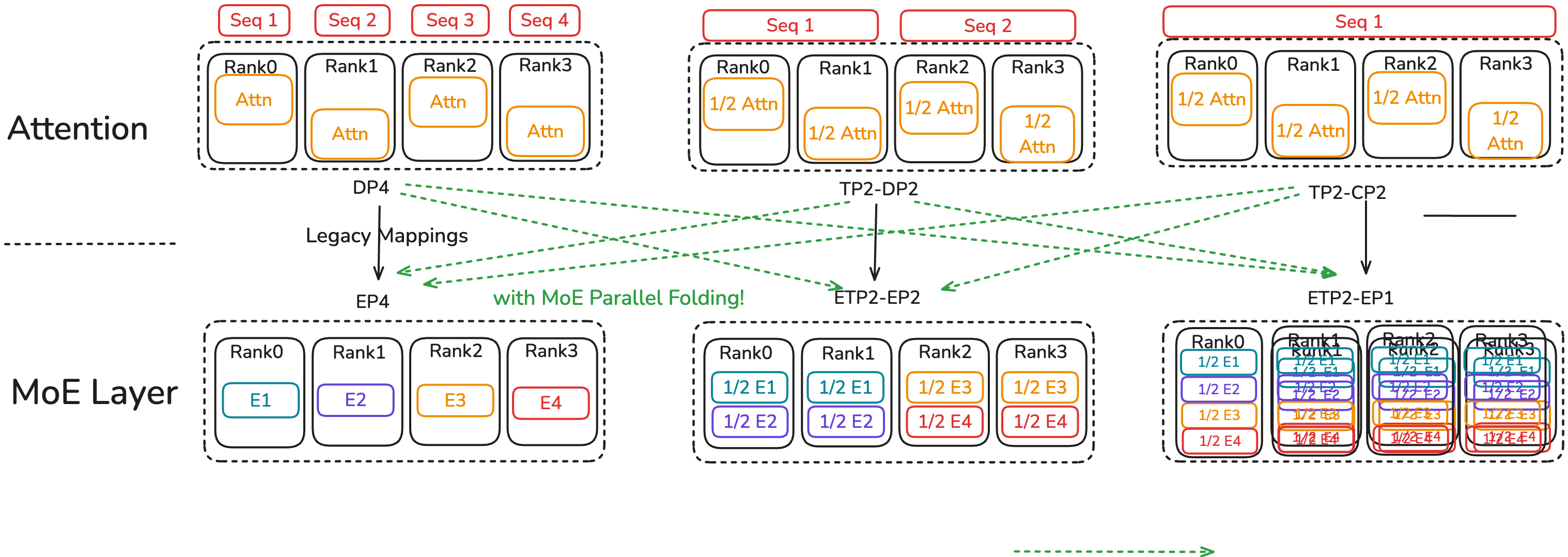
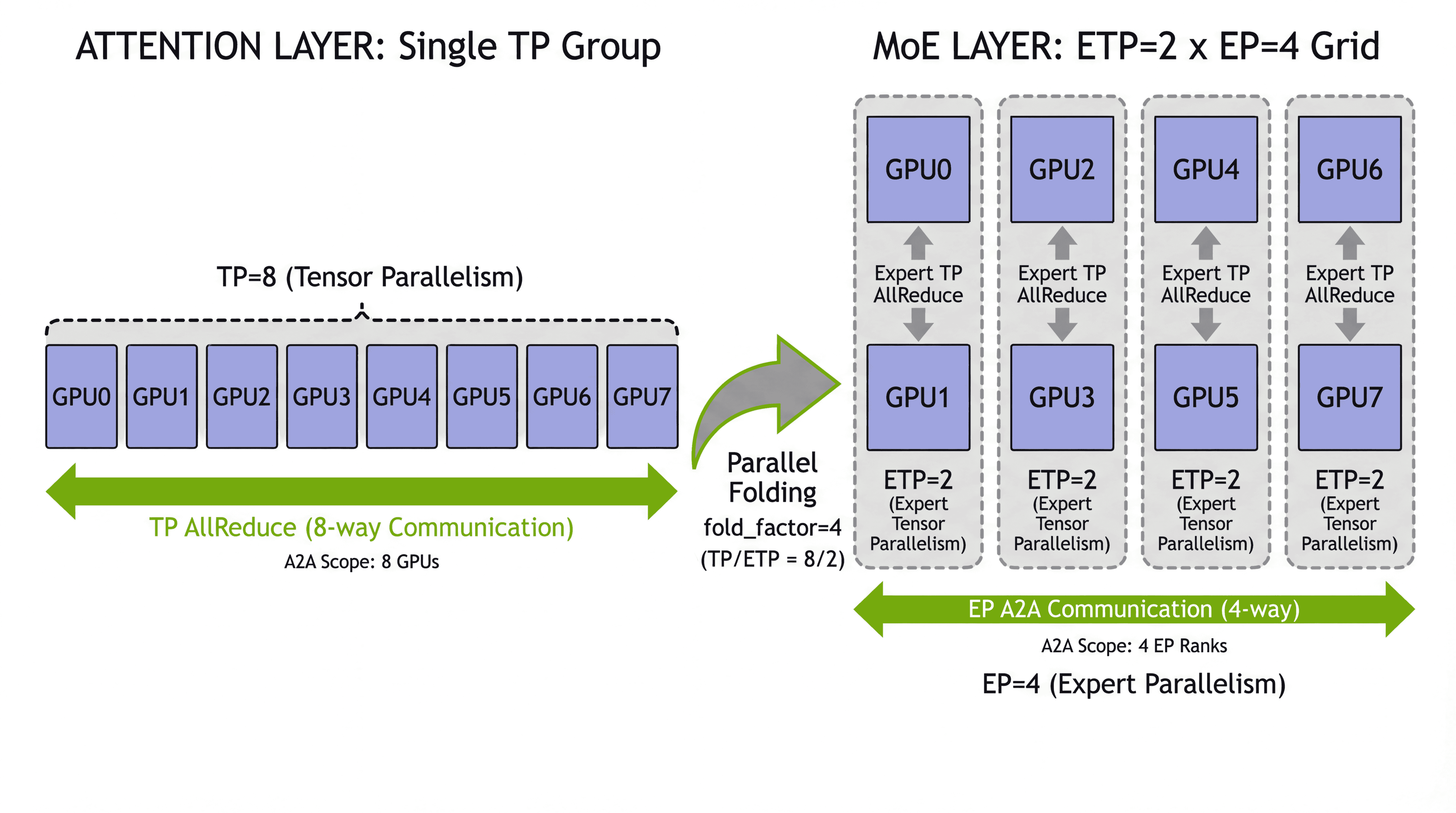
Splitting work across GPUs the smart way (Parallel Folding)
Different parts of a transformer like different “split the work” strategies:
- Attention layers (dense) like heavy Tensor Parallelism (TP) and Context Parallelism (CP) for long sequences.
- MoE layers (sparse) work best with Expert Parallelism (EP) so experts live on different GPUs and get full‑size workloads.
Old systems forced both to share one setup, which made one or the other unhappy. Parallel Folding lets attention and MoE layers use different parallel settings at the same time (they only share the same pipeline stages). This reduces wasted time and communication, especially across slower links between machines.
Extra features for real training
- Load balancing and capacity control so no expert gets overloaded.
- Checkpointing and easy reshuffling when you change how you split the model later.
- Start from dense model checkpoints (“upcycling”) and move to MoE.
- Works with very long contexts (like 16K–64K+ tokens) by adding Context Parallelism and tuning where memory goes.
- Supports reinforcement learning workflows with variable sequence lengths and online weight export.
What did they find?
They report very high per‑GPU throughput on modern NVIDIA platforms:
- DeepSeek‑V3‑685B MoE model:
- About 1,233 TFLOPS/GPU on GB300
- About 1,048 TFLOPS/GPU on GB200
- Qwen3‑235B MoE model:
- About 974 TFLOPS/GPU on GB300
- About 919 TFLOPS/GPU on GB200
They also show that:
- The full stack of memory, communication, and compute optimizations together is what unlocks high speed. Fixing just one part isn’t enough.
- Parallel Folding removes a big limitation (tying expert parallelism to data parallelism), so both attention and MoE layers can run in their favorite modes.
- Reduced precision (FP8/FP4) can safely speed up training and cut memory and communication when used selectively.
- The system is production‑ready and has been used to train MoE models ranging from billions to trillions of parameters on clusters with thousands of GPUs.
Why this matters: these results mean you can train much bigger models for the same or less compute per word, saving time and cost without giving up quality.
Why does this matter?
- Cheaper, faster training: MoE already cuts compute per word by only activating a few experts. This work removes the practical barriers so those savings show up in real training runs.
- Bigger, better models: With memory, communication, and compute balanced, teams can scale to trillion‑parameter MoE models without everything slowing down.
- Flexible and practical: Parallel Folding lets you fit the model to your hardware, not the other way around. The system supports long sequences, RL, and real‑world training features like checkpoints and optimizer sharding.
- Broad impact: Faster MoE training helps build stronger assistants for writing, coding, translation, and more—while using fewer resources.
In short, the paper shows how to turn MoE’s smart idea—only use the right experts for each word—into a fast, scalable reality by coordinating improvements across the whole training pipeline.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of concrete gaps and open questions that remain unresolved and could guide future work:
- Lack of a unified, quantitative cost model that jointly captures memory, communication, and compute trade-offs for MoE (e.g., how batch size, top‑k, EP/TP/CP/PP, offloading, and recomputation interact across topologies and precisions).
- No principled auto-tuning framework to select Parallel Folding configurations (EP/ETP/EDP vs TP/CP/DP/PP) given a cluster’s topology (NVLink/NVSwitch/IB), network bisection, and model hyperparameters.
- Limited portability evidence for DeepEP/HybridEP dispatchers beyond NVLink/NVSwitch-rich systems (e.g., IB-only or heterogeneous cloud networks); unclear fallback performance and tuning recipes.
- Missing analytical/empirical guidance for the minimum tokens-per-expert (or per-GEMM) needed to keep Grouped GEMM efficient under fine-grained experts and small microbatches.
- CUDA Graphs vs. dropless routing remains only partially addressed: how to systematically enable graph capture with dynamic token-expert assignments (e.g., bucketing/padding strategies, shape stabilization) without harming quality or utilization.
- Reduced-precision (FP8/NVFP4) training stability in MoE is under-specified: when to keep router or expert layers in higher precision, how to manage per-expert scaling/outliers, and convergence impacts across datasets and architectures.
- Router-specific precision policy (e.g., FP32 router) guidance is heuristic; thresholds for when lower precision harms routing stability or expert specialization are not quantified.
- Gradient scaling for experts (edp_size/dp_size) under variable token loads may bias updates; variance-reduction or unbiased aggregation strategies for sparse, imbalanced expert gradients are not explored.
- Load balancing remains heuristic (aux losses, token dropping, capacity factors): no clear comparisons of stability/quality trade-offs across strategies, nor adaptive controllers that react to evolving load skew during training.
- Memory spike mitigation from routing skew is not fully solved (especially in dropless modes): no dynamic, per-step capacity tuning or token replication control with formal guarantees against OOM while preserving quality.
- Expert Parallelism across nodes: placement and mapping algorithms that constrain all‑to‑all within high‑bandwidth domains are not formalized; no optimality criteria or fast solvers for EP placement on arbitrary topologies.
- Overhead and correctness implications of Parallel Folding boundaries (attention↔MoE transitions) are not quantified: costs of re-indexing/permutation, synchronization, and gradient consistency across decoupled groups.
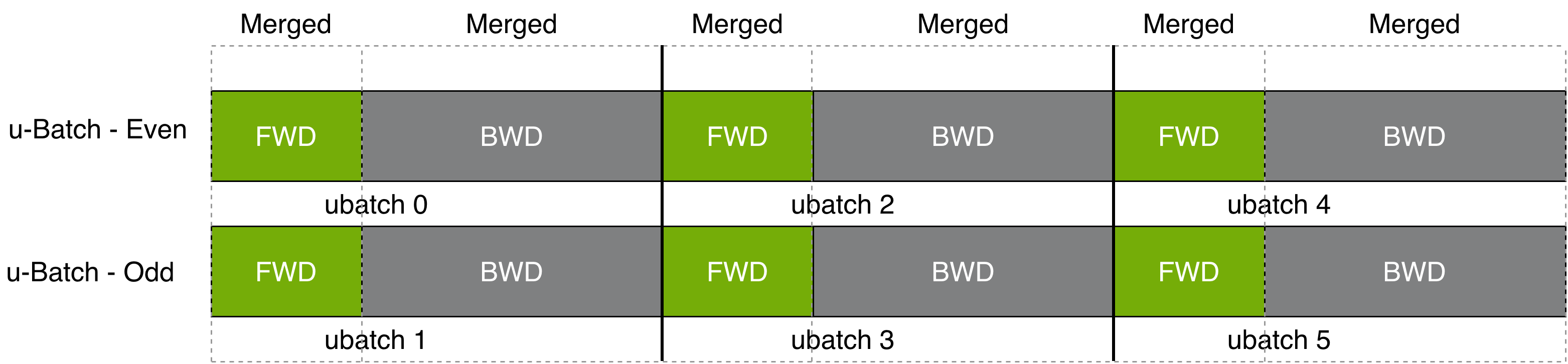
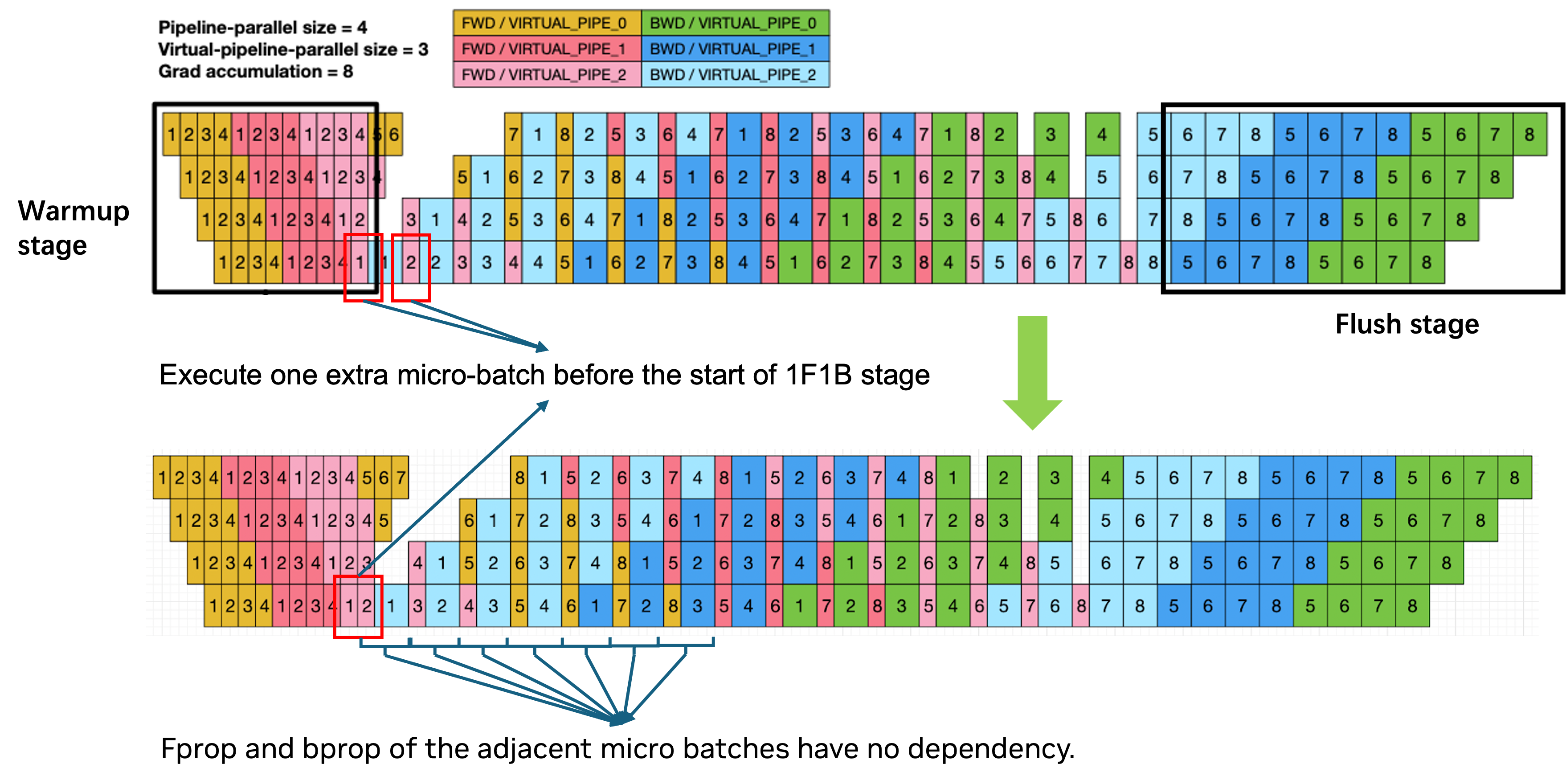
- Interactions between Parallel Folding and pipeline parallelism (PP) under deep pipelines (bubbles, cross-stage all-to-all) lack systematic treatment and benchmarks for different microbatch schedules (1F1B, zero-bubble, etc.).
- Long-context regimes: exact break-even points for switching to high CP vs. high EP, and the effect of long sequences on routing quality, expert load skew, and KV/activation memory are not characterized.
- Shared expert design space is underexplored: how to size and schedule shared experts, overlap them with routed experts, and quantify impacts on specialization, generalization, and latency.
- Distributed optimizer and Megatron-FSDP with EP: concrete guidance on when to prefer each, overlap patterns (AllGather/ReduceScatter vs. all-to-all), memory fragmentation, and stability at >1K GPUs is not provided.
- Fault tolerance and elasticity are unspecified: how to handle expert-rank failures, expert rehoming, or live changes in EP/DP sizes without retraining or quality regressions.
- Monitoring/observability gaps: standardized, low-overhead telemetry for per-expert token load, queueing time, GEMM efficiency, dispatcher bandwidth, and overlap effectiveness, plus automated anomaly detection and feedback control.
- Reproducibility and determinism: dynamic routing and cross-rank token shuffles complicate exact reproducibility; deterministic modes, seed management, and debugging workflows are not detailed.
- Energy/performance metrics are absent: no perf-per-watt or energy-per-token assessments to judge the net efficiency of communication-heavy MoE training vs. dense baselines.
- Benchmark generality: results focus on a few large LLMs and NVIDIA platforms (GB200/GB300/H100); behavior on smaller models, other MoE designs (e.g., Switch, GLaM, Mixtral variants), and non-NVIDIA or mixed clusters is unreported.
- Small-batch or latency-sensitive regimes (e.g., RL fine-tuning) are not thoroughly evaluated: how routing variance, dynamic sequence lengths, and small microbatches affect utilization and stability.
- RL-specific claims (router replay, dynamic CP, offloading) need ablation studies that quantify sample efficiency, stability, and quality trade-offs relative to dense RL post-training.
- Inference path is largely unaddressed: optimal EP/placement for serving, latency vs. throughput trade-offs, caching, and quantization synergy for MoE inference are not described.
- Compatibility and future-proofing: interaction with PyTorch compile/dynamo, graph-mode autograd, and emerging compiler stacks is not established; potential constraints from dynamic routing persist.
- Security and multi-tenant concerns: behavior under network contention, fair bandwidth sharing for all-to-all, and isolation in shared clusters are not discussed.
- Data curriculum/domain drift: how dataset composition influences expert specialization, load skew, and router stability over training time; mechanisms for rebalancing or expert “upcycling” beyond initialization from dense checkpoints.
- Automated dispatcher selection and parameter tuning (e.g., bucket sizes, overlap depth, NCCL algorithm choice) are manual; no topology- and workload-aware auto-tuner is provided.
- Theoretical guidance for choosing E, K, expert width, and layer placement (how many MoE layers, where to insert shared experts) remains empirical; clearer scaling laws tied to the presented system constraints are needed.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage the paper’s MoE training optimizations (Parallel Folding, Expert Parallelism, DeepEP/HybridEP dispatchers, Grouped GEMM, CUDA Graphs, FP8/NVFP4 training, long-context support, distributed checkpointing/FSDP, RL integration) to reduce cost, latency, and risk in production settings.
- Bold capacity at lower cost: fast training of very large MoE LLMs (100B–1T+) for domain-specific models (healthcare, finance, legal, e‑commerce) (sectors: software/AI infra, cloud, healthcare, finance)
- What: Adopt Megatron‑Core MoE with Parallel Folding + EP + DeepEP/HybridEP to train high‑capacity MoE models with sublinear per‑token compute, reaching high TFLOPs/GPU utilization.
- Value: Reduces training time and GPU-hours; enables larger capacity within fixed budgets; preserves expert GEMM efficiency while avoiding cross-node all‑to‑all bottlenecks.
- Potential products/workflows: Internal pretraining pipelines; managed MoE training services; topology‑aware cluster templates that pin EP to NVLink domains and TP/CP across nodes.
- Dependencies/assumptions: NVIDIA H100/GB200/GB300-class GPUs with NVLink/NVSwitch; PyTorch + Megatron‑Core + Transformer Engine; NCCL; adequate high‑bandwidth intra-node fabric; large-scale data pipelines; MoE-appropriate tasks.
- Efficient long-context pretraining and fine-tuning (16k–64k+ tokens) (sectors: healthcare, legal, scientific publishing, education, software)
- What: Use Context Parallelism (CP) + TP for attention and EP for MoE layers via Parallel Folding; selective activation recomputation and offloading to manage activation memory.
- Value: Practical training of long-context models for EHR summaries, case bundles, contracts, code bases, and scientific articles.
- Potential products/workflows: Long-context instruction tuning pipelines; legal/medical document assistants; code review and repository-level analysis models.
- Dependencies/assumptions: Memory budgets and checkpointing tuned for long sequences; topology-aware mapping to avoid cross-node hot spots; data with long-context supervision.
- Faster, cheaper fine-tuning via upcycling from dense checkpoints (sectors: software, enterprise IT, defense, regulated industries)
- What: Convert dense model checkpoints to MoE using Megatron‑Core’s upcycling and distributed checkpoint resharding; retain representations while adding expert capacity.
- Value: Accelerates time-to-value; reduces compute vs training MoE from scratch; smooths transition to MoE for organizations invested in dense models.
- Potential products/workflows: “Dense‑to‑MoE” conversion tools; resharding CI/CD in MLOps.
- Dependencies/assumptions: Compatible dense checkpoints and tokenizer; MoE architecture mapping; router stabilization and load-balancing tuning.
- RL post-training at scale (RLHF/RLAIF) with variable sequence lengths (sectors: AI alignment, content moderation, safety, recommendation systems)
- What: Use Megatron‑Bridge integration, packed sequence support, dynamic CP, and router replay; offloading and online weight export for fast iteration.
- Value: Reduces RL post-training wall time; stabilizes throughput with variable-length data; lowers host overhead.
- Potential products/workflows: RLHF pipelines for safety and tone; reward-model training on long, heterogeneous feedback.
- Dependencies/assumptions: RL frameworks integration (e.g., Ray, TRL-like stacks); feedback data quality; reward model reliability.
- MoE-aware production reliability and operations (MLOps) (sectors: cloud providers, platform teams, enterprises)
- What: Deploy distributed optimizer/FSDP with EP; parallelism-agnostic, distributed checkpointing and flexible resharding; token dropping/capacity control; load-balancing strategies.
- Value: Increases training robustness; simplifies scaling and recovery; reduces downtime and human intervention during large runs.
- Potential products/workflows: Parallelism-agnostic checkpoint store; automated reshard-and-resume; capacity-control monitors; MoE-specific health dashboards.
- Dependencies/assumptions: Robust storage; consistent pipeline parallelism across folded mappings; observability and alerting for expert hot spots.
- Low-precision training (FP8 and NVFP4) to halve activation/communication volumes (sectors: cloud, startups, academia)
- What: Train experts and activations in FP8/FP4 via Transformer Engine’s TEGroupedMLP; selectively keep routers/stability-critical paths in higher precision.
- Value: Cuts memory and bandwidth; improves throughput on Tensor Cores without degrading convergence when used selectively.
- Potential products/workflows: Precision‑policy managers; “calibrate‑then‑train” wizards for FP8/FP4 adoption.
- Dependencies/assumptions: Hardware with FP8/NVFP4 support; calibration/recipe adherence; monitoring for loss spikes.
- Inference throughput/latency improvements for MoE serving (sectors: SaaS LLMs, contact centers, productivity tools)
- What: Reuse Grouped GEMM, fused permutations, and optimized dispatchers to improve MoE inference kernels; optionally leverage shared experts to smooth tail latencies.
- Value: Higher QPS and lower P95 latency for MoE endpoints; enables affordable serving of high-capacity models.
- Potential products/workflows: MoE inference backends with dropless routing; latency-aware expert scheduling; shared-expert prefetch.
- Dependencies/assumptions: Inference stack integration (Triton, TensorRT‑LLM or custom); careful router/capacity tuning to avoid tail latencies.
- Academic research acceleration in MoE architectures and scaling laws (sectors: academia, research labs)
- What: Modular routers, dispatchers (AllGather/All‑to‑All/Flex), and expert backends to quickly evaluate top‑k, load balancing, and expert granularity.
- Value: Shortens iteration cycles for discovering compute‑optimal MoE regimes; enables replicable, large‑scale studies.
- Potential products/workflows: Open MoE baselines; reproducible training recipes; curriculum for distributed systems courses.
- Dependencies/assumptions: Access to multi‑node clusters; funding for GPU time; institutional IRBs for dataset governance.
- Topology-aware cluster scheduling and capacity planning (sectors: cloud/HPC, enterprise IT)
- What: Use Parallel Folding to keep EP within high‑bandwidth domains (NVLink/NVSwitch) and map CP/TP across nodes; schedule jobs accordingly.
- Value: Reduces all‑to‑all overhead; increases cluster utilization; improves MFU predictability.
- Potential products/workflows: EP‑aware schedulers; “MoE slots” in cluster partitions; runbooks for EP/TP/CP selection.
- Dependencies/assumptions: Scheduler support for topology constraints; accurate cluster fabric telemetry.
- Energy/cost reporting and procurement guidance (sectors: policy, sustainability, enterprise governance)
- What: Quantify benefits of MoE + low precision + Parallel Folding to support ESG reporting and procurement (cost/energy per training run).
- Value: Aligns AI investments with sustainability targets; informs RFPs for compute and networking.
- Potential products/workflows: Standardized MFU/energy dashboards; procurement guidelines preferring MoE for certain workloads.
- Dependencies/assumptions: Metering/telemetry; accepted reporting frameworks; stakeholder buy‑in.
Long-Term Applications
The following opportunities require further R&D, ecosystem maturation, or scaling before mainstream deployment.
- Personalized “expert ecosystems” for end users and enterprises (sectors: consumer apps, enterprise productivity, education)
- What: Dynamically compose per‑user or per‑team experts with shared backbones; route tokens to specialists learned from private data.
- Value: Highly personalized assistants without retraining whole models.
- Potential tools/workflows: Expert stores, dynamic expert loading/offloading; router policies that respect privacy contexts.
- Dependencies/assumptions: Secure multi‑tenant isolation; fast expert (un)loading; privacy‑preserving training.
- Federated or siloed MoE training (sectors: healthcare, finance, government)
- What: Train experts on local/siloed data and share only routers/backbones or aggregated deltas; align with data residency rules.
- Value: Cross‑institution capabilities without centralizing sensitive data.
- Potential tools/workflows: Federated EP/EDP orchestration; privacy accounting; router aggregation protocols.
- Dependencies/assumptions: Federated optimization support for EP groups; legal frameworks; robust comms over WAN.
- Heterogeneous/hybrid clusters and edge offloading for MoE (sectors: telecom, industrial IoT, robotics)
- What: Extend Parallel Folding to heterogeneous accelerators/interconnects, dynamically mapping EP/TP/CP across devices of varying capability; offload cold experts to host/edge.
- Value: Efficiently uses mixed fleets; enables near‑edge or on‑prem expert hosting.
- Potential tools/workflows: EP‑aware placement planners; hierarchical dispatchers spanning NVLink/PCIe/Ethernet.
- Dependencies/assumptions: Compiler/runtime support for heterogeneity; reliable edge connectivity; DeepEP‑like kernels across fabrics.
- MoE‑native AIOps: autoscaling and live load balancing (sectors: cloud providers, SaaS)
- What: Monitor expert utilization and latency to autoscale expert replicas (EDP), rebalance routers, and avoid hot experts in real time.
- Value: Stable SLAs and cost efficiency under bursty workloads.
- Potential tools/workflows: Router feedback loops; expert autoscaling controllers; congestion‑aware dispatch.
- Dependencies/assumptions: Low‑overhead telemetry; stable dropless routing; safe online router updates.
- Standardization of low‑precision training/serving (FP8/NVFP4) as a norm (sectors: hardware, frameworks, policy)
- What: Broad adoption of selective FP8/FP4 training/serving with certification recipes; regulators may factor energy efficiency into approvals.
- Value: Industry‑wide cost/energy reductions; predictable convergence profiles.
- Potential tools/workflows: Precision‑policy validators; conformance suites; energy labels for runs.
- Dependencies/assumptions: Cross‑vendor hardware support; reproducible convergence; community benchmarks.
- Cross‑modal and hybrid MoE (e.g., Mamba‑Transformer MoE) for perception‑to‑language systems (sectors: robotics, autonomous systems, healthcare imaging)
- What: Use MoE to specialize across modalities/tasks; exploit Grouped GEMM and dispatchers for sparse activation across components.
- Value: Scalable multi‑skill agents with efficient compute.
- Potential tools/workflows: Modular pipelines that route tokens/signals to modality‑specific experts; long‑context fusion.
- Dependencies/assumptions: Stable training for hybrid architectures; dataset breadth.
- High‑frequency control and planning with MoE policies (sectors: robotics, logistics, manufacturing)
- What: MoE‑based policies where experts specialize by regime/environment; inference pipelines optimized with fused kernels and shared experts for latency.
- Value: Better generalization with fast inference under hard real‑time constraints.
- Potential tools/workflows: Real‑time MoE inference runtimes; safety‑aware routing.
- Dependencies/assumptions: Deterministic low‑latency kernels; certifiable safety; robust sim‑to‑real transfer.
- Sector‑specific, long‑context foundation models (e.g., full‑patient EHRs, multi‑year financial filings, legal archives) (sectors: healthcare, finance, legal)
- What: Combine CP scaling with MoE to manage memory while increasing capacity; integrate shared experts for general patterns and specialized experts for niches.
- Value: Deeper reasoning over longitudinal data at tractable cost.
- Potential tools/workflows: Compliance‑aware data pipelines; retrieval‑augmented long‑context training.
- Dependencies/assumptions: Data governance; sustained memory/network scaling; evaluation frameworks for long‑context tasks.
- Interoperable MoE standards across frameworks and schedulers (sectors: open source, cloud)
- What: Common EP/Parallel Folding abstractions and dispatch APIs so models can move across training stacks and clouds.
- Value: Portability and reduced lock‑in; broader innovation.
- Potential tools/workflows: EP process-group specs; dispatcher ABI; auto‑tuning catalogs for TP/CP/EP.
- Dependencies/assumptions: Community consensus; vendor collaboration; reference conformance tests.
- Explainable routing and compliance auditing for MoE (sectors: finance, healthcare, public sector)
- What: Tools that log/interpret routing decisions and expert contributions for audit trails and bias analysis.
- Value: Trust, transparency, and regulatory compliance for high‑stakes deployments.
- Potential tools/workflows: Router introspection dashboards; per‑expert attribution reports; fairness probes.
- Dependencies/assumptions: Stable APIs for router telemetry; privacy‑preserving logs; accepted auditing standards.
Glossary
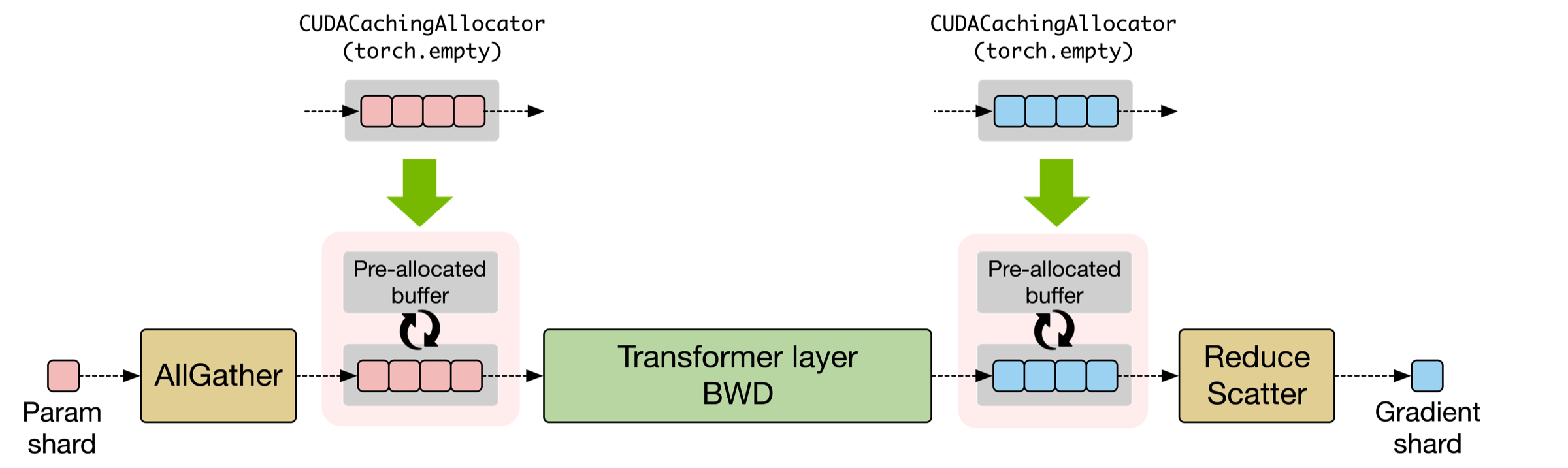
- Activation offloading: Moving intermediate activations to host memory or other storage to reduce GPU memory usage during training. "activation offloading"
- AllGather: A collective communication primitive that gathers tensors from all ranks to every rank. "AllGather (allgather): Each GPU gathers all tokens and filters for local experts."
- AllReduce: A collective operation that aggregates and distributes tensors (e.g., gradients) across all ranks, commonly by summation. "Gradients are synchronized via AllReduce."
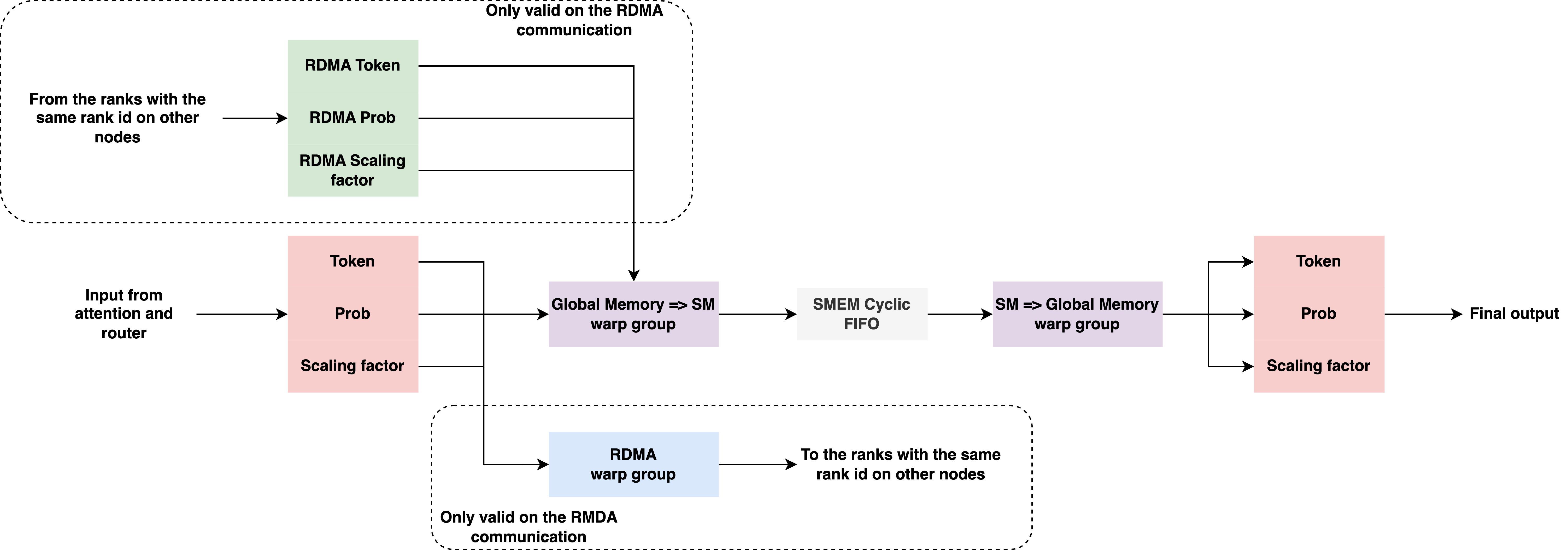
- All-to-all: A collective where each rank sends data to and receives data from every other rank, used to route tokens to experts in MoE. "EP requires all-to-all collectives to dispatch tokens to their assigned experts and collect results"
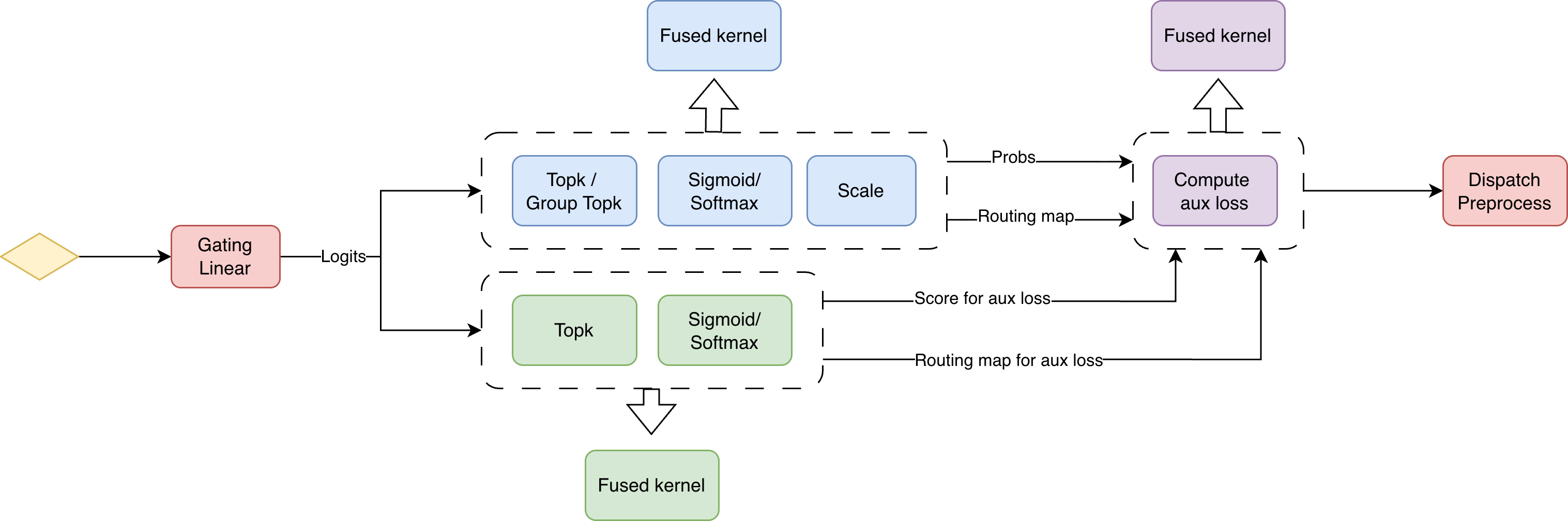
- Auxiliary losses (load balancing): Additional loss terms that encourage even expert utilization to avoid overload/underutilization. "load-balancing auxiliary losses"
- BF16: bfloat16, a 16-bit floating-point format used to reduce memory and increase throughput with manageable precision loss. "trained with BF16 precision"
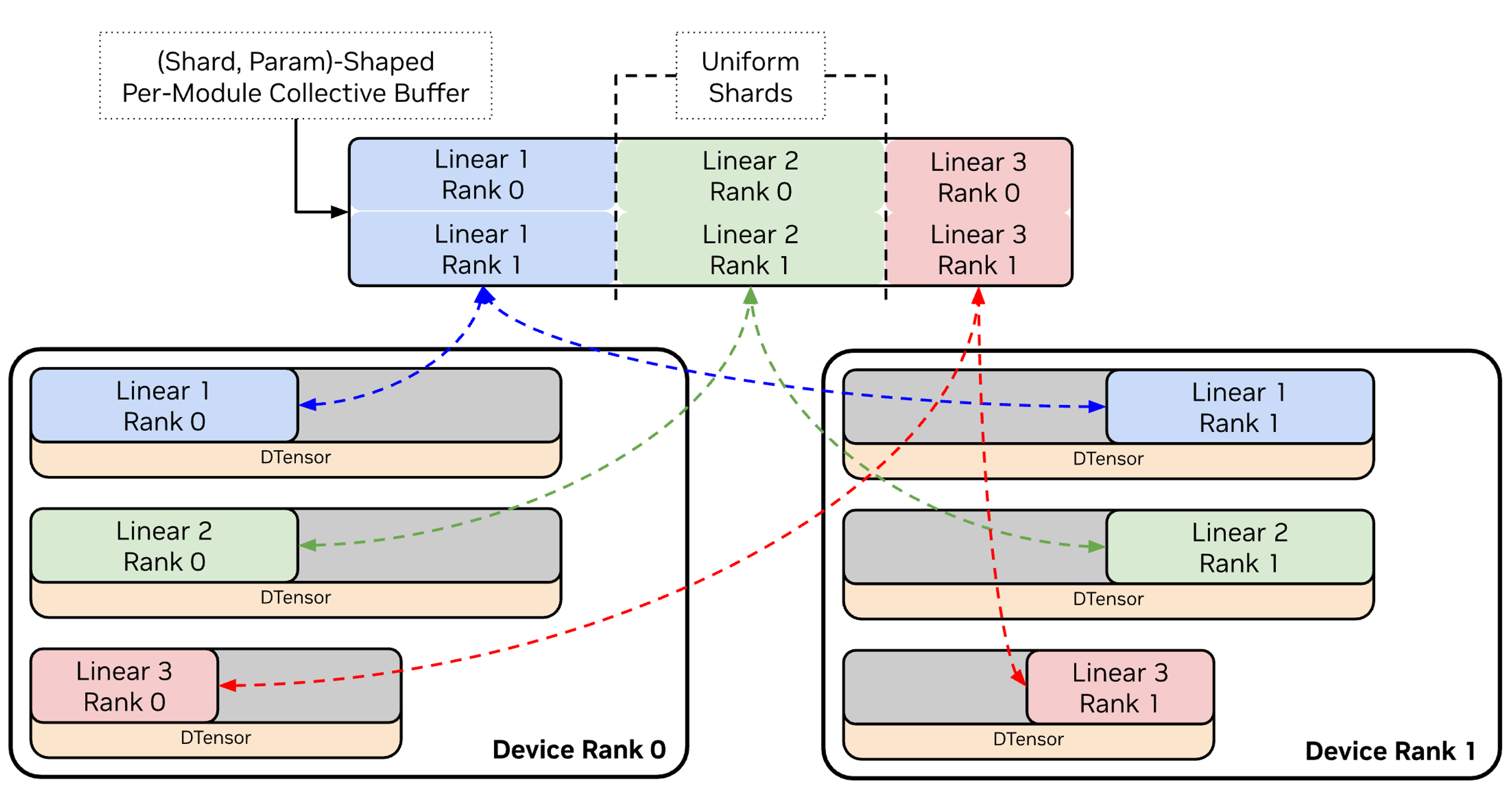
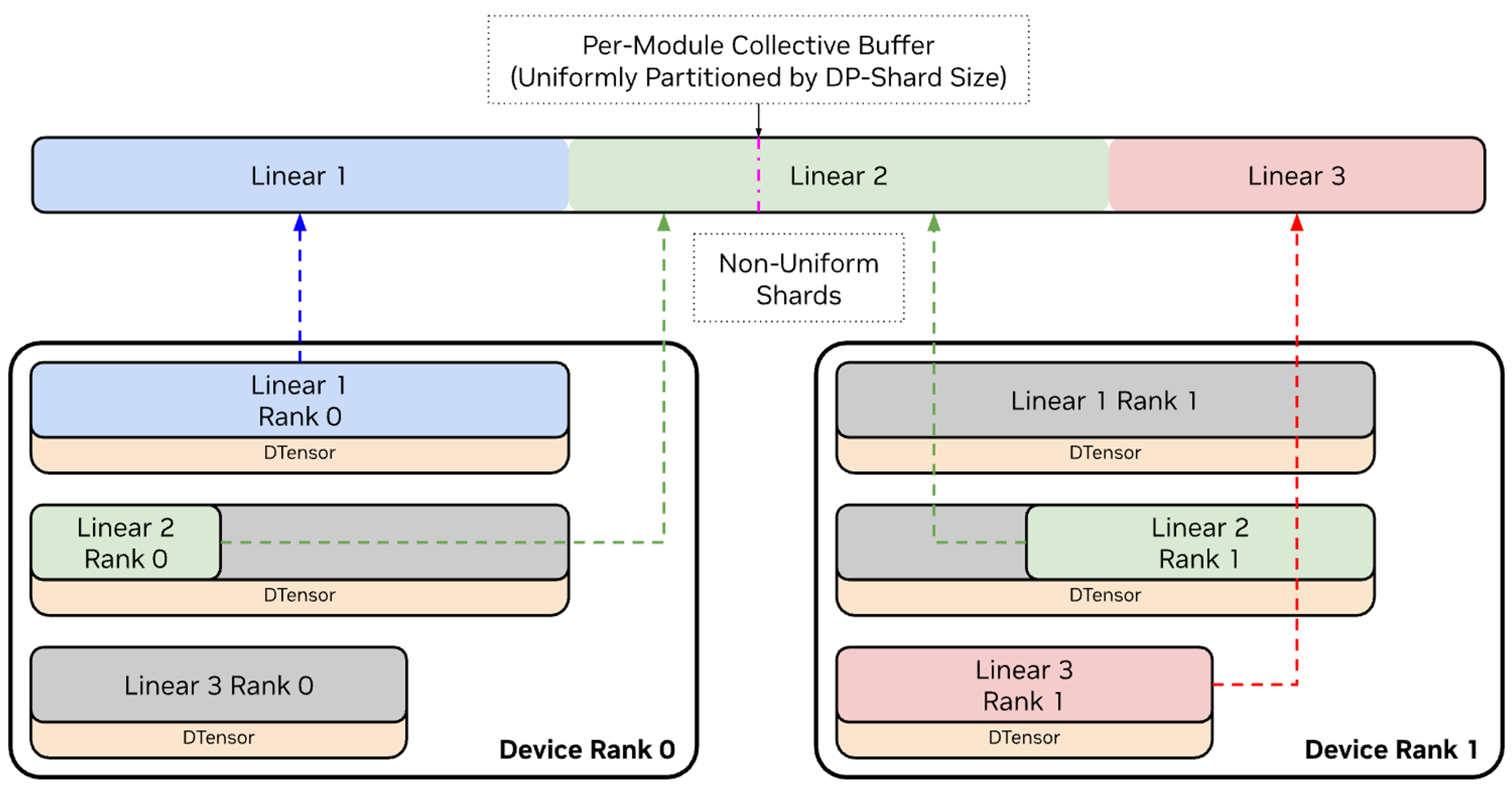
- ChainedOptimizer: A wrapper that composes separate optimizers for different parameter groups (e.g., dense vs expert) to manage distinct reduction and scaling rules. "Megatron-Core uses a ChainedOptimizer that wraps separate optimizers for dense and expert parameters."
- Communication Wall: The bottleneck in MoE training where inter-GPU communication (e.g., all-to-all) dominates step time. "The Communication Wall."
- Context Parallelism (CP): Parallelizing along the sequence dimension to distribute long sequences across GPUs while coordinating attention. "Context Parallelism (CP)"
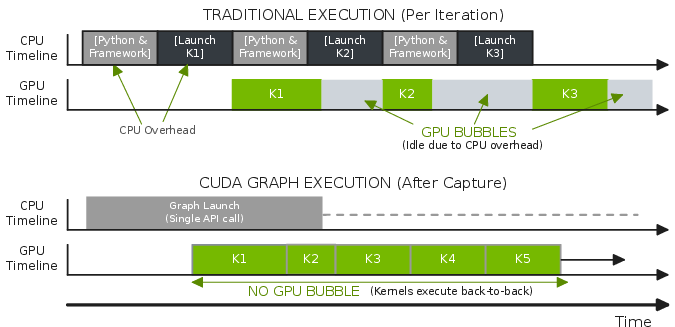
- CUDA Graphs: A CUDA feature to capture and replay GPU workloads with reduced launch overhead, requiring mostly static shapes. "CUDA Graphs eliminate host overhead but require static tensor shapes, conflicting with dropless routing."
- Data Parallelism (DP): Replicating model parameters across GPUs and splitting data batches, synchronizing gradients after each step. "Data Parallelism (DP) replicates the model across GPUs, with each GPU processing different data batches"
- DeepEP: An optimized MoE communication backend that overlaps high-throughput kernels with NVLink transfers to hide latency. "DeepEP (only high-throughput kernels are integrated, hiding NVLink communication latency through overlap)"
- Dense-Sparse Mismatch: The conflict between optimal parallelism for dense attention layers and sparse MoE layers in the same model. "The Dense-Sparse Mismatch."
- DeviceMesh: A structured mapping of tensors/parameters and parallel groups over devices for sharding and collectives. "via a dual DeviceMesh architecture"
- Distributed checkpointing: Saving model states across multiple ranks with flexibility to reshard on load under different parallelism. "distributed checkpointing with flexible resharding"
- Distributed Optimizer: An optimizer that shards states (e.g., moments) across ranks to reduce memory, coordinating updates collectively. "Distributed Optimizer + EP."
- Dropless MoE: A routing regime that does not drop tokens when an expert is overloaded, often implying dynamic shapes. "In dropless MoE, dynamic tensor shapes further require costly host-device synchronization."
- EDP (Expert Data Parallelism): Replicating the same expert across ranks to increase throughput and average gradients correctly. "expt_dp_group (expert data parallelism)"
- EP (Expert Parallelism): Distributing different experts across ranks and routing tokens to the rank that hosts their assigned experts. "Expert Parallelism (EP) distributes experts across GPUs"
- ETP (Expert Tensor Parallelism): Sharding an expert’s parameters across multiple ranks to split its internal compute. "ETP (Expert Tensor)"
- Flex (dispatcher): A dispatcher abstraction that enables pluggable optimized backends (e.g., DeepEP, HybridEP) for token routing. "Flex (flex): Unified design supporting DeepEP ... and HybridEP"
- FP4: 4-bit floating-point format (e.g., NVFP4) used for further memory/communication reduction in certain kernels. "supporting FP8 and FP4 quantization."
- FP8: 8-bit floating-point precision used to reduce memory/communication and accelerate Tensor Core GEMMs with careful scaling. "Comprehensive reduced-precision training (FP8 and FP4) support"
- FSDP: Fully Sharded Data Parallelism; shards parameters, gradients, and optimizer states across data-parallel ranks to minimize memory. "distributed optimizer and FSDP support"
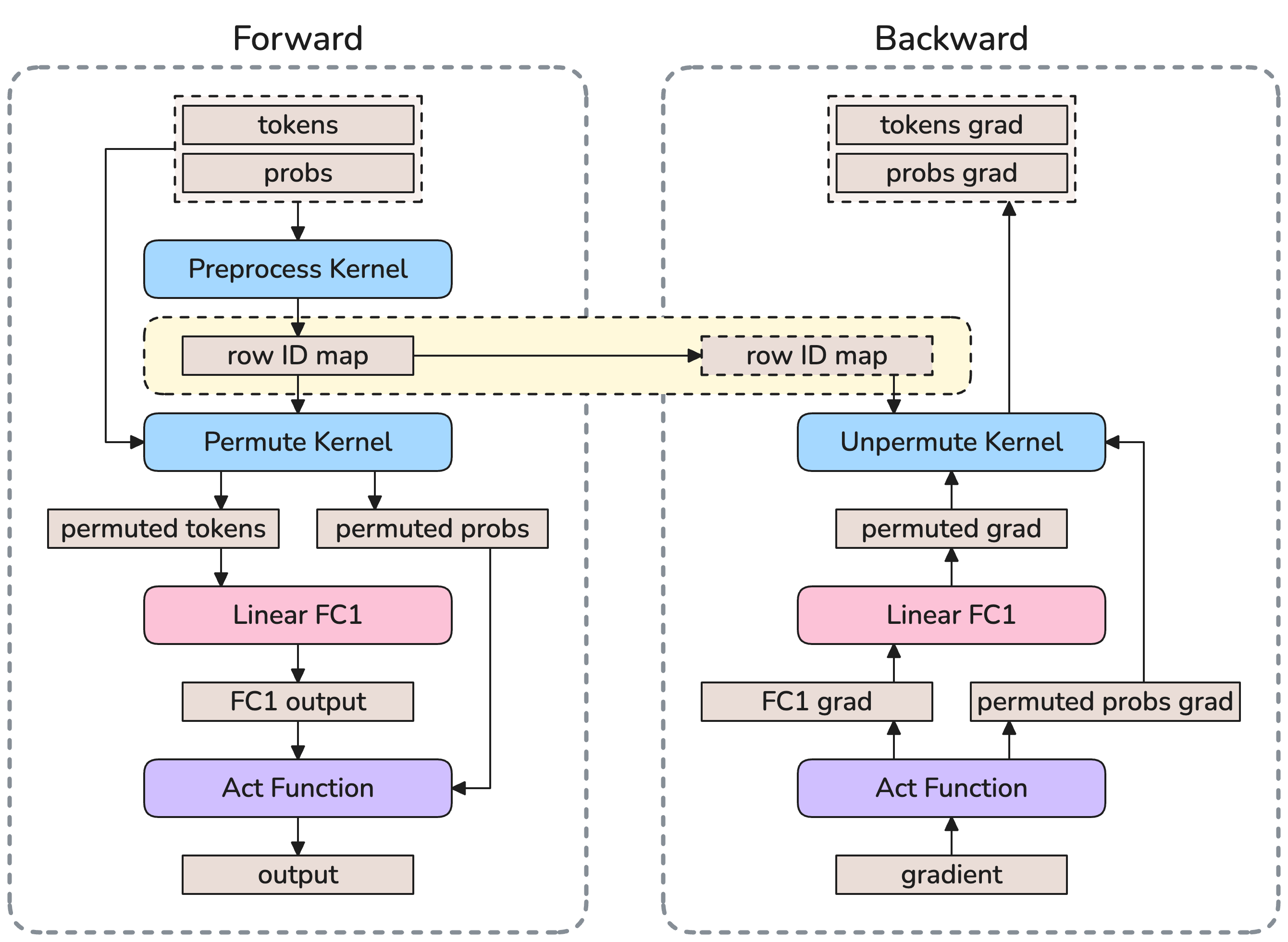
- Grouped GEMM: Batching multiple small matrix multiplications into a single kernel to improve GPU utilization for many experts. "Grouped GEMM enables efficient batching of multiple expert computations"
- HybridEP: An MoE communication backend optimized for NVLink-rich topologies, combining approaches for higher bandwidth. "HybridEP (high-bandwidth MoE communication kernels that deliver better performance on NVLink-rich topologies like NVL72)"
- Kernel fusion: Combining multiple small kernels into one to reduce memory traffic and launch overhead. "kernel fusion"
- Megatron-FSDP: Megatron-Core’s custom FSDP variant integrating with TP/EP/CP and mixed precisions while overlapping comm/compute. "Megatron-Core's custom FSDP (Megatron-FSDP) fully shards parameters, gradients, and optimizer states"
- Memory Wall: The constraint in MoE where total parameter/activation/optimizer memory far exceeds per-token compute needs. "The Memory Wall."
- MFU (Model FLOP Utilization): A measure of how effectively a model uses available FLOPs given parallelism and overheads. "Model FLOP Utilization (MFU)"
- MoE Parallel Folding: A strategy that decouples attention and MoE parallelism mappings so each can use its optimal configuration. "MoE Parallel Folding \cite{liu2025moeparallelfoldingheterogeneous}"
- NCCL: NVIDIA’s collective communications library used for efficient multi-GPU operations. "Standard NCCL-based point-to-point communication"
- NVFP4: NVIDIA’s 4-bit floating-point format used for low-precision training. "NVFP4"
- NVLink: High-bandwidth interconnect between GPUs enabling faster intra-node communication. "NVLink communication latency"
- Parameter-Compute Mismatch: In MoE, total parameters far exceed those active per token, decoupling memory from compute. "Parameter-Compute Mismatch"
- Pipeline bubbles: Idle periods at pipeline stage boundaries that reduce overall utilization. "Pipeline bubbles: Pipeline parallelism introduces idle time at pipeline boundaries."
- Pipeline Parallelism (PP): Splitting the model into stages across ranks and passing micro-batches through the pipeline. "Pipeline Parallelism (PP) splits the model by layers across GPUs"
- ProcessGroupCollection: A structured set of process groups used to organize distinct parallel communication domains. "Megatron-Core organizes these groups through ProcessGroupCollection:"
- ReduceScatter: A collective that reduces and scatters partitions of a tensor across ranks, often used with tensor sharding. "AllGather or ReduceScatter collectives"
- Reduced-Precision Training: Training with lower-precision formats (e.g., FP8/FP4) to save memory/communication and boost throughput. "Reduced-Precision Training in FP8/FP4 for MoE."
- Router replay: An RL-specific optimization that reuses or reapplies routing decisions to reduce overhead. "router replay"
- Shared expert: An expert that processes all tokens regardless of routing, often computed in parallel with routed experts. "a shared expert that processes all tokens regardless of routing."
- SwiGLU/GeGLU: Gated activation functions used in modern MLPs to improve expressivity and performance. "SwiGLU/GeGLU activations"
- Sync-free execution: Execution that minimizes or removes explicit synchronization points to reduce stalls. "sync-free execution"
- Tensor Core: Specialized GPU units that accelerate matrix math, especially effective with FP8/FP4 GEMMs. "accelerating Tensor Core GEMMs"
- Tensor Parallelism (TP): Sharding large weight matrices across ranks along model dimensions, with collectives to combine results. "Tensor Parallelism (TP) shards weight matrices across GPUs along the hidden dimension"
- TEGroupedMLP: A Transformer Engine module implementing grouped expert MLPs with support for low precision. "All local experts run in a single Grouped GEMM call via TEGroupedMLP"
- Token dispatcher: The component that permutes and transfers tokens across ranks to their assigned experts and back. "The token dispatcher prepares tokens for cross-GPU communication."
- Token dropping: A mechanism to cap per-expert load by discarding excess tokens beyond capacity for stability/efficiency. "token dropping with capacity control"
- Top- selection: Choosing the k highest-scoring experts for each token based on router probabilities. "Top- Selection"
- TopKRouter: The router variant that selects the top-k experts per token according to learned gating scores. "The TopKRouter determines which experts process each token."
- Transformer Engine: NVIDIA’s library providing optimized kernels and low-precision support for Transformer training. "Transformer Engine \cite{nvidia_transformer_engine} optimized implementation supporting FP8 and FP4 quantization."
- ZeRO: A family of techniques for sharding optimizer states, gradients, and parameters to reduce memory usage. "ZeRO-style optimizer state sharding"
Collections
Sign up for free to add this paper to one or more collections.