- The paper introduces TensorPool, a 3D-stacked many-core RISC-V processor with dedicated tensor engines that delivers 8.4 TFLOPS at 4.3W for AI-native 6G RAN tasks.
- It employs hierarchical scratchpad memory and advanced 3D stacking to achieve up to 89% utilization and 14.5× speedup on GEMM workloads.
- The design integrates classical PHY kernels alongside AI workloads, enabling real-time processing under stringent edge power constraints.
TensorPool: A 3D-Stacked Many-Core Processor for AI-Native Radio Access Networks
Motivation and Context
TensorPool addresses the imminent computational bottlenecks of AI-native baseband processing in 6G Radio Access Networks (RAN). AI-augmented physical layer (PHY) workflows—channel estimation, beamforming, interference mitigation—incur significant compute complexity, especially stringent under sub-millisecond real-time constraints and edge power budgets (≤100 W). Traditional architectures such as CPUs, FPGAs, and ASICs lack the dynamic scalability and efficiency for these mixed workloads. TensorPool innovates with domain specialization: a heterogeneous many-core RISC-V cluster augmented by dedicated Tensor Engines (TEs), tightly coupled to a scalable scratchpad memory subsystem, all realized in TSMC's 7nm node with advanced 3D-stacking techniques.
AI-Native PHY Workload Characterization
A comprehensive survey of neural architectures for AI-Native RAN reveals two principal classes: full OFDMA uplink chains and focused channel estimation models. Attention- and ResNet-convolutional models dominate, unified by GEMM-intensive computation kernels and moderate parameter footprints (≤4 MiB in FP16 precision). Importantly, the computational demands of edge-deployable models require baseline 6 TFLOPS throughput—1.67× greater than the state-of-the-art TeraPool baseline. This design target ensures practical fit for real-time basestation deployments, minimizing hierarchical data movement.
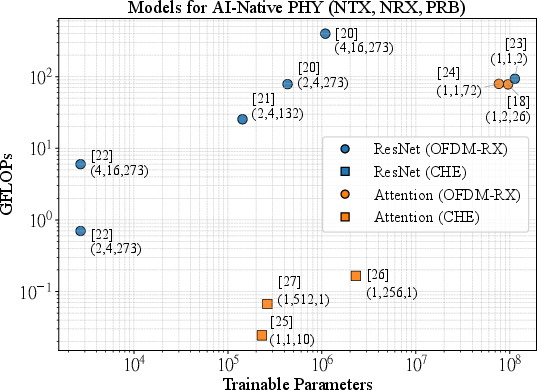
Figure 1: Model complexity and footprint survey for AI-Native PHY tasks: highlighting peak operation counts and memory usage across channel estimation and OFDMA chains.
Architecture and TE-Memory Integration
TensorPool comprises 256 RISC-V PEs and 16 TEs, organized in a modular cluster with hierarchical crossbar interconnects and 4 MiB scratchpad L1 memory. Each TE exposes a 256 FMA pipeline for FP16 MACs, attaining a peak throughput of 8.4~TFLOPS—2.25× that of a homogeneous PE cluster.
Innovatively, TE integration overcomes the non-uniform latency penalty of distributed L1-banks. Throughout burst-mode memory transactions, streaming buffers, and reorder logic, outstanding requests are pipelined and responses are grouped for maximal transfer efficiency. This architecture ensures that computation is not bottlenecked by memory bandwidth, even when accessing remote banks across the cluster.
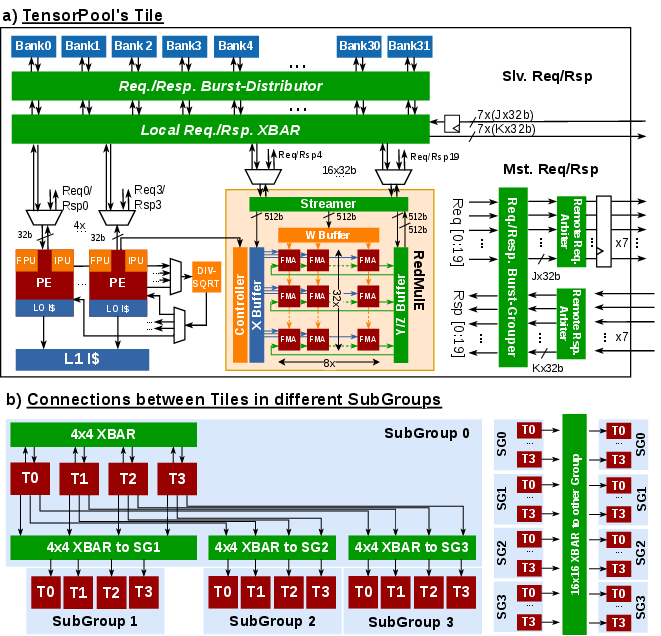
Figure 2: Tile-level TE/PE layout and hierarchical crossbar interconnects for low-latency scratchpad bank sharing.
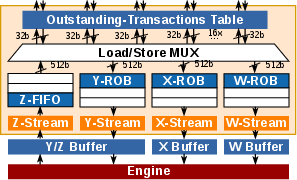
Figure 3: RedMulE TE streamer structure with out-of-order request/response tracking for burst memory transactions.
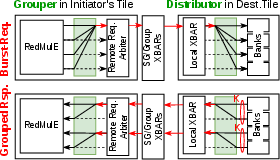
Figure 4: Burst transaction grouping and distribution mechanisms mitigate backpressure in wide TE memory requests.
Memory Balance and Utilization Analysis
Using Kung's principle, analytical and cycle-accurate RTL experiments show TensorPool's TEs achieve near-ideal utilization (98\%) on large GEMM workloads with K=4, J=2 (response/request grouping), validating optimal memory balance both locally and over hierarchical crossbars.
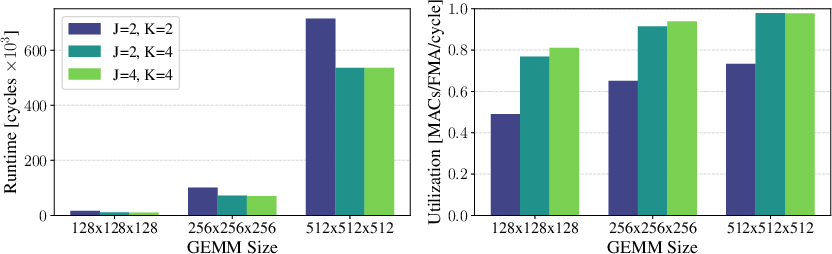
Figure 5: Single-TE GEMM runtime as a function of memory interconnect bandwidth and problem size.
TensorPool enables flexible parallelization: GEMM workloads are dynamically partitioned across TEs with interleaved access to mitigate bank contention. Fully scaled, 16 TEs achieve 89\% utilization—3× greater than pure PE clusters—with up to 14.5× speedup.
PEs concurrently execute classical PHY kernels (Batchnorm, FFT, LS, MMSE detection) in parallel with TEs, yielding low runtime (<0.15 ms for large MIMO/FFT workloads at 1 GHz), supporting hybrid AI/classical signal processing within the same architecture.
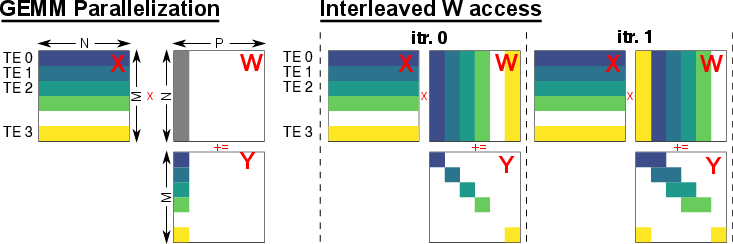
Figure 6: Workload parallelization across TEs and bank-interleaved W-column access for maximized throughput.
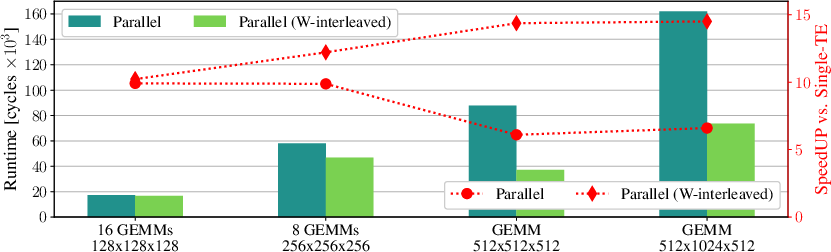
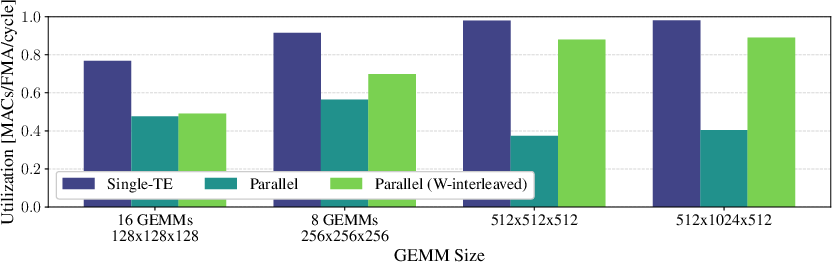
Figure 7: Parallel GEMM runtime scaling and TE utilization with cooperative workload mapping.
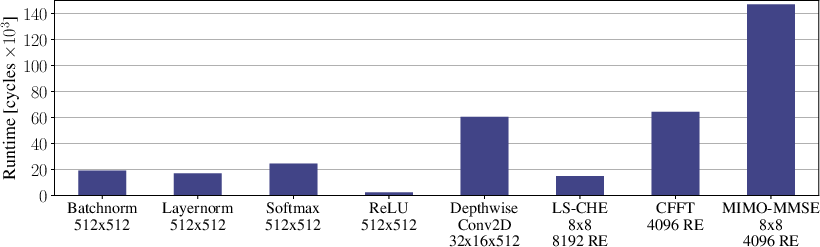
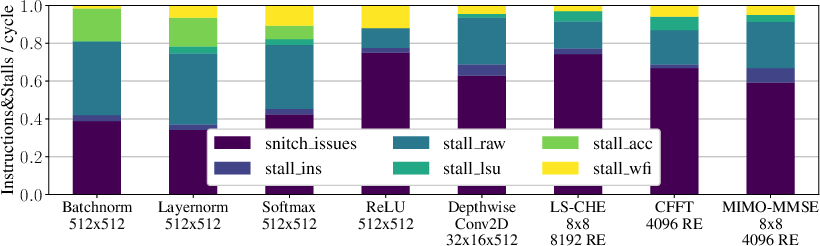
Figure 8: Breakdowns for runtime, IPC, and stall cycles on parallel PHY workloads mapped to PEs.
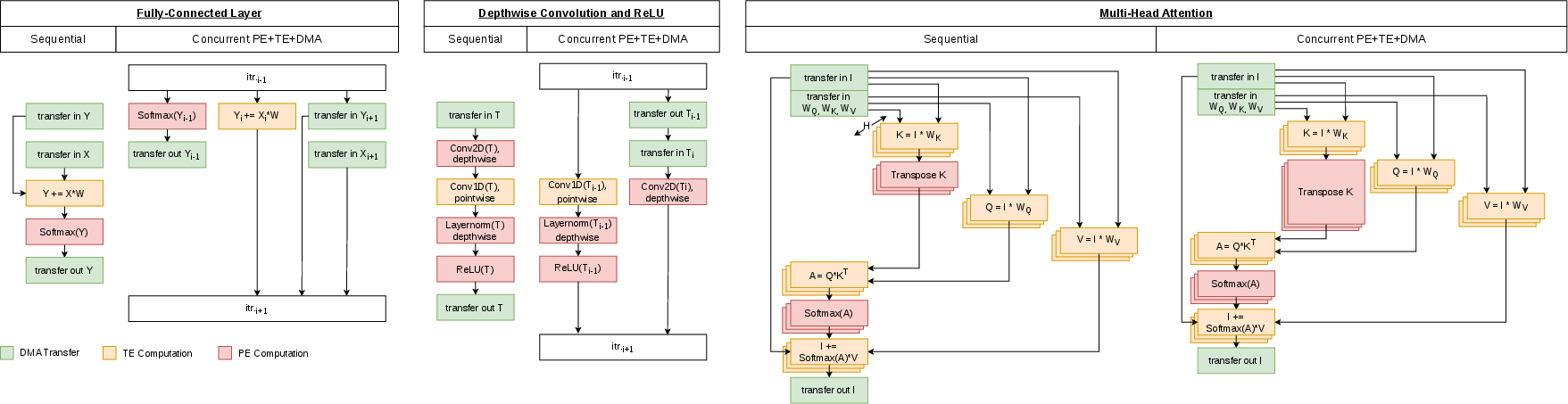
Figure 9: Data-flow diagrams for sequential and concurrent compute/data-movement among TEs, PEs, and DMA.
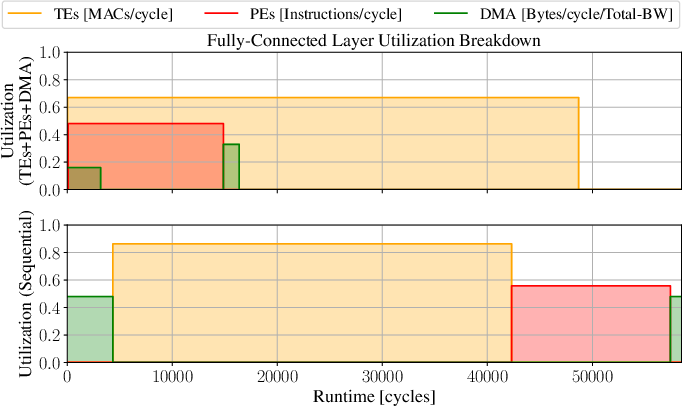
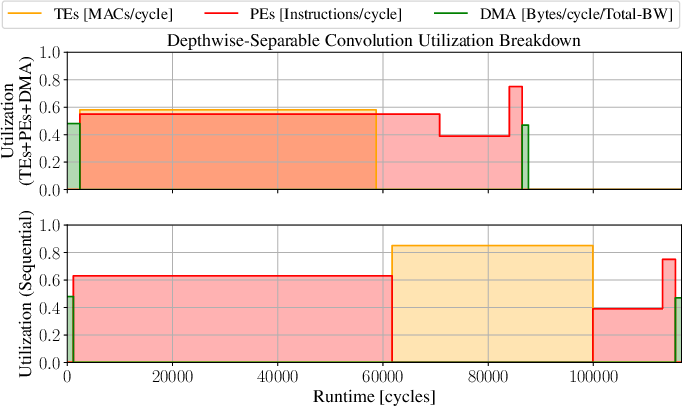
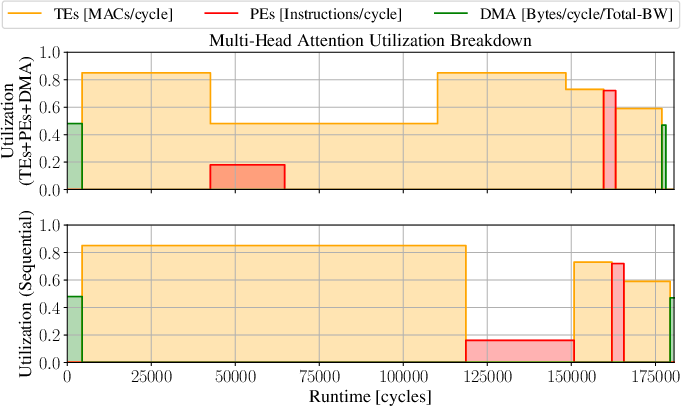
Figure 10: Comparative runtime and utilization metrics for concurrent execution of FC, DW-Conv, and MHA blocks.
Physical Design, Area, and Power
In TSMC N7, TensorPool achieves 57.53~GFLOPS@FP16/W/mm²—9.1× above TeraPool—while maintaining a 4.32 W draw. Subgroup synthesis reveals TE buffering/streamer logic accounts for 50\% of TE area but ensures latency tolerance, yielding 2.23× compute density over PE-only designs. Notably, routing channels occupy 21–31\% of the total cluster area, a substantial area efficiency penalty in 2D realizations.
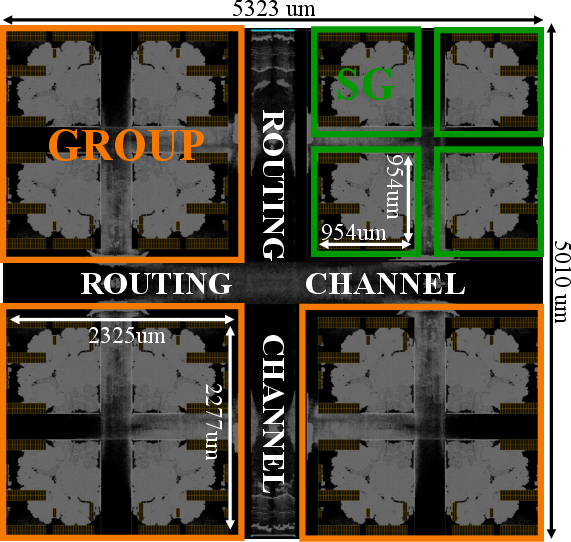
Figure 11: Die snapshot of placed/routed 2D TensorPool cluster.
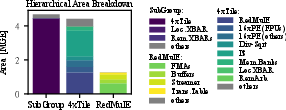
Figure 12: Area breakdown for SubGroup, with TE buffers/streamers as principal contributors.
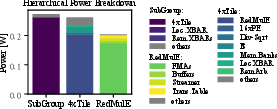
Figure 13: Power breakdown for SubGroup operation under large GEMM loads.
3D-Stacked Implementation and Routing Efficiency
TensorPool's Group macros are partitioned across two stacked dies using wafer-to-wafer hybrid bonding (≤6 TFLOPS0m pitch), eliminating diagonal inter-group routing and reducing channel area by 67%. The total footprint contracts to 2.326 TFLOPS1 less than the 2D design, a superlinear improvement offering promising scalability.
Timing closure demonstrates negligible frequency degradation; cross-tier paths comprise only 10\% of clock period delays, and routing congestion remains controlled.
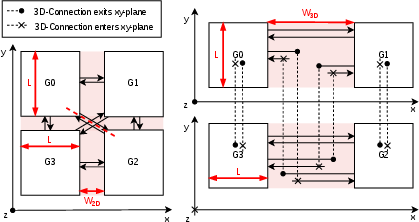
Figure 14: Schematic of 2D versus 3D floorplan; 3D stacking enables streamlined connections and eliminates central routing bottlenecks.
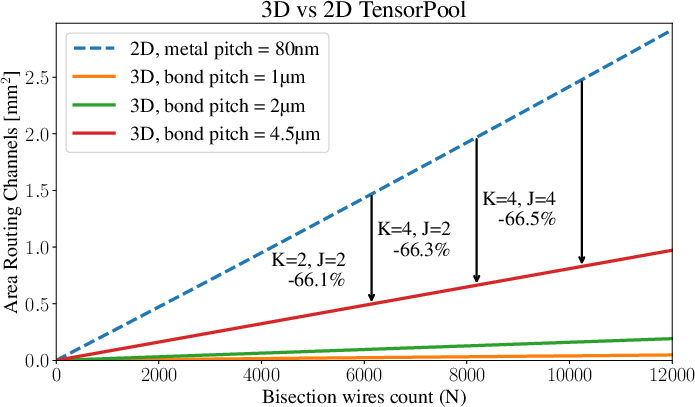
Figure 15: Quantitative comparison of routing channel area in 2D versus 3D stacked implementations.
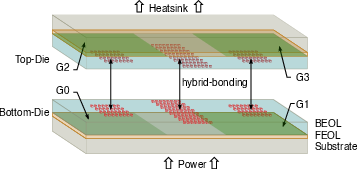
Figure 16: Visualization of wafer-to-wafer hybrid bond stacking; vertical group connections route through central channels.
Comparative Evaluation and Implications
Contrasted with datacenter-oriented GPU tensor clusters (e.g., NVIDIA Aerial RAN systems reaching 503.8 TOPS at 600 W), TensorPool delivers comparable area efficiency per scaled node and greater local memory embodied per compute cluster (4 MiB vs 128 KiB/SM). With 4.32 W edge power and up to 8.4 TFLOPS sustained, it meets AI-RAN processing requirements in edge basestation contexts, offering a practical path forward where commercial GPU solutions are otherwise power-prohibitive.
The 3D stacking technique further amplifies area efficiency, enabling compaction and future performance scaling as memory bandwidth and model sizes evolve.
Conclusion
TensorPool demonstrates that a domain-specialized, 3D-stacked many-core RISC-V cluster with FP16 Tensor Engines enables real-time AI-Native PHY baseband processing within stringent edge power envelopes. Architectural innovations in memory interface, interconnect topology, and scalable TE parallelization enable 89\% utilization and order-of-magnitude efficiency gains, both for GEMM-intensive and mixed classical workloads. 3D stacking introduces superlinear footprint and area efficiency improvements, setting the stage for extensible, high-throughput AI-RAN processors deployable at scale in future wireless infrastructures.