- The paper demonstrates that co-designing a reconfigurable systolic-vector microarchitecture (SNAKE) with multi-core scheduling cuts decode latency by up to 2.9x versus traditional MAC Trees.
- It shows that reallocating on-chip area from large SRAM buffers to increased processing elements achieves over 11x decode speedup against GPUs with enhanced energy efficiency.
- The evaluation confirms that adaptive multi-core scheduling and dynamic array reconfiguration significantly improve compute-area efficiency and reduce power overhead in 3D-stacked NMP systems.
Rethinking Compute Substrates for 3D-Stacked Near-Memory LLM Decoding: Microarchitecture–Scheduling Co-Design
Introduction and Motivation
In the context of LLM inference, the decode phase has emerged as the primary bottleneck due to its token-level generation nature, characterized by poor weight reuse and low arithmetic intensity. Classical systems are memory-bound during decode, but the introduction of 3D-stacked near-memory processing (NMP) dramatically increases available memory bandwidth. However, this paper demonstrates that such architectures often invert the performance bottleneck, returning decode operators to the compute-bound regime. As a result, compute substrate design—especially under the stringent area budgets of logic dies in 3D-stacked DRAM—is pivotal for overall system performance.
The authors identify that prior solutions, typically based on MAC Tree compute organizations, do not scale compute density sufficiently, resulting in the under-utilization of memory bandwidth and suboptimal latency (Figure 1).
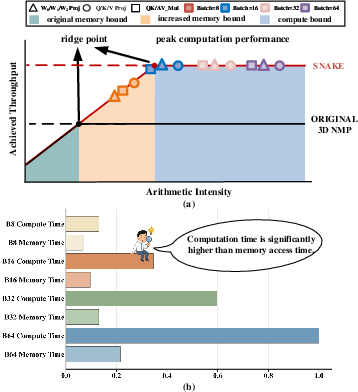
Figure 1: (a) Roofline analysis exposes compute-boundedness of decode operators on 3D NMP; (b) Stratum’s memory-side execution analysis confirms compute limitations.
Systolic Array vs. MAC Tree: Architectural Analysis
The paper provides a direct microarchitectural and area/power comparison between MAC Trees and Systolic Arrays (SAs). MAC Trees, while flexible for reduction operations, require expansive operand delivery and reduction networks, which scale poorly in area and energy efficiency. SAs—composed of simple, regular PEs—enable high compute density and array-level data reuse, which directly translates into superior area and energy efficiency. Under equivalent logical capabilities, SA designs require over 8x less area compared to MAC Trees (Figure 2).
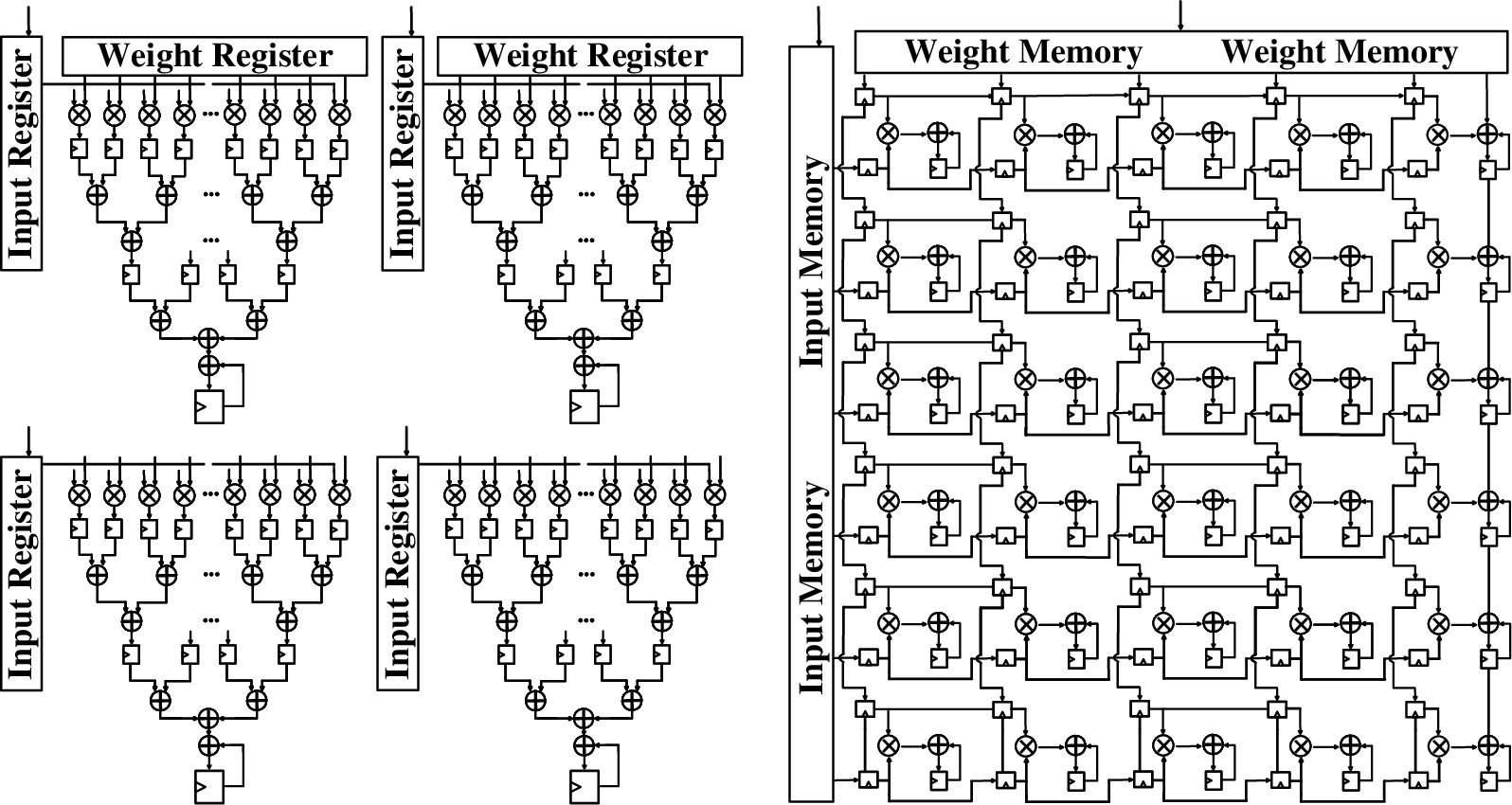
Figure 2: Microarchitectural comparison reveals Systolic Arrays achieve superior area efficiency versus MAC Trees.
However, vanilla SAs are mismatched against LLM decode workloads, which are shape-diverse (notably M≪N,K in GEMM workloads) and require flexible mapping/dataflow. A fixed-shape SA suffers from low PE utilization in such contexts (Figure 3).
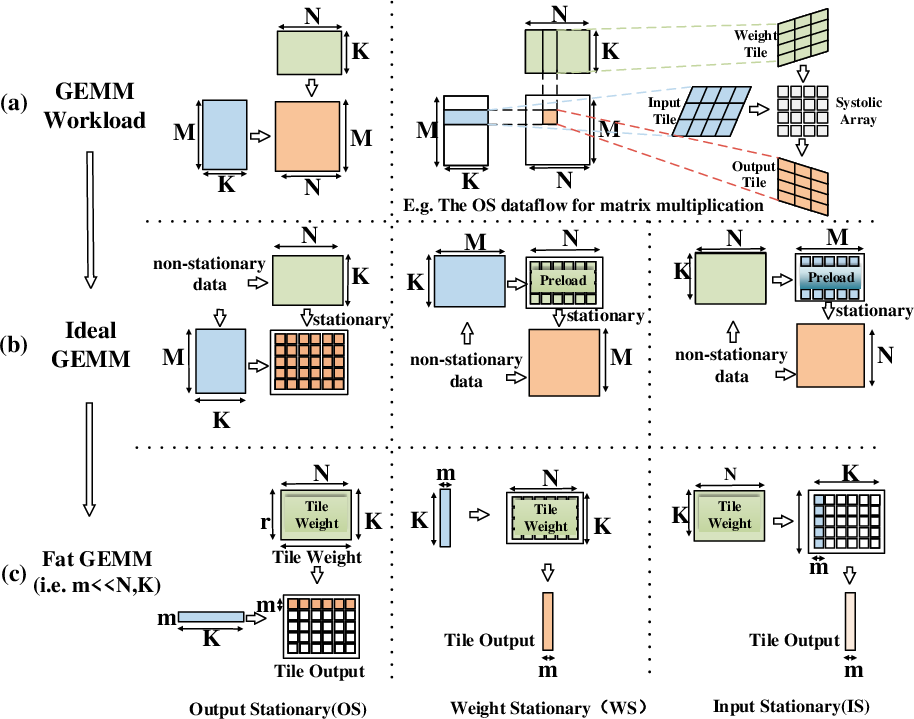
Figure 3: Illustrative abstraction of GEMM mapping and the impact of different systolic dataflows.
Enabling Fine-Grained Reconfigurability
Need for Reconfigurable Systolic Arrays
Decode workloads demand that the compute array adapts to operator shape diversity. Array reconfigurability (logical partitioning, flexible array dimensions) and dataflow reconfigurability (switching between OS and IS modes) are therefore essential for maintaining high utilization within tight area/power budgets. Profiling of representative LLM decode workloads confirms stark preference for different dataflows, contingent on operator characteristics.
Buffer-to-Compute Area Reallocation
With increased local bandwidth, the requirement for large on-chip SRAM buffers is relaxed. This opportunity enables area expenditure to be shifted towards increasing PE counts (more compute), as long as buffer provisioning is tuned not to reintroduce memory stalls. The design space analysis in the paper confirms that increasing PE count yields rapid performance increases and energy efficiency up to the inflection where buffer scarcity dominates. This enables denser compute deployment and elongated arrays optimal for the small-M decode regime (Figure 4).
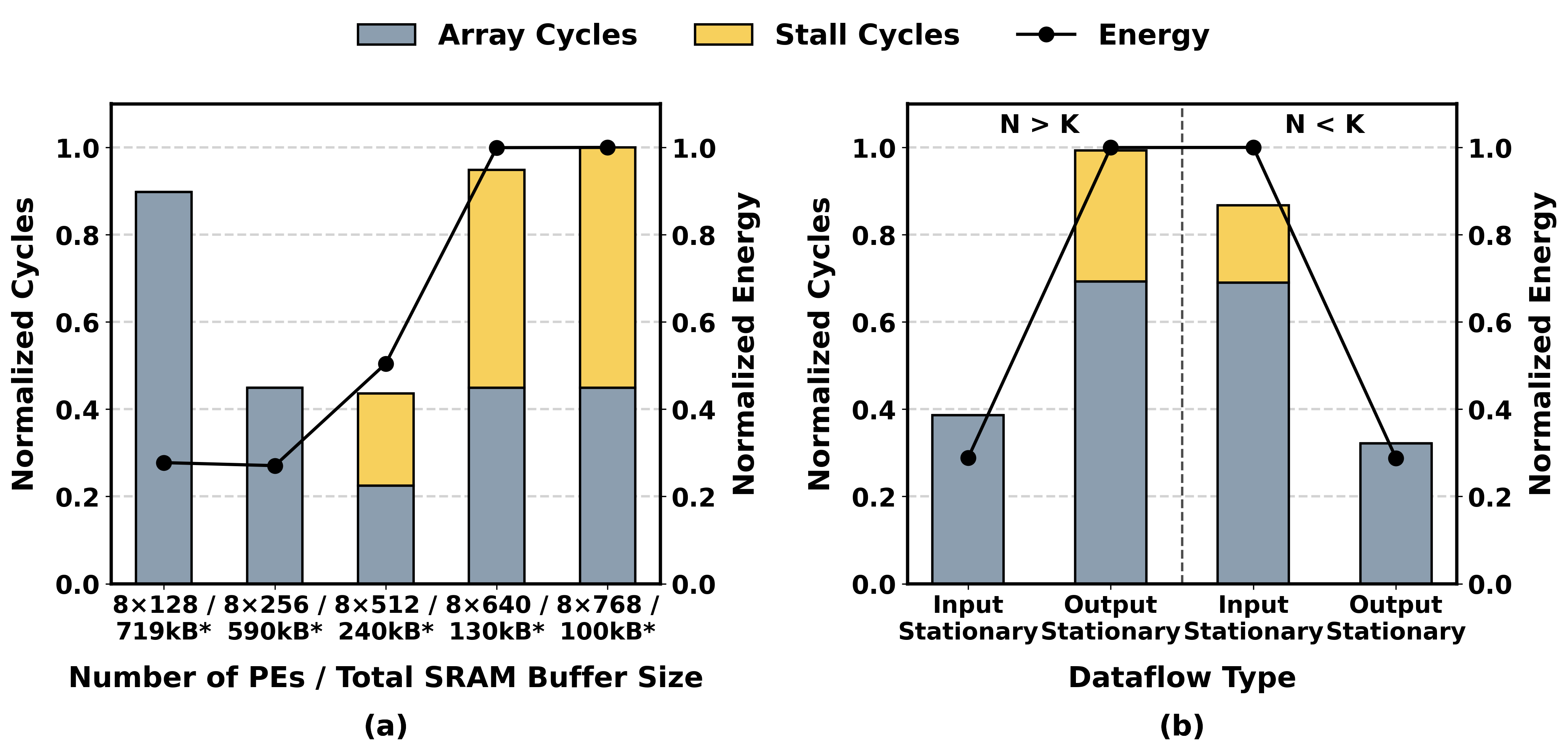
Figure 4: Buffer and dataflow co-design enables maximizing compute density before buffer scarcity harms performance.
SNAKE: Unified Systolic–Vector Microarchitecture
The core contribution, SNAKE, is a specialized, reconfigurable SA co-designed with vector-style execution support, compressing control, buffer, and compute functions for minimal area overhead. The vector core is tightly coupled to the SA—sharing output buffers and repurposing vector buffer area to systolic multi-port buffering when required. Boundary buffers on all four array sides, with port-select logic only provisioned for the weight side, enable shape/dataflow adaptation at fine granularity and minimal area cost. The mapping of small-M operators utilizes a serpentine tiling pattern (SNAKE-like) to maximize logical efficiency (Figure 5 and Figure 6).
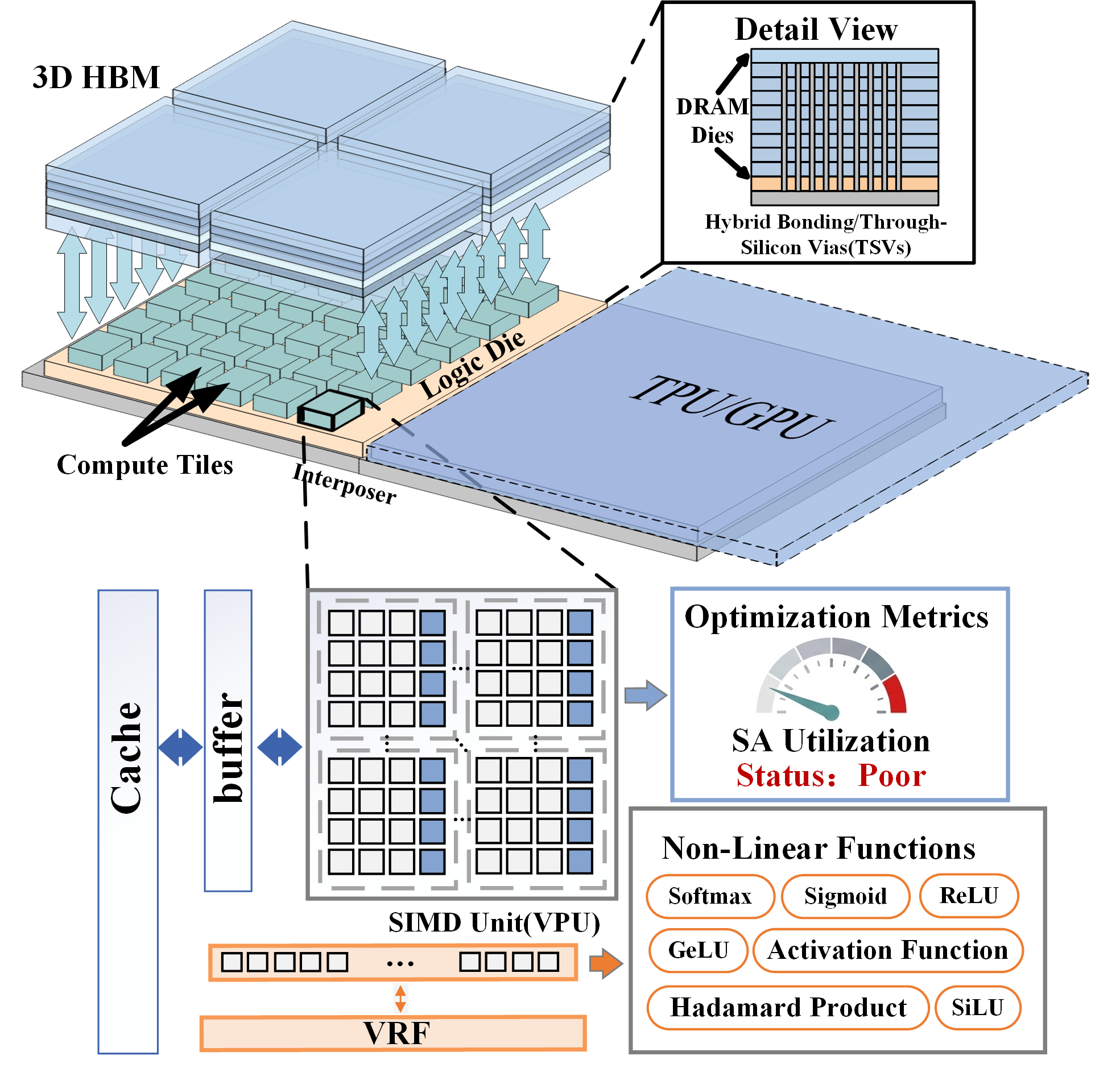
Figure 5: Unified vector and systolic substrate underpins area and flexibility; physical organization supports both execution modes.
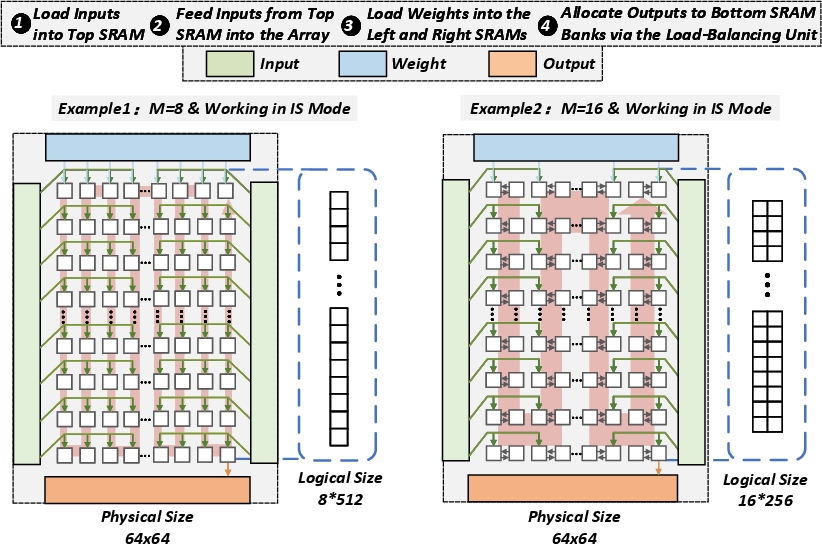
Figure 6: Serpentine logical array remapping for IS dataflow achieves high utilization for small-M operators.
Bandwidth-efficient fetch, direct support for nonlinear/reduction operations, and single-cycle PE mode reconfiguration are supported, with arbitration between systolic and vector units via a banked shared output buffer.
Multi-Core Scheduling: Spatial and Spatio-Temporal Partitioning
Scaling SNAKE requires workload-aware scheduling across multiple Processing Units (PUs). The solution space involves four canonical partitioning strategies (IS-S, IS-ST, OS-S, OS-ST), judiciously assigning dimensional partitioning and dataflow scheduling to different PUs depending on operator shape. Partitioning adapts to both spatial (N, K) and temporal (M) variation, with only lightweight collectives (all-reduce, all-gather) needed for synchronization. Logical remapping enables the same 16 PUs to form either chains or mesh topologies as required (Figure 7).
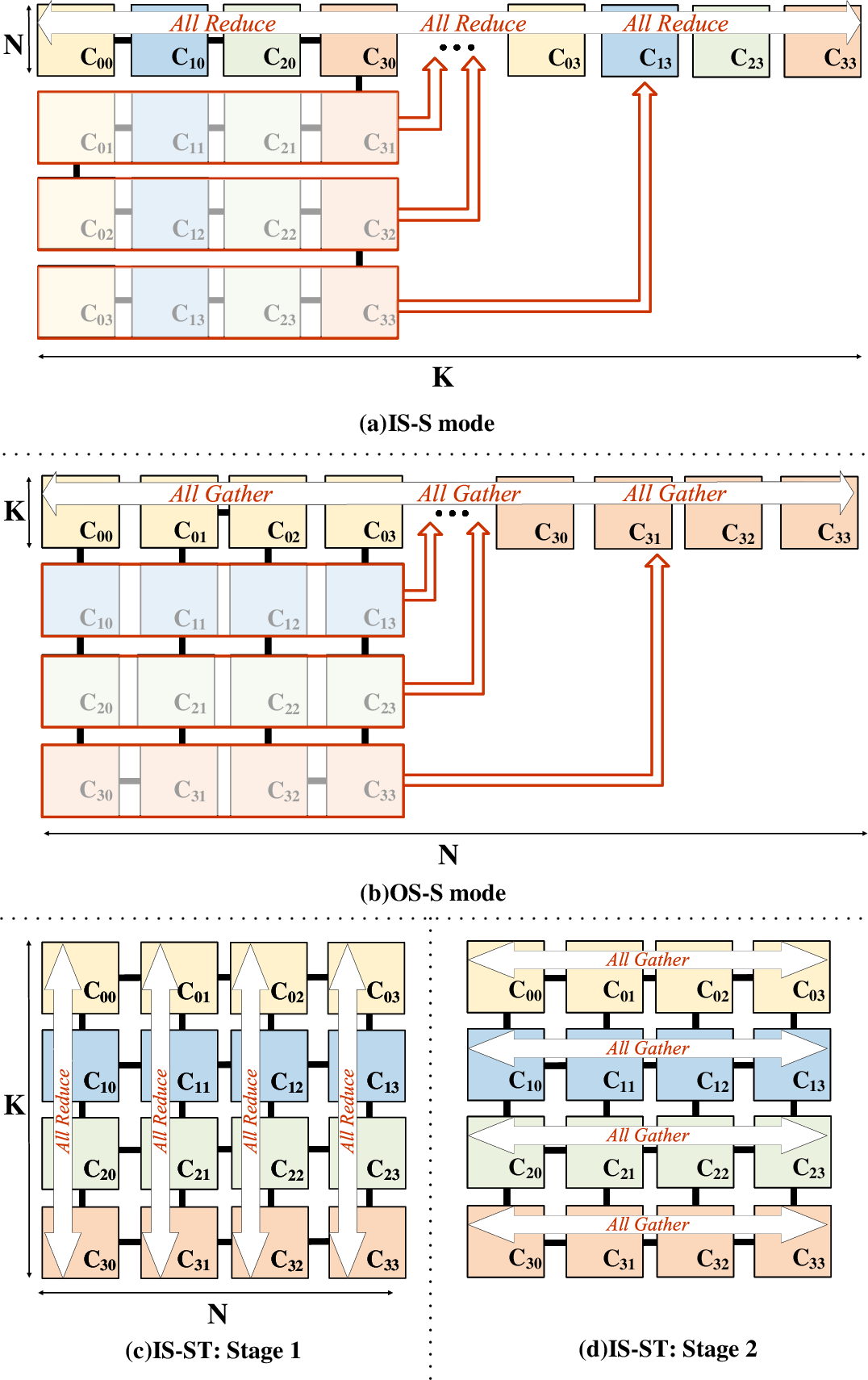
Figure 7: Logical inter-PU partitioning enables both chain and mesh organizational modes, adaptive to operator shapes.
This operator-specific scheduling provides optimal tiling and phase overlap, explicitly handling linear–nonlinear kernel pipelining (e.g., OS, IS implications for MoE layers; Figure 8).
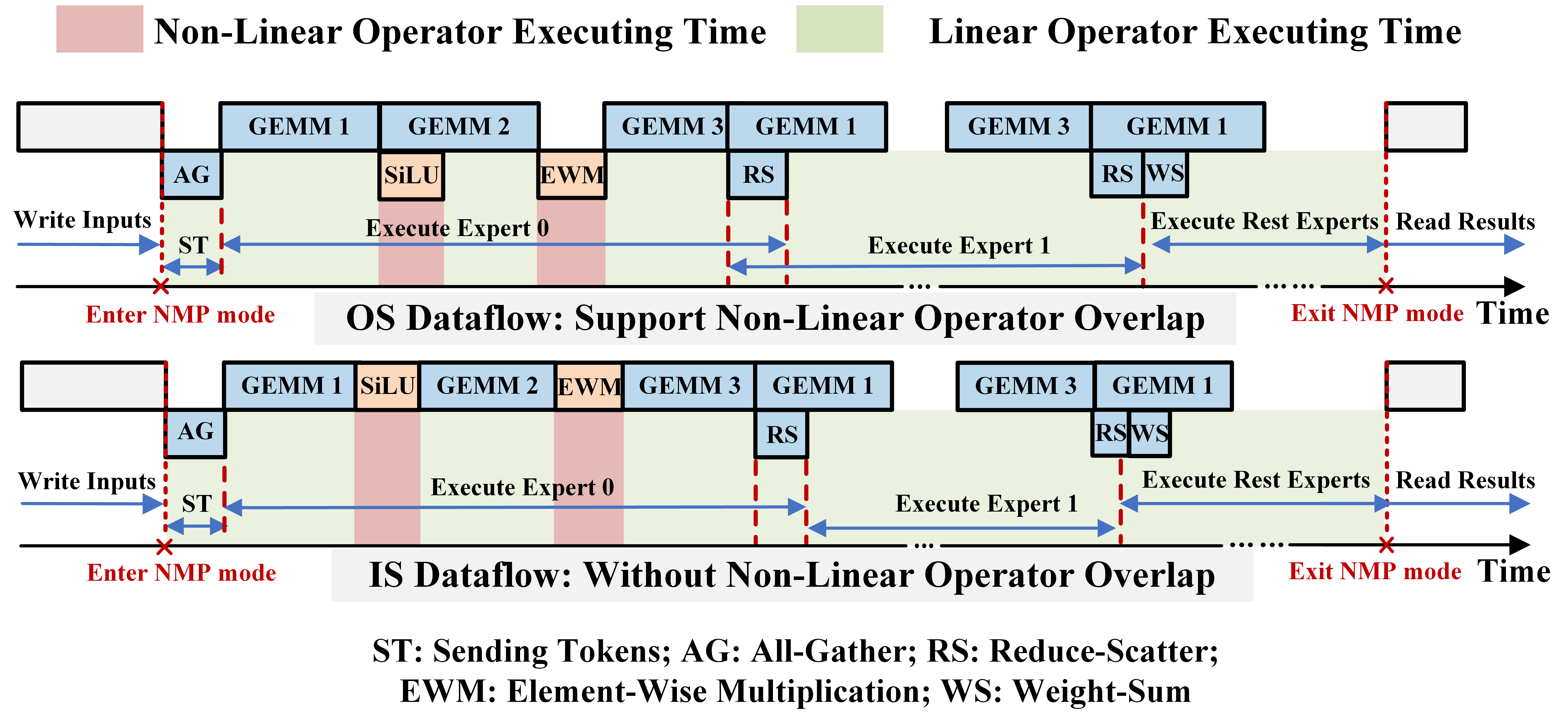
Figure 8: Linear–nonlinear operator overlap evaluated under OS and IS dataflows; critical for MoE decoding efficiency.
Evaluation Results
Area and Power Analysis
The proposed architecture, compared to MAC-Tree and fixed-shape SA baselines, achieves up to 4.00x higher compute-area efficiency (Figure 9). Multi-port buffer overhead for reconfigurability is limited (<6.0% area), and overall buffer area is significantly reduced via co-allocation with vector core resources.
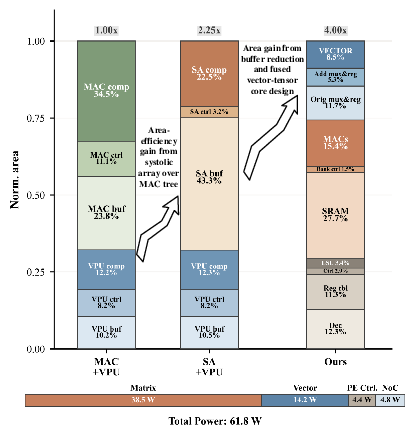
Figure 9: Normalized PU-level area and power breakdown; SNAKE shifts most area to compute, reducing buffer and control overheads.
SNAKE demonstrates substantial gains on decode throughput and energy efficiency: 2.9x speedup and 2.4x higher energy efficiency over MAC-Tree, and >11x decode speedup versus GPU (Figure 10). The reconfigurable SA delivers 2–3x speedup relative to similarly area-constrained fixed-shape SAs, confirming the direct advantage of shape and dataflow adaptivity.
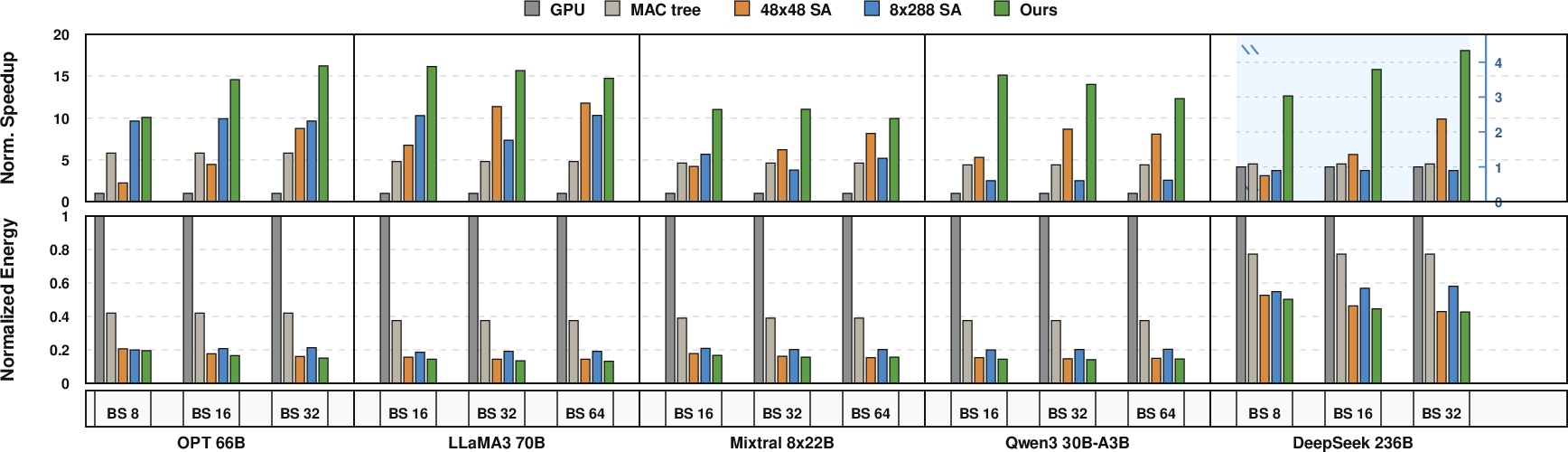
Figure 10: SNAKE achieves superior normalized decode performance and energy efficiency across diverse LLM models.
Latency Under Online Serving
End-to-end and time-between-token latencies are consistently reduced compared to GPU, MAC-Tree, and fixed-shape SA baselines, with particularly strong performance at high request rates due to better resource utilization (Figure 11).
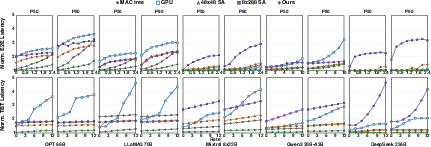
Figure 11: Normalized serving latency highlights robust SNAKE performance under varied request rates.
Multi-PU Partitioning Efficacy
Empirical per-operator scheduling analysis shows significant strategy diversity, especially for MoE models, where per-operator adaptive scheduling yields up to 6.4× lower latency than static partitioning (Figure 12).
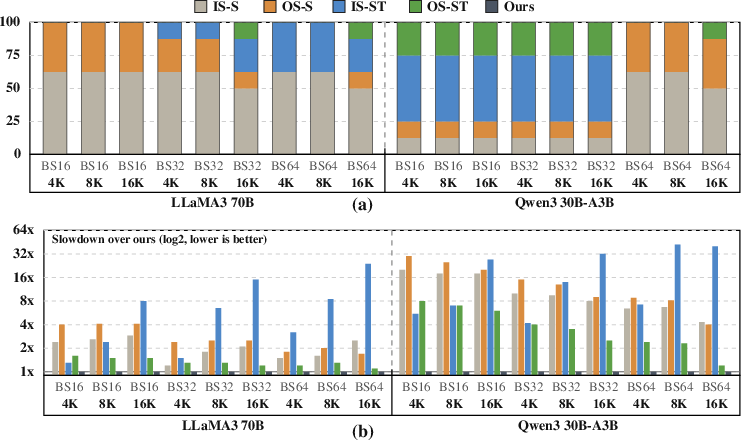
Figure 12: Distribution of scheduling mode choice and fixed-mode slowdown underscores the need for adaptive multi-PU mapping.
Array Shape and Buffer Trade-offs
Batch size and operator diversity induce dynamic preferred array shapes, with buffer provisioning dictating achievable utilization and stall rates. Tuning shape and memory allocation is essential for robustness across diverse workloads (Figure 13).
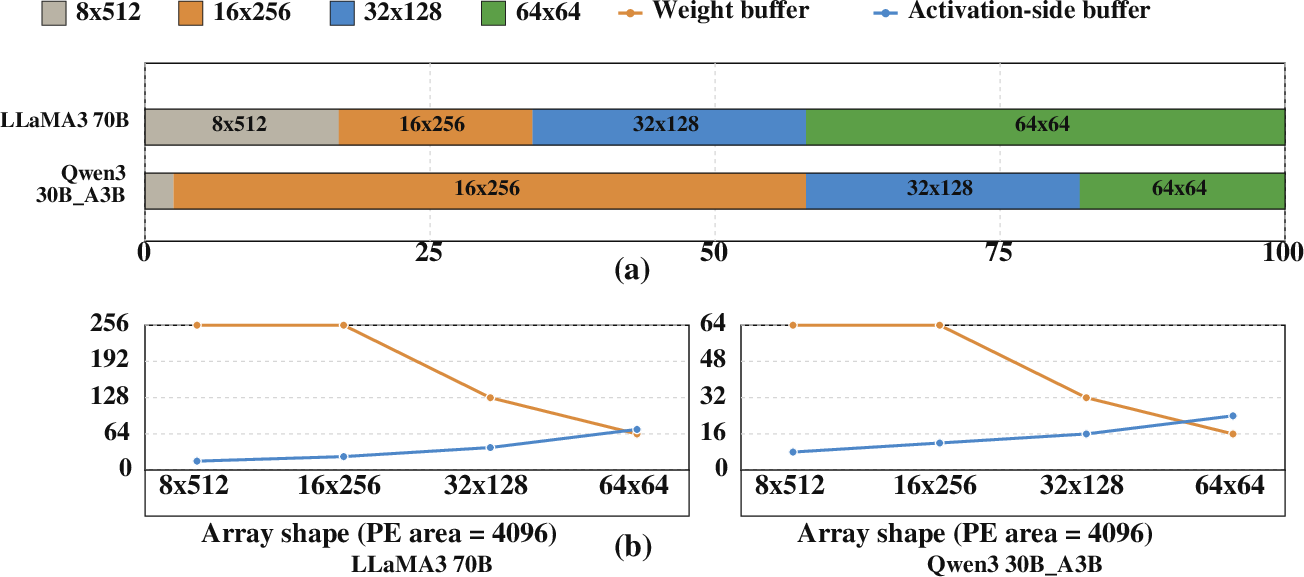
Figure 13: (a) Model-dependent logical array shape demand; (b) buffer size requirements across array configurations.
Conclusion
This work demonstrates that high-performance, energy-efficient LLM decode on 3D-stacked NMP is fundamentally constrained by compute substrate density and workload adaptivity rather than memory bandwidth. By co-designing a reconfigurable, area-optimized systolic-vector substrate (SNAKE) and integrating operator-specific, multi-core scheduling, the architecture uses increased local bandwidth to dramatically elevate decode throughput and responsiveness. Theoretical advances in microarchitecture coalesced with practical, workload-aware multi-core scheduling yield net gains exceeding 2.9x speedup over state-of-the-art MAC-Tree NMP designs.
These findings suggest that practical 3D NMP systems for serving contemporary LLMs should focus on maximizing compute density, aggressive reconfiguration for operator variance, and adaptivity in core scheduling. Future directions include extending such co-design to accommodate evolving LLM operator mixes (e.g., more complex expert hierarchies in MoE models) and dynamic on-device composition of inference pipelines.