- The paper establishes a unified abstraction that decomposes accelerator platforms into blocks, accelerators, nodes, and systems for systematic evaluation.
- It quantifies key trade-offs in latency, throughput, energy, and area, showing that no single platform is optimal across all workloads.
- The study demonstrates how communication overhead and software stack maturity significantly impact real-world LLM inference performance.
Quantitative Analysis of AI Accelerator Competition: xPU-athalon
Introduction
The proliferation of large-scale AI workloads, notably LLM inference, has catalyzed significant architectural diversification in accelerator hardware. "The xPU-athalon: Quantifying the Competition of AI Acceleration" (2604.10852) provides a disciplined, quantitative characterization of current accelerator platforms, including Cerebras CS-3, SambaNova SN-40, Groq LPU, Gaudi, TPUv5e, NVIDIA A100/H100, and AMD MI-300X, highlighting their respective design trade-offs in latency, throughput, energy, power, and programmability. The study uniquely couples operator-level microbenchmarks with end-to-end workload profiling, emphasizing the multidimensionality of optimality in AI hardware selection.
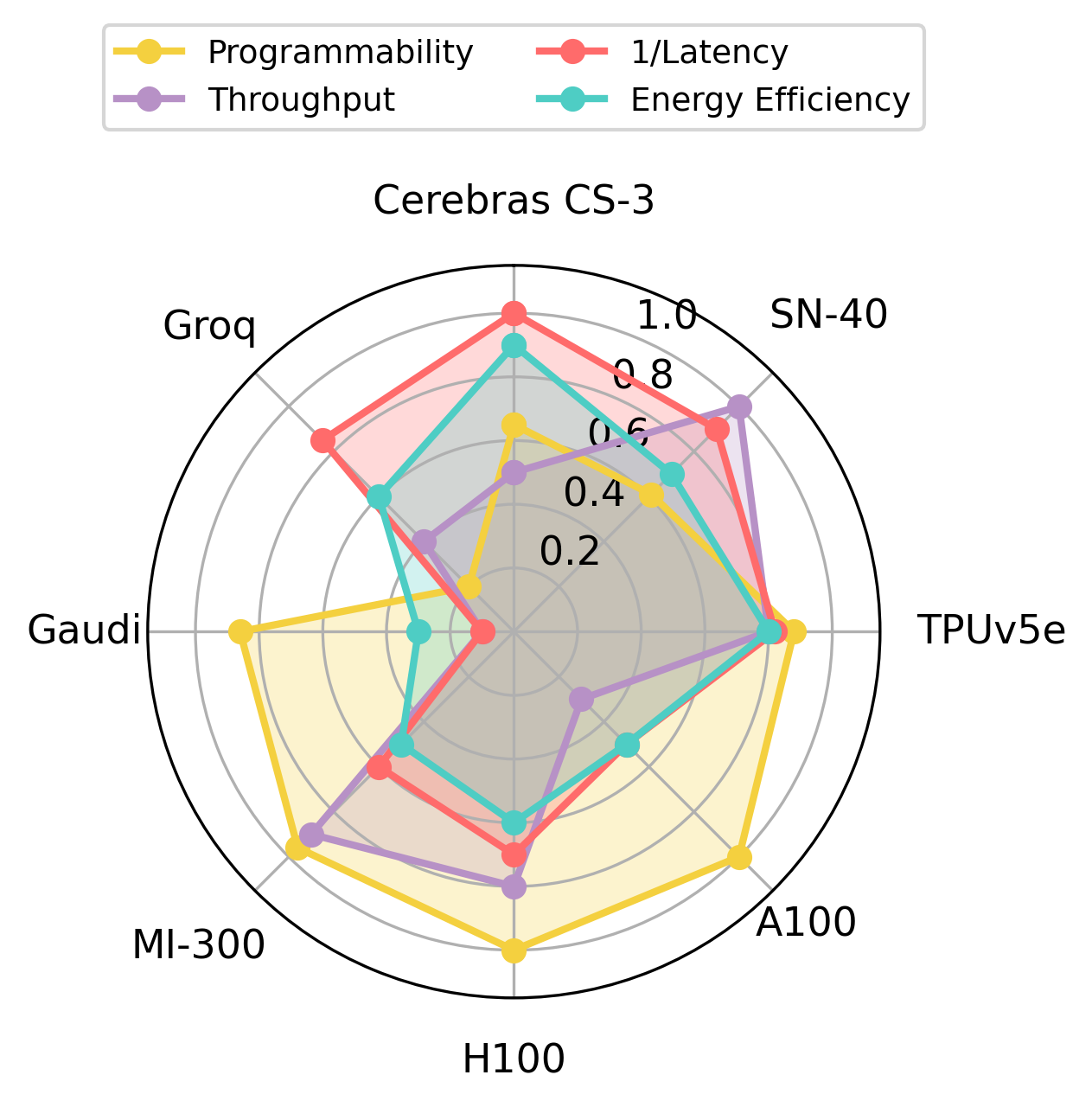
Figure 1: Overview of AI accelerator design space, revealing the nuanced interplay between latency, energy-efficiency, and programmability among state-of-the-art platforms.
Architectural Landscape and Abstraction
The analysis establishes a unified abstraction for accelerator comparison: platforms are decomposed into blocks (compute core + private SRAM), which aggregate into accelerators (with shared on-chip SRAM and external DRAM), scale-out into nodes, and connect into full systems. Distinct architectures are mapped onto this abstraction to enable systematic evaluation.
- Cerebras CS-3: Wafer-scale integration, emphasizing abundant on-chip SRAM and minimized inter-chip communication.
- SambaNova SN-40: Coarse-Grained Reconfigurable Array (CGRA) realized as an RDU, supporting flexible kernel fusion and varying memory tiering.
- Groq LPU: Fully SRAM-based, deterministic architecture without a traditional memory hierarchy.
- Gaudi: Multiple fully programmable VLIW TPCs optimized for matrix and tensor ops.
- TPUv5e: Custom Google hardware, HBM-centric with strong scale-out focus.
- NVIDIA/AMD GPUs: General-purpose, DRAM-based, highly programmable, and established software stack.
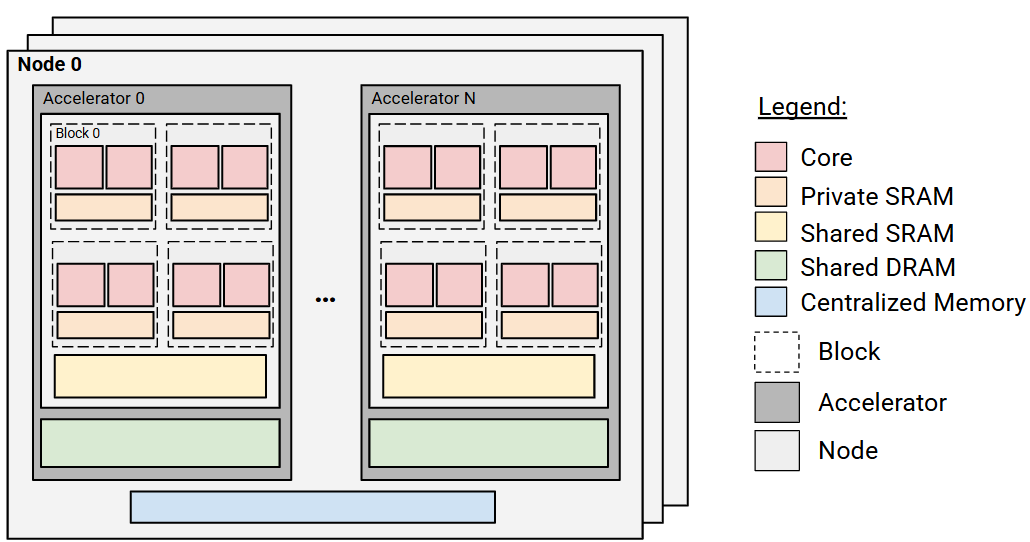
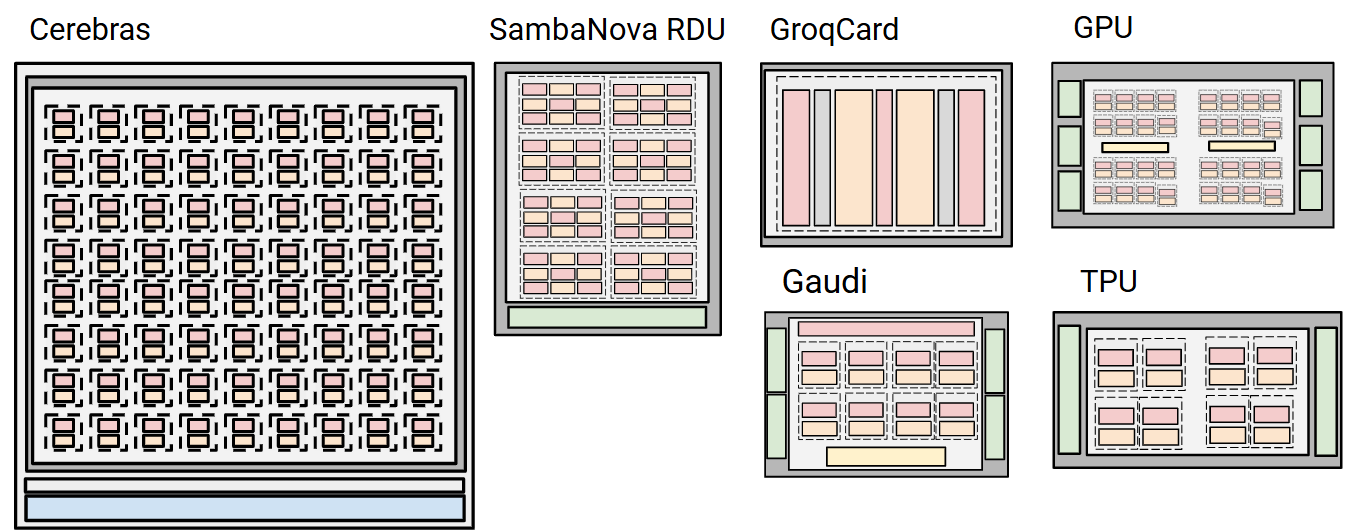
Figure 2: Generalized abstraction mapping each platform to compute/memory block layouts.
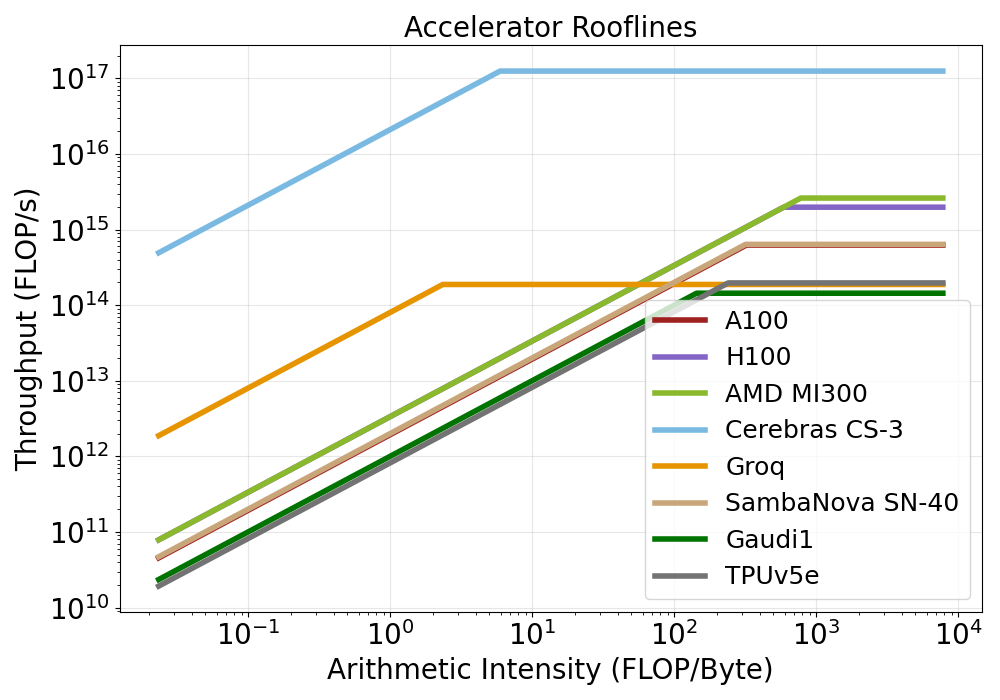
Roofline, Power, and Area Analysis
Empirical throughput (FLOP/s), power-normalized and area-normalized comparisons elucidate how architectural choices impact achievable LLM inference performance.
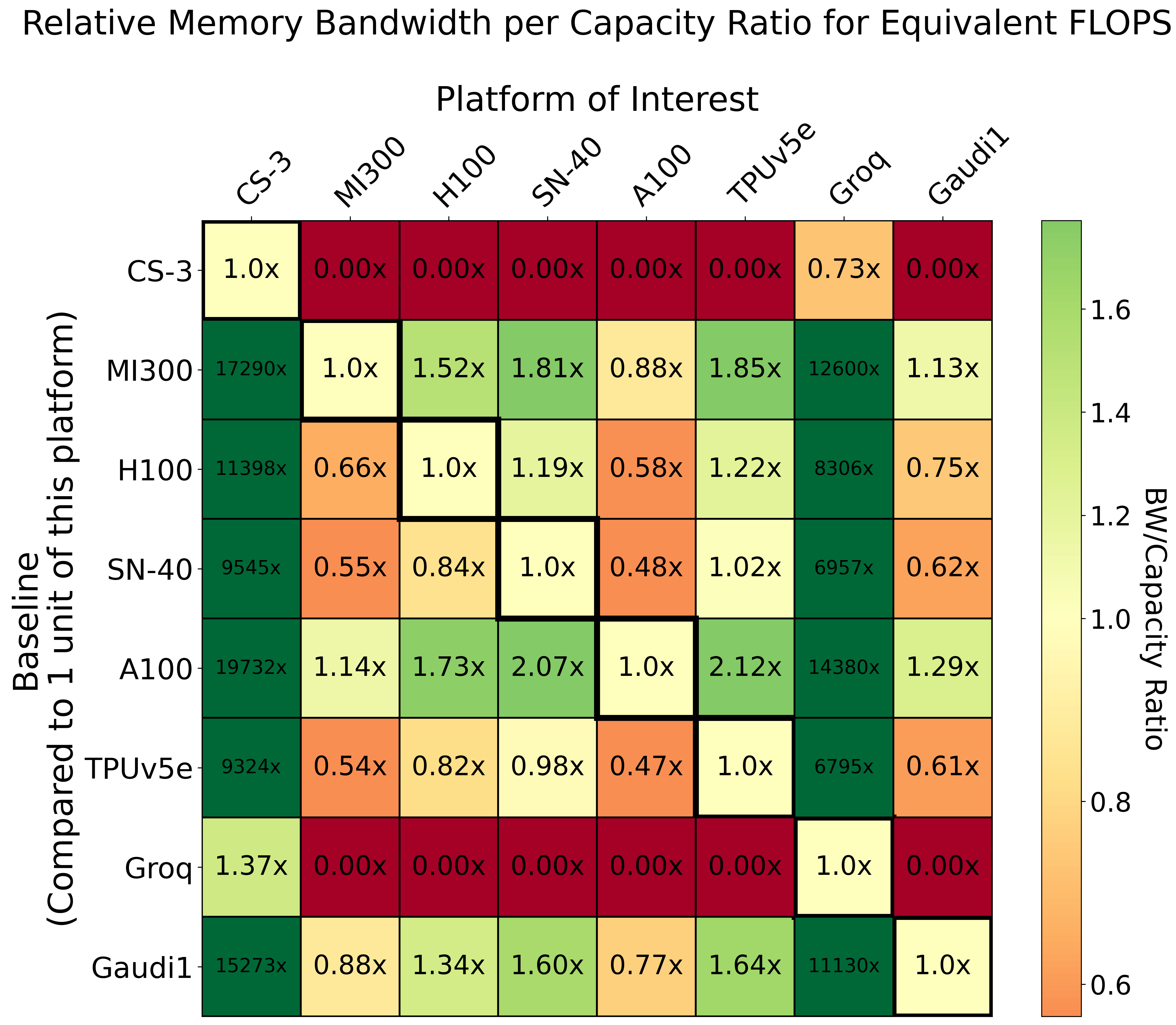
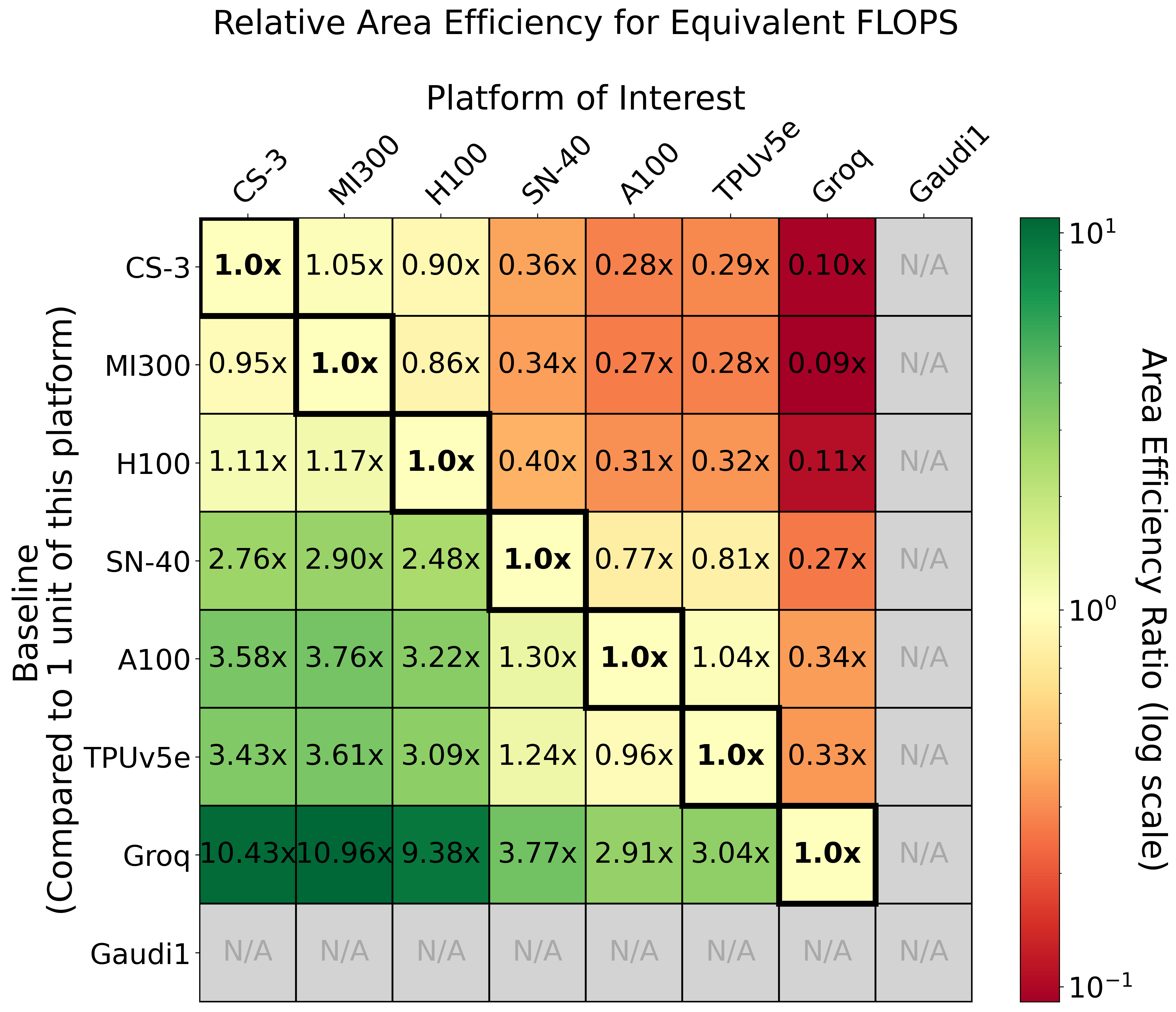
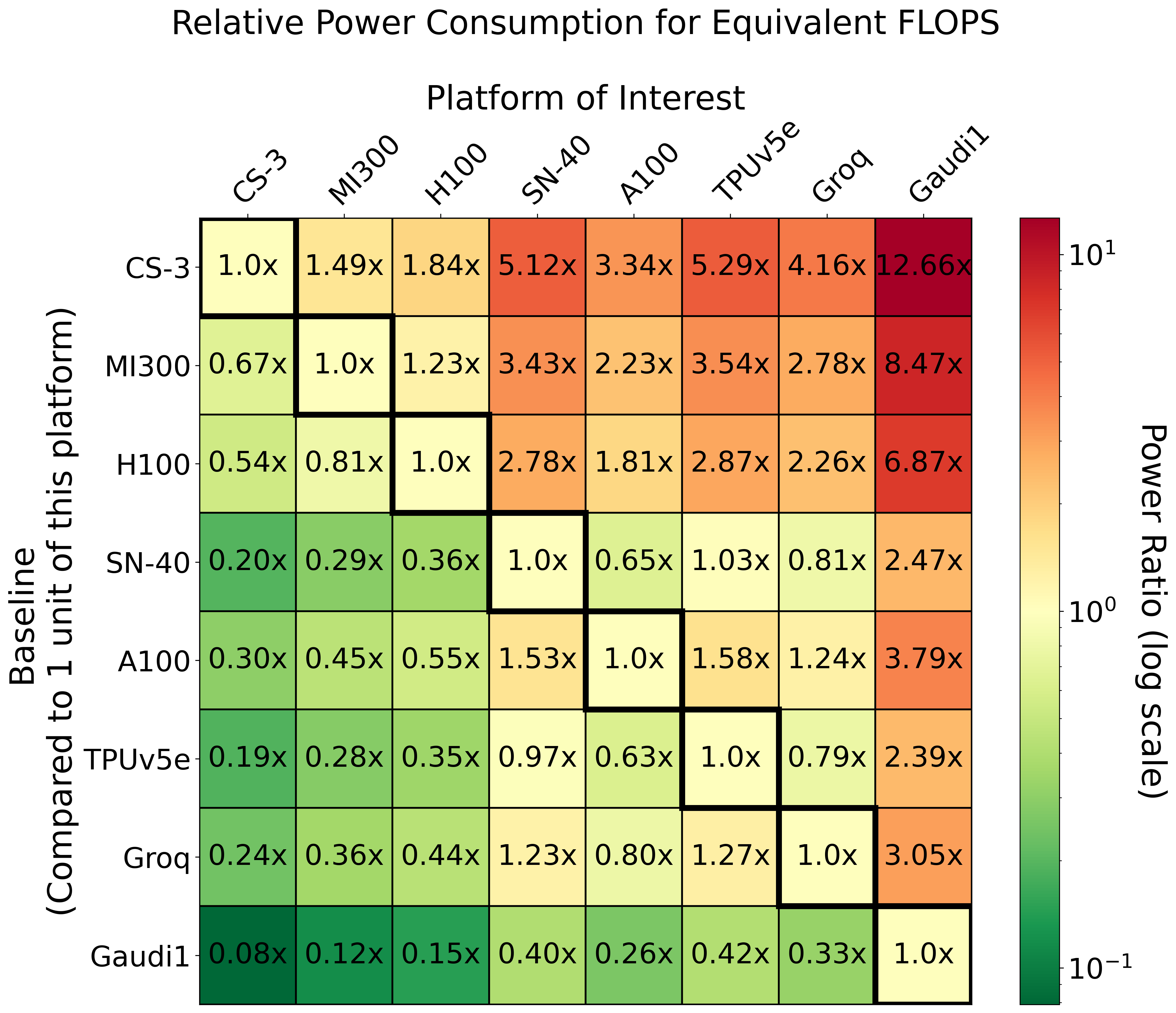
Figure 4: Relative power consumption per equivalent FLOPS across platforms, emphasizing heterogeneous power curves.
LLM Inference: Trade-Offs and Distributed Implications
LLM inference is dissected into prefill (compute-bound) and decode (memory bandwidth-bound) phases. Analysis shows that actual hardware performance hinges on the interplay of batch size, sequence length, model parameters, and—critically—scale-out communication overhead.
- Optimality is Instance-Specific: No universal "best" accelerator exists; the latency/energy Pareto frontier shifts as batch size and sequence length vary. For Llama-3.1-70B at low batch size, Cerebras is optimal, but as throughput requirement grows, more general-purpose or highly optimized throughput platforms (SambaNova, H100, MI-300, TPU) dominate.
- Communication Overheads: Zero-latency scale-out is not achievable in practice—platforms like Groq, which are optimal under isolated (single chip) assumptions, are disadvantaged in distributed settings compared to wafer-scale or tightly integrated nodes.
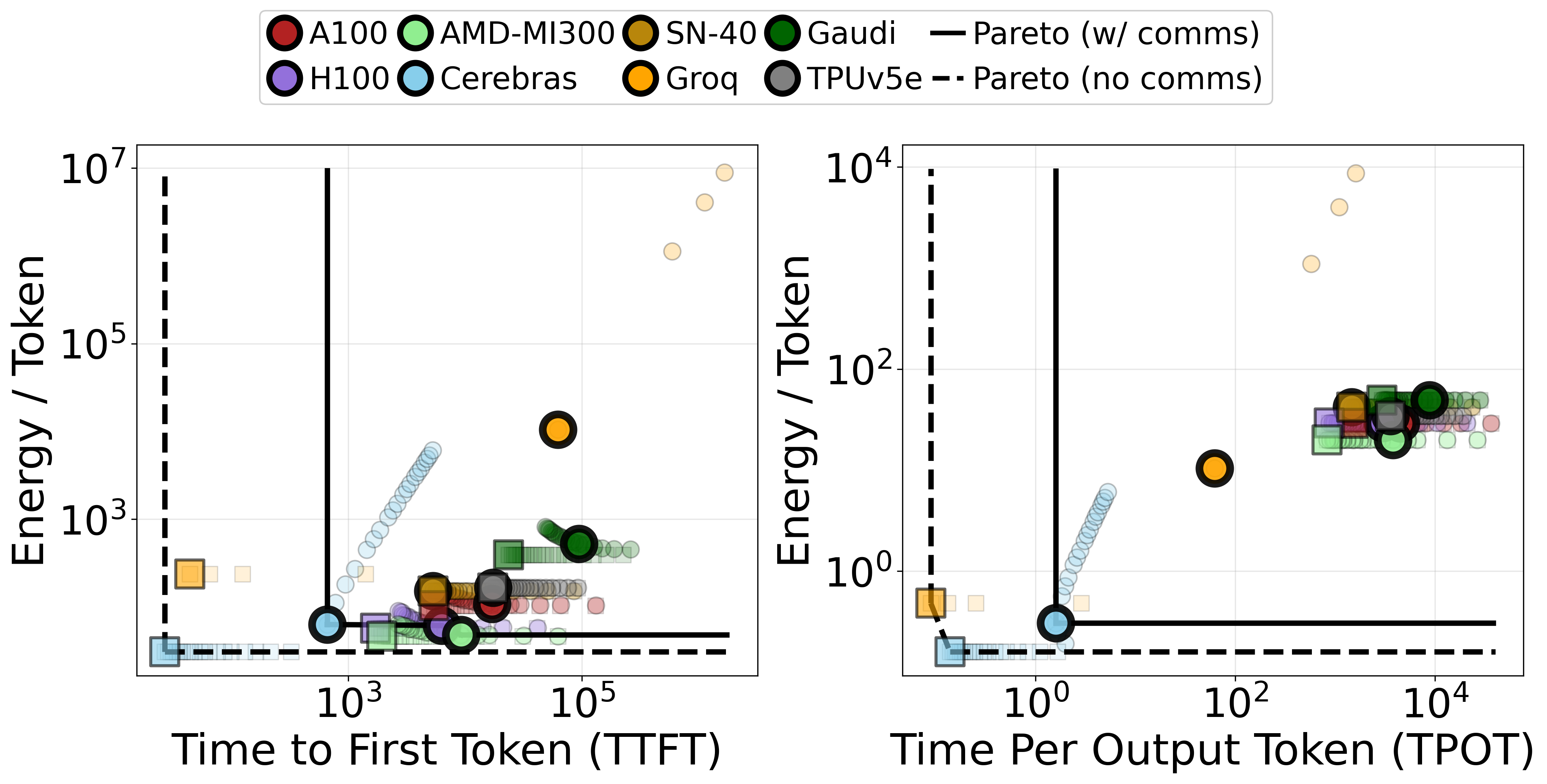
Figure 5: Pareto curves: Observed dominance reversal when including/excluding communication cost during distributed LLM inference.
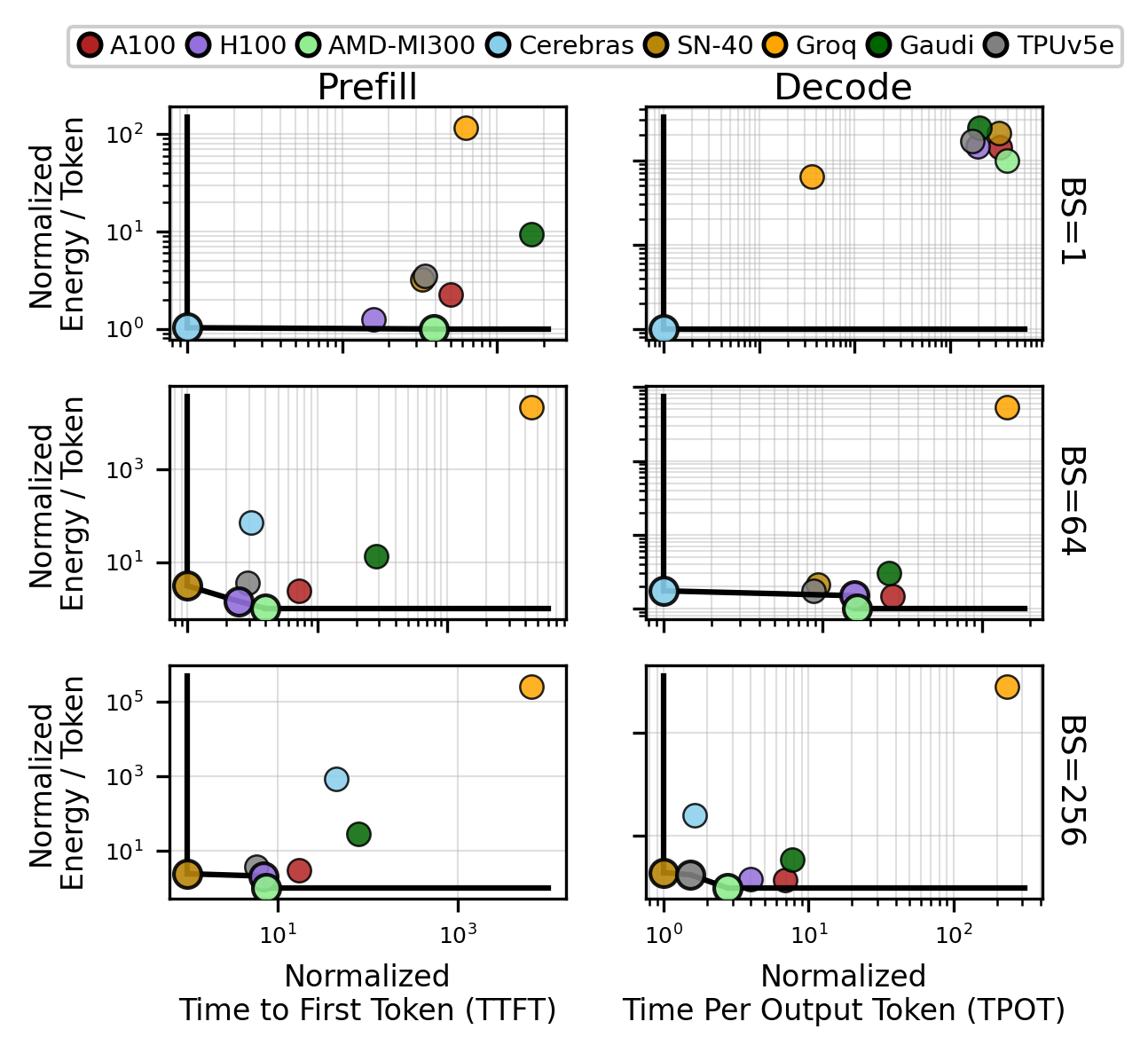
Figure 6: Batch size sweep for Llama-3.1-70B demonstrates shifting Pareto optimality among platforms as workload parameters change.
Empirical Results: Latency, Power, and Primitive Benchmarks
Physical measurement campaigns collect end-to-end as well as operator-level results.
- Low-Batch Inference: Cerebras achieves lowest per-token latency for Llama-3.1-8B (22.89% of H100), with Groq and SN-40 also outperforming H100 at small scale.
- Power Efficiency: TDP-normalized profiles show Cerebras consumes 100% of TDP in both prefill/decode, while NVIDIA GPUs and Gaudi are lower (45-60% at decode). Idle power is 10-60% higher for specialized accelerators, shifting the utilization-efficiency paradigm.
- Primitive Latency: Groq achieves extreme speedup over H100—up to 300× on rsqrt. However, Groq’s high static and operational power draw yields greater energy use per op for certain primitives.
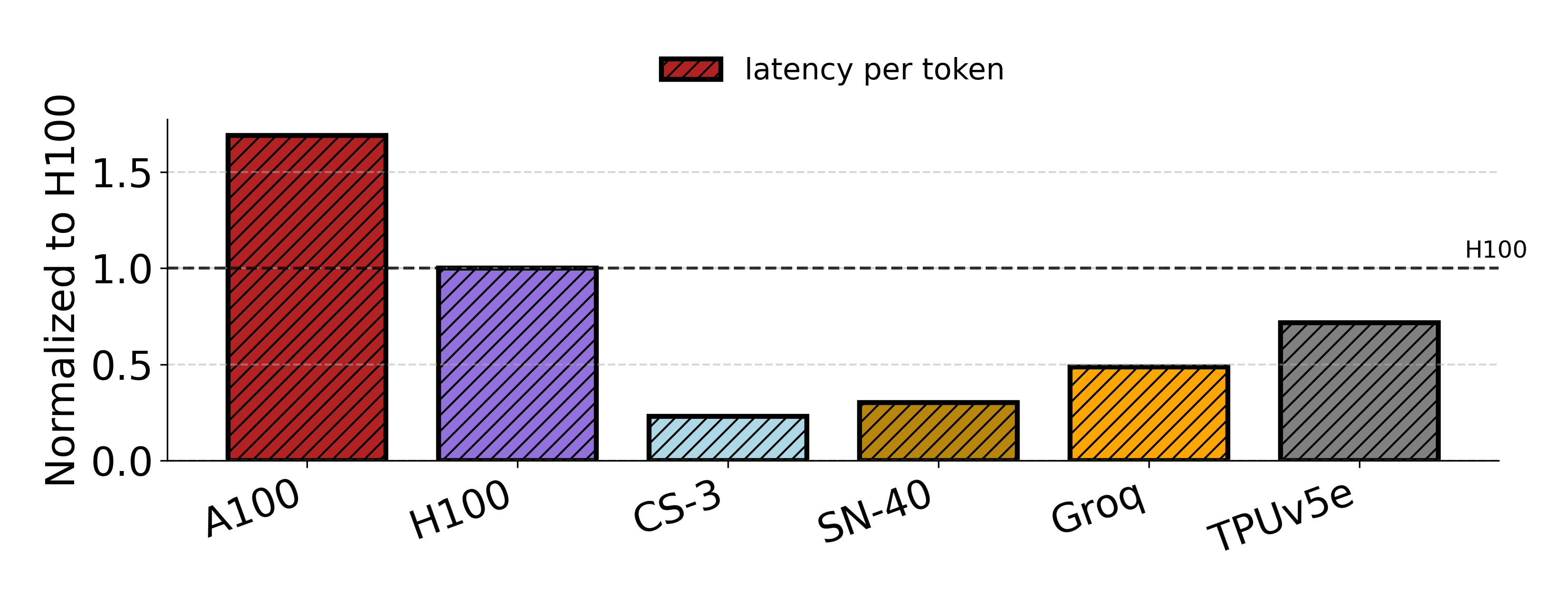
Figure 7: Cerebras achieves leading latency/token on Llama-3.1-8B under low batch.
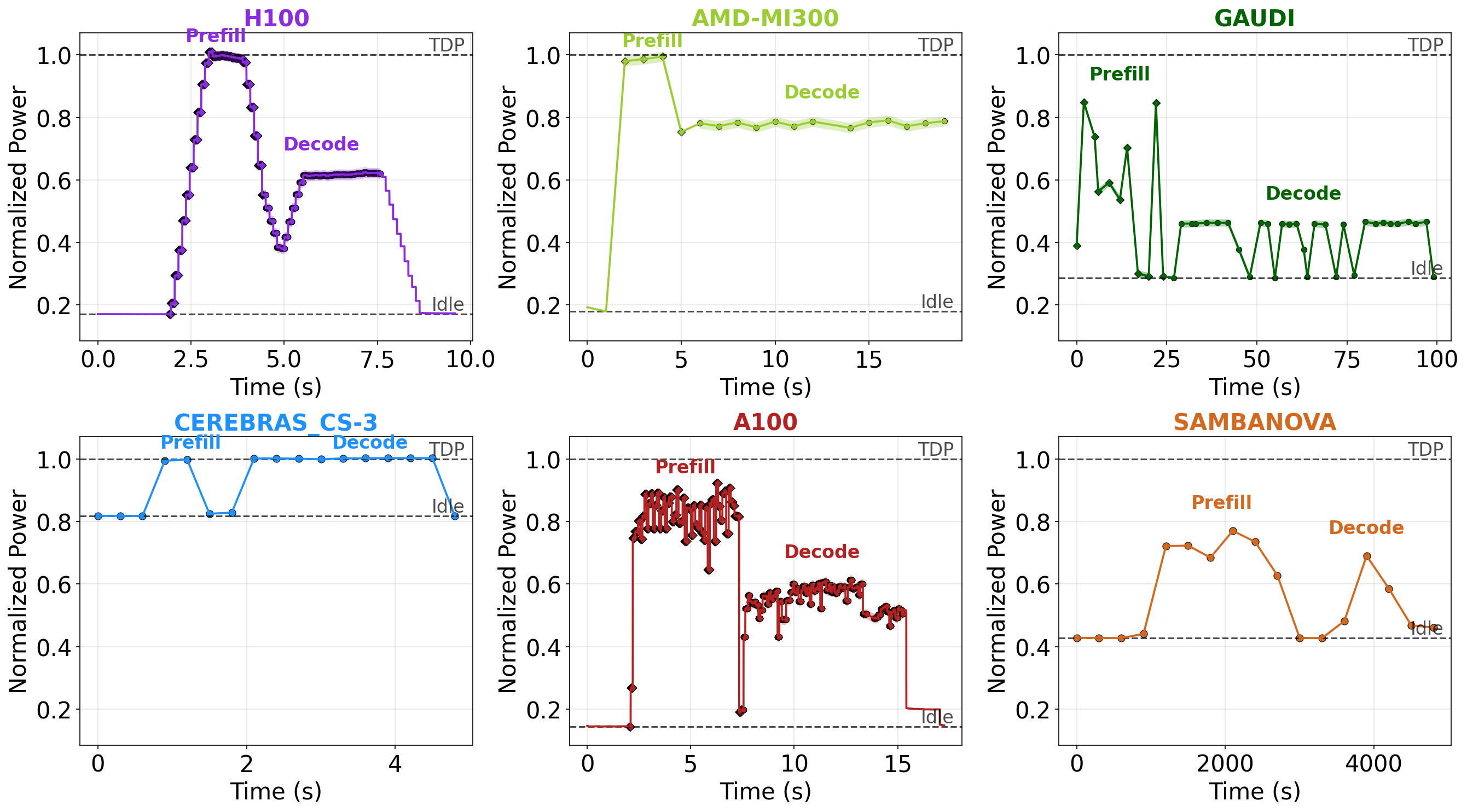
Figure 8: Power traces for prefill and decode—Cerebras and SambaNova maintain high util, NVIDIA and Gaudi lower at decode.
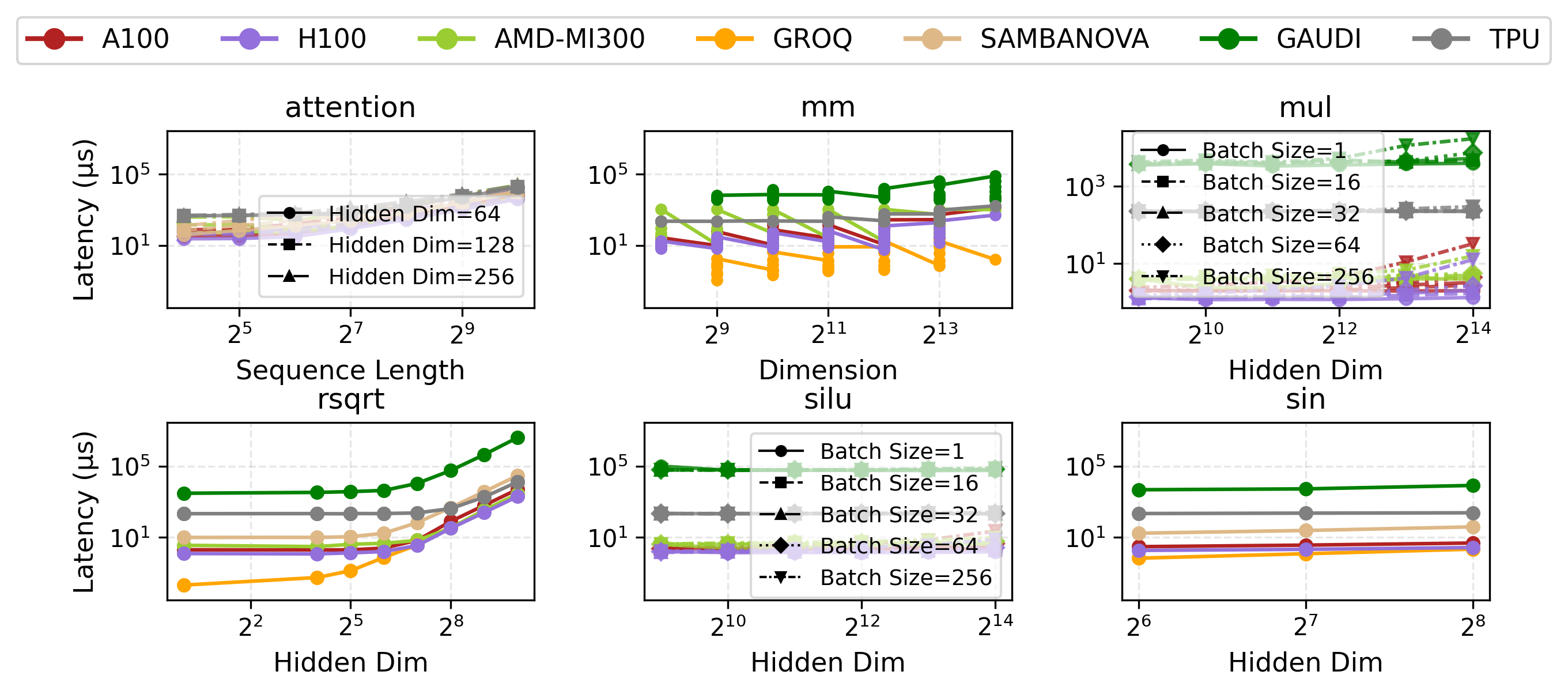
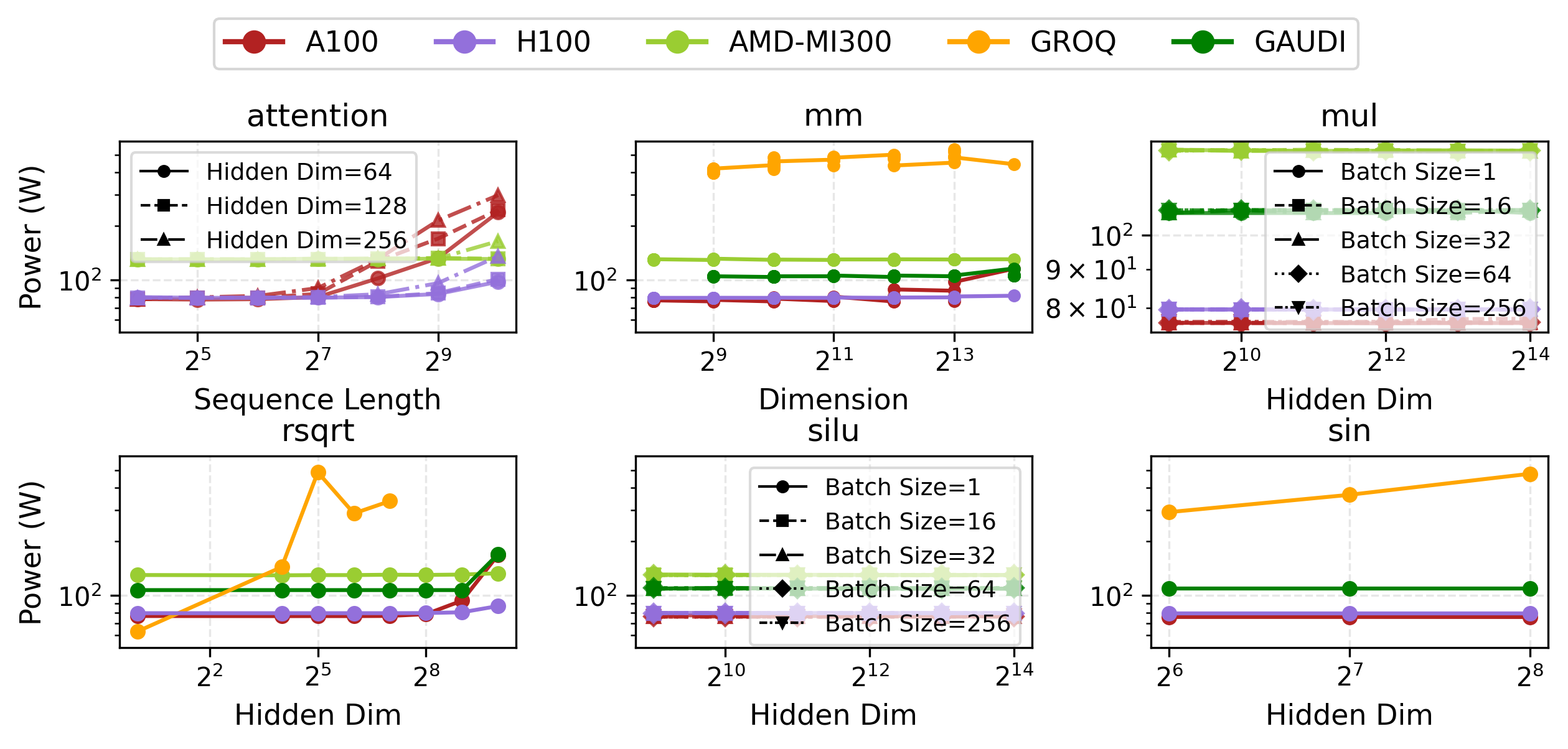
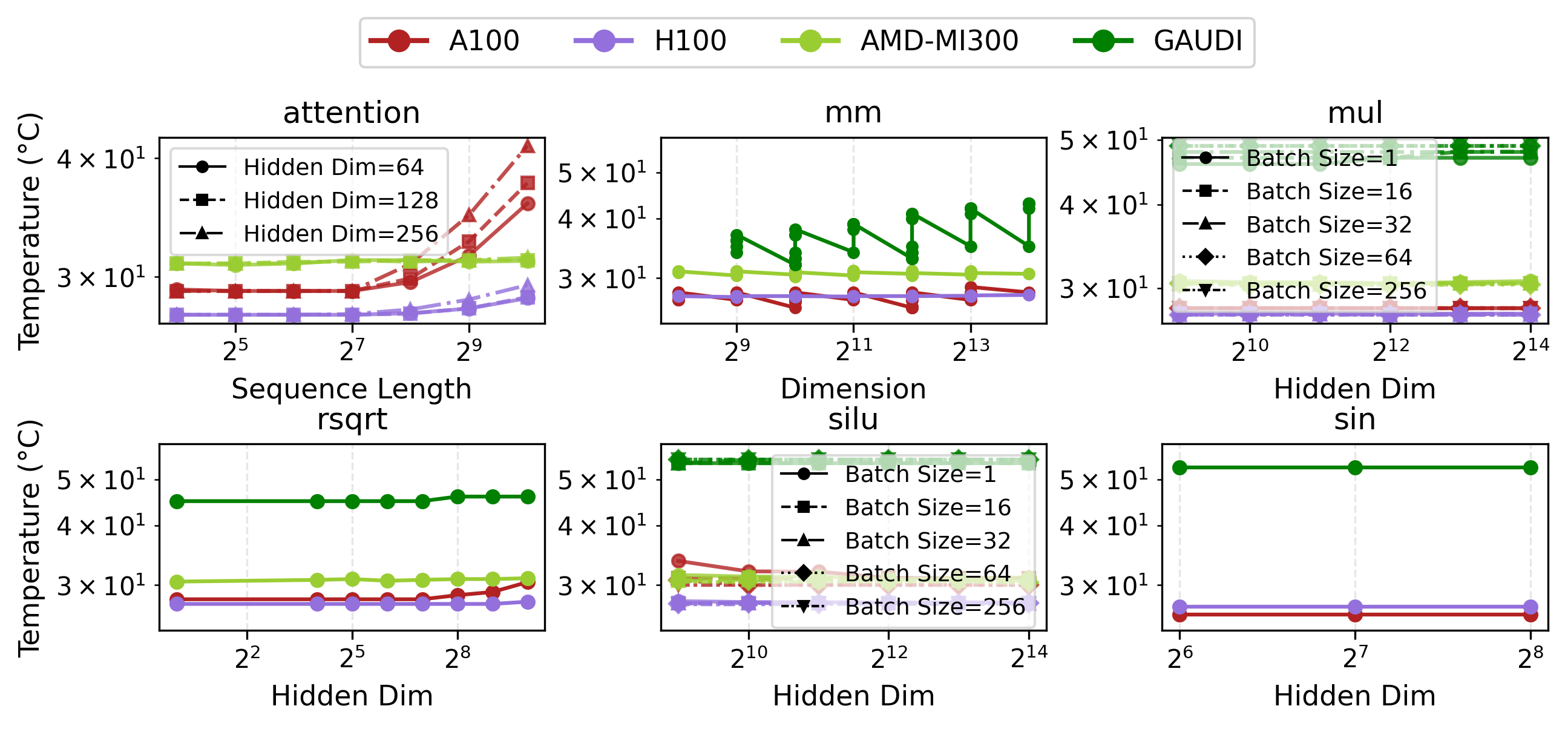
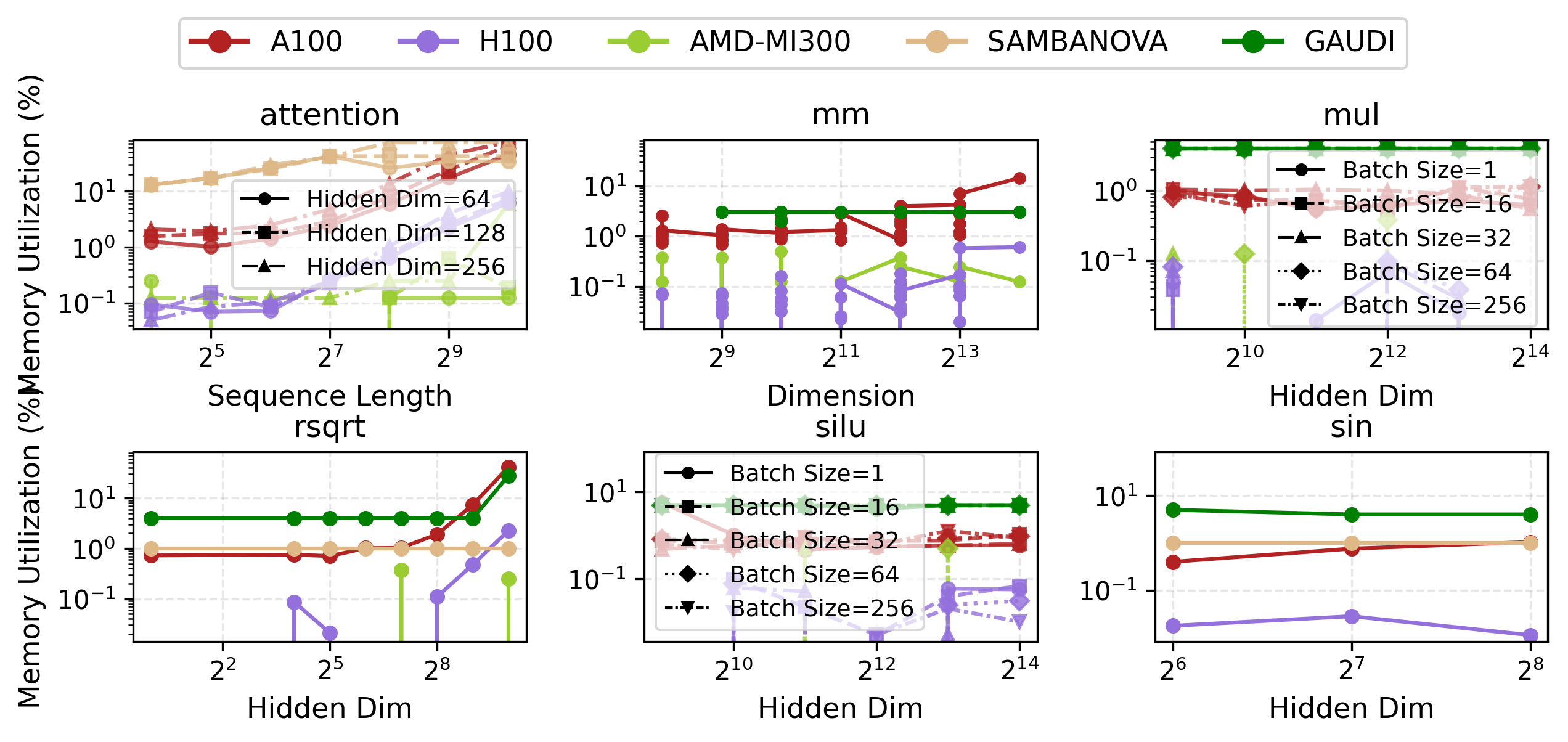
Figure 9: Groq’s small-scale primitive latency is orders of magnitude better than H100 for selected operations.
Communication Energy and Silicon Domain
- On-Wafer vs Off-Chip: CS-3’s monolithic silicon minimizes interconnect energy—CS-3 can achieve up to 74,433× lower energy-per-byte for on-wafer data transfer compared to H100 clusters.
- Inter-Accelerator: Groq’s Interconnect is far more efficient than NVLink but still lags the monolithic wafer, as observed in J/byte scaling with distance.
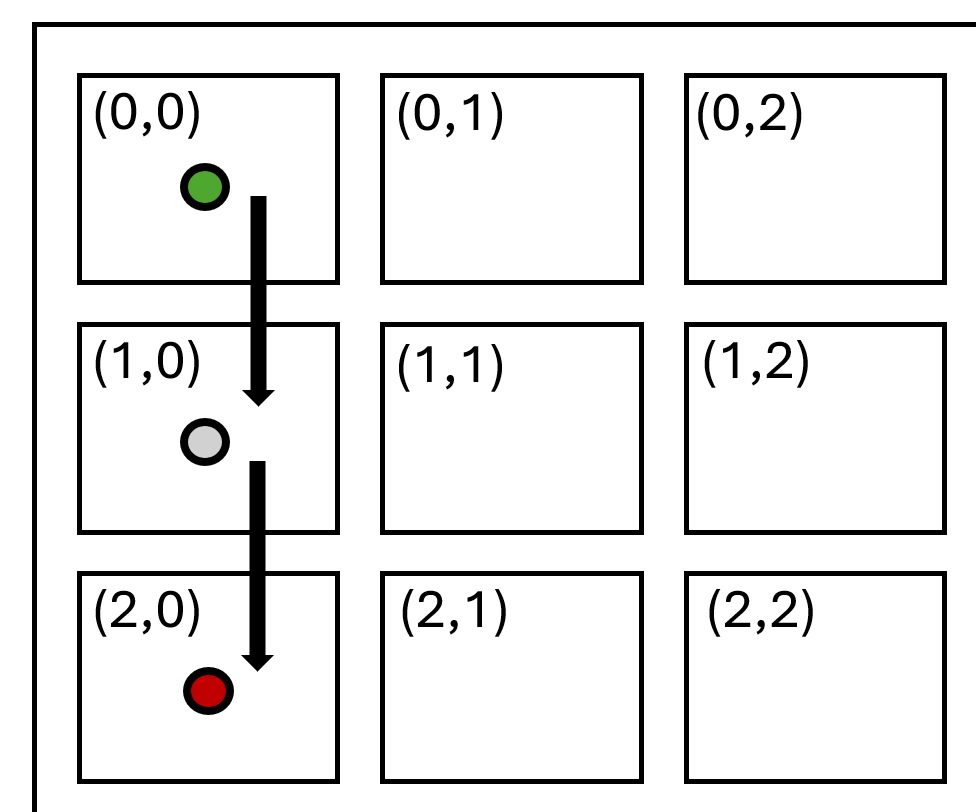
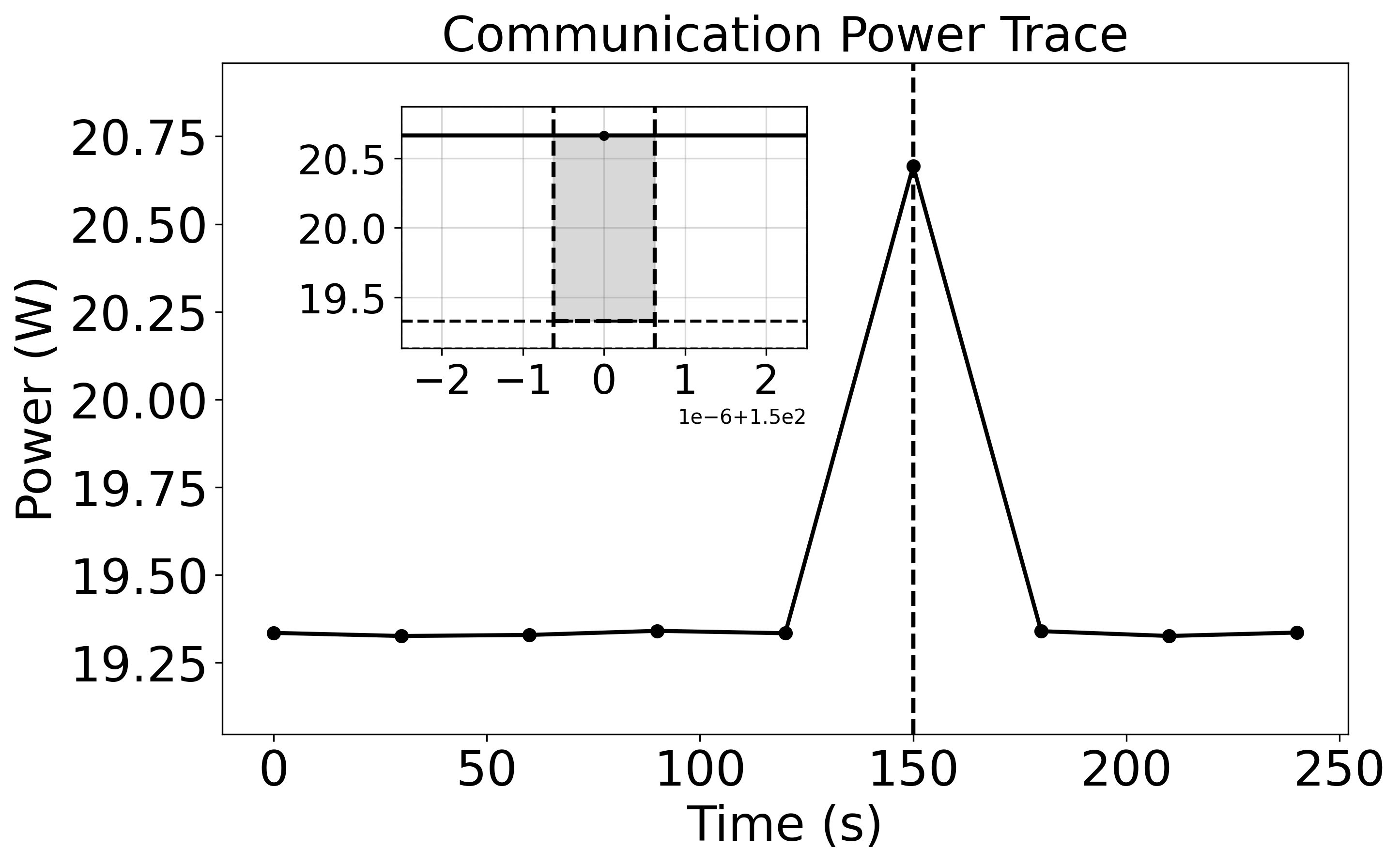
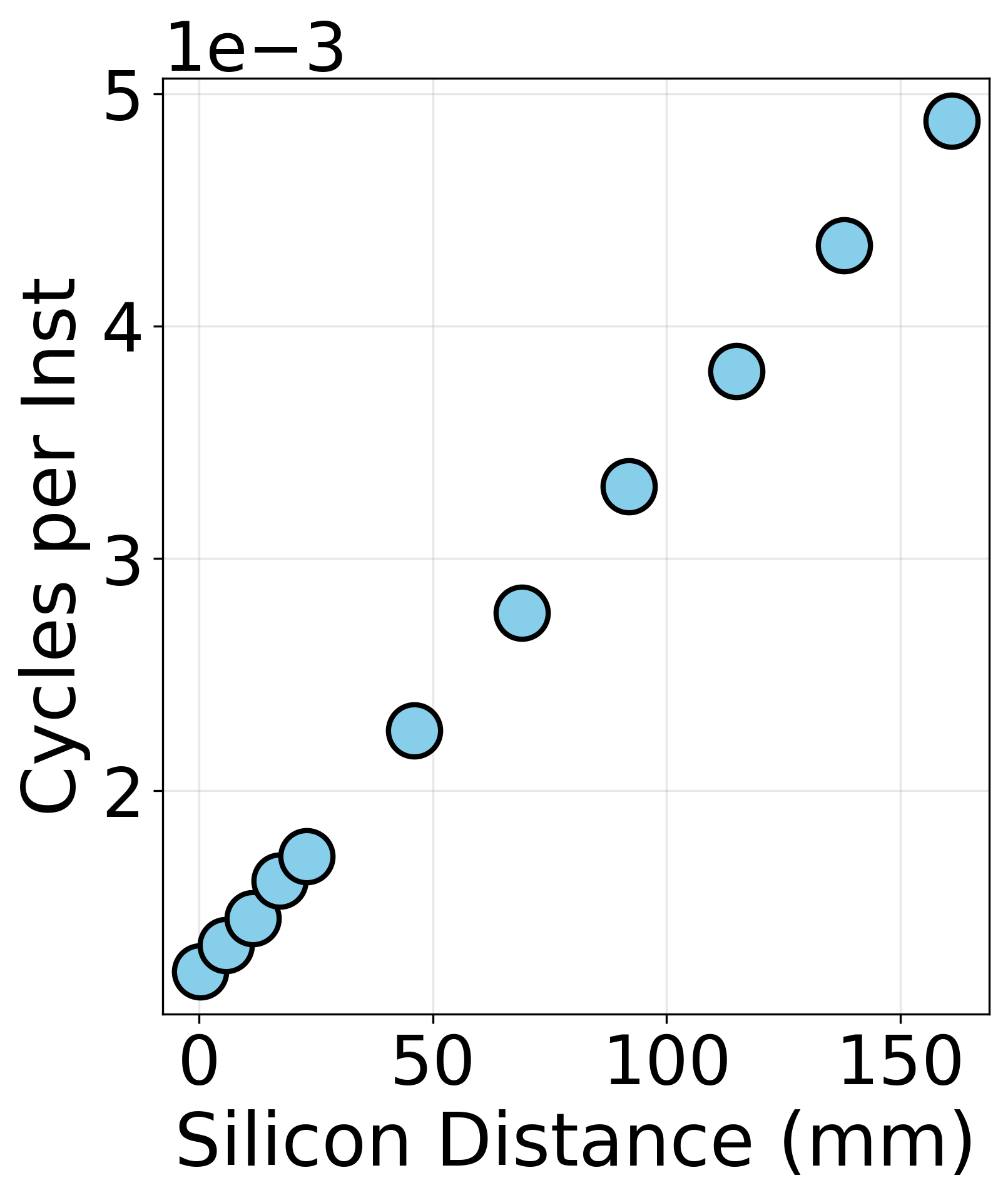
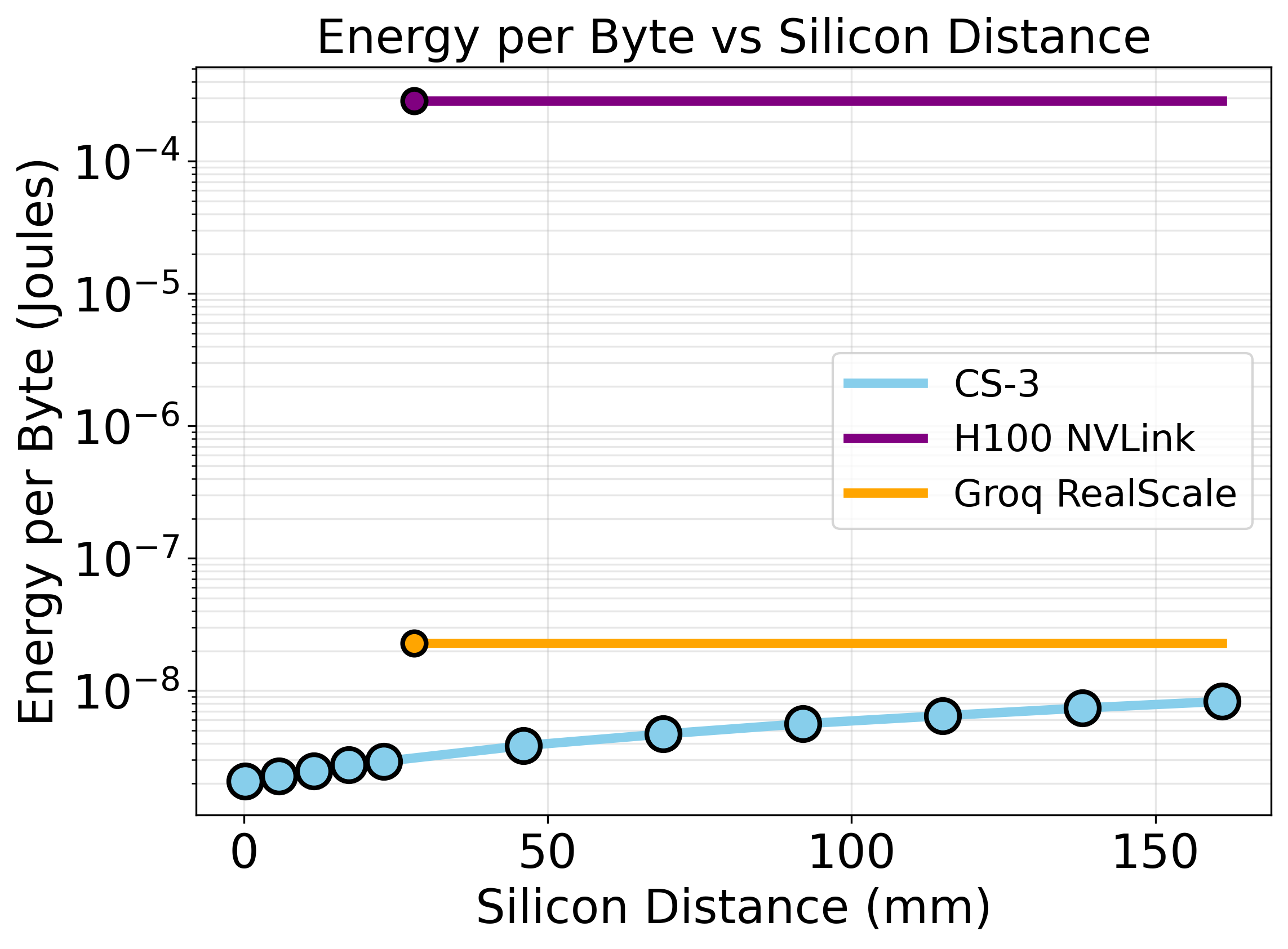
Figure 10: CS-3 intra-wafer communication benchmark schematic and cycle scaling.
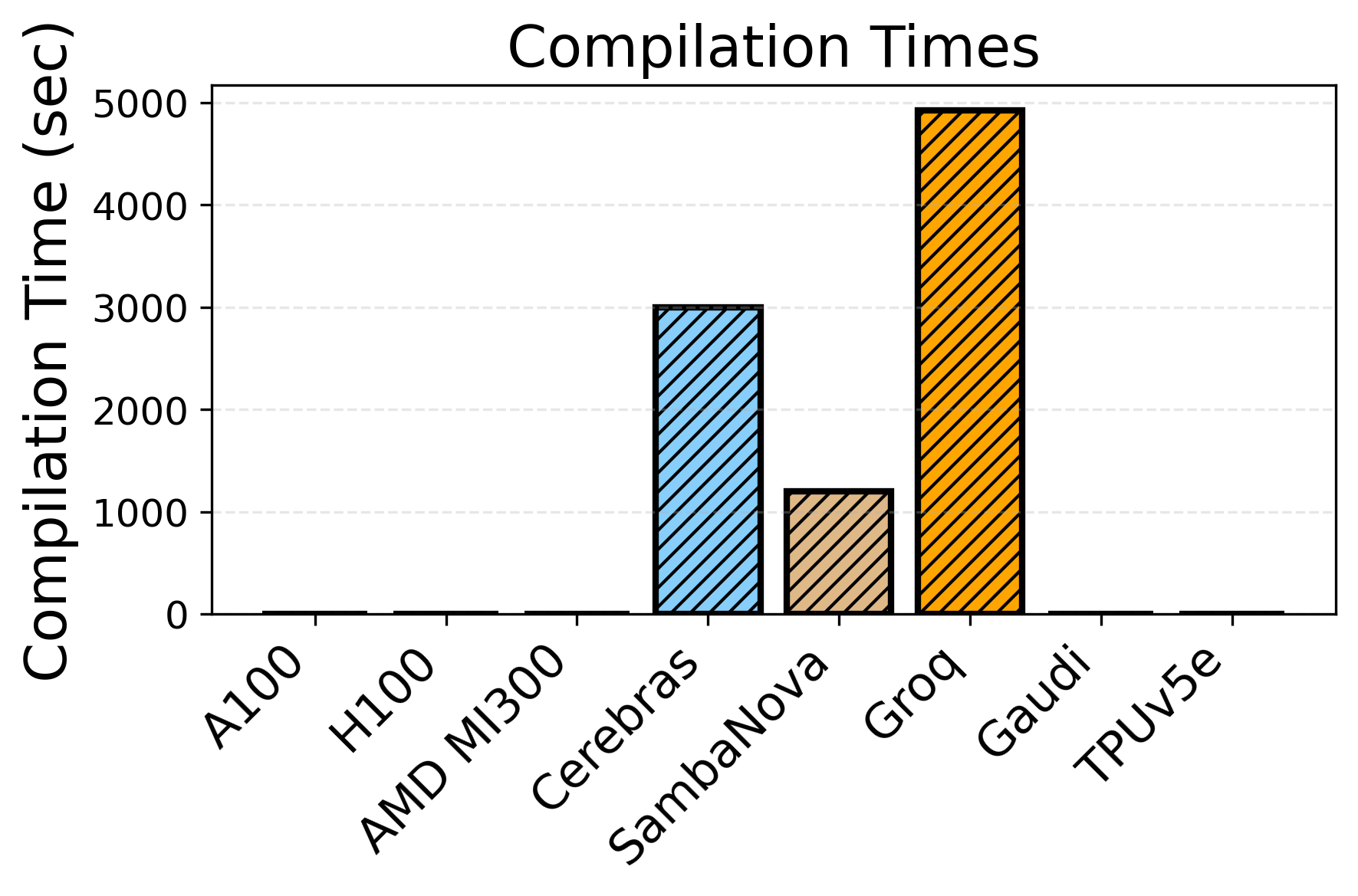
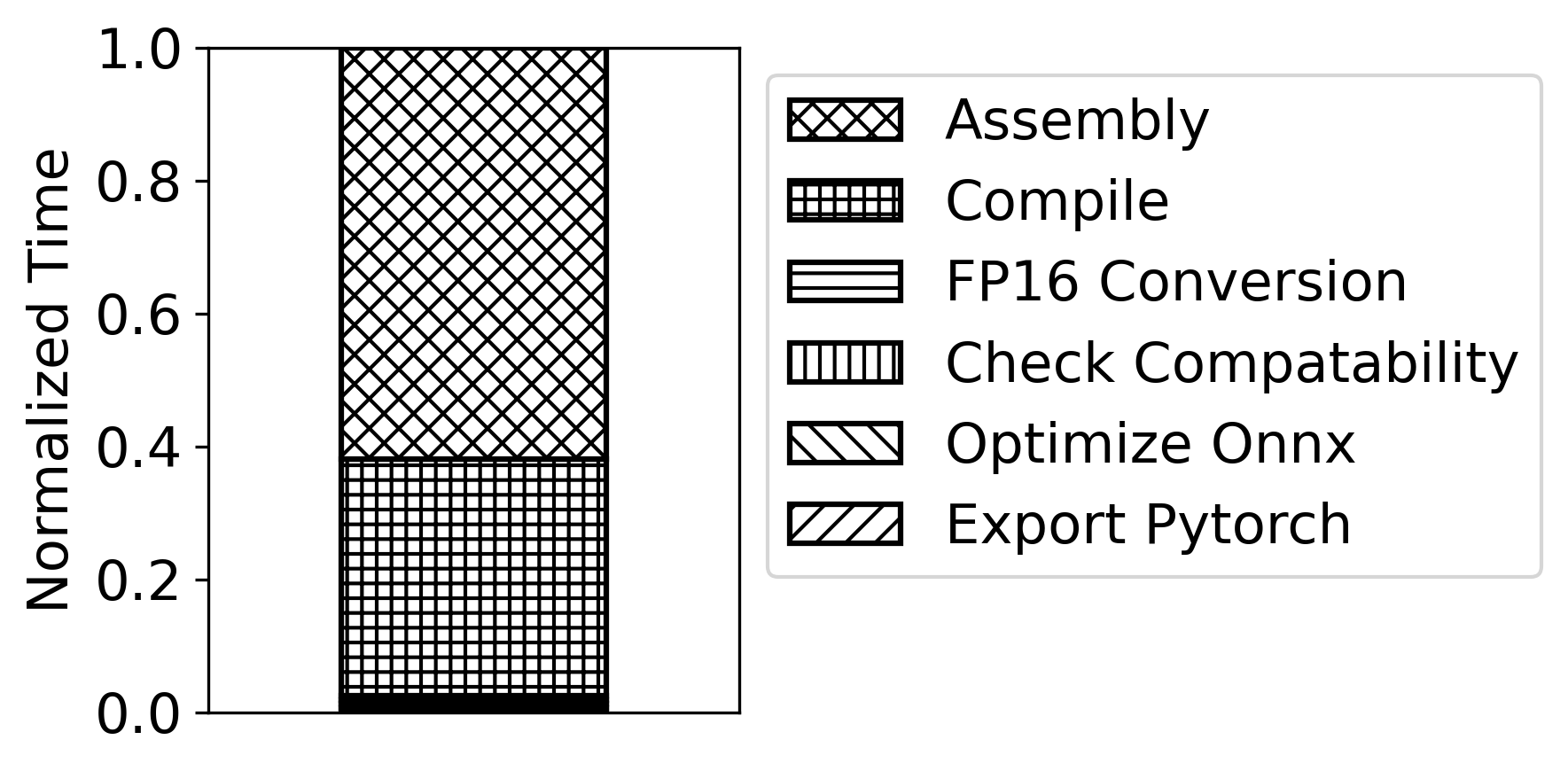
Figure 11: Build/compilation time for LLM inference—Groq and Cerebras incur severe build penalties, impacting R&D velocity.
Programmability and Software Stack
While hardware features dominate peak achievable performance, the software maturity and compilation flows present non-negligible friction. Specialized toolchains and incomplete operator coverage impede both rapid iteration and deployment. Compilation times for non-GPU platforms can be up to 5,000× longer, with Groq, Cerebras, and SambaNova particularly affected. PyTorch compatibility remains partial, with significant gaps in operator coverage and distributed primitives: this fragmentary landscape hinders broad adoption.
Implications and Future Directions
The heterogeneity in accelerator hardware and the multidimensionality of “optimal” design point toward the need for workload-aware deployment strategies and continual hardware-software co-design. For practical deployment, accelerators with high static power demand (Cerebras, SambaNova, Gaudi) must operate at high utilization to deliver energy savings otherwise swamped by idle or underutilized power waste. Furthermore, the significant software enablement gap constrains realization of hardware's nominal performance.
For AI system architects: meaningful platform benchmarks must include distributed workload-aware scale-out, communication cost, and software readiness—not just isolated FLOP/watt figures. We anticipate three near-term research trends:
- Compiler/Kernel Co-Optimization: With LLM-generated code, acceleration of kernel bring-up and compiler iteration is critical to unlock specialized hardware throughput.
- Utilization-Adaptive Scheduling: Task orchestration frameworks must consider static power and batch compositions to maximize effective energy efficiency in high-idle systems.
- System-Level Co-Design: Future platforms may hybridize monolithic and composable architectures to mitigate communication and area efficiency limitations.
Conclusion
This comprehensive benchmarking and architectural study of modern accelerators demonstrates there is no singular winner in the AI hardware race: optimum platform selection is contingent on workload scale, communication topology, software enablement, and batch structure. Absent robust and unified software stacks, hardware advances alone are insufficient to fully exploit accelerator capabilities. The field would benefit from standardized, fine-grained benchmarking practices and active investment in cross-platform software infrastructure—paving the way for heterogeneous, workload-optimized AI systems of the future.