- The paper introduces a comprehensive co-design framework that integrates compute, memory, network topology, and algorithmic parallelism to efficiently train trillion-parameter LLMs.
- The study demonstrates that FullFlat optical architectures can achieve up to 70× throughput improvements and reduce TCO by 20–30% compared to traditional two-tier networks.
- The extended Calculon tool accurately predicts LLM performance within a 10% margin, enabling optimal system configurations across thousands of design points.
Scaling Intelligence: Data Center Co-Design for Next-Gen LLMs
Introduction
The emergence of multi-trillion parameter LLMs, such as GPT-4 (1.8T parameters), demands a radical re-examination of AI data center design. The escalating computational, memory, and networking requirements place pressure on current infrastructure, where Model FLOPS Utilization (MFU) often falls below 50%. The paper "Scaling Intelligence: Designing Data Centers for Next-Gen LLMs" (2506.15006) delivers a comprehensive co-design framework and analytical evaluation—jointly considering compute, bandwidth, memory, network topology, and algorithmic parallelism—targeted at enabling efficient, cost-optimal training of state-of-the-art and future LLMs.
Analytical Framework and Methodology
The study introduces an enhanced analytical performance model, extending the Calculon tool to accurately project runtimes and resource sensitivities for both dense (e.g., GPT-3) and sparse Mixture of Experts (MoE, e.g., GPT-4) architectures. The tool models:
- Application parameters: embedding, sequence size, hidden/attention dimensions, batch sizes.
- System parameters: GPU compute (FP4–FP16), HBM/Tier-2 memory capacity and bandwidth, network link BW/latency.
- Implementation/optimizations: parallel strategies (DP, PP, TP, EP, SP, ES), recompute/offloading, kernel fusion, collective operations (all-reduce/all-to-all), overlapping compute and communication.
This simulator achieves a prediction accuracy within 10% of real-world measurements on modern LLM clusters, and allows exhaustive exploration of thousands of hardware-software design points.
LLM Parallelism and Optimization Landscape
The explosive size of LLMs necessitates intricate, multi-axis parallelism strategies—data, pipeline, tensor, sequence, and expert parallelism/sharding—each mapped to different bandwidth/memory requirements and collective communication patterns.
Key findings:
This parameter sensitivity underscores the vital importance of analytical tools for early-stage exploration and system design.
Network Topology: Two-Tier vs. FullFlat Optical
The study systematically compares conventional two-tier networks (high-bandwidth domains, HBDs—e.g., NVLink, XeLink, Infinity Fabric—combined with low-bandwidth scale-out) to advanced all-optical, FullFlat architectures (Figure 3). FullFlat leverages high-radix, low-diameter, co-packaged optics meshes (HyperX, PolarFly), delivering uniform high-throughput and low-latency across all nodes.
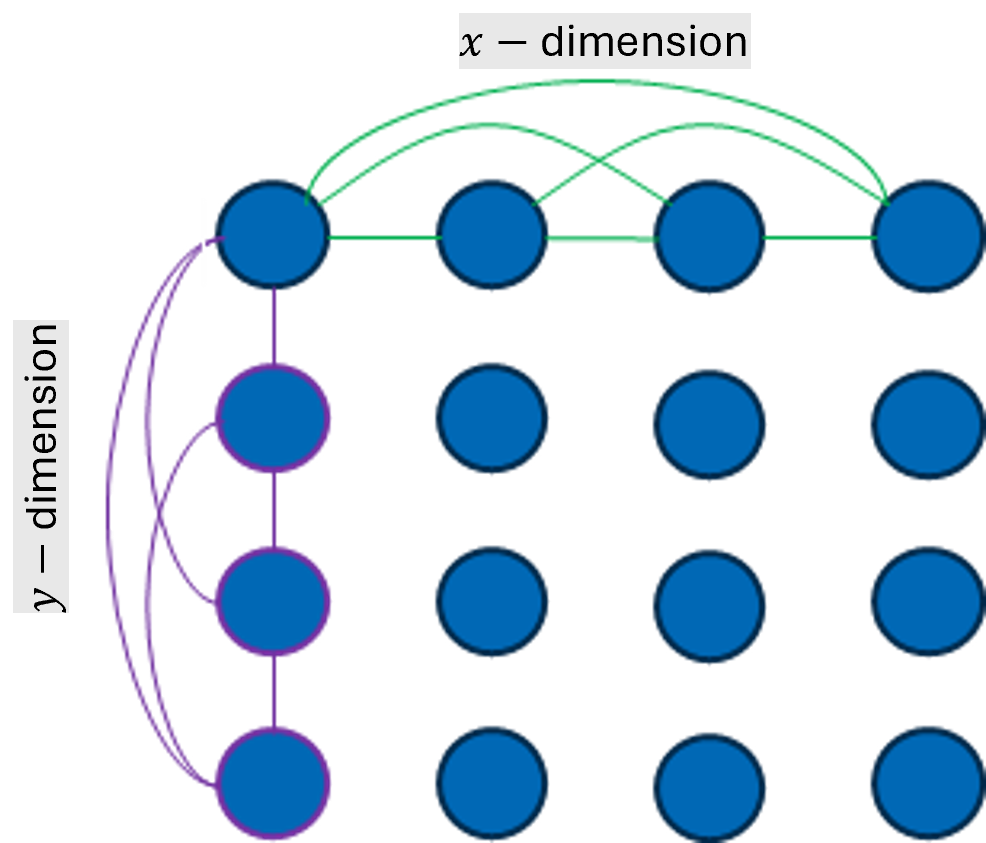
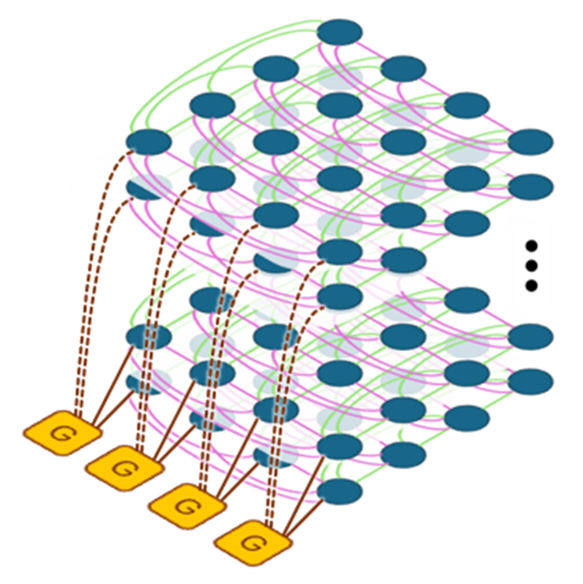
Figure 4: Network topologies: 2D HyperX, 2D HyperX with attached GPUs, and Polarfly, underlying future FullFlat architectures.
Core claims:
- FullFlat topologies consistently deliver higher throughput and better scaling, especially when expert parallel communication fits fully within HBD.
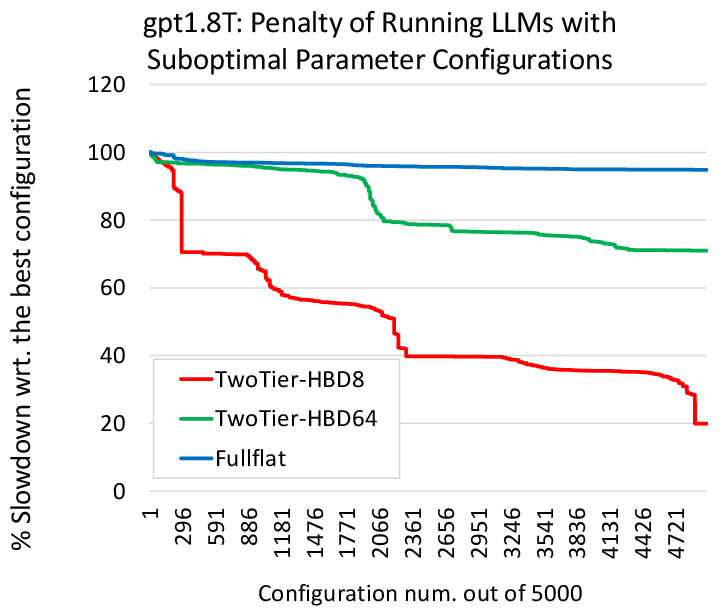
- FullFlat is less sensitive to missing software optimizations (e.g., compute/communication overlap, hardware collectives), with only a 5% gap between top parameter configurations versus up to 80% in two-tier systems.
- FullFlat reduces switch count, hop overhead, and can decrease TCO by 20–30%, with anticipated additional gains in reliability, resiliency, and serviceability.
- Two-tier enhancements (such as HBDs expanding from 8 to 576 GPUs with high BWs in future NVLink generations) can delay, but not fundamentally resolve, scale-out communication bottlenecks for large MoE models.
Empirical Sensitivity Results
Strong Scaling and Throughput
The analysis reveals substantial gains in throughput and scaling with increasing system size and advanced architectures:
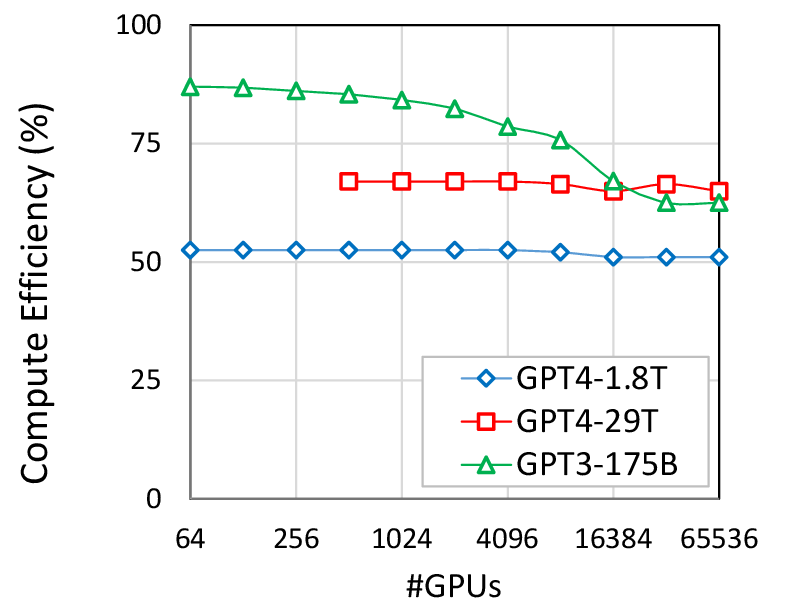
- Scaling GPT-4 (1.8T param) from today’s TwoTier-HBD8 to FullFlat raises throughput 50–70× at 4K GPUs (Figure 5), with optimal scaling observed to 16K–32K GPUs for large models.
- Communication and collective overheads (especially for MoE all-to-all) dominate for insufficient HBD sizes or limited scale-out bandwidth, at both strong and weak scaling points.
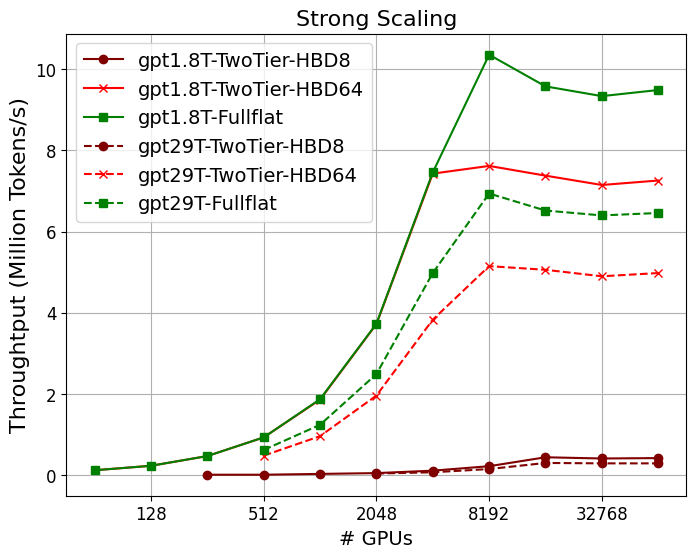
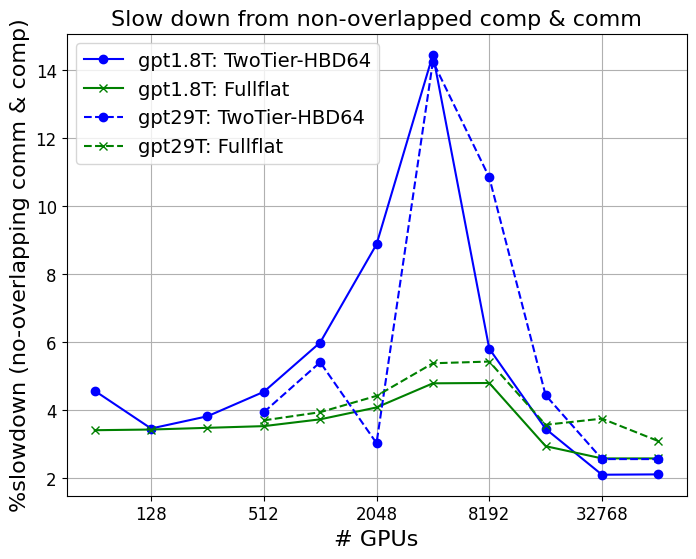
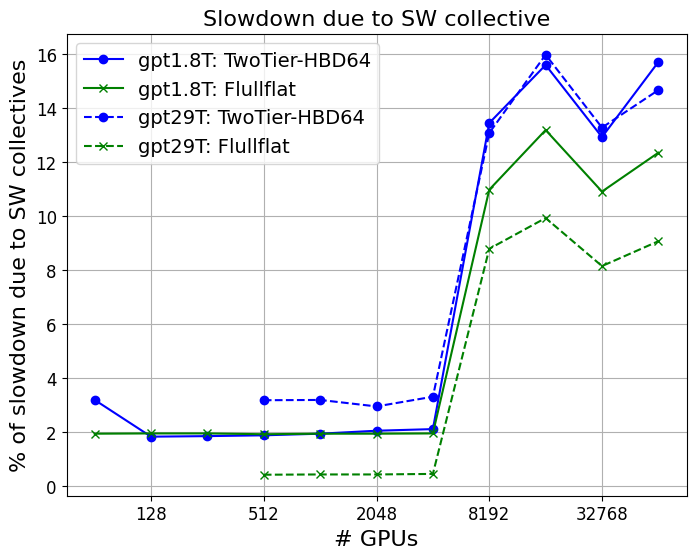
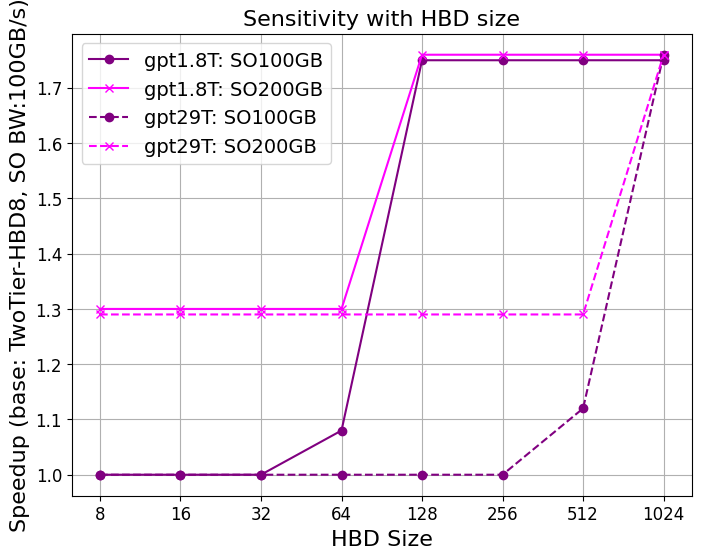
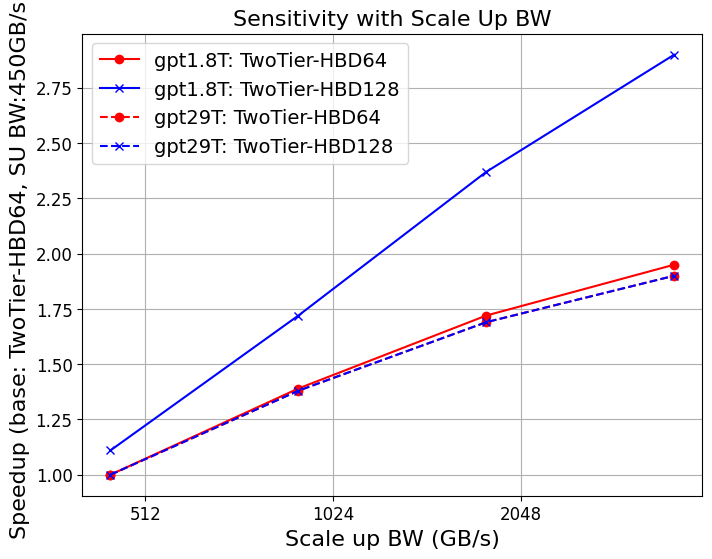
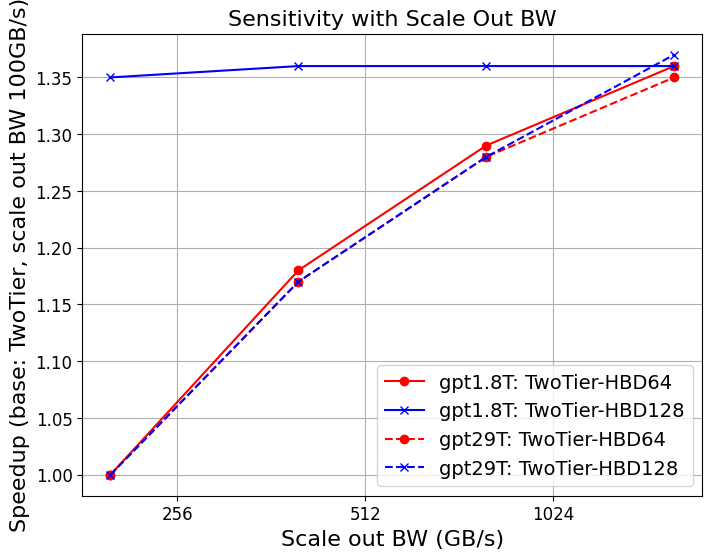
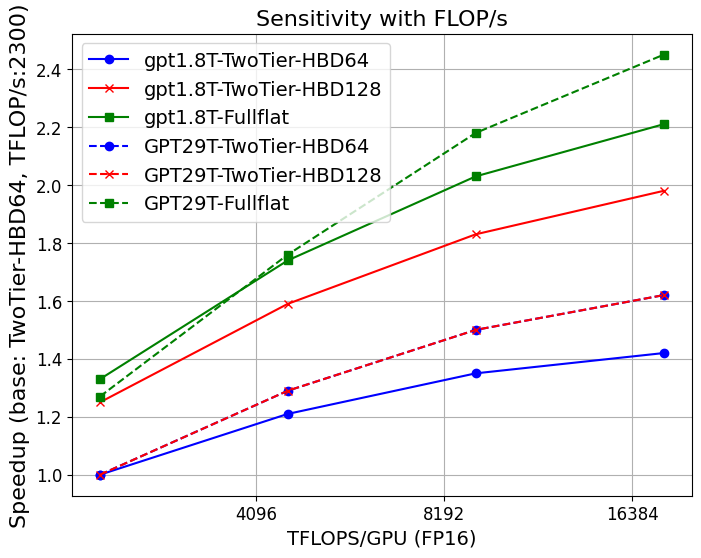
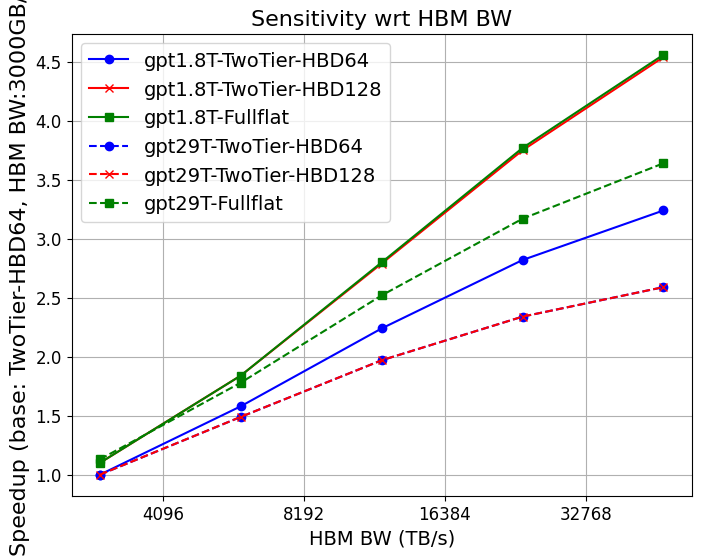
Figure 1: Strong scaling of GPT-4 on different system configurations; FullFlat and advanced two-tier architectures unlock significantly higher throughput.
Hardware-Accelerated Collectives & Comp-Comm Overlap
- Absence of hardware collectives (versus software) imposes 10–16% slowdowns at scale, while missing compute/communication overlap drives further degradation (up to 15% for MoEs; >40% for dense models at large node counts).
- FullFlat architectures are substantially more robust to these software omissions, decoupling system utilization from the need for intricate low-level tuning.
Memory Bandwidth and Capacity
- HBM bandwidth increases (up to 30–48TB/s per GPU) yield 3–4.5× throughput gains for MoEs and 2.6× for dense LLMs.
- Larger HBM capacity (toward 1.3TB/GPU, Figure 6) directly lowers the minimal degree of parallelism, eliminates recomputation/offloading, and boosts achievable MFU, especially for trillion-parameter models.
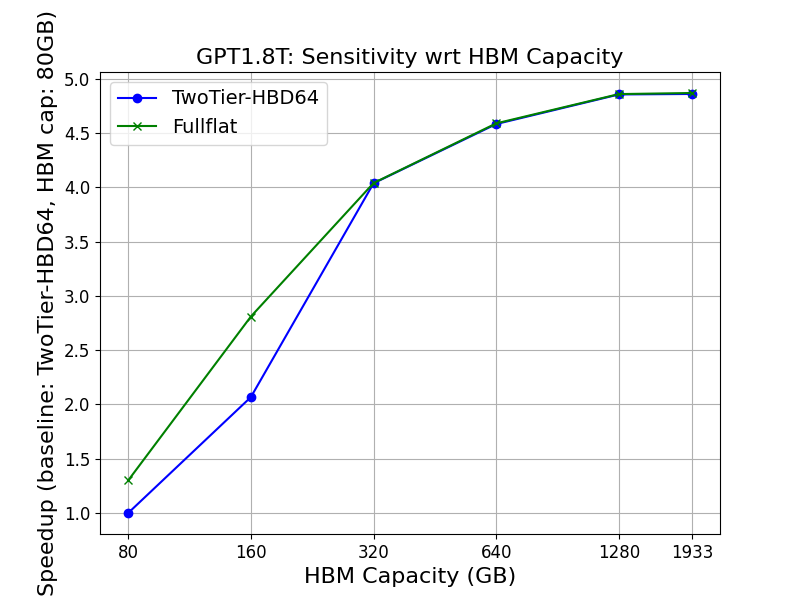
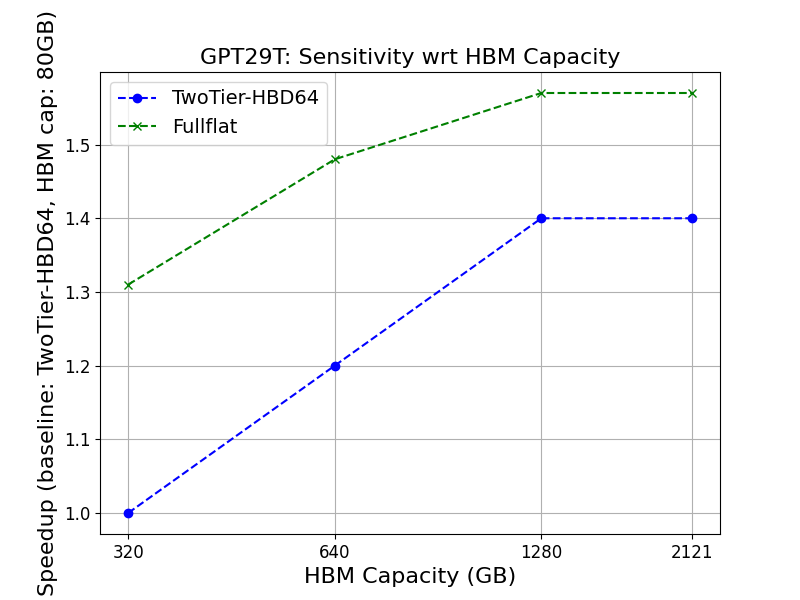
Figure 3: Performance impact of increasing HBM memory capacity; throughput gain plateaus beyond the point where a model fully fits resident in GPU memory.
Impact Factor Ranking
Prioritization for ROI in data center investment must balance:
- Compute FLOPS, Scale-up bandwidth, and HBM bandwidth as primary drivers.
- Adequate HBD to absorb the expert/tensor parallel domains, especially in MoEs.
- Scale-out BW remains necessary as system size and EP increase, but with diminishing marginal returns past a threshold where key communications remain within HBD.
- Software optimizations (collective overlap, hardware collectives) are less critical with FullFlat, but must be addressed in two-tier systems.
FullFlat Optical: Systemic Implications
FullFlat optical networks represent a paradigm shift in data center architecture for AI:
Dense (GPT-3) vs. MoE Workloads
- Dense models (e.g., GPT-3-175B) exhibit higher arithmetic intensity and lower networking sensitivity, but become significantly less tolerant to missing compute/comm overlap and hardware collectives (>40% drop at scale).
- MoEs, while more network-intensive, are comparatively buffered from these software inefficiencies within FullFlat or high-HBD systems; their main bottleneck is the availability of sufficient intra-expert BW.
Practical Guidelines and Future Data Center Design
According to model/application projections:
- Next-gen systems should target ≥1.6TB/s scale-up and ≥200GB/s scale-out BW, 20 PF16 per GPU, 1.3TB HBM, and 256GB/s tier-2 memory BW.
- FullFlat (CPO-based) topologies with 64–1,024 node HBDs and optical mesh interconnects are essential for holistic utilization at million-GPU scale.
- Software frameworks must be equipped for rapid, static, ridgeline/impact factor analysis, and support all relevant parallelism axes and overlap strategies out-of-the-box.
Conclusion
The architectural requirements for next-generation LLMs effectively mandate a systemic co-design approach—one that coordinates compute, memory, network, and software tactics. The analysis in (2506.15006) makes clear that:
- FullFlat optical data centers fundamentally improve throughput, utilization, operational simplicity, and TCO for trillion-parameter LLMs.
- As model size and algorithmic diversity grow, the resiliency, programmability, and MFU delivered by FullFlat and related network topologies will become indispensable.
- The co-design and sensitivity methodology empowers early-phase investment and design decisions, revealing not only critical bottlenecks but also identifying clear stop-points for incremental resource additions, maximizing ROI.
Thus, the practical, theoretical, and operational roadmap to support future LLMs rests on balanced investments in compute, bandwidth, optical connectivity, and robust co-design tooling, ensuring data centers remain scalable, efficient, and future-proof.