Distributed Hybrid Parallelism for Large Language Models: Comparative Study and System Design Guide
Abstract: With the rapid growth of LLMs, a wide range of methods have been developed to distribute computation and memory across hardware devices for efficient training and inference. While existing surveys provide descriptive overviews of these techniques, systematic analysis of their benefits and trade offs and how such insights can inform principled methodology for designing optimal distributed systems remain limited. This paper offers a comprehensive review of collective operations and distributed parallel strategies, complemented by mathematical formulations to deepen theoretical understanding. We further examine hybrid parallelization designs, emphasizing communication computation overlap across different stages of model deployment, including both training and inference. Recent advances in automated search for optimal hybrid parallelization strategies using cost models are also discussed. Moreover, we present case studies with mainstream architecture categories to reveal empirical insights to guide researchers and practitioners in parallelism strategy selection. Finally, we highlight open challenges and limitations of current LLM training paradigms and outline promising directions for the next generation of large scale model development.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple Explanation of the Paper
1. What the paper is about
This paper is a guide to how very LLMs are trained and run across many computers at the same time. It explains different ways to split up the work and memory so huge models can fit and run faster. It compares these methods, shows when to use which, and gives tips for building efficient systems, both for training and for serving user requests (inference).
2. The main questions the paper asks
To make its advice clear, the paper focuses on a few simple questions:
- How do different computers share work and talk to each other efficiently?
- What are the main ways to split a big model or its inputs across devices, and what are the trade‑offs?
- How should we combine several methods (a “hybrid” plan) to get the best speed and memory use?
- How can we automatically pick the best plan for a specific cluster and job?
- What should engineers and researchers keep in mind when designing systems for both training and inference?
3. How the paper approaches the problem
The paper does four things:
- It explains “collective operations,” which are ways machines exchange data:
- Think of a group project: sometimes everyone sends their piece to a leader to combine (Reduce/Gather). Sometimes everyone ends up with the same combined result (AllReduce). Sometimes each person sends a different message to every other person (All‑to‑All). The paper describes the costs of these patterns and how to make them scalable.
- It reviews the main parallel strategies with everyday analogies:
- Data Parallelism (DP): Every device has a full copy of the model, but each works on different training examples. Like multiple cashiers serving different customers with the same register system.
- Pipeline Parallelism (PP): Split the model into stages across devices and run micro‑batches like an assembly line. It boosts throughput but can have “bubbles” (idle time) that smart schedules try to reduce.
- Tensor Parallelism (TP): Split big matrices inside layers across devices. Like slicing a huge pizza so several people can eat in parallel—fast but needs coordination to recombine results.
- Expert Parallelism (EP) for MoE models: Many small “experts” live on different devices; each token is routed to a few experts and then sent back. Picture sorting mail to the right specialists, then reassembling the letters in the original order.
- Sequence/Context Parallelism (SP/CP): Split long input sequences across devices so memory fits and inference latency stays low. Imagine dividing a very long document into chunks and letting different readers process their chunk, passing summaries around a ring.
- LASP (Linear Attention Sequence Parallelism): Special tricks for “linear attention” models to reduce how much data devices need to exchange, making long‑context training and inference more efficient.
- It shows how to combine methods (hybrid parallelism):
- Real systems mix DP, PP, TP, EP, and SP/CP to balance memory, compute, and communication. The “best mix” changes between training (maximize throughput) and inference (minimize latency).
- It discusses automated planning and case studies:
- Cost models estimate time spent on compute vs. communication to search for the best hybrid plan automatically. The paper also shares practical insights from common model architectures and cluster setups.
4. The main findings and why they matter
Key takeaways:
- Training and inference need different strategies:
- Training focuses on high throughput (many examples per second). Methods like DP and PP help, and schedules that overlap compute and communication reduce idle time.
- Inference focuses on low latency (fast answers), especially with long inputs. CP, SP, and careful routing matter more here.
- No single method wins everywhere:
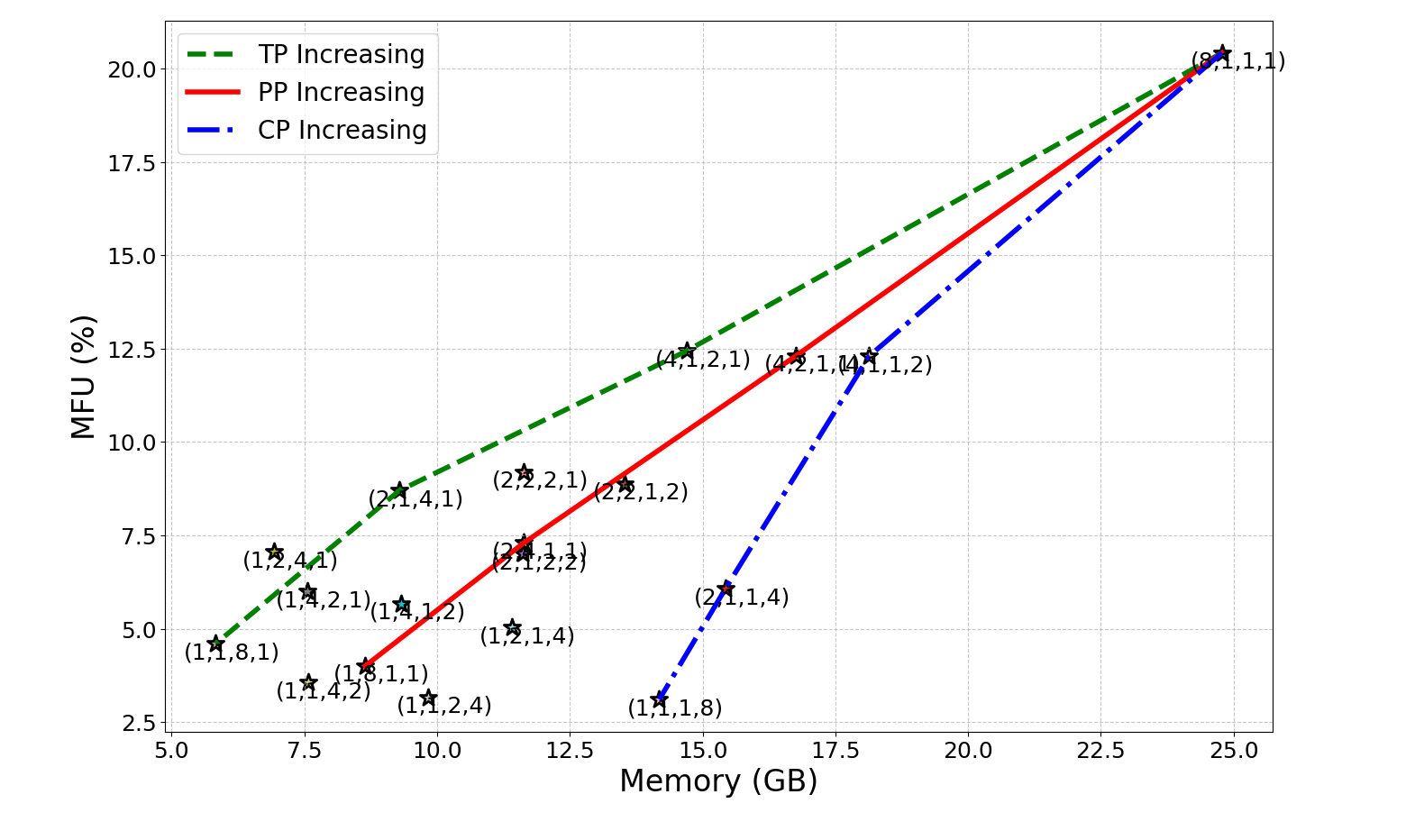
- TP reduces per‑device memory but increases communication; too much TP can slow down small matrix multiplies.
- PP improves throughput but can waste time with bubbles unless you use smart schedules (like 1F1B and newer “zero bubble” or “dual pipe” ideas).
- MoE with EP saves compute per token but requires heavy All‑to‑All communications, so good routing and load balancing are crucial.
- SP/CP make long contexts practical by slicing sequences, using ring‑style communications to keep memory and latency under control.
- Communication patterns are as important as compute:
- Ring‑based collectives (like Reduce‑Scatter + All‑Gather) spread data movement evenly so no single device becomes a bottleneck.
- Overlapping communication with computation (starting data transfers while the GPU is still working) is vital to avoid stalls.
- Good system design requires balancing four things together:
- Memory per device, compute throughput, network bandwidth, and the exact communication pattern. Ignoring any one can ruin performance.
- Automation helps:
- Using cost models and search tools can pick better hybrid strategies faster than hand‑tuning, especially on large clusters.
These findings matter because training giant models uses a lot of time, money, and energy. Even small efficiency gains can save days of training and reduce carbon footprint.
5. What this means going forward
- For engineers: Design hybrid plans that fit your hardware and your goal (training vs. inference). Use ring collectives, overlap communication with compute, and pick PP/TP/EP/SP/CP based on model size, sequence length, and network speed.
- For researchers: Keep improving automatic strategy search, smarter pipeline schedules, better token routing for MoE, and methods that scale to million‑token contexts without exploding memory or latency.
- For the community: Efficient distributed AI supports “Green AI” goals—getting strong results while using less energy. Thoughtful parallelism and communication design make large models more practical and sustainable.
Knowledge Gaps
The following list captures the knowledge gaps, limitations, and open questions the paper leaves unresolved. Each item is framed to be concrete and actionable for future research.
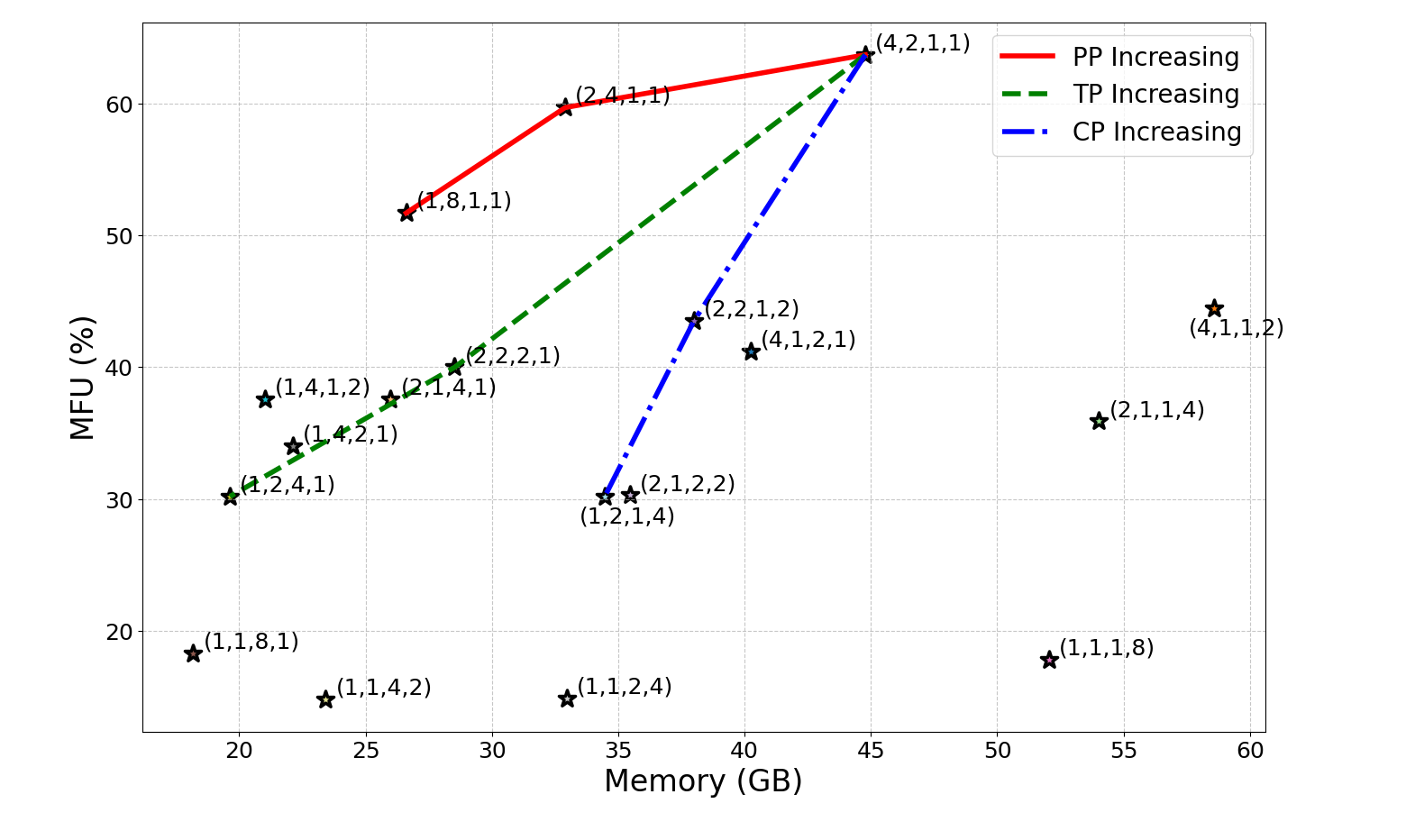
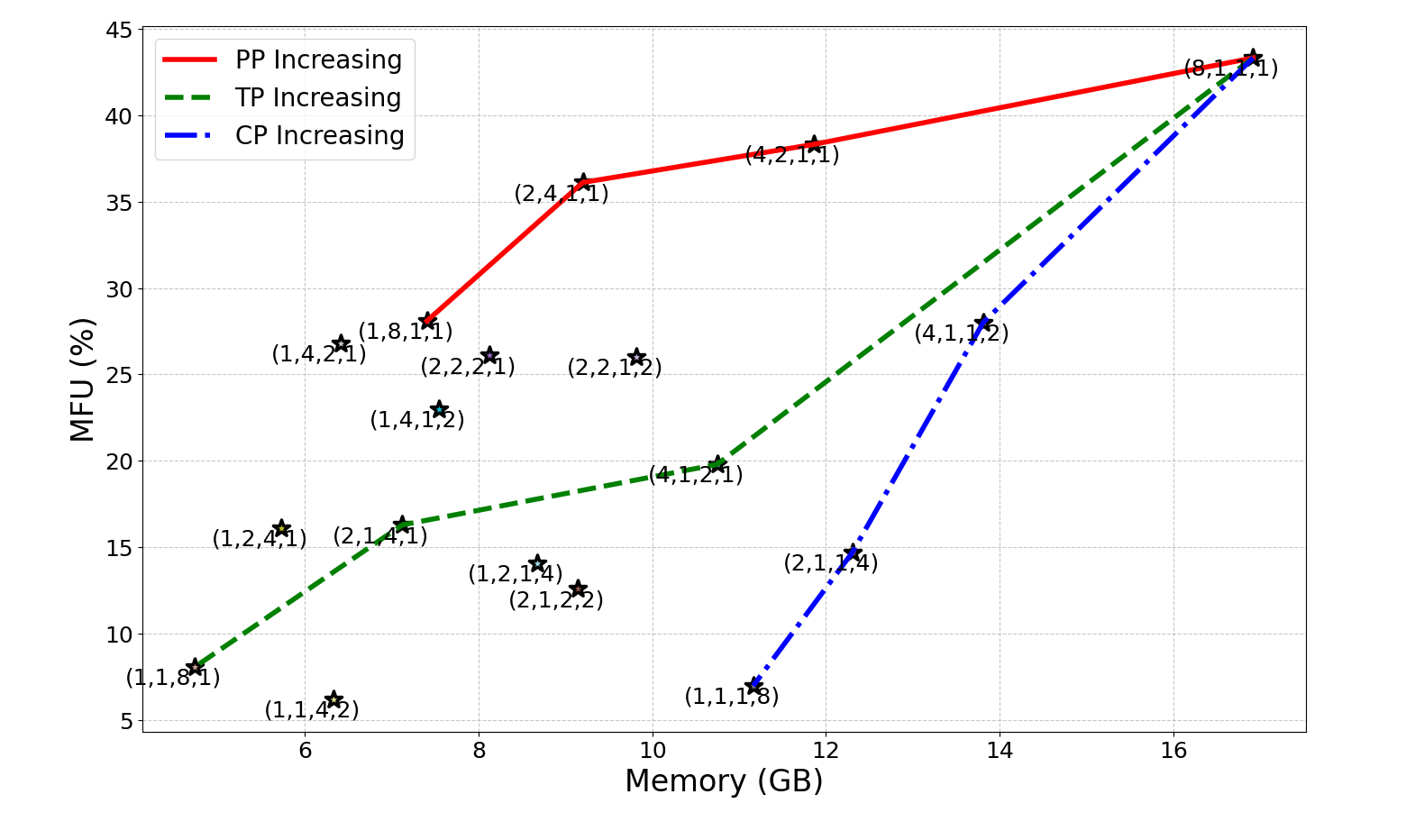
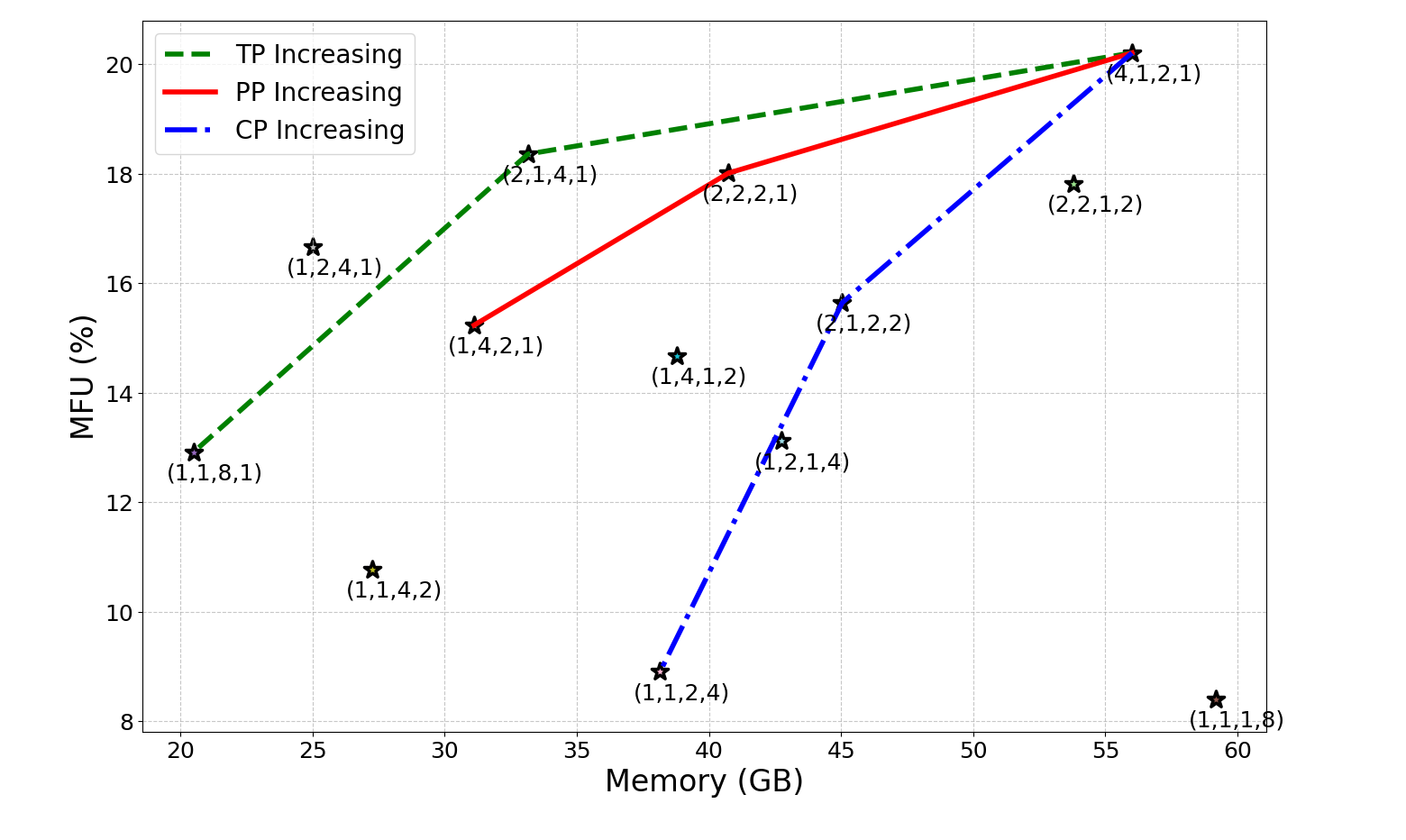
- Lack of validated, hardware-aware cost models: derive and empirically calibrate end-to-end performance models that jointly capture compute (kernel efficiency vs. shard size), memory bandwidth, collective latency (alpha–beta), and hierarchical topology (intra-node NVLink/PCIe vs. inter-node InfiniBand/RoCE) for hybrid strategies combining DP/PP/TP/EP/SP/CP/LASP.
- Missing quantitative benchmarks across strategies: provide reproducible, apples-to-apples comparisons of training and inference throughput, P50/P99 latency, memory footprint, utilization, and energy per token for DP/PP/TP/EP/SP/CP/LASP and their hybrids across realistic sequence lengths (e.g., 4K–1M), batch sizes, and hardware (H100/A100/TPU/NPU).
- No empirical case studies on mainstream architectures: include concrete LLaMA/Transformer-XL/DeepSeek-MoE evaluations with throughput/latency vs. parallelism degree, including ablations for pipeline schedules (GPipe, 1F1B, Zero-Bubble, DualPipe) and tensor-parallel shard sizes vs. d_model.
- Oversimplified collective communication analysis: extend beyond per-device data volume to include latency-bandwidth models, contention, NIC oversubscription, hierarchical collectives (ring/tree), and topology-aware group formation; validate with microbenchmarks for
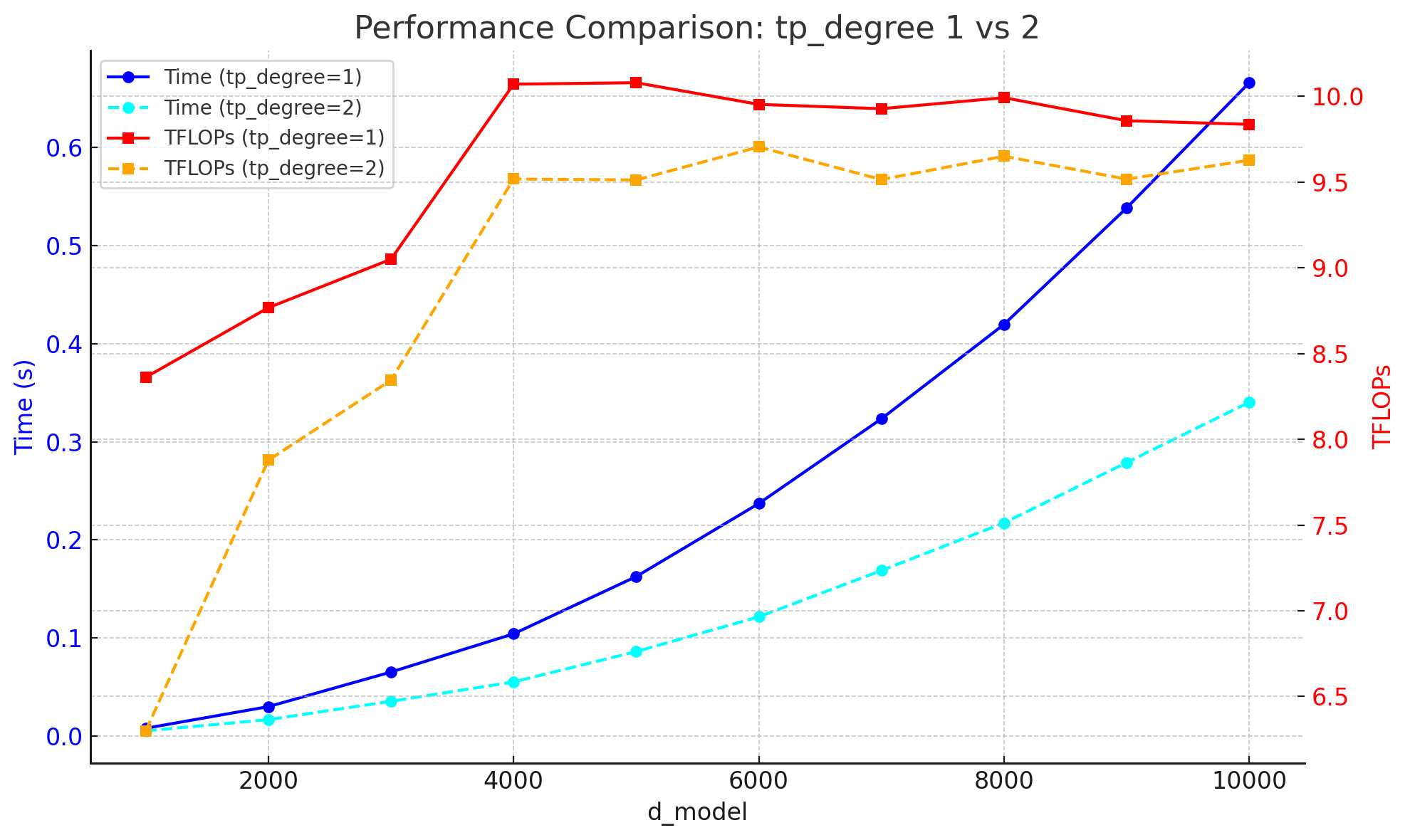
AllReduce,ReduceScatter,AllGather, andAll-to-All. - Missing guidance on TP arithmetic intensity and kernel efficiency: systematically characterize when increasing TP reduces matmul size below efficient kernel thresholds; produce actionable rules (e.g., min tile sizes per architecture) for choosing TP degree given d_model, n_heads, and MLP width.
- Incomplete treatment of communication–computation overlap: formalize and experimentally validate optimal overlap schedules across PP/TP/EP/CP (e.g., ILP/DP formulations for interleaving compute and collectives) and quantify bubble reduction under different micro-batch/token-pipeline configurations.
- No analysis of convergence and optimizer dynamics under extreme parallelization: study effects of very large DP and hybrid strategies on optimization stability (gradient noise scale, LR schedules, clipping), validation accuracy, and training time to target loss.
- Interactions with distributed optimizers and memory sharding left unexplored: evaluate ZeRO stages, optimizer state sharding, gradient partitioning, and activation checkpointing with DP/PP/TP/EP/SP/CP for memory/communication trade-offs and overlap opportunities.
- Dynamic resharding and hot-switching are not addressed: design and evaluate mechanisms to reconfigure parallelism (e.g., prefill vs. decode, TP↔CP↔SP) at runtime with minimal overhead, preserving KV-cache consistency and correctness.
- Long-context inference gaps: provide empirical results for CP/Ring-Attention/UP/LASP at 128K–1M tokens (prefill and decode), including KV-cache partitioning strategies, memory usage, network saturation thresholds, and P99 latency under multi-tenant load.
- LASP details and comparisons missing: complete algorithmic descriptions (forward/backward, kernel tricks, state size), integration into hybrid systems, and head-to-head comparisons with DeepSpeed-UP and Ring-Attention for both training and inference; quantify accuracy impact of linear attention variants.
- MoE routing trade-offs underexplored: systematically study device-limited routing, capacity factors, token drop rates, load-balancing losses, and their effects on accuracy and
All-to-Alloverhead; explore expert placement strategies across racks/nodes to minimize cross-fabric traffic. - Heterogeneous cluster support is not discussed: develop strategies for mixed GPU/NPU generations, asymmetric memory/NIC bandwidth, and non-uniform topologies (fat-tree/dragonfly), including automated placement and shard-size tuning.
- Fault tolerance, elasticity, and straggler mitigation are omitted: design recovery schemes, elastic scaling policies, and adaptive scheduling that preserve correctness and efficiency for hybrid parallel runs under failures and preemption.
- Inference-specific systems gaps: evaluate distributed beam/speculative decoding, paged attention, cache eviction policies, and batching strategies under hybrid parallelism; provide guidelines for low-latency serving with SLA-aware admission control.
- Auto-parallelism remains high-level: define a unified search space and constraints for 3D/4D hybrid strategies, develop cost models tied to SLAs (latency, throughput, cost, energy), and benchmark automatic planners vs. expert-tuned layouts on real clusters.
- Energy and sustainability claims lack measurements: instrument and report energy per token/step, carbon intensity, and throughput-per-watt across strategies; study scheduling for green energy windows and power caps.
- Compiler/runtime integration gaps: assess portability and performance across PyTorch/JAX/TF and NCCL/RCCL/HCCL/HCClike backends; evaluate CUDA Graphs/XLA fusions with PP/TP/EP/CP to reduce launch overhead and improve overlap.
- Attention kernel interactions not covered: quantify impacts of FlashAttention2/3, multi-query/grouped-query attention, and tiled attention on activation/sequence/context parallelism and communication patterns.
- Memory fragmentation and allocator behavior unaddressed: analyze fragmentation under hybrid strategies, multi-stream execution, and tensor rematerialization; propose allocator policies to maintain high effective memory utilization.
- Security and privacy considerations omitted: identify risks of data leakage through collectives/logging in multi-tenant environments and propose defenses (secure aggregation, isolation policies) compatible with hybrid parallelism.
- Standardized evaluation metrics are not defined: propose a consistent suite (throughput, P50/P99 latency, efficiency, utilization, energy, cost-per-token, accuracy retention, time-to-target-loss) and reporting guidelines for parallel strategy selection.
- Reproducibility artifacts missing: release code, configs, topology descriptions, and microbenchmark harnesses to enable independent validation of claimed guidelines and analyses.
Glossary
- Activation recomputation: A memory optimization technique that trades extra computation for reduced activation storage by recomputing activations during backpropagation. "often augmented with memory optimization techniques like activation recomputation~\cite{chen2016training} and distributed optimizers~\cite{rajbhandari2020zero}."
- All-to-All: A collective operation where each rank sends a distinct message to every other rank, used for personalized exchanges such as token routing in MoE. "The All-to-All operation (also known as total exchange or personalized communication) enables each rank to send a distinct message to every other rank, including itself."
- AllGather: A collective operation that collects data from all ranks so that every rank ends up with the full concatenated result. "The AllGather operation extends Gather by collecting data from every rank."
- AllReduce: A collective operation that reduces (e.g., sums) data across all ranks and distributes the final reduced result to every rank. "The AllReduce operation performs a reduction (e.g., sum, min, max) across all ranks and distributes the final result back to every rank."
- Broadcast: A collective communication pattern where data from a root rank is sent to all other ranks. "Conceptually, AllReduce is equivalent to performing a Reduce followed by a Broadcast."
- Collective communication primitives: Fundamental distributed operations (e.g., Reduce, AllReduce, AllGather) that synchronize and exchange data across devices. "Collective communication primitives are fundamental to distributed training, enabling synchronization and data exchange across multiple devices or ranks."
- Context Parallelism (CP): An inference optimization that splits the sequence across devices inside attention, using ring communication to improve latency for long contexts. "Context parallelism (CP) is a system optimization technique that improves the latency and scalability of LLM inference, particularly for long contexts."
- Data Parallelism (DP): A training strategy that replicates the model across devices and splits the mini-batch, synchronizing gradients via all-reduce. "Data parallelism (DP) is the most common parallel training strategy for deep neural networks \cite{goyal2017accurate, li2020pytorch}."
- Device-limited routing: A MoE routing strategy that constrains selected experts to a limited set of devices to reduce cross-device communication. "DeepSeek uses device-limited routing to reduce communication overhead—ensuring that the top-k experts selected for a token are located on a limited number of devices."
- DualPipe: A bidirectional pipeline scheduling algorithm that increases computation–communication overlap and reduces pipeline bubbles. "DeepSeek extended the Zero Bubble 1F1B schedule with bidirectional pipeline scheduling to introduce the DualPipe algorithm, which achieves greater computation–communication overlap and further reduces pipeline bubbles \cite{liu2024deepseek}."
- Expert Parallelism (EP): A parallelization strategy for MoE models where experts are distributed across devices and tokens are routed to their selected experts. "Expert Parallelism (EP) is a parallelization strategy designed specifically for Mixture-of-Experts (MoE) architectures."
- Gather: A collective operation that collects data from all ranks to a single root rank without aggregation. "The Gather operation collects data from all participating ranks and delivers it to a single root rank."
- GPipe: A pipeline scheduling approach that splits a mini-batch into micro-batches to pipeline stages, but can incur pipeline bubbles. "Popular instances of pipeline scheduling algorithms are GPipe \cite{huang2019gpipe}, PipeDream \cite{narayanan2019pipedream}, TeraPipe \cite{li2021terapipe}, Zero Bubble 1F1B~\cite{qi2023zero}, and DualPipe \cite{wang2025review}."
- Linear attention: An attention mechanism that replaces softmax with kernel-based formulations to achieve linear complexity with sequence length. "Modern generative AI architectures often combine traditional softmax attention with linear attention to handle longer context lengths efficiently."
- Linear Attention Sequence Parallelism (LASP): Sequence-parallel methods tailored for linear attention that optimize communication via ring-style P2P (LASP-1) or single AllGather (LASP-2). "two versions of Linear Attention Sequence Parallelism (LASP) have been proposed \cite{sun2024linear, sun2025lasp}."
- Load balancing losses: Auxiliary losses used in MoE to ensure tokens are evenly distributed across experts to avoid stragglers and starvation. "This is often achieved using load balancing losses or bias-based methods."
- Mixture-of-Experts (MoE): A model architecture that replaces a single large MLP with multiple expert MLPs and a router that selects a sparse subset per token. "In MoE architectures, a set of smaller multilayer perceptron (MLP) networks, referred to as experts, replaces a single large MLP."
- Pipeline Parallelism (PP): A model-parallel approach that partitions consecutive layers into pipeline stages across devices, often paired with micro-batching. "Pipeline Parallelism (PP) distributes consecutive layers as pipeline stages across multiple GPUs and each GPU processes a different stage of the network sequentially \cite{narayanan2019pipedream}."
- PipeDream: A pipeline scheduling algorithm that uses interleaved 1F1B to eliminate bubbles, with weight versioning to maintain correctness. "PipeDream improves upon GPipe by eliminating pipeline bubbles through an interleaved scheduling strategy, known as 1 Forward 1 Backward (1F1B)~\cite{narayanan2019pipedream}."
- Point-to-point (P2P) communication: Direct communication between specific pairs of ranks, commonly used in ring-based attention for exchanging sequence chunks. "A ring communication is used to transfer Q or KV chunks between GPUs through point-to-point (P2P) communication."
- Reduce: A collective operation that aggregates data from multiple ranks to a designated root rank using a reduction function. "The Reduce operation aggregates data from multiple ranks and delivers the result to a designated root rank."
- ReduceScatter: A ring-based collective that reduces data across ranks and scatters the reduced slices evenly, lowering per-device communication. "The ReduceScatter operation first performs a reduction across ranks (as in Reduce) and then evenly scatters the reduced result across all ranks."
- Ring Attention: A context-parallel technique that performs attention via ring communication to scale to long sequences. "context-parallel techniques of Ring Attention~\cite{liu2023ring}"
- Ring-AllReduce algorithm: An optimized AllReduce implementation that composes ReduceScatter followed by AllGather to avoid root bottlenecks. "optimized implementations use the Ring-AllReduce algorithm, in which data is first partitioned and reduced in a distributed manner (ReduceScatter), followed by redistribution of the reduced blocks (AllGather)."
- Sequence Parallelism (SP): A parallelism method that partitions inputs along the sequence dimension to distribute activations across devices while replicating weights. "Sequence Parallelism (SP) is a parallelism technique introduced to efficiently train LLMs on long input sequences."
- TeraPipe: A pipeline scheduling algorithm that pipelines across tokens instead of micro-batches to improve utilization in transformer models. "Another following pipeline scheduling algorithm, TeraPipe, introduced a novel form of pipelining tailored to single-transformer architectures by performing pipelining across tokens rather than micro-batches \cite{li2021terapipe}."
- Tensor Parallelism (TP): A model-parallel method that shards projection layer matrices across devices (row/column-wise), requiring collectives to synchronize partial results. "Tensor Parallelism (TP) enables the training of large models by distributing model parameters across multiple GPUs, thereby reducing the computational workload per device \cite{shoeybi2019megatron}."
- Zero Bubble 1F1B: A pipeline schedule that splits backward into two parts and defers global sync to minimize or eliminate pipeline bubbles. "Conversely, Zero Bubble 1F1B proposed an idea to independently schedule the backward computation of two parts, backward for input and backward for gradient, which allow for a pipeline schedule with minimal bubbles."
Practical Applications
Immediate Applications
Below are deployable uses that can be implemented today using the paper’s design guidelines, comparative analysis, and the reviewed techniques (DP/PP/TP/SP/CP/EP, collectives, overlap, and cost-model-based planning).
- Bold, topology-aware hybrid parallel training for LLMs (DP + PP + TP + SP)
- Sectors: software/AI platforms, cloud, healthcare, finance, telecom, defense
- What to do:
- Place tensor parallelism (TP) within high-bandwidth intra-node domains (e.g., NVLink/NVSwitch) and data parallelism (DP) across nodes; use pipeline parallelism (PP) for very deep models; apply sequence parallelism (SP) to fit long sequences; add activation checkpointing to meet memory budgets.
- Overlap gradient reduce-scatter and parameter all-gathers with backprop/forward where supported.
- Tools/workflows: Megatron-LM/Megatron-Core, DeepSpeed, NVIDIA NeMo, PyTorch Distributed + NCCL; ZeRO optimizer; pipeline schedulers (GPipe, 1F1B)
- Assumptions/dependencies:
- Sufficient intra-node bandwidth for TP; stable inter-node fabric for DP/PP; proper global batch-size scaling to avoid convergence degradation; availability of checkpointing and ZeRO in framework.
- Long-context LLM inference with Context/Sequence Parallelism and Ring-Attention
- Sectors: legal, finance, healthcare, education, software engineering (code assistants), media
- What to do:
- Use context parallelism (CP) or Ulysses/TPSP-style sequence parallelism to shard attention across devices for long prompts; adopt ring-style P2P communications to serve 128K–1M token contexts with manageable latency.
- Tools/workflows: DeepSpeed-Ulysses, Ring Attention kernels, Megatron CP/TPSP; integrate with existing inference servers (vLLM, Triton) where possible
- Assumptions/dependencies:
- Attention kernels supporting ring/P2P; adequate GPU memory and intra-node bandwidth; unchanged dense attention math (CP doesn’t alter algorithm) or model support for required kernels.
- Practical Mixture-of-Experts (MoE) training/serving with Expert Parallelism (EP)
- Sectors: foundation-model providers, SaaS AI platforms, cloud
- What to do:
- Distribute experts across devices, use all-to-all for token routing, and employ device-limited/top-k routing to restrain cross-device traffic; add load-balancing losses to avoid expert under/over-utilization.
- Tools/workflows: DeepSpeed-MoE, Megatron-Core MoE, Colossal-AI MoE; NCCL All-to-All
- Assumptions/dependencies:
- High-throughput all-to-all fabric (e.g., HDR/200G+ InfiniBand); robust router load balancing; carefully tuned capacity factors to prevent token drops.
- High-throughput training via improved pipeline schedules and communication–computation overlap
- Sectors: all training-heavy organizations
- What to do:
- Adopt interleaved 1F1B schedules; consider zero-bubble 1F1B or DualPipe to minimize bubbles and overlap collectives with compute; verify correctness (weight versioning or prediction) and memory impact.
- Tools/workflows: PipeDream-like 1F1B, Megatron interleaved schedules, Zero-Bubble 1F1B, DualPipe if available in your stack
- Assumptions/dependencies:
- Scheduler support within chosen framework; possible memory overhead from weight versioning or added bookkeeping; benefit depends on depth and microbatching strategy.
- Memory footprint reduction for long sequences and large models
- Sectors: industry/academia training labs, edge/cloud training
- What to do:
- Apply activation recomputation (checkpointing), SP, and optimizer state sharding (ZeRO) to fit within device memory and enable longer sequence training without changing model quality targets.
- Tools/workflows: PyTorch checkpointing, DeepSpeed ZeRO, Megatron TPSP
- Assumptions/dependencies:
- Extra compute overhead from recomputation; training schedules may need retuning to maintain throughput/quality balance.
- Cost-model–guided parallel strategy selection with existing auto-parallel frameworks
- Sectors: cloud providers, enterprise ML platform teams, academic clusters
- What to do:
- Use automated planners to evaluate DP/PP/TP/SP layouts given cluster topology, bandwidth, and SLAs; search over microbatch size, pipeline depth, and TP degree to meet throughput/latency constraints.
- Tools/workflows: Alpa, FlexFlow, XLA SPMD/Sharders, emerging auto-parallel tuners in Megatron/DeepSpeed
- Assumptions/dependencies:
- Accurate cost models and topology descriptors; non-trivial integration with production training pipelines; heuristics still needed for edge cases.
- SLA- and cost-aware inference planning (prefill vs decode optimization)
- Sectors: LLM serving providers, consumer apps with chat/agents
- What to do:
- Use layouts that favor bandwidth-heavy prefill (e.g., more parallel attention shards) vs compute-bound decode (e.g., KV-cache sharding, lower TP) and batch scheduling tuned per phase.
- Tools/workflows: Serving orchestrators that can reshard KV and weights between phases; inference engines supporting CP/SP; paged attention backends
- Assumptions/dependencies:
- Limited downtime and memory to reshard between phases; sufficient orchestration to route traffic while switching layouts.
- Sustainability and energy/carbon reporting in large-scale training
- Sectors: enterprise AI, policy/compliance, cloud operations
- What to do:
- Instrument training jobs with energy telemetry; choose parallel strategies and batch schedules that minimize communication and idle time; schedule runs for off-peak/grid-friendly windows.
- Tools/workflows: Cluster telemetry + carbon accounting dashboards; strategy planners that report comm/compute balance
- Assumptions/dependencies:
- Availability of accurate metering; organizational policies that prioritize Green AI alongside performance.
- Datacenter/cluster procurement and placement guidelines
- Sectors: cloud/HPC providers, large enterprises building GPU pods
- What to do:
- Use the paper’s guidance to align interconnect topology with expected parallel strategies: prioritize strong intra-node bandwidth for TP and sufficient cross-node bisection for PP/DP/All-to-All; design failure domains with parallel groups in mind.
- Tools/workflows: Network fabric simulators, placement planners, NCCL topology tuning
- Assumptions/dependencies:
- Budget and vendor constraints; the modeled workloads reflect expected production usage (training vs inference mixes).
Long-Term Applications
These opportunities require further research, scaling, or ecosystem maturation (e.g., broader framework support, hardware co-design, or algorithmic advances).
- Fully automated, SLA-aware hybrid parallelism planners and runtime adaptors
- Sectors: cloud, hyperscalers, enterprise ML platforms
- What this enables:
- End-to-end “AutoParallel Orchestrator” that searches and deploys optimal DP/PP/TP/SP/EP layouts per job and adapts online to workload changes and cluster dynamics (preemptions, congestion).
- Dependencies/assumptions:
- High-fidelity cost models, online telemetry, robust compilers/IRs (e.g., MLIR/XLA), and safe runtime resharding mechanisms.
- Dynamic resharding/hot-switching across model phases and loads
- Sectors: LLM serving at scale, multi-tenant platforms
- What this enables:
- Seamless shifts between prefill-optimized and decode-optimized layouts, or training schedules that adapt to curriculum/batch regimes without downtime.
- Dependencies/assumptions:
- Fast state migration (weights/KV/optimizer), consistency guarantees, and scheduler support across heterogeneous hardware.
- Hardware–software co-design for LLM collectives and overlap
- Sectors: semiconductor, cloud, HPC
- What this enables:
- In-network reductions (NIC/ switch offload) for AllReduce/All-to-All; topology-aware kernels; photonic/advanced interconnects tuned for ring and 2D/3D tensor parallel collectives.
- Dependencies/assumptions:
- Vendor adoption, standardized APIs, and integration into NCCL/HCCl/RDMA stacks.
- Production-grade million-token context serving and training
- Sectors: legal/finance due diligence, scientific literature assistants, code intelligence
- What this enables:
- CP variants, 2D double-ring attention, and Linear Attention Sequence Parallelism (LASP) generalized to stable, multi-tenant environments; training/inference with memory- and comm-efficient kernels.
- Dependencies/assumptions:
- Wider adoption of linear/sparse attention in foundation models; mature kernel support; managed memory and KV-cache systems.
- Network-aware MoE with adaptive expert placement and device-limited routing
- Sectors: model providers, cloud
- What this enables:
- Joint optimization of expert placement, routing, and all-to-all patterns to minimize cross-rack traffic while preserving model quality and load balance.
- Dependencies/assumptions:
- Scalable routers with topology inputs, elastic expert placement, and robust training dynamics with dynamic layouts.
- Carbon-aware, grid-integrated scheduling and policy frameworks
- Sectors: cloud/HPC operations, regulators, sustainability officers
- What this enables:
- Training and serving schedulers that react to grid signals (renewables share, carbon intensity), shifting jobs spatially/temporally; standardized sustainability reporting for LLM workloads.
- Dependencies/assumptions:
- APIs from utilities/datacenters, organizational SLAs that accept schedule flexibility, and accepted reporting standards.
- Democratized large-model/long-context training on commodity interconnects
- Sectors: academia, startups, public sector
- What this enables:
- Communication-reducing variants (e.g., 2D/2.5D TP, compression, overlap) to make large models feasible over Ethernet-class fabrics with acceptable efficiency.
- Dependencies/assumptions:
- Further algorithmic work on collective compression and asynchrony; enhanced fault tolerance for less reliable networks.
- Cross-framework standardization of LLM-optimized collectives and metrics
- Sectors: open-source ecosystems, standards bodies
- What this enables:
- Common collective APIs specialized for LLM patterns (reduce-scatter + all-gather pipelines, all-to-all variants), shared benchmarks for throughput/latency/energy.
- Dependencies/assumptions:
- Community convergence and maintainers’ bandwidth across PyTorch, JAX/XLA, TensorFlow, and vendor libraries.
- Heterogeneous multi-accelerator partitioning (GPU/TPU/NPU)
- Sectors: hyperscalers, large research labs
- What this enables:
- Compiler-driven placement/partitioning across mixed accelerator fleets, honoring device-specific kernels and interconnect limits in a unified plan.
- Dependencies/assumptions:
- Common IRs, portable kernel libraries, and cross-vendor runtime protocols.
- Consumer/edge multi-device inference using CP-like sharding
- Sectors: consumer electronics, robotics, on-device assistants
- What this enables:
- Splitting attention/kv workloads across phone + home hub/PC for privacy-preserving long-context inference with acceptable latency.
- Dependencies/assumptions:
- Secure, low-latency local interconnects; lightweight CP kernels; model quantization/compression combined with parallelism.
Notes on sector-specific tools and workflows that may emerge
- Parallelism Planner and Placement Advisor: topology- and SLA-aware tool that proposes hybrid DP/PP/TP/SP/EP layouts, microbatch sizes, and schedules.
- SLA-aware Inference Orchestrator: manages prefill/decode-optimized layouts, KV-cache sharding, and CP/SP configurations per request mix.
- MoE Router with Topology Awareness: device-limited routing integrated with load balancing and expert placement.
- Sustainability Dashboard: integrates energy/comm metrics to evaluate strategy choices against carbon and cost targets.
Across both immediate and long-term scenarios, feasibility hinges on interconnect bandwidth/topology, framework/kernel support (Megatron-LM, DeepSpeed, NeMo, NCCL/RDMA), model architecture compatibility (e.g., linear attention for LASP), and operational maturity (telemetry, autoscaling, and cost modeling).
Collections
Sign up for free to add this paper to one or more collections.