A Full-Stack Performance Evaluation Infrastructure for 3D-DRAM-based LLM Accelerators
Abstract: LLMs exhibit memory-intensive behavior during decoding, making it a key bottleneck in LLM inference. To accelerate decoding execution, hybrid-bonding-based 3D-DRAM has been adopted in LLM accelerators. While this emerging technology provides strong performance gains over existing hardware, current 3D-DRAM accelerators (3D-Accelerators) rely on closed-source evaluation tools, limiting access to publicly available performance analysis methods. Moreover, existing designs are highly customized for specific scenarios, lacking a general and reusable full-stack modeling for 3D-Accelerators across diverse usecases. To bridge this fundamental gap, we present ATLAS, the first silicon-proven Architectural Three-dimesional-DRAM-based LLM Accelerator Simulation framework. Built on commercially deployed multi-layer 3D-DRAM technology, ATLAS introduces unified abstractions for both 3D-Accelerator system architecture and programming primitives to support arbitrary LLM inference scenarios. Validation against real silicon shows that ATLAS achieves $\le$8.57% simulation error and 97.26-99.96\% correlation with measured performance. Through design space exploration with ATLAS, we demonstrate its ability to guide architecture design and distill key takeaways for both 3D-DRAM memory system and 3D-Accelerator microarchitecture across scenarios. ATLAS will be open-sourced upon publication, enabling further research on 3D-Accelerators.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “A Full-Stack Performance Evaluation Infrastructure for 3D‑DRAM‑based LLM Accelerators”
What this paper is about (big picture)
This paper introduces ATLAS, a new “digital test lab” that lets engineers and researchers accurately measure and predict how special AI chips will perform before they are built. These chips are designed to speed up LLMs like the ones behind chatbots. ATLAS focuses on chips that use a new kind of super-fast memory called 3D‑DRAM, which stacks memory layers like a club sandwich and connects them with tiny copper pillars. This setup moves data much faster and uses less energy—perfect for the slowest part of LLMs: generating text one word at a time.
What the researchers wanted to find out
The authors set out to solve three practical problems:
- Can we create a general blueprint (not tied to one company’s design) for both the memory and the compute parts of a 3D‑DRAM‑based AI chip?
- Can we make a simple way to “program” and describe how LLM operations run on these chips so people can reuse it across different chip designs?
- Can we build an accurate, open tool to simulate performance—so anyone can test ideas—then prove it matches what real chips do?
How they approached it (in everyday terms)
Think of running an LLM like running a kitchen:
- “Prefill” is like prepping all your ingredients at once—lots of chopping in parallel (great for GPUs).
- “Decoding” is like plating one dish at a time—less parallelism and lots of trips to the pantry (memory). This is where things slow down.
To make the “pantry trips” faster, the paper focuses on 3D‑DRAM:
- 3D‑DRAM stacks memory layers and connects them with tiny copper columns (hybrid bonding). Shorter paths = higher bandwidth (more “lanes on the highway”) and lower energy per bit moved.
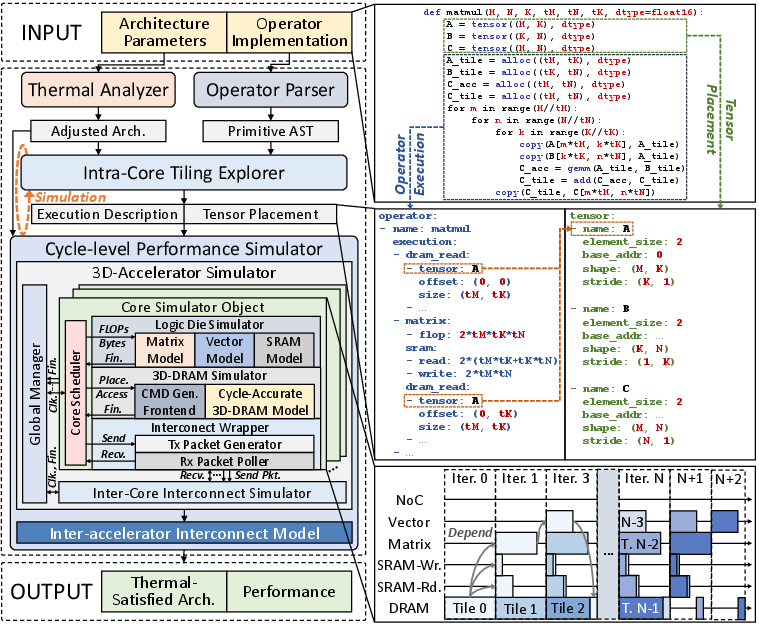
ATLAS models the whole stack—from hardware to software—to act like a “digital twin” of a real system:
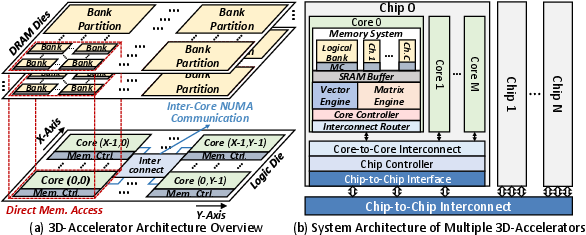
- Hardware model: A general chip layout with many small “cores,” each close to its own slice of 3D‑DRAM. Cores can talk to neighbors over an on‑chip network. This matches how real, high‑bandwidth memory is physically organized.
- Programming model: Simple building blocks (primitives) to describe what to compute and how to move data.
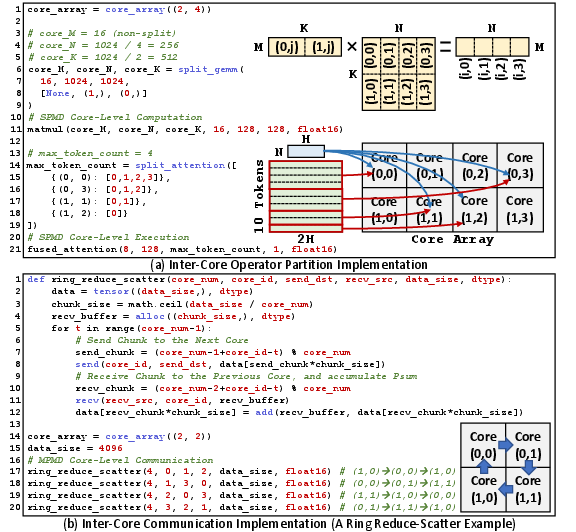
- Inside each core: “everyone runs the same steps on different chunks” (SPMD).
- Between cores: “cores can exchange different pieces as needed” (MPMD).
- Example primitives include: define a tensor in memory, copy tiles between DRAM and on‑chip SRAM, do matrix multiply (GEMM), do elementwise math, and send/receive data between cores.
- Simulation pipeline:
- A thermal checker to make sure the design doesn’t overheat (and to adjust frequency if it does).
- A parser that reads the programmer’s operator descriptions.
- A “tiling explorer” that decides how to break big matrices into tiles that fit on the chip for the best speed.
- A cycle‑by‑cycle simulator that models compute units, memory timing, and on‑chip communication like a real device would.
They explain technical ideas using practical analogies:
- Bandwidth = number of lanes on a highway.
- NUMA (non‑uniform memory access) = each chef has a nearby pantry; it’s faster to use your pantry than your neighbor’s.
- Tiling = cutting a big task (like a huge matrix) into plate‑sized portions that fit on your counter (SRAM).
What they found (key results)
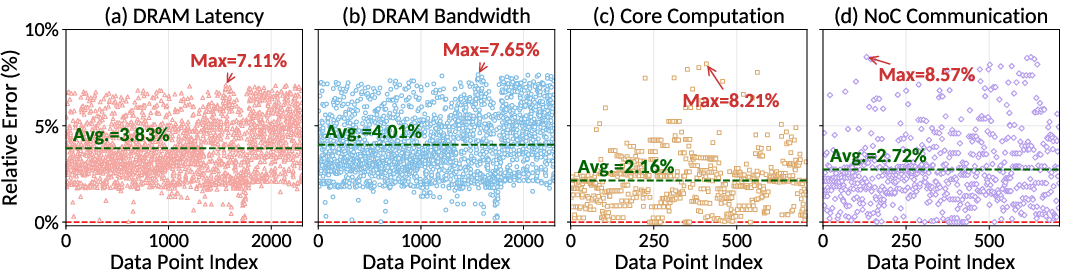
- ATLAS is accurate. When they compared ATLAS’s predictions to a real 3D‑DRAM test chip, it was very close:
- Memory latency/bandwidth: about 3–4% average error, under 8% max error.
- Compute and inter‑core communication: about 2–3% average error, under 9% max error.
- End‑to‑end LLM inference: within 6.37% error.
- It works across many scenarios. ATLAS can simulate different 3D‑DRAM organizations, chip layouts, and interconnects, and it supports LLM operations like attention and matrix multiplications with flexible splitting across cores and devices.
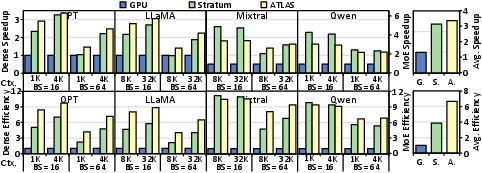
- It helps design better chips. Using ATLAS to explore design choices, they show that well‑tuned 3D‑DRAM accelerators can:
- Speed up LLM decoding by up to about 3.6× compared to a powerful GPU baseline.
- Outperform prior 3D‑DRAM accelerators by about 1.4×.
- It will be open‑sourced, so the community can build on it.
Why this matters
LLMs are getting bigger and better, but making them fast and affordable to run is hard—especially the “decoding” step where the model writes one token at a time and constantly fetches past information from memory. Faster memory is the key, and 3D‑DRAM provides that. But designing these systems is complex and expensive if you rely on closed tools or have to build a chip to test every idea.
ATLAS changes the game by:
- Providing a reliable, open “wind tunnel” for AI chips using 3D‑DRAM.
- Letting teams try many “what if” scenarios safely and cheaply.
- Making it easier to program and reason about how LLM operations map onto real hardware.
Bottom line
This work gives researchers and companies a shared, accurate, and practical way to design and test next‑generation AI hardware that’s optimized for the toughest part of LLMs. That could lead to faster, more energy‑efficient AI services—from cloud chatbots to on‑device assistants—so they respond more quickly, cost less to run, and use less power.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of gaps left unresolved by the paper that future researchers could address:
- End-to-end inference coverage: Prefill (compute-intensive) is not modeled or evaluated; the framework and dataflow focus on decoding only. Examine full serving pipelines with prefill–decoding overlap and scheduling.
- Precision/quantization support: Only FP16 is validated. Add and validate INT8/FP8/BF16, mixed-precision, and quantization-aware kernels; quantify impacts on SRAM tiling, bandwidth, accuracy, and thermal/power.
- Energy and power modeling: Thermal control reduces frequency but there is no end-to-end energy per token, dynamic power models (compute, DRAM, interconnect), or DVFS/throttling/refresh adaptations under thermal constraints. Integrate calibrated, workload-dependent power models.
- Reliability under heat: No modeling of retention-time variation, refresh policies, ECC, scrubbing, or error rates across stacked dies at elevated temperatures. Evaluate performance/energy overheads of RAS features in 3D-DRAM.
- DRAM controller policies: Tile-level scheduling is implemented, but alternate policies (row-buffer management, bank-group-aware reordering, prefetching, out-of-order scheduling) tuned for LLM access patterns are unexplored.
- KV cache management realism: Benchmarks assume block/slot KV layouts, but dynamic allocation, eviction, defragmentation, fragmentation under multi-tenant serving (e.g., PagedAttention) and their performance impacts are not modeled.
- Multi-accelerator communication fidelity: Inter-device links are modeled with fixed bandwidth/latency, omitting topology, routing, protocol overhead, congestion, and NIC behavior (NVLink, CXL, RDMA, PCIe). Develop detailed, topology-aware models.
- Automatic partitioning/mapping: split_gemm/split_attention and core_array mappings are programmer-specified. Create compilers/auto-mappers that select partitions and communication schedules based on topology, workload, and hardware limits.
- Integration with mainstream DSLs/frameworks: The primitives are DSL-aligned, but there is no demonstrated end-to-end compilation from Triton/TileLang/PyTorch graphs to ATLAS kernels, nor correctness/performance validation of such toolchains.
- Inter-core interconnect exploration: Only 2D mesh is considered. Study alternative topologies (torus, concentrated mesh, dragonfly), router microarchitectures (virtual channels, QoS), and their effects on LLM workloads and congestion.
- Compute microarchitecture fidelity: Logic-die latency is modeled via FLOPs/SRAM traffic, not cycle-accurate systolic/SIMD implementations (pipeline hazards, instruction scheduling, bank conflicts). Validate across diverse microarchitectures.
- Validation scope and generalizability: Accuracy is shown for one silicon design and decoding-focused workloads. Extend validation to other model families (FlashAttention v2/v3, long-context methods), different precisions, and edge deployments.
- Prefetching and on-chip buffering: Overlap of DRAM loads and compute is modeled, but sophisticated prefetchers, double-buffer policies, SRAM capacity-induced thrashing, and tile reorderings are not explored.
- Thermal model validation in operation: Material properties are measured ex situ; in situ temperature traces under workload and vertical heat paths through copper pillars/HB interfaces are not validated against the simulator.
- Stacking depth impacts: The effects of varying the number of DRAM dies on bandwidth scaling, timing skew, thermal headroom, retention, and energy are not systematically explored.
- DRAM organization assumptions: The claim that LB reorganization leaves timing unchanged (<50 ps inter-die skew) is not empirically validated across process corners, temperatures, and aging; assess robustness.
- NUMA programming/runtime: MPMD primitives are provided, but there is no runtime that overlaps communication with compute, manages synchronization, or hides programmer burden; quantify synchronization and orchestration costs.
- Serving dynamics and concurrency: Mixed prefill/decoding concurrency, variable-length sequences, queueing, admission control, and kernel preemption are not modeled; analyze throughput/latency under realistic multi-tenant loads.
- Capacity and long-context limits: Impacts of KV cache fragmentation and capacity on very long contexts (e.g., 128K+), multi-session concurrency, and spill/fault handling are not evaluated.
- Host integration overheads: For memory-attached deployments, CPU/GPU driver, DMA, coherency, and kernel launch overheads are abstracted away; quantify these and their interactions with NUMA communication.
- Manufacturing/yield/cost: Very large dies and stacks raise yield, redundancy, repair, and cost concerns; no modeling of defect tolerance or performance impact of spare-row/column mechanisms.
- Security/isolation: Multi-tenant isolation on shared 3D-DRAM, NUMA side-channels, and communication-pattern leakage are not addressed; propose isolation mechanisms and evaluate overheads.
- Reproducibility/open-sourcing: The framework “will be open-sourced,” but the paper lacks a concrete release plan for code, parameters, workloads, and scripts necessary to reproduce results and extend the models.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed now, leveraging the paper’s open, silicon-validated framework (ATLAS), unified programming model, and 3D‑DRAM/accelerator abstractions.
- 3D‑DRAM LLM accelerator design space exploration (DSE)
- Sector: Semiconductors, Cloud AI hardware, EDA/CAD
- What: Use ATLAS to sweep physical-bank/logical-bank (PB/LB) organizations, channel counts, I/O rates, core counts, SRAM sizes, and interconnect topologies to co-optimize memory bandwidth, compute, and thermal limits for LLM decoding.
- Tools/workflows: Define YAML architecture configs + Python kernels using provided primitives; enable autotuning; iterate with cycle-level results and thermal feasibility; compare against GPU/HBM and prior 3D-accelerator baselines.
- Assumptions/dependencies: Availability of HB 3D‑DRAM process options; accurate per-block power numbers; target workloads are LLM decoding (prefill runs on GPUs/TPUs).
- Accelerator kernel development using SPMD/MPMD primitives
- Sector: Software tooling, Compiler/DSL ecosystems (PyTorch/Triton/TVM), AI hardware startups
- What: Implement GEMM and fused attention with the provided DRAM/SRAM/tile primitives; partition across cores; prototype collective patterns (e.g., TidalMesh all-reduce).
- Tools/workflows: Write kernels in Python aligning with Triton/TileLang semantics; auto-generate tile schedules; run cycle-accurate simulations; export placements and execution descriptions.
- Assumptions/dependencies: Quantization/custom ops may require extending primitives; topology-aware communication is needed for best performance.
- Thermal sign-off and frequency derating for stacked DRAM/compute
- Sector: Packaging, Reliability, EDA thermal analysis
- What: Use the HotSpot-based analyzer (with measured material properties) to validate transient temperatures and DRAM retention constraints; auto-derate clock if limits are exceeded.
- Tools/workflows: Provide power/area and stack composition; run transient analysis; feed back adjusted frequency into performance simulation.
- Assumptions/dependencies: Accurate per-layer thermophysical data and power models; access to retention limits for target DRAM technology.
- Cloud inference planning with prefill/decoding split
- Sector: Cloud service providers, MLOps
- What: Model deployments where GPUs/TPUs handle prefill and 3D‑DRAM accelerators handle decoding; size clusters, pick TP/EP degrees, and inter-device bandwidth needs; evaluate throughput vs. latency vs. power.
- Tools/workflows: Simulate decoding-only workloads at various batch sizes/context lengths; model inter-device links (NVLink/CXL/RDMA) with the fixed-bandwidth abstraction.
- Assumptions/dependencies: Accurate link bandwidths/latencies; production scheduling often requires integration with system simulators and real runtime traces.
- Compiler/backend prototyping for 3D‑DRAM accelerators
- Sector: Software tooling, Frameworks
- What: Build a backend mapping high-level ops to the ATLAS primitives; integrate with Triton/TileLang or TVM to auto-generate kernel schedules and core partitions.
- Tools/workflows: Translate IR to tensor/alloc/copy/gemm/reduction calls; emit split_gemm/split_attention + send/recv sequences; autotune tiling factors.
- Assumptions/dependencies: Needs codegen glue; initial focus on FP16 decoding; additional work for training/quantized inference.
- Training and education in 3D integration and memory-centric architecture
- Sector: Academia, Workforce development
- What: Use ATLAS as an open lab for courses on accelerators, 3D packaging, memory systems, and LLM systems; assign projects that co-tune compute/memory/interconnect and thermal constraints.
- Tools/workflows: Distribute open configs and kernels; compare design choices against a silicon-referenced simulator with ≤8.57% error.
- Assumptions/dependencies: Public release and maintenance of ATLAS; course integration.
- Vendor guidance for HB 3D‑DRAM and controller design
- Sector: Memory vendors, IP providers
- What: Validate PB/LB organizations, mini-TSV layouts, command scheduling, and I/O widths against LLM decoding traces; quantify bandwidth utilization and row-buffer hit rates with realistic tiling.
- Tools/workflows: Feed operator-derived DRAM traces into the simulator; co-design internal controller policies for LLM access patterns.
- Assumptions/dependencies: Internal timing/energy models must be parameterized for the vendor’s process; controller RTL validation still needed for productization.
- Collective communication and topology-aware libraries for mesh NoCs
- Sector: Systems software, Libraries
- What: Optimize all-reduce/all-to-all on 2D mesh with TidalMesh or custom collectives for NUMA accelerators; benchmark against ring/tree variants using ATLAS interconnect model.
- Tools/workflows: Implement send/recv patterns via MPMD primitives; measure contention and latency under different topologies/sizes.
- Assumptions/dependencies: Real systems may have different router pipelines/VCs than modeled; library needs hardware-specific tuning.
- Capacity planning and TCO modeling for LLM serving
- Sector: Finance/ops within cloud providers and enterprises
- What: Use ATLAS to estimate throughput/latency and energy for decoding-heavy workloads; size fleets and power budgets; compare to GPU/HBM setups.
- Tools/workflows: Simulate representative models (dense and MoE), batch sizes and contexts; integrate with cost models to quantify $/token and joules/token.
- Assumptions/dependencies: Simulator parameters aligned with intended silicon; non-decoding workloads excluded.
- On-device LLM accelerator feasibility studies
- Sector: Edge devices (phones, laptops, XR, embedded)
- What: Evaluate swapping LPDDR-based NPUs for HB 3D‑DRAM accelerators for low-latency, longer-context assistants; co-design memory footprint and KV-cache layouts.
- Tools/workflows: Model smaller logic nodes/areas, reduced channels; simulate decoding with shorter power envelopes; adapt KV cache block management.
- Assumptions/dependencies: HB 3D‑DRAM availability and cost on edge; thermal envelope constraints; feature support for sleep/retention modes.
Long-Term Applications
These opportunities require further research, supply-chain maturity, or deep integration beyond the current paper’s scope.
- Standardized programming model and APIs for memory-centric LLM accelerators
- Sector: Software ecosystems, Standards bodies
- What: Evolve the SPMD/MPMD primitive set into a common API (akin to CUDA/NCCL) for 3D‑DRAM accelerators; enable portable kernels and collective libraries across vendors.
- Potential products: A standardized “3D‑DRAM Accelerator Runtime” with compiler integration and collective ops.
- Dependencies: Broad vendor/community adoption; spec and conformance tests; alignment with Triton/TileLang/TVM and mainstream frameworks.
- Automated compiler and runtime for partitioning and communication scheduling
- Sector: Compiler research, Frameworks
- What: End-to-end tooling that infers inter-core splits, auto-selects core-array mappings, and synthesizes topology-aware collectives; integrates autotuning and thermal constraints.
- Potential products: TVM/Triton backends with automatic split_gemm/split_attention + comm synthesis; runtime that adapts to NoC congestion.
- Dependencies: Advanced cost models; integration with graph compilers; validation on multiple hardware generations.
- Thermal- and retention-aware dynamic runtime control
- Sector: Run-times, Reliability engineering
- What: Closed-loop controllers that modulate frequency/voltage and tile sizes based on predicted retention margins and transient hotspots; coordinate with memory-controller policies.
- Potential products: Firmware/driver modules for thermal guard-banding; runtime knobs exposed to datacenter schedulers.
- Dependencies: Fast, online thermal proxies; validated retention models; safe operating envelopes from DRAM vendors.
- Co-packaged compute+3D‑DRAM products for consumer and enterprise devices
- Sector: Hardware OEMs (PCs, mobiles, XR), Robotics, Automotive
- What: New SKUs with tightly integrated 3D‑DRAM accelerators for on-device LLMs (private assistants, copilots) and latency-critical reasoning in robots/vehicles.
- Potential products: Laptop SoCs with decoding accelerators; XR headsets with low-latency dialogue; automotive ECUs for in-cabin assistants.
- Dependencies: Cost/yield of hybrid bonding at scale; robust thermal solutions; ruggedization for automotive; software ecosystem maturity.
- Broadening beyond LLMs to other memory-intensive workloads
- Sector: Databases/analytics, Graph processing, Recommenders, Retrieval
- What: Extend primitives/operators to attention-like kernels in retrieval-augmented generation, graph attention networks, sparse matmul, and large embedding lookups.
- Potential products: Near-memory accelerators for vector DBs, GNN inference, and large-scale recommenders.
- Dependencies: Operator coverage beyond GEMM/attention; irregular access scheduling; integration with storage hierarchies.
- Supply-chain and manufacturing standards for HB 3D‑DRAM stacks
- Sector: Policy, Industry consortia
- What: Define reliability/thermal test protocols (e.g., TDTR-backed material characterization) and retention limits for stacked memory under compute heat.
- Potential outcomes: Interoperable specs for 3D stacking interfaces, TSV/mini-TSV reliability criteria, and thermal sign-off standards.
- Dependencies: Collaboration among memory vendors, foundries, OSATs; standard-setting forums.
- Energy and sustainability policy for AI inference
- Sector: Policymakers, Regulators, Sustainability officers
- What: Leverage 77–83% lower DRAM energy/bit (vs. HBM estimates) to craft incentives and procurement guidelines for energy-efficient inference hardware; create reporting standards (joules/token).
- Potential outcomes: Green AI tax credits; datacenter energy benchmarks that include memory subsystem efficiency.
- Dependencies: Independent validation at production scale; lifecycle assessments; alignment with grid/thermal constraints.
- Benchmark suites and MLPerf categories for decoding on memory-centric accelerators
- Sector: Benchmarking consortia
- What: Establish standardized decoding workloads (dense/MoE, batch/context regimes) and metrics for 3D‑DRAM accelerators; include thermal compliance gates.
- Potential outcomes: New MLPerf Inference category; reproducible open-source toolchains built atop ATLAS.
- Dependencies: Community adoption; continuous integration with open tools; vendor participation.
- Reliability and security research in 3D stacks
- Sector: Academia, Security engineering
- What: Study ECC policies, retention-failure modes, thermal and power side channels in stacked DRAM under high-bandwidth access; propose mitigations.
- Potential outcomes: Hardened memory controllers; runtime scrubbing policies; side-channel-resistant interconnect protocols.
- Dependencies: Access to failure data and models; collaboration with vendors; possibly invasive measurements.
- Orchestration for heterogeneous prefill/decoding fleets
- Sector: Cloud schedulers, MLOps
- What: Cluster managers that co-schedule GPU prefill with 3D‑DRAM decoding, optimizing interconnect usage and token-throughput SLAs; model-parallel routing (TP/EP).
- Potential products: Schedulers that query ATLAS-derived performance envelopes to place workloads; admission control tuned for KV-cache pressure.
- Dependencies: Integration with real orchestration stacks (Kubernetes/RDMA fabrics); fine-grained telemetry.
- Financial services and interactive applications with strict latency SLOs
- Sector: Finance, Customer support, Gaming
- What: Adopt memory-centric decoders for ultra-low-latency generation and long contexts (e.g., trading assistants, live support, NPC dialogue).
- Potential products: Dedicated inference nodes using 3D‑DRAM accelerators for latency-critical streams.
- Dependencies: Hardware availability; integration with existing inference gateways; risk/compliance evaluation.
Notes on general feasibility across applications
- The simulator is validated against a specific 3D‑DRAM test chip with ≤8.57% error; porting to other processes/nodes requires parameter retuning.
- The software model targets LLM decoding (FP16) and assumes model-parallel deployments (TP/EP) and collective communication; training and non-LLM workloads require extensions.
- Inter-device links are modeled with a fixed-bandwidth abstraction; real fabrics may exhibit non-idealities (congestion, NUMA placement).
- Thermal analyses rely on accurate material/power inputs; conservative derating may be needed in early designs.
- Hybrid-bonding multi-layer DRAM availability, yield, and cost are pacing factors for mass-market products.
Glossary
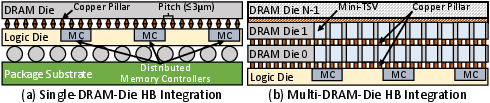
- 3D-Accelerators: Accelerators that tightly integrate compute on a logic die with stacked 3D-DRAM to speed up LLM inference, especially decoding. "3D-Accelerators adopt a distributed multi-core architecture."
- 3D-DRAM: Three-dimensionally stacked DRAM integrated with a logic die, offering very high bandwidth and short data paths. "hybrid-bonding-based 3D-DRAM"
- Abstract Syntax Tree (AST): A structured representation of program code used for analysis and transformation. "parsing the operator implementation into an abstract syntax tree (AST)"
- ACT/PRE: DRAM activate and precharge operations that open and close rows for access. "activate/precharge operations (ACT/PRE)"
- All-reduce: A collective communication that reduces values across participants and distributes the result back to all. "1D all-reduce"
- All-to-all: A collective where each participant sends distinct data to every other participant. "all-reduce/all-to-all"
- ATLAS: The proposed full-stack, silicon-validated simulation framework for 3D-DRAM-based LLM accelerators. "we present ATLAS"
- Autotuning: Automated search for optimal parameters (e.g., tile sizes) to maximize performance. "We provide an autotuning option in the programming interface"
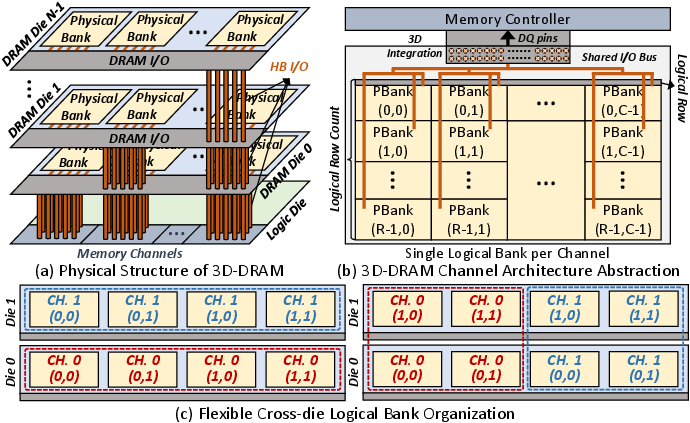
- Bank partitions: Groupings of physical DRAM banks assigned to a compute core to align memory and compute. "PBs on each DRAM die are grouped into bank partitions of equal size."
- BookSim2: A cycle-accurate interconnection network simulator used to model NoCs. "built upon BookSim2"
- CMOS: Complementary metal–oxide–semiconductor technology used to implement compute logic on the logic die. "customize compute logic in CMOS technology"
- CXL: Compute Express Link, a high-speed CPU–device interconnect standard. "CXL"
- Design Space Exploration (DSE): Systematic evaluation of architectural choices to identify high-performance designs. "design space exploration (DSE)"
- Domain-Specific Languages (DSLs): Specialized programming languages for efficiently expressing domain operations (e.g., deep learning kernels). "domain-specific languages (DSLs)"
- DRAM row-buffer: An internal DRAM buffer holding an open row; high utilization reduces access latency. "row-buffer utilization"
- Expert Parallelism (EP): Model-parallel strategy partitioning mixture-of-experts across devices. "tensor/expert parallelism (TP/EP)"
- FP16: 16-bit floating-point format commonly used for faster, lower-power ML computation. "FP16"
- Flit: A flow-control digit; the basic unit transferred over an on-chip network link. "flit size"
- Gated Linear Unit (GLU): An activation structure using gates to modulate linear projections in FFNs. "gated linear unit (GLU)"
- GEMM: General Matrix Multiply; a core linear algebra operation underpinning many DL workloads. "GEMM can express all mainstream tensor workloads."
- Group-Query Attention (GQA): An attention variant where multiple query heads share one KV head. "group-query attention (GQA)"
- HBM: High Bandwidth Memory, a stacked memory technology used in GPUs. "over HBM"
- HotSpot-7.0: A thermal modeling tool used to simulate transient temperatures in stacked chips. "developed upon HotSpot-7.0"
- HR-STEM: High-resolution scanning transmission electron microscopy for measuring layer structures. "high-resolution scanning transmission electron microscopy (HR-STEM)"
- Hybrid bonding (HB): A die-to-die bonding technology enabling dense, low-resistance connections between DRAM and logic. "Hybrid bonding (HB) is a next-generation integration technology"
- Inter-die timing skew: Clock or signal timing differences between stacked dies that can affect synchronization. "inter-die timing skew in 3D-DRAM is below 50ps"
- KV Cache: Stored key/value vectors from prior tokens used during autoregressive decoding to avoid recomputation. "which is known as KV Cache"
- KV head: A head (set of dimensions) associated with key/value vectors used by one or more query heads. "KV head"
- Logic die: The silicon die beneath the DRAM stack that implements compute engines and controllers. "the logic die supports customized CMOS compute logic"
- LPDDR-DRAM: Low-power DDR DRAM used in edge devices and mobile systems. "LPDDR-DRAM"
- Mesh topology: A 2D grid interconnect for cores on-chip, commonly used in NoCs. "Mesh topology"
- Mixture-of-Experts (MoE): A model architecture where a subset of expert networks is selected per token. "mixture-of-experts (MoE)"
- mini-TSVs: Small through-silicon vias used to connect stacked DRAM dies. "mini-TSVs"
- Network-on-Chip (NoC): The on-chip interconnect fabric connecting cores and memory controllers. "Network-on-Chip (NoC)"
- Near-memory processing: Placing compute units close to or within memory components to reduce data movement. "near-memory processing designs"
- Non-uniform memory access (NUMA): A memory architecture where access latencies/bandwidths vary by core–memory proximity. "non-uniform memory access (NUMA) abstraction"
- NPU: Neural Processing Unit; a specialized accelerator for neural network workloads. "NPU"
- NVLink: NVIDIA’s high-bandwidth interconnect for scaling multi-accelerator systems. "NVLink"
- NVLink Fusion: An NVLink feature improving aggregated bandwidth or connectivity between devices. "NVLink Fusion"
- Online softmax: A numerically stable streaming softmax used to fuse attention computations efficiently. "via online softmax"
- Output-stationary dataflow: A compute dataflow that keeps output tiles stationary in fast memory while accumulating partial sums. "Under output-stationary dataflow"
- Physical bank (PB): The basic DRAM array unit in a die, grouped to form logical banks. "physical banks (PBs)"
- Q/K/V vectors: Query, key, and value vectors used in transformer attention computations. "query/key/value (Q/K/V) vectors"
- Ramulator2: A cycle-accurate memory simulator used to model DRAM controller and timing behavior. "into Ramulator2"
- RDMA: Remote Direct Memory Access, enabling direct memory transfers across nodes with low CPU involvement. "e.g., RDMA"
- Reduce-scatter: A collective that reduces data across participants and scatters different partitions to each. "ring reduce-scatter example."
- SRAM: On-chip static RAM used for high-speed buffering of tiles and intermediate results. "SRAM buffer"
- SPMD: Single-Program Multiple-Data; all cores run the same program on different data shards. "single-program multiple-data (SPMD) model"
- TDTR: Time-domain thermoreflectance, a technique to measure thermal properties of materials. "time-domain thermoreflectance (TDTR) test system"
- Tensor Parallelism (TP): Model-parallel strategy that partitions weight tensors across devices. "tensor/expert parallelism (TP/EP)"
- TidalMesh: A communication algorithm optimized for collective operations on 2D mesh NoCs. "TidalMesh algorithm"
- TileLang: A modern DSL for writing tile-optimized GPU/accelerator kernels. "TileLang"
- Triton: A DSL for writing high-performance GPU-style kernels with Pythonic syntax. "Triton"
Collections
Sign up for free to add this paper to one or more collections.