- The paper presents ARM, a novel reward modeling framework that uses tri-state advantage signals and a MIMO temporal transformer to improve long-horizon robotic manipulation.
- It achieves dense, regression-sensitive reward reconstruction, vastly improving performance on complex tasks like bimanual towel folding with a 99.4% success rate.
- The method increases labeling throughput and inference speed while reducing manual reward engineering, making it scalable for generalist robot learning.
Advantage Reward Modeling for Long-Horizon Robotic Manipulation
Introduction and Motivation
The challenge of credit assignment in reinforcement learning (RL) for long-horizon robotic manipulation stems largely from sparse reward structures. While dense rewards can accelerate convergence by providing frequent feedback, their manual engineering demands extensive human labor and is fundamentally limited in handling realistic, non-monotonic, and error-prone behaviors. Existing reward annotation protocols—ranging from vision-LLM (VLM) predictions to subtask segmentation—exhibit issues of unreliability, quantization ambiguity, and inability to robustly handle recovery and regressive behaviors.
To address these inadequacies, "ARM: Advantage Reward Modeling for Long-Horizon Manipulation" (2604.03037) introduces a scalable framework for reward signal generation and policy improvement, focused explicitly on relative advantage modeling over the more brittle paradigm of absolute progress estimation.
ARM Framework Architecture
The ARM framework is decomposed into three primary components:
- Advantage Reward Model (ARM): Implements a Multi-Input Multi-Output (MIMO) Temporal Transformer supervised via a lightweight tri-state labeling regime (progressive, regressive, stagnant). ARM ingests multimodal inputs including visual features, proprioceptive robot states, and task instructions to estimate interval-wise advantage transitions.
- Automated Progress Reconstruction: ARM outputs local advantage predictions which are globally stitched using an accumulation strategy coupled with terminal state anchoring to form high-fidelity, dense reward signals.
- Advantage-Weighted Behavior Cloning (AW-BC): Downstream policy training leverages ARM’s dense, advantage-weighted rewards within a robust reweighting scheme, mitigating dataset heterogeneity and filtering suboptimal demonstrations.
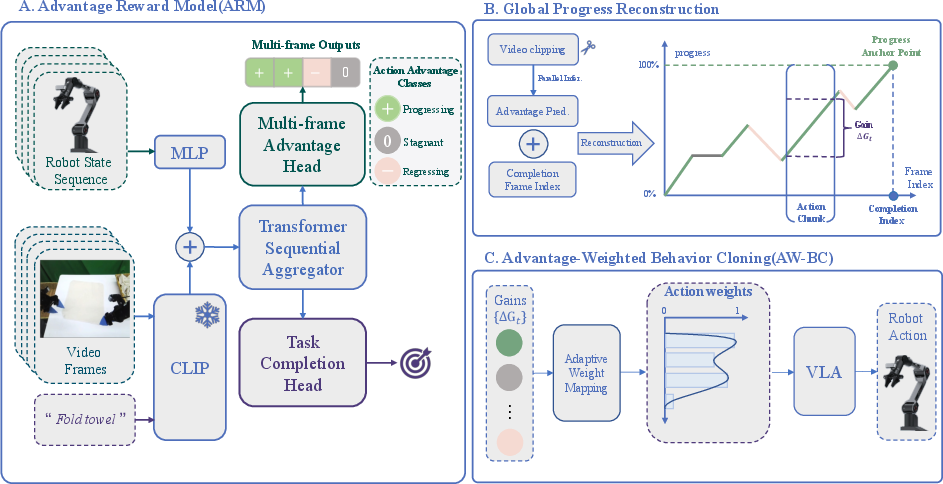
Figure 1: ARM system overview. The framework fuses a MIMO-based Temporal Transformer for advantage classification, an automated progress reconstruction pipeline, and an AW-BC algorithm for policy optimization using relative gains.
Previous reward models often employ MISO architectures that compress historical context into a single reward output, suffering from poor temporal disambiguation in complex manipulation. ARM’s MIMO design natively predicts dense advantage signals over parallel intervals within a causal temporal window, efficiently resolving motion intent, regressions, and subtle recovery actions.
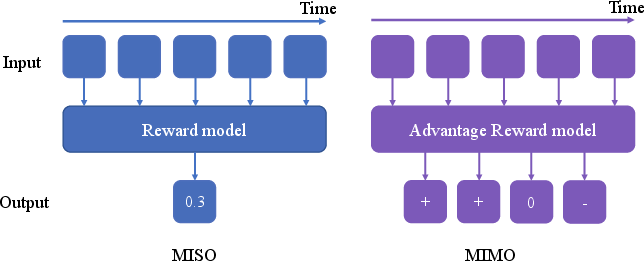
Figure 2: Contrasting MISO and MIMO reward architectures, with MIMO enabling temporally contextualized, multi-output predictions across input segments.
Tri-State Labeling Protocol
Continuous-valued progress labeling introduces excessive annotator bias and inconsistency. ARM reframes annotation as categorical tri-state classification ({+1, 0, -1}; progressing, stagnant, regressing), dramatically reducing cognitive demand and boosting cross-annotator reliability. Initial human-labeled seeds are rapidly scaled via semi-automated model inference, enabling the accumulation of large-scale training corpora with minimal human oversight.

Figure 3: Illustration of the tri-state advantage labeling workflow on a demonstration episode, delineating intuitive progress, regression, and stagnation intervals.
Automated Progress Reconstruction
ARM’s MIMO predictions are globally aggregated into trajectory-wide dense rewards through interval accumulation, with the task completion prediction head supplying absolute anchors for normalization. This strategy avoids the non-monotonic artifacts and drift seen in approaches that rely solely on temporal segmentation or fixed heuristic boundaries.
Task: Long-Horizon Bimanual Towel Folding
ARM is evaluated on a complex, 8-stage bimanual towel-folding task with realistic failure modes, error recovery maneuvers, and long temporal dependencies. Each episode requires both fine-grained manipulation and recovery from regressive errors, pushing the limits of dense reward modeling.

Figure 4: Overview of the bimanual towel-folding task, showcasing extraction, progressive multi-stage folding, and final placement.
Results: Reward Quality, Annotation Efficiency, and Policy Improvement
Reward Precision and Robustness
ARM achieves a Mean Squared Error of $0.0014$ in progress curve alignment (vs. $0.0059$ for SARM [chen2025sarmstageawarerewardmodeling]), with perfect accuracy in terminal state identification across success and failure episodes. Critically, ARM reconstructs smooth, monotonic progress curves that accurately capture regressive dips, outstripping baseline reward models.
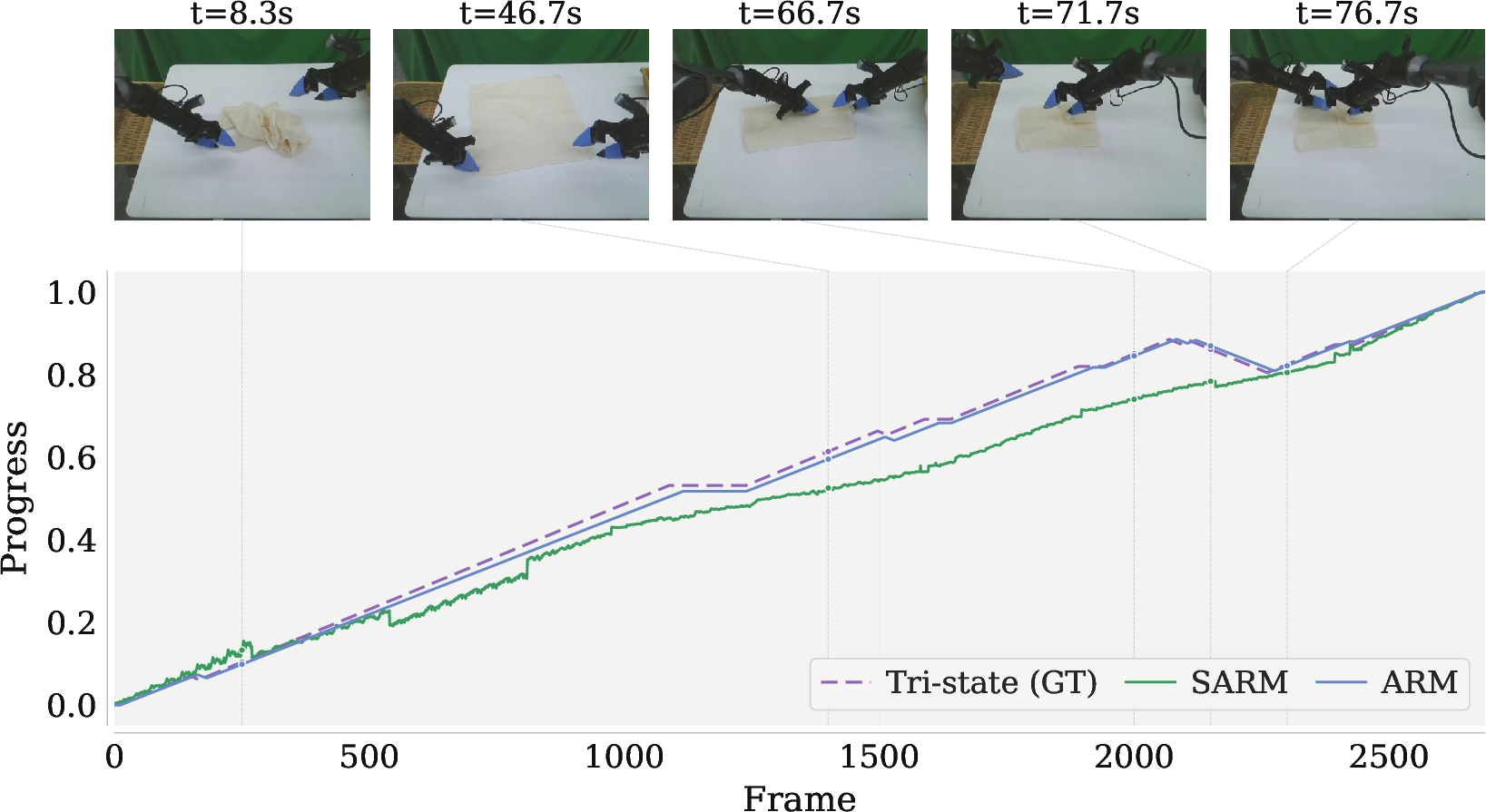
Figure 5: ARM progress reconstruction versus SARM and ground truth; ARM yields smooth, precise, regression-sensitive curves.
Labeling Throughput and Signal Consistency
Tri-state annotation protocol improves human sample throughput by 2.5× relative to subtask segmentation and provides demonstrably smoother and more temporally consistent reward signals than both manual and VLM-generated segmentation.
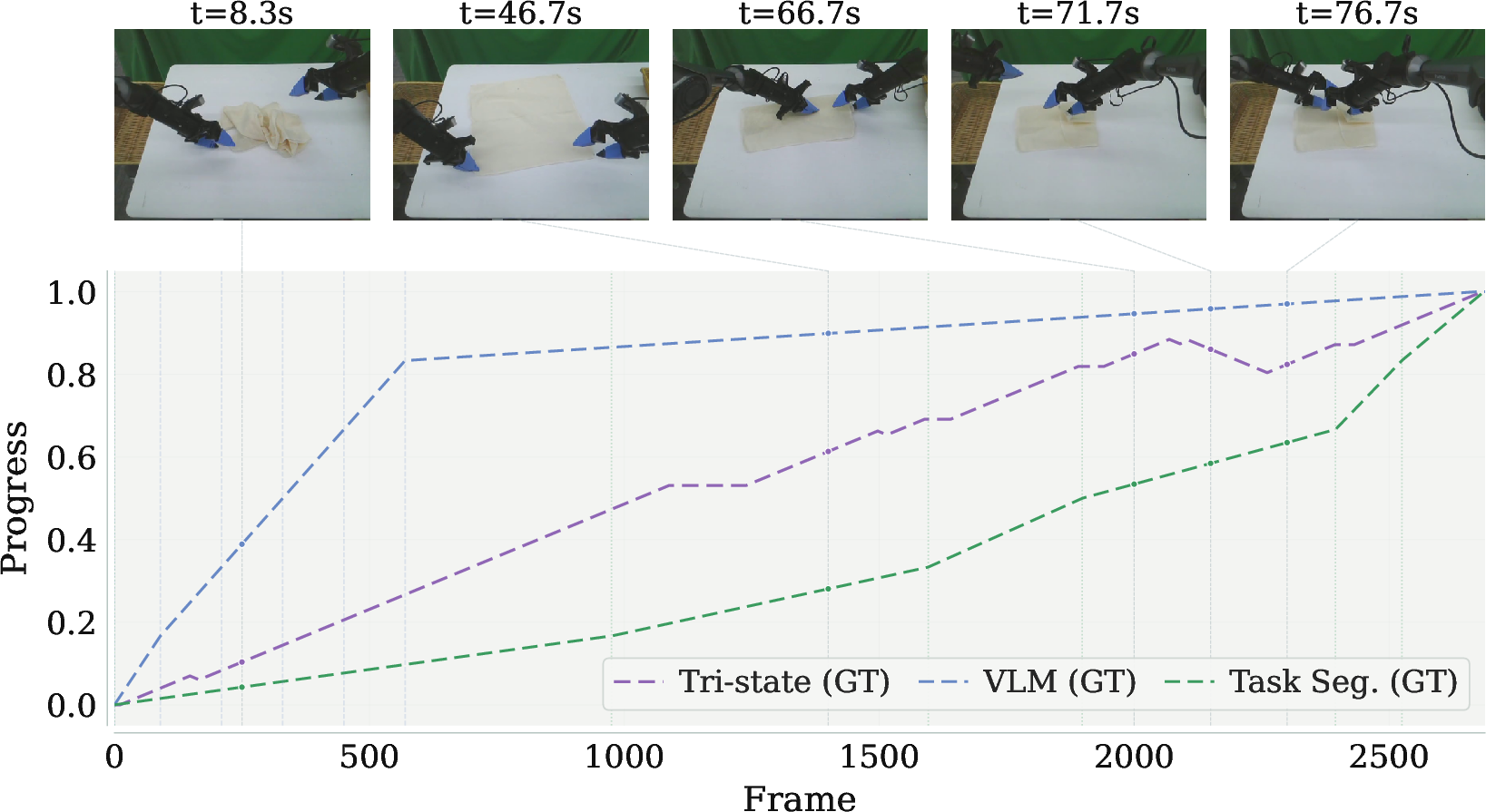
Figure 6: Tri-state ARM yields smooth, dense progress signals, surpassing stepped curves of prior methods.
AW-BC policies trained with ARM-reconstructed rewards achieve a 99.4% success rate on the long-horizon towel-folding task—substantially surpassing Behavior Cloning and previous Reward-Aligned BC baselines. The improvement is robust across throughput and objective folding precision metrics. The ablation study isolates the strength of the tri-state protocol (+13.8% success) and AW-BC (+7.1%) over prior frameworks.
Architectural and System Efficiency
MIMO-based ARM delivers a 13.7× speedup in inference over VLM pipelines, and 3.6× over SARM, a critical factor for large-scale robotic dataset deployment.
ARM is deployed on a 6-DoF bimanual robotic platform, leveraging high-fidelity multimodal perception and 14D proprioceptive control, validated on real hardware.
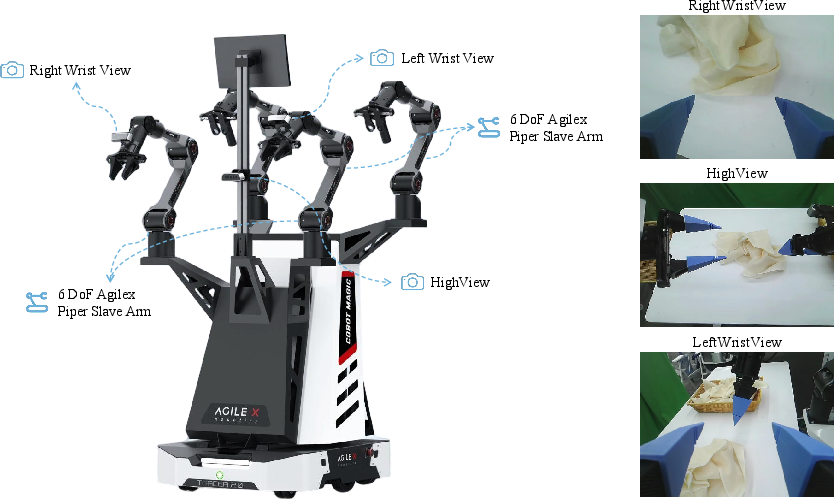
Figure 7: ARM real-world robotic setup with rich multi-camera and sensor integration for continuous manipulation.
Qualitative Model Behavior
ARM reliably identifies non-monotonic progress phenomena, such as temporary regression during recovery or adjustment, and aligns predicted progress dips with ground truth in real time.
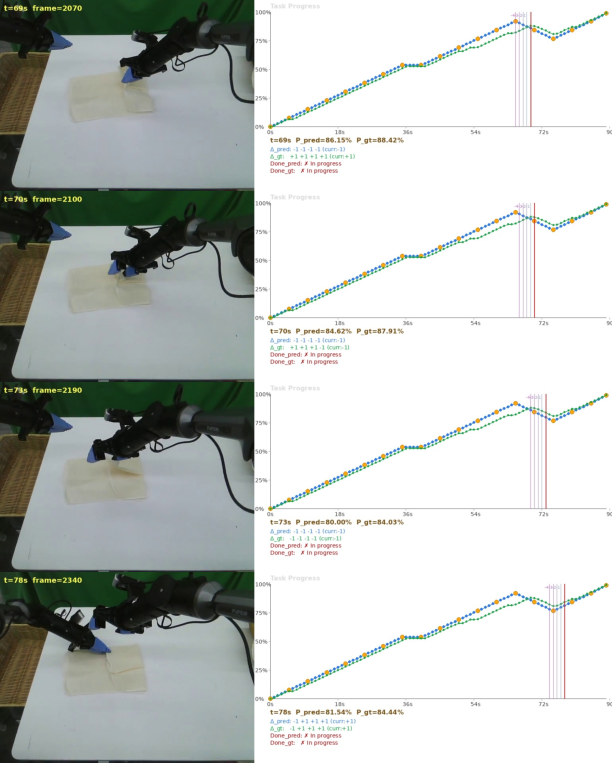
Figure 8: ARM inference — third-person task snapshots aligned with ARM-predicted and ground-truth progress dips during transient regressions.
Implications and Future Directions
By reformulating reward modeling around task-agnostic, relative advantage signals, ARM eliminates the critical reward engineering bottleneck in long-horizon RL for embodied agents. The demonstrated synergy between tri-state labeling and density-adaptive advantage-weighted imitation substantially enhances policy quality, data efficiency, and scalability. This approach is immediately extensible to arbitrary manipulation scenarios characterized by non-monotonicity and sparse success—surpassing the limitations of VLM-based, subtask-centric, or monotonic-reward architectures.
From a theoretical standpoint, ARM further aligns reward modeling with robust offline RL objectives—leveraging relative gains to approximate advantage functions without environmental rewards—thereby closing the loop between vision-language-action modeling and effective credit assignment.
Scalable, automated advantage annotation via methods such as ARM constitutes a critical step toward generalist, long-horizon embodied intelligence capable of self-improving through heterogeneous and weakly supervised data. Future work should integrate ARM-like reward modeling with online RL, hierarchical task decomposition, and unsupervised skill discovery across diverse VLA-capable robotic agents.
Conclusion
ARM establishes a scalable, annotation-efficient, and robust protocol for reward generation and policy improvement in long-horizon robotic manipulation. Its tri-state advantage labeling, MIMO temporal architecture, and AW-BC policy optimization collectively solve key limitations impeding Vision-Language-Action RL deployment. The framework’s 99.4% empirical success on a complex towel-folding task, together with marked gains in annotation and computational efficiency, validate ARM’s utility for future generalist robot learning systems.

