Robometer: Scaling General-Purpose Robotic Reward Models via Trajectory Comparisons
Abstract: General-purpose robot reward models are typically trained to predict absolute task progress from expert demonstrations, providing only local, frame-level supervision. While effective for expert demonstrations, this paradigm scales poorly to large-scale robotics datasets where failed and suboptimal trajectories are abundant and assigning dense progress labels is ambiguous. We introduce Robometer, a scalable reward modeling framework that combines intra-trajectory progress supervision with inter-trajectory preference supervision. Robometer is trained with a dual objective: a frame-level progress loss that anchors reward magnitude on expert data, and a trajectory-comparison preference loss that imposes global ordering constraints across trajectories of the same task, enabling effective learning from both real and augmented failed trajectories. To support this formulation at scale, we curate RBM-1M, a reward-learning dataset comprising over one million trajectories spanning diverse robot embodiments and tasks, including substantial suboptimal and failure data. Across benchmarks and real-world evaluations, Robometer learns more generalizable reward functions than prior methods and improves robot learning performance across a diverse set of downstream applications. Code, model weights, and videos at https://robometer.github.io/.



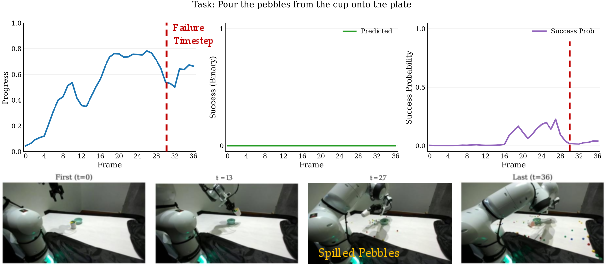
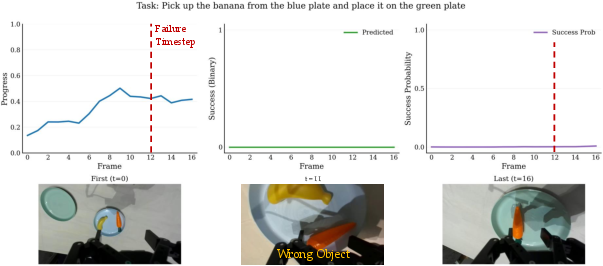
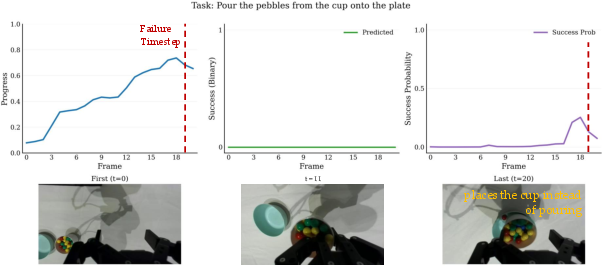

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Robometer, a new way to teach robots how to judge their own progress on a task using videos and written instructions. Think of it like giving robots a “report card” that scores how well they’re doing at each moment. Robometer learns not only from perfect examples but also from failed attempts, which makes it much more practical for real-world learning.
What questions are the researchers trying to answer?
The paper focuses on simple, big-picture questions:
- How can we build a reward system (a scoring method) that works across many robots, tasks, and camera views—not just one specific setup?
- How do we make that reward system learn from both good examples and mistakes without needing people to label everything?
- Does combining two kinds of feedback—“how far along are you?” and “which of these two tries is better?”—help robots learn faster and more reliably?
How did they do it? (Methods explained simply)
To make Robometer work, the researchers used three main ideas:
1) A huge, diverse video dataset (RBM-1M)
They collected over 1,000,000 videos (“trajectories”) of robots and humans performing tasks across 21 different types of robots. Some videos show successful attempts; many show failed or messy attempts. This variety is important because real robots often fail while learning.
- Trajectory = a video of one attempt to do a task (like “put the marker in the holder”).
- Instruction = a short sentence describing the task (e.g., “Place the red block on the blue plate.”).
2) A model that understands both video and language
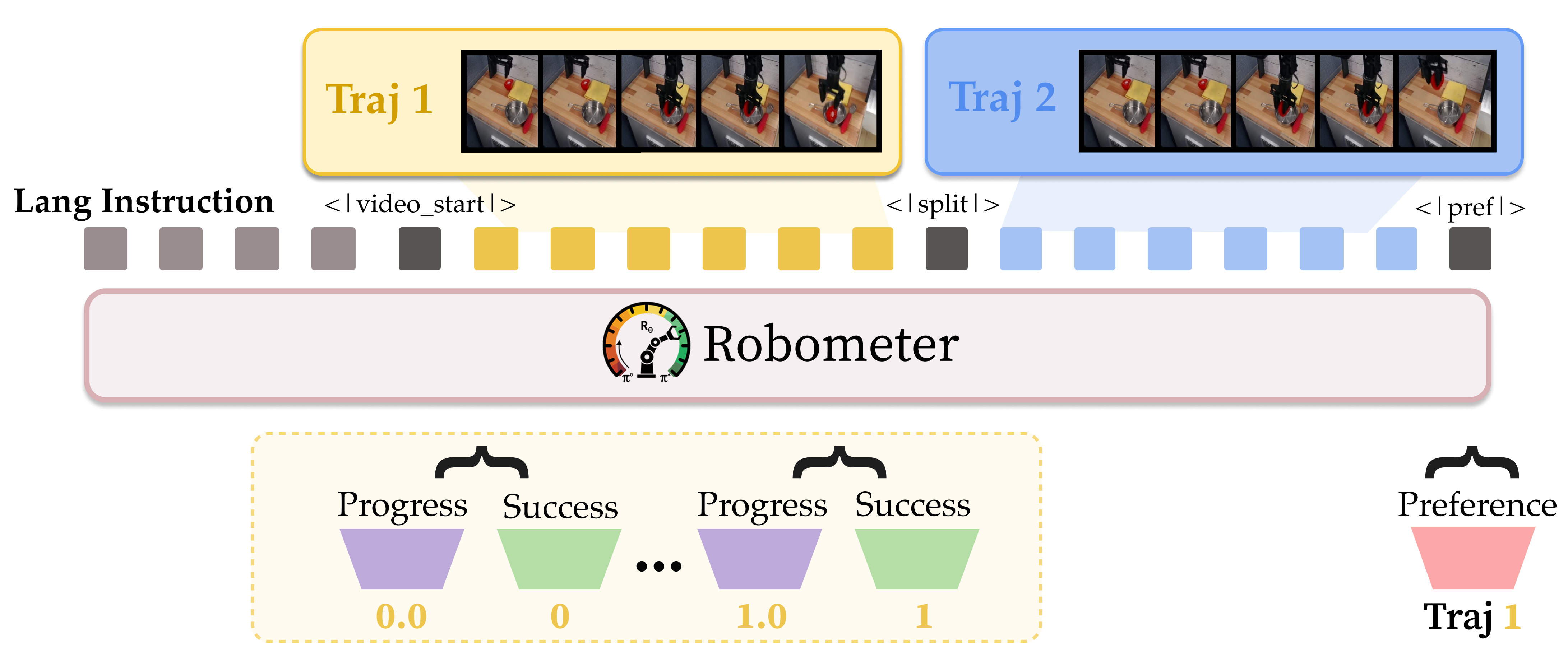
Robometer uses a video-LLM (a VLM) called Qwen3-VL-4B-Instruct. It watches the video and reads the instruction, then produces:
- A progress score for each video frame (like “you’re 60% done now”).
- A success signal at the end (did the task actually get completed?).
- A preference judgment between two videos (which attempt did the task better?).
You can think of “progress” like watching a race and tracking where each runner is on the track at each moment. “Preferences” are like comparing two runners and picking who is closer to the finish line at the end.
3) A training recipe that mixes progress and comparisons
Robometer learns using a “dual objective,” meaning it trains with two kinds of feedback at the same time:
- Frame-level progress: For good demo videos, the model learns that progress should go from 0% at the start to 100% at the end.
- Trajectory comparisons: For pairs of videos, the model learns which one better matches the instruction. This is super helpful for failures, where exact progress numbers are unclear, but it’s easy to say which of two attempts was better.
To make training examples richer and scalable, they used clever data tricks:
- Progress-based comparisons: Compare a successful demo to a failed attempt and teach the model which one is better.
- Instruction negatives: Show two different tasks and teach the model to only reward the video that matches the chosen instruction.
- Video rewind: Take a good video and reverse part of it to simulate “undoing” progress (like picking something up and then dropping it). This teaches the model what backtracking looks like.
These tricks help the model learn from lots of imperfect data without needing humans to label everything frame by frame.
What did they find, and why is it important?
Robometer consistently beats other reward models across many tests and real robot tasks. Here are the highlights:
- Better generalization: It works well on new tasks, new camera views, and new robots not seen during training.
- Stronger alignment to instructions: It gives high rewards when the video matches the instruction and low rewards when it doesn’t—important for multitask scenes.
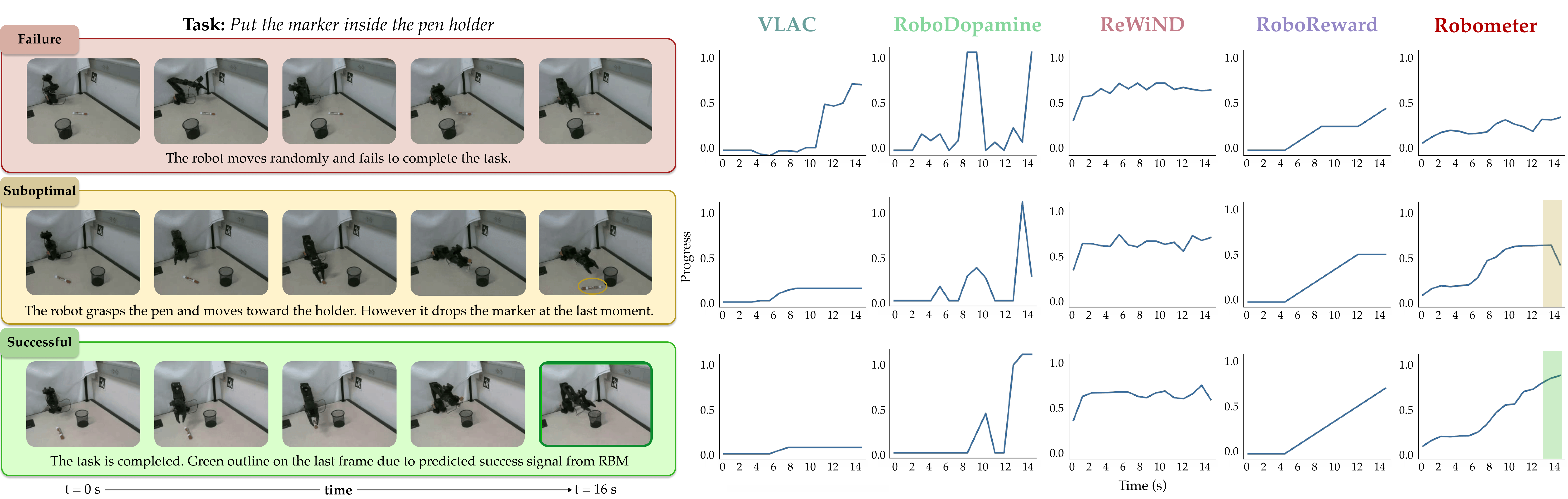
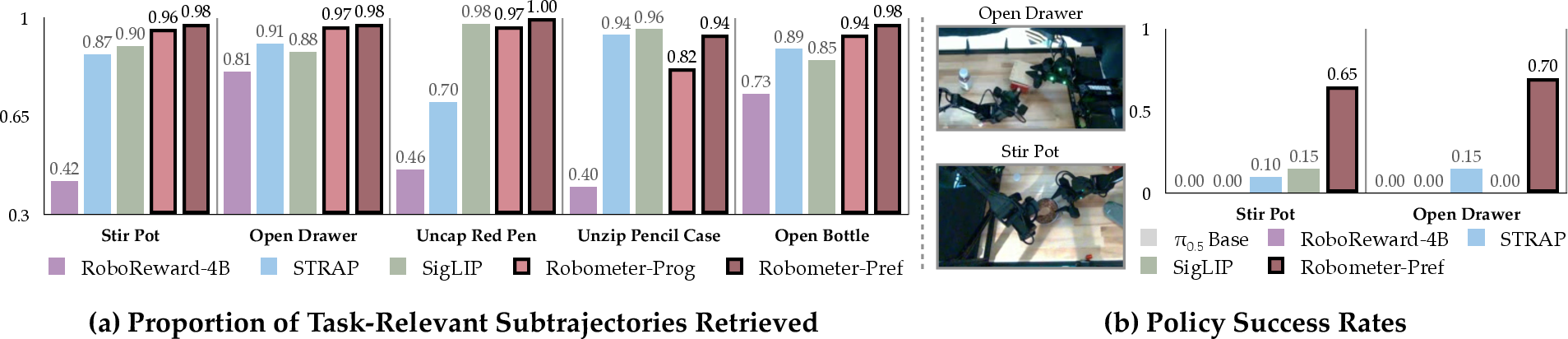
- Distinguishes success vs. failure: It’s much better at telling successful tries from suboptimal or failed ones. In tests, it improved trajectory ranking accuracy and separation (e.g., a 32% relative improvement in telling successful vs. suboptimal).
- Helps robots learn faster:
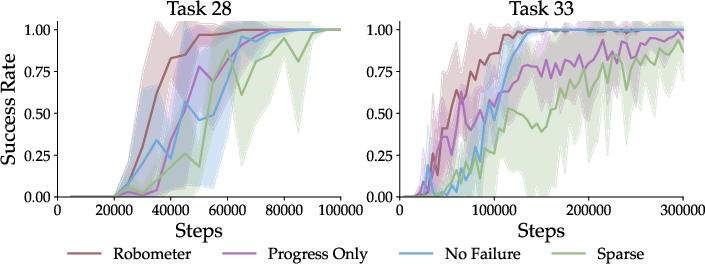
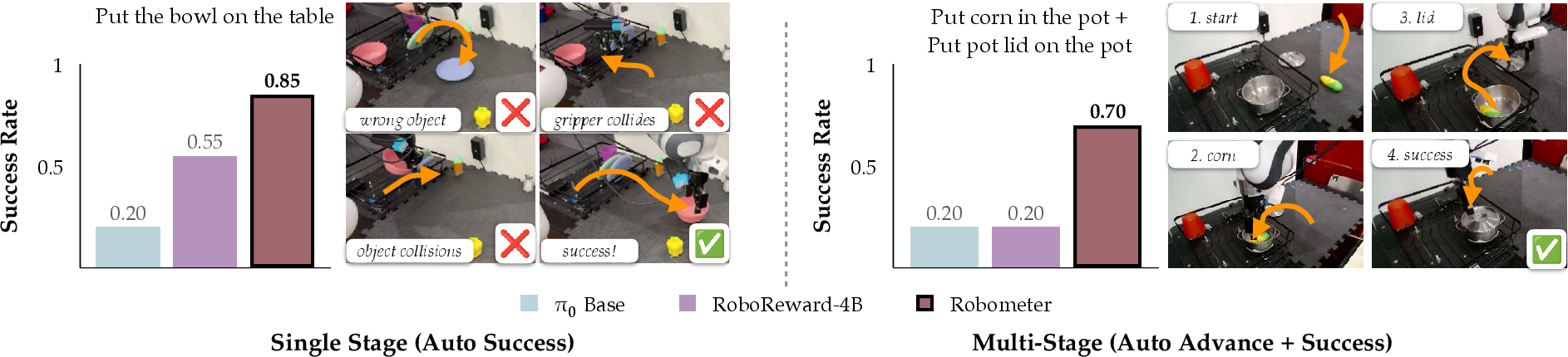
- Online reinforcement learning: Robometer boosted a base policy from 20% to 85% success in under an hour on one task, and from 20% to 70% on a two-stage task—about 2.5× better than a strong baseline.
- Offline reinforcement learning and other applications: Across multiple experiments, policies trained with Robometer achieved roughly 2.4–4.5× higher success rates than the best baseline.
- Ablation studies (fact-checking the design):
- Adding preference comparisons improves performance even when training only on good demos.
- Adding failed data improves performance further—comparisons are especially powerful for messy, realistic data.
- Using a pre-trained video-language backbone is crucial—training a smaller custom model from scratch performed much worse.
In short, Robometer produces more reliable rewards that help robots learn more efficiently and avoid being “tricked” by incorrect behaviors.
Why does this matter?
Robometer shows a practical way to scale robot learning:
- Real-world ready: Robots often see messy data and make mistakes. Robometer learns from that, instead of ignoring it.
- Less manual labeling: By using comparisons and clever augmentations like rewinding videos, the model learns without needing dense human annotations.
- Works across many robots and tasks: This makes it useful as a general tool for robotics labs, companies, and large training pipelines.
- Faster, safer learning: Better reward signals mean robots can learn correct behaviors faster, avoid repeating dangerous mistakes, and handle multi-step tasks more reliably.
Big picture: Robometer moves robotic learning closer to a world where robots can learn new tasks from raw video and text, get better over time, and do so at scale—even when the data isn’t perfect.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of concrete gaps, limitations, and open questions left unresolved by the paper that future work could address.
- Calibration of reward magnitude across tasks and embodiments remains unclear: how to ensure per-frame progress and final rewards are comparable across different instructions, robots, and scenes (beyond monotone ordering), and how this affects policy optimization and multi-task RL.
- Linear progress labeling assumption () for expert demonstrations likely mis-specifies true task advancement; the impact of non-linear or event-based progress supervision and learning progress schedules inferred from structure (e.g., keyframes, contact events) is not evaluated.
- Success labels are defined only at the final frame with a heuristic correction using 10 samples per data source; there is no automatic, scalable procedure to identify the true “completion frame” nor an analysis of label noise effects on reward calibration.
- Preference labels are generated without human annotation by contrasting expert vs. unlabeled failures or using synthetic augmentations; the noise, bias, and validity of these labels—especially in near-ties or subtle quality differences—are not quantified.
- Instruction-negative sampling sets progress to zero for trajectories of other tasks; the risk of penalizing generic or prerequisite behaviors (e.g., grasping an object common to multiple tasks) and the impact on language grounding fidelity remain untested.
- Video rewind augmentation models only a subset of failure modes (temporal reversals); there is no exploration of richer synthetic failures (e.g., occlusions, misgrasps, collisions, object misidentification, multi-object interference, partial progress regressions) or their relative utility.
- Fixed-length pairing and subsequence trimming may bias the model toward length-specific cues and undermine generalization to variable-duration tasks; methods for length invariance and their effect on preference predictions are not analyzed.
- Train–test mismatch in tokenization: progress tokens are inserted only for the first trajectory during training, but inference uses a single trajectory; whether inserting progress tokens for both videos (or alternative token placement strategies) affects performance is not ablated.
- The binary preference loss captures only pairwise ordering, not preference intensity; listwise or graded comparisons, and their influence on reward calibration and policy learning, are not investigated.
- The approach is tied to a single backbone (Qwen3-VL-4B-Instruct); scaling laws across backbone architectures and sizes, compute costs, training stability, and inference latency trade-offs are not reported.
- Robustness of language grounding is underexplored: there is no evaluation on paraphrases, long/ambiguous instructions, compositional templates, multilingual inputs, or instruction errors, nor strategies for handling them.
- Stage-based multi-step RL relies on a pre-trained VLM for stage decomposition at inference time; the reliability of stage detection, failure cases, and end-to-end benchmarks for multi-stage tasks without stage labels are not provided.
- OOD evaluation scope is limited (6 scenes, 3 institutions, select embodiments); generalization to more robots (e.g., legged, aerial), navigation, deformable object manipulation, outdoor settings, and challenging camera conditions has not been tested.
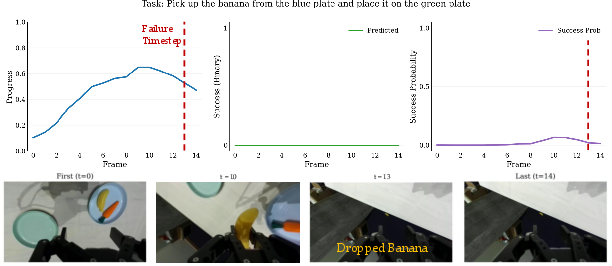
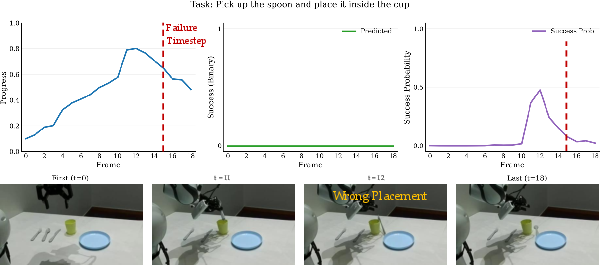
- Reward hacking remains a documented risk (e.g., high rewards for wrong-object interactions); no adversarial evaluation suite, grounding consistency checks, or regularization strategies are proposed to mitigate systematic misalignment.
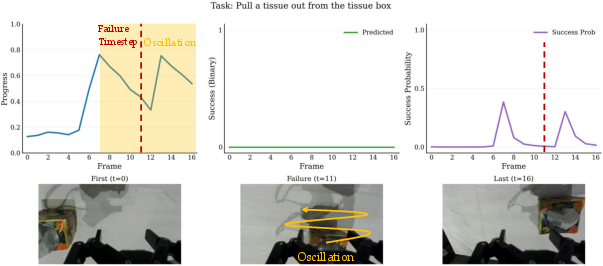
- Temporal credit assignment beyond monotonic progress is not addressed: the model’s ability to localize sub-events, detect irreversible errors, and assign fine-grained credit within complex trajectories is not validated.
- Success prediction usage (thresholding, calibration) is not characterized; false positives/negatives, ROC/AUPRC metrics, and sensitivity analyses—especially their impact on automated resets and stage transitions in RL—are missing.
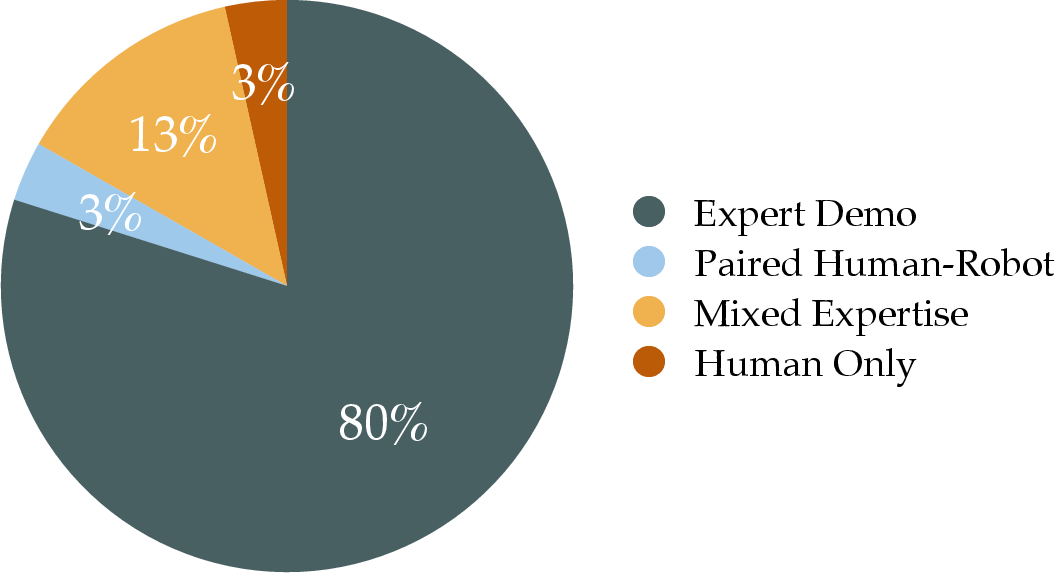
- Dataset composition and bias are insufficiently quantified: the mixture of human and robot trajectories, embodiment imbalance, scene distribution, and potential domain gaps (human-to-robot transfer) are not analyzed for fairness or representational coverage.
- Safety is not evaluated: failure detection beyond ranking, collision or hazard awareness, and risk-sensitive reward shaping to prevent unsafe behaviors are not studied.
- Offline RL results (e.g., IQL with mixed expertise data) are sketched but not systematically analyzed across algorithms, tasks, and hyperparameters; the sensitivity of policy performance to reward scale, normalization, and bootstrapping is not reported.
- Cross-task reward identifiability is unresolved: whether the learned rewards maintain consistent scales and transitivity across tasks for multi-task RL, and mechanisms to enforce inter-task calibration (e.g., anchor tasks or global preference graphs), remain open.
- Multi-modal extensions are not explored: integrating proprioception, object state estimates, audio, or tactile signals could reduce reliance on visual cues; the benefits and training strategies are unknown.
- Architectural design choices (e.g., location/number of learnable tokens, causal masks, video delimiters) are not ablated to establish which components are critical for progress vs. preference prediction.
- Failure detection claims are not benchmarked against specialized detectors across diverse failure taxonomies; sensitivity to camera occlusions, clutter, and rare failure types is not evaluated.
- Compute and deployment constraints are unreported: training time for 1M trajectories, GPU requirements, memory footprint, and real-time inference throughput on robots, as well as strategies for model compression/distillation, need investigation.
- Data licensing, annotation provenance, and reproducibility details (e.g., per-source label quality, failure type labels, scene metadata) are sparse; standardized metadata and transparent curation protocols would aid replication and principled analysis.
Practical Applications
Immediate Applications
The paper introduces Robometer—a general-purpose, video–language reward model that outputs dense per-frame progress, binary success, and trajectory-level preferences—and RBM-1M, a 1M-trajectory dataset with abundant failures. These enable plug-and-play reward shaping, automated success detection, and data-centric workflows with minimal annotation. The following use cases can be deployed now using the released code, weights, and recipes.
- Automatic online reinforcement learning with dense rewards and success-based termination (Robometer + DSRL, DreamZero)
- Sectors: robotics, manufacturing, logistics, labs
- What: Use Robometer’s per-frame progress as dense reward and its success signal to auto-terminate episodes; optionally segment tasks into stages at inference time and auto-advance stages for multi-step tasks.
- Value: 2.5× higher overall success vs. RoboReward in experiments; 20%→85% success in ≤45 minutes on a single-stage task; 20%→70% on a two-stage task.
- Tools/Workflows: “Reward-as-a-Service” module in your training loop; stage manager that parses instructions into stages and triggers transitions on success; ROS node or Python service that takes video + instruction and returns reward/success streams.
- Dependencies/Assumptions: Onboard or edge compute for Qwen3-VL-4B inference; clear task instructions; reliable camera views; human resets still required; reward-misspecification monitoring.
- Offline RL on mixed-quality datasets (Robometer + IQL)
- Sectors: robotics, warehouse automation, assembly
- What: Replace sparse or heuristic rewards with Robometer’s dense rewards in offline RL on datasets containing both expert and noisy trajectories.
- Value: Reported 2.4× average success rate improvement over the best baseline per task.
- Tools/Workflows: Batch post-processing of trajectories to attach reward curves; plug into IQL or other offline RL pipelines.
- Dependencies/Assumptions: Sufficient coverage in offline data; reasonable visual similarity to RBM-1M domains; careful reward scaling for stability.
- Imitation learning data filtering and retrieval
- Sectors: robotics R&D, ML ops for robotics datasets
- What: Rank and filter demonstrations by Robometer’s final reward and success; retrieve top-k aligned demonstrations per instruction; reject off-task or failed demos.
- Value: Higher IL success from cleaner, instruction-aligned data; reduced human curation load.
- Tools/Workflows: Dataset cleaning scripts; retrieval API that inputs instruction and returns top-ranked trajectories.
- Dependencies/Assumptions: Accurate instruction–video matching; calibrated thresholds for success/failure in your domain.
- Zero-shot failure detection and QA monitoring
- Sectors: industrial robotics, field service robots, academic labs
- What: Use success predictions and reward regressions to detect failures across embodiments without task-specific training.
- Value: Early detection of regressions and safety-critical errors; deployable as “shadow mode” monitor before gating real operations.
- Tools/Workflows: Runtime monitor that flags low-progress or non-increasing-reward segments; alerting dashboards.
- Dependencies/Assumptions: Stable camera views; calibrated decision thresholds; false positives/negatives acceptable for alerting.
- Generalizable reward baseline for benchmarking and automated grading
- Sectors: academia, education, corporate R&D
- What: Use Robometer for standardized reward curves and rankings (VOC, Kendall τ) on new tasks; auto-grade student or lab demos for progress and success.
- Value: Comparable, reproducible evaluation without task-specific reward engineering.
- Tools/Workflows: Evaluation harness that ingests videos + instructions; confusion-matrix reporting to test instruction alignment.
- Dependencies/Assumptions: Task instructions precisely describe target behaviors; consistent video capture.
- Rapid domain adaptation via lightweight fine-tuning (LoRA)
- Sectors: specialized manufacturing, healthcare labs, defense labs
- What: Fine-tune Robometer with LoRA on a small, domain-specific dataset (e.g., RoboFAC) to tighten alignment and improve ranking/separation.
- Value: Substantial gains with 1 GPU; improved Kendall τ and success–failure separation vs. training from base VLM.
- Tools/Workflows: LoRA fine-tuning scripts; reward validation suite for your domain.
- Dependencies/Assumptions: Domain data with clear successes/failures; licensing compliance for RBM-1M sources.
- Synthetic supervision generation for existing datasets (video rewind, instruction negatives, progress-based comparisons)
- Sectors: academia, robotics dataset providers, tool vendors
- What: Augment your demos with rewound segments and instruction mismatches to cheaply generate preference pairs and dense targets.
- Value: Leverages abundant failed or unlabeled data without additional human annotation; improves generalization and robustness.
- Tools/Workflows: Data augmentation toolkit mirroring paper’s recipe; integration into dataset pipelines.
- Dependencies/Assumptions: Access to raw video; accurate instruction metadata; careful control of segment lengths to avoid length-as-quality bias.
- Integration into existing VLA/RL frameworks
- Sectors: software for robotics, platform vendors
- What: Provide Robometer as a plugin module to popular frameworks (e.g., DSRL, DreamZero) for reward shaping and stage control.
- Value: Immediate gains in sample efficiency and stability without re-architecting policies.
- Tools/Workflows: Adapter class wrapping inference; batched, low-latency inference for real-time training.
- Dependencies/Assumptions: Framework compatibility; batching and stream handling; GPU scheduling.
- Safety analytics and deployment gating
- Sectors: operations, compliance, QA
- What: Use reward trajectories to define pass/fail gates before deploying updated policies; analyze regressions over time.
- Value: Reduces deployment risk with a cross-task, embodiment-robust signal.
- Tools/Workflows: CI/CD step that evaluates new policies on a held-out scenario bank using Robometer; regression dashboards.
- Dependencies/Assumptions: Representative scenario bank; documented thresholds; periodic recalibration.
Long-Term Applications
The dual-objective reward modeling and large, failure-rich training corpus point toward broader, cross-domain and safety-critical uses as models and infrastructure mature.
- Continual self-improving robot fleets with minimal human supervision
- Sectors: logistics, retail, agriculture, home service robots
- What: Robots log attempts; the system generates preferences from unlabeled failures, updates rewards, and improves policies via online/offline RL loops.
- Value: Lower supervision costs; faster adaptation to new tasks/sites.
- Tools/Workflows: Cloud “RewardOps” service aggregating fleet data, training reward updates, and pushing calibrated checkpoints.
- Dependencies/Assumptions: Robust, privacy-preserving data pipelines; on-device or edge inference; safeguards against reward hacking; periodic human audits.
- Standardized reward models for certification and safety auditing
- Sectors: policy, compliance, insurance
- What: Adopt a benchmarked, general-purpose reward model to evaluate task compliance and safety before deployment.
- Value: Comparable, transparent metrics across vendors (e.g., instruction–video confusion, Kendall τ on staged suites).
- Tools/Workflows: Certification tests using standardized scene/task banks; third-party “reward auditor” services.
- Dependencies/Assumptions: Industry consensus on benchmarks; documented model limitations; governance around updates.
- Assistive and healthcare robotics training with dense, language-grounded rewards
- Sectors: healthcare, eldercare, rehabilitation
- What: Train assistive robots on multi-stage tasks (e.g., positioning items, simple fetch-and-carry) using success-driven stage advancement and dense progress signals.
- Value: More sample-efficient learning from limited, variable-quality data; safer training via early failure detection.
- Tools/Workflows: Hospital-specific LoRA fine-tunes; human-in-the-loop review dashboards.
- Dependencies/Assumptions: Rigorous validation and regulatory approval; domain shifts (lighting, sterile environments) addressed; strict privacy constraints.
- Consumer robotics that adapt from in-home video logs and natural language
- Sectors: home robotics, smart appliances
- What: Personalized robots improve over time by interpreting user instructions and learning from their own failures, using preference-based supervision without heavy annotation.
- Value: Continuous improvement on idiosyncratic household tasks; reduced need for expert demos.
- Tools/Workflows: On-device reward inference; opt-in data collection; staged release with guardrails.
- Dependencies/Assumptions: Strong privacy/security posture; robust OOD generalization; intuitive UX for users to review/override.
- Cross-domain extension to non-manipulation autonomy (e.g., mobile navigation, driving simulation, drone operations)
- Sectors: autonomous vehicles, drones, warehousing
- What: Adapt the preference + progress framework to trajectory modalities beyond tabletop manipulation (e.g., waypoints, egocentric video).
- Value: Leverage failure-rich logs to learn generalizable, instruction-aligned reward models at scale.
- Tools/Workflows: Multimodal inputs (LIDAR/video), domain-specific augmentations, safety envelopes.
- Dependencies/Assumptions: Significant retraining on domain data; new safety constraints; additional sensors.
- Integrated “Reward Studio” for dataset construction, augmentation, and reward-model lifecycle
- Sectors: tool vendors, platforms, ML ops
- What: A product that manages instruction authoring, synthetic preference generation (rewind/negatives), training, calibration, and deployment monitoring.
- Value: Reduces friction of building and maintaining reward models; standardizes workflows across teams.
- Tools/Workflows: GUI + API; experiment tracking; automatic report cards (VOC, τ, confusion).
- Dependencies/Assumptions: Interoperability with major robotics stacks; MLOps maturity; dedicated data governance.
- Multi-modal supervision fusion (language + video + proprioception + force) for richer rewards
- Sectors: advanced manufacturing, surgical robotics
- What: Extend Robometer’s architecture to integrate tactile/force cues and robot state for fine-grained progress signals and anomaly detection.
- Value: Higher fidelity rewards and safer operation on contact-rich tasks.
- Tools/Workflows: Sensor synchronization; calibration pipelines; expanded training corpora.
- Dependencies/Assumptions: New datasets; additional model capacity; careful safety validation.
- Reward-model marketplaces and standards
- Sectors: software platforms, ecosystem builders
- What: Curated, task/industry-specific reward model catalogs with evaluation badges and APIs, enabling drop-in replacement/updates.
- Value: Faster adoption; specialization without retraining from scratch; common metrics.
- Tools/Workflows: Versioned APIs; conformance tests; billing and SLAs.
- Dependencies/Assumptions: Broad adoption of interfaces; governance on evaluation and updates.
Notes on feasibility across applications:
- Generalization depends on visual similarity and instruction quality; OOD tasks may require fine-tuning.
- Real-time use needs GPU/edge compute and low-latency pipelines; batching strategies help.
- Safety-critical deployments require rigorous calibration, monitoring, and human oversight to mitigate reward misspecification.
- Data licensing and privacy constraints apply when leveraging RBM-1M-style aggregates or customer video.
Glossary
- Balanced Binary Cross-Entropy (BalancedBCE): A class-weighted binary cross-entropy loss used to address imbalance between positive and negative samples. "We train success prediction with binary cross-entropy on , with balanced class weights adjusted per-batch to account for negative sample imbalance: ."
- Bimanual manipulators: Robots with two arms used for manipulation tasks. "including bimanual, single-arm, and mobile manipulators"
- C51 formulation: A distributional reinforcement learning method that models value distributions with a fixed set of categorical bins. "following the C51 formulation~\citep{bellemare2017distributional}"
- Causal mask: Attention masking that restricts tokens to attend only to current and previous positions, preserving temporal causality. "The causal mask ensures that tokens attend only to the current and previous frames of , producing dense, frame-level progress estimates for online reward inference, while attends to both trajectories to make a relative judgment."
- Counterfactual instruction labeling: Generating alternative, incorrect instructions to create negative supervision signals. "predict discretized (1-5) progress labels generated via counterfactual instruction labeling by closed-source VLMs"
- Dual objective: Training with two complementary losses to improve performance, here progress prediction and preference prediction. "The model is supervised with a dual objective: predicting frame-level task progress (reward) and learning trajectory-level preferences from pairwise comparisons."
- Embodiment: The physical form or platform of a robot, influencing its capabilities and observations. "spanning 21 robot embodiments"
- Full Fine-Tuning (FFT): Updating all parameters of a model during fine-tuning, as opposed to using parameter-efficient methods. "via LoRA~\citep{hu2022lora} adapters and full fine-tuning (FFT)."
- Inverse reinforcement learning (IRL): Inferring the underlying reward function from expert demonstrations. "inverse RL (IRL), where reward functions are inferred from human demonstrations"
- Kendall τ_a: A rank correlation metric that measures the agreement between two orderings, robust to ties. "Kendall is not calculated for RBM-EVAL-ID\ due to it only having simulation failure data."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning technique that inserts trainable low-rank adapters into a pre-trained model. "We adapt Robometer\ via LoRA~\citep{hu2022lora} adapters and full fine-tuning (FFT)."
- Mean Absolute Error (MAE): A regression metric measuring the average absolute difference between predictions and ground truth. "We further evaluate on the external RoboRewardBench benchmark~\citep{lee2026roboreward}, reporting Mean Absolute Error (MAE) on rewards discretized into 1--5 scores."
- Monotone transformations: Transformations that preserve ordering; reward models identifiable up to such transformations can still guide policy optimization. "reward models that are only identifiable up to monotone transformations, yet sufficient for effective policy optimization"
- Multi-stage rewards: Reward schemes that decompose tasks into sequential stages with stage-specific success signals. "methods that explicitly train with multi-stage rewards"
- Out-of-distribution (OOD): Data that differs significantly from the training distribution in aspects like scenes, embodiments, or viewpoints. "validated on reward model evaluations from 6 out-of-distribution scenes collected at 3 institutions"
- Pairwise comparisons: Supervisory signals based on relative preferences between two trajectories rather than absolute scores. "learning trajectory-level preferences from pairwise comparisons"
- Pearson correlation: A measure of linear correlation between two variables, used here to assess reward alignment over time. "which calculates the Pearson correlation of predicted rewards for each trajectory video frame against their ground-truth timestep value."
- Preference supervision: Training signals derived from relative judgments indicating which of two trajectories better achieves a task. "preference supervision from humans is used to learn reward models"
- Preference token: A learned token inserted into a sequence for aggregating information to predict trajectory-level preference. "and a single preference token () at the end of the multi-video prompt"
- Progress tokens: Learned tokens interleaved with video frames to produce per-frame progress estimates. "We interleave progress tokens () within the first video sequence"
- Qwen3-VL-4B-Instruct: A specific pre-trained vision-LLM used as the backbone for processing videos and language. "Robometer\ instantiates a causally masked VLM, Qwen3-VL-4B-Instruct, to process either one video (for reward inference) or a pair of videos (for preference training)."
- RBM-1M: A large, curated reward-learning dataset of over one million trajectories spanning diverse tasks and robot platforms. "Robometer\ is trained on RBM-1M, a 1M-trajectory dataset spanning 21 robot embodiments"
- Reinforcement Learning from Human Feedback (RLHF): Using human preferences or feedback to train reward models that guide policy learning. "reinforcement learning from human feedback (RLHF), where preference supervision from humans is used to learn reward models"
- Reward shaping: Modifying or augmenting reward signals to facilitate learning, often improving sample efficiency or stability. "RoboReward’s discrete scores are also used for both reward shaping and success detection."
- RoboRewardBench: An external benchmark for evaluating robot reward models. "We further evaluate on the external RoboRewardBench benchmark~\citep{lee2026roboreward}."
- Success-fail difference: A metric quantifying the gap between final rewards on successful versus failed trajectories of the same task. "we also compare a success - fail metric measuring the difference in final reward between successful and failed trajectories of the same task."
- Success prediction: Binary per-frame prediction indicating task completion status used to automate termination or stage progression. "We train success prediction with binary cross-entropy on "
- Value Order Correlation (VOC): A metric computing the Pearson correlation between predicted reward curves and ground-truth timesteps to assess temporal alignment. "We report Value Order Correlation (VOC)~\citep{ma2024generative} "
- Video rewind: An augmentation that reverses segments of a trajectory to simulate regressions and create preference pairs. "Prior work denotes this type of augmentation as video rewind"
- Vision-Language Action (VLA): Models that jointly process vision and language to predict actions and rewards. "VLAC-8B trains a VLA that predicts actions and rewards"
- Vision-LLM (VLM): Models that process both visual inputs and language, used here to predict rewards and preferences from videos. "Robometer is a VLM-based reward model"
- Zero-shot: Using a pre-trained model to generalize to new tasks or domains without task-specific fine-tuning. "directly using pre-trained VLMs for zero-shot video-language reward prediction often yields noisy or inconsistent signals"
Collections
Sign up for free to add this paper to one or more collections.