- The paper presents SARM, a stage-aware reward model that leverages natural language subtask annotations to generate semantically aligned progress signals for long-horizon, contact-rich tasks.
- It demonstrates superior performance with significantly improved reward prediction accuracy and policy success rates, achieving 83% on medium and 67% on hard T-shirt folding tasks.
- The integration of RA-BC and reinforcement learning highlights the framework’s scalability and potential to enhance imitation learning and RL in varied robotic manipulation scenarios.
Stage-Aware Reward Modeling for Long-Horizon Robot Manipulation
Introduction
The paper introduces SARM, a stage-aware reward modeling framework designed to address the challenges of long-horizon, contact-rich robotic manipulation tasks, particularly those involving deformable objects such as T-shirt folding. The central motivation is to overcome the limitations of existing reward modeling approaches, which often rely on frame-index-based progress labeling and struggle with variable-length, heterogeneous demonstrations. SARM leverages natural language subtask annotations to derive semantically meaningful progress signals, enabling robust reward estimation and improved policy learning. The framework is further extended with Reward-Aligned Behavior Cloning (RA-BC), which utilizes the learned reward model to filter and reweight training data, thereby enhancing policy performance in both simulation and real-world settings.
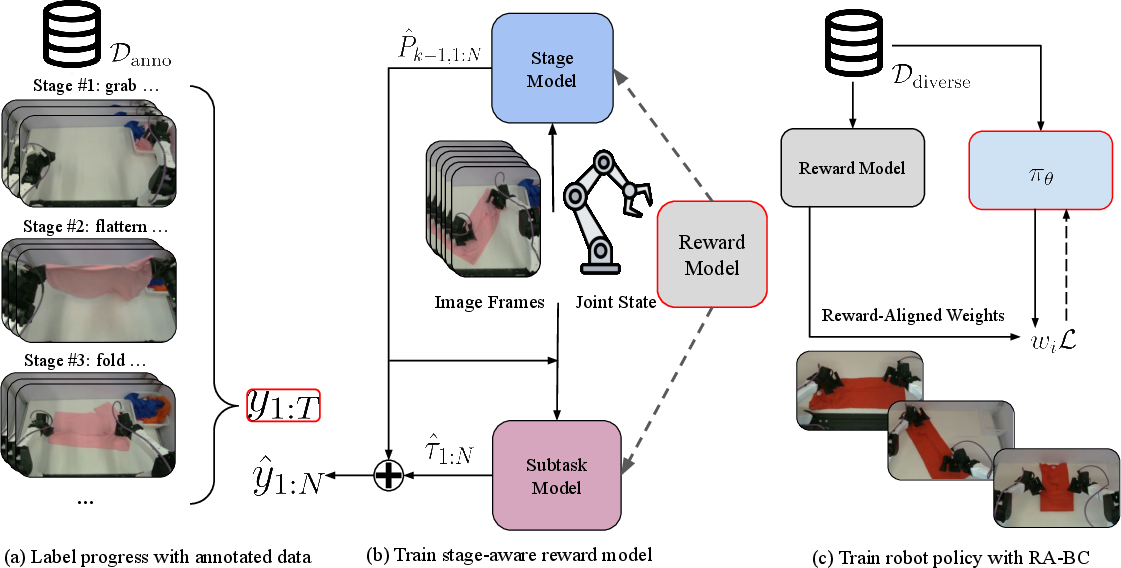
Figure 1: Overview of the SARM framework, illustrating data processing, reward model training, and policy training with reward signals.
Reward Model Architecture and Training
SARM employs a dual-headed architecture comprising a stage estimator and a subtask estimator. The stage estimator predicts the current high-level task stage from multimodal observations (RGB frames and joint states), while the subtask estimator, conditioned on the stage prediction, outputs a fine-grained progress value within the current stage. Both heads share a frozen CLIP-based visual encoder and a transformer-based temporal aggregator, with explicit positional bias only on the initial frame to prevent absolute temporal leakage.
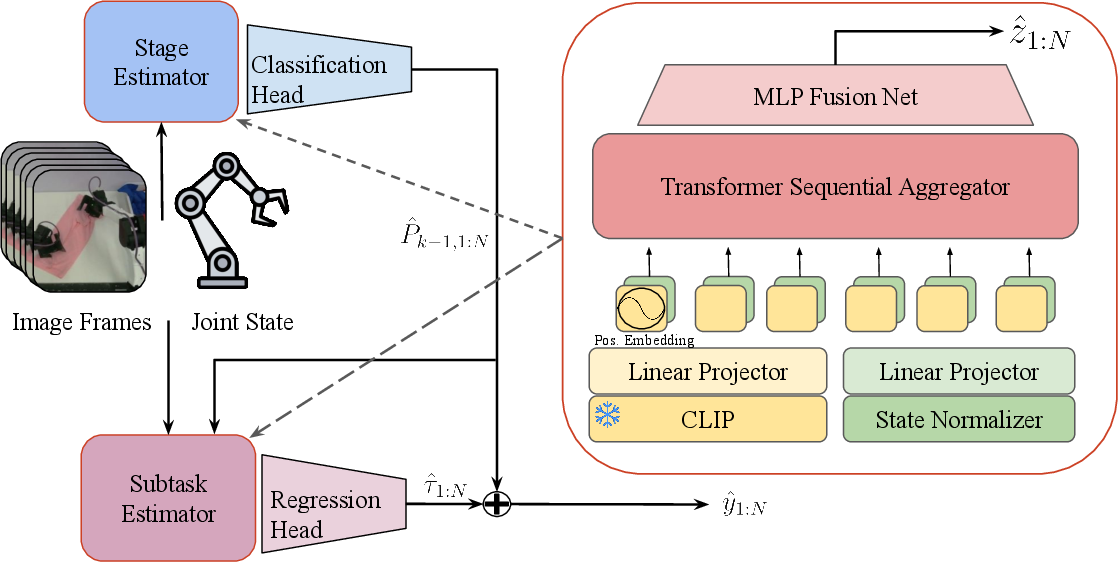
Figure 2: SARM architecture, showing the sequential operation of the stage estimator and subtask estimator for progress prediction.
Progress labels are generated by segmenting demonstration trajectories according to natural language subtask annotations. Dataset-level priors are computed for each subtask, and frame-wise progress targets are assigned via linear interpolation within each subtask segment. This approach ensures that progress labels are semantically aligned and consistent across demonstrations, mitigating the label noise inherent in frame-index-based methods.
A key augmentation is the use of "rewind" frames, which append earlier frames in reverse order to the input sequence, improving the model's robustness to non-monotonic progress and failure cases. The model is trained with cross-entropy loss for stage classification and mean squared error for progress regression, using AdamW optimization.
Reward-Aligned Behavior Cloning (RA-BC)
RA-BC modifies the standard behavior cloning objective by introducing reward-aligned sample weighting. For each training sample, the reward model computes a progress delta between consecutive observation windows. This delta is mapped to a weight using online running statistics (mean and standard deviation), with decisive thresholds for clearly positive or negative progress. The weighted loss objective emphasizes samples that demonstrate meaningful task advancement, effectively filtering out suboptimal or noisy data.
This weighting mechanism is architecture-agnostic and can be applied at the sample or sequence level. In practice, RA-BC provides a drop-in replacement for vanilla BC, enabling scalable and annotation-efficient imitation learning in diverse, imperfect datasets.
Empirical Evaluation
SARM is evaluated on the T-shirt folding task using two datasets: one with dense annotations and one with sparse annotations. Baselines include LIV, VLC, GVL, and ReWiND, all trained on the union of both datasets. SARM consistently outperforms all baselines in both human demonstration progress estimation and real robot policy rollout classification, achieving lower mean squared error and higher classification accuracy.
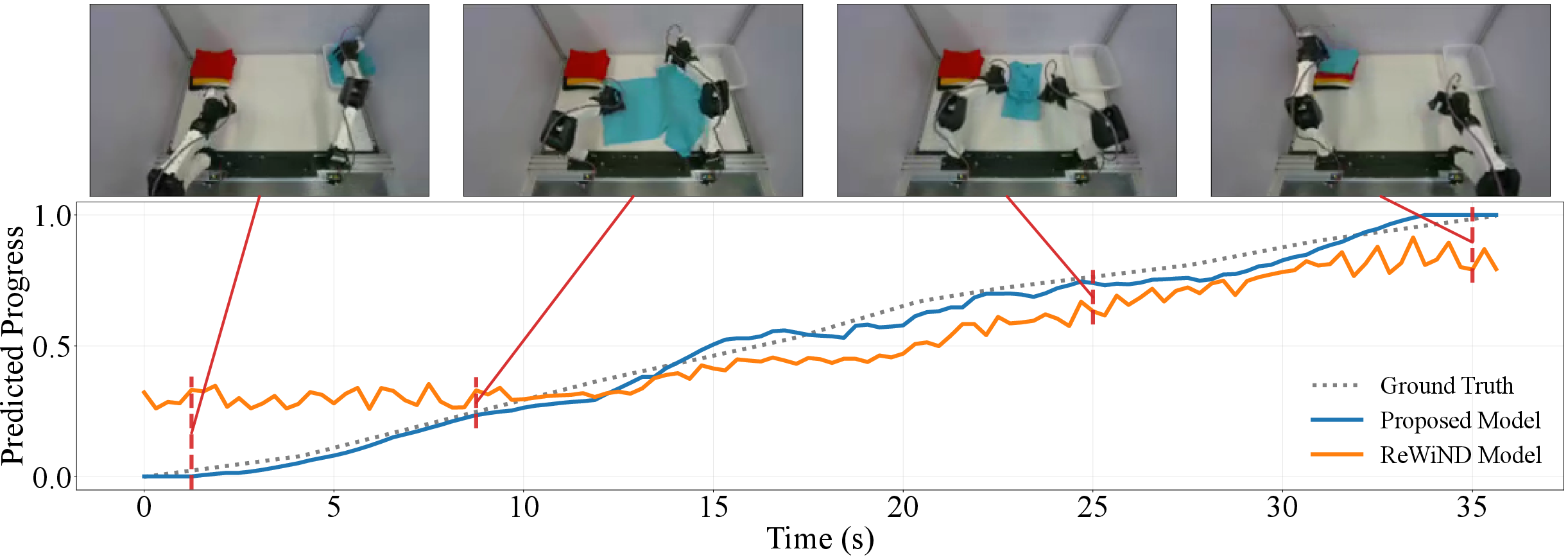
Figure 3: Visualization of predicted task progress for T-shirt folding demonstrations; SARM yields more accurate and calibrated estimates compared to ReWiND.
Ablation studies reveal that models trained solely on dense annotations or without rewind augmentation generalize poorly to out-of-distribution scenarios, underscoring the importance of heterogeneous annotation protocols and temporal augmentation.
Policy Learning with RA-BC
RA-BC is applied to fine-tune Pi0-based policies for T-shirt folding, using both the full dataset and a filtered high-quality subset. Policies trained with RA-BC and SARM reward signals achieve dramatically higher success rates on medium (folding from flattened state) and hard (folding from crumpled state) tasks compared to vanilla BC and RA-BC with ReWiND rewards. Specifically, SARM-based RA-BC attains 83% success on the medium task and 67% on the hard task, while vanilla BC achieves only 8% and 0%, respectively.
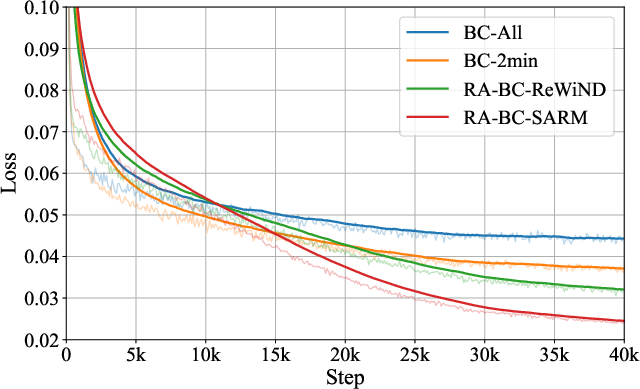
Figure 4: Training loss curves for T-shirt folding policies, showing superior convergence for RA-BC methods.

Figure 5: Example rollout of a RA-BC trained policy successfully folding a T-shirt from a crumpled state.
Reward Model Quality and RL Integration
The quality of the reward model is shown to be pivotal for RA-BC performance. Inferior reward models (e.g., ReWiND) lead to misweighted data and degraded policy success rates. SARM is further integrated with DiffQL for reinforcement learning, providing reward signals for Q-learning in a cube-picking task. RA-QL (DiffQL with SARM rewards) outperforms pure BC in both success rate and discounted return, demonstrating the utility of SARM in RL settings.
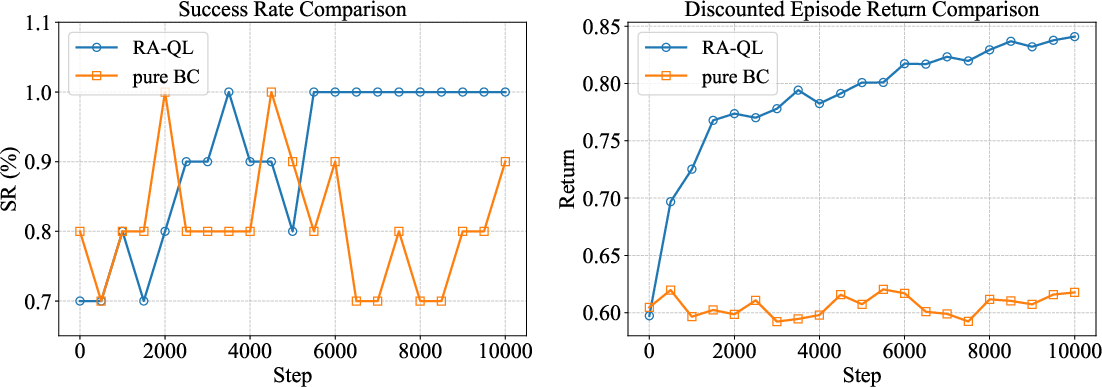
Figure 6: Comparison of RA-QL and pure BC on cube-picking policy training, highlighting improved learning efficiency with SARM-based rewards.
Implementation Considerations
- Computational Requirements: SARM's transformer-based architecture with CLIP backbone is tractable on a single high-end GPU (RTX 4090) for datasets on the order of hundreds of trajectories. Model scaling beyond 60M parameters yields diminishing returns and risks overfitting.
- Annotation Protocols: Natural language subtask annotations are essential for robust progress labeling. Protocol design should reflect the semantic structure of the task and be consistent across annotators.
- Temporal Augmentation: Rewind augmentation is critical for generalization to non-monotonic and failure cases in real-world rollouts.
- Deployment: SARM and RA-BC are compatible with both simulation and real robot platforms, requiring only RGB video and joint state inputs. The reward model can be used for both imitation learning and RL.
Implications and Future Directions
SARM demonstrates that stage-aware, annotation-driven reward modeling is a key enabler for scalable, robust imitation learning in long-horizon manipulation. The framework's ability to generalize across diverse demonstrations and provide reliable progress signals facilitates effective data filtering and sample reweighting, directly improving policy performance. The integration with RL further expands its applicability.
Future research may explore:
- Automated annotation via vision-LLMs to reduce human labeling effort.
- Extension to multi-agent and multi-object manipulation tasks.
- Online adaptation of reward models during policy deployment for continual learning.
- Integration with world models for predictive planning in deformable object manipulation.
Conclusion
SARM provides a principled approach to reward modeling for long-horizon, contact-rich robot manipulation, leveraging natural language annotations and stage-aware progress estimation. Coupled with RA-BC, it enables robust policy learning from diverse, imperfect datasets, achieving strong empirical results in challenging tasks such as T-shirt folding. The framework's modularity and generalization capabilities position it as a foundational component for future scalable robot behavior models.

