- The paper introduces ARM-FM, which leverages foundation models to generate reward machines from natural language task descriptions for compositional RL.
- The framework employs Language-Aligned Reward Machines that integrate natural language instructions with state embeddings to provide dense, interpretable feedback.
- Empirical evaluations across diverse environments demonstrate that ARM-FM outperforms baselines in sparse-reward tasks and enables zero-shot task generalization.
Automated Reward Machines via Foundation Models for Compositional Reinforcement Learning
Introduction and Motivation
The specification of reward functions remains a central bottleneck in scaling reinforcement learning (RL) to complex, long-horizon tasks. Sparse rewards impede credit assignment, while dense, hand-crafted rewards are prone to reward hacking and require significant domain expertise. The ARM-FM framework addresses this by leveraging the high-level reasoning and code-generation capabilities of foundation models (FMs) to automate the construction of reward machines (RMs)—finite-state automata that encode compositional, temporally extended reward structures. This approach enables RL agents to receive structured, interpretable, and dense reward signals derived from natural language task descriptions, facilitating both efficient learning and generalization.
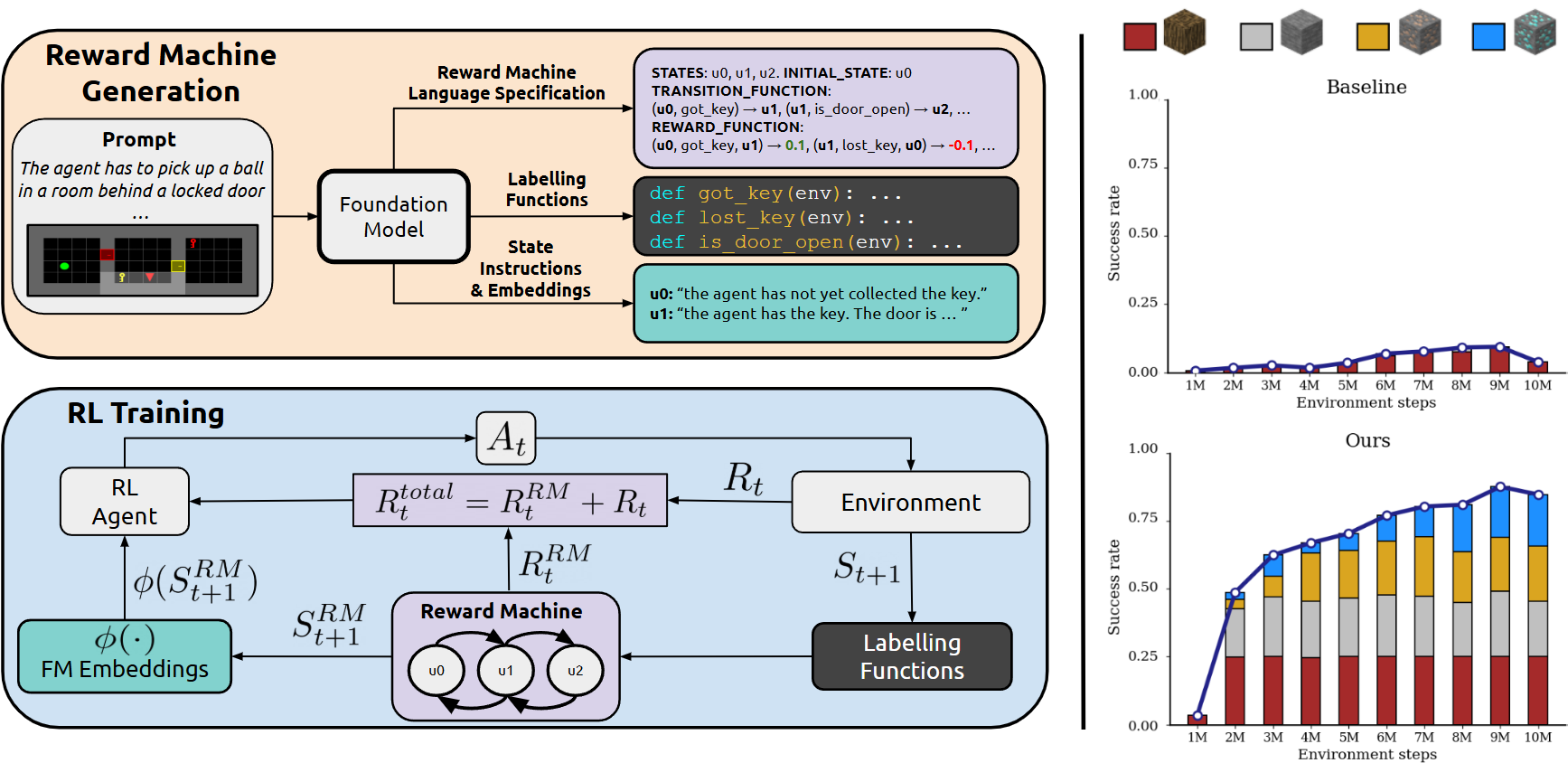
Figure 1: An overview of the ARM-FM framework (left) and its empirical results in a complex sparse-reward environment (right).
ARM-FM Framework
Language-Aligned Reward Machines (LARMs)
ARM-FM introduces Language-Aligned Reward Machines (LARMs), which extend standard RMs by associating each automaton state with a natural language instruction and a corresponding embedding. The FM is prompted with a high-level task description and a visual observation, and it generates:
- The RM structure (states, transitions, events)
- Executable Python labeling functions for event detection
- Natural language instructions for each RM state
This process is iteratively refined using a generator-critic FM loop, optionally incorporating human verification for correctness and compactness. The resulting LARM provides a compositional decomposition of the task, with each subgoal semantically grounded in language.
Policy Conditioning and Skill Space
During RL training, the agent's policy is conditioned on both the environment state and the embedding of the current LARM state. This enables the agent to recognize and reuse skills across tasks with semantically similar subgoals, as the embedding space clusters related instructions. The reward at each timestep is the sum of the environment reward and the LARM reward, with the latter providing dense feedback for subgoal completion.
Empirical Evaluation
ARM-FM is evaluated across a diverse suite of environments, including MiniGrid (sparse-reward gridworlds), Craftium (3D Minecraft-like resource gathering), Meta-World (robotic manipulation with continuous control), and XLand-MiniGrid (procedural meta-RL). The framework is compared against strong baselines, including intrinsic motivation (ICM, RND), LLM-as-agent, and VLM-based reward models.
Sparse-Reward Gridworlds
On MiniGrid DoorKey and long-horizon BabyAI tasks, ARM-FM consistently outperforms all baselines, solving tasks that are intractable for standard RL and intrinsic motivation methods.
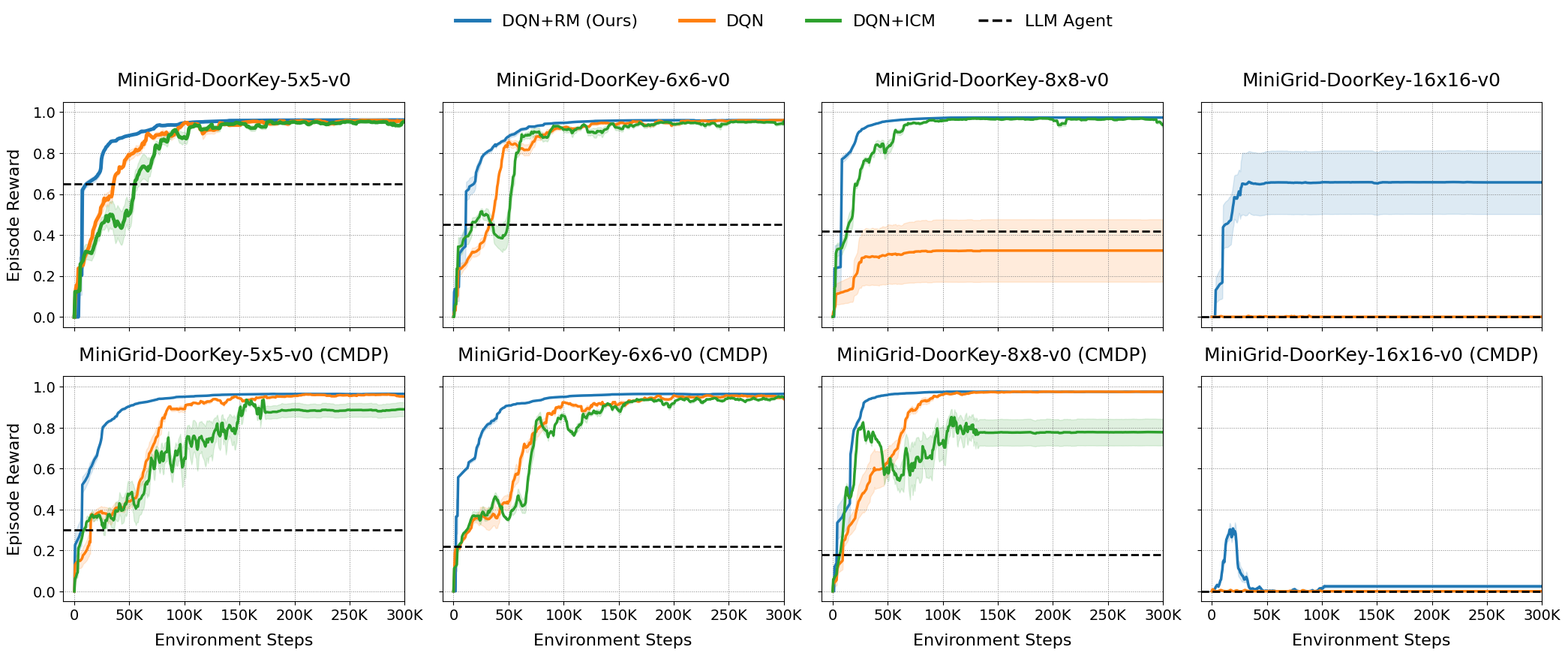
Figure 2: Performance on MiniGrid-DoorKey environments of increasing size. ARM-FM achieves higher rewards across all tasks.
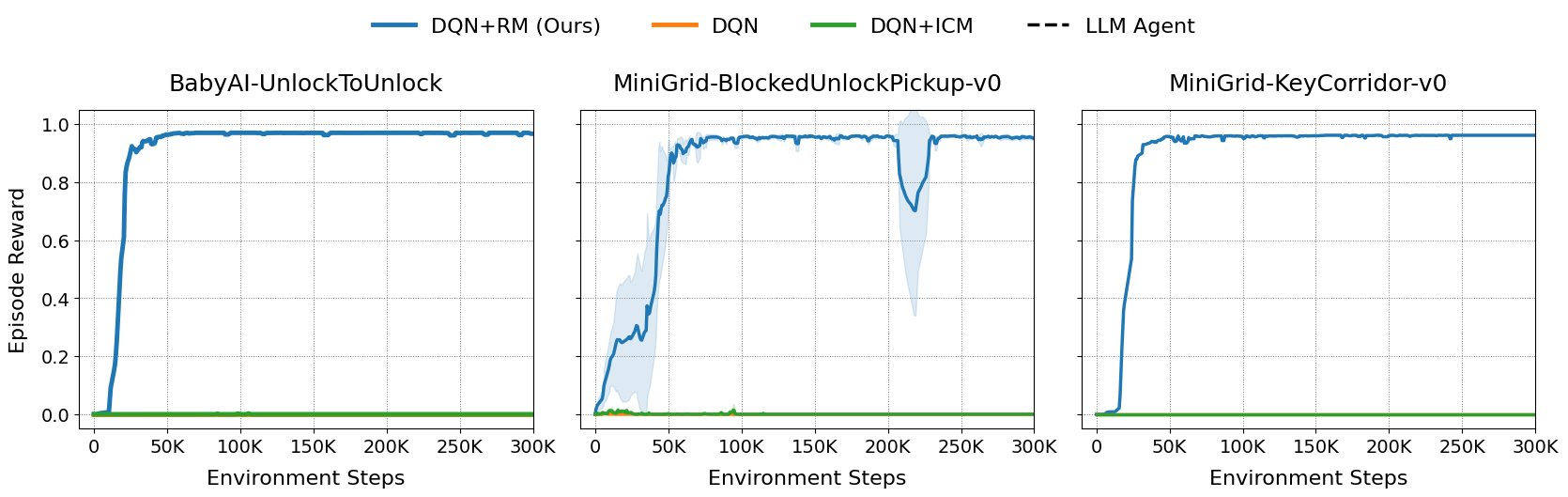
Figure 3: Performance on complex, long-horizon MiniGrid tasks. Only ARM-FM solves all three tasks.
3D Procedural Environments
In Craftium, a procedurally generated Minecraft-like environment, ARM-FM enables PPO agents to solve resource-gathering tasks requiring long action sequences, where baseline agents fail due to the extreme sparsity of the reward.
Figure 1: (Right) ARM-FM enables efficient learning in a complex, sparse-reward 3D environment.
Robotic Manipulation
On Meta-World, ARM-FM automates reward engineering for continuous control tasks, providing dense supervision and enabling higher success rates than sparse reward agents. The LARM can be combined with intrinsic exploration bonuses (e.g., RND) for further gains.
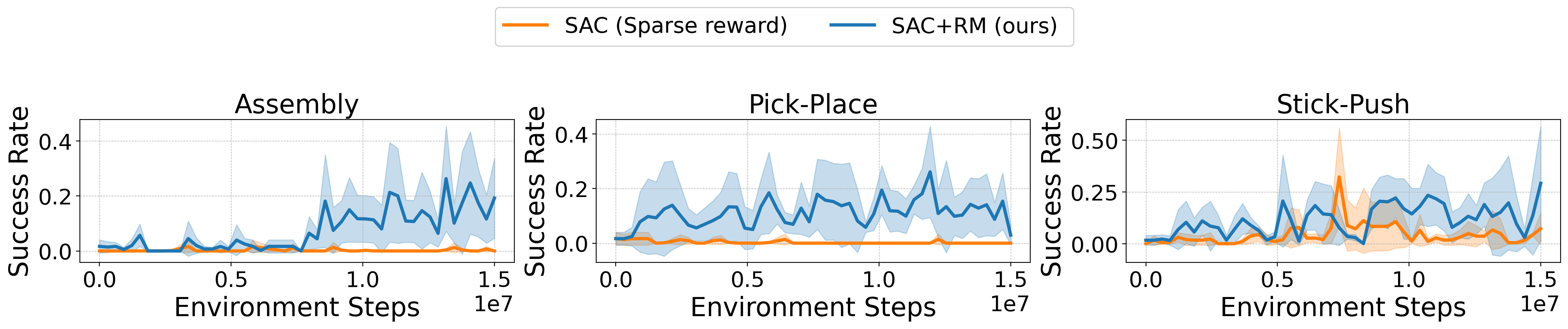
Figure 4: Performance on Meta-World manipulation tasks. ARM-FM achieves high success rates compared to sparse reward agents.
Generalization and Zero-Shot Transfer
Ablation studies in XLand-MiniGrid demonstrate that both the structured rewards and the language-based state embeddings are essential for robust multi-task learning. Conditioning the policy on LARM embeddings enables zero-shot generalization: agents can solve novel composite tasks composed of familiar subgoals without additional training.
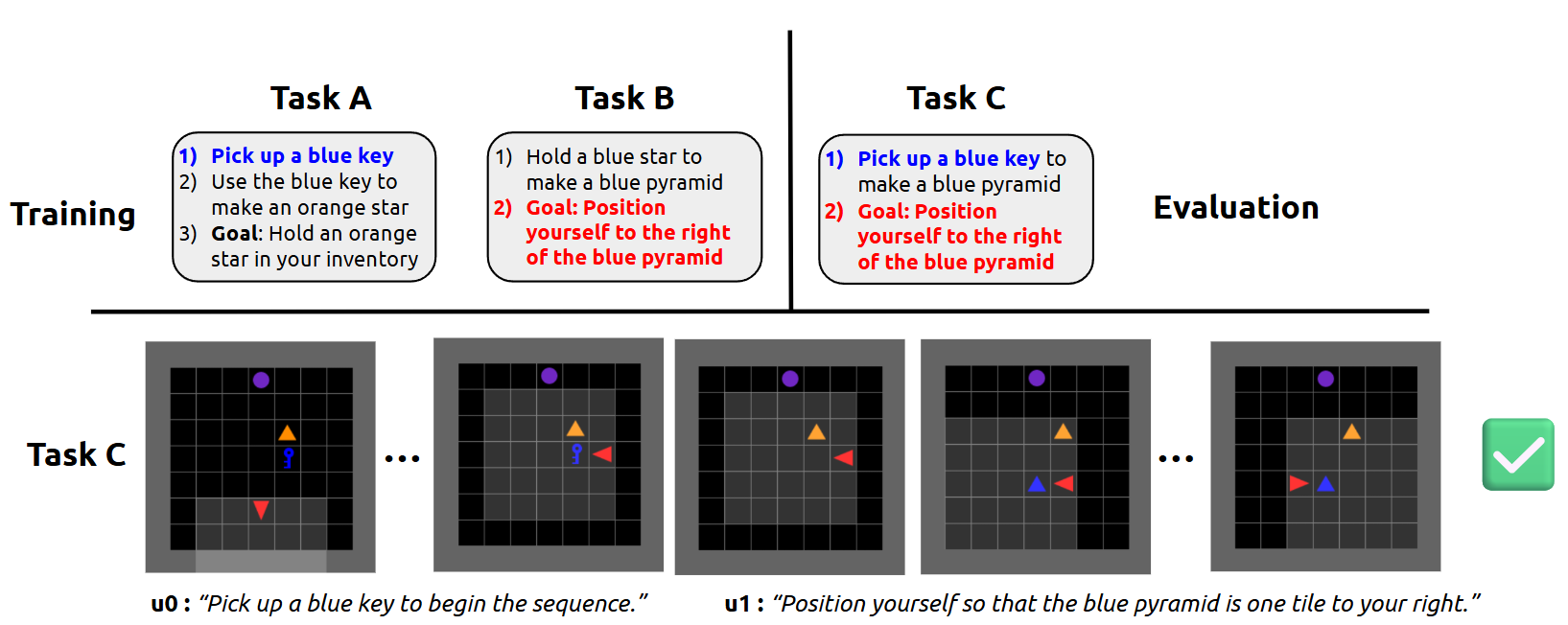
Figure 5: Demonstration of zero-shot generalization. The agent reuses learned skills to solve an unseen composite task.
Analysis of FM Generation and Embedding Space
Larger FMs (e.g., Qwen3-32B) generate syntactically and semantically correct RMs and labeling code with higher reliability. The embedding space of state instructions, visualized via PCA, exhibits clear semantic structure, with start, middle, and end states forming distinct clusters. This structure underpins the agent's ability to generalize and transfer skills across tasks.
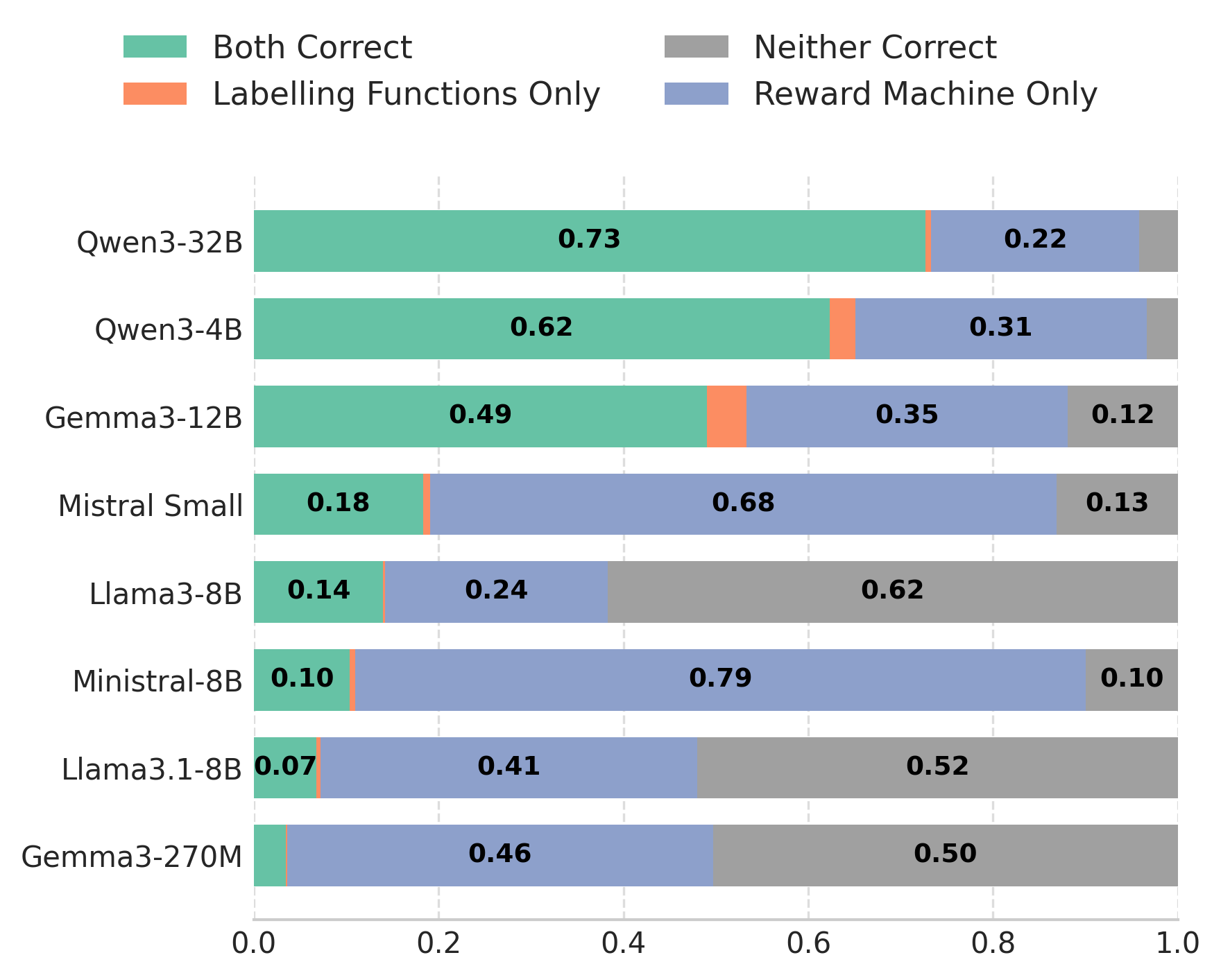
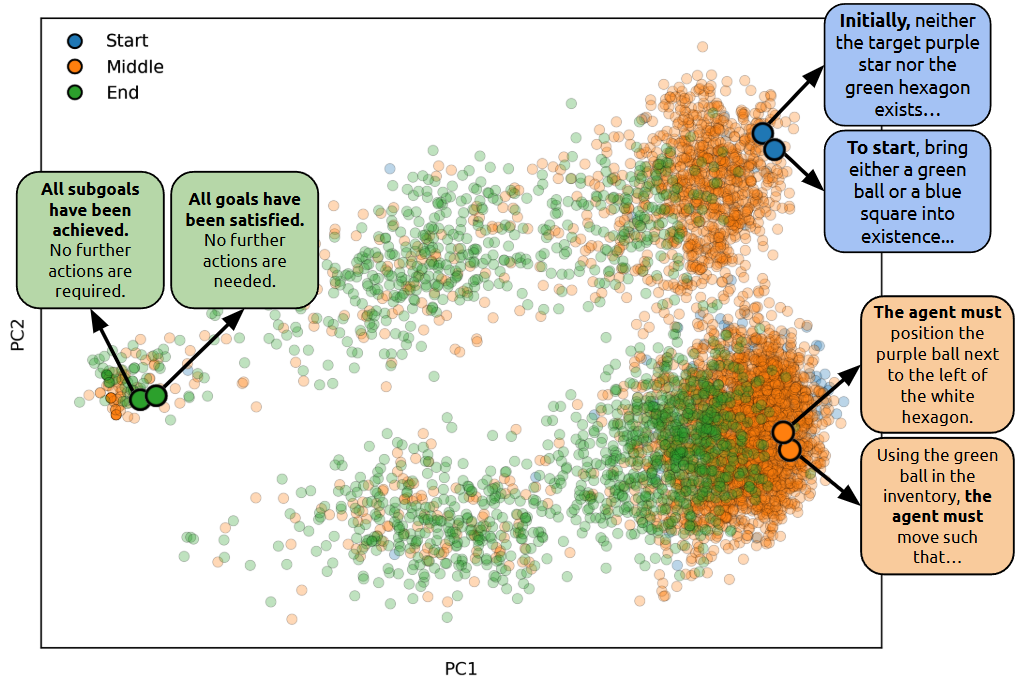
Figure 6: FM generation correctness scales with model size.
Implementation Considerations
Training Procedure
The RL agent is trained using standard algorithms (DQN, PPO, SAC, Rainbow) with the following modifications:
- The state input is augmented with the LARM state embedding.
- The reward is the sum of the environment and LARM rewards.
- The experience replay buffer stores transitions over the joint state space (st,ut).
A detailed pseudocode for DQN with LARMs is provided in the appendix of the paper.
Resource Requirements
- FM inference for RM and labeling function generation is performed offline and can be parallelized.
- The additional computational overhead during RL training is minimal, as LARM state transitions and reward computations are lightweight.
- The embedding function can be implemented using any pretrained LLM (e.g., Qwen, Llama, Gemma).
Limitations and Trade-offs
- Human verification of FM-generated RMs can improve quality but is not strictly required; automated self-correction via formal verification is a promising direction.
- The approach assumes that the FM can generate correct and executable labeling functions for the environment API.
- The semantic quality of the embedding space is critical for generalization; poor embeddings may limit transfer.
Implications and Future Directions
ARM-FM demonstrates that FMs can bridge the gap between high-level task specification and low-level RL reward shaping, automating a process that previously required significant manual effort. The compositional, language-aligned structure of LARMs enables interpretable, modular, and generalizable RL agents. This paradigm supports human-in-the-loop refinement, facilitates policy transfer, and provides a foundation for hierarchical RL.
Future work may focus on:
- Fully automating the RM verification and refinement process via formal methods.
- Extending the approach to richer, more expressive automata (e.g., pushdown reward machines).
- Integrating multimodal FMs for environments with complex visual and symbolic state spaces.
- Scaling to real-world robotics and multi-agent systems.
Conclusion
ARM-FM provides a principled and practical framework for automated, compositional reward design in RL, leveraging the reasoning and code-generation capabilities of foundation models. By translating natural language task descriptions into structured, language-aligned reward machines, ARM-FM enables RL agents to efficiently learn and generalize across complex, long-horizon tasks. The empirical results establish the effectiveness of this approach across diverse domains, and the modular, interpretable structure of LARMs paves the way for scalable, human-aligned RL systems.