Generalizable Dense Reward for Long-Horizon Robotic Tasks
Abstract: Existing robotic foundation policies are trained primarily via large-scale imitation learning. While such models demonstrate strong capabilities, they often struggle with long-horizon tasks due to distribution shift and error accumulation. While reinforcement learning (RL) can finetune these models, it cannot work well across diverse tasks without manual reward engineering. We propose VLLR, a dense reward framework combining (1) an extrinsic reward from LLMs and Vision-LLMs (VLMs) for task progress recognition, and (2) an intrinsic reward based on policy self-certainty. VLLR uses LLMs to decompose tasks into verifiable subtasks and then VLMs to estimate progress to initialize the value function for a brief warm-up phase, avoiding prohibitive inference cost during full training; and self-certainty provides per-step intrinsic guidance throughout PPO finetuning. Ablation studies reveal complementary benefits: VLM-based value initialization primarily improves task completion efficiency, while self-certainty primarily enhances success rates, particularly on out-of-distribution tasks. On the CHORES benchmark covering mobile manipulation and navigation, VLLR achieves up to 56% absolute success rate gains over the pretrained policy, up to 5% gains over state-of-the-art RL finetuning methods on in-distribution tasks, and up to $10\%$ gains on out-of-distribution tasks, all without manual reward engineering. Additional visualizations can be found in https://silongyong.github.io/vllr_project_page/
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Generalizable Dense Reward for Long-Horizon Robotic Tasks”
Overview: What’s this paper about?
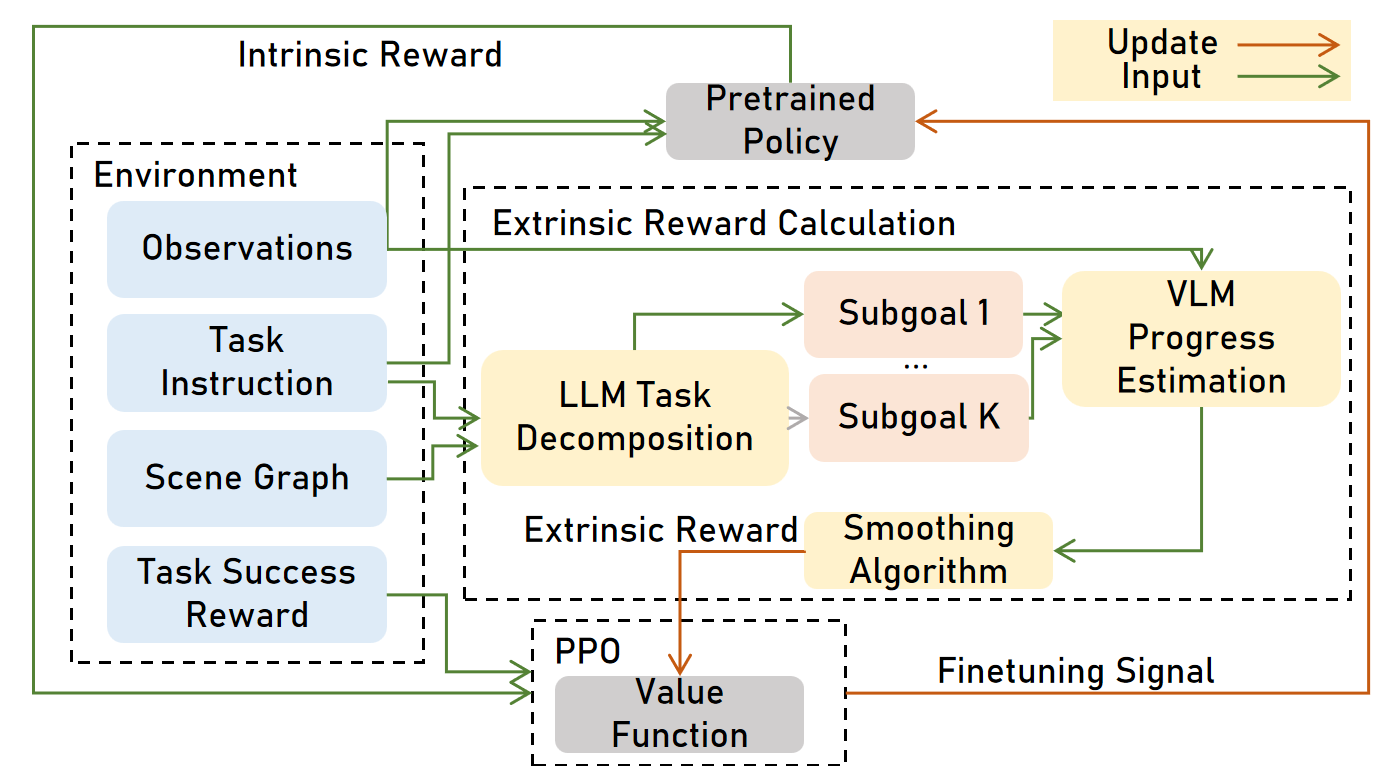
This paper is about teaching robots to handle complex, multi-step chores (like “go to the kitchen, find the mug, pick it up, and bring it to the table”) more reliably. The authors introduce a new way to give robots better, more frequent feedback while training, so they don’t only learn from “you succeeded” or “you failed” at the very end. Their method is called VLLR, and it mixes two kinds of feedback:
- An “outside” progress check that watches the robot’s camera and text instructions to see how far along it is in the task.
- An “inside” confidence signal that rewards the robot when it’s confident and consistent about what to do next.
Together, these help a pre-trained robot get better at long, step-by-step tasks without humans writing custom reward rules for each task.
What questions did the researchers ask?
- How can we fine-tune already-pretrained robot policies to do long, multi-step tasks better?
- Can we give robots frequent, meaningful feedback (not just at the end) without hand-crafting reward rules for every new task?
- Will this work on new task combinations the robot hasn’t seen before?
How did they do it? (Simple explanation of the approach)
Think of a long robot task like following a recipe. If the robot only gets a “good job” after the entire recipe is done, it’s hard to learn. It needs helpful checkpoints, like “you found the eggs” or “you turned on the oven.” VLLR builds those checkpoints automatically and uses them to guide learning.
Here are the main pieces, with everyday analogies:
- Breaking tasks into steps with an LLM
- What it does: Given the house layout (a “scene graph,” basically a map/list of rooms and objects) and a task like “fetch the mug,” a LLM breaks the job into small, ordered steps (subgoals), like “go to the kitchen,” “look for the mug,” “move closer,” “pick it up.”
- Analogy: It’s like asking a smart assistant to outline a to-do list for you.
- Checking visual progress with a VLM (Vision-LLM)
- What it does: A vision-LLM looks at the robot’s camera images and the current subgoal to estimate how far along the robot is. For example, if the subgoal is “see the mug,” and the mug appears in view, the progress score jumps up.
- Analogy: It’s like a teacher marking off steps on your checklist by looking at photos of your work.
- Stabilizing noisy visual feedback
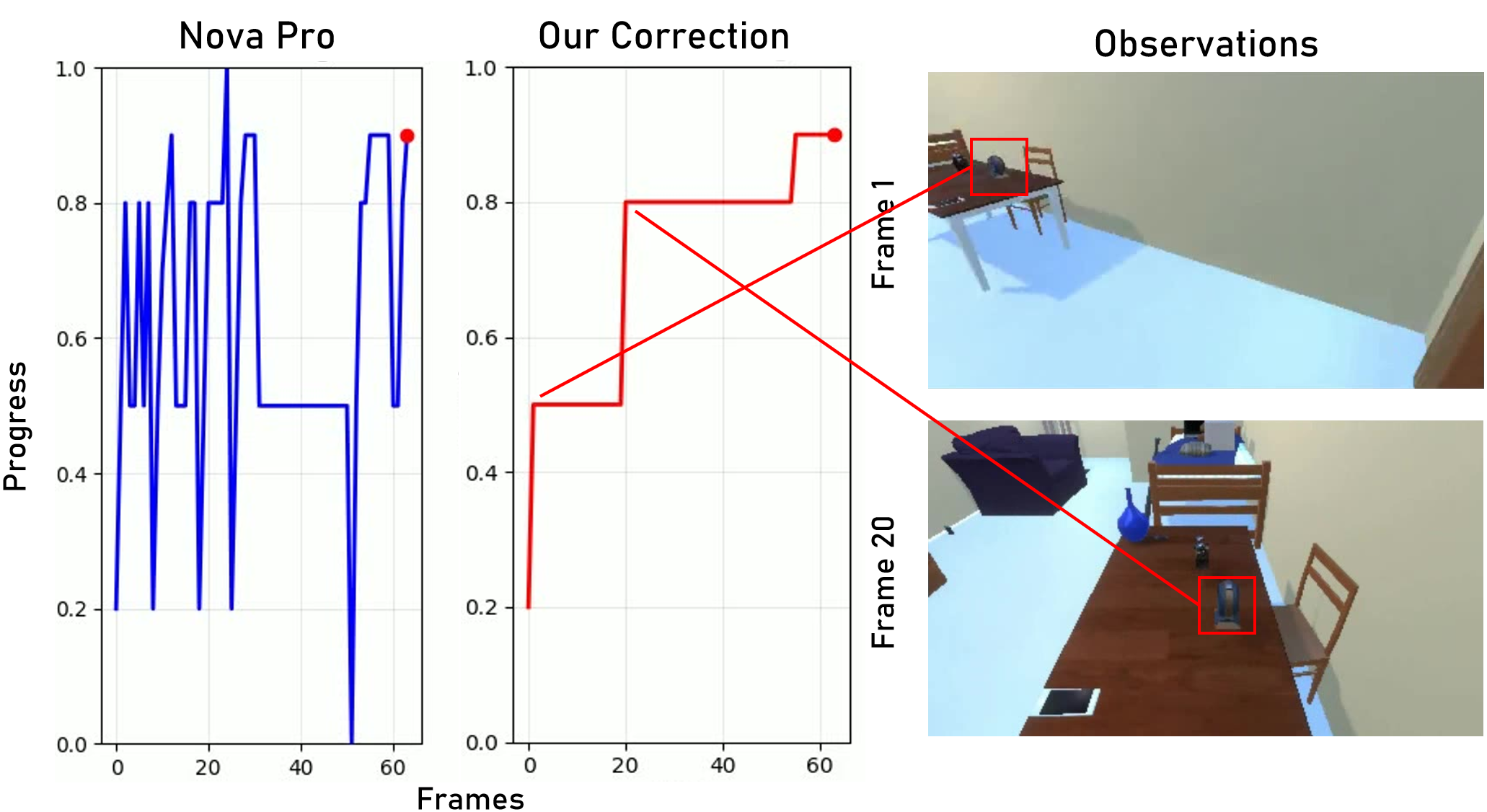
- Problem: Sometimes the visual checker gets confused (for example, it wrongly thinks it saw the mug). If that happens once, the “progress bar” could jump too high and stop giving useful feedback.
- Fix: The authors smooth the progress scores over time so random spikes don’t mess up learning.
- Analogy: If your fitness tracker mistakenly thinks you climbed a flight of stairs, you don’t let that one weird reading change your whole weekly trend.
- Using the visual feedback only at the start to teach a “value function”
- What it does: In reinforcement learning, a value function is the robot’s internal “progress bar” that estimates how close it is to success. The paper uses the VLM’s progress scores for a short warm-up phase to teach this progress bar.
- Why: Asking the VLM at every step is slow and expensive. By training the value function early, the robot can estimate progress by itself later.
- Encouraging decisive, consistent behavior with “self-certainty”
- What it is: This is an “intrinsic” reward from inside the robot’s policy. It looks at how confident the robot is in its chosen action. If the robot’s action choices are very focused (not scattered), it gets a small reward.
- Why it helps: In long tasks, being decisive and consistent usually means the robot understands what’s going on. This signal nudges the robot toward clearer, more stable decisions.
- Analogy: A coach rewarding an athlete not just for outcomes, but also for confident, well-formed moves.
- Two-stage training (so it’s fast and scalable)
- Stage I: Briefly use the visual progress feedback to teach the value function (the internal progress bar).
- Stage II: Turn off the visual model to save time and money. Keep training with:
- the robot’s self-certainty reward, and
- the basic “did you finish the task?” reward.
They use a popular RL method called PPO (you can think of it as a structured practice routine that updates the robot’s behavior step by step).
Key terms in simple words:
- Dense reward: Many small “checkpoints” along the way.
- Sparse reward: Only a yes/no at the end.
- Foundation policy/model: A big, general robot policy pre-trained on lots of examples.
- Out-of-distribution (OOD): New task combinations the robot didn’t see during pretraining.
What did they find, and why is it important?
Here’s what happened when they tested VLLR on a big household-chores benchmark (CHORES), which includes tasks like navigation and manipulation:
- Much higher success: Compared to the base pre-trained policy, success went up by as much as 56%. Compared to strong reinforcement learning baselines, VLLR gained up to 5% on tasks similar to training, and up to 10% on new, never-seen task combinations.
- Faster, more efficient completions: The robot often finished tasks in fewer steps.
- Each part helps in a different way:
- The visual progress warm-up (from the VLM) mostly helped the robot complete tasks more efficiently (fewer wasted moves).
- The self-certainty reward mostly boosted success rates, especially on new, unfamiliar tasks (OOD tasks).
- Lower cost during training: Because the visual model is only used briefly at the start, the method avoids expensive per-step model calls later.
Why this matters:
- Less manual work: No need to hand-craft special reward rules for every new task.
- Better at long tasks: The robot gets guidance throughout, not just at the end.
- More general: Works even when tasks are combined in new ways.
What could this lead to?
- Easier robot training: Engineers can fine-tune robots for complex chores without writing custom reward code each time.
- Better real-world performance: Robots handling multi-step household or warehouse tasks could become more reliable and faster.
- Portability: The idea of “subgoal checkpoints + confidence signals” could be applied to other robots, tasks, and even continuous control settings.
- Next steps: Try this approach on more diverse robots, refine the confidence signal, and explore safety-aware versions for real environments.
In short
VLLR gives robots a smart “progress bar” from the outside (by checking if they’re completing sub-steps) and a helpful “confidence meter” from the inside. This combination makes training more informative and efficient, leading to better performance on long, multi-step tasks—without lots of human reward engineering.
Knowledge Gaps
Below is a concise list of concrete knowledge gaps, limitations, and open questions the paper leaves unresolved. These items are framed to guide actionable follow-up research.
- Reliance on privileged scene graphs: Robustness to incomplete, noisy, or learned (e.g., SLAM-built) scene graphs is untested; evaluate how subgoal decomposition and downstream performance degrade without ground-truth global maps.
- Subgoal decomposition fidelity: No quantitative evaluation of LLM decomposition accuracy, consistency, or failure modes (e.g., missing/incorrect subgoals, wrong ordering); add metrics and human audits of plan correctness.
- Prompt/LLM sensitivity: The method depends on a fixed prompt and a specific LLM (Claude 3.7 Sonnet); perform ablations across prompts/models and analyze variance, stability, and reproducibility of decompositions.
- Dynamic replanning: Decompositions are static; study online replan/update of subgoals when unexpected obstacles, occlusions, or state changes invalidate the initial plan.
- Nonlinear task structures: The approach assumes an ordered list of subgoals; extend to graphs (branching, loops, conditional subtasks) and assess progress estimation on DAG-like task structures.
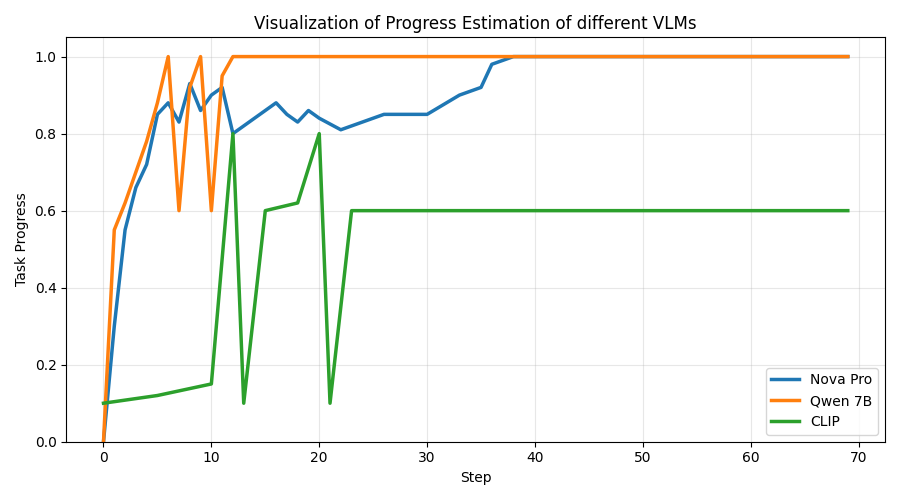
- VLM choice and calibration: Progress estimation is tuned to Nova Pro; systematically compare VLMs, calibrate their confidence, and quantify correlations with ground-truth progress under occlusion, clutter, and lighting variation.
- Progress from minimal context: VLM uses only o_{t-1} and o_t; test longer temporal windows, video-level reasoning, or memory-augmented inputs to reduce ambiguity in progress judgments.
- Post-hoc smoothing bias: The median-filtering and “running maximum” correction uses future frames; quantify bias introduced by using future information and develop online, streaming-safe filters that avoid lookahead.
- Heuristic thresholds: The spike-pruning threshold (1/number of subtasks) and window size are ad hoc; conduct sensitivity analyses and propose data-driven or adaptive thresholding strategies.
- Running-maximum pitfalls: Monotone progress shaping cannot penalize regressions or reward recovery; compare to potential-based shaping that respects MDP structure and penalizes backtracking.
- Stage I duration and refresh: Value initialization uses 200k steps; study scaling laws for warm-up length, periodic “value refresh” with sparse VLM queries, and cost–performance trade-offs.
- Compute/latency accounting: Even with a brief warm-up, per-step VLM queries are costly; provide wall-clock, energy, and dollar cost benchmarks and explore batched or asynchronous querying.
- Self-certainty theory and alternatives: The intrinsic reward is a distribution-concentration measure; compare against classic entropy bonuses, uncertainty estimates, advantage magnitude, curiosity/surprisal, and calibration-aware confidence.
- Overconfidence risks: Analyze and detect cases where high self-certainty corresponds to confidently wrong behavior (reward hacking), and test mitigation (e.g., coupling with advantage sign, confidence calibration).
- Continuous action spaces: The approach is evaluated with 20 discrete actions; specify and test self-certainty and PPO integration for continuous control (e.g., Gaussian policies, entropy/precision measures).
- Weight tuning robustness: No sensitivity analysis for α, β, φ; develop automatic or meta-learned weighting across tasks and quantify robustness to mis-specified weights.
- Sparse-only Stage II: Extrinsic signals are dropped after value init; investigate intermittent or uncertainty-triggered VLM “check-ins” during Stage II and their effect on stability/generalization.
- Partial observability in real setups: Evaluate without privileged global context, relying only on egocentric sensing and memory/state-estimation modules; measure performance under sensor noise and domain shift.
- Real-robot validation: Results are in simulation (CHORES); assess sim-to-real transfer, latency constraints on-device, perception noise, and manipulation errors on physical robots.
- Benchmark breadth: Generalization tested on two OOD tasks from the same suite; expand to other long-horizon domains, embodiments, and action spaces to test cross-benchmark validity.
- Comparative baselines: Missing comparisons to learned reward models (e.g., preference-based, instruction-following reward models) and to recent intrinsic-motivation methods; add head-to-head evaluations.
- Failure case analysis: Provide systematic analysis of failure trajectories (e.g., decomposition errors vs. VLM hallucinations vs. self-certainty misguidance) to prioritize targeted fixes.
- Safety considerations: Study safe exploration under intrinsic bonuses, including constraints to prevent risky, high-certainty behaviors that violate safety or task constraints.
- Metric alignment: The method does not optimize SEL explicitly; investigate reward shaping or training objectives that target SEL or other efficiency-aware metrics directly.
- Multi-modal signals: Explore incorporating depth, tactile, or proprioception into VLM progress estimation and into subgoal verification to reduce reliance on RGB-only cues.
- Uncertainty-aware fusion: Combine VLM confidence scores with policy self-certainty to arbitrate between extrinsic and intrinsic signals (e.g., down-weight extrinsic signals when VLM is uncertain).
- Reproducibility artifacts: The paper promises to release prompts, but no code or data release is confirmed; release code, seeds, and evaluation scripts to enable replication and fair comparison.
Practical Applications
Immediate Applications
The following use cases can be deployed with today’s tools and ecosystems, leveraging existing LLMs/VLMs, foundation robot policies, and standard RL stacks.
- Industry (Warehousing & E‑commerce): Fast reward shaping–free RL fine-tuning for multi-step workflows
- Use case: Improve pick-pack-sort, restocking, and multi-stop mission success by fine-tuning existing foundation policies without hand-crafted dense rewards.
- Workflow/products:
- “Subgoal compiler” service: LLM converts task spec + warehouse scene graph/digital twin into ordered subgoals.
- “Progress verifier” module: VLM-based progress scoring used briefly to initialize a value function; no per-step VLM calls during full training.
- “Certainty-guided PPO”: PPO finetuning with intrinsic self-certainty + sparse success signal.
- Plugin for RLlib/Stable-Baselines3/IsaacGym to add VLLR as a reward adapter.
- Assumptions/dependencies:
- Access to a reasonably accurate scene graph/digital twin and task descriptions.
- Pretrained foundation policy (vision-language-action) and PPO training pipeline.
- Reliable sparse success criteria (e.g., item delivered, bin sorted).
- VLM/LLM APIs available for short Stage I value initialization.
- Healthcare (Hospitals): Service robot finetuning for long-horizon rounds and logistics
- Use case: Medication delivery, specimen transport, supply runs spanning multiple wards, where tasks require sequential navigation and manipulation.
- Workflow/products:
- Task decomposition prompts tuned to hospital maps and policies.
- Short VLM-initialized value training in a simulator, then deployment with certainty-guided policy.
- Dashboard to monitor self-certainty to trigger fallbacks or human-in-the-loop.
- Assumptions/dependencies:
- Hospital layout/scene graphs and standardized task definitions (HL7/FHIR-like task schemas help).
- Clear safety envelopes and triggers when self-certainty is low.
- Compliance with HIPAA/data privacy for any visual data used in Stage I.
- Retail & Facilities (Inspection and Restock): Compositional patrols and shelf-workflows
- Use case: Long-horizon patrol (scan multiple zones, check fixtures), restock sequences across aisles, backroom-to-shelf multi-step tasks.
- Workflow/products:
- Precompute subgoals from store CAD/planogram; use VLM-based progress to initialize values.
- Certainty-guided PPO finetuning to reduce dithering and shorten episode length.
- Assumptions/dependencies:
- Planogram/scene graph availability and periodic updates.
- Basic sparse success definition (e.g., all checkpoints verified, shelf restock completed).
- Smart Home & Consumer Robotics: Personal assistants for multi-step chores
- Use case: “Tidy up living room,” “fetch and put away groceries,” “prepare table,” where success is sparse and tasks are long.
- Workflow/products:
- Home digital twin (from SLAM/scene reconstruction) + LLM subgoals.
- Short offline value initialization with VLM on recorded rollouts; on-device or cloud PPO finetuning using self-certainty + sparse success.
- Assumptions/dependencies:
- Scene graph construction (home mapping) and reliable sparse completion checks.
- Privacy-preserving VLM/LLM use (local models or consented cloud).
- Robotics R&D and Academia: Generalizable reward modeling without task-specific engineering
- Use case: Rapid experimentation on long-horizon benchmarks (e.g., CHORES/Habitat/Isaac) and ablations on reward design.
- Workflow/products:
- Open-source “VLLR reward adapter” for simulators.
- Reproducible prompts for LLM decomposition and VLM scoring, plus the smoothing/post-processing algorithm for progress signals.
- Assumptions/dependencies:
- Access to foundation policies or strong imitation-learned baselines.
- VLM inference budget for Stage I (kept minimal by design).
- Safety & Ops (Cross-sector): Runtime gating using self-certainty
- Use case: Use self-certainty as a heuristic to detect low-confidence states and trigger safe policies, slow-downs, or human teleop.
- Workflow/products:
- Certainty monitors integrated into robot stacks and fleet dashboards.
- Policies that switch to conservative controllers when entropy rises.
- Assumptions/dependencies:
- Calibration of self-certainty thresholds for each embodiment/task.
- Clear fallback behaviors and safety cases.
- Tooling Providers (Simulation and MLOps): Reward-as-a-service components
- Use case: Add “LLM subgoal decomposition” and “VLM progress-to-value init” services to sim offerings.
- Workflow/products:
- Drag-and-drop nodes for subgoal generation and value pretraining.
- APIs to log/store subgoal graphs and progress traces for audits.
- Assumptions/dependencies:
- Integration with scene graphs/asset registries.
- Versioning and governance for prompts and model updates.
Long-Term Applications
These opportunities require further research, scaling, or engineering beyond what is demonstrated, but are natural extensions of the paper’s methods.
- Manufacturing & Complex Assembly: Hierarchical finetuning for multi-stage assembly lines
- Vision: Apply VLLR to long-horizon, continuous-control manipulation with part fetching, assembly, inspection, and rework.
- Potential products:
- “Process-aware” reward models that consume CAD/BOM/assembly plans to auto-generate subgoals.
- Certainty-aligned scheduling between robots and humans on mixed-model lines.
- Dependencies/risks:
- Extension from discrete to continuous action spaces and tight precision constraints.
- Robust scene graphs from dynamic workcells; real-time progress verification beyond egocentric RGB.
- Field Robotics (Energy, Utilities, Construction): End-to-end missions with compositional objectives
- Vision: Pipeline inspections, substation routines, wind farm walkdowns, construction QA with changing environments.
- Potential products:
- “Mission compiler” translating procedures (SOPs) + site maps into subgoals; VLM/3D-VLM progress verification.
- Continual learning where Stage I value initialization happens offline from logged missions; Stage II adapts on-site.
- Dependencies/risks:
- Progress verification in harsh conditions (lighting, weather) and multi-modal sensing (LiDAR/thermal).
- Safety and regulatory approvals for learning-enabled systems.
- Healthcare (Clinical Support & Surgical Suites): Long-horizon coordination and logistics
- Vision: Multi-robot orchestration (sterile supply flow, room turnover, instrument handling) with dynamic priorities.
- Potential products:
- Centralized “reward model bank” for hospital workflows; per-ward subgoal templates; multi-agent certainty-aware routing.
- Dependencies/risks:
- High safety bar; robust sparse success definitions; rigorous validation of self-certainty as a reliable proxy.
- Autonomous Driving & Mobile Autonomy: Route-level behavior optimization via semantic subgoals
- Vision: Use high-definition maps and route plans to define subgoals; use multi-modal progress verification to initialize value functions for complex maneuvers (e.g., merges, detours).
- Potential products:
- “Scenario-aware value initializers” to reduce reliance on hand-crafted shaping in simulation training.
- Dependencies/risks:
- Domain shift from tabletop/home to road; safety-critical constraints; need for high-fidelity progress signals beyond VLMs.
- Multi-Agent Systems (Warehouses, Hospitals, Airports): Team-level subgoal planning with certainty-aware coordination
- Vision: Decompose fleet tasks into agent- and team-level subgoals; use aggregated self-certainty to allocate work and resolve conflicts.
- Potential products:
- Fleet managers that optimize assignments using per-agent certainty and global progress estimates.
- Dependencies/risks:
- Communication and scheduling under uncertainty; theoretical grounding for certainty aggregation.
- On-Robot Continual and Federated Learning: In-situ adaptation without hand-crafted rewards
- Vision: Robots periodically run short Stage I sessions on logged data to refresh value functions; then continue Stage II with certainty-guided PPO during normal ops.
- Potential products:
- Federated “value init” servers; privacy-preserving LLM/VLM distillation on-device.
- Dependencies/risks:
- Resource constraints (compute/latency) and privacy/security of video and scene graphs; robust drift detection.
- Standardization & Policy: Reward-model governance and safety cases for learning-enabled robots
- Vision: Define standards for subgoal decomposition prompts, progress-verifier audits, and self-certainty thresholds.
- Potential outputs:
- Documentation templates, evaluation protocols, and compliance tests for VLLR-like reward modeling.
- Dependencies/risks:
- Agreement across vendors/sectors; alignment with safety regulators and industry bodies.
- Generalized Agent Systems (Beyond Robotics): Long-horizon software/embodied agents
- Vision: Apply the two-stage “progress-to-value” + “self-certainty” template to software agents (e.g., IT automation, RPA) where tasks are decomposed into verifiable milestones.
- Potential products:
- Certainty-guided agent frameworks with LLM milestone verification on logs/UI states.
- Dependencies/risks:
- Defining reliable milestone verification signals; calibration of certainty for non-physical domains.
- Robust Progress Verification: Next-gen VLM/3D-VLM/State Estimators for long horizons
- Vision: Train or fine-tune domain-specific VLMs that reduce hallucinations and support real-time progress estimation from multi-modal input.
- Potential products:
- “Task-aware progress verifiers” that fuse vision, language, maps, proprioception.
- Dependencies/risks:
- Data collection and labeling for progress supervision; maintaining low latency and cost.
- Cross-Embodiment & Cross-Task Reward Transfer: Reward priors reusable across robots and domains
- Vision: Libraries of subgoal templates and value initializers transferable across embodiments (mobile bases, arms, humanoids).
- Potential products:
- “Reward prior packs” for common long-horizon tasks (tidy, restock, inspect).
- Dependencies/risks:
- Differences in action spaces and sensing; need for embodiment-aware adapters.
Notes on Feasibility and Transferability
- What’s ready now:
- The two-stage VLLR pipeline as described (short VLM-supervised value initialization + PPO with self-certainty and sparse success) can be applied to any setting that offers: (a) task instructions, (b) an approximate scene graph, (c) a pretrained policy, and (d) a binary success condition.
- Key assumptions to validate for each deployment:
- Quality of scene graphs and task instructions strongly affects LLM subgoals.
- VLM progress estimates need smoothing and may still be noisy; reliance is limited to Stage I but calibration is important.
- Self-certainty (distribution concentration) must be weighted carefully to avoid overconfidence; requires tuning and monitoring.
- Safety wrappers (fallback policies and thresholds) are recommended when deploying certainty-guided finetuning in the real world.
Glossary
- A* (A-star): A graph search algorithm that computes shortest paths, often used to estimate optimal episode lengths. "calculated using A* and provided by the dataset"
- Ablation studies: Controlled experiments that remove or isolate components of a system to assess their individual contributions. "Ablation studies reveal complementary benefits"
- Affordance: A functional property of an object that suggests possible actions (e.g., something you can sit on). "Object Affordance Navigation"
- Credit assignment: The problem of determining which actions are responsible for outcomes, especially hard with sparse feedback. "relying solely on sparse success signals leads to severe credit assignment problems"
- Critic: In actor-critic RL, the value function estimator that evaluates states (or state-action pairs) to guide policy updates. "the pretrained policy obtained from imitation learning does not provide a suitable critic"
- Dense reward: A frequently provided reward signal that gives feedback at many timesteps rather than only at episode end. "a dense reward framework"
- Egocentric: Referring to observations from the agent’s own viewpoint, such as robot-centered camera images. "two egocentric RGB cameras"
- Extrinsic reward: A reward signal derived from external sources or evaluators (e.g., LLMs/VLMs) reflecting task progress. "an extrinsic reward from LLMs and Vision-LLMs (VLMs)"
- Foundation policy: A pretrained, general-purpose policy model intended to transfer across tasks and environments. "pretrained foundation policies"
- Hallucination: Spurious or incorrect model predictions not grounded in the input (e.g., falsely recognizing an object). "due to false object recognition caused by hallucinations"
- Imitation learning: Learning policies by mimicking expert demonstrations rather than trial-and-error exploration. "trained primarily via large-scale imitation learning"
- Indicator function: A function that outputs 1 when a condition holds and 0 otherwise, used to gate reward terms or stages. "are indicator functions that activate the corresponding reward terms only during the specified training stage"
- Intrinsic reward: A self-derived signal based on the agent’s internal metrics (e.g., confidence) to guide learning. "as an intrinsic reward signal"
- LLM: A neural model trained on large text corpora capable of reasoning and generating structured language outputs. "a LLM"
- Long-horizon: Tasks that require many sequential steps or extended planning before receiving final feedback. "Long-horizon robotic tasks require a robot to compose multiple skills"
- Median filtering: A noise-reduction technique that replaces values with the median of a local window to suppress spikes. "corrected using median filtering"
- Mobile manipulation: Robotic tasks combining navigation (mobility) and object interaction (manipulation). "In mobile manipulation"
- Out-of-distribution (OOD): Data or tasks that differ from those seen during pretraining or training, challenging generalization. "out-of-distribution tasks"
- Policy gradient: A class of RL algorithms that optimize policies by estimating gradients of expected returns with respect to policy parameters. "policy gradient"
- Policy self-certainty: A measure of how concentrated (low-entropy) a policy’s action distribution is, used as a confidence-based intrinsic signal. "we introduce policy self-certainty"
- PPO (Proximal Policy Optimization): A policy-gradient RL algorithm that stabilizes updates by constraining changes to the policy. "PPO finetuning"
- Preference-based RL: RL methods that learn from human or model preferences (comparisons) rather than numeric rewards. "preference-based RL"
- ProcThor: A large-scale, procedurally generated simulator suite for household environments used in embodied AI research. "ProcThor"
- Reward engineering: The manual design of task-specific reward functions or shaping terms to guide RL. "without manual reward engineering"
- Running maximum: A sequence statistic tracking the highest value observed so far, used here to compute incremental progress rewards. "running maximum progress"
- Scene graph: A structured representation of objects and their relationships in an environment used for reasoning and planning. "scene graph"
- SEL (Success weighted by Episode Length): A metric that scales success by efficiency, rewarding shorter successful episodes. "Success weighted by Episode Length (SEL)"
- Sparse reward: A reward signal provided rarely (e.g., only upon success), making learning and credit assignment difficult. "sparse task-success rewards"
- Subgoal: An intermediate objective in a hierarchical task that structures progress toward the final goal. "subgoals"
- Task decomposition: Breaking a high-level instruction into a sequence of ordered subgoals to guide execution. "Task Decomposition with LLMs"
- Temporal consistency filtering: A post-processing step enforcing smoothness over time to suppress spurious prediction spikes. "apply temporal consistency filtering"
- Value function: An estimator of expected future return from a state (or state-action) used to guide policy updates. "the value function"
- Value function initialization: Seeding the critic with informative signals (e.g., VLM-derived progress) before full RL training. "used as a reward signal for initializing the value function"
- Vision-LLM (VLM): A model that jointly processes images and text to assess visual-semantic alignment and progress. "vision-LLM (VLM)"
- World model: An internal representation of environment dynamics and structure that supports prediction and planning. "implicit world model"
Collections
Sign up for free to add this paper to one or more collections.