Robo-Dopamine: General Process Reward Modeling for High-Precision Robotic Manipulation
Abstract: The primary obstacle for applying reinforcement learning (RL) to real-world robotics is the design of effective reward functions. While recently learning-based Process Reward Models (PRMs) are a promising direction, they are often hindered by two fundamental limitations: their reward models lack step-aware understanding and rely on single-view perception, leading to unreliable assessments of fine-grained manipulation progress; and their reward shaping procedures are theoretically unsound, often inducing a semantic trap that misguides policy optimization. To address these, we introduce Dopamine-Reward, a novel reward modeling method for learning a general-purpose, step-aware process reward model from multi-view inputs. At its core is our General Reward Model (GRM), trained on a vast 3,400+ hour dataset, which leverages Step-wise Reward Discretization for structural understanding and Multi-Perspective Reward Fusion to overcome perceptual limitations. Building upon Dopamine-Reward, we propose Dopamine-RL, a robust policy learning framework that employs a theoretically-sound Policy-Invariant Reward Shaping method, which enables the agent to leverage dense rewards for efficient self-improvement without altering the optimal policy, thereby fundamentally avoiding the semantic trap. Extensive experiments across diverse simulated and real-world tasks validate our approach. GRM achieves state-of-the-art accuracy in reward assessment, and Dopamine-RL built on GRM significantly improves policy learning efficiency. For instance, after GRM is adapted to a new task in a one-shot manner from a single expert trajectory, the resulting reward model enables Dopamine-RL to improve the policy from near-zero to 95% success with only 150 online rollouts (approximately 1 hour of real robot interaction), while retaining strong generalization across tasks. Project website: https://robo-dopamine.github.io



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching robots to do precise, tricky tasks—like inserting a plug, stacking blocks, or folding a shirt—by giving them better “rewards” while they learn. In robot training, a reward is like points in a video game: it tells the robot if it’s getting closer to finishing the task. The authors introduce Robo-Dopamine, which has two parts:
- Dopamine-Reward: a smarter “progress meter” that can tell how far along a task the robot is, moment by moment.
- Dopamine-RL: a safe way for robots to use that progress meter to learn quickly without getting “tricked” into chasing the wrong kind of points.
What questions did the researchers ask?
The paper focuses on two simple questions:
- How can we build a general, reliable “progress meter” that understands each small step in a task, even when the robot’s hand blocks the camera?
- How can we use this progress meter to speed up learning, without accidentally encouraging the robot to get stuck in high-scoring-but-wrong behaviors (like repeating a halfway step to farm points)?
How did they do it?
To make this understandable, think of training a robot like guiding a player through a long obstacle course. You need a fair scorekeeper and helpful signs that point towards the finish line without moving the finish line itself.
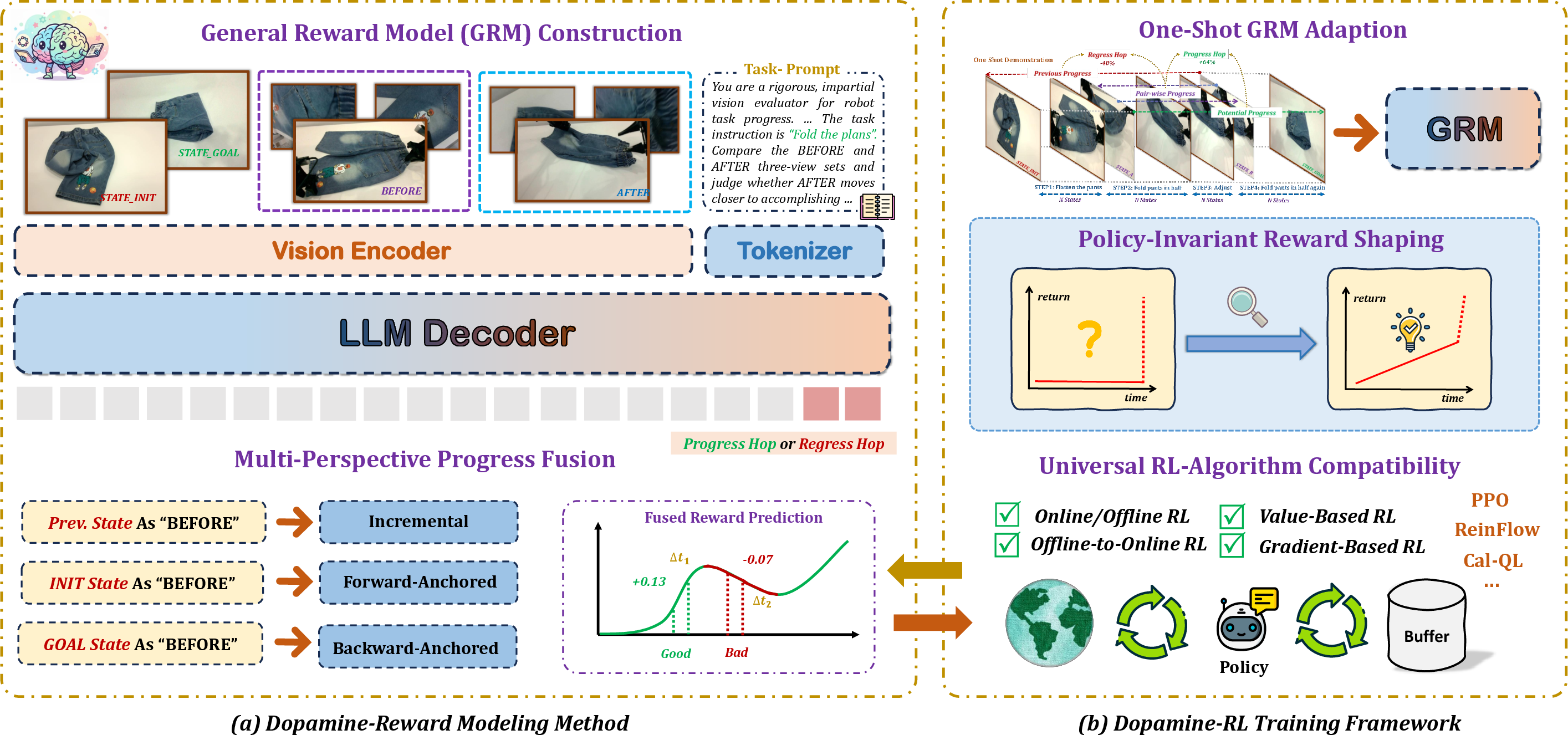
Building a better “progress meter” (Dopamine-Reward and the GRM)
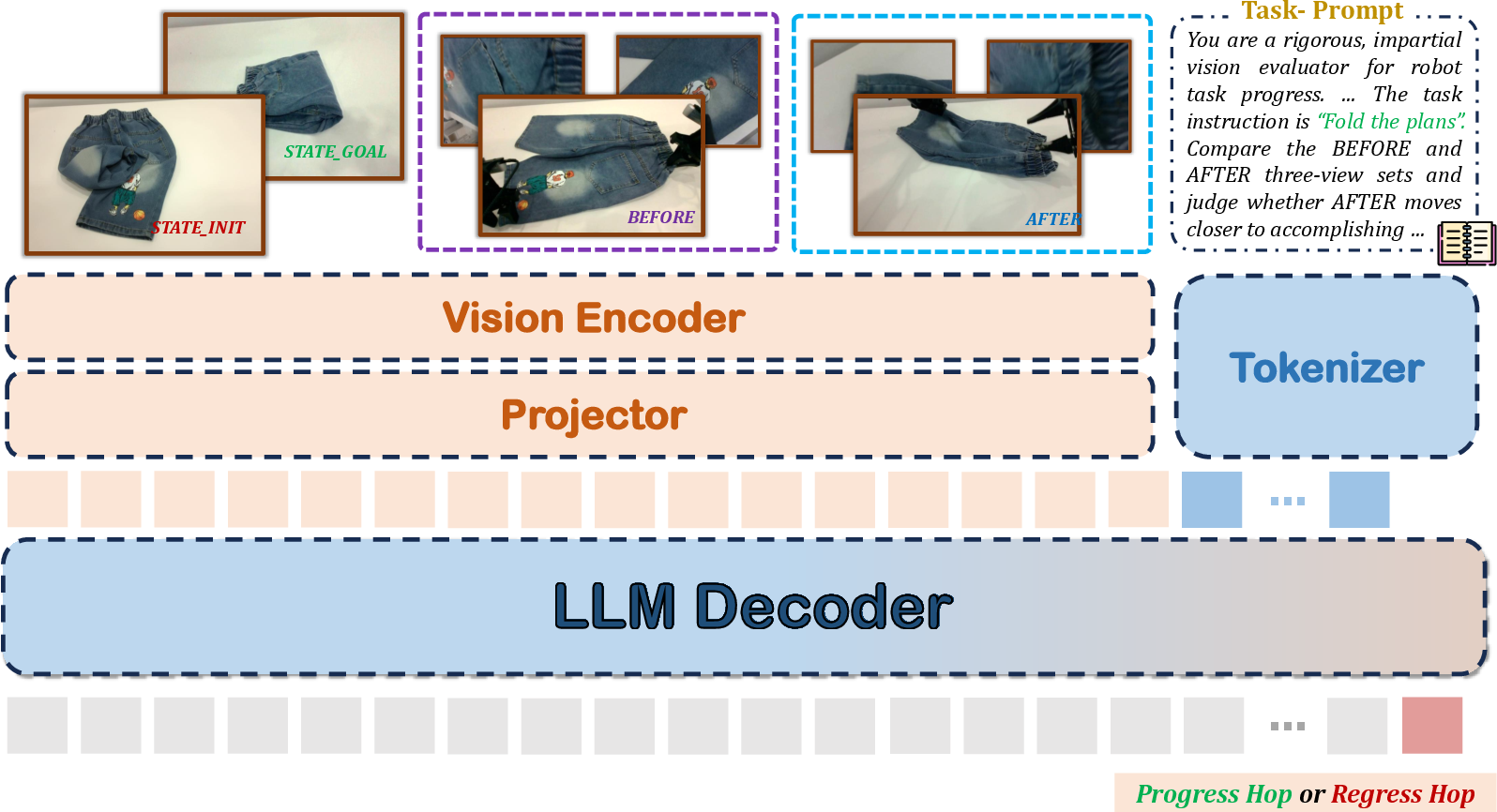
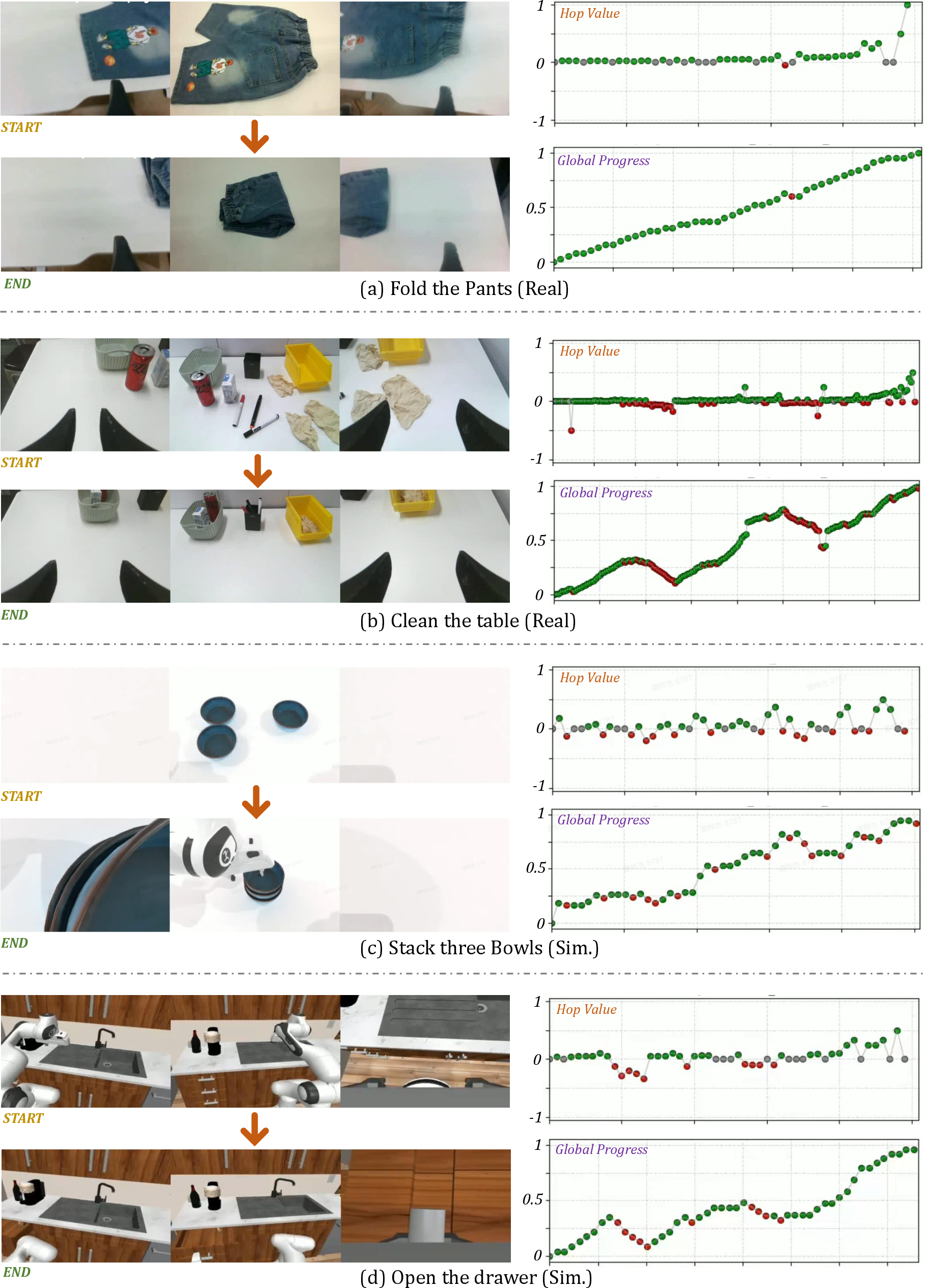
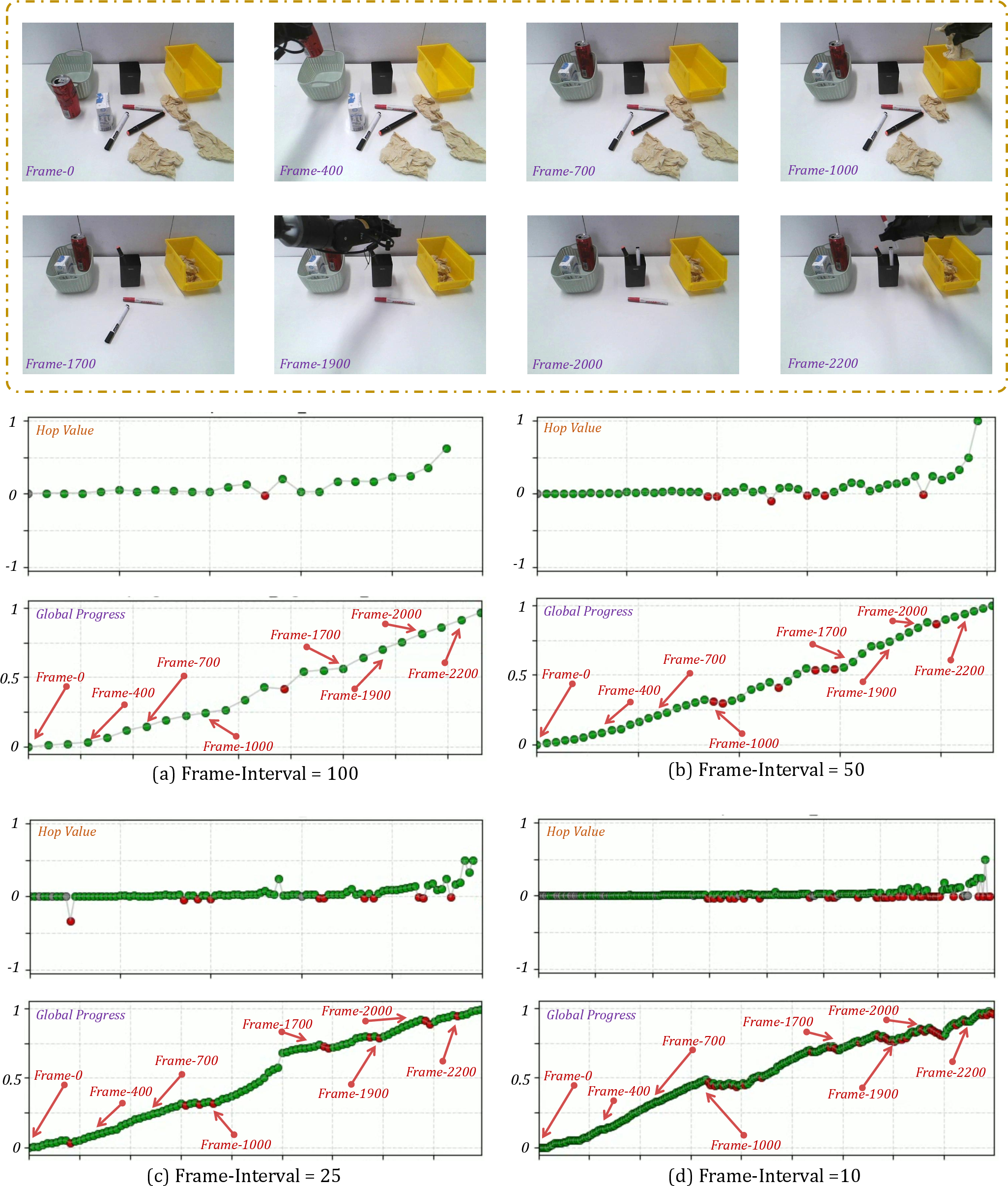
- General Reward Model (GRM): This is an AI judge that looks at the task description plus images from multiple cameras (for example, a wrist camera and a room camera). It compares a “before” and “after” moment and estimates how much closer the robot got to the goal.
- Step-aware progress: The model doesn’t just say “done or not.” It understands small sub-steps (like “grip,” “align,” “insert”) and how important each one is.
- Multi-view vision: Using more than one camera helps when one view is blocked (for example, the robot’s hand hides the object). Seeing from multiple angles makes the judgment more accurate.
- “Hop”-based labeling: Instead of giving a raw score, the model learns how big a “hop” forward (or backward) the robot made from one moment to the next, scaled to the remaining distance to the goal. Think of it like: “How big a leap did you take toward the finish line compared to how far you had left?”
- Multi-Perspective Progress Fusion: The model estimates progress in three complementary ways, then blends them:
- Step-by-step: How much did you improve since the last moment?
- From the start: How far are you from the beginning now?
- From the goal: How close are you to the finish line now?
- Combining these is like asking three fair referees and then averaging their opinions to reduce mistakes.
- Optional consistency check: If the start-based and goal-based views disagree a lot, the system becomes cautious. This prevents “reward hacking,” where the robot might find a weird camera angle that looks good but isn’t real progress.
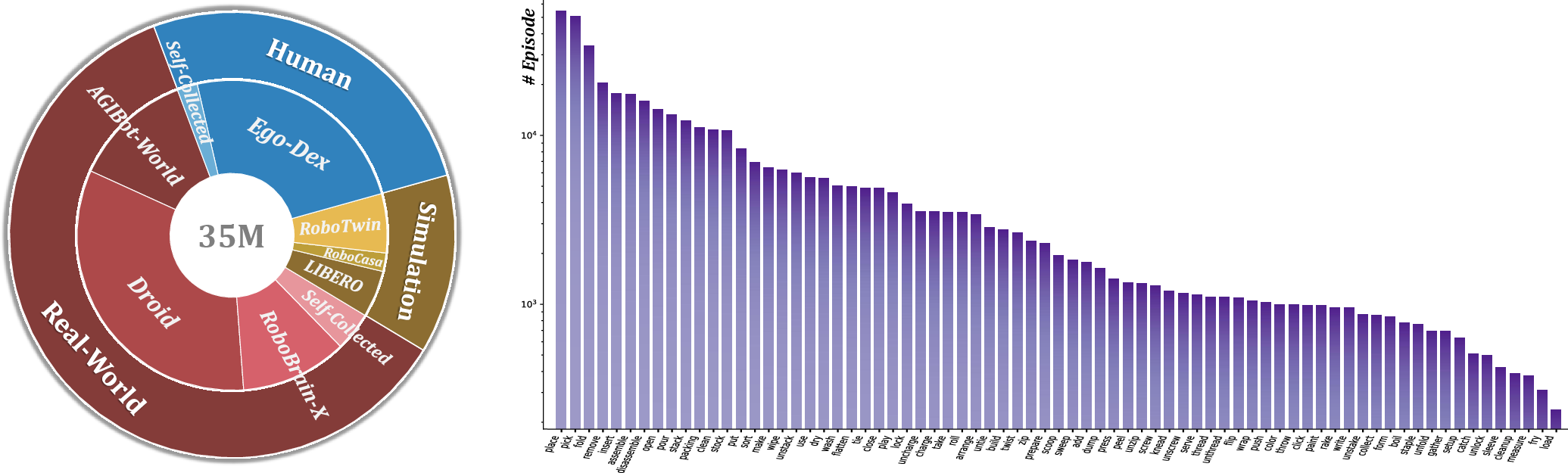
Training the GRM used a very large and diverse dataset: over 3,400 hours of real robots, simulations, and human videos, with more than 100,000 task attempts and 35 million labeled before/after pairs. That much variety helps the model handle many different situations.
Teaching with safe rewards (Dopamine-RL)
- The “semantic trap” problem: If you give points for every small improvement, the robot might find a loophole—like looping a halfway move that earns points—rather than finishing the task.
- Policy-invariant reward shaping: The authors design the reward in a way that adds helpful guidance (nudges toward the goal) without changing what the best final behavior should be. In other words, it adds arrows on the race track but doesn’t move the finish line. This is backed by solid math, so the robot doesn’t get tricked into the wrong strategy.
- One-shot adaptation: To use the GRM on a new task, they only need one example demonstration. This makes setup fast and practical.
- Works with many learning styles: Their method plugs into different reinforcement learning (RL) algorithms, both in simulation and on real robots.
What did they find, and why does it matter?
Here are the main results, explained simply:
- More accurate progress judgments:
- The GRM was very good at judging how far along a task was, even with videos shuffled out of order.
- It correctly judged final success much more often than previous models, especially when using multiple camera views.
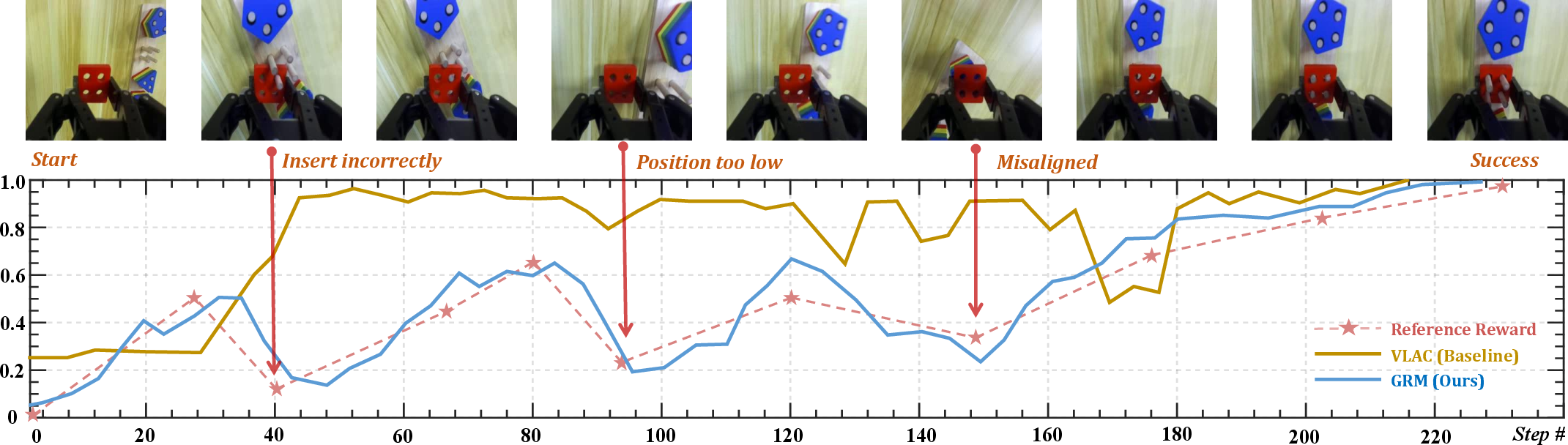
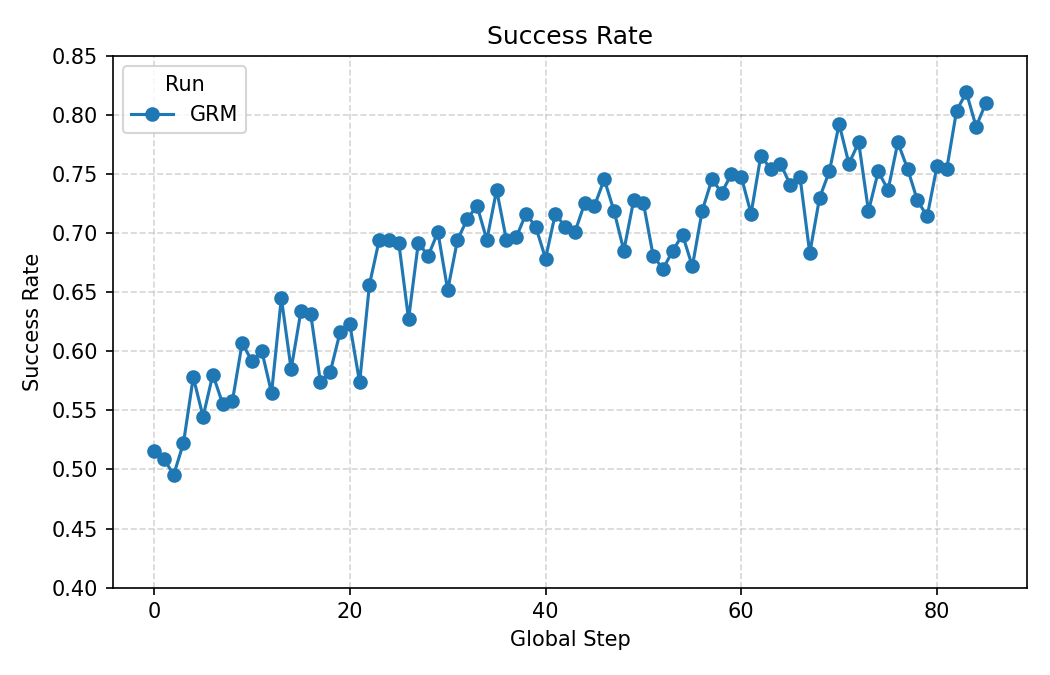
- Faster learning on real robots:
- After adapting to a new task with just one expert example, a robot could go from almost zero success to around 95% success in about 150 tries (roughly one hour of practice).
- Stronger generalization:
- The learned behaviors worked well even when the objects, layouts, or backgrounds changed (for example, different block shapes or table settings).
- Safe and stable training:
- The special reward design avoided the “point farming” trap, keeping the robot focused on truly finishing tasks.
Why it matters: Precise, contact-heavy tasks (like plugging, fitting, and folding) are some of the hardest things for robots to learn. This work shows a way to train robots quickly and reliably without hand-coding lots of rules or spending days collecting huge demonstration sets. It brings practical robot learning closer to real-world use in homes, warehouses, labs, and factories.
What’s the bigger impact?
- Less manual reward engineering: Teams won’t have to design a custom scoring system for every new task.
- Fewer demonstrations needed: One good example can be enough to get started.
- Safer, more reliable learning: The robot won’t learn weird shortcuts that look good in the score but fail in reality.
- Works across many tasks and setups: Multi-view and step-aware design make it robust to occlusions and small, precise motions.
In short, Robo-Dopamine gives robots a trustworthy sense of progress and a safe way to use it, helping them master difficult tasks much faster and with far less human effort.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper presents promising results, but several aspects remain missing, uncertain, or left unexplored. Future work could concretely address the following points:
- Scope of generalization: Evaluate GRM and Dopamine-RL on substantially broader settings (mobile manipulation, deformable objects, fluids, outdoor scenes, cluttered environments, non-planar workspaces) to quantify limits of visual progress modeling outside the tested tasks.
- Multi-view dependency: Characterize how performance degrades with fewer cameras, unsynchronized views, miscalibration, variable baselines, and missing viewpoints; develop methods for automatic camera calibration and view-robust reward inference without multi-view rigs.
- Occlusion robustness beyond vision: Assess and integrate proprioception, force/torque, tactile, or audio signals for phases where visual cues are insufficient (e.g., tight-fit insertions under full occlusion).
- Dataset release and reproducibility: Clarify availability of the 3,400-hour, 100K-trajectory dataset and standardized splits; quantify dataset biases and coverage, and provide privacy/compliance documentation to enable reproducible benchmarking.
- Annotation cost and quality: Measure the human effort for keyframe segmentation and hop labeling; report inter-annotator agreement; study sensitivity to segmentation granularity and propose automated or weakly supervised segmentation/labeling pipelines.
- Multi-strategy tasks and step ordering: Determine whether hop-based progress and step-wise discretization penalize valid alternative action sequences; develop order-agnostic progress models that respect multiple feasible strategies.
- Fusion strategy design: Replace simple averaging with learned, uncertainty-aware fusion (e.g., Bayesian ensembling, heteroscedastic weighting); provide theoretical guarantees or error bounds for fusion under correlated prediction errors.
- Uncertainty calibration and OOD detection: Formalize the consistency-checking heuristic (parameter α, normalization) with calibrated uncertainty; quantify false-positive reward hacking rates and develop principled OOD detectors that gate reward updates.
- Policy-invariant shaping with noisy potentials: Derive theoretical and empirical bounds on performance and convergence when the potential Φ is inaccurate; analyze how misestimated Φ interacts with PBRS and whether invariance holds in practice given noisy outcome detection.
- Automated outcome detection thresholding: Conduct sensitivity analyses for the success threshold δ; explore adaptive thresholds and temporal stability checks to avoid premature termination or misclassification of near-misses.
- Compute footprint and real-time feasibility: Report GRM inference latency, throughput, and hardware requirements (edge vs. cloud) during closed-loop control; study how computational delays affect policy learning and control stability.
- Safety and constraint handling: Incorporate safety-aware exploration (contact force limits, risk-sensitive RL, constraint satisfaction) and evaluate policy behavior under safety-critical conditions; provide failure handling and fallback strategies.
- Robustness to camera failures and desynchronization: Test resilience to dropped frames, drifting timestamps, motion blur, dynamic viewpoint changes, and partial sensor outages; add temporal alignment mechanisms and fault-tolerant fusion.
- Temporal modeling vs. pairwise hops: Compare pairwise hop predictions against sequence models (RNNs/Transformers) that leverage longer temporal context; quantify gains on truly long-horizon tasks and under partial observability.
- Online GRM adaptation: Explore on-policy or active learning to continuously refine GRM during RL (with safeguards against reward hacking), including human-in-the-loop corrections and data selection strategies.
- Broader baselines and ablations: Benchmark against stronger PRM and PBRS methods, inverse RL, preference-based RL, and modern reward-learning frameworks; provide detailed ablations on GRM size, architecture, and training regimes.
- Sensitivity to discount factor γ and shaping scale: Systematically study how γ (and λ, h) affects shaping magnitude, learning dynamics, and convergence; consider scheduling or adaptive discounting for different task horizons.
- Integration of non-visual modalities for high-precision contact: Quantify where vision-only rewards fail and how adding haptics/force improves success on tight-tolerance assemblies; design multi-modal GRM variants.
- Cross-embodiment transfer: Test GRM/Dopamine-RL across diverse robot morphologies, grippers, and actuation types; measure how much one-shot adaptation suffices and when additional adaptation data is needed.
- Task description quality and language conditioning: Analyze sensitivity to ambiguous or incorrect instructions; evaluate automatically generated or compressed task descriptions and their impact on progress estimation.
- Reward calibration beyond VOC and binary completion: Provide continuous calibration metrics (e.g., expected calibration error), human preference alignment studies, and per-step progress accuracy benchmarks.
- Cyclic or non-monotonic tasks: Investigate reward behavior on tasks with loops, repeated subtasks, or regressions; design progress measures that avoid oscillation exploitation and remain path-independent when appropriate.
- Lifelong and multi-task settings: Study continual learning, task-switching, and catastrophic forgetting in GRM and policies; enable transfer and retention across many tasks without degradation.
- Data balancing hyperparameters: Report sensitivity to N_hop, N_dis, ε (zero-hop threshold), and α (consistency weight); offer guidelines or automated tuning procedures for robust GRM training.
- Human-robot interaction and multi-agent tasks: Extend to collaborative manipulation with humans or other robots; handle social safety, intent inference, and dynamic role allocation.
- Release artifacts and documentation: Ensure code, trained models, calibration tools, and detailed experimental protocols are publicly available; include robustness tests, failure case catalogs, and reproducibility checklists.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging the paper’s General Reward Model (GRM), Dopamine-Reward, and Dopamine-RL. Each bullet includes the sector, an actionable use case, potential tools/workflows, and key assumptions or dependencies.
- Sector: Manufacturing (electronics, assembly)
- Use case: Rapidly teach cobots precision insertion and assembly (e.g., connector plugging, circuit completion, peg-in-hole) using one-shot GRM adaptation and Dopamine-RL to reach high success rates with ~1 hour of robot interaction.
- Tools/workflows: Multi-view camera kit (wrist + third-person), GRM-inference service, Dopamine-RL plugin for PPO/Cal-QL/ReinFlow, “Progress Dashboard” for fused progress curves, automated success thresholding (Φ ≥ 0.95).
- Assumptions/dependencies: Camera calibration and synchronization, clean single expert demonstration, safe exploration gates (e-stop, workspace constraints), GPU for GRM inference, task similar enough to GRM pretraining distribution.
- Sector: Logistics and warehousing
- Use case: Pick-and-place, packing, shelf replenishment under occlusion (hands, containers), with GRM providing robust step-aware progress and Dopamine-RL accelerating learning across varying layouts and backgrounds.
- Tools/workflows: GRM multi-view fusion, consistency-aware progress filtering to prevent reward hacking in OOD states, ROS/MoveIt integration, reward shaping via PBRS-compatible term F = γΦ(s′) − Φ(s).
- Assumptions/dependencies: Reliable object detections are not strictly required (GRM is video-based), but multi-view coverage and well-defined initial/goal states are needed.
- Sector: Industrial QA and rework
- Use case: Automated corrective actions (e.g., detecting misalignment and performing re-insertion or tightening) guided by dense progress signals rather than brittle binary success classifiers.
- Tools/workflows: GRM reward profiles for error detection, Dopamine-RL for policy refinement, “Reward Integrity Monitor” using bi-directional consistency to flag spurious signals.
- Assumptions/dependencies: Access to process videos and consistent task goal specification; minimal per-task SFT (one-shot) on rework exemplars.
- Sector: Robotics startups and integrators
- Use case: Productize “Reward-as-a-Service” for client robots—providing GRM-based reward signals and a Dopamine-RL SDK that plugs into common RL stacks (online, offline-to-online).
- Tools/workflows: Robo-Dopamine SDK (GRM + shaping + consistency checks), model wrappers for ROS2, calibration utilities, telemetry for progress/VOC metrics.
- Assumptions/dependencies: Service-level agreements on data privacy (multi-view streams), sufficient inference throughput, task onboarding via one demo and textual description.
- Sector: Healthcare (simulation training)
- Use case: Train precision manipulation policies in surgical or rehab simulators (suturing proxies, tool alignment) with dense, step-aware progress to reduce manual reward engineering.
- Tools/workflows: GRM adapted to simulation visuals, policy-invariant shaping to avoid stall-at-high-progress behavior, curriculum design via adaptive hop sampling.
- Assumptions/dependencies: Visual domain match (sim render fidelity), stringent safety gating before any real-world deployment; regulatory considerations keep this to sim-only in the near term.
- Sector: Education (robotics curricula, labs)
- Use case: Teach PBRS, multi-view perception, and process reward modeling with hands-on labs where students adapt GRM from one demo and observe faster RL convergence vs. sparse rewards.
- Tools/workflows: Lab kits with wrist/overhead cameras, open-source RL baselines (PPO, Q-learning), prepackaged tasks (folding, stacking, insertion).
- Assumptions/dependencies: Modest compute and camera setups; reproducible task stations; adherence to the paper’s success thresholding and safety practices.
- Sector: Academia (research and benchmarking)
- Use case: Evaluate PRMs and reward shaping on public datasets (DROID, LIBERO, RoboCasa) with VOC benchmarks; compare multi-view vs. single-view baselines and ablate fusion strategies.
- Tools/workflows: GRM training/finetuning scripts, rank-correlation evaluation, ablation harness (incremental, forward, backward fusion).
- Assumptions/dependencies: Access to datasets and multi-view data; alignment with paper’s hop-based discretization and sampling.
- Sector: Home robotics (labs and pilot deployments)
- Use case: Household tasks like folding clothes, clearing desks, loading dishes; one demonstration per task and multi-view setup to mitigate occlusions and generalize across object/background changes.
- Tools/workflows: Consumer-grade wrist/overhead cameras, smartphone-captured initial/goal states, Dopamine-RL policy learning with automated completion detection.
- Assumptions/dependencies: Safety and reliability constraints; currently best suited to controlled lab or pilot settings rather than unsupervised consumer deployment.
- Sector: Policy (organizational governance)
- Use case: Internal guidelines for reward shaping in robotics to avoid misaligned incentives; adopt policy-invariant GRM shaping and consistency checks as standard safeguards.
- Tools/workflows: Technical policy templates specifying PBRS-compatible shaping, OOD consistency metrics, reward hacking audits on exploration logs.
- Assumptions/dependencies: Organizational buy-in; cross-functional collaboration between ML, safety, and operations teams.
- Sector: Software/ML tooling
- Use case: Plug-in modules for existing RL libraries to consume GRM progress and apply shaping without changing optimal policies; a “multi-view reward sensor” abstraction in perception stacks.
- Tools/workflows: Environment wrappers exposing Φ(s), shape-reward functions, success gating, replay buffers enriched with progress annotations.
- Assumptions/dependencies: Stable RL APIs; deterministic logging for reproducibility; correct γ configuration and Markovian reward assumption.
Long-Term Applications
These applications are feasible with further research, scaling, or productization. They extend the current capabilities to broader, higher-stakes, or more complex domains.
- Sector: Generalist factory robots (fleet-scale self-improvement)
- Use case: On-the-line robots that continuously learn and adapt to new SKUs and fixtures via one-shot GRM adaptation; centralized “Reward Model Hub” serving task-specific potentials to fleets.
- Tools/products: Reward Model Marketplace, fleet A/B testing harness, cross-task transfer learning for GRM, automated task description ingestion.
- Dependencies: Robust cross-domain generalization, enterprise MLOps for model versioning and compliance, strong safety monitors for online RL.
- Sector: Dexterous manipulation and micro-assembly
- Use case: In-hand manipulation (e.g., wiring, tiny component placement) where tactile sensing, fine contact dynamics, and occlusion are extreme.
- Tools/products: GRM extensions that fuse tactile/force-torque data with multi-view vision; higher-resolution, high-rate cameras; specialized hop discretization for dexterous sub-steps.
- Dependencies: Multi-modal sensor fusion research, richer datasets, new GRM architectures, precise simulators for pretraining.
- Sector: Healthcare (assistive and surgical robots in the real world)
- Use case: Robots assisting with dressing, feeding, or surgical subtasks guided by dense, verifiable progress signals that avoid semantic traps.
- Tools/products: Clinically validated GRM variants, human-in-the-loop oversight tools, certified PBRS libraries with explainable progress telemetry.
- Dependencies: Rigorous safety standards, clinical trials, regulatory approval (FDA/CE), robust fail-safes and liability frameworks.
- Sector: Hazardous environments (energy, subsea, nuclear)
- Use case: Maintenance robots executing manipulation under severe occlusion and limited visibility using multi-view (remote) vantage points and GRM-based reward shaping.
- Tools/products: Remote multi-view rigs, domain-adapted GRMs, reliability scoring via consistency-aware weighting in OOD states.
- Dependencies: Ruggedized hardware, resilient comms, domain adaptation across weather/lighting; extensive validation.
- Sector: Multi-robot coordination
- Use case: Team policies shaped by shared or decomposed progress potentials, enabling coordinated assembly or packing tasks without misaligned incentives.
- Tools/products: Joint-progress GRM, compositional shaping for sub-teams, consensus mechanisms for progress estimates.
- Dependencies: Advances in multi-agent RL with PBRS, communication protocols, compositional reward designs.
- Sector: Consumer home robots
- Use case: Broadly capable domestic robots that learn new chores from one demo and generalize; task training apps with camera-based initial/goal capture.
- Tools/products: Home multi-view camera packs, task training mobile app, privacy-preserving GRM inference (on-device or edge).
- Dependencies: Robust, unsupervised reliability; low-cost hardware; strong privacy and safety guarantees; simplified user onboarding.
- Sector: Standards and certification (policy)
- Use case: Formal standards for learned reward models and PBRS to prevent reward hacking; certification pathways for GRM-based systems.
- Tools/products: Auditable protocols for progress estimation (VOC, consistency metrics), conformance tests for policy invariance, logging requirements.
- Dependencies: Multi-stakeholder consortia, regulatory engagement, reference implementations and benchmarks.
- Sector: Tooling and ecosystem
- Use case: End-to-end pipelines for multi-view data collection, calibration, annotation, hop discretization, and GRM training; reward integrity monitoring services.
- Tools/products: Calibration wizards, dataset governance tools, automated label quality checks, “Progress Integrity” dashboards.
- Dependencies: Standardized data schemas, open datasets across industries, scalable training infrastructure.
- Sector: Language-conditioned task learning
- Use case: Combine GRM with language to define and decompose novel tasks; align progress with textual sub-goals and safety constraints.
- Tools/products: VLM-conditioned GRMs with step semantics, prompt libraries for tasks and constraints, semantic consistency monitors.
- Dependencies: Robust language grounding under occlusion; mitigating hallucinations; evaluation suites for step-aware semantics.
- Sector: Model marketplaces and interoperability
- Use case: Share and monetize task-adapted GRMs and shaping configurations across vendors; interoperable “reward adapters” for diverse robot platforms.
- Tools/products: APIs for reward potentials, ROS2-compatible adapters, license management, telemetry budgets.
- Dependencies: Platform-neutral standards, IP frameworks, cross-robot abstraction layers.
Cross-cutting assumptions and dependencies (impacting feasibility)
- Multi-view perception and calibration are central; occlusion-resilience assumes synchronized wrist and third-person views.
- One-shot adaptation benefits from high-quality demonstrations and accurate initial/goal state specification; extremely novel tasks may need more demos.
- PBRS-based policy invariance requires correct progress estimation and discount consistency; γ must be set coherently across RL updates.
- Safety and exploration constraints are non-negotiable for real robots; integrate e-stops, workspace limits, and human oversight.
- Compute requirements (for 3B–8B GRMs) and latency affect real-time applicability; consider edge accelerators or batching strategies.
- Data governance and privacy are essential when using human-centric or workplace videos; ensure consent, anonymization, and secure storage.
Glossary
- Auto-regressive models: Models that generate outputs by conditioning on previously generated elements in a sequence, often used for policies or dynamics; "auto-regressive models~\cite{xu2024rldg, chen2025conrft, lu2025vla}"
- Backward-Anchored Prediction: A progress estimation method anchored at the goal state to improve sensitivity near completion; "Conversely, Backward-Anchored Prediction is anchored to the goal state , where progress is one."
- Behavioral Cloning (BC): A supervised learning approach that trains policies to mimic expert demonstrations; "We compare against strong baselines: Behavioral Cloning (BC) on 50 demos, and Proximal Policy Optimization~\cite{ppo} (PPO) using a sparse reward in simulation and ConRFT~\cite{conrft} for real-world settings."
- Cal-QL: An offline-to-online Q-learning algorithm used for real-world RL; "In real-world settings, we combine with Cal-QL\cite{calql} (a offline-to-online Q-learning based RL algorithm) and it also delivers exceptional outcomes."
- Diffusion/flow-based models: Generative modeling approaches (diffusion or normalizing flows) used for policy or dynamics learning; "and diffusion/flow-based models~\cite{liu2505flow, zang2025rlinf, zhang2025reinflow}"
- Discounted potential: A potential function multiplied by an exponential discount factor to derive shaping rewards; "we derive the reward from the continuous-time ``discounted potential'' ."
- Dopamine-Reward: A dense reward modeling method that learns step-aware process rewards from multi-view inputs; "To address these, we introduce Dopamine-Reward, a novel dense reward modeling method for learning a general-purpose, step-aware process reward from multi-view inputs."
- Dopamine-RL: A policy learning framework that uses policy-invariant reward shaping with dense rewards for efficient learning; "Building upon GRM via Dopamine-Reward, we propose Dopamine-RL, a robust and unified policy learning framework Dopamine-RL to resolve the second limitation."
- Forward-Anchored Prediction: A progress estimation method anchored at the initial state to provide a stable global reference; "Forward-Anchored Prediction provides a stable global reference by anchoring to the initial state , where progress is zero:"
- General Reward Model (GRM): A vision-LLM trained to predict fine-grained task progress and provide dense rewards; "We construct a General Reward Model (GRM) trained on a large and diverse 35M-sample dataset spanning real-world, simulation, and human-centric videos with our Dopamine-Reward"
- Hop-based relative progress normalization: A formulation that normalizes relative progress between states to prevent drift and keep progress in [0,1]; "Hop-based relative progress normalization."
- Multi-Perspective Progress Fusion: A fusion of incremental, forward-anchored, and backward-anchored predictions to produce robust progress estimates; "we employ Multi-Perspective Progress Fusion, which combines incremental, forward-anchored, and backward-anchored predictions into a final fused reward."
- Outcome Reward Models (ORMs): Models that provide binary success/failure rewards, commonly as success classifiers; "In real-world RL, a common practice is to train a success classifier as Outcome Reward Models (ORMs) to provide a binary reward signal~\cite{chen2025conrft,luo2025precise}"
- Out-of-Distribution (OOD): States or observations outside the training distribution that can cause unreliable model behavior; "its naive application in online RL faces the risk of Out-of-Distribution (OOD) hallucination."
- Policy-Invariant Reward Shaping: A shaping method that preserves the optimal policy while providing dense guidance; "Dopamine-RL employs a theoretically-sound Policy-Invariant Reward Shaping method, which enables the agent to leverage dense rewards for efficient self-improvement without altering the optimal policy"
- Potential-Based Reward Shaping (PBRS): A shaping framework where rewards are derived from differences in a potential function to guarantee policy invariance; "This matches the standard Potential-Based Reward Shaping (PBRS) framework \cite{ng1999policy}, with the GRM progress serving as the potential function."
- Process Reward Models (PRMs): Models that assign dense, step-wise rewards reflecting task progress rather than just outcomes; "recent work leverages visionâLLMs (VLMs) as Process Reward Models (PRMs)~\cite{ma2023liv,alakuijala2024video,ma2024gvl,zhai2025vlac,chen2025sarm}"
- Proximal Policy Optimization (PPO): A popular on-policy RL algorithm that optimizes a clipped surrogate objective; "PPO\cite{ppo} (Proximal Policy Optimization) algorithm"
- Q-function: The expected return of taking an action in a state and following a policy thereafter; "Since the shaping term telescopes to a state-dependent constant that is independent of the subsequent policy , the shaped Q-function is simply a state-wise shift of the original one:"
- Reward hacking: Exploiting imperfections in the reward model to obtain high rewards without accomplishing the true task; "leading to ``reward hacking.''"
- Semantic trap: A misalignment where dense proxy rewards cause a policy to optimize intermediate signals rather than the true objective; "Naively incorporating dense rewards can induce a semantic trap \cite{ng1999policy} that misguides policy optimization by inadvertently altering the optimal policy"
- Success classifier: A model trained to classify whether an episode is successful, typically used to produce binary rewards; "In real-world RL, a common practice is to train a success classifier as Outcome Reward Models (ORMs) to provide a binary reward signal"
- Telescoping sum: A series where consecutive terms cancel, leaving only boundary terms; "the cumulative discounted shaping term forms a telescoping sum that collapses to a constant boundary term"
- Value-based methods: RL algorithms that learn value functions (e.g., Q-learning) rather than directly optimizing policies; "It adapts effectively to both value-based methods and gradient-based approaches."
- Value-Order Consistency (VOC): A rank-correlation metric measuring alignment between predicted progress scores and temporal order; "The GRM achieves over 92.8\% accuracy in progress assessment, with a Value-Order Consistency (VOC) score of 0.953 on rank-correlation benchmarks"
- Video Frame Rank-Correlation: An evaluation protocol that measures how well predicted values respect the chronological order of frames; "Video Frame Rank-Correlation"
- Vision-LLMs (VLMs): Models that jointly process visual and textual inputs for tasks like progress assessment; "recent work leverages visionâLLMs (VLMs) as Process Reward Models (PRMs)~\cite{ma2023liv,alakuijala2024video,ma2024gvl,zhai2025vlac,chen2025sarm}"
Collections
Sign up for free to add this paper to one or more collections.