Token Warping Helps MLLMs Look from Nearby Viewpoints
Abstract: Can warping tokens, rather than pixels, help multimodal LLMs (MLLMs) understand how a scene appears from a nearby viewpoint? While MLLMs perform well on visual reasoning, they remain fragile to viewpoint changes, as pixel-wise warping is highly sensitive to small depth errors and often introduces geometric distortions. Drawing on theories of mental imagery that posit part-level structural representations as the basis for human perspective transformation, we examine whether image tokens in ViT-based MLLMs serve as an effective substrate for viewpoint changes. We compare forward and backward warping, finding that backward token warping, which defines a dense grid on the target view and retrieves a corresponding source-view token for each grid point, achieves greater stability and better preserves semantic coherence under viewpoint shifts. Experiments on our proposed ViewBench benchmark demonstrate that token-level warping enables MLLMs to reason reliably from nearby viewpoints, consistently outperforming all baselines including pixel-wise warping approaches, spatially fine-tuned MLLMs, and a generative warping method.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Token Warping Helps MLLMs Look from Nearby Viewpoints”
What is this paper about?
This paper asks a simple question: can we help AI systems that “look” at pictures also imagine how the same scene would look from a slightly different angle? Instead of redrawing every pixel (which can introduce mistakes), the authors try “warping” the image’s building blocks inside the model, called tokens, to create a clean, stable view from a nearby viewpoint. They show that this token warping makes the AI better at answering questions that require taking a new viewpoint.
What questions did the researchers ask?
The researchers focused on three easy-to-understand questions:
- If we shift the camera a little, can an AI imagine the new view well enough to answer questions about left/right and what objects look like?
- Is it better to move around pixels (the tiny dots that make up an image) or to move around tokens (patch-sized pieces the model uses internally)?
- If we move tokens, which way works best: pushing tokens from the old view to the new one (forward warping) or pulling the right tokens into the new view from the old one (backward warping)? And when pulling, is it enough to grab the nearest token, or should we re-cut the patch exactly at the needed spot?
How did they study it?
First, a few quick translations of technical terms:
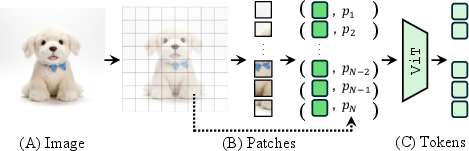
- Multimodal LLM (MLLM): A big AI that understands both pictures and text.
- Vision Transformer (ViT): A vision model that breaks an image into small square patches (like tiles), turns each tile into a token (a vector), and reasons with those tokens.
- Token: Think of it like a “smart tile” that contains both the look of a small image patch and where it sits in the picture.
- Depth map: A per-pixel estimate of how far things are from the camera—like a grayscale 3D map of the scene.
- Warping: Using depth and camera motion to figure out where parts of the image would land when you look from a slightly different angle.
What they did, in simple steps:
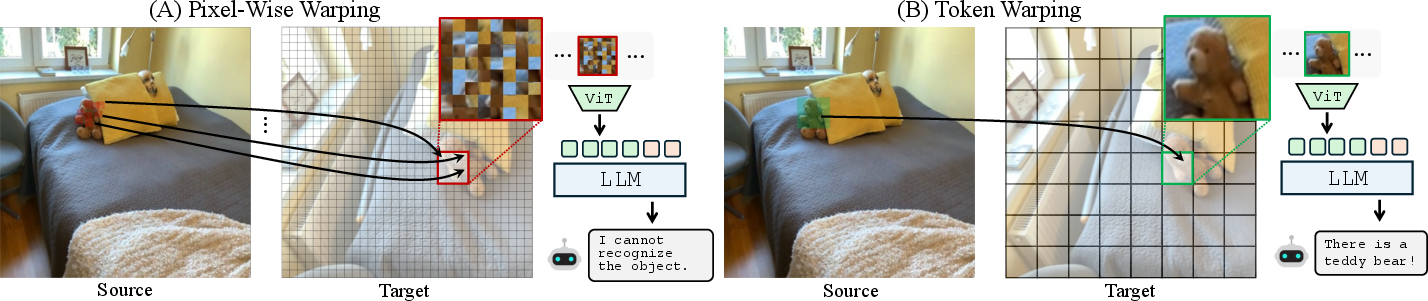
- Why tokens, not pixels: Warping pixels is fragile. Even tiny depth errors can stretch or distort objects. Tokens are bigger “parts,” so they’re more forgiving to small mistakes and preserve meaning better.
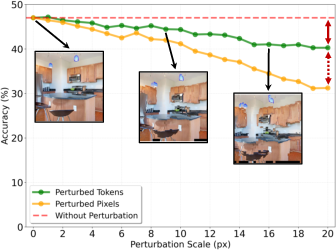
- Noise test: They “jittered” token positions on purpose (moved where patches are fetched) to see if the AI’s understanding falls apart. It didn’t—performance stayed strong even with fairly large jitters. This suggests tokens are robust to small geometric errors, which is perfect for viewpoint changes.
- Two warping directions:
- Forward warping: Push tokens from the old view into the new one. Problem: the new view can end up with holes and irregular spacing, confusing the model.
- Backward warping: Start with a clean grid in the new view and, for each position, pull the best-matching token from the old view. This keeps a neat grid the model expects.
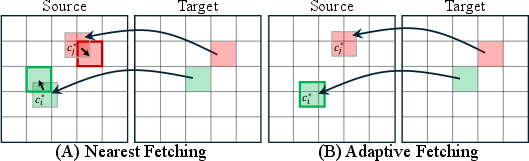
- Two ways to fetch tokens in backward warping:
- Nearest fetching: Grab the closest existing token. Fast and simple.
- Adaptive fetching: Re-cut the patch exactly at the needed center. More precise but a bit slower.
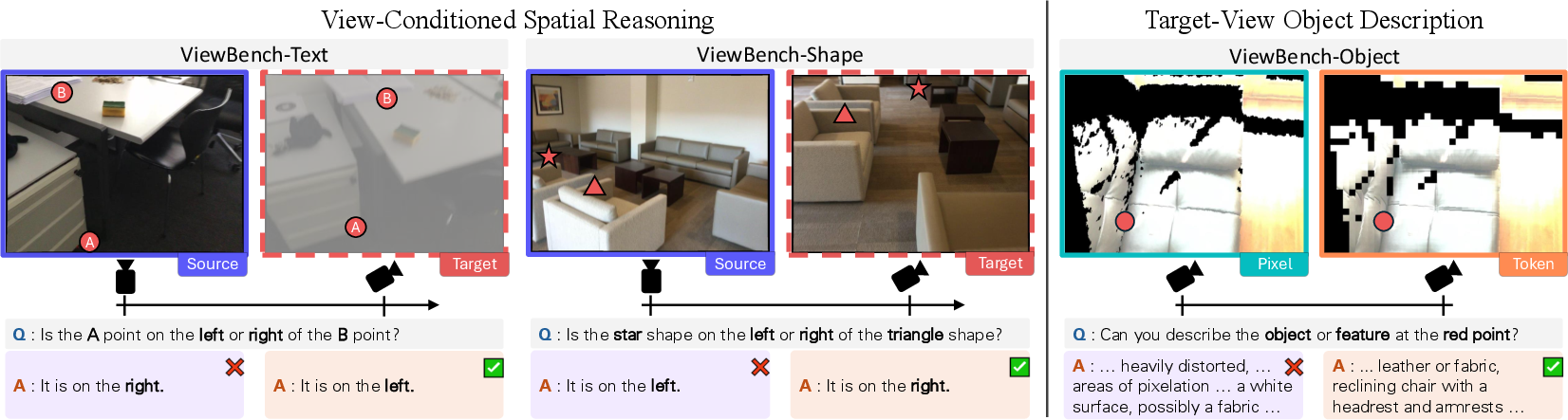
- A new test called ViewBench: They built a benchmark from real 3D indoor scenes (nearby camera pairs) to ask:
- Left/right spatial questions (with text labels or simple shapes).
- Short descriptions of objects from the target viewpoint.
- They measured accuracy for left/right and used another strong model to score description quality.
What did they find, and why is it important?
Main findings (in plain language):
- Tokens beat pixels for viewpoint changes. Warping tokens keeps objects looking normal instead of stretched or broken.
- Backward token warping is best. Starting from a clean grid in the target view and pulling the right tokens preserves structure and helps the AI reason correctly.
- Simple can be enough. The “nearest” token method often works as well as the fancier “adaptive” one, while being faster.
- Stronger than other approaches. Backward token warping outperformed:
- Pixel warping methods,
- Special MLLMs trained on spatial tasks, and
- A generative method that tries to draw the new view.
- Minimal extra cost. This works at inference time (no retraining), with small extra computation.
Why this matters: If an AI can “mentally rotate” or shift its viewpoint reliably, it gets better at tasks like:
- Understanding scenes for robots and AR/VR,
- Navigating spaces,
- Answering questions about what’s around a corner or from another person’s position,
- Keeping object details intact while changing angles.
What could this change in the future?
This work suggests that the “parts” inside vision models—tokens—are a sweet spot for mental imagery in AI: not too tiny (pixels), not too coarse (whole objects), but part-level units that are stable and meaningful. That could lead to:
- Better spatial reasoning for everyday AI assistants and embodied robots.
- Smarter and more reliable viewpoint handling in videos, navigation, and multi-camera systems.
- Practical add-ons that improve existing models without retraining.
Simple limitations and next steps:
- Works best for nearby viewpoint changes (big jumps are harder).
- Relies on a depth map; very poor depth will still hurt.
- Occlusions (hidden surfaces) and moving objects are tricky.
- Future work could combine token warping with multi-view inputs, improved depth, or lightweight training to handle larger view shifts.
In short: By “moving tokens instead of pixels,” the authors give AI a sturdier way to imagine a scene from a new angle—making viewpoint-aware reasoning more accurate, more robust, and easier to plug into today’s models.
Knowledge Gaps
Below is a single, concrete list of the paper’s unresolved knowledge gaps, limitations, and open questions that future work could address.
- Disocclusion handling: The method purposely avoids synthesizing new pixels and evaluates only regions visible in both source and target views; a principled approach to handling newly visible (disoccluded) content is missing.
- Viewpoint magnitude limits: The approach targets “nearby” viewpoint changes; quantify breakdown regimes as a function of baseline/overlap (e.g., <5% overlap, large translations/rotations) and identify thresholds beyond which token warping fails.
- Pose/intrinsic noise: Sensitivity to errors in extrinsics/intrinsics (, ) is not analyzed; realistic calibration noise, lens distortion, and rolling-shutter effects should be ablated.
- Depth quality and domain robustness: Only a single monocular depth model is used; evaluate across multiple depth estimators and domains (outdoor, textureless, reflective/transparent) to map error sensitivity and robustness.
- Occlusion/visibility resolution in backward warping: Backward mapping via a proxy mesh and ray casting lacks explicit evaluation of occlusion handling at depth discontinuities; compare different visibility strategies and quantify failure modes.
- Patch size and stride effects: The impact of ViT patch size/stride on robustness and spatial fidelity under warping is not studied; assess multi-scale or variable patch sizes for improved detail preservation.
- Orientation/scale-aware tokenization: Warping changes local orientation and scale, yet cropping remains axis-aligned and fixed-scale; explore rotated/scaled patches, deformable tokens, or orientation-aware embeddings.
- Forward warping generalization: Forward warping yields irregular token distributions considered out-of-distribution; test whether fine-tuning the vision encoder/MLLM on irregular grids mitigates performance drop (data vs. method limitation).
- Warping at deeper feature layers: Only patch embeddings are warped; investigate warping intermediate ViT features or attention positions, and compare semantic fidelity vs. computational cost.
- Computational overhead: “Minimal overhead” is not quantified; profile latency/memory for nearest vs. adaptive fetching across resolutions, patch sizes, and batch sizes.
- Cross-model generality: Results center on Qwen2.5-VL-7B; validate across diverse MLLMs (e.g., LLaVA variants, InternVL, Phi-3-Vision, GPT-4o family) and positional encoding schemes to assess universality.
- Dynamic scenes and videos: The benchmark uses static indoor scans; evaluate in dynamic scenes and video streams where moving objects and temporal consistency matter.
- Outdoor and challenging materials: Extend evaluation to outdoor environments and scenes with specular/transparent surfaces where depth is unreliable, to test robustness in real-world conditions.
- Evaluator reliability: Object-description scores rely on Qwen2.5-14B as an automatic judge; validate with human evaluation, measure inter-rater agreement, and assess evaluator bias toward specific methods.
- Benchmark task breadth: Current tasks focus on left–right reasoning and basic attribute description; add depth ordering, occlusion reasoning, up/down, distance estimation, metric geometry, counting, and relational queries under viewpoint change.
- Large-gap viewpoint scenarios: Incorporate cross-room or multistory viewpoint changes and very low-overlap pairs in ViewBench to map failure regions and stress-test token warping.
- Hybrid synthesis strategies: Explore token warping combined with generative filling for disoccluded regions; define metrics for hallucination correctness and consistency with source-view semantics.
- Calibration-aware warping: Introduce probabilistic warping that propagates depth/pose uncertainty, and test whether confidence-aware reasoning improves reliability.
- Multi-view fusion: When multiple source views exist, study token selection/aggregation strategies across views and their impact on spatial reasoning under viewpoint change.
- End-to-end training: The pipeline is inference-time only; investigate fine-tuning the vision encoder/LLM with warped-token inputs and learning warping parameters/embeddings for better distribution alignment.
- Positional embeddings after warping: Precisely characterize how positional embeddings are recomputed and compare absolute vs. relative vs. 3D-aware embeddings; quantify their contribution to performance.
- Limits of token robustness: The jitter experiment uses CV-Bench-2D with moderate displacements; probe cases requiring extreme local fidelity (OCR, thin structures, small objects, fine textures) to delineate robustness boundaries.
- Boundary-aware strategies: Analyze failures near depth discontinuities and object edges; design boundary-aware token selections or adaptive patch shapes to reduce warping artifacts there.
- Proxy mesh construction details: The mesh/ray-casting pipeline is deferred to the supplement; compare TSDF/Poisson/point-based proxies and sampling densities to quantify mapping accuracy and stability.
- Fair baseline prompting: Specialist MLLMs receive textual camera-motion prompts; assess prompt sensitivity and ensure comparable, standardized prompting across baselines to rule out prompt-induced bias.
- Safety/robustness in agents: Examine whether warping introduces spurious artifacts that could mislead downstream decisions in embodied agents; develop diagnostics and safeguards.
Practical Applications
Immediate Applications
The following use cases can be deployed now by integrating the paper’s backward token warping (preferably “Backward-Nearest”) into ViT-based MLLMs with off-the-shelf depth and pose estimation. Each item notes key dependencies and sector fit.
- Robotics micro–viewpoint reasoning for navigation and manipulation — Robotics
- What: Let a mobile robot or arm “mentally shift” its viewpoint by a few centimeters/degrees to answer spatial questions (e.g., “Is the handle left of the latch if I move slightly right?”) without rendering new pixels or retraining the MLLM.
- Tools/workflows: Token-warp module as a ROS2 node that takes RGB + depth (from stereo/LiDAR/monocular depth) and relative pose, then feeds warped tokens to an MLLM (e.g., Qwen2.5-VL, LLaVA derivatives) for task reasoning.
- Dependencies/assumptions: Nearby viewpoint with overlap (>5–10%); calibrated intrinsics and a relative pose estimate; ViT-based vision encoder; mostly rigid scenes.
- AR-guided assistance with stable viewpoint-aware Q&A — Software/AR, Daily life
- What: On-device assistants answer “from where I’ll stand next” questions while you reposition the phone (e.g., “From a step to the left, is the outlet above the desk?”), improving left/right judgments and reducing generative artifacts.
- Tools/workflows: Integrate with ARCore/ARKit depth and device pose; apply backward token warping; surface answers and arrow overlays in the AR view.
- Dependencies/assumptions: Smartphone AR depth/pose; small baseline shifts; static indoor scenes; ViT-based MLLM on-device or via edge server.
- Retail shelf auditing and warehouse slot checks with single-view extrapolation — Retail/Logistics
- What: Robots or handheld scanners reliably infer near-view spatial relations (e.g., “Is SKU A to the left of SKU B if I sidestep one slot?”) from one frame plus predicted depth, improving count/planogram checks without extra capture.
- Tools/workflows: Shelf scan -> predict depth -> backward token warp -> MLLM answers spatial prompts; integrate into existing inventory QA dashboards.
- Dependencies/assumptions: Narrow viewpoint deltas along aisles; shelf rigidity; barcode/label visibility preserved; camera calibration.
- CCTV and PTZ camera analysis with non-hallucinatory viewpoint reasoning — Security/Operations
- What: Operators (or analytic agents) assess near-view layout changes (e.g., “From a 5° pan right, is the bag to the left of the pillar?”) without synthesizing pixels, aiding PTZ reposition suggestions and multi-camera handoffs.
- Tools/workflows: Depth from multi-view or monocular estimators; compute relative pan/tilt; backward token warping before MLLM VQA; log answers with confidence.
- Dependencies/assumptions: Calibrated intrinsics, approximate pose; modest motion; acceptance that newly revealed occlusions cannot be hallucinated.
- Drone and field inspection “peek” reasoning — Energy/Infrastructure
- What: During line or façade inspection, agents answer positional questions for small lateral offsets (e.g., “If I nudge right, is the tag above the bracket?”) to reduce redundant captures.
- Tools/workflows: Monocular depth (or stereo) + IMU pose; token warp; MLLM Q&A; plug into flight assistants for next-best micro-motions.
- Dependencies/assumptions: Short-baseline micro-motions; reasonably rigid targets; adequate depth under outdoor lighting.
- Safer assistance for visually impaired users — Assistive tech
- What: Given a single photo and intended step direction, assistants answer near-view questions like “Will the handle be to my left after I step forward?” with fewer hallucinations than generative image synthesis.
- Tools/workflows: Smartphone depth/pose; token warp to intended pose; concise MLLM answers with directional audio cues.
- Dependencies/assumptions: Reliable device pose; small steps; static scenes; clear object detection.
- Plug-and-play “Token Warp” inference module for MLLMs — Software/ML tooling
- What: A lightweight library that performs backward token warping given RGB, depth, intrinsics, and relative pose, exposing a drop-in API for ViT-based MLLMs to improve viewpoint-conditioned reasoning with minimal overhead.
- Tools/workflows: PyTorch/TensorRT ops for re-patchify/nearest fetching; wrappers for Qwen2.5-VL/LLaVA; ROS2 and ONNX runtimes.
- Dependencies/assumptions: ViT-style patch tokenization; access to vision encoder; depth and pose estimates.
- ViewBench as a standard evaluation suite — Academia/Industry evaluation
- What: Adopt ViewBench in CI to regression-test viewpoint robustness for MLLM releases, model selection, and ablation of depth/pose sources.
- Tools/workflows: Bench harness using Qwen2.5-VL as both solver and judge (for Object task) or external graders; stratify by overlap bins.
- Dependencies/assumptions: License/availability of ScanNet-derived pairs; reproducible depth/pose inputs; consistent prompting.
Long-Term Applications
These opportunities require further research, scaling, or engineering (e.g., broader baselines, occlusion handling, tighter SLAM integration, specialized hardware).
- Embodied agents that plan micro-motions via “mental viewpoint shifts” — Robotics
- What: Couple token warping with action selection so agents evaluate multiple hypothetical near viewpoints before moving, optimizing for information gain or manipulability.
- Tools/workflows: Model-predictive control over discrete “mental” viewpoints; uncertainty-aware scoring; integration with SLAM and task planners.
- Dependencies/assumptions: Fast depth/pose; low-latency token warp; uncertainty estimation; extended to mild nonrigid scenes.
- Training-time augmentation for viewpoint robustness — ML research
- What: Use token warping as a data augmentation layer during MLLM fine-tuning to internalize perspective-taking, reducing reliance on explicit depth at inference.
- Tools/workflows: Curriculum with synthetic relative poses; multi-task losses over spatial VQA and alignment; joint depth–token consistency regularizers.
- Dependencies/assumptions: Large-scale training; stable optimization with warped tokens; generalization beyond ViT backbones.
- Hybrid 3D-token pipelines (SLAM + token warping) — Software/Perception
- What: Fuse online mapping (e.g., depth fusion/SLAM or Gaussian splats) with token warping to improve occlusion reasoning and handle moderate baselines while still avoiding full image synthesis.
- Tools/workflows: 3D proxy mesh maintenance; ray casting for backward mapping; token-level visibility tests; memory-efficient token caches.
- Dependencies/assumptions: Persistent 3D scene representation; moving-object handling; bandwidth/compute budgets on edge devices.
- Viewpoint-aware teleoperation and surgical assistance — Healthcare/Teleoperation
- What: Provide surgeons/operators with reliable, near-viewpoint spatial Q&A in constrained spaces (e.g., endoscopy) to plan tiny instrument adjustments without relying on hallucinated frames.
- Tools/workflows: Medical-grade calibrated scopes; depth from shape-from-motion or learning; regulatory-grade validation on clinical benchmarks.
- Dependencies/assumptions: High-accuracy depth in low-texture/reflective scenes; strict safety evaluation; certification pathways.
- ADAS and autonomous driving micro-forecasting — Automotive
- What: Use token warping for short-horizon, ego-motion–conditioned spatial judgments (e.g., “after a slight lane shift, is the cone inside our path boundary?”), complementing sensor fusion.
- Tools/workflows: Ego-motion from CAN/IMU; multi-camera calibration; integration with occupancy grids; safety monitors.
- Dependencies/assumptions: Robust depth under motion blur/weather; dynamic-object modeling beyond rigid assumptions; real-time guarantees.
- Privacy-preserving analytics via token-only transformations — Policy/Privacy tech
- What: Standardize token-level viewpoint transformations on-device so cloud services receive only warped tokens, reducing raw image exposure while enabling spatial Q&A.
- Tools/workflows: Edge NPUs for tokenization/warping; secure enclaves; policy audit trails documenting “no new pixel synthesis.”
- Dependencies/assumptions: Acceptability of token representations under privacy law; provable leakage bounds; edge compute availability.
- Hardware/SDK acceleration for token warping — Semiconductors/Edge AI
- What: Provide NPU kernels for re-patchify, nearest fetch, and token-grid remapping to meet real-time constraints in AR glasses, robots, and vehicles.
- Tools/workflows: Vendor SDKs (CUDA/TensorRT, CoreML, Qualcomm AI Engine); operator fusion with ViT encoders; memory tiling for patches.
- Dependencies/assumptions: Standardized tokenization interfaces; cross-model compatibility; sustained throughput targets.
- Standards and benchmarks for viewpoint robustness — Policy/Standards, Academia
- What: Extend ViewBench into a recognized standard (e.g., NIST-style) for evaluating embodied AI perspective-taking, informing procurement and certification of MLLM-enabled systems.
- Tools/workflows: Public leaderboards; protocols for depth/pose disclosure; multi-domain test suites (indoor, outdoor, dynamic).
- Dependencies/assumptions: Community adoption; governance for dataset bias; periodic updates to reflect new sensors/backbones.
- STEM and cognitive education tools on mental imagery — Education
- What: Interactive curricula where students visualize “token-level” mental rotation and perspective-taking, comparing pixel vs token transformations to learn 3D reasoning.
- Tools/workflows: Web demos with controllable viewpoint shifts; classroom labs using open-source MLLMs and ViewBench subsets.
- Dependencies/assumptions: Simplified datasets for pedagogy; accessible licenses and compute.
Notes on feasibility across applications:
- Core assumptions from the paper: effectiveness is strongest for nearby viewpoint changes with overlapping fields of view; requires camera intrinsics and a relative pose, plus a depth map (predicted or GT). ViT-based vision encoders are assumed; scenes should be mostly rigid; the method does not hallucinate disoccluded content. Performance hinges on depth quality and pose accuracy; backward token warping preserves dense regular grids and is recommended over forward warping.
Glossary
- 3D-aware features: Feature representations that encode 3D structure to improve spatial understanding in vision-LLMs. "Multiple works integrate 3D-aware features or positional embeddings into 2D MLLMs to enhance their 3D understanding~\cite{fu2025_scenellm, cheng2025sr3d, zhu2024llava3d, thai2025splattalk, zheng2025video3dllm}."
- 3D proxy mesh: A lightweight mesh built from a depth map to approximate scene geometry for geometric operations like warping. "we build a lightweight 3D proxy mesh from the source image's depth map and compute the mapping from each target grid to the source via ray casting."
- Adaptive fetching: A token retrieval strategy that re-patchifies the source image at mapped coordinates so tokens are centered precisely at target locations. "The second, adaptive fetching, directly re-patchifies the input image at each mapped location by treating it as the patch center, rather than assigning the nearest precomputed token."
- Backward token warping: Warping at the token level using backward mapping from a regular grid in the target view to fetch corresponding source tokens. "we find that backward token warping can reliably transfer source image content to novel viewpoints without synthesizing new pixels."
- Backward warping: Mapping target-view coordinates back to the source image to fetch corresponding content, preserving a dense grid in the target view. "Backward warping takes the opposite strategy: we first define a dense, regular grid in the target view and retrieve the corresponding tokens from via the mapping ."
- Camera-conditioned diffusion model: A generative diffusion model conditioned on camera parameters to synthesize images from specified viewpoints. "a generative warping technique that employs a camera-conditioned diffusion model to directly synthesize the target-view image."
- Camera pose matrix: A 4×4 matrix encoding the camera’s extrinsic parameters (position and orientation) relative to world coordinates. "with camera pose matrix , representing the world-to-camera transformation."
- Depth map: A per-pixel estimate of distance from the camera to scene points used for geometric reasoning and warping. "We further assume that a depth map corresponding to is available"
- Forward warping: Projecting content from the source view into the target view directly, which can lead to irregular token placements. "Forward warping projects tokens from into the target viewpoint via and computes their positional embeddings accordingly."
- Forward-warping function: The function that maps source coordinates to target coordinates under known intrinsics, depth, and relative pose. "where denotes the forward-warping function that projects token positions from the source to the target viewpoint."
- Generative warping: Producing a target-view image by generative modeling (rather than direct geometric warping), potentially introducing hallucinations. "a generative warping technique that employs a camera-conditioned diffusion model to directly synthesize the target-view image."
- Grid-center coordinates: The 2D coordinates of patch centers on the image grid used to index or warp tokens. "Let denote the grid-center coordinates of ."
- Intrinsic matrix: A camera calibration matrix encoding focal length and principal point, used for projecting between 3D and image coordinates. "along with the intrinsic matrix ."
- Inverse warping: A warping strategy that samples source content by mapping target coordinates back to the source (often called backward warping). "Comparison of inverse warping strategies (Sec.~\ref{sec:token_warping})."
- Monocular depth estimation: Predicting depth from a single RGB image without multi-view information. "either as ground truth or estimated via monocular depth estimation~\cite{yang2024depth}"
- Multimodal LLM (MLLM): A LLM that processes and reasons over both text and visual inputs. "help multimodal LLMs (MLLMs) understand how a scene appears from a nearby viewpoint?"
- Nearest fetching: A token retrieval strategy that assigns to each mapped location the nearest precomputed source token. "The first, nearest fetching, constructs all image tokens only once on the input view and then assigns to each mapped target location the nearest precomputed token."
- Novel view synthesis: Generating images from new camera viewpoints, typically using 3D cues or generative models. "a camera-conditioned diffusion model that uses implicit warping for novel view synthesis"
- Oracle (evaluation): An upper-bound reference using ground-truth target-view images to contextualize achievable performance. "an oracle performance metric obtained by using the ground-truth target-view image"
- Patchifying: Converting an image into fixed-size patches for transformer-based processing; re-patchifying repeats this at new centers. "but patchifying the warped image introduces local distortions, resulting in degraded MLLM understanding."
- Pixel-wise warping: Warping individual pixels to a target view using depth and camera parameters, often sensitive to depth errors. "Pixel-wise warping retrieves pixels for each target coordinate, but patchifying the warped image introduces local distortions, resulting in degraded MLLM understanding."
- Positional embeddings: Vector encodings of spatial position added to token embeddings so transformers can reason about layout. "processed jointly with positional embeddings."
- Ray casting: Tracing rays from target-view pixels through a 3D proxy to find corresponding points in the source image. "and compute the mapping from each target grid to the source via ray casting."
- Relative pose: The transformation from source to target camera frames combining rotations and translations. "the relative pose ."
- Retrieval-position noise: Perturbations in the coordinates used to fetch patches/tokens, used to test robustness. "we evaluate MLLM's sensitivity to retrieval-position noise by perturbing the regular grid center points used to fetch local patches."
- Token warping: Performing viewpoint transformations by moving or fetching image tokens instead of pixels to improve robustness. "We explore token warping as a means of enabling viewpoint changes for MLLMs"
- Vision encoder: The component that converts patch embeddings and positions into image tokens for downstream multimodal processing. "are processed by a vision encoder (\eg, ViT~\cite{vaswani2017attention, dosovitskiy2021vit})"
- Vision Transformer (ViT): A transformer architecture for images that operates on patch tokens instead of convolutional features. "Vision Transformers (ViT)~\cite{vaswani2017attention, dosovitskiy2021vit}"
- View-conditioned spatial reasoning: Reasoning about spatial relationships from a specified (possibly transformed) viewpoint. "We design two tasks, both tailored to evaluate an MLLM's ability to simulate viewpoint changes for spatial reasoning: (1) view-conditioned spatial reasoning and (2) target-view object description."
- ViewBench: A benchmark of paired viewpoints and questions to evaluate viewpoint-aware reasoning in MLLMs. "In this section, we introduce~ViewBench, a benchmark designed to assess MLLMs' ability to perform spatial reasoning tasks that require imagining a scene from alternative viewpoints while accurately transferring fine-grained details from the observed viewpoint."
- Visual Question Answering (VQA): Answering natural-language questions about visual content, used here to quantify spatial reasoning. "CV-Bench-2D~\cite{tong2024cambrian} VQA tasks"
- World-to-camera transformation: The extrinsic transform that maps world coordinates into the camera frame. "representing the world-to-camera transformation."
Collections
Sign up for free to add this paper to one or more collections.

