- The paper introduces GETok, a token-based spatial representation that converts 2D image coordinates into learnable tokens for precise localization.
- It employs a propose-and-refine mechanism using grid and offset tokens, achieving superior spatial reasoning and efficient reinforcement learning optimization.
- The approach unifies various vision-language tasks and demonstrates significant performance improvements in applications like obstacle detection and lane recognition.
Grounding Everything in Tokens for Multimodal LLMs
Introduction and Motivation
The paper "Grounding Everything in Tokens for Multimodal LLMs" (2512.10554) addresses a central challenge in extending MLLMs beyond semantic understanding to precise 2D spatial reasoning and localization. Despite significant progress, most MLLMs sacrifice spatial precision due to architectural constraints imposed by autoregressive tokenization and limited representational choices for spatial data. Standard approaches rely on textual coordinates, fixed-size patch embeddings, or 1D bin-based discretization, all of which yield suboptimal spatial topology preservation and increased tokenization brittleness.
The paper introduces GETok, a spatial representation method that equips MLLMs with a specialized vocabulary of discrete, learnable tokens directly representing 2D image coordinates, thereby reifying spatial location as part of the model's autoregressive language interface. This is achieved by discretizing the image domain into a structured grid (grid tokens) and enabling fine-grained iterative adjustment using additional offset tokens. The work proposes a unified referential interface and demonstrates strong performance in spatial reasoning benchmarks, while highlighting the emergent advantages of this token-centric formalism for both supervised and reinforcement learning paradigms.
Tokenized Spatial Representation: GETok
Lexical Framework
GETok introduces an explicit spatial lexicon by augmenting the MLLM vocabulary with two new, learnable token classes:
- Grid Tokens: An n×n uniform lattice covering the image domain, where each cell center is mapped to a discrete token. This guarantees native spatial topology and a direct mapping from tokens to 2D spatial anchors, in contrast to 1D bins or digit sequences which induce geometric discontinuities.
- Offset Tokens: Local displacement vectors that allow adjustment of grid token locations with minimal vocabulary inflation. A small, fixed set of offset tokens delivers effective sub-grid refinement, supporting iterative "propose-and-refine" localization.
This design leverages the compositionality of language modeling, treating spatial positions as atomic vocabulary elements rather than multi-token compositions, thus simplifying parsing and reducing format brittleness.
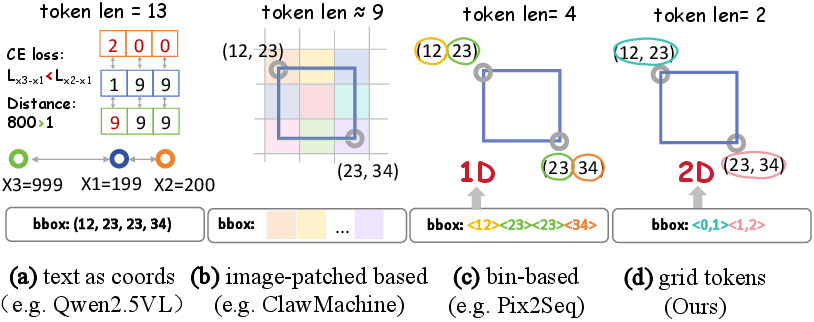
Figure 1: A comparative analysis of grounding representations, where 2D grid tokens exhibit far superior topology preservation and sequence brevity compared to coordinate-, patch-, or 1D bin-based approaches.
The token-centric framework supports seamless multi-format reference conversion (e.g., points, boxes, masks, polylines) without architectural changes.

Figure 2: GETok affords input/output reference compatibility across diverse formats and scales, enabling unified grounding within a single architecture.
Propose-and-Refine Mechanism
GETok combines coarse proposal (via grid tokens) and iterative refinement (via offset tokens). Spatial localization is decomposed into a two-step process:
- Grid Token Proposal: Initial anchor points, possibly comprising a subset of the grid, refer to coarse object extents.
- Offset Token Refinement: Local refinements are applied, leveraging offset tokens to move or suppress (e.g., via a delete token) misaligned proposals.
This enables progressive error correction and high-resolution localization from a compact token set.

Figure 3: Illustration of propose-and-refine—grid tokens initiate spatial anchors, while offset tokens support fine manipulation toward precise localization.
Supervised and RL Training Paradigms
Discretization and Data Construction
The paper introduces an efficient, training-free greedy algorithm to convert dense spatial labels, such as segmentation masks, into sparse, information-preserving sets of grid tokens. This process maximizes mask coverage with minimal redundant points, supporting scalable data augmentation.

Figure 4: Automated mask-to-token conversion pipeline using a greedy approach for efficient data expansion.
Self-Improving Reinforcement Learning (RL)
Exploiting GETok's 2D-structured action space, the authors devise a self-improving RL framework. This formalizes spatial grounding as a two-stage generative process—first sampling grid-token proposals, then iteratively refining spatial hypotheses using offset tokens. The reward functions encode geometric consistency, mask/box IoU, and alignment with critical semantic points, complementing chain-of-thought and multi-turn refinements characteristic of recent R1/VLM-RL approaches.
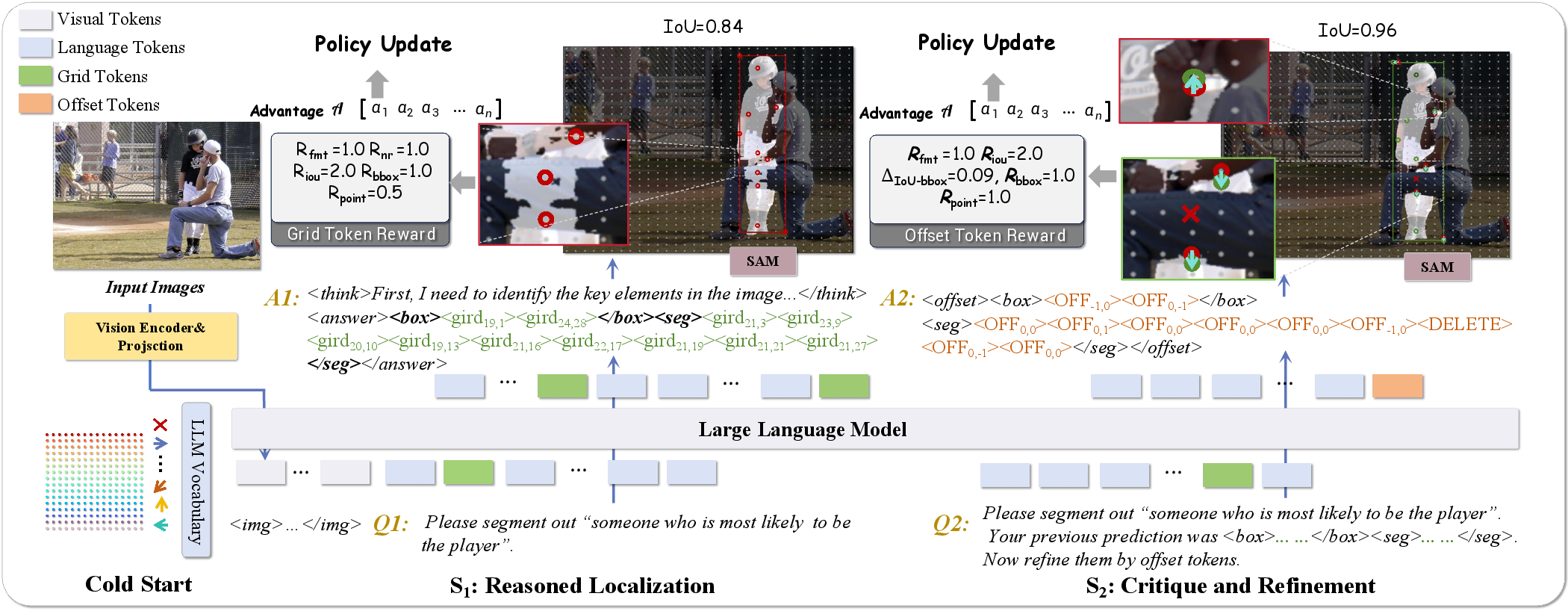
Figure 5: Schematic of the self-improving RL pipeline: grid tokens propose spatial anchors; offset tokens enact iterative local correction.
Comparative Analysis of Localization Vocabularies
The work contrasts GETok's grid tokens with text coordinate and 1D bin-like representations. Quantitative experiments and attention map visualizations demonstrate that grid tokens produce attention activations tightly bound to object extents with spatial continuity—unlike fragmented and discontinuous activations seen for 1D schemes.

Figure 6: Heatmap comparison showing that grid-token attention is topology-aware and consistently covers object regions.
Moreover, GETok achieves faster convergence and higher sample efficiency in RL, attributed to its low-entropy, geometry-aligned action space.
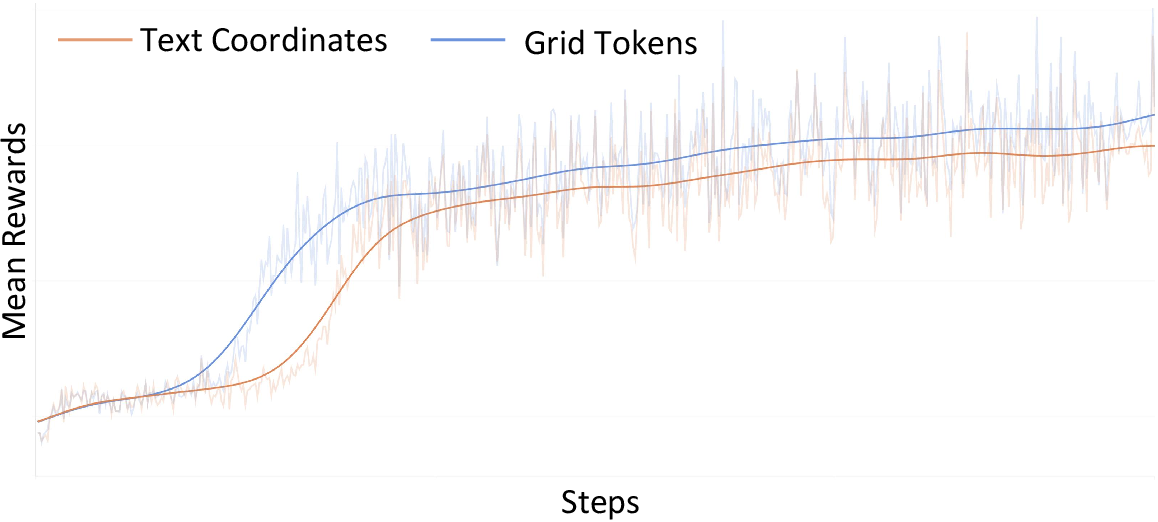
Figure 7: Reward curve comparison confirms superior convergence and steady learning for grid tokens versus text coordinates.
Unified Cross-Task Grounding and Real-World Case Studies
GETok generalizes naturally across a spectrum of vision-language tasks, including referring segmentation, comprehension, captioning, and unifies referential grounding irrespective of granularity or instance multiplicity. The unified representation supports both single-instance and multi-instance queries with no need for task-specific heads.

Figure 8: GETok's unified representations facilitate seamless handling of diverse visual-linguistic concepts within a single framework.
Empirical evaluation in safety-critical real-world driving tasks demonstrates significant improvements over coordinate-based baselines for tasks such as static obstacle classification and lane polyline detection, confirming GETok's practical utility in high-precision spatial reasoning domains.

Figure 9: Qualitative driving scene results highlight GETok's robust region-referencing under varied and complex traffic scenarios.
Implications and Future Directions
The introduction of a token-based, discrete spatial lexicon provides a foundational change in how MLLMs can reason about and generate referential spatial language. Key implications include:
- Architectural Generality: By encoding spatial references as tokens, GETok avoids bespoke architectural modifications (e.g., object-detection heads or region decoders) while maintaining compatibility with autoregressive transformers and instruction-following interfaces.
- Cross-task Unification: The approach unifies disparate referring tasks and output granularities, streamlining multi-task and multi-instance MLLM pipelines.
- RL Policy Optimization: The structured action space induced by 2D tokens significantly smoothens reward landscapes, enhancing RL-based preference optimization and bootstrapping.
- Data/Annotation Scalability: Automated mask-to-token conversion bridges label formats and eases the use of new datasets, facilitating broader real-world deployment.
Future work may address vocabulary scaling, leveraging hierarchical tokenization or adaptive spatial granularity, and extending this paradigm to video, structured documents, or 3D spatial reasoning. Interfacing GETok with end-to-end differentiable segmentation decoders, as well as integrating it with in-context learning and memory-augmented MLLMs for persistent spatial navigation, are promising avenues.
Conclusion
GETok operationalizes a token-based paradigm for precise 2D grounding in Multimodal LLMs, subsuming spatial referencing through a unified, language-compatible vocabulary. This delivers robust and precise spatial reasoning, efficient RL optimization, and cross-task generalization with straightforward architectural integration. The approach demonstrates competitive or superior empirical results across both academic benchmarks and complex real-world scenarios, substantiating the merit of lexicalized spatial reasoning for the next generation of MLLMs.

