- The paper introduces a Visual Chain-of-Thought mechanism that integrates explicit 3D reconstruction and iterative perspective synthesis for improved spatial reasoning.
- It employs object-centric keyword extraction, prompt-driven segmentation, and 3D mesh generation to resolve occlusion and viewpoint ambiguities.
- Experimental evaluations demonstrate significant accuracy gains across benchmarks, outperforming both generalist and specialized spatial MLLMs.
Enhancing MLLM Spatial Reasoning via Active 3D Scene Exploration
Introduction and Motivation
Multimodal LLMs (MLLMs) have rapidly expanded their competence in visual and textual domains; however, they exhibit pronounced deficiencies in 3D spatial reasoning, primarily due to reliance on 2D visual priors derived from large-scale image-text datasets. These limitations are acute in downstream embodied AI applications—robotic manipulation, navigation, and spatial QA—where accurate object-level perception, spatial relation inference, and physical reasoning in 3D scenes are non-negotiable.
Prior efforts to augment MLLMs for spatial reasoning have generally taken training-intensive approaches: post-training on limited 3D datasets, tool-calling pipelines dependent on external visual or geometric libraries, or prompt engineering. Yet these paradigms are often computationally expensive, scale poorly, and struggle with viewpoint ambiguity and the lack of explicit geometric modeling. Crucially, they diverge from the natural human process of resolving spatial ambiguities by mental reconstruction and multi-perspective exploration.
The paper "Enhancing MLLM Spatial Understanding via Active 3D Scene Exploration for Multi-Perspective Reasoning" (2604.06725) proposes a novel, training-free framework that systematically emulates this human-like spatial exploration in MLLMs, introducing a Visual Chain-of-Thought (Visual CoT) mechanism grounded in explicit 3D scene reconstruction and iterative perspective synthesis.
Methodology
The core pipeline consists of two interconnected modules: 3D Reconstruction and Perspective Transformation. Rather than depending on fine-tuning or massive 3D domain data, it orchestrates existing MLLMs, a promptable segmentation backbone, a 3D mesh generator, and knowledge-guided multi-view reasoning in a zero-shot fashion.
Upon receiving an image and a spatial question, the system executes the following:
- Object-Centric Keyword Extraction: Leveraging the MLLM's generation abilities, it extracts object-related keywords at multiple granularities—original, expanded (with positions, synonyms, and appearance), and abbreviated (nouns only). This comprehensive lexical set guides the segmentation phase.
- Prompted Segmentation and Mask Deduplication: Using the extracted keywords, a concept-guided segmentation model (SAM3) generates object masks which undergo de-duplication via IoU-based filtering to ensure unique, unambiguous object representations.
- 3D Mesh Construction: The masked image is processed by a promptable 3D mesh generator (SAM3D-Object), yielding watertight object meshes. Occlusion handling and spatial fidelity are prioritized to ensure accurate subsequent reasoning.
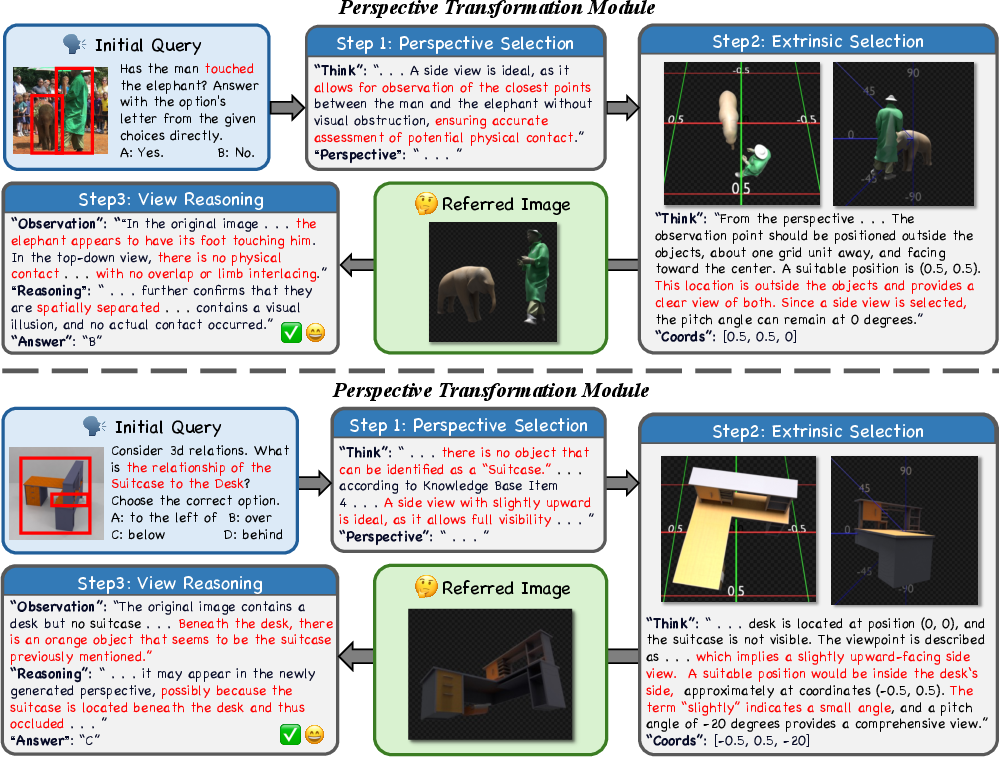
- Perspective Knowledge Integration and View Selection: The system accesses an external, human-curated knowledge base that encodes viewpoint selection heuristics for various spatial task types, supporting generalization and reasoning in novel instances.
- Camera Pose Computation and Novel View Synthesis: Guided by the MLLM and knowledge base, the framework computes optimal camera extrinsics (centered at the geometric centroid of all objects, with parameters derived from scene structure and task requirements). The camera is placed in the 3D mesh to synthesize informative new views through precise spatial transforms and coordinate mapping.
- Iterative View Reselection: An MLLM-driven quality check validates each candidate view for object completeness, relevance, and occlusion mitigation; if the view is unsatisfactory, pose selection and rendering iterate until a valid informative perspective is achieved.
- Multi-View Visual CoT Reasoning: The MLLM integrates multi-view visual cues produced by dynamic scene exploration into its reasoning trajectory, ultimately outputting a final answer grounded in rich, geometrically consistent spatial evidence.

Figure 1: The Visual CoT mechanism resolves perspective ambiguities by reconstructing the 3D scene and synthesizing novel, unambiguous viewpoints for robust spatial question answering.
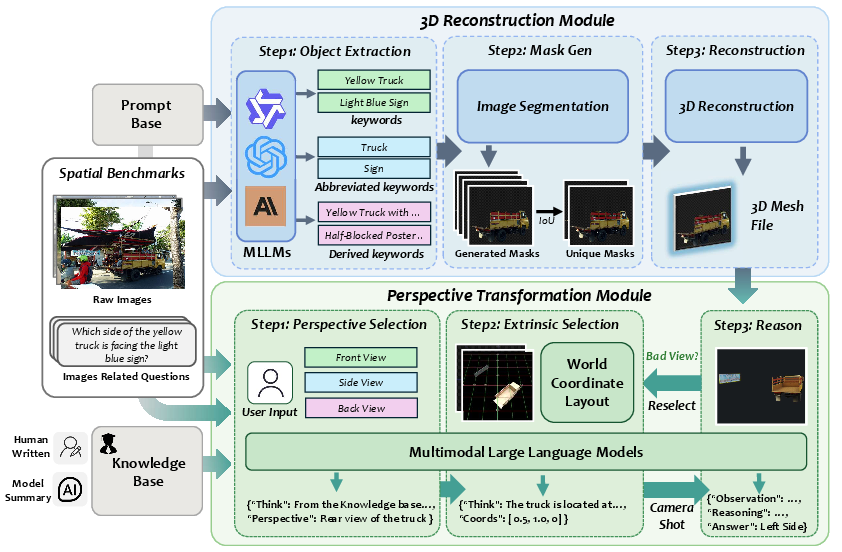
Figure 2: End-to-end model pipeline, comprising object-level keyword extraction, segmentation and deduplication, 3D mesh construction, knowledge-guided perspective selection, and iterative multi-view reasoning.
Experimental Evaluation and Ablation
The approach is extensively benchmarked against both generalist (e.g., GPT-5.2, Gemini-2.5-Flash, Qwen3-VL-8B-Instruct) and specialized spatial MLLMs (e.g., SpatialLLM-8B, VLM3R-7B, SpaceMantis-8B) on three challenging datasets: 3DSRBench, SpatialScore, and Rel3D. Sub-task distributions are visualized in Figure 3.
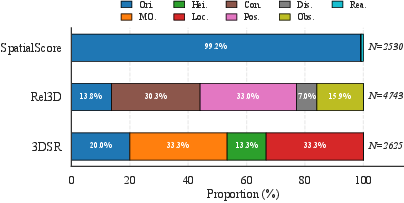
Figure 3: Sub-task distribution in 3DSR, Rel3D, and SpatialScore benchmarks, illustrating the coverage of key spatial reasoning primitives.
Numerical Highlights:
- On 3DSRBench, the proposed method achieves 70.7% accuracy, exceeding GPT-5.2 by 7.2% absolute and Gemini-2.5-Flash by 5.6%.
- On SpatialScore, it yields 77.6% accuracy, surpassing GPT-5.2 by 6.1%.
- On Rel3D, the method reaches 66.4%, outpacing GPT-5.2 by 1.0% absolute.
- Specialized models across all tasks are consistently outperformed, indicating that explicit multi-view 3D exploration provides significant advantages over domain-specific tuning or architectural modifications.
Ablation studies confirm that:
Theoretical and Practical Implications
From a theoretical standpoint, this work advances the paradigm of Visual Chain-of-Thought by tightly coupling linguistic decomposition with explicit 3D geometric scene understanding and dynamic perspective-taking. It bridges the gap between 2D-centric visual-language pretraining and the demands of physical, spatially-grounded reasoning, providing evidence that training-free, pipeline-centric augmentation can unlock generalist MLLM capabilities for embodied spatial reasoning.
Practically, the framework offers:
- Domain-agnostic, training-free deployment: No domain-specific finetuning on 3D datasets is required, facilitating immediate integration with new MLLMs and new video/image corpora.
- Interpretability and robustness: The explicit multi-stage reasoning pipeline supports stepwise introspection and error analysis, critical for high-stakes applications.
- Direct applicability to embodied AI and manipulation. The method's generalization in zero-shot scenarios, particularly for task types and occlusion conditions absent from the knowledge base, implies strong readiness for sim-to-real transfer and real-time embodied scenarios.
Future Prospects
The demonstrated success of this training-free, knowledge-augmented 3D exploration blueprint suggests several promising directions:
- Extension to dynamic/video scenes for temporal spatial reasoning and causal inference.
- Incorporation of active perceptual control in embodied agents (robotic systems, interactive agents) that can autonomously select viewpoints or physically manipulate sensors.
- Greater integration of external knowledge and self-supervised scene graph construction, fusing data-driven and symbolic reasoning for even richer spatial QA performance.
Conclusion
By introducing a Visual Chain-of-Thought mechanism grounded in explicit 3D reconstruction, this work establishes a new methodological and empirical standard for spatial reasoning in MLLMs without requiring retraining or model architectural changes. Its strong performance across major spatial benchmarks and robust handling of occlusion and viewpoint ambiguity suggest that multi-perspective active scene exploration is a critical ingredient for advancing MLLM spatial comprehension, with significant implications for both embodied AI applications and future model design.