- The paper reveals that VLMs struggle with spatial tasks because vision embeddings act as 'bag-of-tokens', which overshadows positional cues.
- It demonstrates that normalizing vision tokens and leveraging spatially rich intermediate-layer features improve spatial reasoning, boosting accuracy by over 8% on synthetic benchmarks.
- Experimental results on standard benchmarks confirm that embedding normalization consistently enhances spatial processing in multimodal models.
Beyond Semantics: Rediscovering Spatial Awareness in Vision-LLMs
Introduction
"Beyond Semantics: Rediscovering Spatial Awareness in Vision-LLMs" addresses a critical limitation in Vision-LLMs (VLMs): their struggle with spatial reasoning despite strong object recognition capabilities. By drawing inspiration from the dual-pathway model of human vision, the paper proposes innovative interpretability-driven solutions to enhance spatial awareness in VLMs.
Analysis of Spatial Reasoning Failures
VLMs are proficient in ventral tasks like object recognition but underperform in spatial (dorsal) tasks, such as distinguishing left from right. This paper identifies that vision embeddings in VLMs act predominantly as a "bag-of-tokens," neglecting spatial structure due to large embedding norms that overshadow subtle positional cues within attention mechanisms.
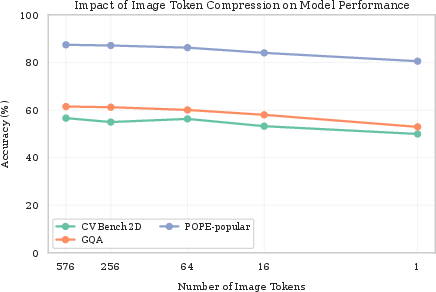
Figure 1: Performance impact of vision token compression on standard benchmarks (GQA, CV-Bench 2D, and POPE). Only minor accuracy degradation occurs, even under extreme token compression (down to a single token).
Bag-of-Tokens Hypothesis
Two core experiments verify this hypothesis:
- Token Permutation Test: Randomizing vision token order significantly less impacts performance, indicating order insensitivity.
- Spatial Compression Study: Reducing token count—with minimal performance loss—indicates reliance on semantics over spatial data (Figure 1).
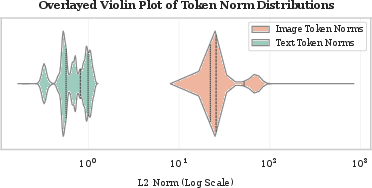
Figure 2: Distribution of L2 norms for vision and text tokens in COCO validation dataset (log scale). Vision token norms range between 101 and 103, while text token norms range between 3×10−1 and 100.
Theoretical Analysis
The embedding norm analysis reveals vision tokens have magnitudes overshadowing positional cues, as shown in Figure 2. Attention logits are disproportionately influenced by these large norms, reducing positional encoding effectiveness despite employing mechanisms like RoPE.
Restoring Spatial Awareness
Building on interpretability insights, the study develops a targeted synthetic benchmark and proposes two model interventions:
- Vision Token Normalization aligns vision embeddings with text embedding magnitudes, enhancing positional cue visibility.
- Intermediate-Layer Features tap into spatially rich early-layer data, preserving geometric information crucial for spatial tasks (Figure 3).
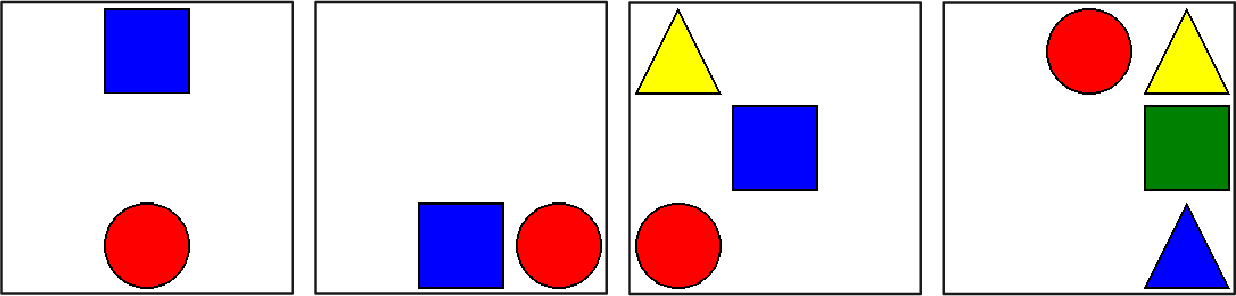
Figure 3: Illustrative scenes from our 2DS Dataset. The left two images show two object arrangements, while the right two images illustrate more complex three and four object arrangements.
Experimental Results
The interpretability-driven interventions yield marked improvements in spatial reasoning across synthetic and standard benchmarks:
- Synthetic Dataset (2DS): Vision normalization and intermediate features reignite spatial reasoning, with accuracy improvements surpassing 8% over baseline models.
- Standard Benchmarks: Moderate yet consistent gains validate the solution's generalizability, especially in spatially tasked CV-Bench 2D and GQA datasets.
Analysis and Future Directions
Attention visualization (Figure 4), showing increased focused attention on spatial tokens, underscores the effectiveness of embedding normalization. Interventions drive a nuanced interpretability trade-off: they require balancing embedding norm adjustments with the leverage of intermediate features to distribute spatial reasoning load across layers.

Figure 4: Visualization of self-attention patterns. We overlay the attention map on top of the image. The question for the model is under each row. We use the first target word of the response for attention map, for example, the attention map is based on 'square' and 'circle' for top left rows. Entropy values are on top of each image.
Future work should refine normalization strategies, explore 3D spatial reasoning, and upgrade architectures to maintain balanced semantic and spatial processing.
Conclusion
The paper illuminates VLMs' interpretability gaps and proposes actionable solutions restoring spatial cognition akin to the "dorsal stream" pathway. By prioritizing embedding norm adjustments and enriched layer features, this work sets a new standard for enhancing spatial reasoning within multimodal AI models.