- The paper demonstrates that integrating adaptive visual imagination with text-based planning prevents geometric drift and errors in multi-step spatial reasoning.
- It introduces a closed-loop data engine that leverages difficulty-aware routing and stringent verification to create a robust multimodal spatial reasoning dataset.
- Empirical results on benchmarks like SPAR-Bench and VSI-Bench show significant performance gains, highlighting the benefit of combining textual and visual modalities.
SpatialImaginer: Adaptive Visual Imagination for Robust Spatial Reasoning
Spatial reasoning—reasoning about geometric and physical structures from visual input—remains a persistent and critical challenge for multimodal LLMs (MLLMs), especially as embodied and physical understanding becomes central for next-generation AI agents. Despite recent gains on vision-language (V+L) benchmarks, MLLMs exhibit a fundamental brittleness on multi-step spatial tasks: text-only chain-of-thought (CoT) reasoning fails to preserve consistent spatial states, leading to geometric drift, misinferred topology, and accumulated spatial errors over multiple steps. The paper "SpatialImaginer: Towards Adaptive Visual Imagination for Spatial Reasoning" (2604.17385) provides an empirical and conceptual analysis of this limitation, arguing that the abstraction inherent to linguistic tokens is ill-suited for continuous, fine-grained 3D geometric cognition. Instead, the authors posit that explicit externalization of spatial state into the visual modality enables stable intermediate representations and robust multi-step deduction.

Figure 1: Visual externalization of intermediate reasoning states prevents geometric inconsistency, as opposed to text-only methods that fail to preserve spatial structure in multiview scenarios.
Data Engine for Selective, Verified Visual Interleaving
A core contribution is a closed-loop data engine that constructs an adaptive multi-modal spatial reasoning dataset. The pipeline routes queries via difficulty-aware mechanisms, leveraging ensemble disagreement from several state-of-the-art VLMs (Qwen3-VL, InternVL3, GLM-4.1V) as a proxy for spatial complexity. Only queries consistently unsolved in text are routed for explicit intermediate visual rendering. Synthesized visuals undergo strict two-stage verification: factuality checks filter structural errors, while a blind QA phase using an independent MLLM tests whether the visual anchor indeed enables correct deduction. This yields high-quality, leakage-resistant interleaved reasoning data, balanced with backfilled high-quality pure-text reasoning samples to avoid mode collapse.
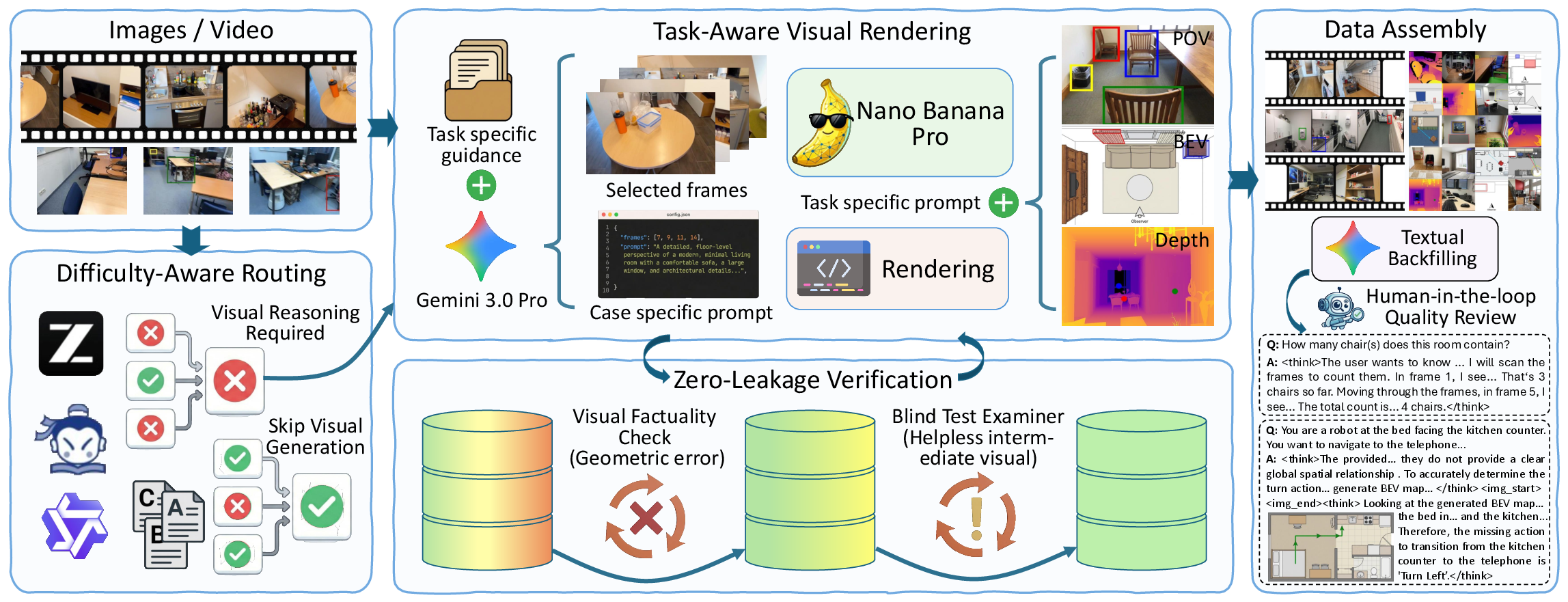
Figure 2: The data engine isolates spatial bottlenecks via difficulty-aware routing for targeted visual rendering, followed by rigorous verification and manual refinement for dataset quality.
The resulting dataset covers a wide gamut of spatial tasks, with sharply balanced distribution between interleaved visual reasoning and pure textual deduction, ensuring that the model learns to invoke visual imagination judiciously.
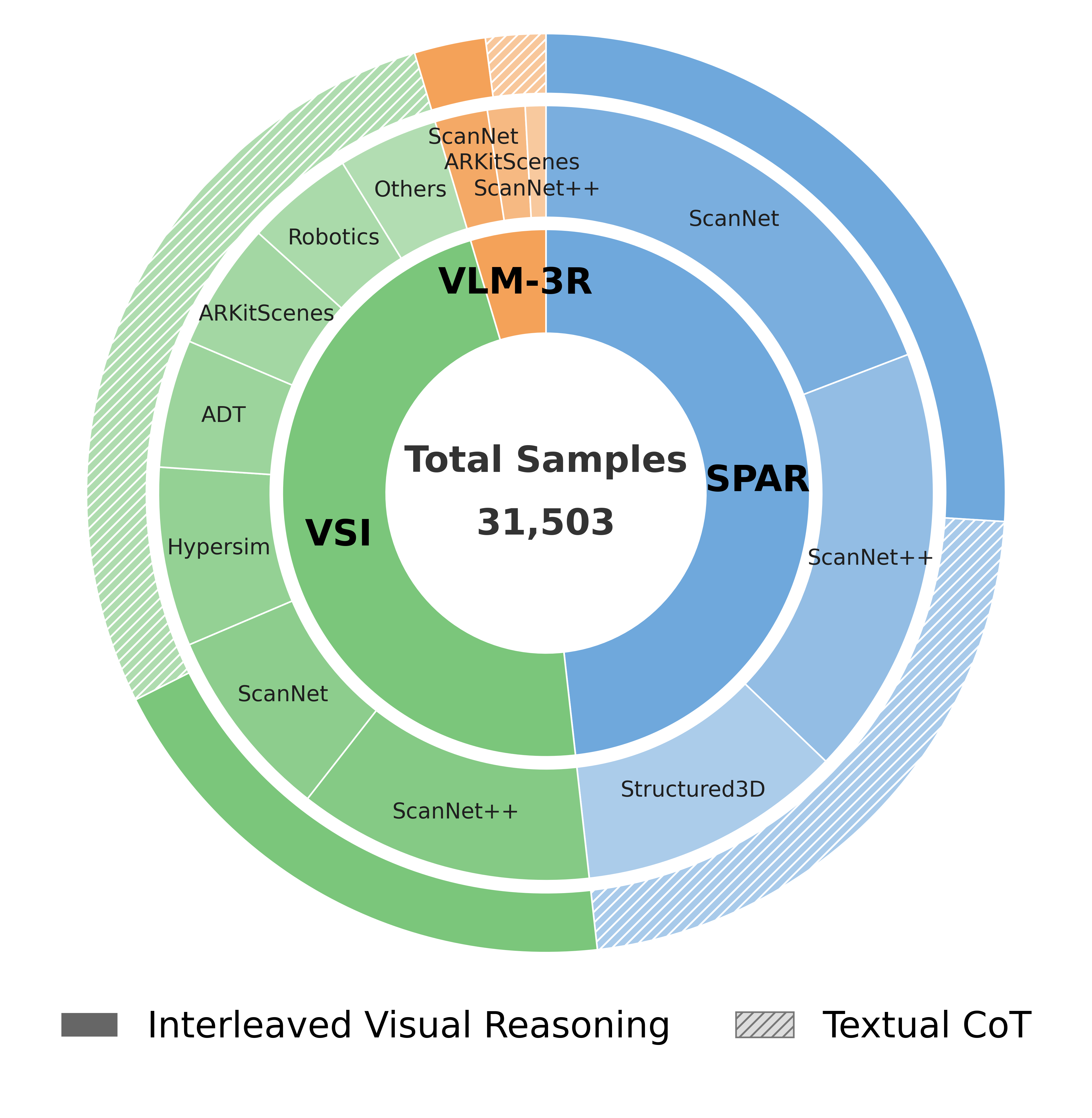
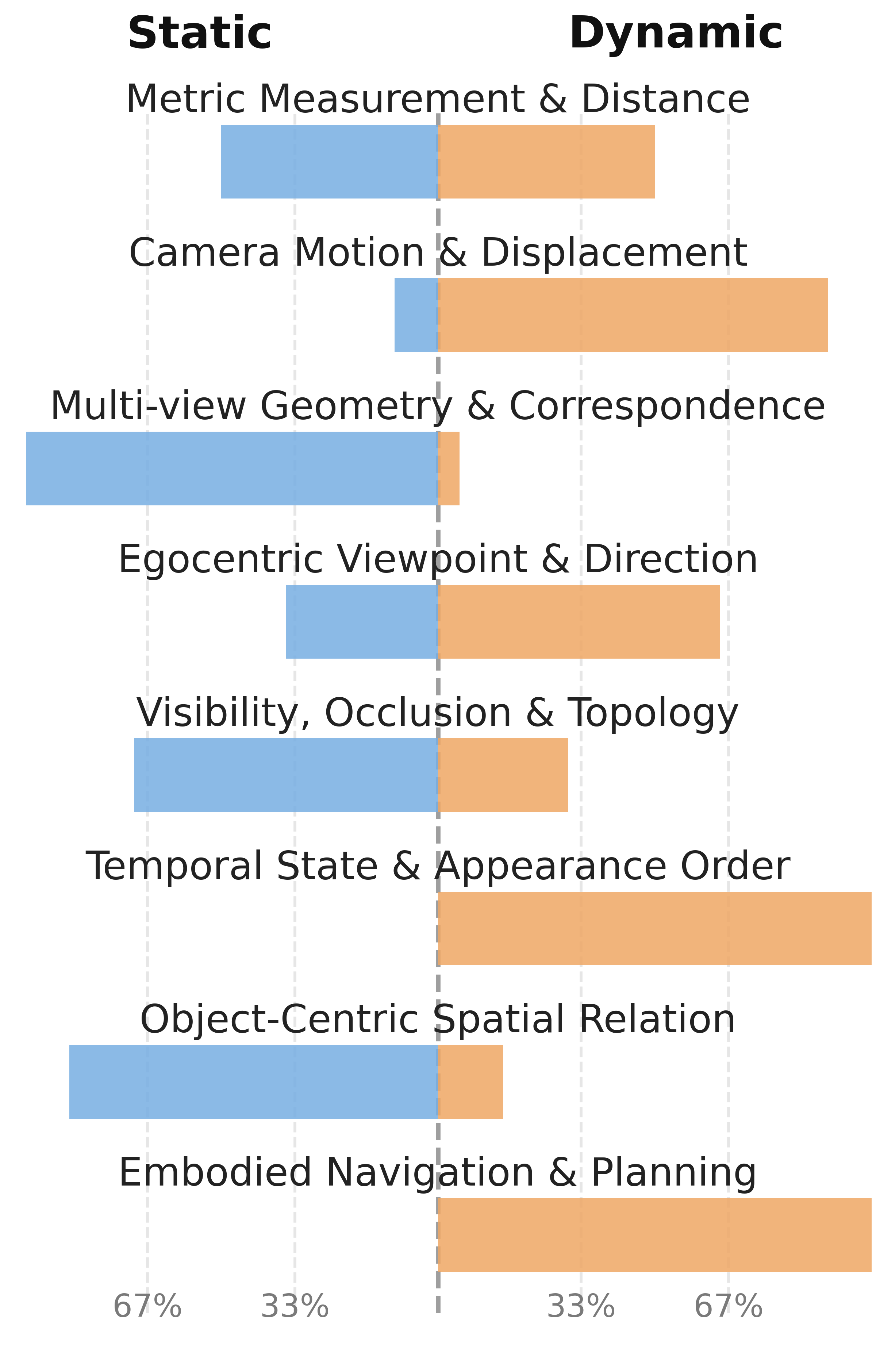
Figure 3: Dataset breakdown by source, spatial pattern, and reasoning task, ensuring comprehensive static and dynamic spatial coverage.
Adaptive Interleaved Reasoning Architecture
SpatialImaginer leverages a unified generative multimodal architecture built on BAGEL-7B-MoT, interleaving planning, visual, and deduction modules within a single autoregressive token sequence. Semantic planning is handled textually; when required, an intermediate visual state is generated (bird’s-eye, depth, or POV representations), followed by deductive closure, possibly conditioned on the generated visual state.
The model’s input/output structure is:
- Cplan: Textual planning
- Cvis: Visual execution (optionally empty)
- Cdeduct: Deductive resolution, including final answer
Generation is decomposed as:
P(A,C∣X,Q)=P(Cplan∣X,Q)⋅P(Cvis∣Cplan,X,Q)⋅k=1∏LP(ak∣a<k,Cvis,Cplan,X,Q)
Purely textual deduction is favored for semantic or simple spatial cases; visual generation is invoked for geometry-intensive queries when textual abstraction is insufficient.

Figure 4: The unified reasoning pipeline adaptively interleaves spatial planning, visual imagination, and deduction, enabling robust mode switching between semantic and geometric state tracking.
Joint Optimization and Token Representation
Optimization is staged:
- Geometric-Aware Warmup: Before visual generation, the LLM backbone and vision encoder are aligned to 3D metric priors, training only on ViT features and targeting properties like depth and orientation. This stage equips downstream learning with geometric anchors.
- Joint Interleaved Training: Both ViT and VAE token streams are activated. Standard cross-entropy and rectified flow loss are used for textual and visual segments, respectively. A high-noise time shift in the flow model emphasizes geometric alignment over texture synthesis during visual state generation.
Token ablation reveals that explicit visual latent tokens (VAE) provide significant additional gains over ViT-only features, especially for tasks demanding faithful geometric reasoning.
Empirical Results and Analysis
SpatialImaginer is evaluated across six comprehensive spatial intelligence benchmarks, including VSI-Bench, SPAR-Bench, ViewSpatial, and 3DSRBench.
Key performance outcomes:
- SPAR-Bench: Achieves 62.3 average (absolute SOTA for open-source and proprietary models; prior open source best: 46.6).
- VSI-Bench: 63.7 average, eclipsing specialized models and even GPT-5 and Cambrian-S-7B.
- Uniform gains: Outperforms all baselines on five of six spatial benchmarks, maintaining robust performance profiles across static, dynamic, and embodied reasoning domains.
- High-level spatial tasks (object relation, imagination, position matching): Shows gains exceeding 18–30 points versus strong textual CoT or 3D-prior models, evidencing the necessity of explicit visual externalization for multi-step spatial consistency.
Textual CoT is shown to systematically impair performance on high-complexity spatial tasks, while the interleaved visual approach provides a strong additive effect, most pronounced for geometric and topological consistency requirements.
Implications and Future Outlook
SpatialImaginer demonstrates that text-only reasoning in MLLMs is structurally inadequate for geometric cognition, as linguistic abstraction inherently induces spatial information loss during state propagation. The divide-and-conquer, interleaved paradigm—assigning semantic planning/textual deduction to the LLM but offloading geometric state transformations to an explicit visual imagination—fundamentally shifts the design of spatial intelligence architectures. The empirical superiority and robustness across spatial benchmarks indicate that this approach offers a scalable pathway to practical, reliable embodied AI.
This work also offers a scalable, adaptive data curation methodology that leverages model uncertainty and task difficulty to avoid wasteful or unnecessary visual computation, a property critical for efficient deployment. On the theoretical front, it points toward frameworks that tightly integrate symbolic (textual) and sub-symbolic (visual, geometric) processing, raising prospects for future fusion architectures that more closely parallel human dual-coding and mental simulation mechanisms.
Further developments may include extension to real-world 3D scenes with sensor noise, more generalizable visual generation modules, and integration with active perception systems.
Conclusion
"SpatialImaginer: Towards Adaptive Visual Imagination for Spatial Reasoning" (2604.17385) establishes that explicit, adaptive visual imagination is essential for robust, multi-step spatial reasoning in multimodal LLMs. By bridging the representation gap between continuous 3D geometry and discrete linguistic tokens, and by equipping models with the ability to invoke visual anchoring only when necessary, the proposed framework achieves state-of-the-art spatial intelligence while avoiding spurious inductive biases. This work marks a critical advance in the development of MLLMs capable of reliable geometric reasoning—a prerequisite for next-generation embodied and interactive AI agents.