- The paper introduces Perceptio, which augments LVLMs with segmentation and depth tokens to model explicit spatial geometry.
- It employs a dual-token streaming architecture using SAM2 for segmentation and a VQ-VAE framework for depth tokenization to enhance spatial reasoning.
- Empirical evaluations on benchmarks like RefCOCO and HardBLINK demonstrate notable improvements in spatial reasoning and VQA performance over baseline models.
Perceptio: Spatial Token Generation for Enhanced Spatial Reasoning in Vision-LLMs
Motivation and Problem Statement
Despite advances in Large Vision-LLMs (LVLMs), spatial grounding—comprehending depth, distance, and positional relationships—remains a clear deficiency. Existing LVLMs, even those with web-scale pre-training, often lack explicit modeling of complex spatial geometry, leading to poor performance in tasks requiring detailed spatial or geometric reasoning. Perceptio addresses this gap by augmenting LVLMs with explicit, in-sequence spatial tokens representing both 2D semantic segmentation and discretized 3D depth, thus enabling comprehensive spatial intelligence within a single autoregressive sequence.
Model Architecture and Spatial Tokenization
Perceptio builds atop the InternVL-2.5 backbone, integrating both semantic and geometric cues via two distinct spatial token streams: segmentation tokens and depth tokens. The approach utilizes frozen teacher models for supervision—Segment Anything Model 2 (SAM2) for semantic segmentation and Depth Anything V2 for dense monocular depth prediction. Depth is tokenized through a Vector Quantized-Variational Autoencoder (VQ-VAE) trained on distributionally matched depth data, yielding a robust codebook for compact, quantized 3D representations.
Perceptio’s generation sequence enforces the ordering:
[seg tokens],[depth tokens],[text tokens]
where segmentation tokens condition a SAM2 decoder, depth tokens index the VQ-VAE codebook for reconstructing the depth map, and subsequent text tokens yield the final answer. This spatial chain-of-thought ensures the model grounds language generation in explicit spatial priors.
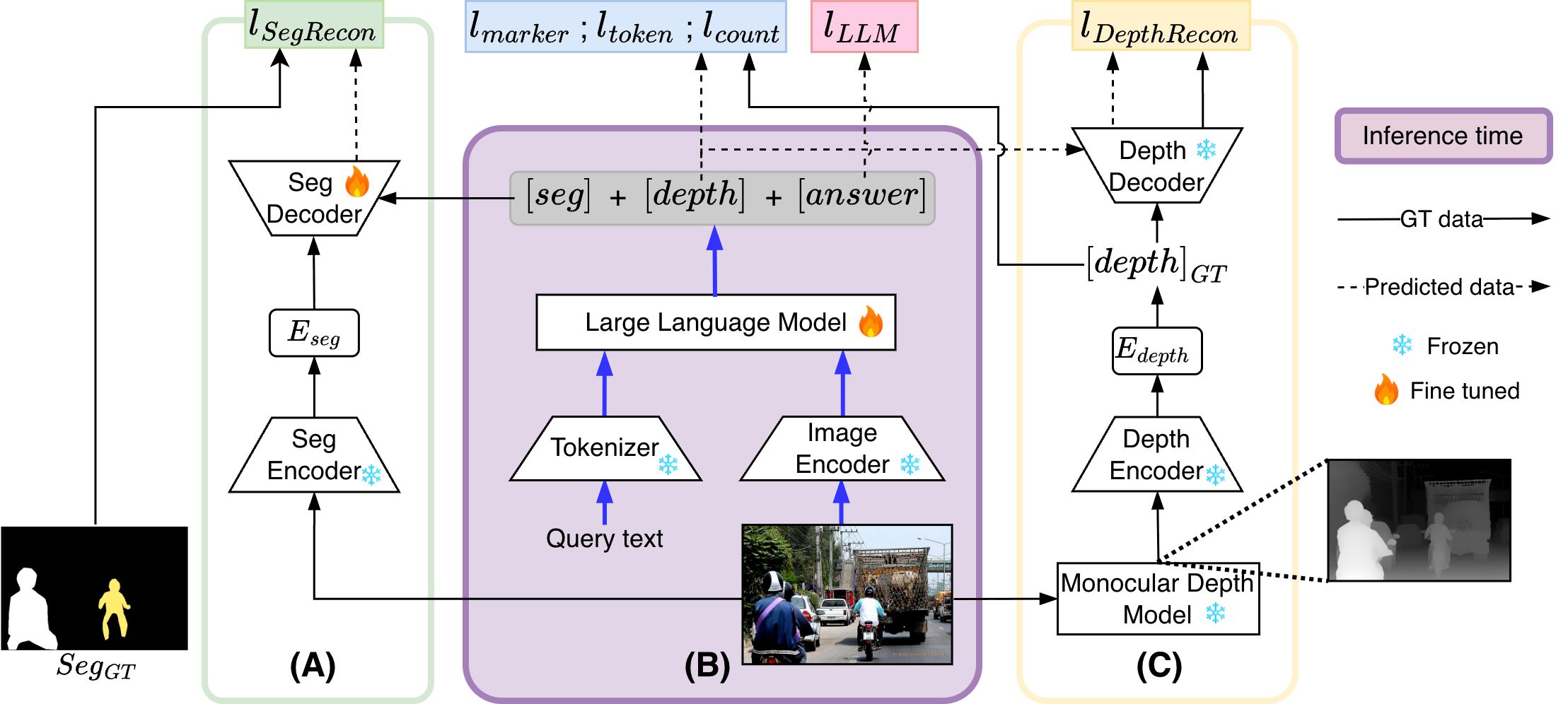
Figure 1: The Perceptio model architecture, illustrating the sequence in which segmentation and depth tokens are generated before textual answer tokens, guided by frozen teacher models.
Training and Loss Functions
Training involves multi-task co-supervision using a curated 56K-example dataset, where referring expression segmentation data is augmented with aligned depth tokens and attribute descriptions. The composite loss function consists of standard language modeling loss, segmentation reconstruction loss (pixel-wise cross-entropy plus DICE), and depth token objectives (marker, token, count losses) plus differentiable reconstruction via soft codebook mixing. Depth tokenization is stabilized through start/end marker losses and count regularization, while end-to-end differentiability is achieved through soft token averaging.
Evaluation and Numerical Results
Perceptio is evaluated on referring segmentation (RefCOCO, RefCOCO+, RefCOCOg), spatial reasoning (HardBLINK), and general multimodal VQA (MMBench, SEED-Bench, AI2D, MMStar, ScienceQA). Key numerical findings include:
- Referring Segmentation: Perceptio-8B achieves 82.7%/77.9%/80.0% cIoU on RefCOCO/RefCOCO+/RefCOCOg, consistently outperforming Sa2VA-8B (by +1.1/+1.7/+1.3 points).
- Spatial Reasoning: On HardBLINK relative depth tasks, accuracy improves by 10.3 points over the best prior (75.8%/71.0%/66.1% on 3/4/5-point tasks, 71.0% average).
- General VQA: MMBench accuracy increases by +1.0% to 83.4%.
Ablations reveal the necessity of both spatial token streams: removing depth tokens reduces HardBLINK accuracy by 25.8 points, while omitting segmentation tokens degrades VQA performance by up to 2.3 points.

Figure 2: Visual comparison on scene understanding—Perceptio predictions demonstrate accurate segmentation and depth reconstruction with well-grounded spatial text responses.
Qualitative Analysis
Qualitative results show Perceptio’s improved spatial grounding in complex scenes and competitive segmentation mask predictions. Its generated depth maps exhibit clear separation, enabling nuanced spatial language answers absent in prior approaches.

Figure 3: Comparative evaluation with Sa2VA—Perceptio yields semantically aligned segmentation and consistent depth layering, outperforming depth-agnostic baselines.
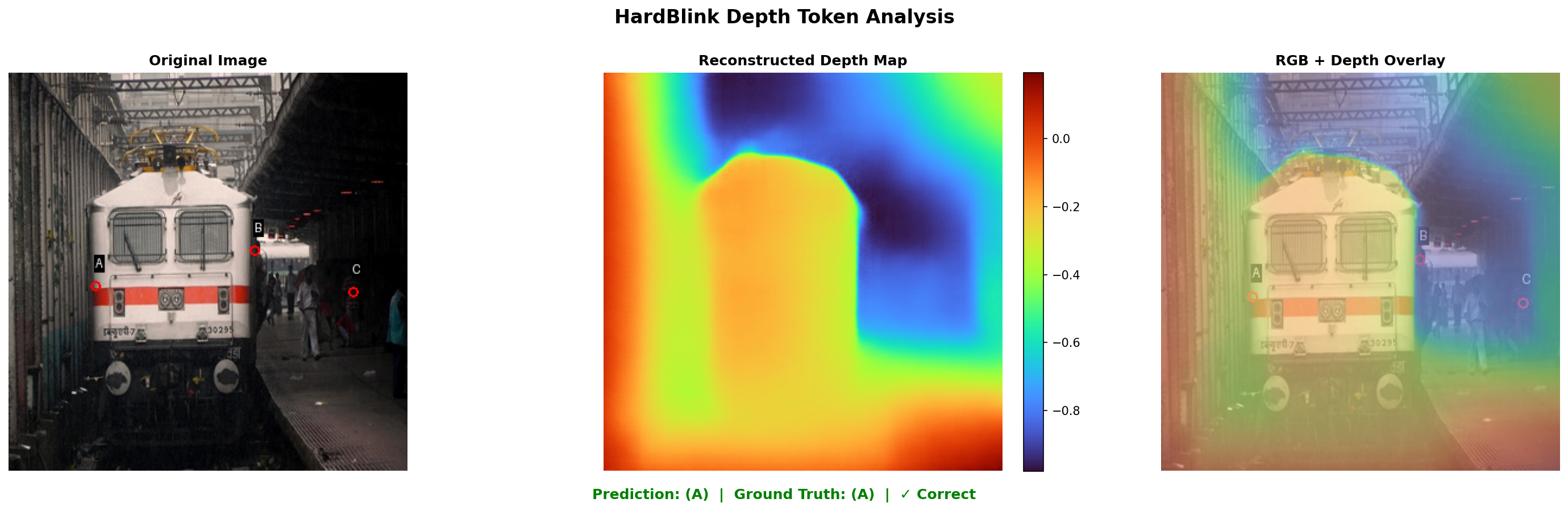
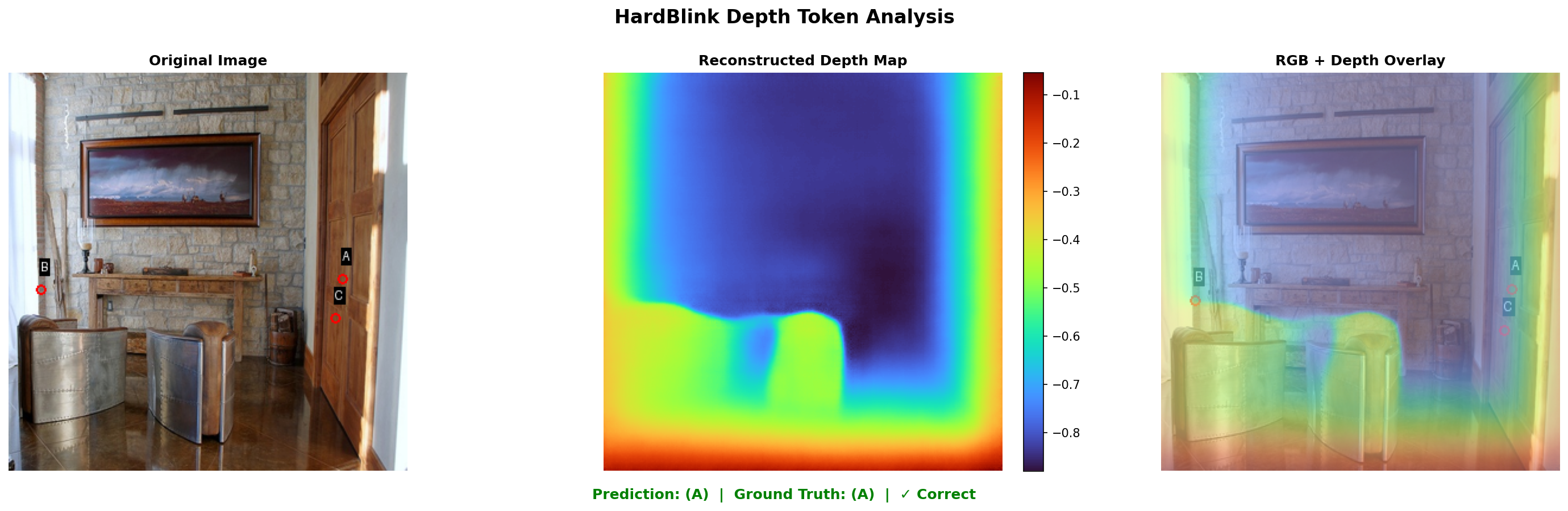
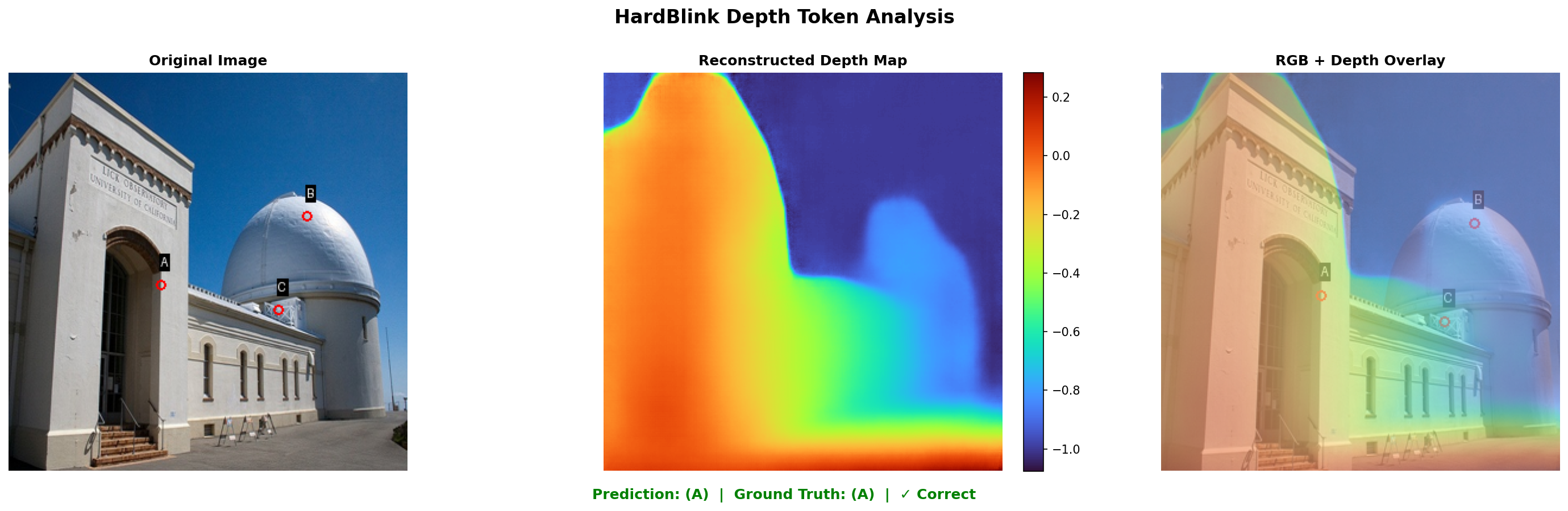
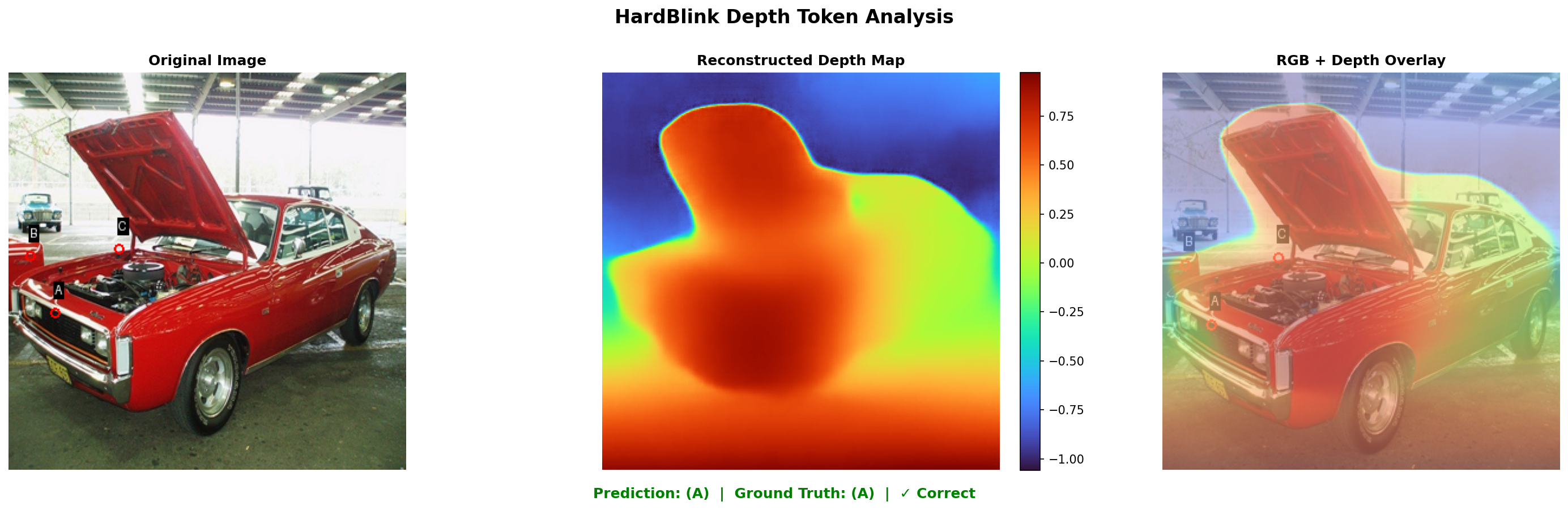
Figure 4: HardBLINK depth reasoning—overlayed depth maps illustrate Perceptio’s correct decision-making based on the reconstructed 3D structure.

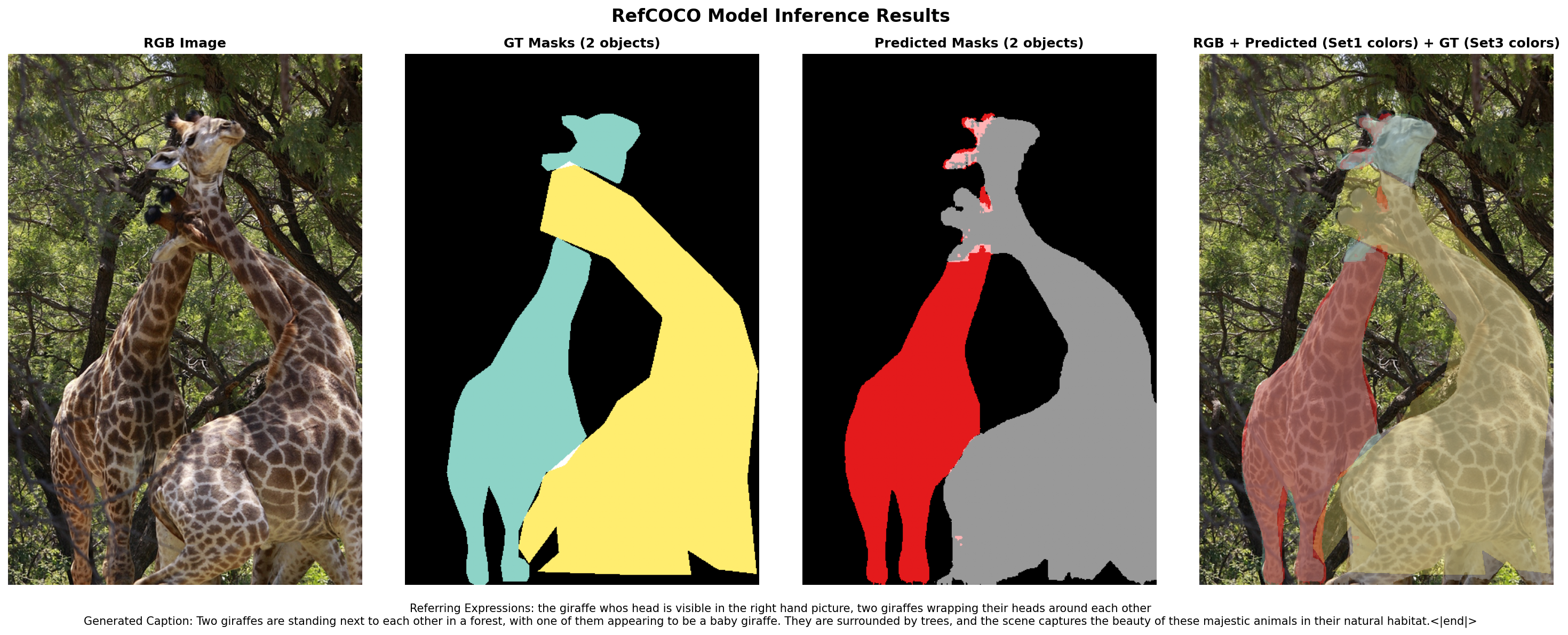
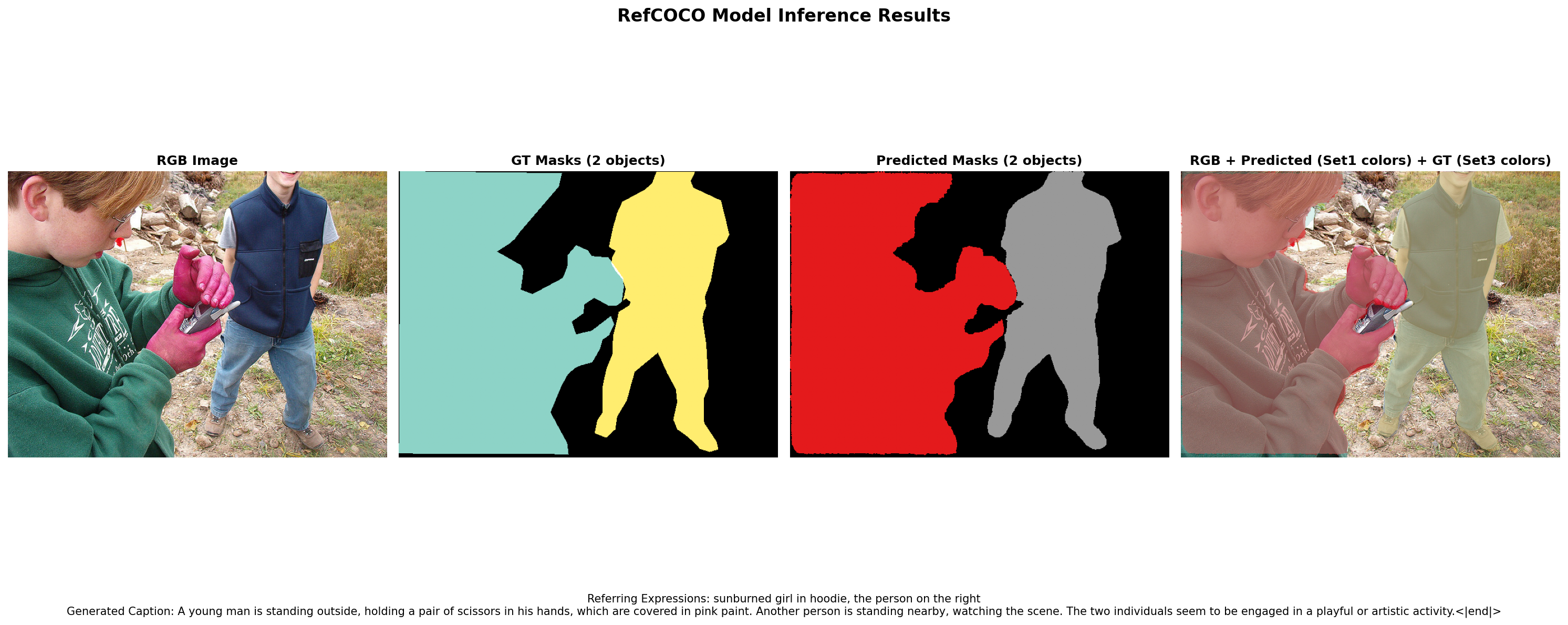
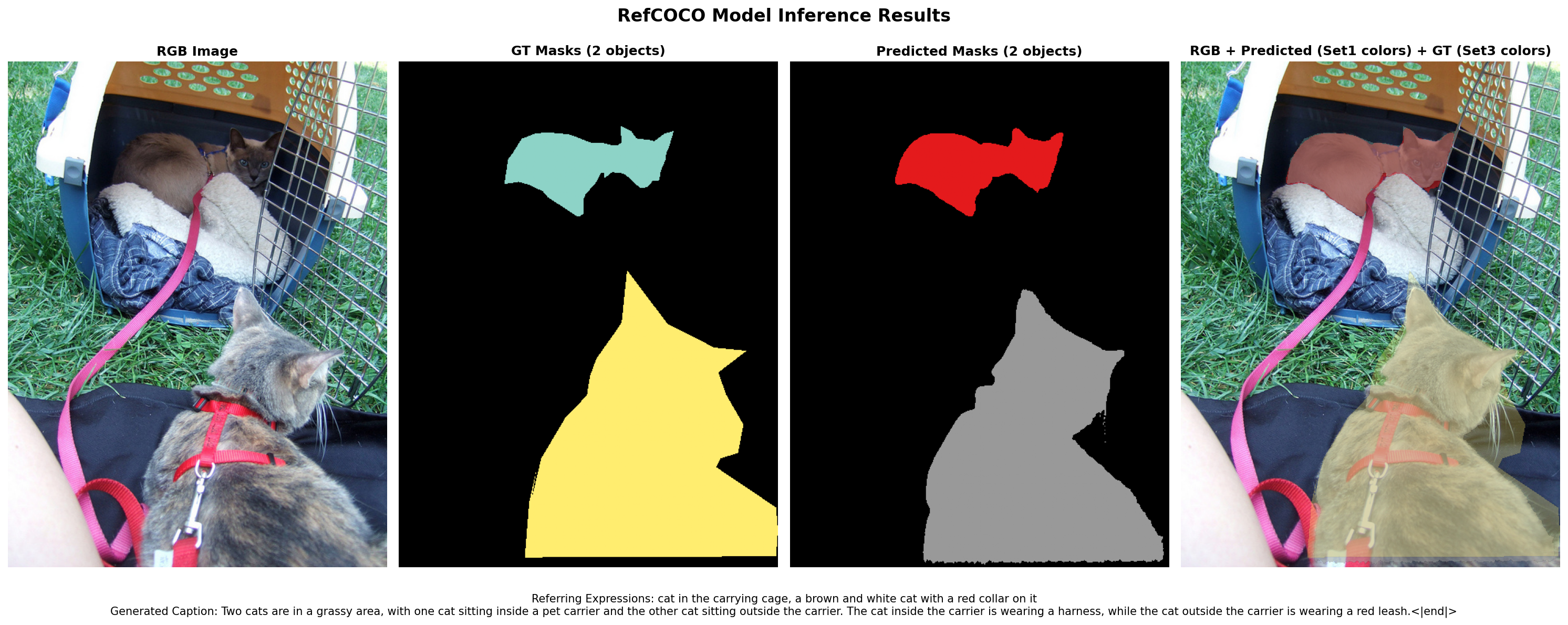
Figure 5: RefCOCOg segmentation—Perceptio’s predictions demonstrate high alignment with ground truth instance masks and robust semantic boundary delineation.
Ablation and Objective Contribution
Loss ablations confirm the complementary impact of depth token generation and soft reconstruction objectives. Removing any depth-specific loss terms consistently suppresses spatial benchmarks, underscoring the necessity for both discrete and continuous supervision.
Practical and Theoretical Implications
Perceptio introduces a unified, autoregressive modeling strategy for spatial perception, directly applicable to tasks requiring fine-grained visual grounding and reasoning, with negligible inference overhead even when generating additional spatial tokens. The approach reveals an optimization tension between text-only VQA and depth token generation, suggesting future directions for curriculum learning, adaptive task weighting, or modular spatial token integration.
Theoretically, Perceptio sets a precedent for joint optimization of complementary 2D and 3D signals within LVLMs, moving toward models capable of generalizable spatial concepts transferable across domains. The spatial chain-of-thought paradigm could be generalized to incorporate additional perception tokens (surface normals, optical flow) for unified spatial intelligence.
Conclusion
Perceptio demonstrates that explicit embedding of spatial tokens—segmentation and discretized depth—into LVLM sequences yields materially stronger spatial grounding, outperforming text-only and perception-limited baselines on both spatial reasoning and general multimodal benchmarks. The spatial tokenization architecture and composite loss function together advance the state-of-the-art in referring segmentation, relative depth reasoning, and general image QA. This work motivates further exploration into the expansion of perception tokens and adaptive training strategies, with the ultimate aim of orchestrating comprehensive spatial intelligence in autoregressive multimodal LLMs.

