- The paper introduces two novel modules, SCF-VR and RDS, to overcome optimization disbalance and fixed-depth constraints in multimodal latent reasoning.
- It presents SCF-VR for refined visual grounding by re-encoding spatially coherent image areas and RDS for adaptive token-level reasoning depth.
- Experimental results indicate state-of-the-art accuracy improvements (up to +7%) and a significant reduction in inference latency across diverse benchmarks.
Visual Enhanced Depth Scaling for Multimodal Latent Reasoning
Introduction
The paper "Visual Enhanced Depth Scaling for Multimodal Latent Reasoning" (2604.10500) introduces a unified framework for advancing the reasoning depth and visual grounding in multimodal LLMs (MLLMs) via latent-space implicit reasoning. The study rigorously analyzes the optimization dynamics at the token level and identifies two primary bottlenecks in current latent reasoning practices: a modality-induced optimization disbalance that causes visual tokens to be under-optimized, and a fixed-depth constraint that inhibits sufficient contextual refinement for complex tokens. Addressing these, the authors propose two synergistic modules: Spatially-Coherent Finer Visual Replay (SCF-VR) to intensify visual feature engagement, and Routing Depth Scaling (RDS) for adaptive, token-level iterative refinement. The solution is embedded within a curriculum learning regime that incrementally internalizes explicit reasoning into the latent space. This essay provides an in-depth summary and technical discussion, highlights the strong experimental performance achieved, and outlines implications for future multimodal reasoning architectures.
Analysis of Token-Level Optimization Dynamics
The empirical analysis presented in the paper demonstrates a significant disparity between the optimization trajectories of visual and text tokens. Specifically, visual tokens exhibit consistently higher and much more volatile gradient norms compared to their textual counterparts throughout model training. This observation is attributed to the intrinsic mismatch in feature space alignment and the dominant influence of the textual modality in joint training, which disadvantages the convergence of visual features.
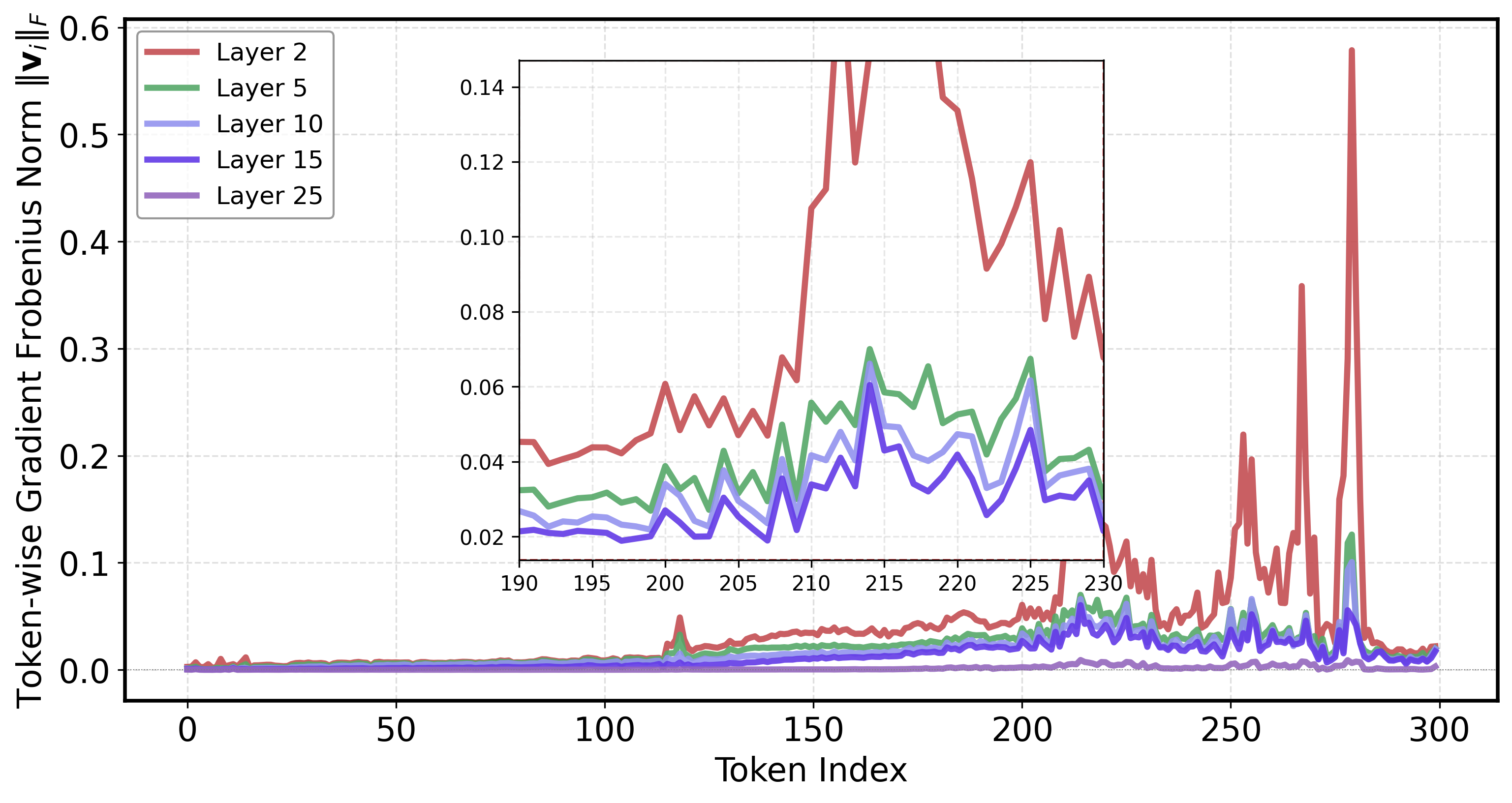
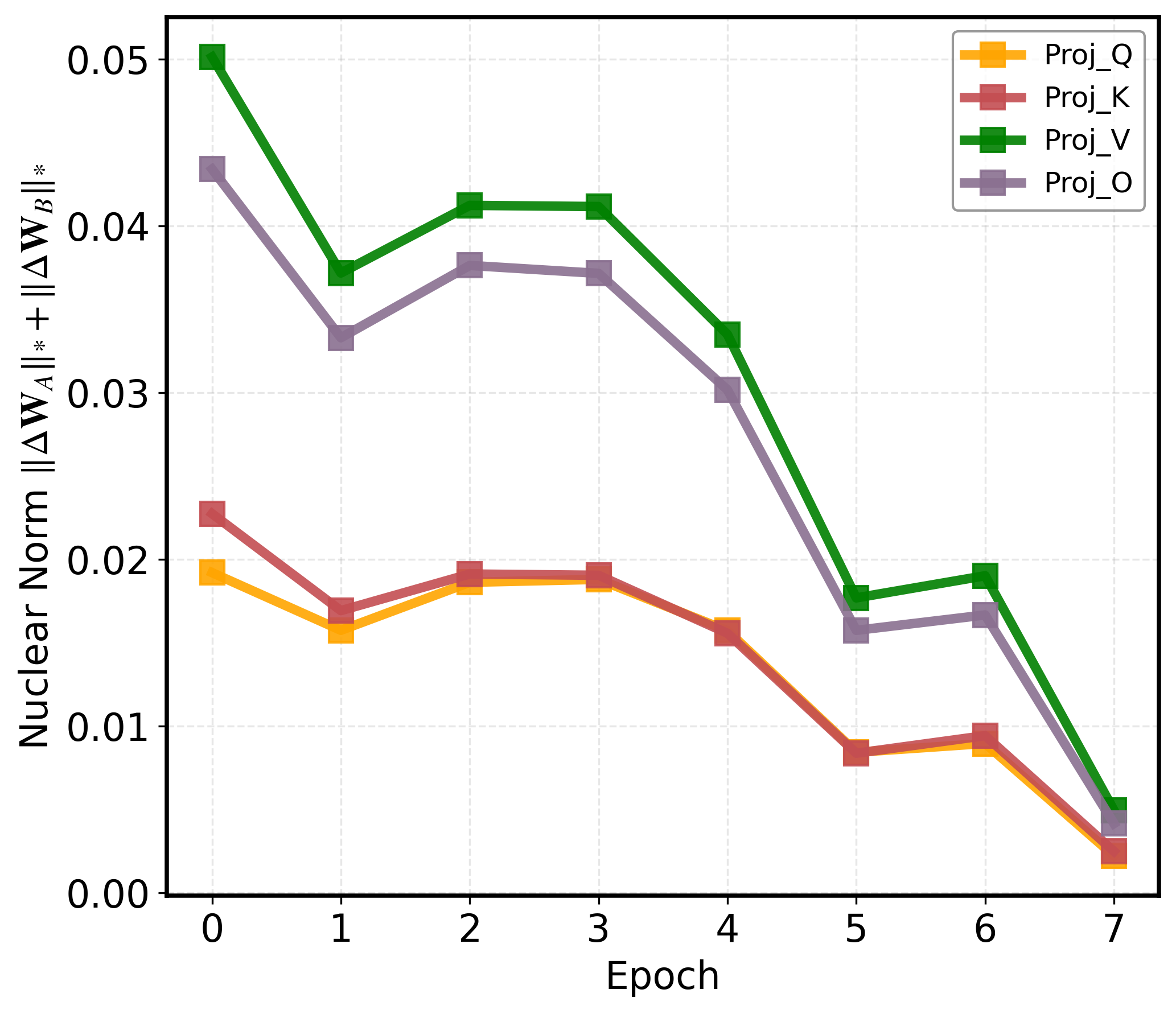
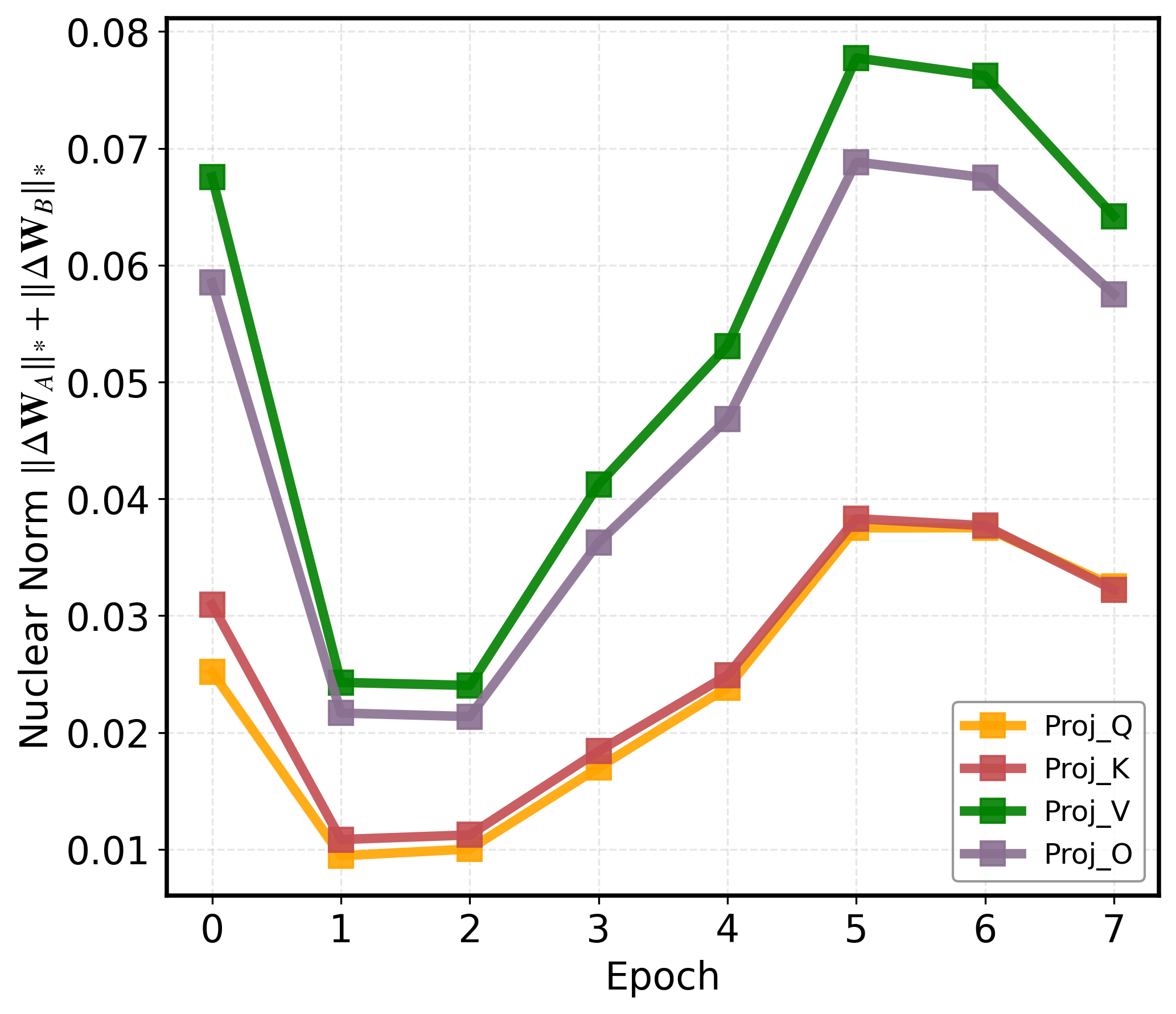
Figure 1: Visualization of token Frobenius norm across epochs shows that visual tokens (indices ~200–280) have elevated, unstable gradients compared to text tokens.
Moreover, the fixed-depth transformer decoding mechanism results in persistent optimization oscillations for complex (difficult-to-learn) tokens, evidenced by their nuclear norm evolution showing slow convergence and substantial late-phase volatility. This rigid architectural budget allocation prevents adaptive, complexity-aware resource deployment during latent reasoning and engenders inefficiencies and bottlenecks when handling compositional or visually ambiguous samples.
Methodology
Overall Framework
The proposed framework augments the standard MLLM latent reasoning pipeline by introducing two orthogonal but synergistic mechanisms—SCF-VR and RDS—which operate exclusively during the implicit (latent) feature propagation steps. These modules dynamically enhance both the informativeness of visual representations and the contextual refinement capability for complex tokens.
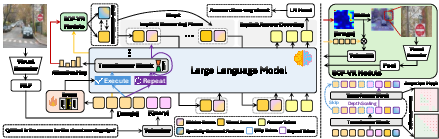
Figure 2: Left, a schematic overview of the framework where visual and text tokens are jointly encoded, and during the implicit reasoning phase, SCF-VR focuses visual grounding and RDS allocates additional reasoning to challenging tokens; right, architectural details of these modules.
SCF-VR: Spatially-Coherent Finer Visual Replay
SCF-VR performs reasoning-step-level attention-based selection of salient visual tokens, weighted and aggregated using normalized transformer attention maps. To ensure spatial consistency and mitigate the scattered focus problem, the module identifies and crops spatially contiguous image regions that maximize attended-token density, subsequently re-encoding these regions to provide high-fidelity supervision to the latent visual tokens via a self-distillation loss. This auxiliary learning objective is crucial for enforcing fine-grained visual grounding without requiring external region annotations.
RDS: Routing Depth Scaling
The RDS module employs a lightweight routing network integrated at each transformer layer to score token importance (contextual complexity or information density) and selects the top-α subset for further iterative processing. Tokens with higher router scores undergo additional local reasoning steps, while others pass through unchanged, yielding a non-uniform, token-wise adjustable reasoning depth. Variants of token selection (fixed-top-α, cosine-annealed retention, soft-mix, etc.) are investigated, with empirical results indicating that a fixed 32-token selection yields the best balance between performance and resource utilization.
Curriculum Latent Training
The training protocol initiates with explicit Chain-of-Thought (CoT) supervision to establish base reasoning skills, then progressively replaces explicit reasoning steps with latent tokens in a curriculum. This facilitates the model in compacting explicit rationales into latent space while maintaining logical structure and visual grounding, effectively learning to internalize discrete reasoning chains into continuous, expressive hidden states.
Experimental Analysis and Results
Benchmarks and Baselines
The method is systematically validated across twelve challenging multimodal reasoning benchmarks, including mathematical (MathVista, MM-Math), vision-centric (MMVP, HallusionBench, GQA), and compositional datasets (MMStar, BLINK, ScienceQA, M3CoT), using Qwen2.5-VL and Chameleon backbone architectures.
Quantitative Results
The approach achieves state-of-the-art accuracy on nearly all evaluated benchmarks, outperforming explicit CoT variants, tool-augmented solutions, and other latent reasoning methods—particularly on vision-centric data (MMVP: +4.67% gain over the prior best). Inference efficiency is markedly enhanced, with autoregressive step counts and end-to-end latency reduced by an order of magnitude relative to explicit CoT techniques while maintaining high solution fidelity.
Ablation and Sensitivity Studies
Ablation studies show consistent gains from both SCF-VR and RDS. The visual replay module yields up to +7% accuracy improvement on M3CoT when combined with adaptive depth scaling. The performance is robust to reasonable variations in window size and router token retention, with optimal results for small-to-moderate parameter values.
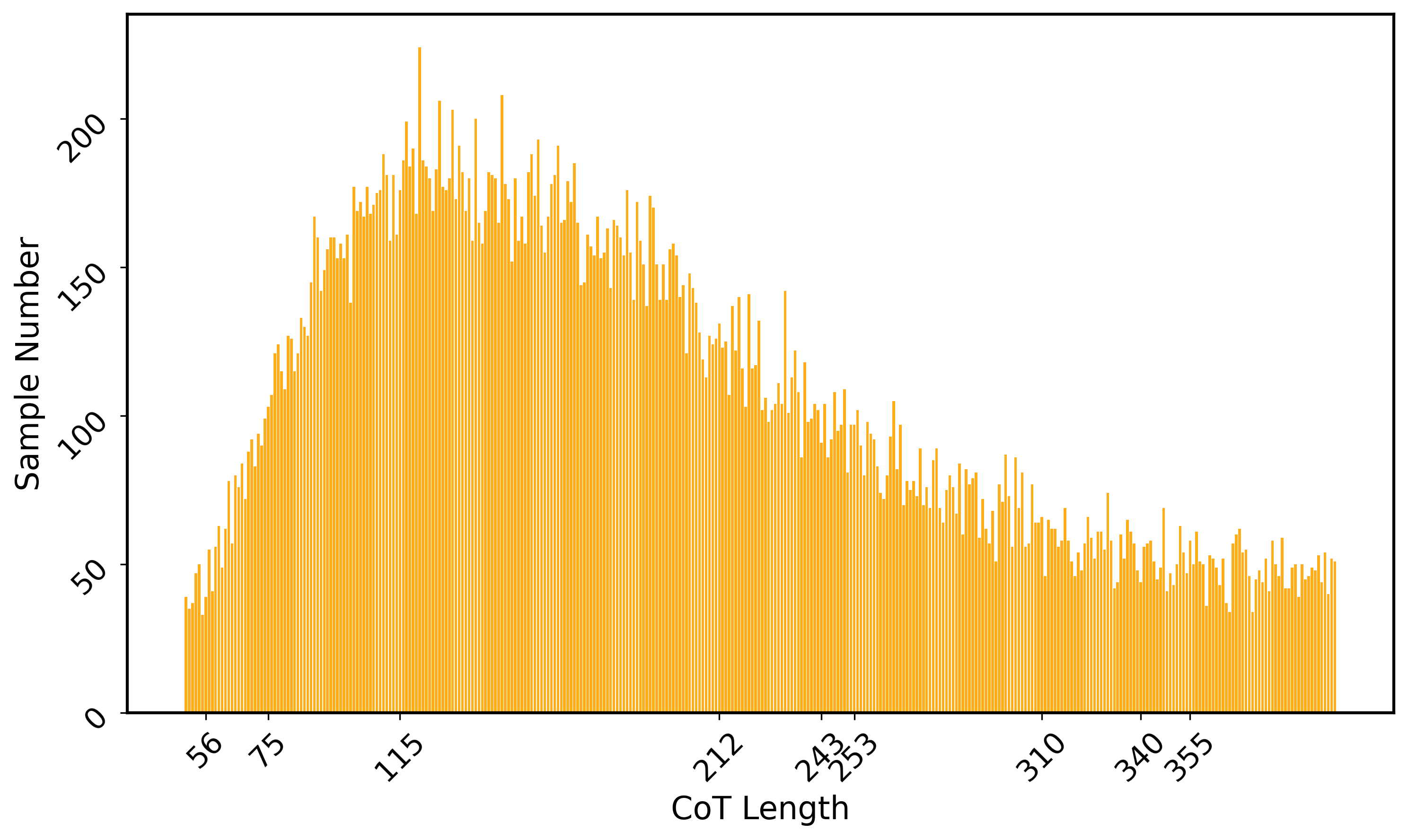
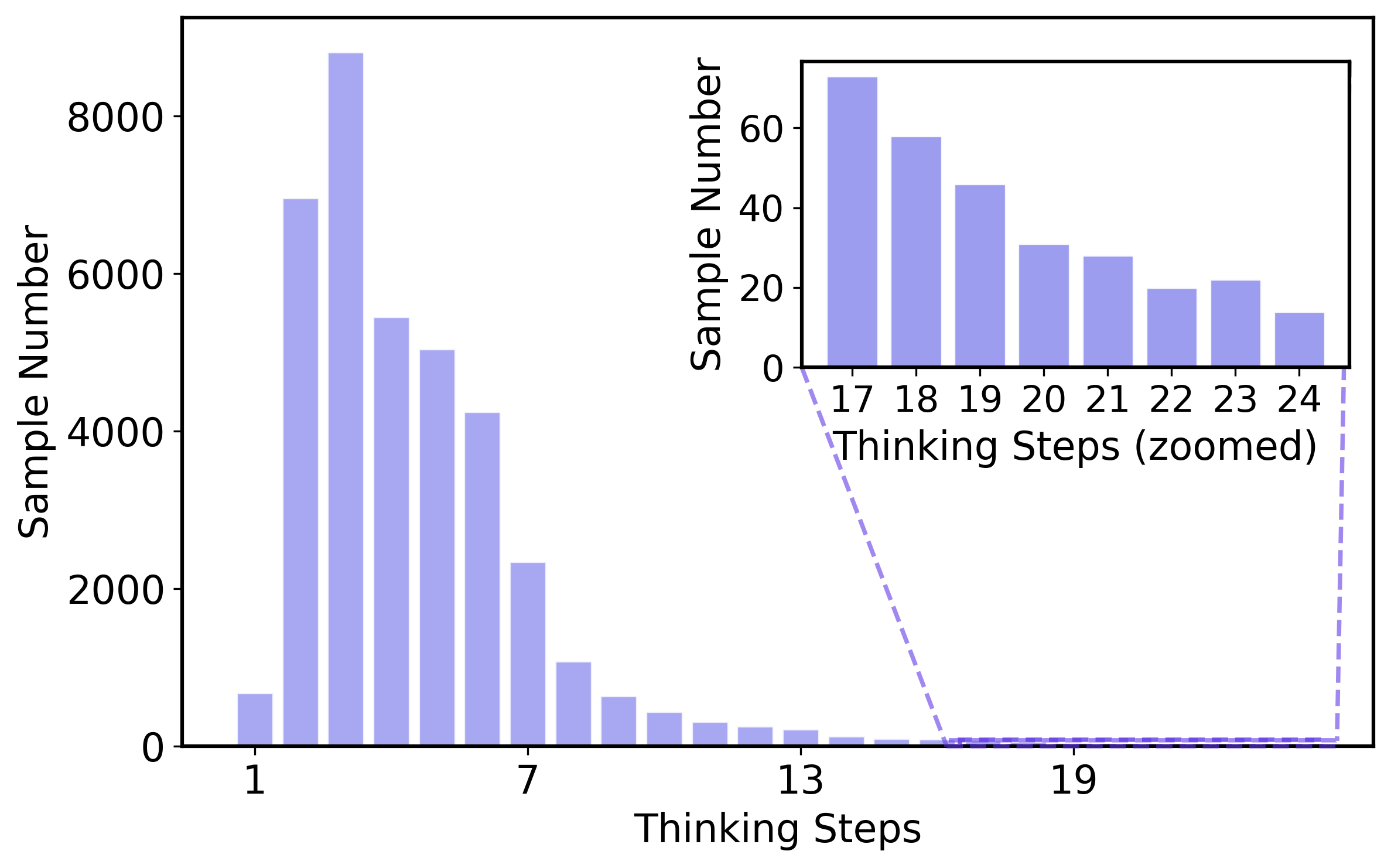
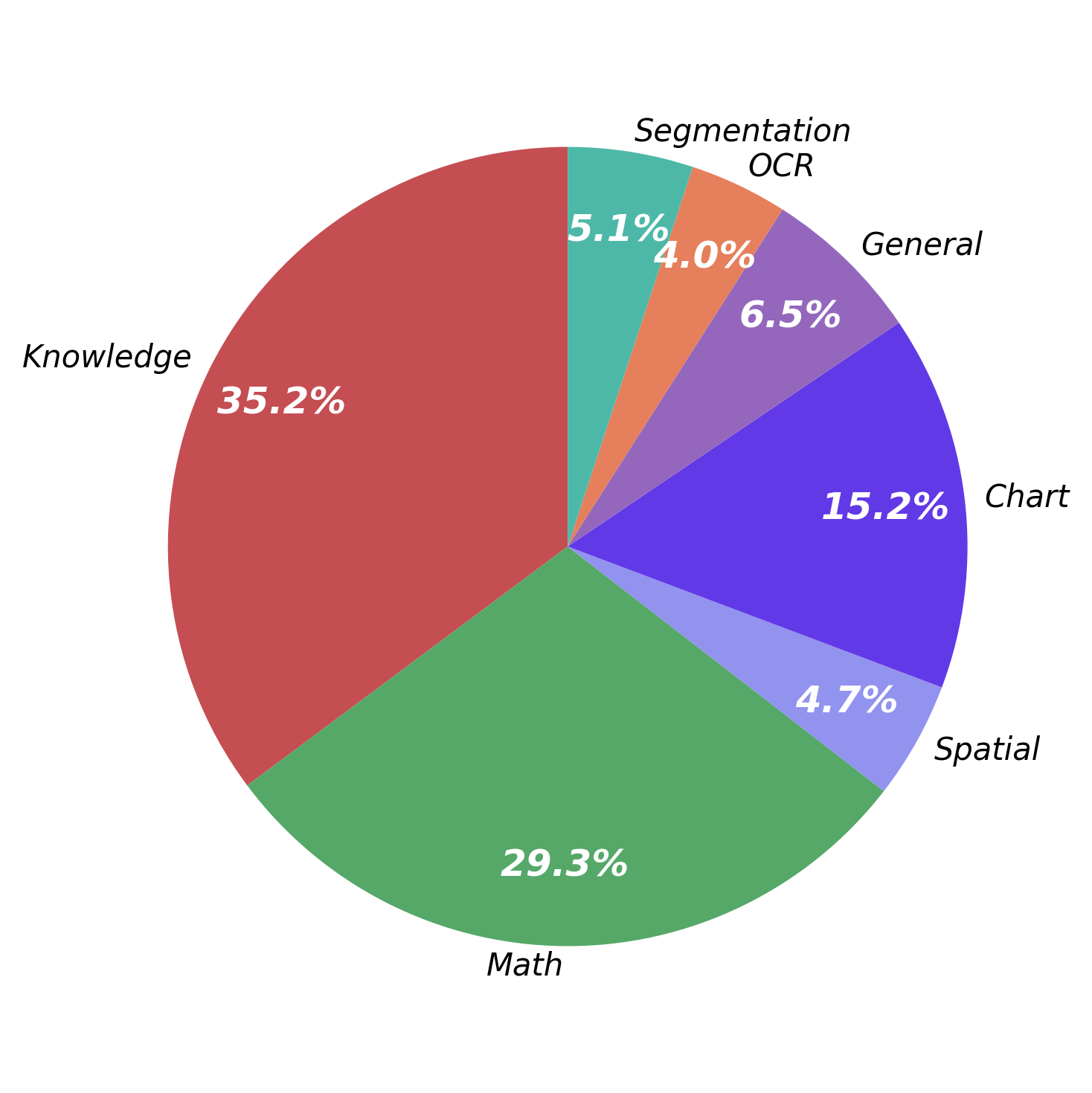
Figure 3: Distribution of CoT lengths, reasoning steps, and topics in the curriculum training data subset reveals high task diversity and variability in reasoning demand.
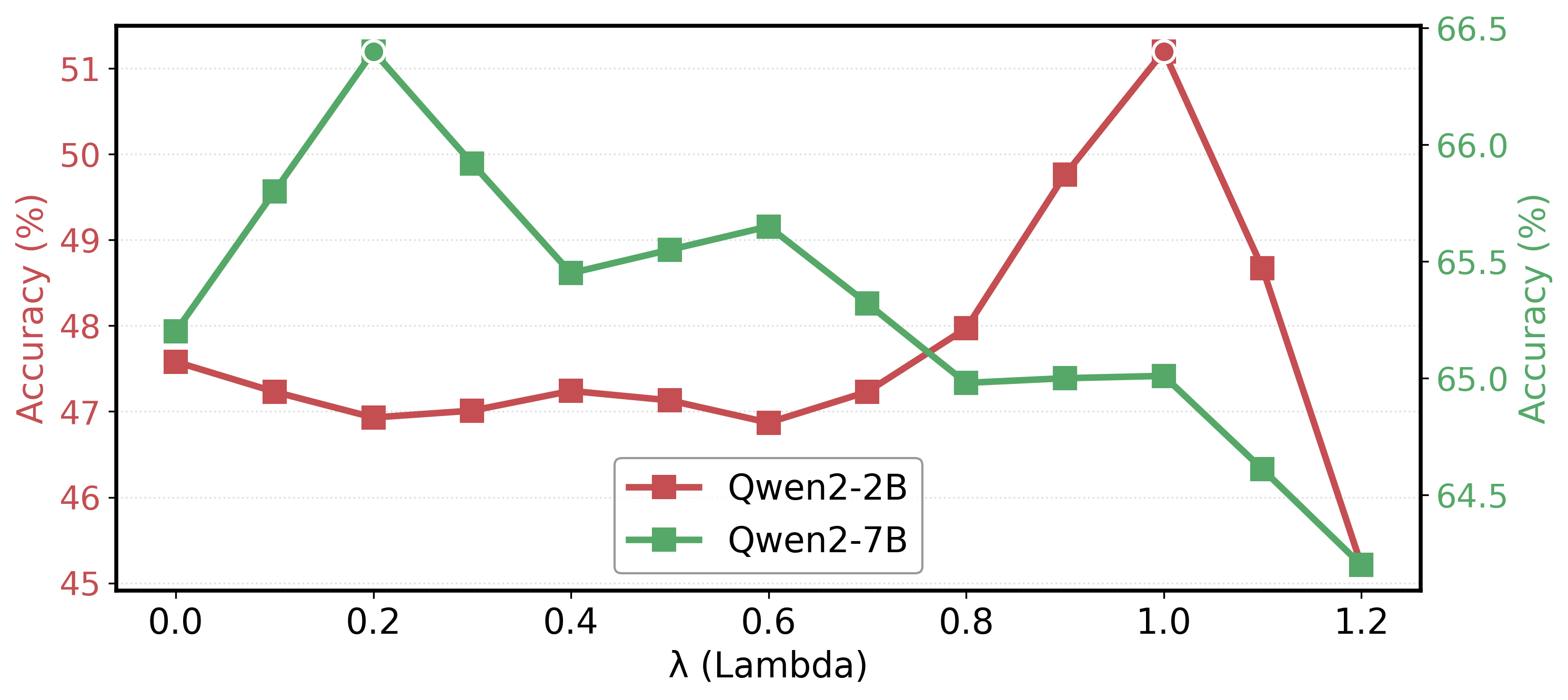
Figure 4: Sensitivity analysis exhibits model performance as a function of the self-distillation λ, indicating scale-dependent optimality.
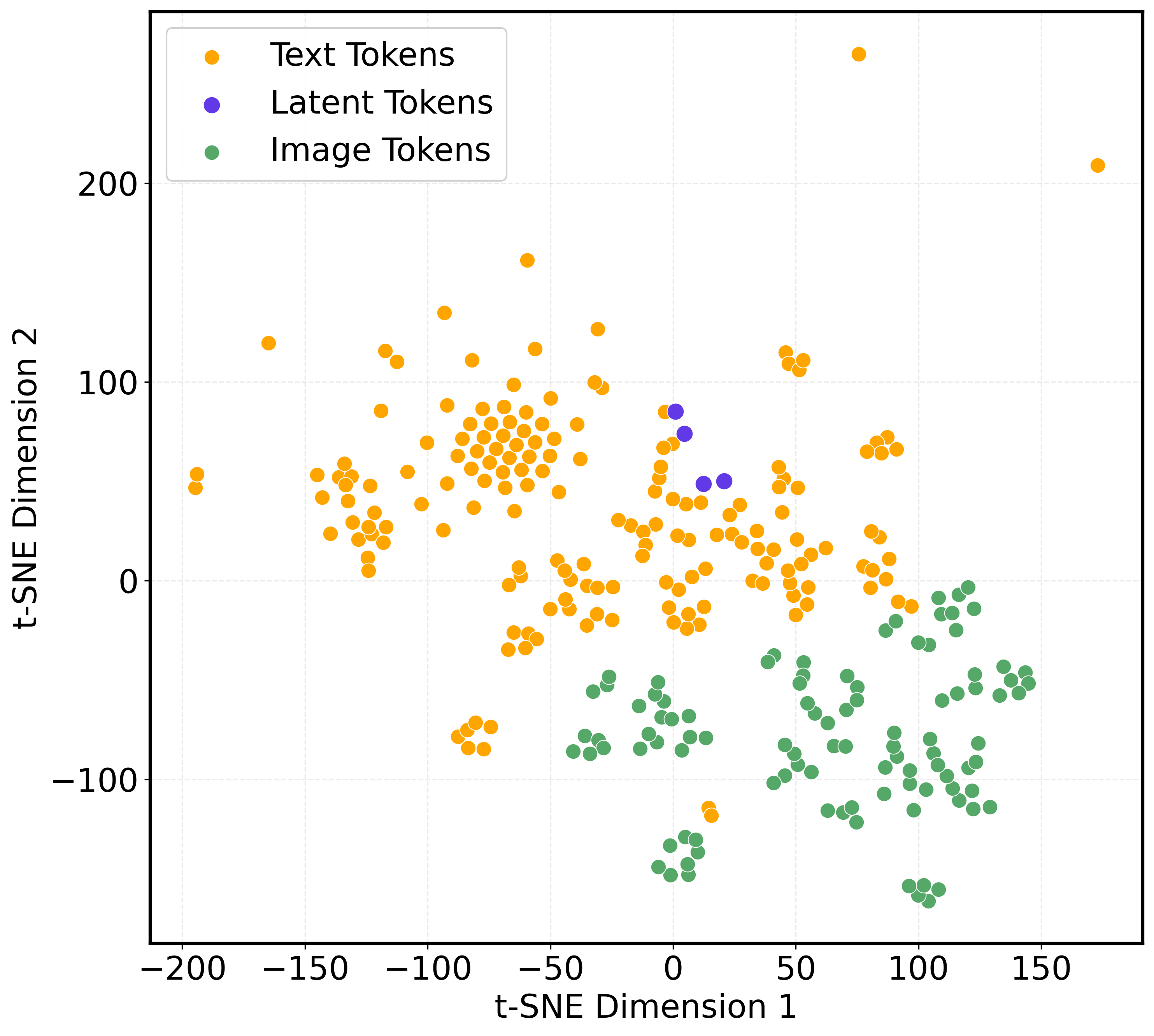
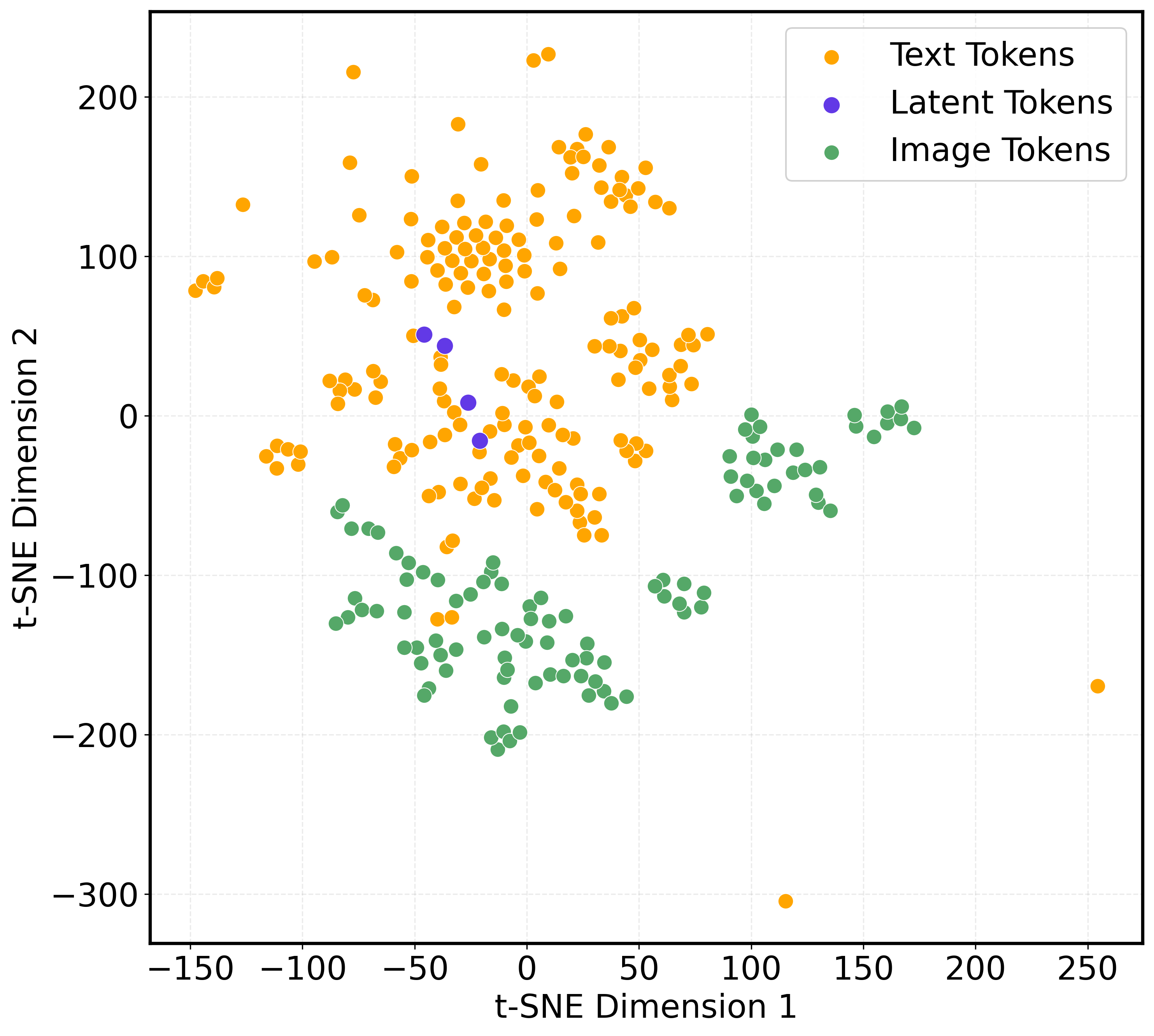
Figure 5: Evaluation of the effect of varying the number and filter ratio of event prototypes visualized in the latent space.
Qualitative Analysis
Embedding-space visualizations (not shown) indicate that latent tokens learned under the proposed method cluster more closely to visual features within text-dominant manifolds—indicative of enhanced cross-modal integration. Visualizations of attention-guided crop regions demonstrate stepwise alignment between latent-state rationales and semantically meaningful image regions over successive reasoning steps.

Figure 6: Step-wise visual focus transitions align attention-weighted cropping with evolving logical rationales during latent reasoning.
Theoretical and Practical Implications
The architecture establishes a paradigm where MLLMs dynamically multiplex reasoning resources based on per-token complexity, decouple visual and textual optimization bottlenecks, and exploit curriculum strategies to synthesize compact but logically coherent internal chains. These findings suggest that future MLLM designs should incorporate spatially-coherent replay and depth scaling to robustly address reasoning tasks requiring compositionality, visual discrimination, or fine-grained multimodal grounding. The ablation results and scalability analysis reinforce the utility and generalizability of the approach across varying model sizes and backbone designs.
Conclusion
"Visual Enhanced Depth Scaling for Multimodal Latent Reasoning" provides a rigorous, modular approach for addressing key limitations in multimodal latent-space reasoning. Through the introduction of SCF-VR and RDS—deployed within a curriculum learning regime—the method achieves robust gains in both predictive fidelity and inference efficiency. These advances have significant implications for the next generation of MLLMs, especially as the task complexity and scale of deployed systems continues to increase. Further extensions to long-horizon reasoning (e.g., video or 3D data) and multi-step compositional domains are both tractable and promising given these results (2604.10500).