Chain-of-Visual-Thought: Teaching VLMs to See and Think Better with Continuous Visual Tokens
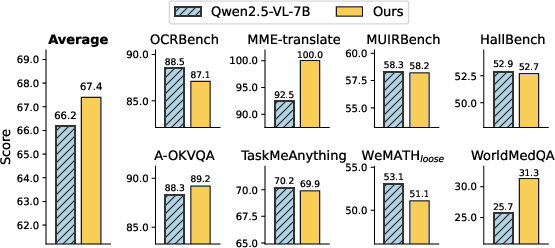
Abstract: Vision-LLMs (VLMs) excel at reasoning in linguistic space but struggle with perceptual understanding that requires dense visual perception, e.g., spatial reasoning and geometric awareness. This limitation stems from the fact that current VLMs have limited mechanisms to capture dense visual information across spatial dimensions. We introduce Chain-of-Visual-Thought (COVT), a framework that enables VLMs to reason not only in words but also through continuous visual tokens-compact latent representations that encode rich perceptual cues. Within a small budget of roughly 20 tokens, COVT distills knowledge from lightweight vision experts, capturing complementary properties such as 2D appearance, 3D geometry, spatial layout, and edge structure. During training, the VLM with COVT autoregressively predicts these visual tokens to reconstruct dense supervision signals (e.g., depth, segmentation, edges, and DINO features). At inference, the model reasons directly in the continuous visual token space, preserving efficiency while optionally decoding dense predictions for interpretability. Evaluated across more than ten diverse perception benchmarks, including CV-Bench, MMVP, RealWorldQA, MMStar, WorldMedQA, and HRBench, integrating COVT into strong VLMs such as Qwen2.5-VL and LLaVA consistently improves performance by 3% to 16% and demonstrates that compact continuous visual thinking enables more precise, grounded, and interpretable multimodal intelligence.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI models that look at pictures and read text—called Vision-LLMs (VLMs)—to “think visually,” not just in words. The authors introduce a new method called Chain-of-Visual-Thought (CoVT), which helps these models understand fine details in images, like where things are, how far away they are, and the shapes of objects, so they can answer questions more accurately.
Key Questions
The paper asks:
- How can we help AI “see” details in images while it’s thinking, instead of translating everything into words?
- Can we make this visual thinking efficient and built into the model, without relying on extra tools?
- Will this help with tricky tasks like counting objects, understanding depth (which thing is closer), and recognizing edges and shapes?
Methods (How it works)
Think of AI “tokens” as tiny pieces of information the model uses to think—like words in a sentence. Most VLMs think with text tokens only (discrete tokens), which are great for logic and language but bad at capturing smooth, detailed visual information.
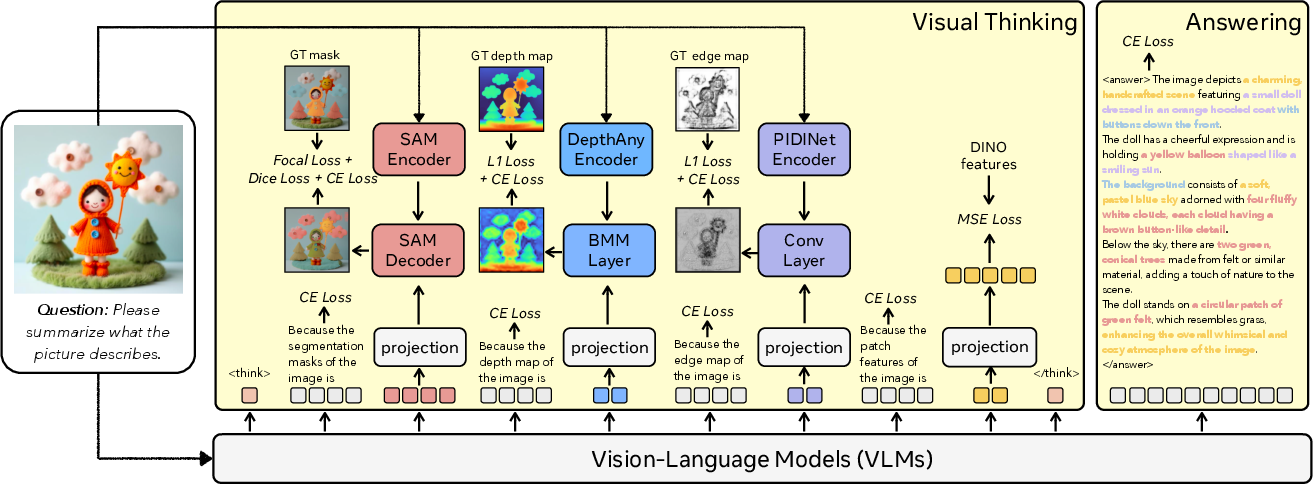
CoVT adds “continuous visual tokens,” which are like compact, mini-visual notes the AI uses internally while thinking. These tokens store:
- Segmentation: where each object is and its shape (like coloring in each object).
- Depth: how far each part of the image is from the camera (like a 3D map).
- Edges: the outlines and boundaries of things (like tracing with a pencil).
- DINO features: patch-level features that capture the overall look and meaning of parts of the image (like a fingerprint for each small region).
To teach the model what these tokens mean, the authors align them with small, specialist “vision experts” during training:
- SAM for segmentation (object masks)
- DepthAnything v2 for depth (distance maps)
- PIDINet for edges (edge maps)
- DINOv2 for patch features (semantics)
During training, the model learns to generate these visual tokens and then uses simple decoders to reconstruct the corresponding visual outputs (masks, depth maps, edge maps, etc.). This teaches the model to connect its internal visual thinking with real visual signals. At test time, the model can reason using these visual tokens directly; if needed, it can also “decode” them so we humans can see its visual thought process.
Training happens in four easy-to-understand stages:
- Comprehension: Learn what each type of visual token means.
- Generation: Practice producing the visual tokens from an image.
- Reasoning: Use the tokens inside a “visual thought chain” to help answer questions.
- Efficient reasoning: Learn to pick the most useful tokens and not depend on using all of them every time.
Main Findings
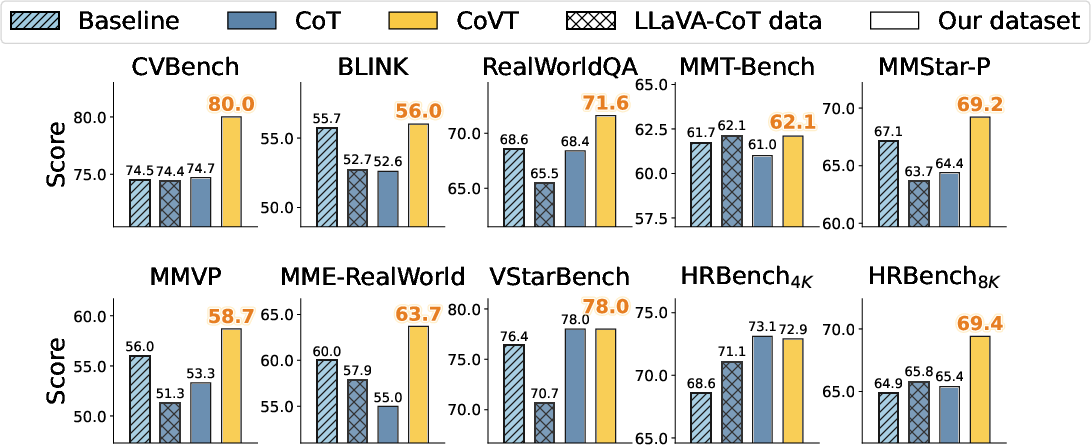
- CoVT improves performance on many vision-heavy tasks by about 3% to 16%. These include counting objects, understanding how far things are (depth), and recognizing small details in real-world images.
- The model becomes more precise and grounded in the actual image. It no longer has to force everything into words, which can lose important visual information.
- The method is self-contained: it doesn’t need extra external tools or to generate new images during thinking.
- It’s 3D-aware: depth tokens help the model reason about which object is closer or farther away.
- It’s interpretable: the visual tokens can be decoded into human-readable maps (like showing edges or depth), so you can see how the AI “thought visually.”
- Text-only “chain-of-thought” can sometimes hurt performance on picture-heavy tasks. Visual thought chains fix that by keeping the model’s reasoning anchored to the image.
- The way tokens are aligned matters. Aligning tokens through task decoders (like SAM’s mask decoder) works better than just matching features, because it preserves richer details.
- The number of tokens is important. A balanced setup (for example, 8 segmentation tokens + 4 depth tokens + 4 DINO tokens) worked best—too few loses detail, too many becomes hard to train.
Why It Matters
This research shows a practical way to make AI “see and think” at the same time. That means:
- Better accuracy on tasks that depend on fine visual details, like counting items, comparing distances, or finding small objects.
- More trustworthy AI, because we can visualize its visual reasoning and understand how it reached an answer.
- Less dependence on external tools, which makes systems simpler and cheaper to run.
- A flexible foundation: new types of visual tokens can be added later to cover more kinds of perception.
In short, CoVT helps AI go beyond just talking about pictures—it helps AI actually think in pictures.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research.
- Dependence on specific vision experts: The approach is trained with SAM, DepthAnything v2, PIDINet, and DINOv2. It is unclear how performance and stability change when substituting, updating, or removing these experts, or when experts have domain-specific biases or failures.
- Robustness to domain shift: Generalization to out-of-distribution imagery (e.g., medical, satellite, scientific plots, drawings, nighttime, low-light, heavy occlusion, motion blur) is not evaluated; sensitivity to domain shift in the supervising experts remains unknown.
- Token budget optimization: Only segmentation token count is ablated; the optimal number and allocation for depth, edge, and DINO tokens—and the trade-off between total token budget and accuracy/efficiency—are unstudied.
- Dynamic token selection policy: Stage 4 randomly drops token groups, but a learned policy for selecting which visual tokens to generate per query (e.g., via gating or routing) is not explored; the benefit of adaptive selection vs. fixed sets is unknown.
- Implementation clarity of “continuous tokens” in autoregressive decoding: How continuous visual tokens are represented, scheduled, and integrated in a primarily discrete token generation pipeline (e.g., embedding injection, positional handling, caching, beam search, sampling) is not fully specified; reproducibility may suffer.
- Inference efficiency and latency: End-to-end inference costs (latency, memory footprint, throughput) with and without decoding the visual tokens, and the incremental overhead vs. standard VLMs, are not reported.
- Training compute and scalability: The added training complexity from expert alignment and decoders (e.g., wall-clock time, GPU hours, memory), scalability to larger models or datasets, and economic cost are not quantified.
- Teacher noise and error propagation: The impact of imperfect expert outputs (pseudo-labels) on learned visual tokens, and strategies to mitigate teacher error (e.g., confidence-weighting, bootstrapping, robust losses), are not investigated.
- Unsupervised/self-supervised visual tokens: Whether CoVT can learn useful visual tokens without relying on external experts (e.g., via self-distillation, masked modeling, contrastive objectives) remains open.
- Interpretability fidelity: While qualitative visualizations are shown, the faithfulness of decoded visual tokens to the model’s internal reasoning (e.g., causal tests, counterfactuals, invariance across runs) is not quantitatively assessed.
- Stability and consistency of visual thoughts: The variance of generated visual tokens across random seeds, prompts, or minor image perturbations (and its effect on answers) is not measured.
- Multi-image and video reasoning: CoVT is demonstrated on single images; extensions to temporal reasoning (video, multi-view, stereo) and the design of motion/temporal visual tokens (e.g., optical flow, tracking) are unaddressed.
- 3D awareness beyond monocular depth: Claims of 3D awareness rely on monocular depth; tasks requiring metric depth, occlusion handling, multi-view consistency, or explicit 3D geometry (e.g., normal maps, point clouds) are not evaluated or supported.
- Quantitative evaluation of decoded outputs: The accuracy of decoded masks, edges, and depth maps relative to ground truth (e.g., mIoU, F-score, RMSE/δ metrics) is not reported, limiting validation of perceptual grounding quality.
- Robustness to adversarial or noisy inputs: Sensitivity to noise, compression artifacts, adversarial perturbations, and varying resolutions is untested; defenses or calibration mechanisms are unspecified.
- Calibration and uncertainty: There is no assessment of uncertainty estimation for visual tokens or final answers, nor calibration across visual thought chains (e.g., confidence scores tied to token quality).
- Impact on non-vision language abilities: While non-vision benchmarks show slight gains, deeper analysis of potential trade-offs (e.g., catastrophic forgetting, interference in reasoning or knowledge tasks) is missing.
- Comparative fairness and breadth: Comparisons focus on a few baselines (Qwen2.5-VL, LLaVA, Aurora); it is unclear how CoVT stacks up against stronger or more diverse tool-augmented and latent-reasoning systems under matched training/evaluation protocols.
- Curriculum and loss weighting: The four-stage curriculum and fixed loss weights (γ and λ set to 1) are not justified or optimized; their sensitivity and optimal scheduling remain open.
- Token semantics and compositionality: How different visual token types interact (e.g., synergy, redundancy, conflicts), and whether higher-level perceptual tokens (e.g., pose, parts, affordances) improve reasoning, are unexplored.
- Learned routing between text and visual reasoning: There is no mechanism to decide when to rely on visual vs. textual thoughts; the design of a controller for modality routing or cross-modality arbitration is absent.
- Generalization to broader tasks: Extensions to OCR-intensive tasks, fine-grained recognition (e.g., species, models), detection/segmentation benchmarks, and embodied or physics reasoning tasks are limited or missing.
- Scaling laws: The relationship between model size, token budget, data scale, and performance (e.g., whether larger models benefit more from CoVT) is not characterized.
- Privacy and ethics: Potential privacy risks of decoding internal visual thoughts (e.g., sensitive content, faces) and guidelines for safe interpretability are not discussed.
- Open-source reproducibility: Full implementation details (code, training scripts, hyperparameters beyond brief mentions, data splits, seeds) and statistical significance testing of improvements are lacking, hindering replication.
- Integration with retrieval or tool use: How CoVT interacts with or replaces tool-augmented pipelines (e.g., plugging in OCR/segmentation tools or retrieval), and whether hybrid approaches yield better trade-offs, is not studied.
- Extension to multimodal inputs beyond images: Support for audio, depth sensors, LiDAR, or multimodal streams, and visual token designs for each modality, remain open questions.
Practical Applications
Practical Applications of Chain-of-Visual-Thought (CoVT)
CoVT augments vision–LLMs (VLMs) with compact, continuous visual tokens (segmentation, depth, edges, patch features) that can be decoded for interpretability or used purely in latent form for efficiency. It improves fine-grained perception (counting, spatial relations, geometry) without external tools at inference, plugs into existing VLMs (e.g., Qwen2.5-VL, LLaVA), and operates within a small token budget (~20 tokens). Below are actionable applications derived from CoVT’s findings, methods, and innovations.
Immediate Applications
These can be prototyped or deployed now with modest adaptation (e.g., fine-tuning on domain data), leveraging existing VLMs and the CoVT training recipe.
Industry
- Vision QA and inline inspection in manufacturing
- Use case: Defect detection, part counting, alignment checks on assembly lines with interpretable overlays (masks, edges, depth ordering).
- Tools/products/workflows: A CoVT-LoRA adapter on top of an existing VLM; inspector dashboard that displays decoded visual thoughts alongside pass/fail decisions; W&B-style logging of tokens for root-cause analysis.
- Assumptions/dependencies: Domain fine-tuning required; high-quality imaging; non–safety-critical gatekeeping; SAM/DepthAnything/PIDINet/DINO used only during training, decoders optional at inference for visualization.
- Retail shelf analytics and inventory audits
- Use case: Product counting/facings, shelf compliance, misplaced item detection with spatial grounding.
- Tools/products/workflows: Mobile app for associates; planogram compliance reports with “show-your-work” masks/depth maps.
- Assumptions/dependencies: In-store lighting variability; moderate on-device/in-cloud compute; labeled exemplars for store formats.
- Infrastructure and energy asset inspection (drones/handheld)
- Use case: Crack/corrosion detection (edge tokens), object localization (segmentation), and approximate depth reasoning for prioritizing faults.
- Tools/products/workflows: Post-flight analytics pipeline that attaches visual thought overlays to each finding; triage UI for inspectors.
- Assumptions/dependencies: High-resolution imagery; domain calibration; human-in-the-loop review; not a substitute for certified NDT.
- Document and layout understanding (software/finance/ops)
- Use case: Table/line detection, stamp/signature counting, form region segmentation to support OCR and data extraction.
- Tools/products/workflows: CoVT-enhanced document pipelines that expose edge/segmentation maps to downstream OCR/LLM agents.
- Assumptions/dependencies: Training on scanned/document datasets; integration with OCR; handling watermark/noise artifacts.
- Data labeling acceleration and model debugging (ML Ops)
- Use case: Generate pseudo-labels (masks, edges, depth) to bootstrap specialist models; diagnose VLM failure modes via decoded tokens.
- Tools/products/workflows: Auto-labeling services; “visual thought” inspection panels in experiment tracking tools.
- Assumptions/dependencies: QA of pseudo-labels; privacy controls for stored visual tokens.
Academia
- Interpretable multimodal reasoning research
- Use case: Probing how VLMs ground answers in perception; ablations across token types (seg/depth/edge/DINO).
- Tools/products/workflows: Open protocols for decoding and scoring visual thought chains; benchmark contributions focusing on grounding.
- Assumptions/dependencies: Access to baseline VLM checkpoints and training data; reproducible decoders.
- Synthetic supervision and curriculum design
- Use case: Use decoded tokens as intermediate targets to build curricula for perception-heavy tasks or to study error accumulation vs. shorter reasoning chains.
- Tools/products/workflows: Four-stage data formatting recipe (comprehension → generation → reasoning → efficient reasoning).
- Assumptions/dependencies: Curated datasets for stages; robust token–decoder alignment strategies.
Policy and Governance
- Transparent AI auditing and procurement
- Use case: Require “visual audit trails” where models evidence claims (e.g., “3 helmets detected”) with masks/edges/depth; reduce hallucinated attributions.
- Tools/products/workflows: Compliance checklists that include decoded visual thoughts; audit logs attached to each decision.
- Assumptions/dependencies: Governance frameworks recognizing token-level interpretability; storage/PII safeguards.
Daily Life
- Accessibility and assistive description
- Use case: Grounded scene descriptions for low-vision users with highlighted regions and spatial relations (e.g., “the keys are on the front-left corner of the table” with overlays).
- Tools/products/workflows: Mobile assistants that display or narrate visual thoughts; haptic or AR pointers tied to segmentation/edge maps.
- Assumptions/dependencies: Device camera quality; optional decoding when bandwidth permits; careful UX for cluttered scenes.
- Photo organization and personal analytics
- Use case: Count people/objects, find items, cluster photos by scene layout with interpretable justifications.
- Tools/products/workflows: Consumer apps that tag images using CoVT tokens and show visual evidence on demand.
- Assumptions/dependencies: On-device or cloud processing; user consent and privacy controls.
Long-Term Applications
These require further research, scaling, domain validation, real-time constraints, or regulatory approvals.
Industry and Robotics
- Real-time closed-loop robotics and autonomous systems
- Use case: On-robot CoVT for grasp planning, collision avoidance, and precise spatial reasoning with interpretable safety checks.
- Tools/products/workflows: Hardware-accelerated token generation/consumption; safety monitors that compare visual thoughts to expected constraints.
- Assumptions/dependencies: Latency budgets, energy constraints, multi-view/video tokens, safety certification; robust OOD generalization.
- Tool-free unified perception stacks
- Use case: Replace external perception calls with latent “visual tools” learned via CoVT, reducing orchestration complexity in multimodal agents.
- Tools/products/workflows: Token plug-in system for new perceptual experts (e.g., flow, surface normals) with standardized decoders.
- Assumptions/dependencies: Scalable training pipelines; community standards for token interfaces; catastrophic forgetting avoidance.
- Industrial AR/VR and digital twins
- Use case: Persistent, geometry-aware overlays in AR work instructions; depth-aware anchoring from single views augmented with temporal tokens.
- Tools/products/workflows: CoVT-augmented AR toolkits that expose visual thought maps to anchoring/rendering modules.
- Assumptions/dependencies: Extension from images to video/sequence tokens; SLAM integration; device acceleration.
Healthcare and Safety-Critical Domains
- Medical imaging decision support (non-diagnostic to diagnostic)
- Use case: Lesion counting, region-of-interest localization, anatomy-aware QA with interpretable maps; education and triage first, eventual clinical support.
- Tools/products/workflows: Radiology assistants that surface visual thought overlays alongside textual summaries; clinician-in-the-loop validation.
- Assumptions/dependencies: Rigorous domain training, bias/robustness studies, clinical trials, regulatory clearance; calibrated uncertainty.
- Transportation and AV perception audits
- Use case: Post-hoc analysis of near-misses or failures with token-level evidence for what the system “saw” and “considered.”
- Tools/products/workflows: Incident forensics tools that reconstruct visual thought chains from logs.
- Assumptions/dependencies: Data retention policies; privacy; synchronization with sensor suites; standards for explainability.
Cross-Sector Platforms and Standards
- Standardized multimodal audit trails and reporting
- Use case: Sector-wide conventions for logging and exchanging continuous visual thought tokens as part of compliance packages.
- Tools/products/workflows: Open schemas/corpora for token streams; regulatory toolkits to validate grounding quality.
- Assumptions/dependencies: Stakeholder consensus; benchmark suites that quantify “groundedness” and calibration.
- Edge deployment and hardware co-design
- Use case: Token-efficient chips/firmware that natively support generation/consumption of continuous visual tokens with minimal power.
- Tools/products/workflows: Compiler passes that fuse projection/decoder operations; quantization-aware token learning.
- Assumptions/dependencies: Vendor support; accuracy–efficiency trade-off studies; robustness under compression.
Education and Human–AI Collaboration
- Visual reasoning tutors and curricula
- Use case: Step-by-step, grounded explanations for geometry, physics, and spatial logic, with interactive overlays that mirror the model’s thought chain.
- Tools/products/workflows: Classroom tools that let students toggle token types (seg/depth/edge) to explore alternative reasoning paths.
- Assumptions/dependencies: Age-appropriate datasets; pedagogical validation; guardrails against overreliance.
- Collaborative AI design tools
- Use case: Co-creation workflows where designers inspect and edit visual thought tokens to steer outcomes (e.g., UI layout assistance, spatial composition in creative tools).
- Tools/products/workflows: Token editors; “what-if” panels to perturb visual thoughts and preview downstream effects.
- Assumptions/dependencies: Intuitive UIs; provenance tracking; versioning of latent chains.
Key Assumptions and Dependencies Across Applications
- Training vs. inference: CoVT relies on lightweight expert models (SAM, DepthAnything v2, PIDINet, DINOv2) to align tokens during training; inference is self-contained. Decoders are only needed if human-readable visualizations are required.
- Base model and hardware: Requires a compatible VLM (e.g., Qwen2.5-VL, LLaVA) and moderate GPU for training (reported on 1×A100 or 4×A6000); deployment can be cloud or sufficiently capable edge.
- Domain adaptation: Most production applications need fine-tuning on domain-specific data to ensure reliability and reduce OOD failures.
- Interpretability vs. performance: Decoding visual thoughts adds transparency but optional overhead; pure latent reasoning preserves efficiency.
- Safety and regulation: Critical domains (healthcare, AV, industrial robotics) demand rigorous validation, uncertainty calibration, monitoring, and compliance auditing before deployment.
- Data governance: Visual thought logs may contain PII or sensitive operational details; logging, retention, and access must follow privacy and security best practices.
Glossary
- 3D-aware understanding: The capability to perceive and reason about three-dimensional spatial relationships. "C O VT uniquely combines continuous visual reasoning, dense perceptual cues, and 3D-aware understanding within a single self-contained framework."
- A-OKVQA: A benchmark for visual question answering that requires common-sense knowledge. "A-OKVQA [40], TaskMeAnything [68], WeMATH [38], and WorldMedQA-V [36]."
- Aurora: A prior multimodal method that uses latent representations for visual tasks. "Aurora [4] employs VQ-VAE latents of depth and detection signals to enhance depth estimation and counting,"
- Autoregressive prediction: A modeling approach where the next token is predicted based on previous tokens. "the VLM with C O VT autoregressively predicts these visual tokens to reconstruct dense supervision signals (e.g., depth, segmentation, edges, and DINO features)."
- Batch Matrix Multiplication (BMM): A batched operation that multiplies matrices, used here to reconstruct depth maps. "DepthAnythingv2 through batch matrix multiplication (BMM) to reconstruct the depth map,"
- BLINK: A benchmark for vision-centric reasoning tasks. "BLINK [19]"
- CCoT: Compressed Chain-of-Thought; a method that compresses CoT into continuous tokens for efficient reasoning. "CCoT [10] compresses CoT into continuous tokens for denser reasoning."
- Chain-of-Thought (CoT): A reasoning paradigm that uses intermediate textual steps to solve problems. "text-based Chain-of-Thought (CoT) reasoning [54]"
- Chain-of-Visual-Thought (CoVT): The proposed framework enabling VLMs to reason with continuous visual tokens. "We introduce Chain-of-Visual-Thought (C OVT), a framework that enables VLMs to reason not only in words but also through continuous visual tokens—compact latent representations that encode rich perceptual cues."
- Continuous latent embeddings: Dense vector representations used for efficient reasoning instead of explicit CoT. "Coconut [23] finds that continuous latent embeddings are more efficient than explicit CoT,"
- Continuous visual tokens: Compact latent vectors encoding fine-grained perceptual information for reasoning. "continuous visual tokens—compact latent representations that encode rich perceptual cues."
- CV-Bench: A benchmark focusing on fine-grained visual reasoning tasks like depth and counting. "CV-Bench [46]"
- Depth ordering: Determining which parts of an image are closer or farther from the camera. "vision-centric tasks (e.g., counting, depth ordering, and scene understanding)"
- DepthAnything v2: A task-oriented depth estimation model used to supervise depth tokens. "DepthAnything v2 [63]"
- Depth map: A per-pixel estimate of distance from the camera. "the depth map of the image is <depth>"
- Dice loss: A loss function for segmentation that measures overlap between predicted and ground-truth masks. "while dice loss and focal loss are applied."
- DINO: A self-supervised representation learning method used as a perceptual expert. "DINO [7], contrastive encoders"
- DINO features: Patch-level features extracted by DINO used for supervisory alignment. "depth, segmentation, edges, and DINO features"
- DINOv2: An improved version of DINO for extracting patch-level visual features. "DINOv2 [37]"
- Distillation losses: Losses used to align model representations with expert guidance. "propagate the reconstruction and distillation losses through the continuous tokens, aligning the model’s internal latent representations with expert guidance."
- Edge detection: Identifying boundary structures in images; used as a perceptual expert. "edge detection, or self-supervised representation learning"
- Edge tokens: Visual tokens that encode geometry-level boundary details. "Edge tokens provide geometry-level details,"
- Focal loss: A loss function designed to address class imbalance by focusing on hard examples. "while dice loss and focal loss are applied."
- Frozen vision encoder: A vision feature extractor whose parameters are not trained during the main optimization. "given visual features V extracted from a frozen vision encoder"
- Hungarian matching algorithm: A combinatorial optimization method for matching predicted masks to ground-truth masks. "the Hungarian matching algorithm is employed to match the predicted masks with the ground truths,"
- HRBench: A high-resolution benchmark for multimodal reasoning. "HRBench8k [50]"
- L1 loss: Mean absolute error loss used for reconstruction alignment. "The L1 reconstruction loss is employed for aligning Depth tokens."
- Latent imagination: Generating visual content in latent space to support reasoning. "Mirage [64] uses latent imagination for visual reasoning tasks."
- Latent space reasoning: Performing multi-step reasoning using hidden continuous representations. "reasoning in latent space can strengthen LLMs in complex, multi-step tasks [6, 8]."
- LLaVA: A family of vision-LLMs used as baselines and training data sources. "LLaVA-v1.5-13B."
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning technique for large models. "C O VT uses LoRA [24] tuning method,"
- Mask prompts: Vector prompts fed into a segmentation decoder to produce masks. "SAM uses 8 visual tokens as mask prompts;"
- MCoT: Multimodal Chain-of-Thought that edits or generates images during reasoning. "MCoT [11] enables continuous visual reasoning by editing or generating supplementary images,"
- Mirage: A method that leverages latent imagination for visual reasoning. "Mirage [64] uses latent imagination for visual reasoning tasks."
- MME-RealWorld (MME-RW): A real-world multimodal benchmark subset. "MME-RealWorld (MME-RW) [69]"
- MMT-Bench (MMT): A benchmark for multimodal model testing. "MMT-Bench (MMT) [66]"
- MMStar: A benchmark with subsets for coarse and fine-grained perception and instance reasoning. "MMStar [9]"
- MMVP: A benchmark for multimodal visual perception. "MMVP [47]"
- MSE loss: Mean squared error loss used for feature-level alignment. "and aligned under an MSE objective."
- Multi-head attention: A neural mechanism enabling models to attend to information from multiple representation subspaces. "The projection layer consists of one multi-head attention layer and two full connected layers."
- Next-token prediction: The standard autoregressive training paradigm for sequence models. "the pipeline follows a clean next-token prediction paradigm,"
- Patch-level features: Visual descriptors computed over image patches rather than pixels. "DINO uses 4 tokens to match patch-level features."
- PIDINet: A model for edge detection used to supervise edge tokens. "PIDINet [42]"
- Prompt-level alignment: Aligning visual tokens by using them as prompts to task decoders. "task-oriented signals are aligned at the prompt level, while representation-based signals are aligned in feature space."
- Qwen2.5-VL-7B: A vision-LLM used as a baseline for experiments. "Qwen2.5-VL-7B [3]"
- RealWorldQA (RW-QA): A dataset of real-world visual question answering tasks. "RealWorldQA (RW-QA) [59]"
- Representation-based experts: Models that provide feature representations rather than explicit task outputs. "representation-based experts (e.g., DINO [7], contrastive encoders), with alignment strategies tailored to each"
- SAM: The Segment Anything Model used to supervise segmentation tokens. "SAM [27]"
- Segmentation tokens: Visual tokens encoding instance position and shape for 2D spatial perception. "Segmentation tokens provide instance-level position and shape information,"
- Self-supervised representation learning: Learning representations from unlabeled data using pretext tasks. "self-supervised representation learning"
- Tool-Augmented Reasoning: Approaches that equip models with external tools for specialized tasks. "Tool-Augmented Reasoning Equipping VLMs with external tools enables them to use specialized vision models"
- VChain: A method that interleaves images and text in the reasoning chain. "VChain [26] interleaves images and text in the reasoning chain,"
- Vision–LLMs (VLMs): Models that jointly process visual and textual inputs. "Vision–LLMs (VLMs) excel at reasoning in linguistic space but struggle with perceptual understanding"
- Visual CoT: A method that interprets images via text-only chains of thought. "Visual CoT [41] relies on textual interpretations of images, limiting reasoning to the discrete text space."
- Visual thought chains: Sequences of visual reasoning steps bridging language and vision. "These visual “thought chains” bridge language and vision, enabling fine-grained understanding, spatial precision, and geometric awareness beyond the reach of text-based reasoning."
- VLMEvalKit: A toolkit used for evaluating vision-LLMs. "All evaluations are performed using VLMEvalKit [15]."
- VQ-VAE: Vector-Quantized Variational Autoencoder; a model producing discrete latent codes. "Aurora [4] employs VQ-VAE latents of depth and detection signals"
- V* Bench: A benchmark for evaluating multimodal models. "V* Bench (V*) [57]"
- WorldMedQA-V: A medical question answering benchmark with visual components. "WorldMedQA-V [36]"
Collections
Sign up for free to add this paper to one or more collections.