Symbol-Equivariant Recurrent Reasoning Models
Abstract: Reasoning problems such as Sudoku and ARC-AGI remain challenging for neural networks. The structured problem solving architecture family of Recurrent Reasoning Models (RRMs), including Hierarchical Reasoning Model (HRM) and Tiny Recursive Model (TRM), offer a compact alternative to LLMs, but currently handle symbol symmetries only implicitly via costly data augmentation. We introduce Symbol-Equivariant Recurrent Reasoning Models (SE-RRMs), which enforce permutation equivariance at the architectural level through symbol-equivariant layers, guaranteeing identical solutions under symbol or color permutations. SE-RRMs outperform prior RRMs on 9x9 Sudoku and generalize from just training on 9x9 to smaller 4x4 and larger 16x16 and 25x25 instances, to which existing RRMs cannot extrapolate. On ARC-AGI-1 and ARC-AGI-2, SE-RRMs achieve competitive performance with substantially less data augmentation and only 2 million parameters, demonstrating that explicitly encoding symmetry improves the robustness and scalability of neural reasoning. Code is available at https://github.com/ml-jku/SE-RRM.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new kind of small, efficient AI model that solves puzzle-like reasoning tasks (such as Sudoku and ARC-AGI) by “thinking” in steps. The key idea is to build the model so it naturally understands that swapping labels (like renaming digits or colors) shouldn’t change the underlying problem. The authors call these models Symbol-Equivariant Recurrent Reasoning Models (SE-RRMs).
What questions are the researchers trying to answer?
- How can we build compact AI models that reliably solve structured reasoning puzzles (like Sudoku), without needing huge amounts of training data?
- Can we make these models automatically treat symbols (digits, colors) as interchangeable when the rules say they should be, so they don’t waste effort learning unnecessary differences?
- Will this “built-in symmetry” make the models more accurate, more robust, and better at generalizing to new puzzle sizes or new symbols?
How do these models work?
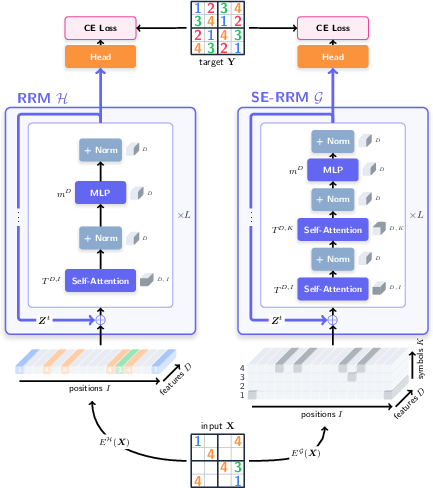
First, a quick idea of the baseline approach (RRMs):
- Recurrent Reasoning Models (RRMs) solve problems step by step, like a student who writes down a guess, checks it, and improves it repeatedly. Each step updates an internal “state” (the model’s current understanding), and the model can be trained to make good updates at every step (this is called “deep supervision,” like a teacher checking your work throughout, not just at the end).
- Traditional RRMs read puzzle inputs as a sequence of positions (cells on a grid) with symbol embeddings (digits or colors), and they use transformer layers (attention plus small MLPs) to refine their state over time.
What SE-RRM adds:
- The model is redesigned to explicitly keep track of both positions and symbols at the same time. Think of a 3D notebook:
- One axis for features (what the model knows),
- One axis for grid positions (cells),
- One axis for symbols (digits/colors).
- Attention is applied twice per block:
- Along the position axis (to relate cells to each other),
- Along the symbol axis (to relate symbols to each other).
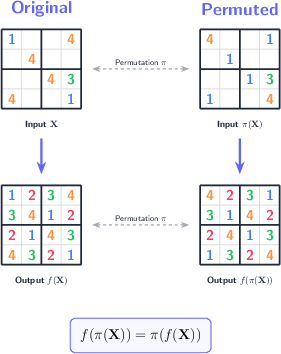
- The same embedding is used for all “usual” symbols (like digits 1–9 in Sudoku), so the model doesn’t prefer one symbol over another. Special tokens (like “unknown” or “mask”) get their own embedding. This design guarantees “symbol equivariance,” meaning if you rename every 1 to 7 and every 7 to 1, the model’s solution renames accordingly, without breaking the answer.
- Output is predicted as a score for each (position, symbol) pair, which can be turned into probabilities for “which symbol goes in this position.”
In everyday terms:
- Imagine you’re solving Sudoku. Whether the puzzle uses digits 1–9 or letters A–I, the rules are the same. SE-RRM builds this idea into the model’s brain: swapping labels shouldn’t confuse it. It looks at the grid both across positions and across symbols so it can reason about where symbols are allowed, not just what they are named.
A few technical terms explained simply:
- Attention: A way for the model to “focus” on the most relevant parts of the puzzle when making a decision.
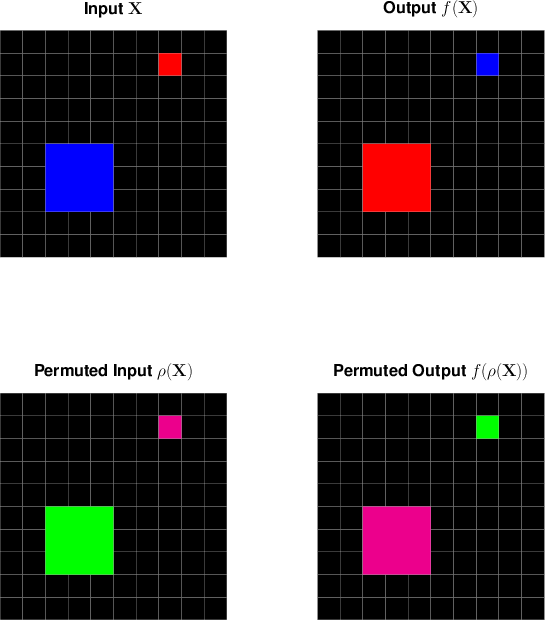
- Equivariance: If you rename symbols in the input, the output renames in the same way (the solution structure stays correct).
- Deep supervision: The model gets feedback at multiple steps, not just at the end, so it learns to improve progressively.
- Recurrent state: The model’s “scratchpad” that it updates each step as it reasons.
What did they find?
The paper reports strong results:
- Sudoku:
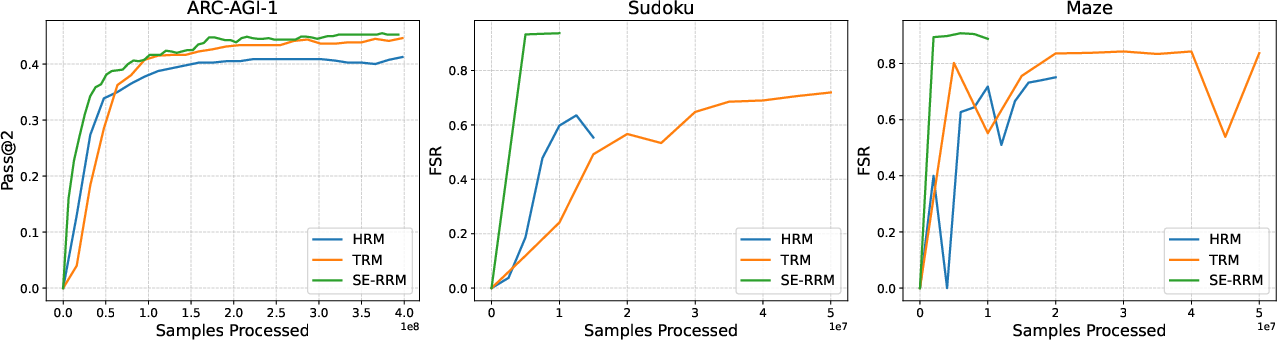
- On standard 9×9 Sudoku, SE-RRM solved more puzzles and made fewer mistakes than previous RRM models (HRM and TRM).
- SE-RRM trained only on 9×9 Sudoku still worked well on smaller 4×4 puzzles and could partially handle larger 16×16 and 25×25 puzzles. Earlier RRMs couldn’t extrapolate to larger symbol sets at all.
- ARC-AGI (a tough benchmark of colored-grid reasoning tasks):
- SE-RRMs reached competitive performance with far less “data augmentation” (fewer artificially altered training examples) and just about 2 million parameters. This shows the symmetry-aware design makes the model more robust and efficient.
Why this matters:
- By building symmetry into the model, it learns faster (less redundant data needed), generalizes better (handles new sizes or symbol sets), and is more stable (swapping labels won’t break it).
What’s the bigger impact?
- Better small models for reasoning: You don’t always need a giant LLM. SE-RRMs show that smart architecture choices can make compact models strong at step-by-step logical tasks.
- Fewer training tricks: Encoding symmetry directly reduces the need for heavy data augmentation, saving time and compute.
- More robust reasoning: In many real problems (planning, scheduling, diagnosis), labels can be arbitrary (like team IDs or category colors). Treating them as interchangeable by design can make AI systems more reliable.
- Generalization to new symbols: SE-RRM can integrate new symbols during testing more naturally than older RRMs—handy when puzzle sizes or symbol sets change.
- Trade-offs: The model does extra attention along the symbol axis, which increases computation roughly with the number of symbols. It’s great when the grid is big and the symbol set isn’t huge (like Sudoku), but if there are very many symbols, the extra cost can be high.
In short
The authors designed a reasoning model that “doesn’t care” about how symbols are named and proves that this idea makes puzzle-solving smarter. By attending both across positions and across symbols, SE-RRM delivers better accuracy, stronger generalization, and greater efficiency on structured reasoning tasks like Sudoku and ARC-AGI—all with a small model size. This approach could help future AI systems handle rule-based problems more reliably in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of gaps and open questions left unresolved by the paper that future researchers could address.
- Incomplete evaluation coverage: ARC-AGI and Maze results are mentioned but not reported with quantitative metrics, training regimes, or ablations, making it unclear where SE-RRM’s advantages and weaknesses lie beyond Sudoku.
- Generalization failure at larger Sudoku sizes: SE-RRM trained only on 9×9 achieves zero fully solved rate (FSR) on 16×16 and 25×25 despite non-trivial grid-point accuracy (GPA); identify architectural, training, and decoding bottlenecks preventing exact solutions at scale.
- Data augmentation claims unquantified: The paper asserts “substantially less” augmentation is needed but provides no controlled ablation comparing (i) baseline RRMs with augmentation, (ii) SE-RRM with and without augmentation, and (iii) augmentation levels vs performance curves.
- Runtime and memory costs not measured: Complexity is analyzed asymptotically (O(I2K + K2I)), but no empirical throughput, latency, or memory profiles are reported across Sudoku sizes and ARC-AGI tasks; practical deployment constraints remain unclear.
- Conditions for breaking or preserving symbol equivariance are underspecified: Task-type embeddings are allowed to deviate from identical initialization and may break symbol equivariance; provide principled criteria and diagnostics for when equivariance should be preserved or relaxed.
- Expressivity questions: Does SE-RRM approximate the class of permutation-equivariant functions over symbols and positions (with positional embeddings)? Formal expressivity guarantees or counterexamples are missing.
- Robustness under distribution shift is asserted but not tested: Evaluate SE-RRM vs RRMs on controlled shifts (new symbol distributions, novel rule variants, unseen layouts) to substantiate robustness claims.
- Handling semantically structured symbols: Using the same embedding for all non-special symbols assumes interchangeability; assess performance on tasks where symbols carry intrinsic structure (e.g., arithmetic relations) and explore hybrid designs that retain equivariance while encoding symbol-specific priors.
- Scalability when K ≫ I: SE-RRM may be impractical in regimes with many symbols; investigate sparse symbol-attention, low-rank factorization, or grouped-symbol strategies to reduce O(K2I) cost.
- Adaptive computation is not evaluated: The paper mentions learned stopping criteria and dynamic reasoning steps but does not report their use or benefits; compare fixed vs adaptive inference budgets for accuracy/efficiency trade-offs.
- Baseline fairness and alternative designs: The claim that HRM/TRM cannot extrapolate to unseen symbols is demonstrated for standard versions; evaluate modified baselines (e.g., symbol-axis encodings or shared symbol embeddings) to ensure a fair comparison.
- Constraint-aware decoding is absent: Sudoku constraints are not enforced at decoding; measure gains from integrating differentiable constraints, consistency regularizers, or lightweight symbolic search (e.g., beam search, CP back-check) to improve FSR at larger sizes.
- Failure mode analysis is missing: Provide error breakdowns (row/column/subgrid violations, ambiguity patterns) for Sudoku and ARC-AGI to guide architectural or training fixes.
- Sensitivity to recurrent state initialization and training schedule: Explore how Z0 initialization, number of recurrent steps, deep supervision frequency/detach strategy, and optimizer/hyperparameters affect convergence and generalization.
- Parameterization details of axial attention are underexplored: Clarify and ablate whether position- and symbol-attention share parameters, heads, or projections, and how attention order (position→symbol vs symbol→position) impacts performance.
- Interaction between positional embeddings and symbol equivariance: Formalize and verify that positional encoding schemes (e.g., RoPE) do not unintentionally break symbol equivariance via cross-dimensional interactions; provide tests and safeguards.
- Protocols for integrating new symbols at inference: The paper claims new-symbol integration is enabled, but exact-solution performance collapses at larger K; develop training curricula, calibration procedures, or normalization strategies for variable-K inference.
- Equivariance with task-type embeddings: The symbol-equivariance proofs exclude task-type embeddings; propose methods (e.g., constrained parameterization or regularization) to guarantee equivariance when task-type information is present.
- Comparison to GNNs/deep sets: Benchmark SE-RRM against graph-based and deep-set equivariant architectures on the same tasks to isolate benefits of axial attention over alternative symmetry-aware designs.
- Real-world structured tasks: Extend evaluation beyond synthetic benchmarks (Sudoku, ARC-AGI, Maze) to planning/scheduling/CP problems with variable I and K, reporting exactness, scalability, and runtime.
- Reproducibility gaps: Provide complete training details (dataset sizes, augmentation recipes, optimizer, learning rate schedules, recurrent steps, early stopping criteria) and seeds to enable replication and fair comparisons.
- Normalization and MLP design choices: Only RMSNorm and SwiGLU are reported; ablate alternative normalizations (LayerNorm, ScaleNorm) and MLP variants to test stability and performance impacts on recurrent reasoning.
- Curriculum and multi-scale training: Investigate curricula over grid sizes and symbol cardinalities, and multi-scale training (joint 4×4/9×9/16×16) to improve extrapolation to larger boards and unseen K.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now, leveraging the paper’s methods and findings. Each item specifies sectors, the application concept, potential tools/workflows, and feasibility notes.
- Symmetry-robust puzzle solvers and tutors (software, games, education)
- Application: Build Sudoku and ARC-style puzzle engines that automatically handle symbol/color permutations and generalize across grid sizes (e.g., train on 9×9 and deploy on 4×4, 16×16, 25×25).
- Tools/workflows: Use the open-source SE-RRM codebase; package models (~2M params) for on-device inference; export via ONNX for mobile apps; incorporate axial attention across position and symbol dimensions.
- Assumptions/dependencies: Puzzles exhibit symbol-permutation invariance; number of symbols K is moderate relative to positions I; positional embeddings are correctly applied to avoid unwanted position equivariance.
- Reduced data-augmentation pipelines for symmetry-aware tasks (software, ML engineering)
- Application: Replace costly symbol/color permutation augmentation with SE-RRM layers in structured symbolic tasks (e.g., grid-based classification with interchangeable labels).
- Tools/workflows: Integrate symbol-attention layers in existing transformer-based pipelines; create a reusable “symbol-equivariant embedding” module; monitor training sample complexity and convergence.
- Assumptions/dependencies: Task labels are interchangeable (true symmetry); the task can be represented as a tuple/grid of symbols; the symbol set size does not explode (K ≪ I preferred).
- Heuristic guidance for constraint solvers (software, optimization)
- Application: Use SE-RRM outputs to guide CP/SAT/MIP solver search (e.g., Sudoku, graph coloring), reducing branching and runtime while preserving solver correctness.
- Tools/workflows: Wrap SE-RRM as a policy/value heuristic in OR-Tools or MiniZinc pipelines; run iterative inference to refine states; fall back to exact solvers for proof/certification.
- Assumptions/dependencies: Solver integration is feasible; SE-RRM’s suggestions improve pruning; tasks admit symmetry so equivariance is beneficial.
- Lightweight, on-device reasoning for educational tools (education, software)
- Application: Deploy small SE-RRM models in classrooms and mobile apps to teach logic/combinatorics, provide instant explanations, and auto-grade puzzle assignments.
- Tools/workflows: Edge deployment on mobile/embedded hardware; a curriculum tool that generates puzzles of varying sizes using the same model; iterative decoding for step-by-step explanations.
- Assumptions/dependencies: Compute/memory budgets support small recurrent runs; explainability via intermediate states is acceptable; tasks are safely non-critical.
- Maze and grid pathfinding in games (software, games)
- Application: Integrate SE-RRM for discrete grid-based pathfinding and puzzle generation where labelings are arbitrary (e.g., tile colors), improving robustness to asset permutations.
- Tools/workflows: Use symbol axial-attention to keep behavior invariant to art/asset recolors; pair with game-level A* for final path validation.
- Assumptions/dependencies: Discrete grid abstraction is appropriate; symbol sets (tile types) remain modest in size; position embeddings are used to avoid unwanted position equivariance.
- Academic baselines for symmetry-aware reasoning (academia)
- Application: Establish SE-RRM as a baseline for ARC-AGI-like tasks and Sudoku, studying robustness, sample efficiency, and test-time scaling with explicit symmetry encoding.
- Tools/workflows: Reproduce experiments using the GitHub repo; ablation studies on symbol and position embeddings; benchmark against TRM/HRM with reduced augmentation.
- Assumptions/dependencies: Availability of labeled solutions; consistent evaluation protocols; research compute for iterative training.
Long-Term Applications
The following opportunities require further research, scaling, domain adaptation, or integration with other systems before broad deployment.
- Symmetry-aware combinatorial optimization in industry (logistics, manufacturing, scheduling)
- Application: Use SE-RRM as a learned heuristic or co-pilot for complex timetabling, crew rostering, and resource allocation where certain identifiers (e.g., interchangeable slots/colors) are symmetric.
- Tools/workflows: Hybrid pipelines combining SE-RRM with CP/SAT solvers; iterative refinement with learned stopping criteria; scenario testing across variable problem sizes.
- Assumptions/dependencies: Many enterprise constraints are heterogeneous and may break symmetry; requires careful domain encoding and validation; safety-critical contexts need exact solvers and audit trails.
- Symbol-invariant decision support in healthcare (healthcare)
- Application: Prototype triage and scheduling tools that remain invariant to arbitrary code labelings (e.g., procedure categories, bed types), improving robustness and reducing bias from label encodings.
- Tools/workflows: Pair SE-RRM-based heuristics with hospital scheduling systems; enforce constraint satisfaction via a symbolic backend; monitor equity and compliance metrics.
- Assumptions/dependencies: Clinical validation, regulatory approvals, and interpretability; many medical identifiers are not interchangeable—symmetry must be explicitly justified per task.
- Compiler optimization and EDA (software, robotics, energy)
- Application: Assist register allocation and graph coloring tasks (symbol colors interchangeable), or placement/routing heuristics in chip design with symmetry-aware reasoning.
- Tools/workflows: Integrate SE-RRM into existing compilers/EDA toolchains as a heuristic; co-train on solved instances; maintain exact verification passes post-heuristic search.
- Assumptions/dependencies: Large K in some domains may stress complexity (O(I2K + K2I)); mapping problems to SE-RRM tensor formats; stringent correctness requirements.
- Finance and insurance risk/pricing with category code robustness (finance, insurance)
- Application: Build models that are invariant to arbitrary recoding of categorical groupings (e.g., product classes, tariff bands), reducing reliance on hand-crafted augmentations and improving robustness.
- Tools/workflows: SE-RRM modules for tabular-structured reasoning tasks; hybrid pipelines with rule engines; audit logging of iterative states for compliance.
- Assumptions/dependencies: Many categories have semantic differences (not symmetric); K can be large (potentially impractical); regulatory constraints on model behavior demand extensive validation.
- Robotics task planning with interchangeable object classes (robotics)
- Application: Use SE-RRM for discrete task planning where certain object classes or markers are interchangeable (colors/tags), aiding robustness to labeling changes in symbolic planners.
- Tools/workflows: Bridge SE-RRM discrete plans to continuous controllers; integrate with classical planners for guarantees; deploy recurrent inference for adaptive computation.
- Assumptions/dependencies: Translating from grid/symbol tasks to real robotic states; data collection of solved plans; maintaining safety and formal verification.
- Policy and operations planning with verified heuristics (policy, public sector)
- Application: Resource allocation (e.g., school seat assignments) with symmetry-aware heuristics that are label-invariant, paired with exact solvers for proof of correctness.
- Tools/workflows: Decision-support portals combining SE-RRM heuristics and CP/SAT certification; transparency via intermediate states; fairness audits for symmetry assumptions.
- Assumptions/dependencies: Public accountability and explainability; many identifiers are not interchangeable in practice; formal guarantees required before deployment.
- AutoML symmetry detection and model selection (software, academia)
- Application: Automatically detect permutation symmetries in tasks and insert SE-RRM layers or training protocols, reducing augmentation and improving generalization.
- Tools/workflows: Symmetry-detection modules; configurable axial attention blocks; meta-learning to select recurrence depth and stopping criteria.
- Assumptions/dependencies: Reliable detection of true symmetries; domain-specific validation; scalability when K grows.
- Standards and benchmarking for symmetry-aware reasoning (academia, policy)
- Application: Establish benchmark suites and evaluation standards for permutation-equivariant reasoning, encouraging robust, sample-efficient models in regulated domains.
- Tools/workflows: Community datasets with controlled symmetries; reporting protocols for data augmentation reliance; stress tests for extrapolation across symbol counts and grid sizes.
- Assumptions/dependencies: Cross-institution collaboration; alignment on metrics and fairness criteria; sustained funding and compute resources.
Cross-cutting feasibility notes
- Architectural constraints: SE-RRM’s complexity scales as O(I2K + K2I); it is most practical when the number of positions I dominates the number of symbols K. Tasks with K ≫ I may be impractical without architectural or algorithmic improvements.
- Task suitability: Symbol equivariance is beneficial only when labels are truly interchangeable. In many real-world domains, identifiers carry semantics—careful scoping is essential.
- Safety and guarantees: For high-stakes applications, use SE-RRM as a heuristic combined with exact symbolic solvers to retain correctness and provide certificates.
- Generalization: The demonstrated extrapolation across grid sizes and integration of new symbols suggests resilience, but domain transfer requires task-specific encoding and validation.
- Deployment: The small parameter count enables edge and mobile use; iterative inference allows flexible compute at test time, but latency may increase with recurrence steps.
Glossary
- ARC-AGI: A benchmark of abstract visual reasoning tasks used to evaluate generalization and problem-solving abilities in AI systems. "such as ARC-AGI tasks \citep{chollet2019measure, chollet2025arc}"
- Axial-Attention: An attention mechanism that applies self-attention along one axis (e.g., rows) and then along the other axis (e.g., columns) to model multi-dimensional structures efficiently. "For example, Axial-Attention \citep{ho2019axial} applies one transformer block along the rows and another transformer block along the columns of an image,"
- categorical cross-entropy loss: A standard loss for multi-class classification that compares predicted class probabilities to the true class label. "A categorical cross-entropy loss can then be applied independently to each position."
- constraint programming (CP): A paradigm for solving combinatorial problems by specifying constraints that feasible solutions must satisfy, solved via systematic search. "have traditionally been solved using symbolic methods such as SAT, constraint programming (CP), and mixed-integer optimization (MIP) solvers"
- Criss-Cross Attention: An attention mechanism that captures long-range dependencies by attending along criss-cross patterns (rows and columns) in images. "while Criss-Cross Attention \citep{huang2019ccnet} applies the same principle in the domain of image segmentation."
- Deep Equilibrium Models (DEQs): Neural architectures that define outputs as fixed points of recurrent transformations and train via implicit differentiation. "While Deep Equilibrium Models (DEQs) \citep{bai2019deep} similarly rely on fixed external inputs,"
- deep sets: Neural architectures designed to process sets by enforcing permutation invariance or equivariance over elements. "Permutation equivariance has previously been explored in deep sets \citep{deepsets}"
- deep supervision: A training strategy that applies loss signals at intermediate layers or iterations, not just the final output, to improve gradient flow and learning. "An important technique employed in both HRM and TRM is deep supervision."
- fixed-point iteration scheme: An iterative procedure where a function is repeatedly applied until its input and output converge (reach a fixed point). "in a fixed-point iteration scheme."
- graph neural networks: Neural models operating on graph-structured data, typically invariant or equivariant to node permutations. "and graph neural networks \citep{scarselli2008graph, kipf2016semi, defferrard2016convolutional, gilmer2017neural}"
- Hierarchical Reasoning Model (HRM): A recurrent reasoning architecture that structures computation hierarchically to solve discrete reasoning tasks. "Hierarchical Reasoning Model (HRM) \citep{wang2025hierarchical}"
- implicit differentiation: A technique to compute gradients through solutions of equations (e.g., fixed points) without unrolling iterative procedures. "optimizing them via implicit differentiation instead of time-unrolled dynamics."
- learned stopping criterion: A model-learned mechanism that decides when to stop iterative computation based on the current state. "The iterative updates can be combined with a learned stopping criterion, enabling adaptive computation time and dynamic control over the number of reasoning steps per task instance."
- mixed-integer optimization (MIP) solvers: Optimization solvers for problems with both integer and continuous variables, often used in combinatorial settings. "such as SAT, constraint programming (CP), and mixed-integer optimization (MIP) solvers"
- MSA-Transformer: A transformer variant that attends along multiple dimensions of multiple-sequence alignments, modeling dependencies across sequences and residues. "The MSA-Transformer \citep{rao2021msa} employs an attention operation in sequence and another attention operation in residue direction for multiple-sequence alignments of different protein sequences."
- NP-hard: A class of problems at least as hard as the hardest problems in NP; no known polynomial-time algorithms exist for them. "solving generalized Sudoku is NP-hard \citep{yato2003complexity}"
- permutation equivariance: A property where permuting inputs results in the same permutation applied to outputs, preserving structure under symmetry. "which enforce permutation equivariance at the architectural level"
- positional embeddings: Learned or deterministic vectors added to token representations to encode position information for attention models. "Positional embeddings (e.g., RoPE, \citet{su2024roformer}), can be added to the tokens $\Be_i$ to enable attention-based operations to reason about the relative positions and relationships of symbols within the domain."
- Recurrent Reasoning Models (RRMs): A family of architectures that perform multi-step reasoning via recurrent updates to a latent state, producing intermediate outputs. "The structured problem solving architecture family of Recurrent Reasoning Models (RRMs), including Hierarchical Reasoning Model (HRM) and Tiny Recursive Model (TRM), offer a compact alternative to LLMs, but currently handle symbol symmetries only implicitly via costly data augmentation."
- RMSNorm: Root Mean Square Layer Normalization, which normalizes activations by their root-mean-square without centering. "As for vanilla RRMs, RMSNorm \citep{zhang2019root} is used as a normalization layer,"
- RoPE: Rotary position embeddings; a positional encoding method that rotates query/key vectors to encode relative positions in attention. "Positional embeddings (e.g., RoPE, \citet{su2024roformer}), can be added"
- SAT: Boolean satisfiability problem; deciding if there exists an assignment of boolean variables that satisfies a logical formula. "such as SAT, constraint programming (CP), and mixed-integer optimization (MIP) solvers"
- self-attention: A mechanism where each token attends to all others (including itself) to compute contextualized representations. "The first are self-attention layers \citep{vaswani2017attention},"
- stablemax: A softmax-like activation designed to improve numerical stability or robustness when converting logits to probabilities. "A softmax activation function, or a similar function such as stablemax, is applied to these logits,"
- SwiGLU: A gated MLP activation (Switch-GLU) that improves transformer feed-forward layers by combining linear transformations with gated non-linearities. "specifically SwiGLU modules \citep{shazeer2020glu},"
- symbol equivariance: Equivariance with respect to permutations of symbols (e.g., digits or colors), ensuring outputs transform consistently under symbol re-labelings. "A key limitation of existing recurrent reasoning models (RRMs) is the lack of explicit symbol equivariance."
- Tiny Recursive Model (TRM): A compact RRM variant that recursively applies a small transformer block for iterative reasoning. "Tiny Recursive Model (TRM) \citep{jolicoeur2025less}"
- Wilson score confidence intervals: A method for binomial proportion confidence intervals with better coverage properties than the normal approximation. "with 95\% Wilson score confidence intervals."
Collections
Sign up for free to add this paper to one or more collections.