Tiny Recursive Reasoning with Mamba-2 Attention Hybrid
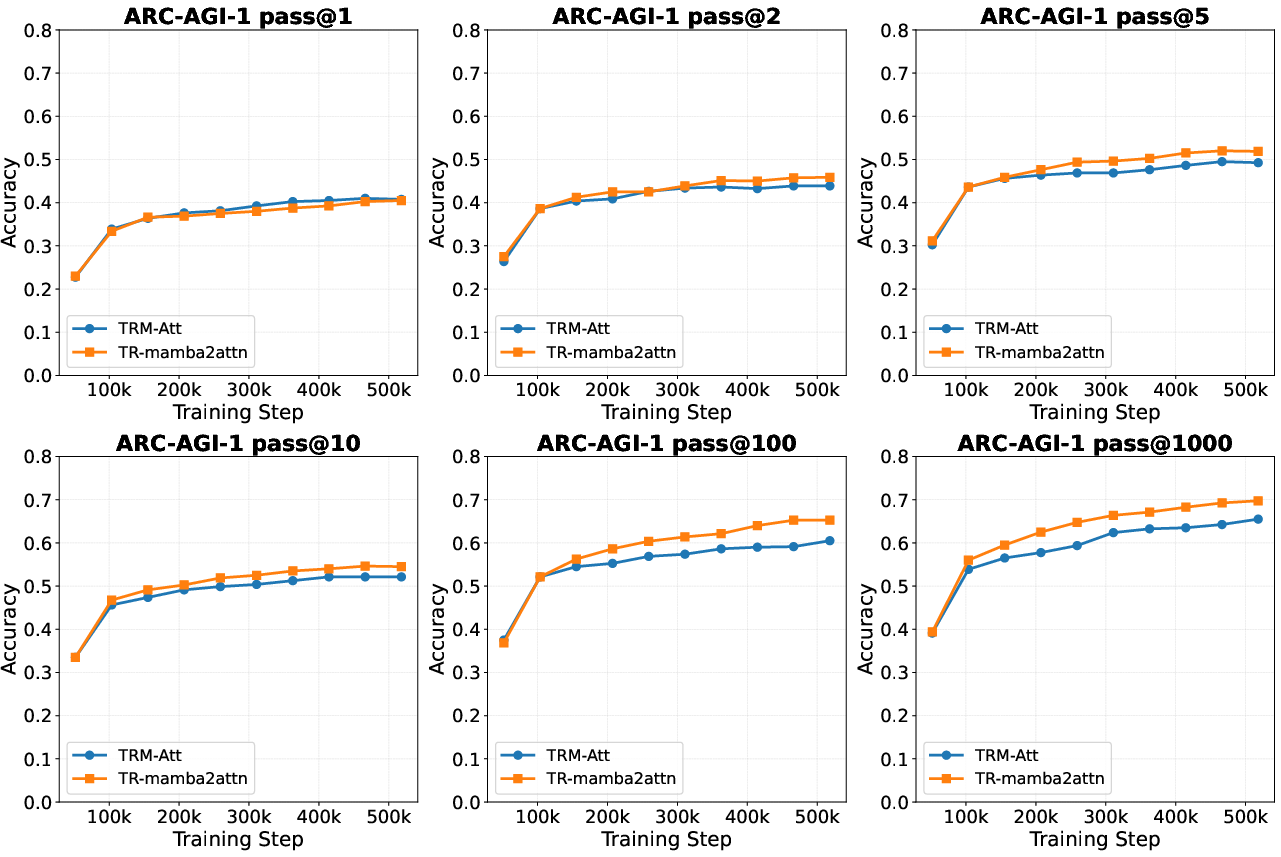
Abstract: Recent work on recursive reasoning models like TRM demonstrates that tiny networks (7M parameters) can achieve strong performance on abstract reasoning tasks through latent recursion -- iterative refinement in hidden representation space without emitting intermediate tokens. This raises a natural question about operator choice: Mamba-2's state space recurrence is itself a form of iterative refinement, making it a natural candidate for recursive reasoning -- but does introducing Mamba-2 into the recursive scaffold preserve reasoning capability? We investigate this by replacing the Transformer blocks in TRM with Mamba-2 hybrid operators while maintaining parameter parity (6.83M vs 6.86M parameters). On ARC-AGI-1, we find that the hybrid improves pass@2 (the official metric) by +2.0\% (45.88\% vs 43.88\%) and consistently outperforms at higher K values (+4.75\% at pass@100), whilst maintaining pass@1 parity. This suggests improved candidate coverage -- the model generates correct solutions more reliably -- with similar top-1 selection. Our results validate that Mamba-2 hybrid operators preserve reasoning capability within the recursive scaffold, establishing SSM-based operators as viable candidates in the recursive operator design space and taking a first step towards understanding the best mixing strategies for recursive reasoning.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper studies how very small AI models can “think” better by looping through their thoughts multiple times before giving an answer. It looks at a new way to build these tiny models using a piece called “Mamba-2” mixed with attention. The main goal is to see if swapping the usual Transformer blocks for a Mamba-2 + attention mix keeps—or improves—the model’s ability to solve tricky puzzles, like those in the ARC-AGI reasoning benchmark.
The Big Questions
The paper focuses on two simple questions:
- Can tiny models reason well by thinking in loops, even without writing out step-by-step explanations?
- If we replace the usual attention-based blocks with a Mamba-2 hybrid (which processes information step-by-step very efficiently), does the model get better at finding correct answers?
How the Model Thinks (Methods)
Think of the model as having two levels of “inner thoughts”:
- A high-level plan (): the big picture of how to solve the puzzle.
- A low-level plan (): the details that change minute to minute.
The model updates these inner thoughts in cycles (like going over a draft a few times), but it doesn’t speak its steps out loud. This is called latent recursion—meaning the model does its reasoning inside, silently, by refining hidden states again and again.
What changed in this paper:
- The original tiny model (TRM) used Transformer attention blocks to update these inner thoughts.
- The new model swaps those blocks for a Mamba-2 + attention hybrid operator. Mamba-2 processes sequences in a fast, step-by-step way (like reading a sentence one word at a time, remembering what matters, and forgetting what doesn’t), while attention adds the ability to look across the whole puzzle grid in both directions.
Why that matters:
- Attention is good at connecting distant parts of a sequence instantly (like jumping around a page).
- Mamba-2 is good at streaming information efficiently (like reading line-by-line with a smart memory).
- Combining them aims to keep strong reasoning while speeding up and diversifying the model’s internal “thinking.”
To make the comparison fair, both models are almost the same size (about 6.8 million parameters). This way, any improvement is likely due to the operator change, not just a bigger model.
A crucial detail: the model uses “post-norm,” which is like turning the volume back to a safe level after each thinking loop. Without this, repeated loops can make the internal signals blow up and crash (like turning your speakers louder every time you replay a song until they break).
What They Tested
They tried the models on three types of puzzles:
- ARC-AGI-1: Abstract visual puzzles with colored grids. The model makes many guesses per puzzle by viewing rotated or recolored versions (called augmentations), then votes on the best final answer.
- Sudoku-Extreme: Standard 9×9 Sudoku.
- Maze-30×30-Hard: Find a path through a big maze.
To judge how often the model includes the correct answer in its top guesses, they use pass@K:
- pass@1: The correct answer is the top guess.
- pass@2: The correct answer is within the top 2 guesses (the official ARC-AGI score, because some puzzles genuinely need 2 guesses).
- Higher K (like pass@100) means “Did the correct answer show up anywhere among lots of guesses?”
Main Results
Here are the key findings, explained simply:
- ARC-AGI-1 puzzles:
- The Mamba-2 hybrid improves pass@2 by about +2 percentage points (from 43.88% to 45.88%).
- At higher K values (like pass@100), the improvement gets bigger (about +4.75 points).
- pass@1 stays about the same between models, meaning both pick their top guess similarly well.
- What this suggests: the hybrid makes a better variety of guesses, increasing the chance the correct answer is somewhere in its candidate list (better coverage), without hurting the model’s ability to choose the best one for its first guess (selection).
- Sudoku-Extreme:
- Models that use dense, all-to-all mixing (MLP-t variants) do best here, reaching around 87.4% accuracy.
- The attention and Mamba-2 hybrid versions are weaker on Sudoku.
- Why? Sudoku on a small fixed grid benefits from very strong, direct connections across all cells at once.
- Maze-30×30-Hard:
- The MLP-t variants fail completely on this larger grid task.
- The Mamba-2 + attention hybrid does much better (about 80.6%), beating the attention-only version (about 60.8%).
- Training was unstable, so exact numbers varied, but the pattern was clear: different tasks need different mixing strategies.
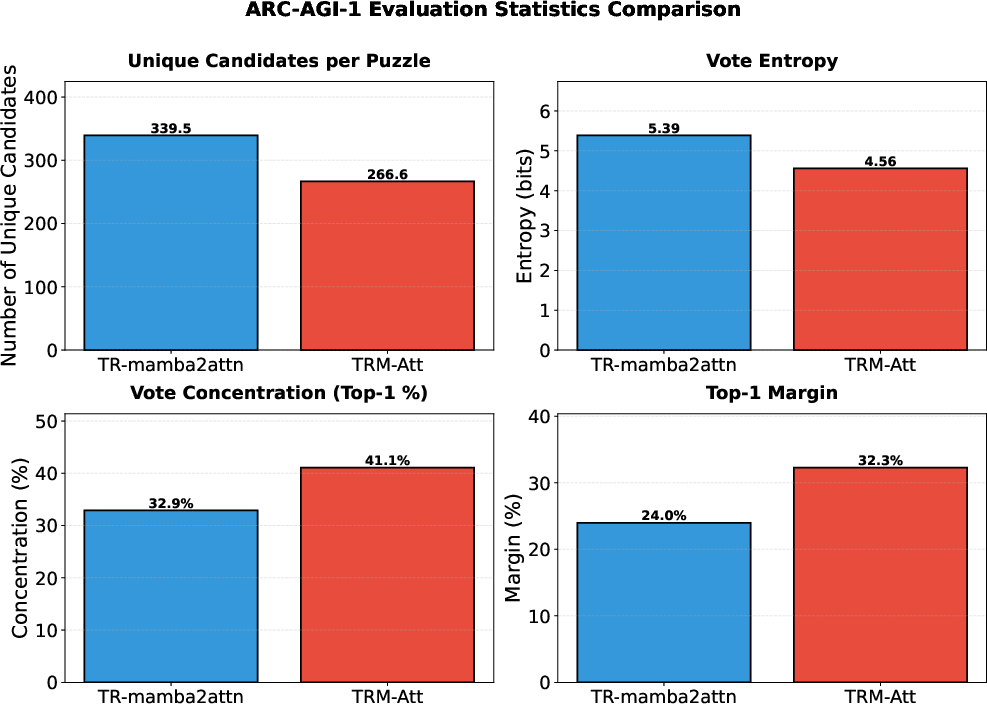
In ARC-AGI, they also found a “coverage vs selection” trade-off:
- The hybrid creates more diverse candidate answers (more unique ideas), so it’s more likely to include the correct one somewhere among its guesses.
- The attention-only model concentrates votes more strongly on its top pick, which can be good when the correct answer is already obvious.
Why It Matters
This paper shows that:
- Tiny models can reason well if they get more “thinking time” at test time by looping through internal states (latent recursion), not just by growing huge.
- Swapping in Mamba-2 (with attention to keep full-grid communication) preserves and even improves reasoning on puzzles like ARC-AGI—especially for making sure the correct answer appears somewhere in the model’s candidate list.
- Different tasks benefit from different mixing styles:
- Small grids with strict constraints (Sudoku) prefer dense, all-to-all mixing (MLP-t).
- Large spatial tasks (Maze) benefit from efficient sequential processing plus attention.
- The finding encourages exploring how state space models like Mamba-2 can be mixed into recursive reasoning systems, potentially making them faster and more flexible.
Simple Takeaways
- Thinking in loops helps tiny models solve complex puzzles—even without writing out step-by-step explanations.
- Mamba-2 + attention is a strong combo for recursive reasoning: it improves the chance of including the correct solution across many guesses.
- Post-norm is essential so the model’s repeated “thinking passes” stay stable.
- There’s no single best architecture for all tasks—choose mixing strategies based on the puzzle’s shape and size.
- This work is a first step toward smarter, faster tiny models that think internally and efficiently, potentially making reasoning more accessible without huge model sizes.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Compute-normalized evaluation is absent: no measurements of FLOPs per forward pass, latency, memory footprint, throughput, or energy on common hardware, despite efficiency claims for Mamba-2.
- Statistical reliability is unclear: results are reported largely from single runs/checkpoints without multi-seed means, confidence intervals, or significance testing for the +2.0 pp pass@2 gain.
- Training instability is noted (Maze high variance) but not addressed: no analysis of causes, stabilizing techniques, or run-to-run variability quantification.
- FLOPs parity is not established: parameters are matched, but operator-level compute (FLOPs), memory bandwidth, and runtime differ; comparisons may conflate architectural benefits with compute discrepancies.
- Hybrid design space is underexplored: no ablation over the number, ordering, and proportions of Mamba-2 vs attention/MLP-t blocks, gating strategies, or residual routing choices.
- Pure SSM baselines are missing: no evaluation of pure Mamba(-2) with bidirectional or multi-pass scans (e.g., forward+backward sweeps, chunked or multi-orientation scans) to test whether attention is strictly necessary.
- 2D/state-space variants are not studied: no exploration of 2D SSMs, multi-scan raster orders (raster vs serpentine vs Hilbert), or multi-head/state SSMs that could capture bidirectional grid dependencies.
- Outer–inner recurrence interaction is not probed: it remains unknown whether, and how, Mamba’s inner recurrence can internalize or replace the outer-loop recursion; the paper leaves this as future work.
- Mamba state handling across loops is unspecified: do SSM states reset or persist across inner/outer cycles? The effect of state persistence vs reset on reasoning quality is unexplored.
- Adaptive computation (Q-halt) is introduced but not analyzed: no report on step distributions, halting calibration, accuracy-speed trade-offs, or ablations with/without halting.
- Post-norm “essential for recursion stability” is asserted without ablation: no direct pre-norm vs post-norm comparisons across depths/operators with quantified stability and performance impacts.
- Coverage vs selection mechanism is hypothesized but not causally tested: no controlled interventions (e.g., entropy regularization, diversity penalties/bonuses, reranking schemes) to validate that Mamba-2 specifically drives candidate diversity.
- Aggregation and augmentation dependence is untested: results rely on ~880× dihedral/color augmentations and a fixed vote-based aggregator; no ablation of augmentation count/types, alternative aggregators, or diminishing-returns curves.
- Pass@K to pass@1 conversion is unaddressed: given improved coverage, can learned reranking, calibration, or meta-solvers convert the hybrid’s broader candidate set into higher pass@1?
- Task breadth and modality generality are limited: only ARC-AGI-1, Sudoku-9×9, and Maze-30×30 are tested; no ARC-AGI-2 evaluation, no language/math/code reasoning, and no cross-modality studies.
- ARC-specific diagnostics are missing: no per-concept ARC breakdown, error taxonomy, or qualitative examples to understand which puzzle types benefit from the hybrid.
- Grid-size scaling is unclear: MLP-t’s success on 9×9 Sudoku vs failure on 30×30 Maze is observed but not explained; scaling curves with grid size and complexity are not provided.
- Recursion-depth scaling and test-time compute scaling are not characterized: no curves for varying outer/inner steps (H, L), inference-time iteration counts, or anytime/incremental performance for the hybrid vs baseline.
- Input representation sensitivity is not studied: no ablations on grid encoding, tokenization, channel design, or positional schemes and their interactions with SSM vs attention.
- Comparative breadth of backbones is narrow: no comparisons to other lightweight/state-space models (e.g., S4, Hyena, RWKV) at the same scale to disentangle Mamba-specific from SSM-general effects.
- Data/sample efficiency is unreported: no analysis of learning curves, data efficiency, or convergence speed differences between attention and hybrid operators.
- Reproducibility details are incomplete: missing or minimal hyperparameters, optimizer configs, training schedules, compute budget, and code/model release; results may be hard to replicate.
- Robustness and distribution shift are untested: no evaluation under novel color palettes, non-dihedral transforms, noise, occlusion, or adversarial perturbations to assess stability of the coverage gains.
- Cross-augmentation state usage is unexplored: states appear independent per augmentation; it is unknown whether amortized or shared-state strategies across augmentations could further boost coverage or selection.
- Theoretical/mechanistic understanding is lacking: no mechanistic interpretability or analysis of how Mamba-2 alters latent trajectories to increase candidate diversity; the source of the coverage gain remains opaque.
- Parameter-scaling laws are unknown: results at ~7M parameters only; it is unclear whether hybrid advantages persist, shrink, or grow at 1M, 20M, 100M+ parameter scales.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, leveraging the paper’s findings on tiny latent-recursive models and Mamba-2 hybrids, the coverage-vs-selection insight, and the augmentation-plus-voting workflow.
- Software/Developer Tools: Multi-candidate code generation with verifier-in-the-loop
- Description: Use a small TR-mamba2attn model to generate diverse candidate code solutions rapidly, then select the correct program via unit tests, linters, or static analysis. The hybrid’s improved pass@K (coverage) helps surface correct solutions more reliably.
- Potential tools/products/workflows: “Lightweight Reasoner” microservice that produces N candidates; CI pipeline plugs in unit-test-based selection; SDK exposing pass@K knobs and a “thinking time” slider for inference loops.
- Dependencies/assumptions: Robust test suites or verifiers must exist; transfer from ARC-like tasks to code requires task-specific finetuning; coverage advantage is most useful when a reliable external checker selects the winner.
- Operations Research/Enterprise Planning: Constraint satisfaction via diverse candidate sets
- Description: For scheduling (shifts, rooms, deliveries) and resource allocation, use TRM-mlp-t or TR-mamba2mlpt variants (which excelled on Sudoku) to produce candidate schedules; select via a constraint solver or rule engine.
- Potential tools/products/workflows: Hybrid ML+OR pipeline; candidate generation API feeding OR tools (CP-SAT, MILP) to validate/score; dashboard tracking candidate diversity and final feasibility.
- Dependencies/assumptions: Domain constraints must be formally specified and verifiable; model needs task adaptation; MLP-t’s strengths on small fixed grids may not scale to larger problem sizes without careful tuning.
- Robotics/Embedded: On-device pathfinding and planning on small maps
- Description: Use TR-mamba2attn for real-time pathfinding on constrained grids (Maze-like scenarios), benefiting from the tiny parameter count and efficient test-time computation.
- Potential tools/products/workflows: Embedded planning module with adjustable recursion depth; safety wrapper verifying path validity; fallback to classical algorithms when confidence is low.
- Dependencies/assumptions: Reported maze training variance suggests careful model selection/checkpointing; requires grid-like representations; larger spatial maps may need attention hybrids rather than MLP-t.
- Product UX/Consumer Apps: Ambiguity-aware suggestions with top-2 presentation
- Description: In ambiguous tasks (form autofill, template selection, personalization), present top-2 outputs (inspired by ARC’s official pass@2 metric) to improve user success.
- Potential tools/products/workflows: “Top-2 chooser” component backed by hybrid latent recursion and an aggregation layer; A/B testing to calibrate K for best UX.
- Dependencies/assumptions: User interfaces must handle multiple suggestions gracefully; the model’s ranking must be paired with lightweight human verification.
- Data Engineering/ETL: Candidate transformations with voting-based aggregation
- Description: Adopt the paper’s augmentation-and-voting protocol for data cleaning/transformation (e.g., column type inference, missing value imputation). Generate many candidate mappings and select via a scoring function.
- Potential tools/products/workflows: ETL augmentation library (analogs to dihedral/color transforms: schema permutations, type casts, normalization variants); scoring functions for consistency and downstream task accuracy; entropy-based diversity monitoring.
- Dependencies/assumptions: Requires well-designed augmentations and reliable scoring; feasibility depends on the task’s ability to be formalized into verifiable transformations.
- Cost-Efficient Reasoning in LLM Products: “Tiny reasoner” pre-filter
- Description: Use TR-mamba2attn to cheaply generate diverse options and prune obvious failures before invoking large models, cutting inference costs while maintaining accuracy.
- Potential tools/products/workflows: Cascade architecture (tiny hybrid model → verifier → big model fallback); pass@K tuning and adaptive compute (Q-halt signal from TRM).
- Dependencies/assumptions: Requires tight integration and latency budgeting; task alignment between tiny and large model domains; verifiers to select/prune candidates.
- Education/Games: Offline puzzle assistants (Sudoku, logic puzzles)
- Description: Deploy Sudoku solvers with MLP-t variants on mobile devices; offer step-by-step hints or final answers without a network connection.
- Potential tools/products/workflows: Mobile SDK with puzzle solver; candidate diversity meter to generate alternative hint paths; teacher dashboards to craft practice sets.
- Dependencies/assumptions: Generalization beyond Sudoku requires additional data and finetuning; interpretability of latent reasoners is limited (no CoT text).
- Academic Tooling: Coverage-vs-selection diagnostics and pass@K dashboards
- Description: Adopt the paper’s metrics (vote entropy, unique candidate count, top-1 margin) to diagnose model behavior in candidate-set generation tasks.
- Potential tools/products/workflows: Evaluation suites that track coverage/selection trade-offs; difficulty stratification tools; training-time curves for pass@K.
- Dependencies/assumptions: Requires model outputs to be aggregatable into candidate sets; needs standardization across tasks.
Long-Term Applications
These applications require further research, scaling, domain adaptation, or engineering work to reach production-grade reliability.
- General-Purpose On-Device Reasoning Assistants
- Description: A small, efficient assistant that solves diverse reasoning tasks (planning, math, data wrangling) locally using latent recursion and Mamba-2 hybrids.
- Potential tools/products/workflows: Reasoning OS layer in mobile/IoT; adaptive compute budget settings; verifier plugins per task domain.
- Dependencies/assumptions: Robust transfer beyond grid tasks; on-device verifiers; broad task libraries; privacy and safety constraints.
- Code Assistant with Multi-Candidate Generation and Automated Selection
- Description: A “lightweight coder” that proposes many solutions rapidly and chooses via tests, reducing reliance on large models for routine programming.
- Potential tools/products/workflows: IDE integration; batched candidate generation and test execution; coverage-tuned inference loops; telemetry to learn from failures.
- Dependencies/assumptions: High-quality test coverage; task-specific training; handling complex codebases; security sandboxing for test execution.
- Task-Aware Mixer Selection Platform (Attention vs MLP-t vs SSM Hybrid)
- Description: Automatically select/update operator mixes (attention, MLP-t, Mamba-2) per task characteristics (grid size, constraint density) to optimize accuracy and efficiency.
- Potential tools/products/workflows: Meta-learning or A/B search over mixers; performance predictors; automatic retraining pipelines.
- Dependencies/assumptions: Requires well-defined task taxonomies; significant MLOps investment; careful measurement of training variance and stability.
- Healthcare Decision Support: Candidate treatment plans with guideline verifiers
- Description: Generate diverse treatment options subject to constraints (comorbidities, drug interactions), then validate against clinical guidelines and simulations.
- Potential tools/products/workflows: Verified candidate-set generation; integration with EHRs; simulation-based scoring; human-in-the-loop approval.
- Dependencies/assumptions: Strong, auditable verifiers; regulatory compliance; extensive domain finetuning; rigorous safety evaluation.
- Finance/Risk: Scenario generation with backtesting-driven selection
- Description: Produce multiple trading/risk scenarios and choose via backtesting or stress-testing simulators; leverage hybrid models’ coverage to surface edge cases.
- Potential tools/products/workflows: Risk engines consuming candidate sets; dashboards for scenario diversity and vote entropy; policy governance on model use.
- Dependencies/assumptions: Reliable simulators; robust data; regulatory constraints; careful calibration to avoid overfitting or spurious strategies.
- Energy/Grid Operations: Constraint-respecting dispatch and scheduling
- Description: Generate candidate dispatch plans under grid constraints and select via physics-informed simulators; benefit from efficient test-time compute to explore more candidates.
- Potential tools/products/workflows: ML+simulation co-optimization; fail-safe selection; incident replay for retraining; adaptive compute scheduling.
- Dependencies/assumptions: High-fidelity simulators; domain adaptation; real-time constraints; safety and reliability requirements.
- Policy and Public Sector Planning: Multi-scenario generation for procurement/logistics
- Description: Create diverse policy or logistics plans (routes, supply distribution) and select via cost, fairness, or resilience criteria.
- Potential tools/products/workflows: Scenario generators tied to verifiable objectives; transparent selection dashboards; stakeholder review tooling.
- Dependencies/assumptions: Formalized objectives; trusted evaluation metrics; ethical oversight; task-specific training data.
- Internalizing Outer-Loop Recursion into SSM State Updates
- Description: Research direction to absorb recursive loops into Mamba-like SSMs’ inner recurrence to further reduce compute and improve stability.
- Potential tools/products/workflows: New SSM architectures with built-in “thinking” depth; compute-normalized benchmarks; stability-enhanced normalization schemes.
- Dependencies/assumptions: Significant model innovation; rigorous evaluation across diverse tasks; theoretical and empirical validation of convergence/stability.
- Test-Time Compute Scaling “Reasoning Budget” Feature for APIs
- Description: Commercial APIs offering adjustable “reasoning time” using linear-time SSM hybrids to explore more candidate solutions at controlled cost.
- Potential tools/products/workflows: Pricing tied to recursion depth; pass@K guarantees; auto-select verifiers; monitoring of diversity metrics.
- Dependencies/assumptions: Customer education on coverage vs selection trade-offs; dependable verifiers; platform support for Mamba-2 kernels.
- Safety/Compliance-Focused Latent Reasoning with Verifier Governance
- Description: Apply candidate-set generation to compliance tasks (privacy checks, access control), selecting only verifier-approved outputs.
- Potential tools/products/workflows: Governance layers with audit trails; formal verifiers; kill-switches when coverage indicates uncertainty.
- Dependencies/assumptions: Formal, machine-checkable compliance rules; reliable verifiers; strict audit requirements.
Cross-Cutting Assumptions and Dependencies
- Verifier availability is crucial: The paper’s coverage gains (pass@K improvements) translate best when a reliable external checker or scoring function exists.
- Task transferability: Results are shown on ARC-AGI, Sudoku, and Maze; domain-specific finetuning and representation design are needed for new tasks.
- Mixer choice matters: MLP-t excels at small, dense-constraint grids, while attention hybrids scale better to larger spatial tasks; automated mixer selection is desirable.
- Stability and normalization: Post-norm (RMSNorm) is essential for recursion stability; training variance observed on Maze necessitates careful checkpoint selection and monitoring.
- Augmentation and aggregation: The dihedral/color permutation plus voting protocol is a reusable workflow pattern; effective augmentations and ranking metrics must be crafted per domain.
- Hardware/software support: Efficient Mamba-2 kernels and inference engines are required to realize linear-time benefits at scale; integration into existing MLOps stacks is nontrivial.
Glossary
- Adaptive Computation Time (ACT): A mechanism that allows a model to adaptively decide how many computation steps to perform before halting. "HRM \citep{wang2025hierarchical} originally motivated post-norm for Q-learning convergence stability in their Adaptive Computation Time mechanism."
- Abstraction and Reasoning Corpus (ARC): A benchmark of visual puzzles designed to evaluate abstract reasoning in AI systems. "The Abstraction and Reasoning Corpus (ARC) \citep{chollet2019arc} evaluates abstract reasoning through visual puzzles."
- ARC-AGI-1: A specific evaluation split of ARC used by the ARC Prize, emphasizing general intelligence-style reasoning. "On ARC-AGI-1, we find that the hybrid improves pass@2 (the official metric) by +2.0\% (45.88\% vs 43.88\%)."
- Bidirectional attention: An attention mechanism that allows information flow across all positions in both directions within a sequence. "The original TRM uses bidirectional attention for cross-position communication."
- Bidirectional processing: Processing that allows dependencies to be captured across the entire sequence in both directions, not just causally. "For sequence-to-sequence tasks like Sudoku, Maze, and ARC-AGI, bidirectional processing is essential to capture dependencies across the entire spatial grid."
- Candidate coverage: The degree to which a model’s set of generated candidates includes the correct answer. "This suggests improved candidate coverage---the model generates correct solutions more reliably---with similar top-1 selection."
- Chain-of-thought prompting (CoT): A prompting technique where models generate explicit intermediate reasoning steps to improve problem-solving. "LLMs have excelled in reasoning tasks such as mathematics, code generation, and logical inference through chain-of-thought prompting \citep{wei2022cot}, iterative refinement, and sampling with aggregation \citep{wang2022selfconsistency, yao2023tot}."
- Colour permutations: Systematic remapping of colors in ARC grids to generate augmented inputs. "The evaluation protocol used in TRM expands each test input into 880 augmentations via dihedral transformations and colour permutations."
- Constraint satisfaction: Solving problems defined by variables and constraints, such as Sudoku, by finding assignments that satisfy all constraints. "Sudoku-Extreme: 99 constraint satisfaction puzzles"
- Coverage-vs-selection trade-off: A tension between generating diverse candidate solutions (coverage) and accurately ranking the best one first (selection). "C3: Analysis of pass@K patterns revealing a coverage-vs-selection trade-off: the hybrid improves candidate diversity while maintaining top-1 selection quality."
- Causal processing: Sequential processing in one direction where each position depends only on past positions. "it processes information causally in one direction."
- Cross-position mixing: Mechanisms (attention or dense operations) that explicitly mix information across different positions in a sequence or grid. "explicit cross-position mixing (attention or dense MLP) to capture bidirectional dependencies."
- Dihedral transformations: Symmetry operations (rotations and reflections) applied to grids for data augmentation. "The evaluation protocol used in TRM expands each test input into 880 augmentations via dihedral transformations and colour permutations."
- Hierarchical Reasoning Model (HRM): A small latent-recursion model with separate high- and low-level components for recursive reasoning. "The Hierarchical Reasoning Model (HRM) \citep{wang2025hierarchical} first demonstrated that extremely small models could achieve remarkable performance on abstract reasoning through latent recursion."
- Hybrid operator (Mamba-2 + attention): An update block that combines state space recurrence with attention-based mixing. "We present a TRM variant where Transformer blocks are replaced with a Mamba-2 + attention hybrid operator \citep{gu2024mamba, dao2024mamba2}, parameter-matched to the original."
- Inner recurrence: The inherent recurrent state update inside SSMs (e.g., Mamba) that refines representations over time. "leveraging Mamba's inherent inner recurrence rather than relying solely on outer-loop iteration."
- Iterative refinement: Repeatedly updating a representation to progressively improve a solution or reasoning state. "latent recursion---iterative refinement in hidden representation space without emitting intermediate tokens."
- Latent recursion: Iterative reasoning through hidden states without emitting intermediate tokens. "An emerging alternative is latent recursion: iterative refinement in hidden representation space without emitting intermediate tokens \citep{geiping2025recurrent, saunshi2025looped, hao2024coconut}."
- Looped Transformers: Architectures that reuse a small block multiple times to simulate deeper reasoning via latent thoughts. "\citet{saunshi2025looped} explicitly study
Looped Transformers'' denoted as , where a -layer block is looped times, proving that these loops generatelatent thoughts'' and can simulate chain-of-thought reasoning steps." - Mamba: A selective state space model enabling linear-time sequence modeling with input-dependent dynamics. "Mamba \citep{gu2024mamba} introduces selective SSMs, where model parameters vary with input, enabling the model to selectively propagate or forget information."
- Mamba-2: An efficient SSM variant with simplified recurrence and improved hardware utilization via SSD. "Mamba-2 \citep{dao2024mamba2} simplifies this to (where is a scalar), achieving 2--8 faster training through improved hardware utilization via Structured State Space Duality (SSD)."
- MLP-t: A transposed-sequence MLP block that provides all-to-all cross-position communication without attention. "MLP-t, which operates on the transposed sequence dimension for all-to-all cross-position communication without attention."
- Mixer (sequence mixer): The core operator that mixes information within or across positions in a sequence (e.g., attention, SSM). "Mamba-2 provides an alternative mixer with linear complexity."
- Normalisation placement: The design choice of where normalization is applied relative to residual connections (pre-norm vs post-norm). "A critical implementation detail for recursive models is the normalisation placement."
- Parameter parity: Matching model parameter counts across variants to isolate the effect of architectural changes. "We investigate this by replacing the Transformer blocks in TRM with Mamba-2 hybrid operators while maintaining parameter parity (6.83M vs 6.86M parameters)."
- pass@K: A metric indicating whether the correct answer appears within the top-K ranked predictions. "The pass@K metric measures whether the correct answer appears in the top-K ranked predictions."
- Post-norm: A residual-block design that normalizes after adding the residual, improving stability in deep or recursive settings. "Post-norm resolves this by re-normalising after each residual add:"
- Pre-norm: A residual-block design that normalizes inputs before the residual function, common in modern Transformers. "Modern LLMs typically use pre-norm:"
- Q-halt signal: A learned halting output that controls adaptive computation time in recursive models. "output heads (LM prediction + Q-halt signal for adaptive computation)."
- Q-learning: A reinforcement learning method used here to motivate stability considerations in recursive architectures. "HRM \citep{wang2025hierarchical} originally motivated post-norm for Q-learning convergence stability in their Adaptive Computation Time mechanism."
- Recursion schedule: The plan for how many outer and inner cycles a recursive model executes during inference. "The recursion schedule remains unchanged:"
- Residual connections: Skip connections that add inputs to outputs of blocks; here used with post-norm for stability. "Both use post-norm residual connections (norm{paper_content}add) between components."
- Residual stream magnitude: The scale of the residual signal propagated through repeated updates, which can grow and destabilize recursion. "it bounds the residual stream magnitude across recursive unrolling, preventing divergence."
- RMSNorm: A normalization technique based on root-mean-square that stabilizes training and recursion. "We follow this design and use post-norm (RMSNorm) in all our experiments."
- Selective SSMs: State space models whose parameters are modulated by the input to selectively retain or forget information. "Mamba \citep{gu2024mamba} introduces selective SSMs, where model parameters vary with input, enabling the model to selectively propagate or forget information."
- State Space Models (SSMs): Models that evolve a hidden state via linear recurrences to process sequences efficiently. "State Space Models (SSMs) offer an alternative to attention for sequence modeling, addressing the quadratic complexity of Transformers."
- State space recurrence: The recurrent update rule in SSMs that evolves hidden states over time. "Mamba-2's state space recurrence () is itself a form of iterative refinement"
- Structured State Space Duality (SSD): A theoretical framework connecting transformers and SSMs, enabling efficient algorithms. "achieving 2--8 faster training through improved hardware utilization via Structured State Space Duality (SSD)."
- Token space: Operating with explicit emitted tokens during reasoning, as opposed to latent-state updates. "Most compute-scaling approaches operate in token space, producing visible intermediate steps that can be inspected and verified \citep{wei2022cot, nye2021scratchpads}."
- Top-1 selection: Whether the correct answer is ranked first among predictions; contrasts with broader coverage metrics. "with similar top-1 selection."
- Tree of Thoughts (ToT): A reasoning method that expands multiple solution paths for deliberate problem solving. "Tree of Thoughts \citep{yao2023tot} and scratchpads \citep{nye2021scratchpads} extend this to search and planning."
- Vote entropy: A measure of dispersion or diversity in votes among candidate predictions. "The hybrid generates substantially more unique candidates per puzzle (339.5 vs 266.6, +27\%) with higher vote entropy (5.39 vs 4.56), indicating greater diversity in the candidate pool."
- Winner selection: The process of choosing the top-ranked candidate among predictions, emphasized by low-K metrics like pass@1. "whilst lower K values (especially pass@1) reflect winner selection---whether the aggregation correctly ranks the answer first."
- Quadratic complexity: Computational cost that scales with the square of sequence length, characteristic of standard attention mechanisms. "State Space Models (SSMs) offer an alternative to attention for sequence modeling, addressing the quadratic complexity of Transformers."
Collections
Sign up for free to add this paper to one or more collections.