Simulating Environments with Reasoning Models for Agent Training
Abstract: LLM agents excel in compact environments requiring deep reasoning but remain brittle when operating in broader, more complex contexts that demand robustness across diverse tools and schemas. Building bespoke environments for training is heavy, brittle, and limits progress. In this paper, we demonstrate that LLMs can simulate realistic environment feedback without access to actual testbed data or APIs. Inspired by this capability, we propose two frameworks: Simia-SFT, a pipeline that synthesizes SFT data by amplifying small seed sets into diverse trajectories in an environment-agnostic manner, and Simia-RL, a framework that enables RL training without real environment implementations through LLM-simulated feedback. Fine-tuning open models yields consistent improvements across multiple benchmarks, surpassing GPT-4o and approaching o4-mini on $τ2$-Bench. Together, Simia-SFT and Simia-RL enable scalable agent training without environment engineering, replacing heavy and brittle implementations with flexible LLM-based simulation.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simulating Environments with Reasoning Models for Agent Training — Explained Simply
What is this paper about?
This paper shows a new way to train AI “agents” (smart assistants that can plan, use tools, and complete tasks) without building complicated practice environments. Instead of coding every website, app, or tool they might use, the authors let a LLM pretend to be the environment. Think of it like training a pilot in a flight simulator: the simulation is realistic enough that the pilot learns useful skills, without ever flying a real plane.
What questions are the researchers trying to answer?
The paper focuses on three easy-to-understand goals:
- Can an LLM convincingly pretend to be the apps, tools, and systems an agent would use in real life?
- If yes, can we use this pretend (simulated) world to create lots of good training data?
- Will agents trained this way actually perform better on real tests?
To do this, they introduce two frameworks:
- Simia-SFT: A method to create lots of supervised training examples (step-by-step “how to do the task”) using simulations.
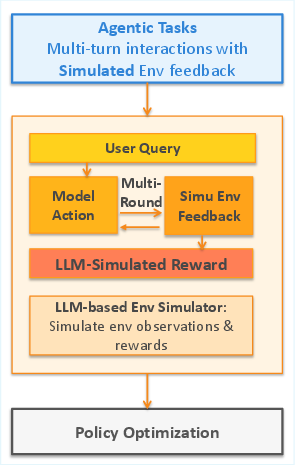
- Simia-RL: A method to do reinforcement learning (learning from trial-and-error) using simulations, including simulated rewards and error messages.
How did they do it? (Methods in plain language)
The main idea: use an LLM to act as both “the world” and “the tools” an agent interacts with.
They do this in two parts.
- Simia-SFT (Supervised Fine-Tuning)
- Start with a few good example tasks (called “seed” examples), like booking a flight, shopping online, or managing calendars.
- Clean the seeds: The LLM checks they make sense, are complete, and follow the right format.
- Write strong prompts: The LLM is told exactly which tools exist, what the rules are, and how answers should look.
- Simulate full conversations: The LLM acts out complete task runs—user asks for something, the agent reasons, calls a tool, and the “environment” (also the LLM) replies with results or errors.
- Fix formatting: Simple rules repair broken JSON or tool calls so the data is clean and usable.
Analogy: It’s like giving a drama class a script outline (tools and rules) and one sample scene (seed). Then the students improvise many believable scenes that follow the rules, and a director tidies up the transcripts afterward.
- Simia-RL (Reinforcement Learning)
- The agent tries to solve tasks step by step.
- The LLM plays two roles:
- Environment: It produces the results of tool calls and realistic error messages.
- Referee: It decides if the task was done correctly and gives a reward (1 for success, 0 for failure).
- The agent learns from this feedback and improves its policy.
Analogy: Imagine practicing customer support. A coach pretends to be the customer (environment), reacts to what you say, and at the end scores how well you solved the problem (referee).
Key terms explained:
- Trajectory: The full record of a task from start to finish, including thoughts, tool calls, and results—like a play-by-play highlight reel.
- Tool/API: A function the agent can call, such as “search flights,” “add to calendar,” or “buy item.”
- SFT (Supervised Fine-Tuning): Teaching the model by showing it lots of correct examples.
- RL (Reinforcement Learning): Letting the model try, fail, get feedback, and try again.
What did they find? Why does it matter?
The results show that models trained using simulated data performed strongly across several challenging tests:
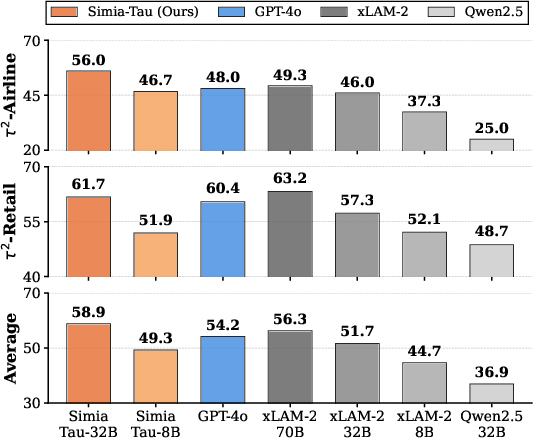
- On τ2-Bench (Airline and Retail tasks):
- Their 32B model (Simia-Tau, based on Qwen2.5-32B) beat GPT-4o and even outperformed a 70B open baseline (xLAM-2-70B), getting close to o4-mini.
- Their 8B model beat a larger open baseline on Airline and Retail.
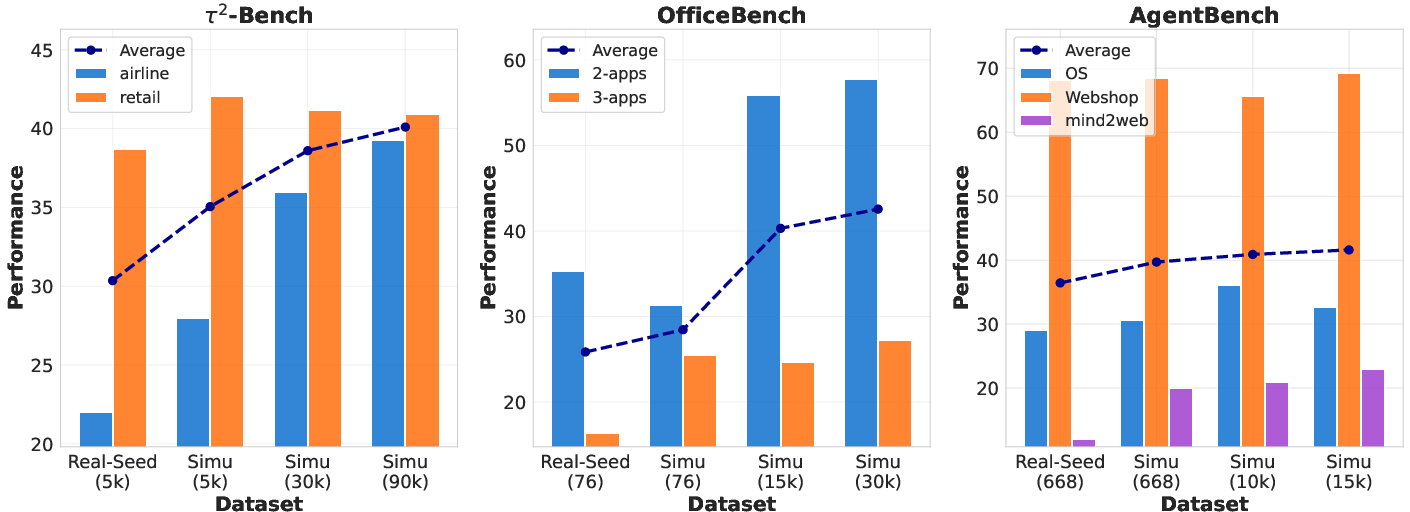
- On OfficeBench (multi-app office tasks):
- Their fine-tuned 7B–8B models significantly improved over standard baselines and even beat GPT-4 in average score for some settings.
- Doing RL in the simulated environment sometimes helped more than RL in the real environment because the simulator gave richer, clearer feedback when things went wrong.
- On AgentBench (web browsing, shopping, operating system tasks):
- Their models were competitive with GPT-4 and GPT-4o and clearly better than many open baselines, especially on WebShop and OS tasks.
- Data quality and scale:
- When they trained on the same amount of data, simulated data performed as well as—or better than—data collected from real environments.
- As they generated more simulated data, performance kept improving. This shows simulations can scale up cheaply and quickly, while real environment data is costly and slow to collect.
Why this matters:
- You don’t need to build every app, website, or tool just to train an agent.
- You can create lots of realistic practice experiences using LLMs as simulators.
- Training becomes faster, cheaper, and easier to adapt to new domains.
What could this change in the future? (Implications)
- Faster progress: Teams can train robust agents without months of building and maintaining custom environments.
- Broader coverage: It’s easier to cover many tools and edge cases by simulating them.
- Better learning signals: Simulated environments can give detailed, helpful error messages that guide the agent to improve.
- Practical impact: This could speed up building assistants for office work, online shopping, travel bookings, and more everyday tasks.
A few cautions:
- Simulations can introduce bias if they don’t perfectly match real-world behavior.
- The paper mostly tested certain domains (airline, retail, web, office). More areas still need exploration.
In one sentence
The paper shows that using LLMs to simulate tools and environments is a powerful, scalable way to train AI agents—making them more reliable on real tasks without the heavy cost of building complex, real-world test systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Real-world transfer without simulators: No end-to-end evaluation of agents trained on simulated trajectories interacting with live APIs and production environments to quantify transfer gaps and failure modes.
- Simulator fidelity metrics: Lacks formal measures of how closely LLM-simulated environment feedback matches real environment dynamics (error codes, latencies, rate limits, state transitions, tool side effects).
- Distribution shift sensitivity: Unclear robustness when tool schemas, policies, or environment implementations change; no experiments on schema drift, versioning, or unseen tools.
- Reward reliability and calibration: Binary LLM-judged rewards (0/1) are not validated for consistency across models or annotators; no inter-rater agreement or calibration against human judgments.
- Reward shaping and granularity: No exploration of dense or shaped rewards (partial credit, progress signals, penalties) and their effect on sample efficiency and policy quality.
- Reward hacking risk: No analysis of whether agents exploit systematic weaknesses in the simulated environment/reward to game success (e.g., prompt exploitation, shortcut behaviors).
- Human realism of trajectories: No human evaluation of simulated trajectory realism and plausibility (e.g., agent behaviors, user actions, tool outputs) beyond benchmark scores.
- Semantic correctness of tool calls: Post-processing repairs JSON/formatting but does not verify semantic correctness (e.g., constraints satisfied, prices valid, inventory available).
- Coverage of edge cases: No quantitative analysis of long-tail scenarios (timeouts, partial failures, conflicting constraints, permission/auth errors) or their prevalence in synthetic data.
- Data contamination safeguards: Seed selection and simulator prompts may leak benchmark-specific priors; no audit to ensure test-set integrity and contamination avoidance.
- Open-source-only simulation viability: Main synthesis and RL rely on closed models (GPT-5, o4-mini); no definitive study that comparable results are achievable with open simulators.
- Prompt design sensitivity: No systematic study of how prompt components (tool specs, exemplars, feedback format) affect simulator fidelity, diversity, and downstream performance.
- Stage-wise pipeline ablation: Lacks quantitative attribution of gains to pre-filtering, simulation, and post-processing stages; no removal/addition ablations.
- Dataset diversity and deduplication: No metrics for diversity, redundancy, and near-duplicate rates in synthesized trajectories; absence of explicit dedup procedures or diversity control.
- Scaling laws for simulated data: No analysis of performance scaling with data size (beyond a few points) to identify diminishing returns, optimal mix of domains, or simulator/model size effects.
- Cross-domain generalization: Experiments span limited domains; unclear how the approach extends to finance, healthcare, IoT, robotics, multi-modal tools, or non-English settings.
- Multi-modal and non-text tools: The simulator only models textual feedback; no support or evaluation for image, audio, or UI element interactions typical in real agent environments.
- Real-user interaction robustness: Benchmarks use simulated users; no studies with real users or logs to assess robustness to human variability, ambiguity, and error.
- Online adaptation to environment drift: No mechanism or experiments for continual learning or online adaptation when tool schemas or policies change mid-deployment.
- Error taxonomy and root-cause analysis: No granular error analysis (planning vs. tool calling vs. recovery vs. state tracking) to target improvements.
- Safety, fairness, and bias auditing: No assessment of harmful outputs, bias propagation from simulators, or fairness across user groups, tasks, and languages.
- Compute, cost, and efficiency: Missing reports on data generation/training costs, throughput, hardware, and energy; no comparison of efficiency vs. real-environment data collection.
- RL algorithm breadth and scaling: RL limited to GRPO for 64 steps; no sweeps over algorithms (PPO, DPO variants), horizons, batch sizes, or the effect of longer training.
- Mixed SFT+RL training recipes: Limited exploration of curricula (e.g., pretraining on easy synthetic, fine-tuning on hard real), replay strategies, or offline RL with simulator data.
- Uncertainty estimation and confidence: No calibration metrics (ECE, Brier) or selective prediction strategies for agent decisions under uncertainty.
- Tool concurrency and statefulness: No evaluation for concurrent tool calls, multi-session state management, or transactional consistency across tools.
- Rate limits and operational constraints: Simulators do not model quotas, retries, and backoff policies; unclear how agents behave under realistic operational constraints.
- Robust parsing and execution guarantees: Post-processing enforces syntax only; no formal guarantees for end-to-end executability or recovery from malformed calls in deployment.
- Simulator drift and stability: No study of simulator variability across temperatures, model updates, or prompts; unclear stability of training feedback over time.
- Data provenance and licensing: Seeds and synthesized data policies are not detailed; reproducibility risks if simulator prompts or seed sources change or are restricted.
- Benchmark generalizability: Heavy reliance on a few benchmarks; unclear generalization to broader agent tasks or bespoke enterprise workflows outside benchmark schemas.
Practical Applications
Practical, Real-World Applications
Below are actionable use cases derived from the paper’s findings and methods, grouped by immediacy and mapped to relevant sectors. Each item includes potential tools/products/workflows and key assumptions or dependencies affecting feasibility.
Immediate Applications
- Enterprise agent prototyping without environment engineering
- Sector: software, enterprise IT, RPA
- Tools/products/workflows: “Simulator-as-a-Service” using Simia-SFT to generate multi-turn tool-use trajectories directly from API/tool schemas and a small seed set; plug-ins for CI/CD to validate agent behaviors before connecting to production APIs
- Assumptions/dependencies: Accurate tool specifications and input/output formats; a capable simulator LLM (e.g., o4-mini or similar); post-processing for JSON/tool-call correctness; later validation against real systems
- Synthetic training data for tool-augmented customer support agents
- Sector: retail, travel/airline, telecom, banking customer service
- Tools/products/workflows: Data generation pipelines that expand a few representative tickets into diverse trajectories covering error recovery, state tracking, and edge cases; SFT recipes for small-to-mid-size open models
- Assumptions/dependencies: Representative seed dialogues; coverage of common failure modes; guardrails to prevent simulator-induced bias; privacy policies for using synthetic data in model training
- Multi-app office automation assistant development
- Sector: productivity software, enterprise workflow automation
- Tools/products/workflows: Simia-SFT-generated trajectories for cross-app tasks (Word/Excel/Calendar/Email) and Simia-RL loops to improve error handling; agent integrations into existing suites (e.g., Microsoft 365, Google Workspace)
- Assumptions/dependencies: High-fidelity tool schemas; simulators that can reflect cross-app constraints (file types, scheduling conflicts); resource management for long context windows
- Agent QA and integration testing in CI/CD
- Sector: software engineering, DevOps
- Tools/products/workflows: LLM-simulated environments to stress-test tool invocation, schema adherence, and error recovery; automated checks (format, logic, completeness) and rule-based repairs in pipelines
- Assumptions/dependencies: Deterministic prompt templates for reproducibility; coverage metrics for simulated trajectories; alignment of simulator feedback with real system behaviors
- Privacy-preserving data augmentation
- Sector: healthcare, fintech, public sector
- Tools/products/workflows: Replace or complement real logs with simulated trajectories to reduce PII exposure; audit trails showing synthetic origin for compliance
- Assumptions/dependencies: Legal acceptance of synthetic data in model training; clear separation between real and synthetic artifacts; domain experts validating realism and absence of leakage
- Faster onboarding for new APIs/tools
- Sector: SaaS platforms, API marketplaces
- Tools/products/workflows: Auto-generated “learning kits” (prompts + synthetic trajectories) for tool vendors to publish alongside their schemas; immediate agent tuning without building testbeds
- Assumptions/dependencies: Tool owners provide complete, unambiguous schemas; schema changes tracked and versioned; light human review for safety and correctness
- Enriched error mediation for production agents
- Sector: all sectors using agents in production
- Tools/products/workflows: LLM layer that translates terse system errors into rich, actionable feedback (as shown in OfficeBench case study), improving agent recovery without changing backend systems
- Assumptions/dependencies: Guardrails to avoid hallucinated fixes; clear escalation paths when simulator feedback conflicts with real system; monitoring for unintended behaviors
- Academic coursework and lab kits for agentic LLMs
- Sector: academia, education
- Tools/products/workflows: Teaching modules using Simia-SFT and Simia-RL to let students build and test agents without infrastructure; open datasets and prompts for reproducible assignments
- Assumptions/dependencies: Access to an affordable simulator LLM; curated seed sets per domain; institutional compute resources or cloud credits
- Red-teaming and robustness exercises for agents
- Sector: AI safety, risk, compliance
- Tools/products/workflows: Simulated environments that systematically generate adversarial conditions (schema mismatches, rate limits, stale state) to harden agents via SFT and RL
- Assumptions/dependencies: Domain experts define realistic threat models; measurable robustness criteria (e.g., Passk); periodic retraining as tools evolve
Long-Term Applications
- Unified enterprise “digital twin” for agent training and certification
- Sector: enterprise IT, systems integration
- Tools/products/workflows: Centralized simulation platform reflecting cross-domain tool ecosystems (CRM/ERP/BI), enabling RL training, regression testing, and continuous evaluation before deployment
- Assumptions/dependencies: Ongoing synchronization between simulator schemas and production APIs; governance for change management; standardized reward functions and success criteria across teams
- Regulatory sandboxes for AI agents
- Sector: policy/regulation, public sector, finance
- Tools/products/workflows: Standards bodies define simulator-based compliance tests (privacy, safety, fairness, auditability) for agent certification; formal Passk-like robustness metrics
- Assumptions/dependencies: Regulator acceptance of simulator-based evidence; transparent simulator designs; cross-industry agreement on benchmarks and reporting
- Healthcare agent training with simulated EHR/workflows
- Sector: healthcare
- Tools/products/workflows: Simulated clinical scheduling, documentation, and billing flows to tune assistants while avoiding real patient data; later validation in controlled pilot environments
- Assumptions/dependencies: Clinically accurate schemas; strict safety and reliability thresholds; human-in-the-loop verification; integration with hospital IT policies
- Financial operations assistants for back-office tooling
- Sector: finance, insurance
- Tools/products/workflows: Simulated environments for reconciliation, KYC/AML checks, claims processing; RL to refine error recovery under policy constraints
- Assumptions/dependencies: Detailed policy rules and audit requirements encoded in prompts; conservative reward shaping to avoid risky behaviors; extensive real-world validation
- Autonomous UI agents that generalize across unseen apps
- Sector: software, RPA, low-code/no-code
- Tools/products/workflows: Agents ingest new tool schemas and bootstrap competence via simulated trajectories, reducing environment-specific engineering and speeding adoption
- Assumptions/dependencies: Schema quality and coverage; strategies to mitigate overfitting to simulator artifacts; domain adaptation layers when connecting to real apps
- Continuous self-evolution pipelines (RL + telemetry distillation)
- Sector: software lifecycle, MLOps
- Tools/products/workflows: Combined simulated RL training followed by SFT on selected production telemetry, closing the loop for ongoing improvement; dashboards for drift detection
- Assumptions/dependencies: Safe data handling; robust reward functions; processes to prevent catastrophic forgetting and maintain compliance
- Cross-domain benchmark ecosystems and shared repositories
- Sector: academia, open-source communities
- Tools/products/workflows: Public hubs with tool schemas, prompts, simulated trajectories, and evaluation protocols, fostering reproducible research and rapid iteration
- Assumptions/dependencies: Community curation; licensing clarity; scalable hosting and moderation
- Simulation for robotics and IoT agents
- Sector: robotics, smart infrastructure
- Tools/products/workflows: Extend environment simulation to include sensor/actuator abstractions and failure modes; pre-train planners and controllers before limited real-world trials
- Assumptions/dependencies: Bridging the sim-to-real gap for physical dynamics; hybrid evaluation with hardware-in-the-loop; safety certification requirements
- Cost-efficient dataset creation businesses
- Sector: data services, AI tooling
- Tools/products/workflows: Startups offering domain-specific synthetic data generation (tool use, error recovery, multi-app workflows) with post-processing and validation services
- Assumptions/dependencies: Demonstrated parity or superiority to real logs for target tasks; clear ROI relative to collection/annotation costs; guarantees on privacy and bias controls
- Government workflow automation and public service agents
- Sector: public administration
- Tools/products/workflows: Simulated environments for forms, appointments, benefits processing, and records management, enabling safe pre-deployment training of citizen-facing agents
- Assumptions/dependencies: Strong guardrails and explainability; bilingual/multilingual support; rigorous pilot evaluations and stakeholder oversight
Glossary
- Agentic RL: Reinforcement learning framed around autonomous, tool-using agents. "we propose Simia-RL, an agentic RL framework for RL on LLM-simulated environments"
- Amortized prompt-and-schema design: Treating environment engineering as reusable prompt and data schema design rather than per-environment code. "This reframes environment engineering as an amortized prompt-and-schema design question"
- API invocation: An agent’s act of calling structured interfaces (APIs) to perform actions or retrieve data. "multi-turn API invocation, error recovery, and state tracking."
- CoT (Chain-of-Thought): Explicit step-by-step reasoning traces produced by models. "the behavior leads to excessively long CoT sequences"
- Compositional tool use: Coordinating multiple tools in sequence to accomplish complex tasks. "compositional tool use, and coordination across office utilities."
- Context length: The maximum number of tokens the model can consider in a single prompt-response interaction. "a maximum context length of 60,000 tokens."
- Environment Feedback Simulation: LLM-driven generation of tool outputs and errors in response to agent actions. "Environment Feedback Simulation processes agent actions to produce simulated tool outputs and error messages;"
- Environment-agnostic: Not tied to any specific environment implementation or tool backend. "in an environment-agnostic manner"
- Format Check: Validation of structural and formatting constraints in synthesized trajectories. "Format Check validates structural adherence, including proper role round and correct JSON formatting."
- GRPO: A policy optimization algorithm used for reinforcement learning with LLMs. "We conduct GRPO training followed by SFT"
- Hermes XML style: A structured markup convention for tool call serialization (e.g., XML tags). "by using Hermes XML style (e.g., <tool_call>)"
- LLaMA-Factory: A training framework/tooling for fine-tuning LLMs. "Fine-tuning is conducted with LLaMA-Factory"
- LLM simulator: An LLM used to emulate environment dynamics and feedback during training. "The LLM simulator is prompted to synthesize novel agent trajectories"
- Logic Check: Assessment of consistency in reasoning steps and action sequences. "Logic Check assesses the consistency of reasoning chains and action sequences;"
- Multi-turn: Interactions spanning multiple rounds of agent-user or agent-environment exchanges. "multi-turn interactions within simulated environments."
- Pass{k}: Robustness metric requiring success across k consecutive retries. "Pass^{k} performance comparison on the -Bench across Airline and Retail domains"
- Policy optimization: Improving an agent’s decision-making strategy based on feedback/rewards. "to guide policy optimization."
- Pre-filtering: Automated screening of seed data for quality before synthesis. "LLM-Based Pre-Filtering to validate seed quality"
- RAGEN: An RL framework for multi-turn agent training. "We implement RL experiments using RAGEN built on VeRL"
- Reward Computation: Evaluation that assigns numerical rewards based on task completion criteria. "(2) Reward Computation assesses trajectory completion and assigns reward"
- RL (Reinforcement Learning): Training paradigm using environment interactions and reward signals to optimize behavior. "a framework that enables RL training without real environment implementations"
- Rule-Based Post-Process: Deterministic checks and fixes to ensure trajectories conform to required structure. "Rule-Based Post-Process"
- Seed trajectory: A small, initial example interaction used to bootstrap synthetic generation. "Given a set of seed trajectory"
- Semantic correctness: The degree to which synthesized content is meaningfully accurate, beyond mere format validity. "while remaining bounded by the synthesizer's semantic correctness."
- Simia-RL: The paper’s RL framework leveraging LLM-simulated environments. "we propose Simia-RL, a framework that enables RL training without real environment implementations"
- Simia-SFT: The paper’s pipeline for environment-agnostic supervised fine-tuning data synthesis. "Simia-SFT, a pipeline that synthesizes SFT data by amplifying small seed sets into diverse trajectories in an environment-agnostic manner"
- SFT (Supervised Fine-Tuning): Training an LLM on labeled trajectories to improve performance. "synthesizes SFT data"
- State tracking: Maintaining and updating environment or task state across steps in an interaction. "multi-turn API invocation, error recovery, and state tracking."
- State transitions: Changes in the environment state caused by agent actions. "generate coherent environment dynamics, state transitions, and tool interactions"
- Structural fidelity: Adherence of generated data to required schemas and structural constraints. "enforcing structural fidelity absent from raw synthesizer outputs"
- Temperature: A generation hyperparameter controlling output randomness and diversity. "Trajectory simulation is performed using GPT-5 and o4-mini as synthesizers with temperature 1.0."
- Tool invocation: Executing tools/functions with specified arguments during a trajectory. "including task descriptions, reasoning steps, tool invocations, and environment responses;"
- Tool schemas: Formal specifications describing available tools, their inputs/outputs, and constraints. "more domains with different tool schemas"
- Trajectory synthesis: Automated generation of complete agent interaction sequences for training. "Agent Trajectory Synthesis pipeline"
- User simulator: A model or process that emulates user behavior to interact with agents during evaluation/training. "we use GPT-4.1 as the user simulator (temperature set to 0)"
- VeRL: An RL infrastructure/library used to run training (here, underlying RAGEN). "We implement RL experiments using RAGEN built on VeRL"
- World modeling abilities: An LLM’s implicit knowledge used to simulate plausible environment dynamics. "exploiting their world modeling abilities to generate coherent environment dynamics, state transitions, and tool interactions"
Collections
Sign up for free to add this paper to one or more collections.

