- The paper introduces Environment Tuning, which leverages a structured curriculum, actionable feedback, and fine-grained progress rewards to train multi-turn agents with as few as 400 samples.
- Empirical results highlight significant improvements, with models like Qwen2.5-7B-Instruct jumping from 7.00% to 36.92% accuracy and robust generalization on out-of-distribution tasks.
- Ablation studies confirm that each component—curriculum stages, environment augmentation, and precise reward structuring—is essential for stable learning and to prevent training collapse.
Environment Tuning: A Paradigm Shift for Data-Efficient Multi-Turn Agent Training
Motivation and Problem Setting
The paper addresses the challenge of training LLM-based agents for complex, multi-turn tool-use tasks under severe data scarcity. Existing paradigms—Supervised Fine-Tuning (SFT) on synthetic trajectories and standard Reinforcement Learning (RL)—are shown to be inadequate. SFT leads to overfitting and poor generalization, while RL suffers from cold-start issues and instability due to sparse, uninformative feedback and long-horizon credit assignment problems.
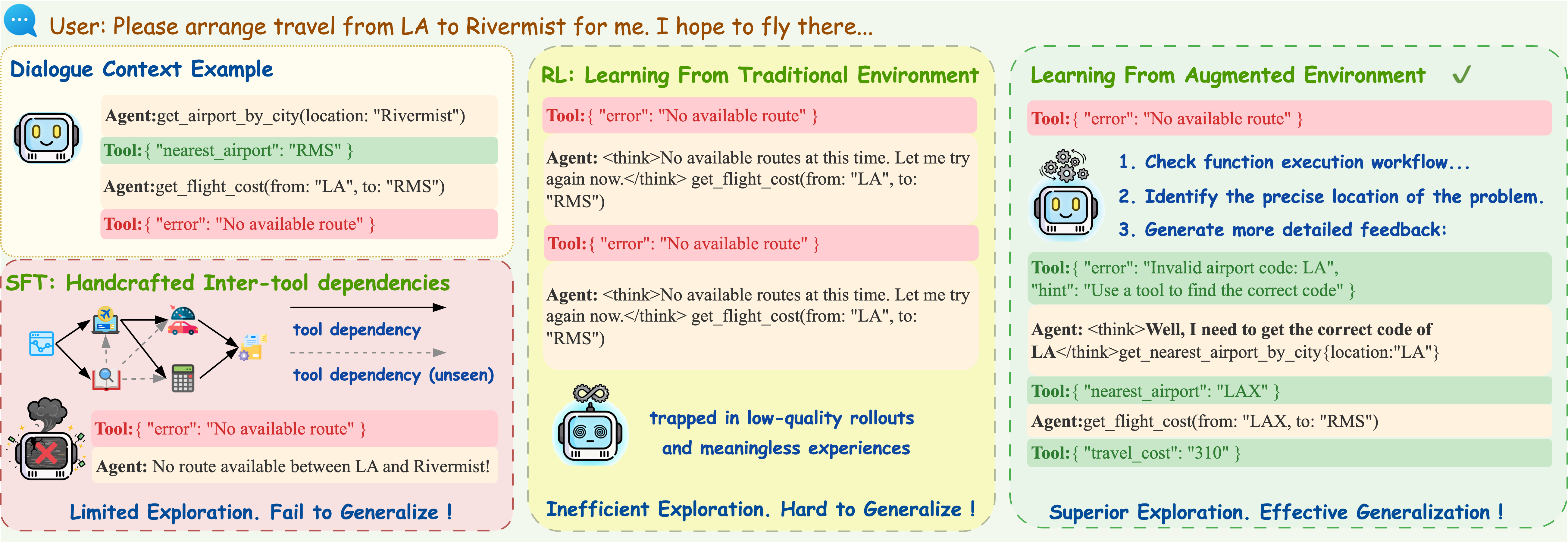
Figure 1: Limitations of SFT and RL for multi-turn tool-use, and the actionable feedback advantage of Environment Tuning.
The core research question is how to enable robust, generalizable agent learning from a minimal set of problem instances, without reliance on expert demonstrations or large-scale synthetic data.
Environment Tuning Framework
The proposed Environment Tuning paradigm orchestrates agent learning through three tightly integrated mechanisms:
- Structured Curriculum: A four-stage progression that decomposes the learning problem, starting from syntactic correctness and culminating in full task generalization.
- Actionable Environment Augmentation: The environment is engineered to provide fine-grained, pedagogical feedback upon failure, transforming ambiguous errors into actionable lessons.
- Fine-Grained Progress Rewards: Dense, turn-level rewards replace sparse, binary signals, enabling effective credit assignment and stable policy optimization.
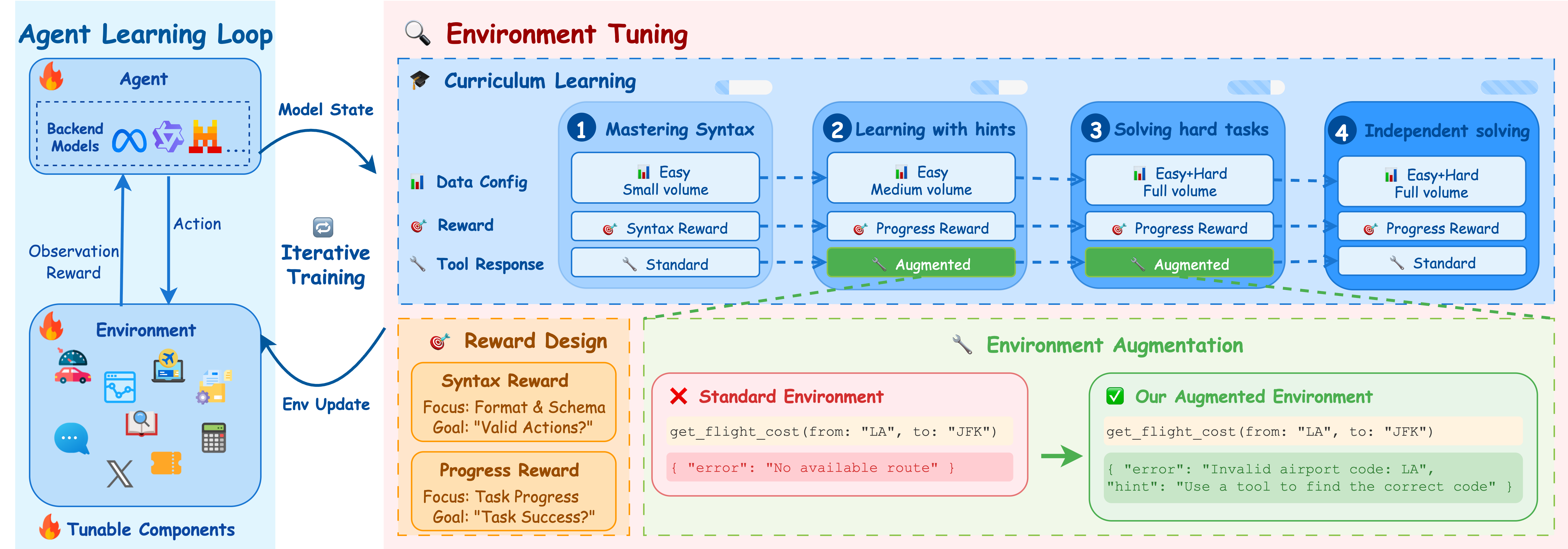
Figure 2: The Environment Tuning module implements a four-stage curriculum, dynamically configuring reward, feedback, and data splits to enable stable, efficient learning.
Curriculum Stages
- Stage 1: Isolates syntactic and schematic correctness, using format and tool-call rewards to ensure the agent can produce valid, parseable actions.
- Stage 2: Introduces task-oriented reasoning with Progress Reward and augmented feedback, focusing on foundational multi-turn capabilities.
- Stage 3: Exposes the agent to the full spectrum of complex scenarios (e.g., missing parameters/functions, long context), maintaining dense rewards and augmented feedback.
- Stage 4: Disables augmentation to align with evaluation conditions, forcing the agent to generalize without scaffolding.
Stage transitions are governed by validation accuracy plateaus and gradient norm stability, preventing premature progression and mitigating RL instability.
Actionable Environment Augmentation
Standard environments return generic or cryptic errors, impeding exploration. The augmented environment provides explicit, context-sensitive hints (e.g., "Invalid airport code[s]:..." or "Paths are not allowed. Specify only file/directory name..."), enabling the agent to infer dependencies and operational constraints through interaction rather than memorization.
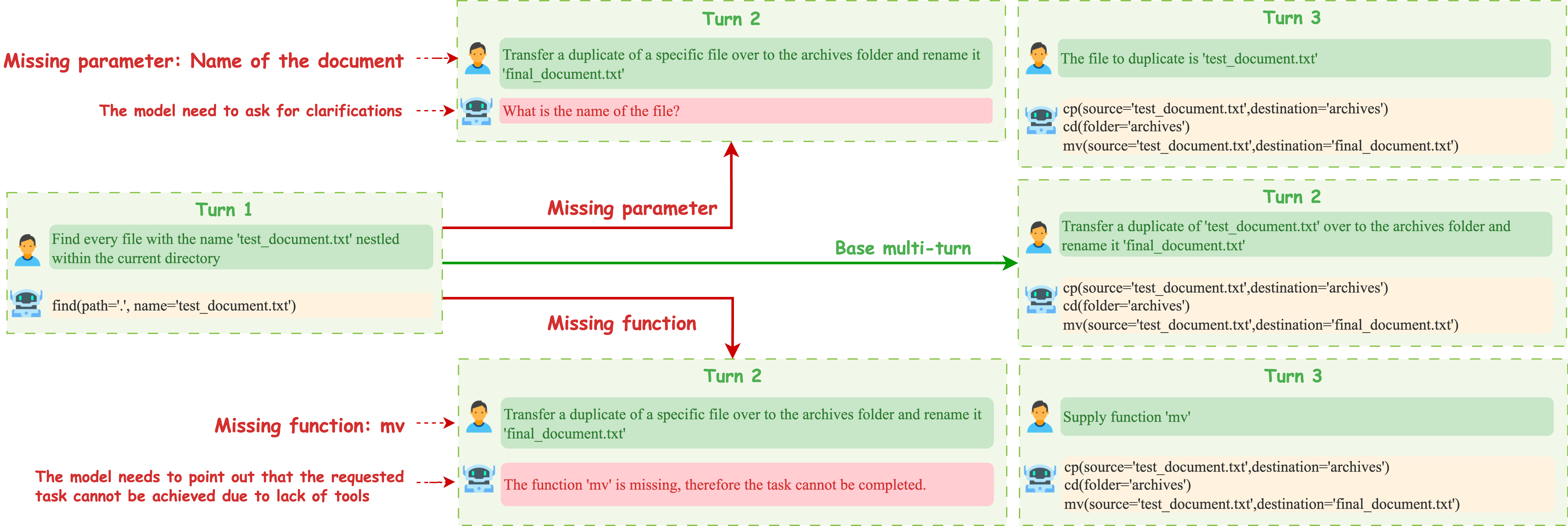
Figure 3: Multi-turn tool-use scenarios from BFCL V3, illustrating the diversity of reasoning and recovery skills required.
Fine-Grained Progress Reward
The reward at each turn is computed as the product of state and execution correctness, averaged over the episode. This dense signal allows the agent to learn from partial successes and supports efficient exploration in long-horizon, multi-turn settings.
Empirical Results
On the BFCL V3 multi-turn benchmark, Environment Tuning delivers substantial improvements across both base and SFT-tuned models, using only 400 training samples:
- Qwen2.5-7B-Instruct: 7.00% → 36.92% (+29.92%)
- Llama-3.1-8B-Instruct: 5.48% → 28.25% (+22.77%)
- watt-tool-8B: 35.74% → 54.34% (+18.50%)
- ToolACE-2-Llama-3.1-8B: 37.99% → 47.18% (+9.19%)
These results surpass several strong open-source and proprietary baselines, demonstrating the method's data efficiency and architecture-agnostic applicability.
Out-of-Distribution Generalization
On OOD tasks (BFCL V4 Web Search/Memory, ACEBench Agent), SFT baselines exhibit severe performance collapse (e.g., xLAM-2: 70.50% → 5.00% on Web Search), while Environment Tuning consistently improves or maintains generalization. For example:
- Llama-3.1-8B-Instruct: 1.00% → 15.00% (Web Search)
- ToolACE-2-Llama-3.1-8B: 9.00% → 14.00% (Web Search), 8.34% → 15.00% (ACEBench Agent)
This demonstrates that environment-driven exploration, rather than trajectory imitation, is critical for robust generalization.
Ablation and Training Dynamics
Ablation studies isolate the contributions of each component:
- Actionable Environment Augmentation: Yields >20% improvement on ambiguous tasks (Missing Parameters/Functions), and stabilizes learning curves.
- Fine-Grained Progress Reward: Essential for complex splits; binary rewards lead to training failure.
- Structured Curriculum: Direct RL (single-stage) leads to rapid gradient explosion and performance collapse after ~70 steps, while the curriculum ensures stable, monotonic improvement.
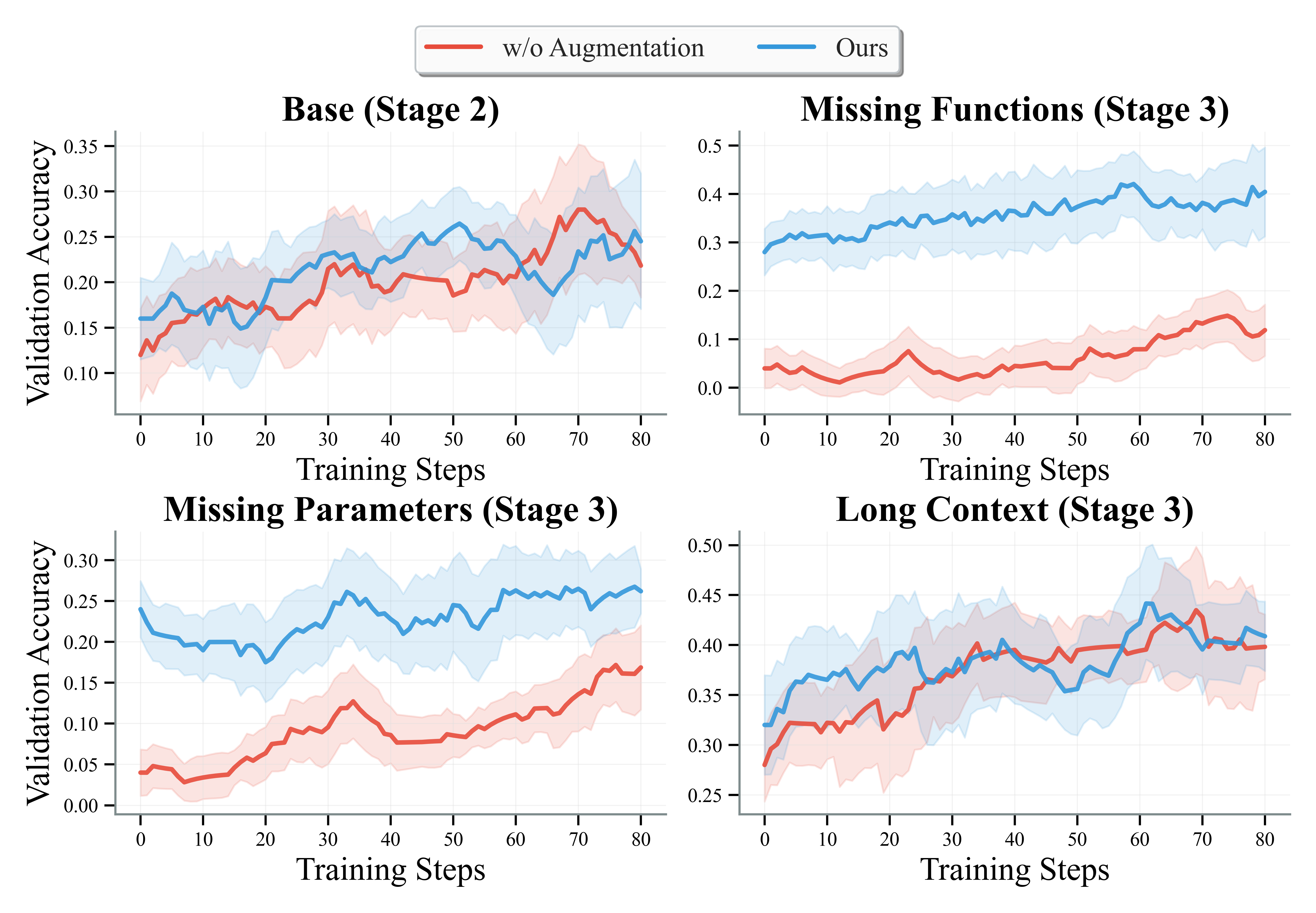
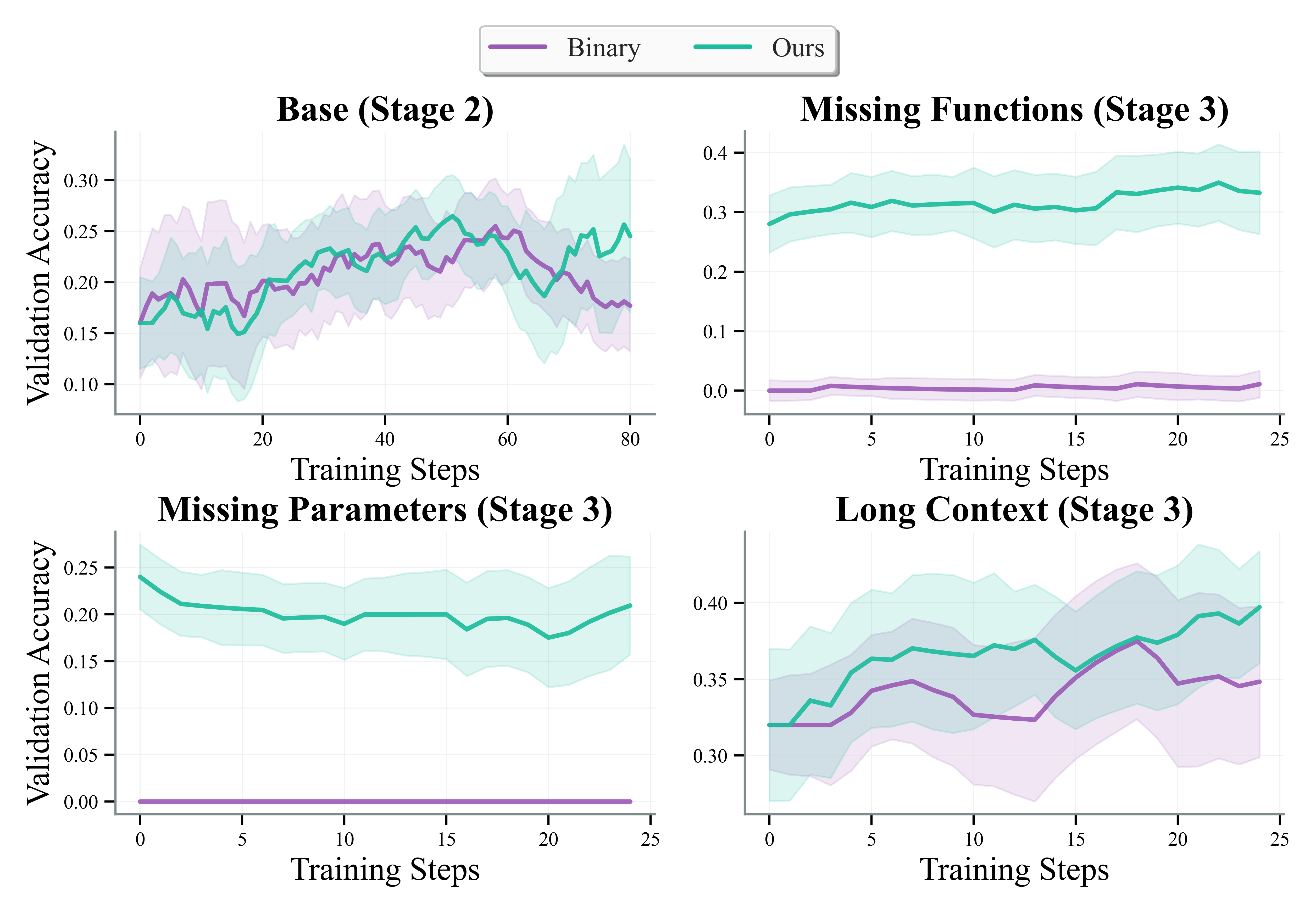
Figure 4: Ablation study for environment augmentation, showing its critical role in stability and performance.
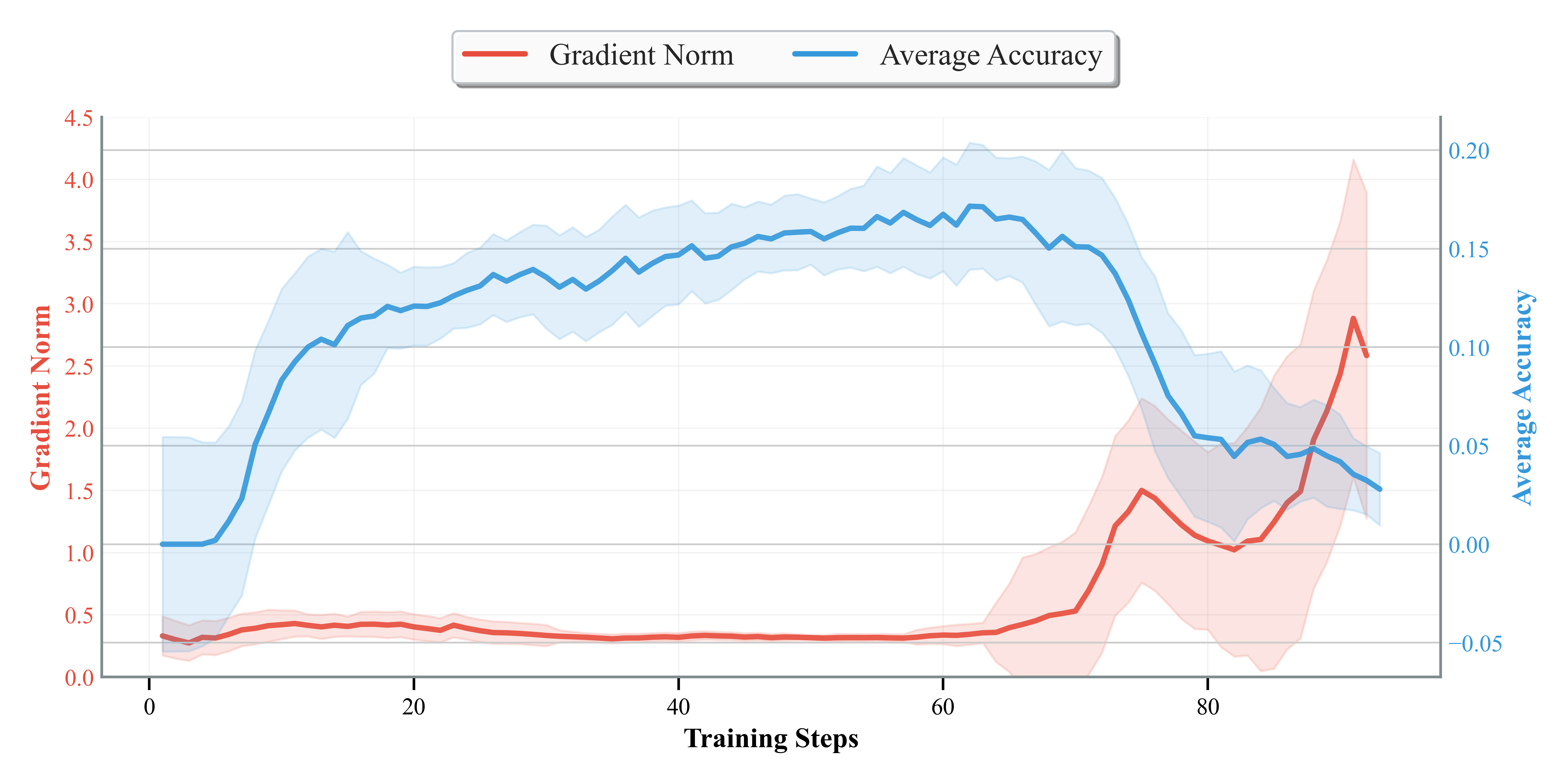
Figure 5: Training collapse in single-stage RL, with accuracy dropping as gradient norm explodes.
Figure 6: A high KL loss coefficient (β=0.1) is necessary to maintain policy entropy and prevent collapse.
Implementation Considerations
- Algorithm: Adapted PPO with Group-Relative Policy Optimization (GRPO), decoupled clipping, and a substantial KL penalty (β=0.1) for entropy preservation.
- Data: Only 400 problem instances from BFCL V3; no expert demonstrations or large-scale synthetic data.
- Environment Engineering: Requires domain-specific augmentation to provide actionable feedback, but does not require explicit dependency graphs or handcrafted trajectories.
- Resource Requirements: The method is compatible with 7B–8B parameter models and can be applied to both base and SFT-tuned architectures.
- Scalability: The curriculum and augmentation principles are extensible to larger models and more complex, multi-modal environments.
Theoretical and Practical Implications
The results challenge the prevailing paradigm of trajectory-based SFT for agentic tasks, demonstrating that environment-centric, curriculum-driven RL can achieve superior data efficiency and generalization. The approach decouples agent learning from the need for expert demonstrations, instead leveraging environment engineering to provide rich, pedagogical feedback.
Practically, this enables the development of robust, adaptable agents in domains where high-quality demonstrations are prohibitively expensive or unavailable. Theoretically, it suggests that the design of the training environment—specifically, the informativeness and granularity of feedback—can be as critical as the choice of model architecture or optimization algorithm.
Future Directions
- Automated Curriculum and Feedback Generation: Developing methods to automatically construct curricula and generate actionable feedback, reducing the manual engineering burden.
- Extension to Multi-Modal and Real-World Environments: Applying Environment Tuning to settings involving vision, speech, or physical actuation.
- Integration with Model-Based RL: Leveraging learned environment models to further enhance sample efficiency and generalization.
- Robustness and Safety: Investigating the impact of environment augmentation on agent robustness to adversarial or unexpected scenarios.
Conclusion
Environment Tuning represents a principled, empirically validated approach for training multi-turn, tool-augmented agents under extreme data scarcity. By shifting the focus from imitation of static trajectories to environment-driven exploration, and by leveraging curriculum learning, actionable feedback, and dense rewards, the method achieves both stable learning and strong generalization. This paradigm has significant implications for the design of future agentic systems, particularly in resource-constrained or rapidly evolving domains.