- The paper introduces an automated synthesis pipeline for multi-turn agent trajectories, integrating SFT and RL protocols to improve tool-based reasoning.
- It employs graph-based random walks and QA-based decompositions to generate rule-verifiable simulation environments, ensuring semantic realism.
- Experimental results across benchmarks demonstrate ASTRA’s efficacy in enhancing multi-step planning and stable, efficient agent training.
ASTRA: Automated Synthesis of Agentic Trajectories and Reinforcement Arenas
Motivation and Problem Statement
Tool-augmented LLM agents address increasingly complex interactive tasks requiring API invocation, long-horizon planning, and multi-step decision making. However, current agent training protocols are constrained by manual annotation, simulations that lack rule verifiability, exclusive reliance on either SFT or RL, and instability in long-horizon learning. ASTRA introduces a fully automated, end-to-end framework that integrates scalable multi-turn trajectory synthesis and verifiable environment generation to explicitly target these limitations.
Automated Multi-Turn Data and Environment Synthesis
ASTRA's SFT methodology leverages large-scale MCP server registries and tool emulators to construct diverse and executable multi-turn data. The pipeline normalizes disparate tool schemas into a unified format, filters for actionable documents, and employs graph-based random walks for tool-chain creation, verifying dependencies and task coherence via LLM. Controlled augmentation (paraphrase, complexity, persona) and a multifaceted task scoring regime ensure both semantic realism and tool-use necessity.
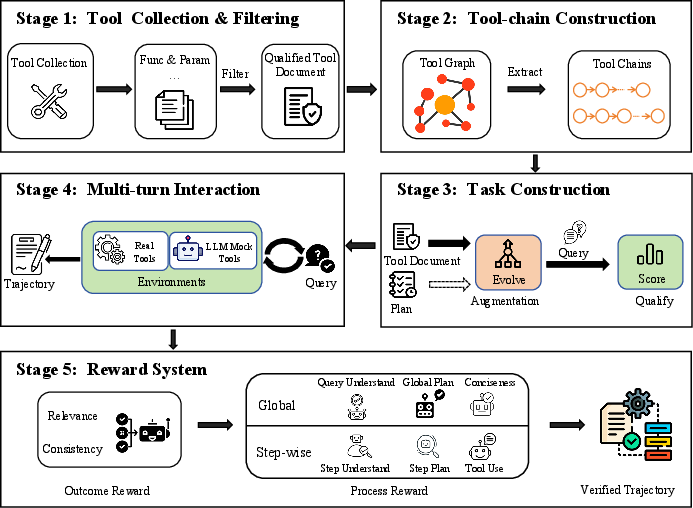
Figure 1: Pipeline for multi-turn tool-chain trajectory synthesis including document normalization, chain construction, and augmentation.
After chain validation, SFT trajectories are realized by hybrid execution across both real and simulated tool endpoints, emulating real-world unreliability and logging outputs for fine-tuning.
QA-Based Verifiable Environment Synthesis
For RL, ASTRA systematically decomposes semantic reasoning via QA instance synthesis, extracting structured multi-hop subgoals and representing dependency topology as an explicit DAG. Samples are filtered for tool-use steps, atomicity, rationality, and task completeness, generating code-executable Python environments for each validated sub-question and merging functionally equivalent sub-environments to constrain the action space.
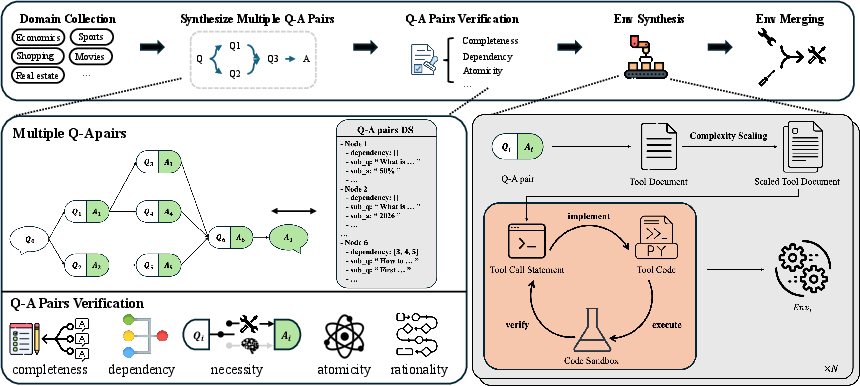
Figure 2: Framework for QA-based environment synthesis, converting decomposed reasoning traces into independent, rule-verifiable simulation environments.
This process yields training instances paired with isolated rule-verifiable simulators, facilitating trajectory-level online RL.
Unified Agentic Training Protocol
Supervised Fine-Tuning (SFT)
Fine-tuning is performed on Qwen3-14B and Qwen3-32B using high-frequency checkpointing with decoupled weight/training-state snapshots for observability and efficiency. Context parallelism supports long-horizon training, and the pipeline enables models to internalize structured tool use and multi-turn conventions.
Reinforcement Learning (RL)
ASTRA frames policy learning as online RL over instance-specific, sandboxed environments. The agent executes tool sequences (Figure 3) until a turn or sequence cap is reached, with rollouts collected for trajectory-level optimization using the GRPO objective (KL and entropy terms omitted for stability). Adaptive batch filling (Figure 4) ensures that batches only contain rollouts with informative reward variance, mitigating collapse in advantage estimates and promoting stable training.
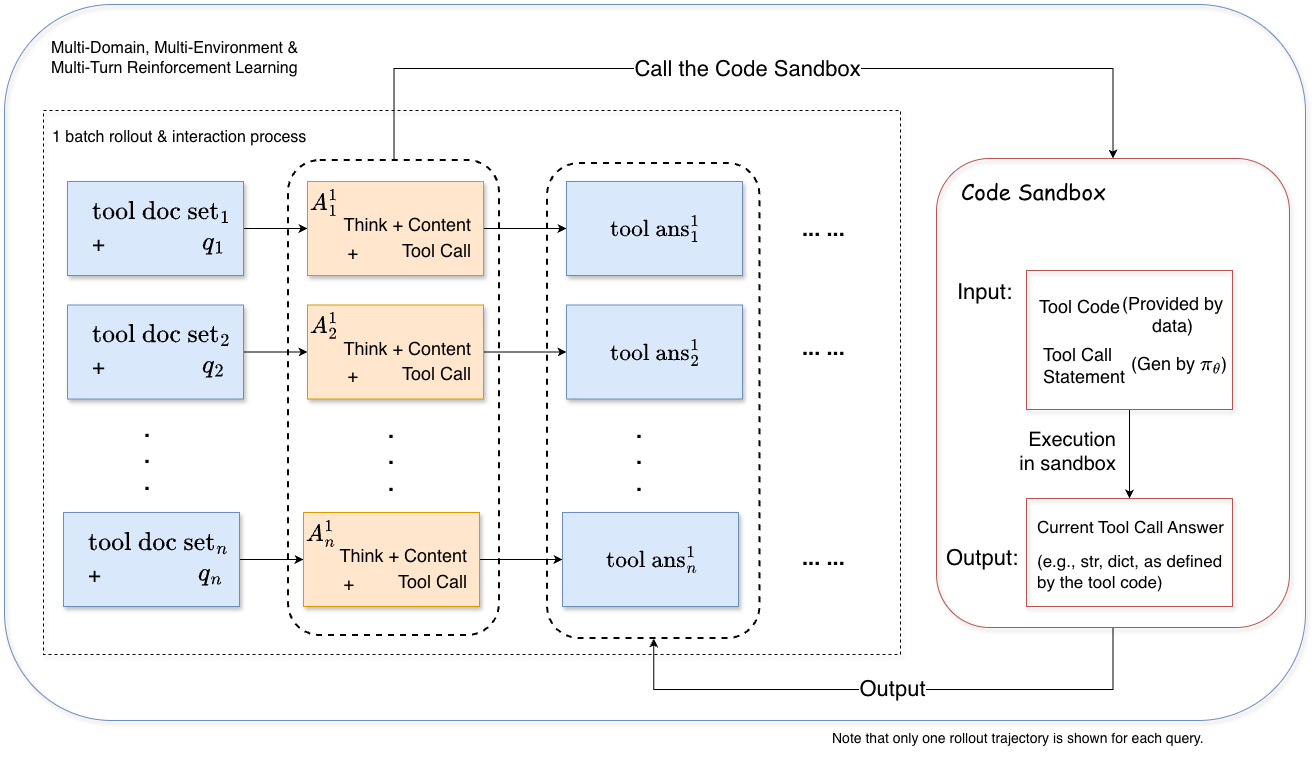
Figure 3: Online multi-turn rollout procedure for agentic RL over isolated environments.
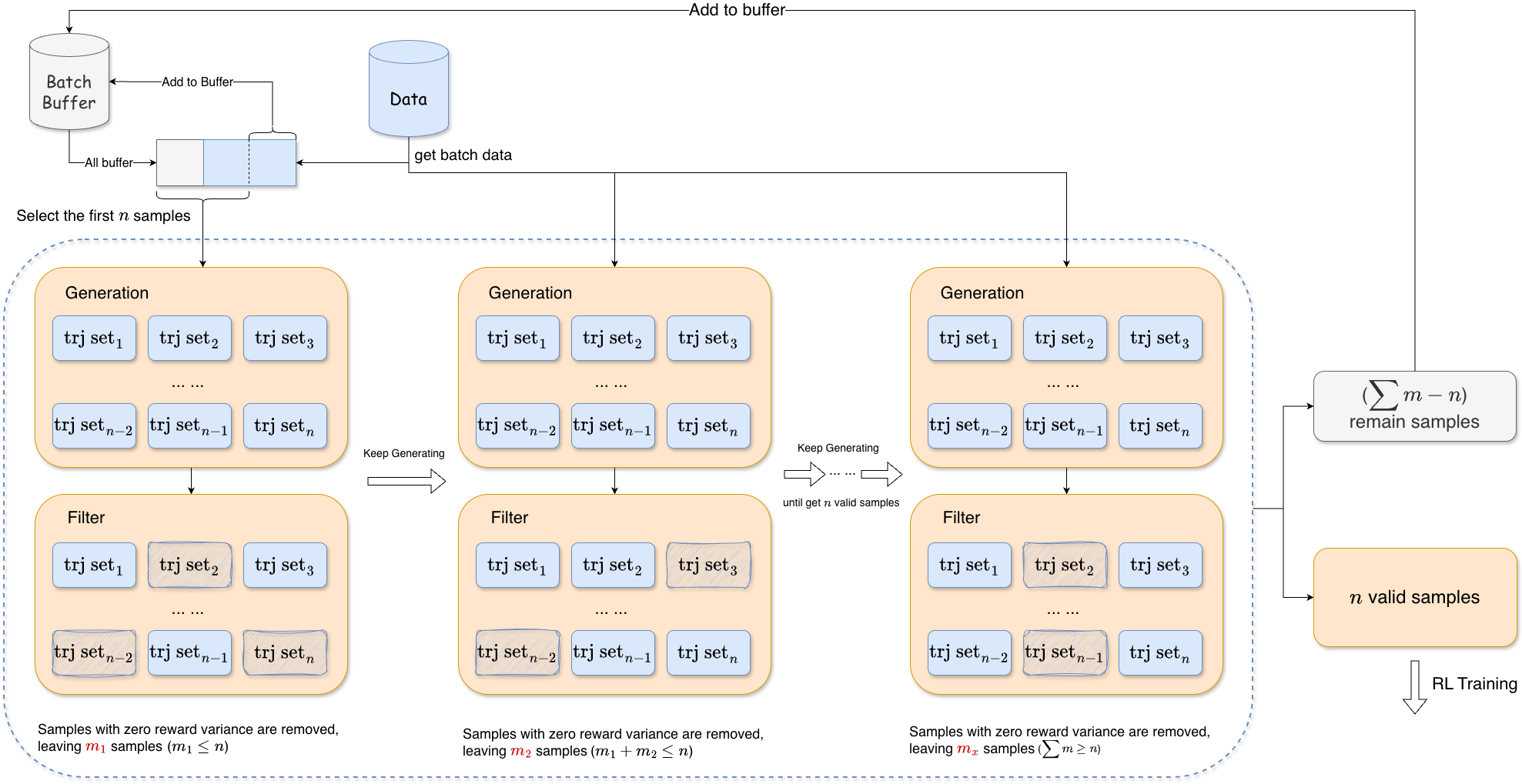
Figure 4: Adaptive batch filling scheme guarantees a batch of non-degenerate, learning-active trajectories.
Tool discrimination is induced by augmenting each instance with controlled sets of semantically diverse, task-irrelevant tools sampled according to embedding-based similarity bands. This augmentation is critical for promoting negative tool judgment and robustness under expansive tool inventories.
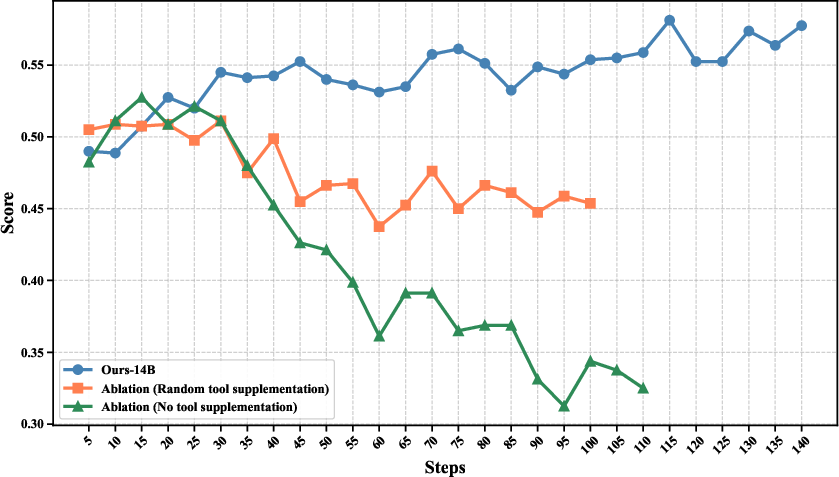
Figure 5: Ablation of irrelevant-tool mixing reveals necessity for discrimination pressure and negative tool judgment.
Trajectory-Level F1 Reward Design
ASTRA proposes a trajectory-level F1-style reward, jointly optimizing sub-task recall and precision of tool invocation. Comparative ablations (Figure 6, 8) demonstrate that recall-only rewards drive overuse and instability, whereas precision-only rewards induce brittleness; F1 harmonic mean produces balanced exploration and stable optimization.
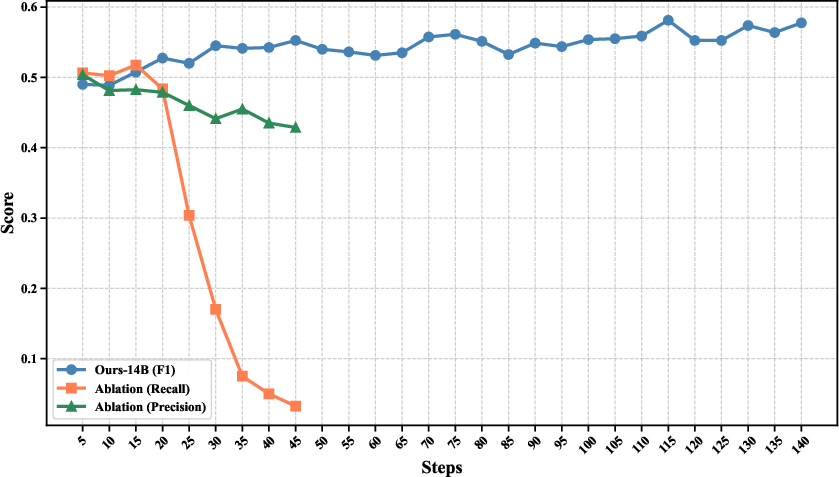
Figure 6: Reward design ablation compares recall-only, precision-only, and F1 reward effects on training and performance.
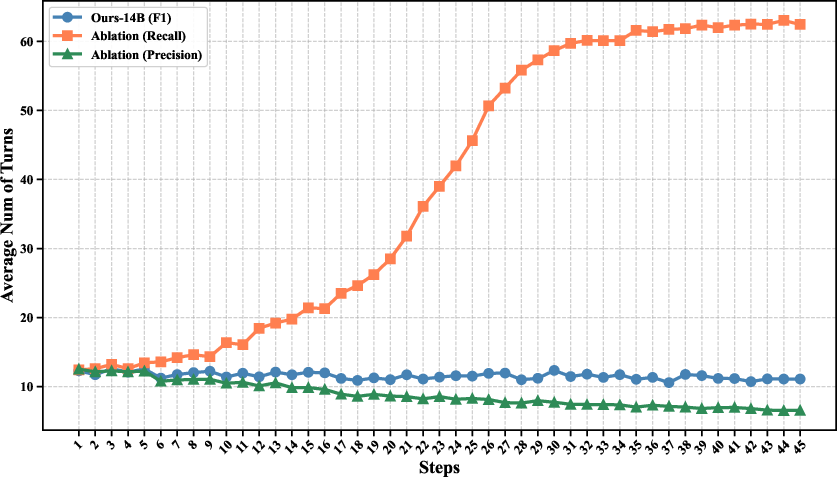
Figure 7: Dialogue turn distribution evolution for different reward configurations, showing that F1 design yields well-behaved, efficient interactions.
Experimental Results
Extensive evaluation on agentic benchmarks—BFCL v3 Multi-Turn, τ2-Bench, and ACEBench—at both 14B and 32B scales shows that ASTRA-trained models consistently outperform open-source baselines and are competitive with closed-source systems, especially in multi-step and long-context settings. RL-driven gains are confirmed across all metrics, while performance on non-agentic reasoning (AIME) remains undiminished, evidencing robust core logical competence.
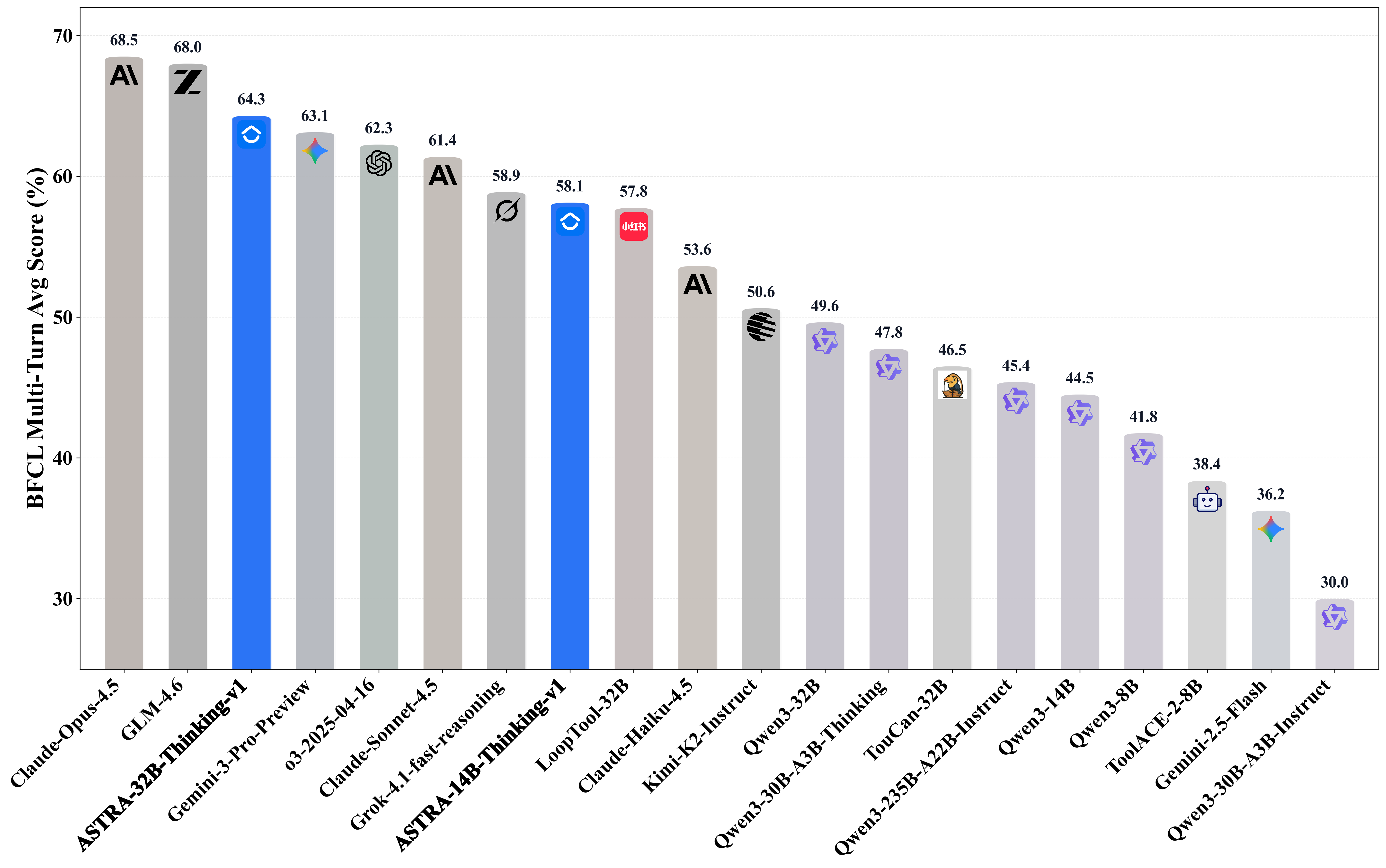
Figure 8: Model performance comparison on BFCL v3 Multi-Turn with ASTRA attaining competitive accuracy versus closed and open-source alternatives.
Training Stage Analysis
Stage-wise analysis demonstrates that SFT delivers a step-change in multi-turn adaptation and output conciseness, while RL augments this foundation, broadening exploration over the semantic/compositional topology and optimizing task-oriented, efficient behavior. Output statistics show SFT compresses response length, RL converges to efficient intermediate lengths, and interaction depth remains stable across protocols.
Large-Scale Data and Environment Coverage
ASTRA synthesizes 54,885 multi-turn SFT samples covering 6,765 unique tools across 41 domains (distribution shown in Figures 9, 11). RL environments are built from 6,596 instances, averaging 4.37 reasoning hops with predominance in real estate, e-commerce, and healthcare and domain/task parallelism reflecting real application diversity (Figures 12, 13).
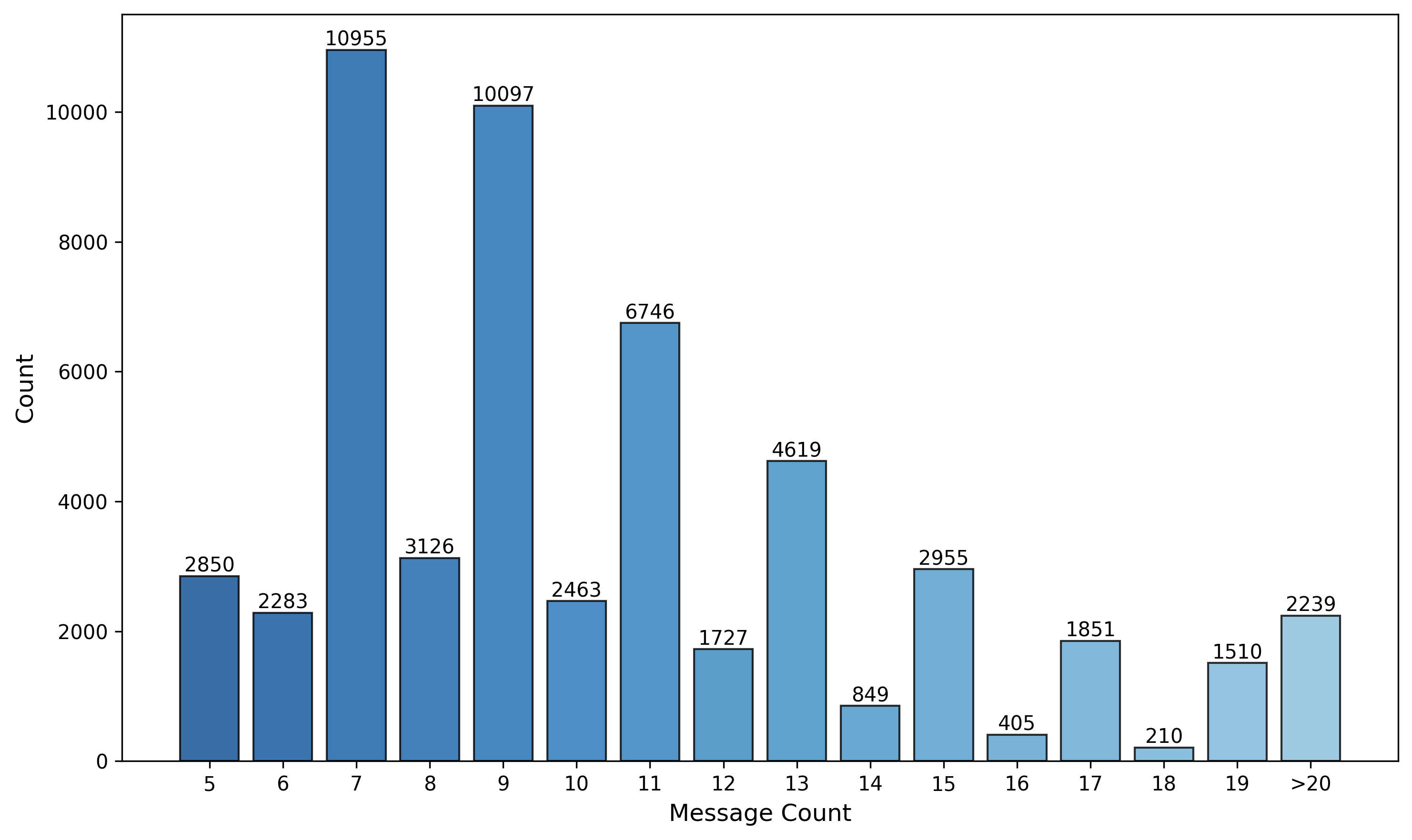
Figure 9: Distribution of messages per SFT sample, illustrating multi-turn complexity.
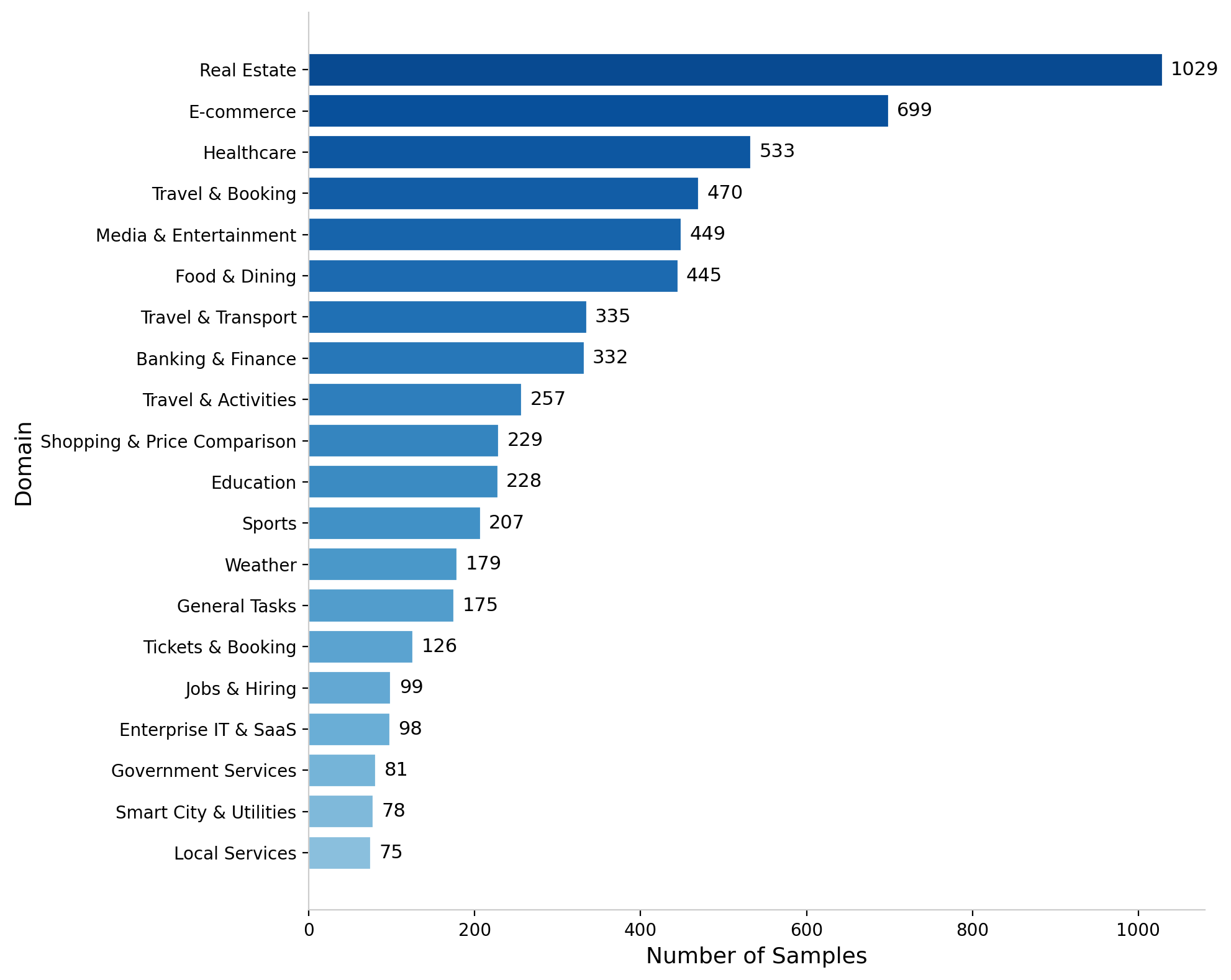
Figure 10: Top 20 domain distribution in the RL dataset, representing extensive domain coverage.
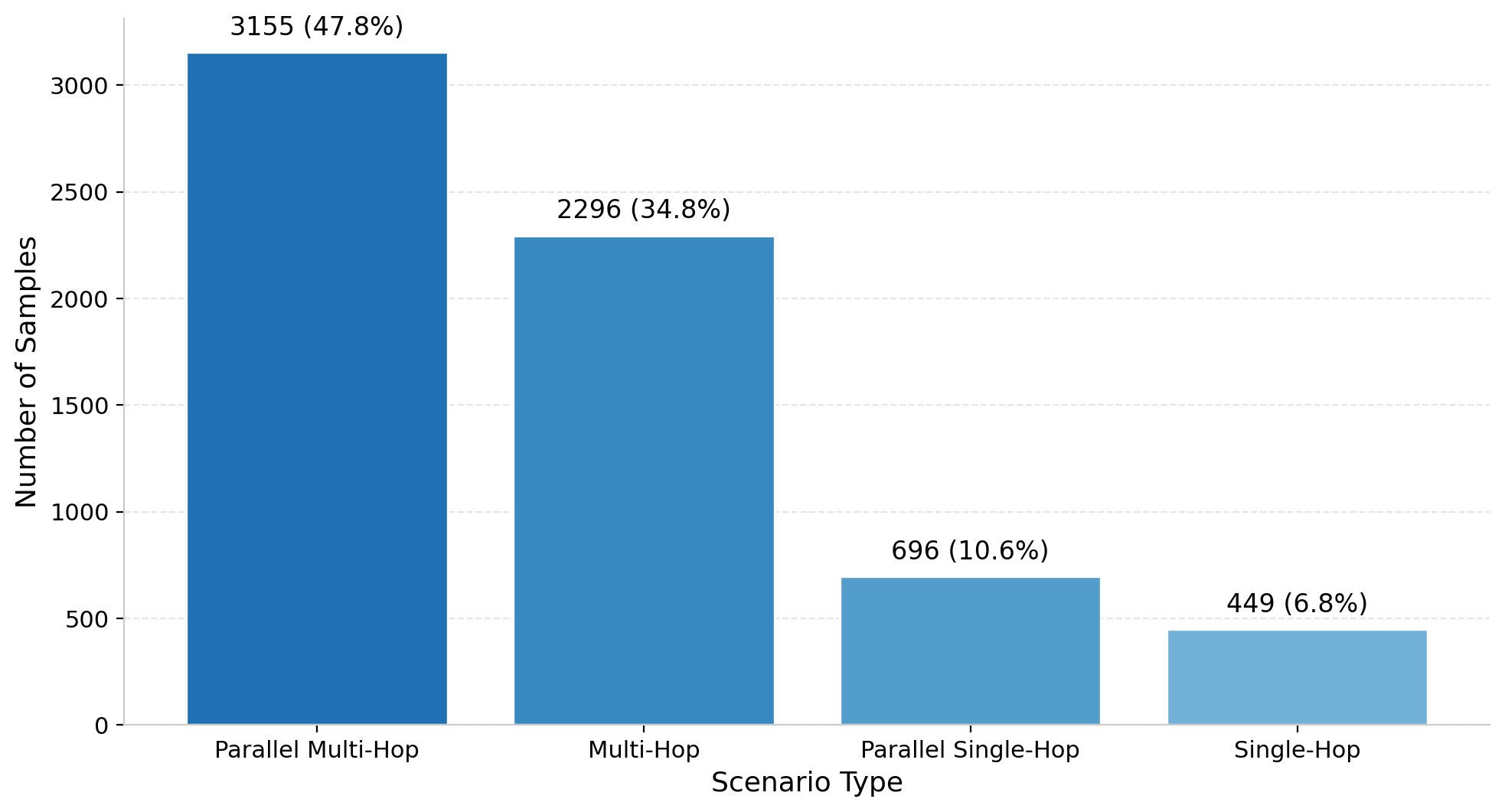
Figure 11: RL scenario type distribution with a focus on parallel and multi-hop complexity.
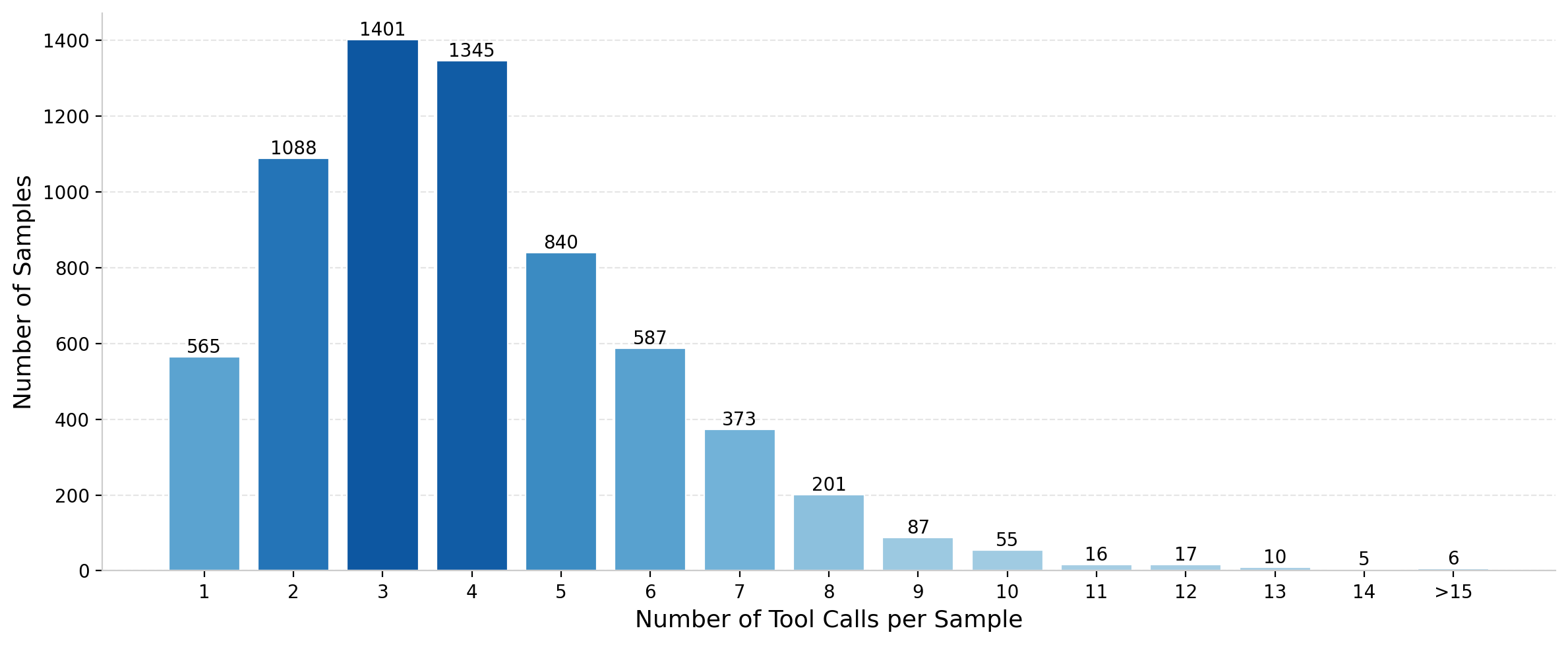
Figure 12: Distribution of tool calls per RL sample, emphasizing frequent parallel tool use.
Implications and Future Directions
ASTRA establishes an open-source paradigm for fully automated agentic training, minimizing manual bottlenecks and enabling scalable synthesis of both agentic trajectories and rule-verifiable RL environments. The duality between static tool topology in SFT and compositional semantic topology in RL offers flexibility for diverse downstream applications and robust adaptation to complex, evolving interactive scenarios.
Practically, ASTRA's pipeline enables generation of executable environments per scenario, empowering iterative agent improvement and deployment across real-world domains. Theoretically, it affirms the importance of dense trajectory-level credit assignment, discrimination signals, and compositional environment construction for the advancement of grounded agentic LLMs.
Future work may extend ASTRA to interactive, user-driven online RL with evolving intents and feedback, and incorporate cost-aware automation in environment synthesis, including topology refinement and maximal reuse of validated semantic structures prior to instantiation.
Conclusion
ASTRA delivers a comprehensive, scalable framework for training tool-augmented LLM agents through fully automated trajectory and environment synthesis with integrated SFT and RL protocols. Empirical results validate agentic performance, efficiency, and robust reasoning. By open-sourcing its pipelines and models, ASTRA facilitates reproducibility and accelerates research toward adaptive, generalizable, and verifiable agentic intelligence in open environments (2601.21558).