- The paper introduces the Mirage framework, which integrates latent visual tokens with textual reasoning to enhance multimodal analysis.
- The paper employs a two-stage fine-tuning paradigm that jointly supervises text and latent tokens, significantly boosting spatial and formal reasoning tasks.
- The paper's experiments demonstrate improved performance on benchmarks such as VSP and SAT compared to traditional text-only models.
Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens
The paper "Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens" presents the Mirage framework, which enhances Vision-LLMs (VLMs) by incorporating latent visual tokens to facilitate multimodal reasoning without explicit image generation.
Introduction and Motivation
VLMs have shown significant progress in multimodal understanding tasks. However, existing models typically rely on text-only decoding, which limits their performance in tasks requiring visual imagination or reasoning. The Mirage framework addresses this limitation by introducing latent visual tokens that allow VLMs to interleave visual and textual reasoning without the need for pixel-level image generation.
The Mirage approach is inspired by human mental imagery, where individuals construct and manipulate simplified visual cues internally, rather than producing detailed visual images. This simplifies the reasoning process and makes it computationally efficient.
Mirage Framework
Mirage operates in a two-stage fine-tuning paradigm:
- Stage 1: Joint Supervision for Latent Grounding
In the first stage, Mirage supervises both text and latent visual tokens. The VLM is trained to predict the next word and reconstruct a compact latent visual vector from compressed image embeddings. This stage anchors latent tokens in the visual subspace, ensuring they contain meaningful visual cues for later reasoning steps.
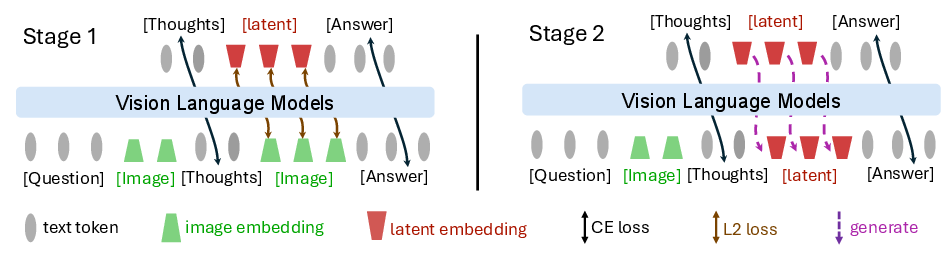
Figure 1: Pipeline of Mirage Framework. Stage 1 jointly supervises text and latent visual tokens, grounding the latter in the visual subspace; Stage 2 drops the latent supervision, anchoring the grounded latent tokens for subsequent text generation.
- Stage 2: Text-Only Supervision with Latent Relaxation The second stage removes direct supervision on latent vectors, optimizing only text tokens. It allows the model to treat autoregressively generated latent embeddings as priors guiding subsequent word generation, resulting in flexible interleaved reasoning without enforcing predefined embeddings.
This framework allows VLMs to produce interleaved reasoning trajectories that blend latent visual tokens with text, enhancing the model's ability to perform complex multimodal reasoning tasks.
Experimental Validation
The experiments demonstrate Mirage's effectiveness across diverse benchmarks, including spatial reasoning tasks (VSP, BLINK-Jigsaw, SAT) and formal spatial reasoning in mathematical contexts (COMT). The evaluations reveal that Mirage significantly enhances reasoning abilities compared to text-only baselines and performs comparably with unified multimodal models requiring pixel-level supervision.
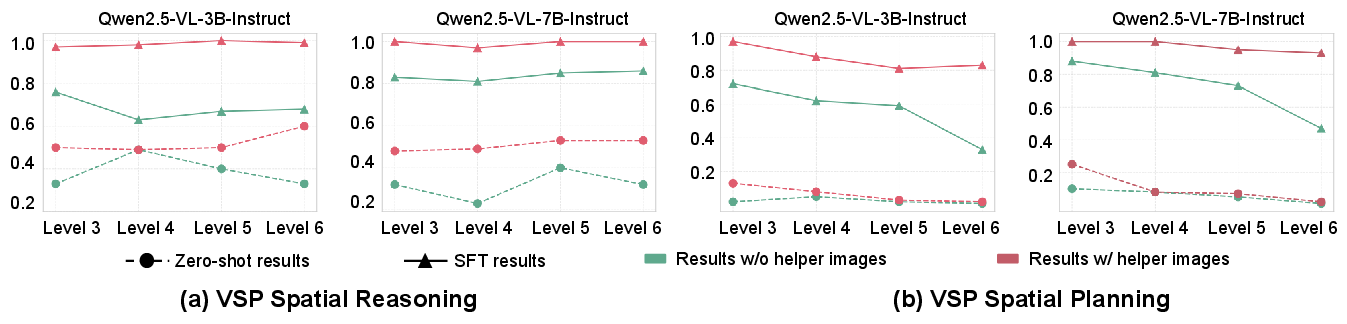
Figure 2: Performance with Helper Images as Input Priors. We evaluate model accuracy using synthesized helper images under both zero-shot and fine-tuned settings. The results highlight the informativeness of the generated images and confirm their high data quality.
Analysis and Insights
Data Generation Quality
The paper introduces a data-generation pipeline for creating task-specific helper images used during training. These helper images significantly improve model performance by providing informative visual cues essential for multimodal reasoning.
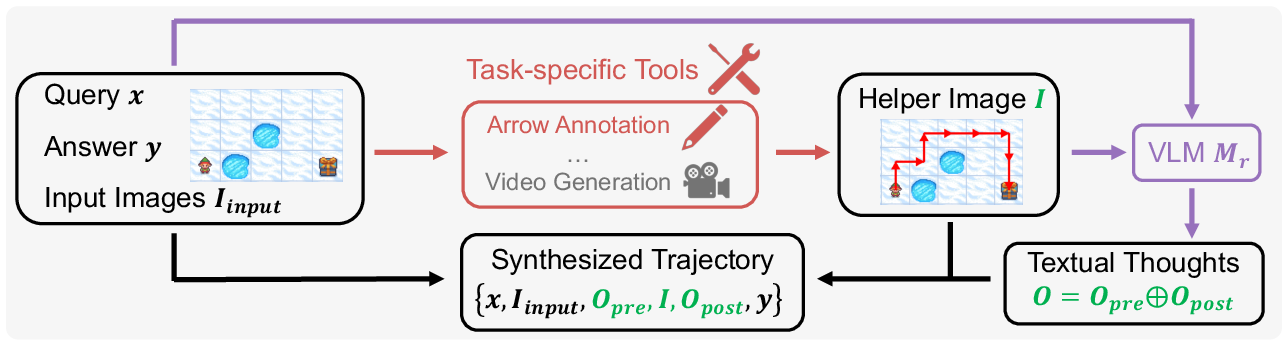
Figure 3: Data-generation Pipeline. For each question-answer pair, we first create a helper image with task-specific tools (here, annotate the map with arrows), then prompt a VLM to produce textual reasoning that embeds this image. The text and helper image together form the synthetic multimodal trajectory used for training.
Latent Embeddings
An analysis of latent embeddings using t-SNE visualization shows that latent tokens remain closely associated with the visual representation subspace while retaining adaptability introduced in the second training stage. This demonstrates Mirage's ability to maintain valuable visual information within flexible reasoning trajectories.
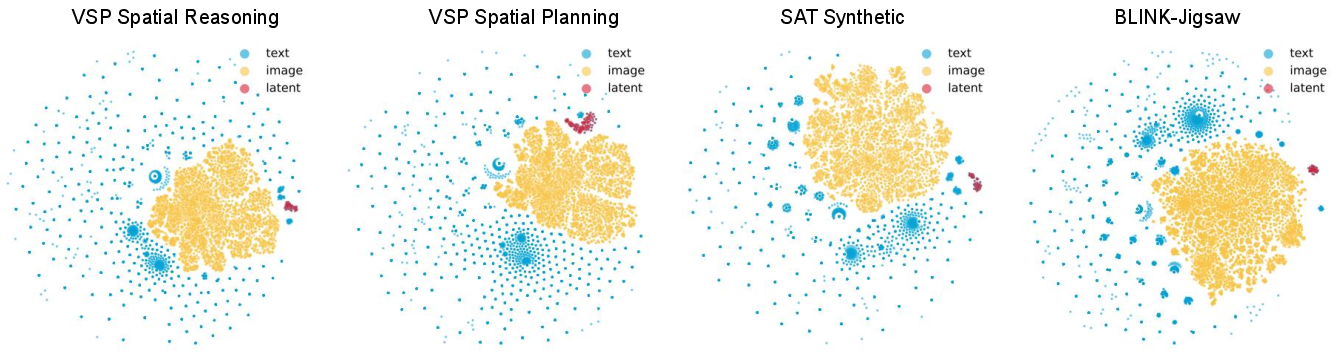
Figure 4: Visualization of Latent Embeddings. We visualize our latent tokens along with text and image embeddings with t-SNE. Our latent tokens cluster near, yet just outside, the visual representation subspace, consistent with the two-stage training design.
Conclusion and Future Directions
Mirage offers a novel approach to enhancing VLMs by integrating latent visual tokens for interleaved multimodal reasoning. By eliminating the need for pixel-level image generation, Mirage enables efficient reasoning while maintaining rich visual information. Future research could explore the integration of Mirage into unified models and its application to a broader range of multimodal and textual tasks. Additionally, improving the quality of synthetic multimodal trajectories remains a critical area for development.
With Mirage, the potential for deeper multimodal reasoning in VLMs is unlocked, offering promising directions for future advancements in AI reasoning capabilities.

