- The paper reveals that while extended reasoning improves logical inference in VLMs, it concurrently degrades visual recognition due to 'visual forgetting'.
- The paper introduces Vision-Anchored Policy Optimization (VAPO), a reinforcement learning framework that inserts visual anchors to maintain perceptual grounding during multi-step reasoning.
- Experimental results show that VAPO-Thinker-7B achieves 2–4% accuracy gains on vision-intensive benchmarks by effectively reducing perception errors.
The Dual Nature of Reasoning in Vision-LLMs: Analysis and Mitigation via Vision-Anchored Policy Optimization
Introduction
This paper presents a systematic investigation into the dual nature of reasoning in Vision-LLMs (VLMs), revealing a fundamental trade-off: while extended reasoning enhances logical inference, it can simultaneously degrade perceptual grounding, leading to increased errors in visual recognition. The authors identify "visual forgetting"—the progressive neglect of visual input during multi-step reasoning—as the primary cause of this phenomenon. To address this, they introduce Vision-Anchored Policy Optimization (VAPO), a reinforcement learning framework that explicitly incentivizes visual grounding throughout the reasoning process. The resulting model, VAPO-Thinker-7B, achieves state-of-the-art performance across a diverse set of multimodal benchmarks.
Empirical Analysis of Reasoning in VLMs
The study begins by challenging the prevailing assumption that longer or more elaborate reasoning always improves VLM performance. Through controlled experiments with leading VLMs (e.g., Vision-R1, R1-OneVision, VLAA-Thinker), the authors introduce an "early decision" protocol, prompting models to answer at intermediate reasoning steps. This enables fine-grained measurement of how accuracy evolves as reasoning progresses.
The results demonstrate that, although initial reasoning steps yield accuracy gains, further reasoning often leads to a plateau or even a decline in performance, particularly on vision-intensive tasks. Notably, a significant fraction of errors in full-reasoning mode are "perception errors"—failures to correctly interpret visual details—which could have been avoided by stopping reasoning earlier.

Figure 1: Examples where more reasoning yields less accuracy, highlighting cases where early decision outperforms full reasoning.
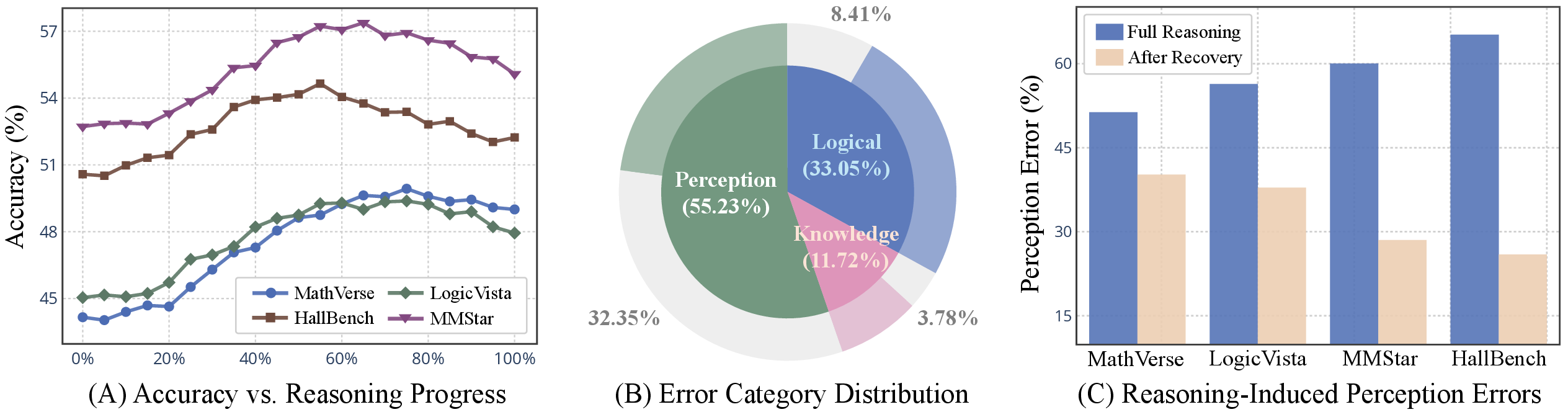
Figure 2: (A) Accuracy evolution during reasoning; (B) Error category distribution and recoverability; (C) Perception error ratios across benchmarks.
This dual effect is most pronounced in benchmarks requiring fine-grained visual understanding (e.g., MMStar, HallusionBench), where perception errors dominate and are often recoverable by truncating the reasoning process.
Visual Forgetting: Mechanism and Evidence
To elucidate the mechanism underlying this trade-off, the authors analyze the evolution of attention to visual tokens during reasoning. They observe a marked decline in visual attention as generation progresses, indicating that the model's decisions become increasingly driven by its own prior outputs rather than the visual input—a phenomenon termed "visual forgetting."
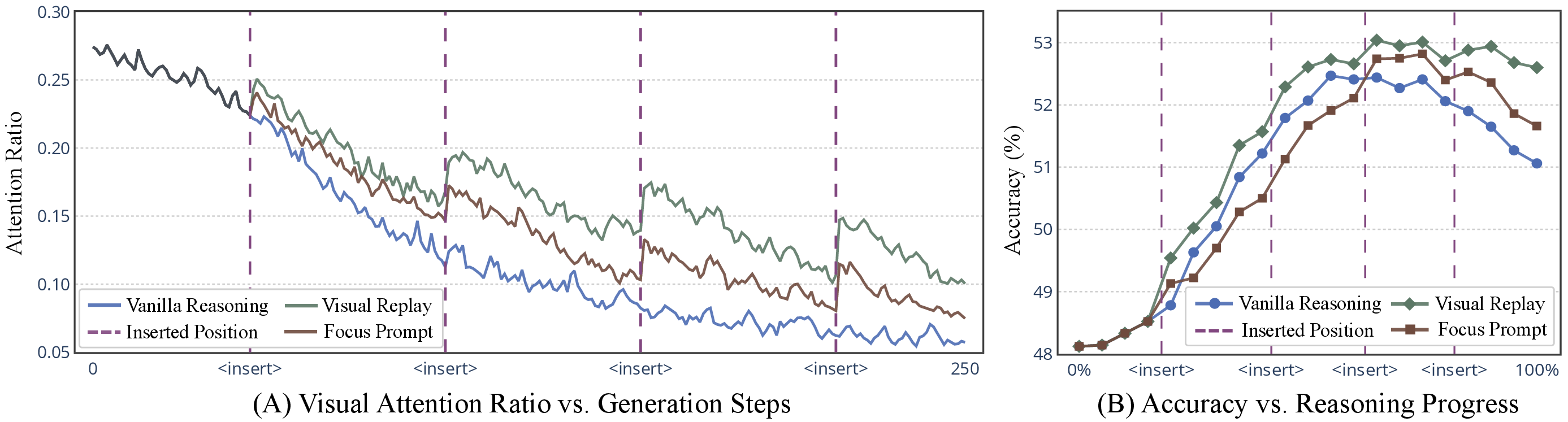
Figure 3: (A) Decline in attention to visual tokens during reasoning; (B) Accuracy trends under vanilla reasoning, visual replay, and focus prompt interventions.
Two inference-time interventions—visual replay (re-inserting the image) and focus prompts (explicitly instructing the model to attend to the image)—temporarily restore visual attention and partially recover accuracy, empirically validating the visual forgetting hypothesis. However, these remedies are computationally inefficient and do not address the underlying training deficiency.
Vision-Anchored Policy Optimization (VAPO)
To fundamentally mitigate visual forgetting, the authors propose VAPO, a policy gradient algorithm that augments standard RL-based training (e.g., GRPO) with explicit perceptual supervision. The core idea is to insert "visual anchors"—checkpoints along the reasoning trajectory where the model is required to judge the truth of visual claims about the input image. These claims, generated by GPT-5, are designed to be balanced (equal correct/incorrect) and independent of the question context, ensuring that their verification requires genuine visual grounding.
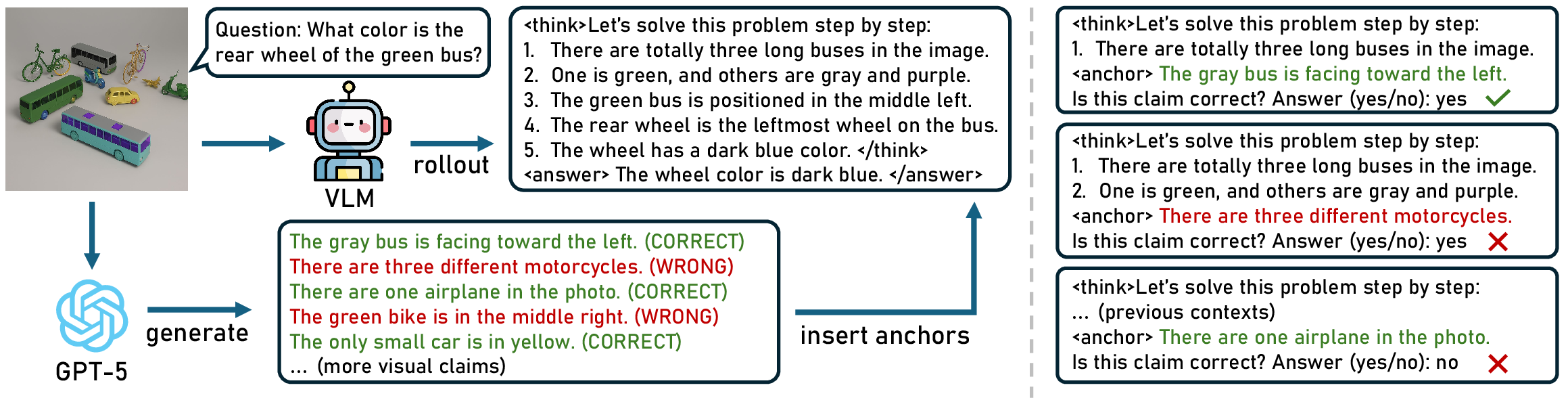
Figure 4: Overview of VAPO: visual claims are generated and inserted as anchors during reasoning, with the model's perceptual capability probed at each anchor.
At each anchor, the model's binary judgment (yes/no) is scored against the ground truth, and a "perception reward" is computed as a late-emphasis weighted sum over all anchors. This reward is combined with standard accuracy and format rewards, and the overall objective is optimized via group-based policy gradients. The late-emphasis weighting targets the tendency for perceptual grounding to degrade in later reasoning steps.
Experimental Results
VAPO-Thinker-7B is evaluated on ten established benchmarks spanning mathematical reasoning, logical inference, and general-purpose multimodal tasks. The model consistently outperforms strong open-source and proprietary baselines, with average gains of 2–4% in accuracy. The improvements are especially pronounced on vision-intensive tasks, where VAPO corrects a substantial fraction of perception errors that baseline models fail to resolve.
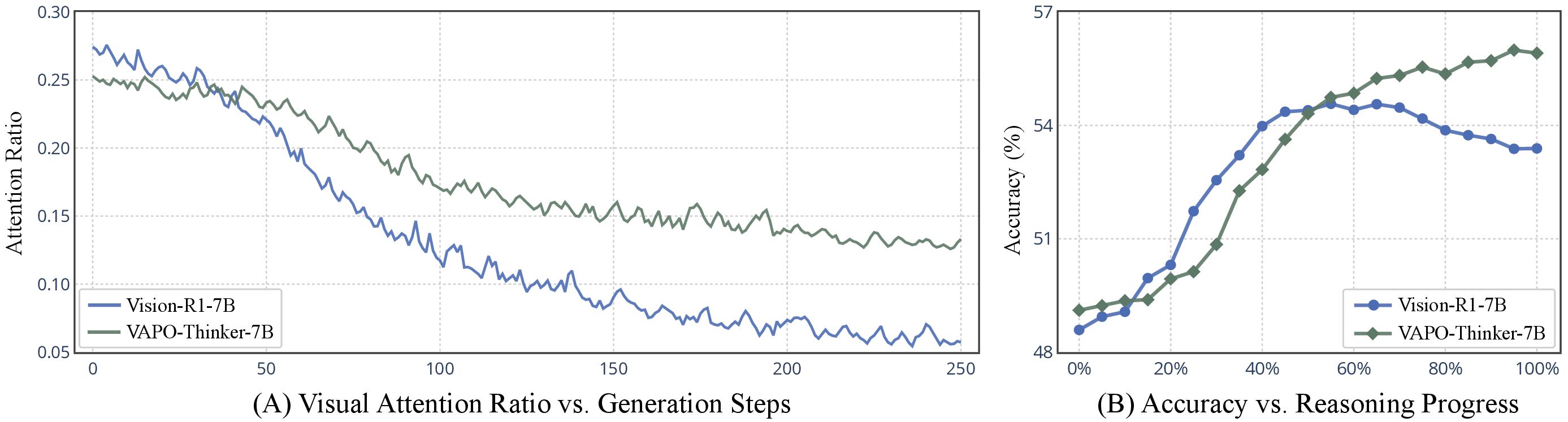
Figure 5: (A) VAPO sustains higher visual attention throughout reasoning; (B) Accuracy remains stable or improves with longer reasoning under VAPO, in contrast to baseline decline.
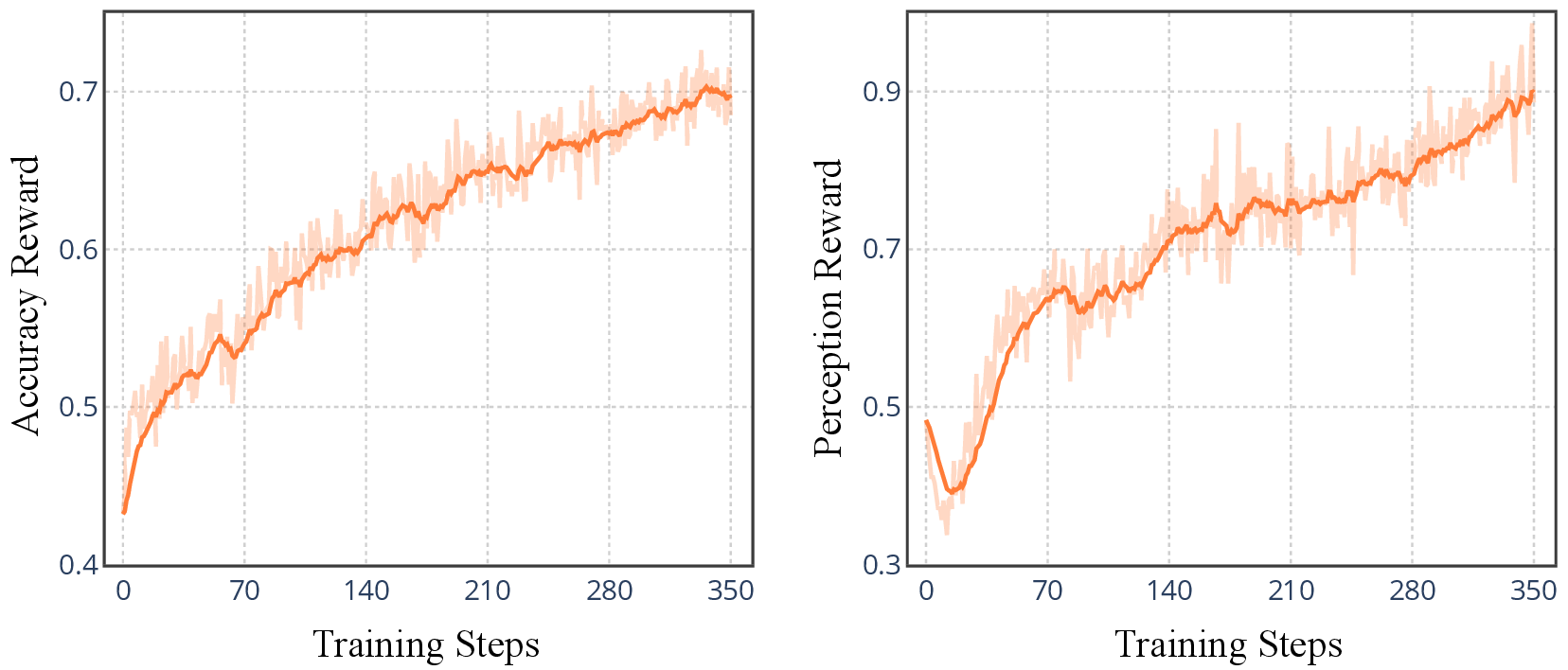
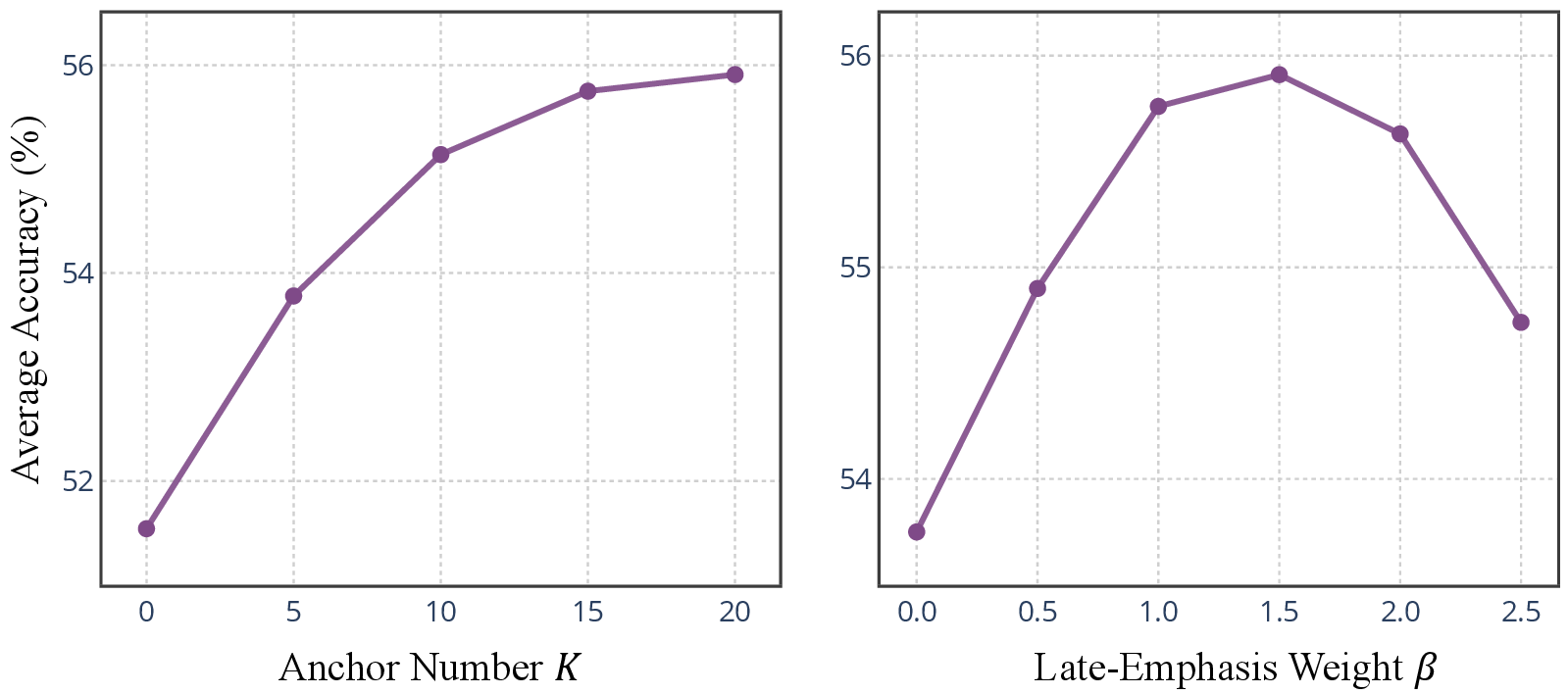
Figure 6: Training curves showing parallel improvement in accuracy and perception reward, indicating enhanced visual grounding.
Ablation studies confirm that increasing the number of visual anchors and emphasizing later anchors both contribute to improved visually grounded reasoning. The perception reward is shown to be critical: replacing it with a naive attention-based reward yields inferior results, underscoring the importance of explicit perceptual supervision.
Analysis and Implications
The findings have several important implications:
- Reasoning in VLMs is not universally beneficial: Extended reasoning can degrade perceptual accuracy, especially in tasks requiring fine-grained visual understanding.
- Visual forgetting is a central bottleneck: Without explicit incentives, VLMs tend to rely on self-generated context, neglecting the visual input as reasoning progresses.
- Perceptual supervision is essential: Training-time interventions that anchor reasoning in visual evidence are necessary to fully realize the potential of multimodal reasoning.
- VAPO is efficient and generalizable: The method introduces minimal computational overhead and can be readily extended to multi-image or video-based tasks.
Theoretically, this work challenges the assumption that chain-of-thought or test-time scaling strategies from LLMs transfer directly to VLMs. Practically, it provides a scalable framework for improving the reliability and factuality of VLM outputs, with direct relevance to safety-critical applications.
Future Directions
Potential avenues for further research include:
- Adaptive anchoring: Dynamically adjusting anchor density and weighting based on task characteristics or model uncertainty.
- Claim generation quality: Leveraging more advanced or human-annotated visual claims to further enhance perceptual supervision.
- Extension to temporal and multi-image reasoning: Applying VAPO to video understanding or multi-view tasks, where visual grounding is even more challenging.
- Integration with other modalities: Exploring the impact of anchoring in audio, sensor, or structured data contexts.
Conclusion
This paper provides a rigorous analysis of the dual nature of reasoning in VLMs, identifying visual forgetting as a key limitation and introducing VAPO as an effective solution. By anchoring the reasoning process in visual evidence, VAPO-Thinker-7B achieves state-of-the-art performance and sets a new standard for visually grounded multimodal reasoning. The work highlights the necessity of perceptual supervision in VLM training and opens new directions for research in robust, interpretable, and reliable multimodal AI.