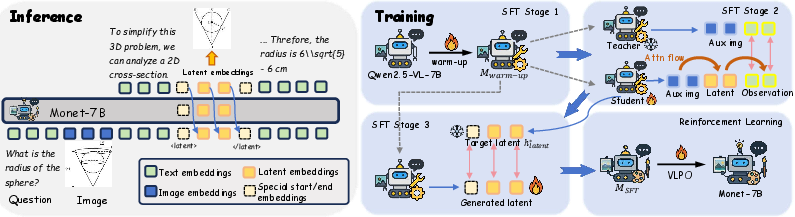
Monet: Reasoning in Latent Visual Space Beyond Images and Language
Abstract: "Thinking with images" has emerged as an effective paradigm for advancing visual reasoning, extending beyond text-only chains of thought by injecting visual evidence into intermediate reasoning steps. However, existing methods fall short of human-like abstract visual thinking, as their flexibility is fundamentally limited by external tools. In this work, we introduce Monet, a training framework that enables multimodal LLMs (MLLMs) to reason directly within the latent visual space by generating continuous embeddings that function as intermediate visual thoughts. We identify two core challenges in training MLLMs for latent visual reasoning: high computational cost in latent-vision alignment and insufficient supervision over latent embeddings, and address them with a three-stage distillation-based supervised fine-tuning (SFT) pipeline. We further reveal a limitation of applying GRPO to latent reasoning: it primarily enhances text-based reasoning rather than latent reasoning. To overcome this, we propose VLPO (Visual-latent Policy Optimization), a reinforcement learning method that explicitly incorporates latent embeddings into policy gradient updates. To support SFT, we construct Monet-SFT-125K, a high-quality text-image interleaved CoT dataset containing 125K real-world, chart, OCR, and geometry CoTs. Our model, Monet-7B, shows consistent gains across real-world perception and reasoning benchmarks and exhibits strong out-of-distribution generalization on challenging abstract visual reasoning tasks. We also empirically analyze the role of each training component and discuss our early unsuccessful attempts, providing insights for future developments in visual latent reasoning. Our model, data, and code are available at https://github.com/NOVAglow646/Monet.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Monet, a new way to help AI systems that can see and read (called multimodal LLMs, or MLLMs) “think with pictures” inside their own heads. Instead of drawing extra helper images or calling outside tools, Monet lets the AI create and use small, invisible “mental pictures” (special vectors called latent embeddings) during its step-by-step reasoning. This makes the AI’s visual thinking more flexible, faster, and closer to how humans imagine things while solving problems.
What questions did the researchers ask?
They focused on two simple questions:
- Can an AI learn to create useful “mental pictures” that help it reason about images, without needing to generate extra visible images or rely on external tools?
- How do we train and reward these mental pictures so they actually improve results, not just the text the AI writes?
How did they do it?
The team designed both a training process and a special reward method to teach the AI to think in “invisible pictures.”
Key idea: “Mental pictures” in the model’s head
- When the AI reasons, it can decide to output a special marker
"<latent>"that starts a short sequence of “mental picture” embeddings. Think of these as compact, internal sketches the model uses to focus on important visual details. - After a fixed number of these embeddings, it stops with
"</latent>"and continues with normal text. This lets the model switch between talking and “imagining.”
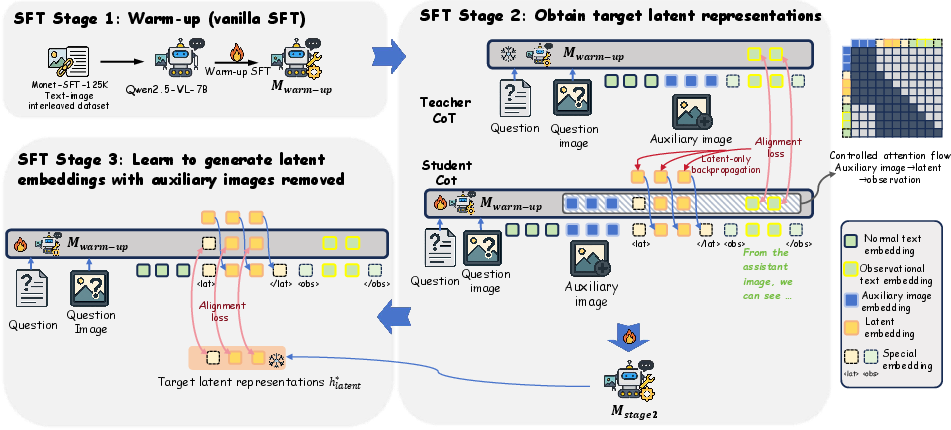
A three-step training pipeline (Supervised Fine-Tuning, or SFT)
The researchers used a staged approach to make sure the AI’s mental pictures are accurate and helpful. Here’s a brief, student-friendly summary of each step:
- Stage 1: Warm-up
- Goal: Teach the model the pattern of reasoning that mixes images and text.
- Why: Without practice, the model tends to ignore helper images and guess from language alone.
- Stage 2: Learn high-quality mental pictures with guidance
- Two copies of the model are used: a “teacher” and a “student.”
- The teacher sees real helper images and produces strong internal signals for key “observation words” (the parts of the explanation that describe what is seen).
- The student sees the same problem but must replace helper images with its own mental pictures.
- Two tricks make this work:
- Align observation signals: Make the student’s internal signals on observation words match the teacher’s, so the student’s mental pictures capture the same useful visual details.
- Controlled attention: Allow the student’s mental pictures to directly “look at” the real helper images during training, but block the text from seeing them. This forces visual information to flow like this: helper image → mental picture → observation words.
- Important safety rule: Only let the “mental picture” parts learn from this alignment (to prevent the model from taking shortcuts elsewhere).
- Stage 3: Fly solo without helper images
- Now the student has to generate mental pictures without seeing any helper images.
- It aligns its mental pictures to the high-quality ones it learned in Stage 2, so it can “imagine” the right visual cues on its own.
A new reward method: VLPO (Visual-latent Policy Optimization)
- Regular reinforcement learning methods (like GRPO) mostly reward the text steps, not the mental pictures, because text has clear probabilities but the mental pictures are continuous vectors.
- VLPO fixes this by estimating how likely the model would be to produce a given mental picture and then rewarding or discouraging it—just like with words.
- Intuition: If a certain mental picture helped the model get the right answer, VLPO nudges the model to produce a similar mental picture next time. If it hurt performance, the model learns to avoid it.
- They only reward the final answer being correct and well-formatted—not the act of using mental pictures—so the model learns to use them only when helpful.
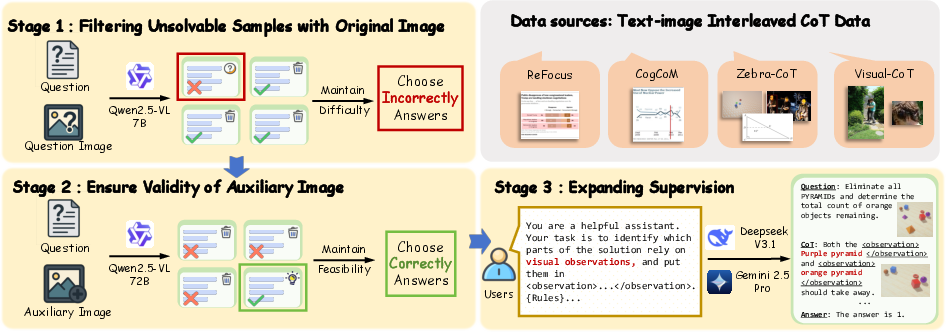
Building the training dataset (Monet-SFT-125K)
To train well, they curated 125,000 problems with image–text step-by-step explanations:
- They kept only problems where extra helper images were truly necessary (the base model fails without them).
- They checked that those helper images were accurate (a stronger model can solve the problem using them).
- They marked which words in the explanation were “observation words” (the parts that describe what is seen), providing precise supervision for learning good mental pictures.
What did they find, and why is it important?
Monet led to consistent improvements on many benchmarks that test vision-and-language reasoning, such as detailed real-world questions, charts, documents (OCR), and even tricky visual logic puzzles that don’t look like the training data.
Key takeaways:
- Monet’s mental pictures improved both seeing (perception) and thinking (reasoning) across several tests, beating strong baselines that either:
- Only trained with text,
- Cropped images, or
- Tried older “latent” methods that didn’t directly train mental pictures during reinforcement learning.
- It generalized well to unfamiliar tasks (out-of-distribution puzzles), showing the model wasn’t just memorizing patterns.
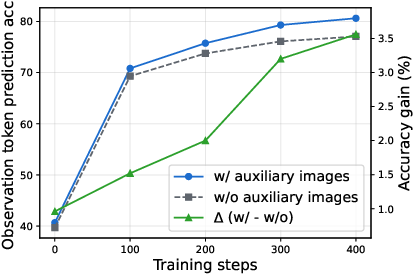
- An analysis showed each training piece matters:
- Without letting mental pictures directly learn from helper images, performance dropped.
- Without aligning observation signals, performance dropped.
- If the alignment wasn’t forced to update only the mental-picture parts, the model “cheated” and didn’t truly learn better mental pictures.
- Their new reinforcement learning method, VLPO, helped most with using mental pictures wisely and robustly, especially on unfamiliar tasks, while standard methods mostly improved text-only reasoning.
In short: Teaching the AI to imagine helps it reason more flexibly and accurately.
What could this change in the future?
- Smarter, faster visual reasoning: Because Monet doesn’t rely on external tools or making extra images, it can be simpler and faster to deploy.
- More human-like “inner vision”: The model learns to form internal sketches that capture what matters, similar to how people imagine diagrams or zoom in mentally.
- Broader applications: From reading documents and charts, to helping with geometry, navigation, educational tools, and robotics—anywhere an AI must “look, think, and explain.”
Simple caveats:
- Training is multi-stage and more complex than standard fine-tuning.
- Reward design for mental pictures could be explored further to make the model even better.
Overall, Monet shows a practical path toward AI that doesn’t just talk about pictures—it actually “thinks in pictures” internally, making its visual reasoning more flexible and powerful.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of the main unresolved issues and concrete research directions suggested by the paper.
- Adaptive control of latent reasoning length: Monet uses a fixed number of latent embeddings K and a special
<latent>/</latent>trigger, but does not learn when to start/stop or how many latent steps to use per instance. Develop policies that adapt K dynamically based on task difficulty, uncertainty, or compute budget. - Interpretability and auditability of latent embeddings: The “visual thoughts” remain opaque. Investigate methods to decode, visualize, or probe latent embeddings (e.g., via inversion or auxiliary decoders) to understand what visual information they encode and to verify correctness and safety.
- VLPO’s probability model and theory: VLPO assumes a Gaussian output distribution for latent embeddings with a fixed σ and uses a probability ratio that appears to mix old/new policies in a nonstandard way. Provide a principled derivation, clarify the denominator, analyze calibration of σ, and establish convergence/stability guarantees (e.g., under multimodal latent distributions, off-policy sampling, and clipping).
- Credit assignment over latent steps: Rewards are outcome-based (final answer) and not assigned to specific latent steps. Explore step-level or segment-level rewards (e.g., via temporal difference learning, learned value functions) to better reinforce useful latent actions and discourage redundant ones.
- Reward shaping beyond accuracy/format: The paper does not explore richer rewards (e.g., intermediate consistency checks, visual observation correctness, reasoning structure quality). Systematically study how reward design influences latent reasoning quality and OOD generalization.
- Compute and memory trade-offs: Claims of reduced alignment cost are not quantified. Measure and report training/inference FLOPs, memory footprint, latency, and throughput versus image-token alignment and tool-based baselines, and identify bottlenecks introduced by the three-stage SFT and VLPO.
- Reliability of “observation token” supervision: Key observation tokens are identified by LLM judges (DeepSeek-V3.1, Gemini 2.5), but their accuracy and bias are unvalidated. Compare multiple selection strategies (e.g., attention/grad-based attribution, human annotation, ensemble judges) and analyze inter-annotator agreement and downstream impact.
- Teacher–student target selection in Stage 2/3: Stage 3 aligns to latent targets produced by the Stage 2 student (not the frozen teacher). Investigate whether using teacher-generated targets, ensembling teachers, or iterative distillation improves stability and performance.
- Attention mask design search: The controlled “aux-image → latent → observation” attention flow is fixed. Systematically explore alternative attention patterns (e.g., allowing selective text-to-image attention, bidirectional latent-text coupling, gating mechanisms) and their effects on reasoning.
- Layer-wise alignment strategy: The paper aligns all layers with cosine similarity and sets fixed weights. Evaluate per-layer weighting, selective layer alignment, alternative losses (contrastive/InfoNCE/MMD), and their impacts on generalization and robustness.
- Portability across architectures and scales: Monet is demonstrated on Qwen2.5-VL-7B. Test portability to other MLLMs (e.g., LLaVA, InternVL, Pangea) and larger/smaller scales; identify architecture-specific changes (connectors, positional encodings, caching).
- Generalization across modalities and domains: Monet is evaluated on images only and a narrow set of benchmarks. Extend to video, 3D, medical/remote sensing documents, and multilingual OCR; assess cross-domain robustness and failure modes.
- Latent-trigger calibration and usage metrics: The model’s decision to invoke latent reasoning is not analyzed. Measure invocation frequency, correlate with difficulty/accuracy/cost, and design cost-aware policies that balance performance with latency/compute.
- Safety, robustness, and adversarial concerns: Latent reasoning could encode spurious correlations or be vulnerable to adversarial prompts/images. Develop diagnostics and defenses (e.g., robust training, anomaly detection in latent space, certified bounds).
- Hyperparameter sensitivity: Key hyperparameters (K_train/K_test, α/β for alignment, σ in VLPO) are fixed with limited exploration. Provide sensitivity analyses, automated tuning, or adaptive schedules that respond to task feedback.
- Hybridization with tool use: Monet is compared to cropping/tool methods but not combined with them. Study hybrid agents that choose between latent reasoning and external tools, including learned routing, uncertainty-based selection, and cost-aware policies.
- Multi-turn and interactive settings: Monet is evaluated on single-pass QA. Investigate multi-turn dialogue, visual revisitation, memory across turns, and latent-state persistence or summarization over long interactions.
- Granularity and automation of observation-token selection: The current approach highlights discrete tokens. Explore span-level, phrase-level, or structured supervision (e.g., semantic roles), and automatic selection via learned detectors to reduce dependence on external LLM judges.
- Statistical rigor and error analysis: Results lack confidence intervals, significance tests, and detailed failure-case analyses. Provide variance across seeds, per-category breakdowns, and qualitative error taxonomies to guide targeted improvements.
- Reproducibility issues in data curation: The paper mentions Monet-SFT-125K and Monet-SFT-152K inconsistently. Clarify dataset size, release full curation scripts, judges’ prompts/criteria, and provenance to ensure replication.
- Information leakage and shortcut prevention: “Latent-only backpropagation” reduces shortcuts, but there is no formal analysis of leakage paths (e.g., via residual connections). Develop diagnostics to verify that optimization truly improves latent representations rather than hidden shortcuts.
- Latent embedding design choices: Latents reuse decoder hidden states; alternative designs (separate latent head, different dimensionality, learned latent codebooks) are unexplored. Evaluate architectural variants that may improve capacity, stability, or interpretability.
- Per-task adaptive K selection and curricula: Accuracy peaks at different K_test by task, but the model does not learn this. Design curricula and meta-controllers that predict K or halt based on confidence/progress signals.
- Dataset composition and bias: Monet-SFT-125K is heavily sourced from Visual-CoT with relatively few geometry/3D/counting items. Quantify domain imbalance and study its effect on learned latent skills; curate balanced datasets or targeted augmentations.
- VLPO–KL interaction and regularization for latents: The GRPO-style KL term is defined for text tokens; its effect on latent tokens is unclear. Formalize KL regularization for continuous latent actions to prevent policy collapse or overfitting.
- Finer-grained intermediate evaluation: Beyond final-answer accuracy, introduce checks for intermediate visual observations (e.g., grounding correctness, spatial relations) to validate that latent embeddings carry the intended visual information.
Glossary
- Accuracy reward: A scalar reward that gives 1 for a correct answer and 0 otherwise to guide RL optimization. "We use an accuracy reward (1 for a correct answer; 0 otherwise)"
- Advantage: The per-step, normalized reward signal used in policy-gradient updates, computed from outcome rewards. " is the advantage computed based on the outcome rewards of the responses"
- Alignment loss: A training objective that aligns hidden representations (e.g., of observation tokens) across different conditions to improve consistency. "maximize their cosine similarity through the alignment loss:"
- Attention mask: A matrix controlling which tokens/embeddings can attend to others during transformer inference and training. "apply a modified attention mask that allows these image embeddings to be attended only by the latent embeddings"
- Autoregressive decoding: Generating outputs step-by-step where each step conditions on previously generated content. "autoregressively-generated latent embeddings"
- Auxiliary images: Additional images inserted into intermediate reasoning steps to provide visual evidence. "the incorporation of auxiliary images in the intermediate steps of chain-of-thought (CoT)"
- Chain-of-thought (CoT): An explicit sequence of reasoning steps produced by a model to reach an answer. "chain-of-thought (CoT) can improve the visual reasoning of multimodal LLMs (MLLMs)"
- Clip function: The PPO-style operation that bounds policy ratios to stabilize RL updates. "\operatorname{clip}\left(r_{i,t}(\theta), 1-\varepsilon, 1+\varepsilon\right)"
- Controlled attention flow: A design that constrains how visual information passes via attention (e.g., image → latent → observation). "through a controlled attention flow."
- Cosine similarity: A measure of orientation similarity between vectors used to align representations. "maximize their cosine similarity through the alignment loss:"
- Decoder: The part of a transformer that generates outputs; its last-layer representation can be fed back as the next input embedding. "the representation from the last layer of the MLLM decoder is fed back as the next input embedding."
- Distillation-based supervised fine-tuning (SFT): A teacher–student training pipeline where supervision is transferred from a teacher to a student under SFT. "a three-stage distillation-based supervised fine-tuning (SFT) pipeline."
- Format reward: A reward that encourages outputs to follow a desired format (e.g., math answers boxed). "a format reward encouraging the model to place the final answer in ``\verb|\boxed{}|''."
- GRPO: Group Relative Policy Optimization, an RL algorithm applied to text tokens that can miss optimizing latent steps. "We further reveal a limitation of applying GRPO to latent reasoning"
- Grounding: A visual tool/task that maps textual references to image regions (e.g., bounding boxes). "invoking visual tools such as grounding or depth estimation models"
- Hidden representations: Internal vector states of tokens across layers that encode semantic/visual information. "align the hidden representations of observation tokens under these two conditions."
- Interleaved chain-of-thought: Reasoning sequences that mix image and text segments step-by-step. "imageâtext interleaved CoTs"
- KL divergence: A regularization term that penalizes divergence from a reference policy in RL. "-\beta \operatorname{K L}\left(\pi_\theta | \pi_{\text{ref}\right)"
- Latent embeddings: Continuous vectors generated by the model that act as intermediate visual thoughts. "generating continuous embeddings that function as intermediate visual thoughts"
- Latent Gaussian distribution: A probabilistic model treating latent embeddings as samples from a Gaussian for computing action probabilities. "model $\mathbf{h}^{\text{old}_{i,t}$ as a sample drawn from a latent Gaussian distribution"
- Latent-only backpropagation: Restricting gradient flow so alignment losses update only latent embeddings, preventing shortcuts. "we restrict gradient flow from $\mathcal{L}_{\text{align-obs}$ to pass solely through the generated latent embeddings"
- Latent visual space: A continuous, internal representation space where visual reasoning occurs without explicit images. "reason directly within the latent visual space"
- Mean pooling: Averaging token embeddings to compress sequences, which may distort fine-grained features. "using mean pooling to compress the image tokens"
- MLLM (Multimodal LLM): A large model that processes and reasons over multiple modalities (e.g., text and images). "multimodal LLMs (MLLMs)"
- Next-token prediction (NTP): The standard language modeling objective to predict the next token given context. "applying a next-token prediction (NTP) loss on text tokens during supervised fine-tuning (SFT)"
- Observation tokens: Specific text tokens that describe crucial visual findings used to supervise latent alignment. "text tokens corresponding to crucial visual observations"
- Out-of-distribution (OOD) generalization: The ability to perform well on data and tasks not seen during training. "strong out-of-distribution generalization on challenging abstract visual reasoning tasks"
- Policy gradient: RL optimization that adjusts model parameters to increase expected reward via gradients of action probabilities. "explicitly incorporates latent embeddings into policy gradient updates"
- Reference model: A fixed or slowly-updating model used in KL regularization to stabilize RL training. "$\pi_{\text{ref}$ is the reference model."
- Reinforcement learning (RL): Training via reward-driven optimization of policies for sequences of actions or tokens. "a reinforcement learning method that explicitly incorporates latent embeddings"
- Rollout: The process of generating trajectories/responses from a policy to compute rewards and updates. "latent embeddings collected during rollout"
- Teacher–student model: A training setup where a teacher provides signals that the student learns to mimic or align with. "We initialize both a teacher and a student model"
- VLMEvalKit: A standardized toolkit for evaluating multimodal LLMs across benchmarks. "We adopt the VLMEvalKit framework for fair evaluation."
- VLPO (Visual-latent Policy Optimization): An RL method that assigns probabilities to continuous latent embeddings for direct optimization. "we propose VLPO (\underline{V}isual-\underline{l}atent \underline{P}olicy \underline{O}ptimization), a reinforcement learning method"
Practical Applications
Immediate Applications
The following applications can be deployed now by adapting the paper’s training/inference recipes (three-stage SFT, VLPO), codebase, and dataset (Monet-SFT-125K). They benefit from Monet’s ability to reason in a continuous latent visual space without calling external visual tools, which reduces latency and tool-chain fragility.
- Industry — Document, form, and receipt understanding (finance, insurance, logistics, public sector)
- What: Question answering, validation, and extraction over scanned documents, ID cards, invoices, bills of lading, and claims photos; cross-checking numbers and entities referenced in accompanying charts or tables.
- Why Monet: Strong chart/OCR and real-world perception gains; “latent visual thoughts” obviate explicit cropping and tool invocations, reducing latency and error modes from brittle toolchains.
- Tools/Products/Workflows: “Latent Visual Reasoning OCR Assistant” API; RPA nodes that accept screenshot/image input and produce verified fields plus explanations; server-side inference with adjustable latent length K.
- Assumptions/Dependencies: Sufficient image resolution; domain-specific evaluation sets; on-prem GPU or secure cloud; base backbone (e.g., Qwen2.5-VL-7B) licensing; guardrails for sensitive PII handling.
- Industry — Business Intelligence and dashboard QA (finance, energy, operations)
- What: Natural-language Q&A over charts/dashboards; anomaly explanations; consistency checks between numbers and visuals.
- Why Monet: Outperforms baselines on chart/real-world benchmarks; works without external chart parsers or cropping tools.
- Tools/Products/Workflows: “ChartQA Copilot” embedded in BI platforms; nightly report verification; screenshot-to-insight bots for legacy dashboards.
- Assumptions/Dependencies: Domain-specific chart types (waterfalls, treemaps) may require light finetuning; reliable screenshot capture; answer-format validation.
- Software — Screen-reading and UI agents
- What: Agents that reason over application UIs (buttons, dialogs, tables) to navigate workflows, validate states, and troubleshoot based on screenshots.
- Why Monet: Latent reasoning allows selective internal “focus” without bounding-box prediction or tool orchestration; lower end-to-end latency.
- Tools/Products/Workflows: “Latent UI Agent” SDK with <latent></latent> decoding and K control; replay-logs of latent embedding segments for debugging.
- Assumptions/Dependencies: Consistent UI theming; permissioned screenshot capture; robustness to localization and theming variants.
- Customer support — Image triage and guidance
- What: Intake and triage of customer-provided photos (e.g., device screens, labels, receipts); step-by-step instructions using visual evidence.
- Why Monet: Better perception/reasoning without external tool calls; works across diverse real-world images.
- Tools/Products/Workflows: Support portal widget with image Q&A; escalation triggers based on confidence/format rewards.
- Assumptions/Dependencies: Domain adaptation for device classes; error-handling policies; latency budgets.
- Education — Geometry/diagram reasoning and math tutoring
- What: Explanations of diagram-based problems, geometry constructions, and visual puzzles; hints grounded in inferred visual features.
- Why Monet: Trained on interleaved CoTs (including geometric and visual-logic tasks); exhibits OOD improvements on VisualPuzzles.
- Tools/Products/Workflows: “Latent Geometry Tutor” that produces text-plus-latent steps; auto-grading of student diagrams with visual justifications.
- Assumptions/Dependencies: Age-appropriate safety policies; curriculum-aligned prompts; explainability expectations.
- Accessibility — Assistive reading of complex visual materials
- What: Reading and explaining forms, charts, signage, or infographics for visually impaired users on mobile or wearable devices.
- Why Monet: Reduced reliance on external tools lowers privacy risks and latency; robust to diverse layouts.
- Tools/Products/Workflows: Mobile app with local/cloud inference; configurable latent length K for device constraints.
- Assumptions/Dependencies: On-device acceleration or efficient server; language coverage; content safety filters.
- ML/AI Engineering — Latent RL and training utilities
- What: Use VLPO to optimize continuous latent steps in any MLLM; reuse Monet-SFT-125K and the three-stage SFT pipeline to build better image–text CoTs.
- Why Monet: VLPO directly optimizes latent embeddings (GRPO cannot); the SFT pipeline delivers higher-quality latent targets and supervision.
- Tools/Products/Workflows: “VLPO Trainer” module; “Observation-token alignment” loss; controlled attention masks (image→latent→observation).
- Assumptions/Dependencies: Compute budget for multi-stage SFT; selection of σ hyperparameter in VLPO; monitoring for reward hacking.
- Compliance/Policy Operations — On-prem visual reasoning with reduced data movement
- What: Process sensitive images (IDs, contracts, health forms) within secured environments without third-party tool calls.
- Why Monet: Latent in-model reasoning shortens tool chains and lowers leakage risk vectors.
- Tools/Products/Workflows: On-prem inference service with auditable logs (including format rewards and answer boxing); privacy assessments citing reduced external calls.
- Assumptions/Dependencies: Internal MLLM deployment maturity; security reviews; traceability requirements.
- Data curation/Labeling — Higher-quality image–text CoT dataset construction
- What: Adopt the paper’s three-stage curation (necessity filtering, correctness checks via stronger models, observation-token highlighting) to improve training data.
- Why Monet: Demonstrated that such filtering makes auxiliary images necessary and accurate, and highlights key tokens for stronger supervision.
- Tools/Products/Workflows: “CoT Curation Pipeline” using LLM judges and solvability filters; dataset QA dashboards.
- Assumptions/Dependencies: Access to strong LLM judges; cost of multi-pass filtering; IP/licensing of sources.
Long-Term Applications
These require further research, scaling, safety evaluation, or domain-specific training before real-world deployment.
- Healthcare — Visual reasoning over medical images (radiology, pathology)
- What: Derive intermediate visual “thoughts” for lesion localization, measurement reasoning, and report grounding.
- Why Monet: Internal visual latent steps could reduce dependence on specialized toolchains and might generalize better to novel presentations.
- Tools/Products/Workflows: “Latent Clinical Reader” with certified pipelines; clinician-in-the-loop UIs showing latent steps.
- Assumptions/Dependencies: Regulatory approvals; extensive domain finetuning; rigorous bias/safety audits; explainability and traceability of latent steps.
- Robotics/Autonomy — Latent visual planning and spatial reasoning
- What: Closed-loop perception–reasoning for manipulation/navigation using internal latent visual steps rather than external detectors.
- Why Monet: VLPO generalizes policy optimization to continuous latent actions, a natural fit for learning visual subgoals.
- Tools/Products/Workflows: Multimodal control stacks where latent segments condition downstream planners; sim-to-real curricula with VLPO.
- Assumptions/Dependencies: Real-time constraints; safety-critical validation; sensor fusion; robustness to distribution shift.
- Scientific imaging — Microscopy, astronomy, remote sensing
- What: Hypothesis-driven reasoning over complex images (e.g., counting, morphology, pattern detection) with interpretable intermediate visual states.
- Why Monet: OOD gains suggest potential for abstract pattern reasoning across unfamiliar domains.
- Tools/Products/Workflows: “Latent Lab Assistant” integrated with ELN/LIMS; provenance logging of latent segments for scientific audit.
- Assumptions/Dependencies: Domain datasets and ground-truth; uncertainty quantification; collaboration with domain experts.
- AR/Field operations — Visual task guidance without external tool orchestration
- What: Construction/maintenance assistance using head-mounted cameras; reasoning about schematics, panels, and spatial constraints on-device.
- Why Monet: Tool-free latent reasoning reduces end-to-end latency and connectivity requirements.
- Tools/Products/Workflows: AR overlays driven by latent visual steps; offline inference with smaller backbones.
- Assumptions/Dependencies: Robustness to lighting/occlusions; model compression; safety and human-factors testing.
- Public-interest analytics — Auditing charts in reports and media for misleading visuals
- What: Detect inconsistencies, misleading scales, or cherry-picked ranges in public documents.
- Why Monet: Chart/OCR strengths and OOD reasoning could flag suspect visual rhetoric.
- Tools/Products/Workflows: “Chart Audit Bot” for regulators/newsrooms; evidence packages that cite latent steps.
- Assumptions/Dependencies: Agreed-upon criteria for “misleading”; human oversight; risk of false positives and reputational impacts.
- Explainability and safety — Visualizing latent steps for trust and debugging
- What: Map latent embeddings to approximated visual proxies or attention heatmaps to explain internal visual thoughts.
- Why Monet: Latent steps are central to the method; making them interpretable can improve trust and debugging.
- Tools/Products/Workflows: “Latent-Explainer” toolkit that visualizes image→latent→observation flows; red-teaming probes on latent misuse.
- Assumptions/Dependencies: New visualization methods; potential leakage of proprietary representations; trade-offs with performance.
- Foundation model platforms — Generalized RL for continuous thoughts
- What: Extend VLPO beyond vision to optimize continuous latent “thinking” in text or multimodal LMs (e.g., soft tokens, tool-selection vectors).
- Why Monet: Shows how to assign probabilities to latent vectors for policy gradients.
- Tools/Products/Workflows: “VLPO-as-a-Service” training backend; policy libraries with configurable σ and mixed discrete/continuous action spaces.
- Assumptions/Dependencies: Community adoption; stability with longer latent segments; reward design beyond answer accuracy.
- Industrial monitoring — Reasoning over camera feeds and HMI panels
- What: Cross-validate dial readings, trend charts, alarms, and procedures across multiple displays for anomaly triage.
- Why Monet: Internal latent attention could replace bespoke detectors in heterogeneous plants.
- Tools/Products/Workflows: “Control-Room Copilot” that ingests multi-screen snapshots; incident timelines with latent reasoning states.
- Assumptions/Dependencies: Real-time performance and safety; domain adaptation; integration with control systems.
- Privacy-preserving on-device assistants
- What: Offline reasoning over personal documents and photos on mobile/edge devices.
- Why Monet: Eliminates external tool calls; model can run fully locally as hardware improves.
- Tools/Products/Workflows: Quantized smaller backbones with latent decoding; adaptive K based on device budget.
- Assumptions/Dependencies: Hardware NPUs; memory constraints; energy usage; careful failure handling.
- Data ecosystem — Weakly supervised CoT generation at scale
- What: Port the three-stage curation pipeline (necessity, correctness, token highlighting) to new domains (e.g., medical, legal).
- Why Monet: Demonstrated better supervision for latent training than naïve interleaved CoTs.
- Tools/Products/Workflows: Automated curation services with LLM judges; quality scoring based on “observation token” predictability.
- Assumptions/Dependencies: Access to expert or very strong LLM judges; cost and governance; IP/sourcing compliance.
Cross-cutting assumptions and dependencies to consider
- Training complexity: Multi-stage SFT plus RL (VLPO) requires significant compute, careful masking, and latent-only backprop for alignment losses.
- Model generalization: Results are shown on Qwen2.5-VL-7B; performance and stability must be validated for other backbones/sizes and languages.
- Reward design: Current RL rewards emphasize final-answer accuracy and formatting; richer, task-specific rewards may be needed for safety-critical domains.
- Latent length K: Performance is sensitive to K; deploying adjustable K with monitoring is recommended.
- Interpretability: Latent embeddings are not inherently human-interpretable; additional tooling is needed where audits are required.
- Safety: OOD gains are promising but not guarantees; human-in-the-loop and fail-safes are essential in regulated/high-stakes settings.
Collections
Sign up for free to add this paper to one or more collections.