Visual Generation Unlocks Human-Like Reasoning through Multimodal World Models
Abstract: Humans construct internal world models and reason by manipulating the concepts within these models. Recent advances in AI, particularly chain-of-thought (CoT) reasoning, approximate such human cognitive abilities, where world models are believed to be embedded within LLMs. Expert-level performance in formal and abstract domains such as mathematics and programming has been achieved in current systems by relying predominantly on verbal reasoning. However, they still lag far behind humans in domains like physical and spatial intelligence, which require richer representations and prior knowledge. The emergence of unified multimodal models (UMMs) capable of both verbal and visual generation has therefore sparked interest in more human-like reasoning grounded in complementary multimodal pathways, though their benefits remain unclear. From a world-model perspective, this paper presents the first principled study of when and how visual generation benefits reasoning. Our key position is the visual superiority hypothesis: for certain tasks--particularly those grounded in the physical world--visual generation more naturally serves as world models, whereas purely verbal world models encounter bottlenecks arising from representational limitations or insufficient prior knowledge. Theoretically, we formalize internal world modeling as a core component of CoT reasoning and analyze distinctions among different forms of world models. Empirically, we identify tasks that necessitate interleaved visual-verbal CoT reasoning, constructing a new evaluation suite, VisWorld-Eval. Controlled experiments on a state-of-the-art UMM show that interleaved CoT significantly outperforms purely verbal CoT on tasks that favor visual world modeling, but offers no clear advantage otherwise. Together, this work clarifies the potential of multimodal world modeling for more powerful, human-like multimodal AI.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper explores a simple idea: people often think using both words and pictures in their minds. Current AI mostly “thinks” with words. The authors ask whether AI can reason more like humans if it also “thinks” with pictures it generates itself. They argue that for tasks tied to the physical world—like tracking objects, understanding shapes, or imagining different viewpoints—visual thinking can be better than only using words.
Objectives and Questions
The paper sets out to answer a few clear questions in an easy-to-understand way:
- When does making and using images during reasoning help an AI solve problems?
- How exactly should an AI combine words and images while thinking step by step?
- Can we create fair tests to measure whether visual thinking really improves reasoning?
Methods and Approach
To make these ideas concrete, the authors do three main things.
Key ideas behind “world models”
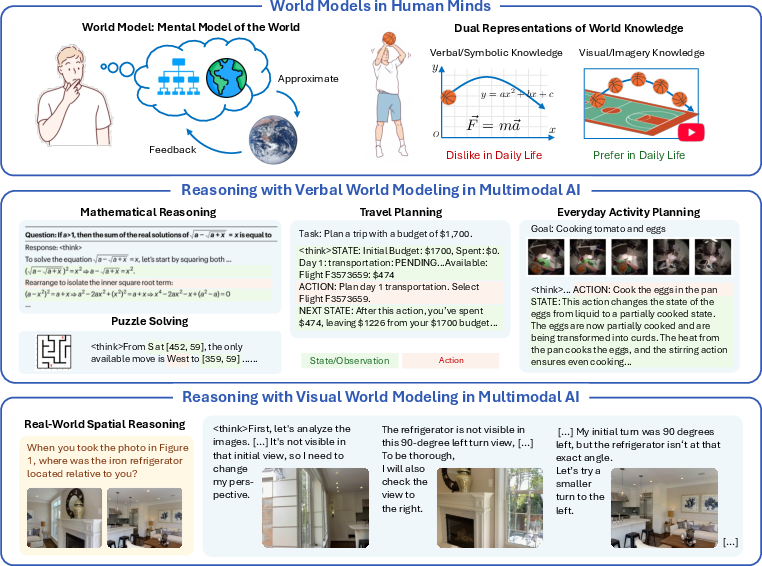
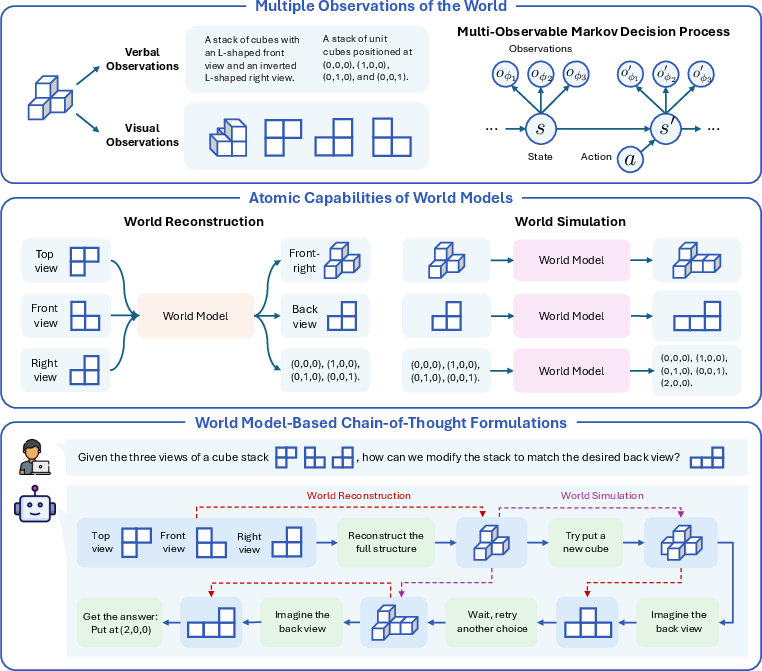
Think of a “world model” like the mental map you build of a situation. For example, when you see a maze, you imagine paths and turns in your head. The paper says a good world model has two basic abilities:
- World reconstruction: Fill in missing details and imagine new views. Like seeing the front of a Lego tower and guessing what the backside looks like, then mentally rotating it to see that backside.
- World simulation: Predict what will happen next. Like imagining where a ball will bounce after it hits a wall.
Current AI often relies on “chain-of-thought” (CoT), a step-by-step explanation in words. The authors introduce an “interleaved” CoT that mixes words and pictures: at each step, the AI not only writes what it thinks but also generates an image to keep track of the situation, like a visual scratchpad.
They propose the “visual superiority hypothesis”: on tasks grounded in the physical world, visuals are often more informative than words and carry useful real-world knowledge learned from images and videos.
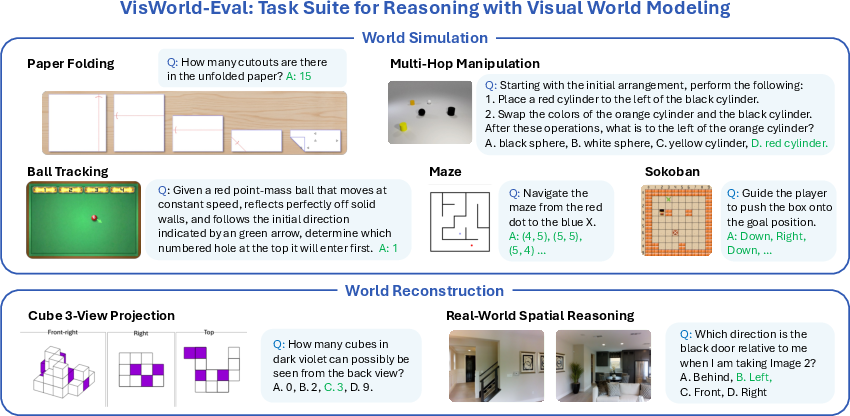
Building tests: the VisWorld-Eval suite
To test these ideas fairly, they created a bundle of seven tasks that each need either reconstruction or simulation:
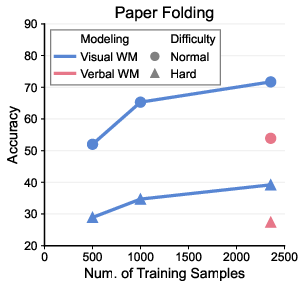
- Paper folding: Predict where holes will appear after unfolding a folded, punched paper.
- Multi-hop manipulation: Track changes to objects (add, remove, recolor) and their spatial relations across several steps.
- Ball tracking: Predict which hole a bouncing ball will enter after reflecting off walls.
- Maze and Sokoban: Classic grid puzzles involving simple state tracking and movement.
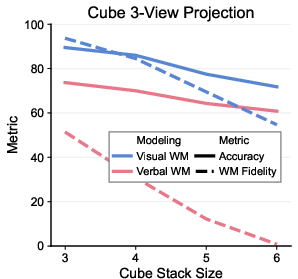
- Cube 3-view projection: Given a few views of stacked cubes, infer another unseen view.
- Real-world spatial reasoning (MMSI): Infer positions of cameras, objects, and regions from multiple photos.
Models and training
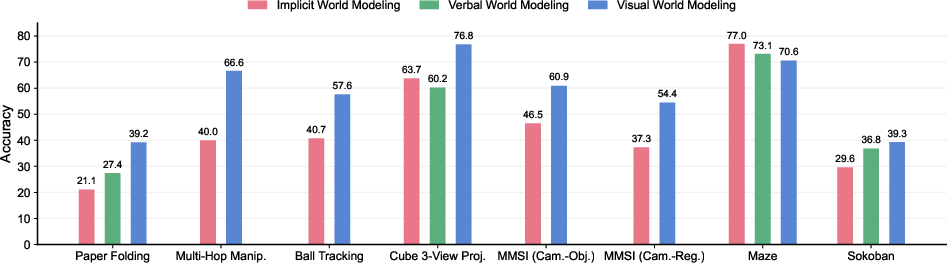
The authors use a strong open-source unified multimodal model (UMM) called BAGEL that can both write and generate images. They fine-tune it on examples of step-by-step reasoning in three styles:
- Implicit CoT: Only words, no explicit tracking of states.
- Verbal CoT: Words that explicitly track the state (like coordinates or grids).
- Interleaved CoT: Words plus generated images at each step.
They compare how well each style works on different tasks.
Main Findings
Here are the key results in a compact form:
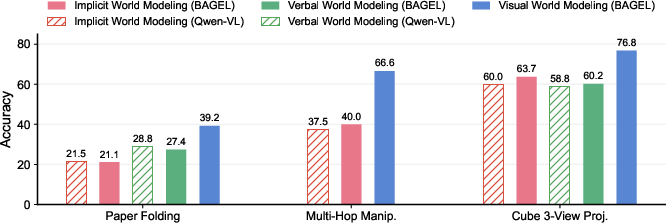
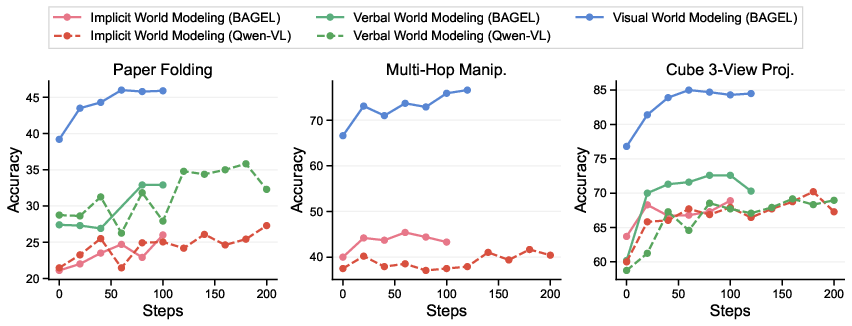
- Visual thinking helps on physical and spatial tasks. Interleaved CoT (words + images) beats purely verbal CoT in paper folding, multi-hop manipulation, ball tracking, cube 3-view, and parts of real-world spatial reasoning. Why? Pictures are rich and precise, making it easier to track shapes, symmetry, motion, and space.
- Visual thinking is more sample-efficient. On paper folding, the mixed approach reaches similar accuracy using over 4× less training data than purely verbal reasoning, suggesting visuals carry stronger prior knowledge learned from images/videos.
- Not all tasks need visuals. For simple grid puzzles like mazes and Sokoban, visual generation did not help. The task states are tiny (often just one or two coordinates), so words are enough.
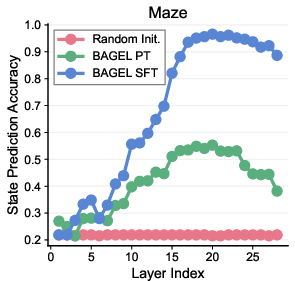
- Emergent “implicit” world modeling. Even without explicitly tracking positions, the model’s hidden layers learned to represent maze states internally. Probes showed the model could recover masked coordinates from its internal representations—explaining why verbal-only reasoning can already be strong on simple tasks.
- Fidelity matters. On cube 3-view, the visual scratchpad’s intermediate images stayed structurally correct much more often than verbal descriptions, which tended to drift or hallucinate. This shows visuals can keep the model “grounded” during multi-step reasoning.
Why This Matters
These findings suggest that adding a visual pathway helps AI reason more like people on tasks tied to the physical world. Words can be vague or miss fine details (like exact shapes and motions), while pictures offer concrete, detailed information and tap into knowledge learned from the massive visual content on the internet.
Implications and Impact
If future AI systems use interleaved words and images when thinking:
- Robotics and planning could improve, because the AI can internally simulate how objects move and interact.
- Education and tutoring might get smarter visual explanations, like showing step-by-step diagrams alongside text.
- Scientific and engineering tools could benefit from clearer visual reasoning, such as mentally “rotating” molecules or simulating physical processes.
- User-facing assistants could become better at spatial tasks: interior design, navigation instructions, or image-based problem solving.
In short, this work shows a practical path toward more human-like reasoning in AI: let models think in pictures as well as words, and choose visuals when the problem is about the physical world.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The following points summarize what remains missing, uncertain, or unexplored, focusing on concrete directions future researchers can act on:
- Generality across models: Results are demonstrated primarily on a single open-source UMM (BAGEL). It remains unclear whether the observed benefits of interleaved visual-verbal CoT hold across architectures (autoregressive visual tokens vs. diffusion/flow), scales, and pretraining regimens.
- Scope of evaluation tasks: VisWorld-Eval includes seven tasks with synthetic settings and constrained dynamics. There is no assessment on richer, continuous, or noisy physical processes (e.g., friction, deformable objects, occlusion, partial observability) or on real-world embodied/interactive tasks (robotics, manipulation, navigation).
- Video vs. image generation: The paper focuses on image-based observations for visual world modeling. It remains unknown whether video generation (temporal coherence) would improve simulation-heavy tasks or reduce hallucinations relative to images.
- Objective for visual learning in RL: RLVR optimizes verbal outputs only; visual generations are regularized via KL to SFT. The field lacks methods and evidence for end-to-end RL on visual reasoning steps (e.g., optimizing image/video intermediates against task rewards).
- Quantifying “informativeness” and “prior knowledge”: Theoretical bounds invoke mutual information and distribution-shift arguments but are not empirically estimated. Methods to measure modality-specific informativeness and pretraining-aligned priors in practice are missing.
- Decision policies for when to generate visuals: There is no mechanism to decide adaptively when visual steps should be inserted, at what granularity, or which view parameters φ to synthesize. Learning or planning view-selection policies is left unexplored.
- Robustness and calibration of visual steps: The fidelity evaluation (e.g., cube 3-view) ignores color and uses simple shape matching. Systematic metrics for step-level correctness, robustness to perturbations (noisy inputs, occlusions), and calibration of intermediate visual states are not provided.
- Hallucination characterization: While visual steps are claimed to reduce hallucinations, the paper does not quantify hallucination rates or define failure taxonomies for visual vs. verbal world modeling across tasks.
- Cost–benefit trade-offs: The computational overhead, latency, and memory cost of generating visual intermediates are not characterized against accuracy improvements; there is no guidance on when the cost is justified.
- Scale and data efficiency: Sample-efficiency results are provided only for paper folding with SFT. Scaling laws for interleaved CoT (data size, CoT length, image resolution, number of steps) and their interaction with pretraining priors are unknown.
- Tool-augmented verbal baselines: Verbal baselines do not use external tools (e.g., geometry engines, physics simulators, spatial planners). It is unclear whether tool-using verbal systems could close the gap without visual generation.
- Alternative structured world models: The paper compares images vs. free-text. Intermediate structured representations (graphs, 3D occupancy grids, programmatic spatial DSLs) are not explored as potentially more faithful and sample-efficient world models.
- Generalization tests: Out-of-distribution evaluation is limited (e.g., cube stacks of size six only). Broader OOD tests across scene complexity, camera configurations, and dynamics are needed to validate the visual superiority hypothesis.
- Interactive reasoning and planning: Tasks are static QA. It remains unknown how interleaved visual CoT performs in interactive settings with actions affecting future observations (closed-loop planning, exploration, backtracking).
- Emergent implicit world models: Probing results are shown for 5×5 mazes; it is unclear whether implicit state tracking emerges in larger mazes, Sokoban variants, or more complex spatial/physical tasks, and how such internal states compare to explicit visual sketches.
- View-parameter grounding: The formulation treats view selection via φ, but the implementation does not validate whether models correctly infer and control φ (camera pose, projection type) or learn policies to choose informative viewpoints.
- CoT format sensitivity: There is no ablation on prompt templates, CoT length, image count per step, resolution, or image style (sketches vs. photorealistic) to determine which interleaved designs are most effective.
- Failure analyses in MMSI-Bench: The paper reports mixed gains on positional-relationship subtasks but lacks granular error analyses to pinpoint whether failures stem from spatial understanding, generation quality, or alignment issues.
- Measuring prior alignment: The claim that visual pretraining provides richer priors is plausible but untested; quantifying modality-specific distribution shift between pretraining and downstream tasks, and correlating it with sample efficiency, is an open problem.
- Unified objectives for reasoning + generation: Beyond SFT and RLVR, joint training objectives that explicitly couple reasoning correctness and visual fidelity (e.g., differentiable consistency checks between the verbal plan and generated images) are missing.
- Multi-modality beyond vision: The MOMDP formalism supports multiple observation modalities, but the paper focuses on vision and language only. The role of audio, haptics, or depth in world modeling and reasoning remains unexamined.
- Safety and reliability: There is no evaluation under adversarial or ambiguous inputs, nor analyses of failure modes that could lead to unsafe plans in physical tasks.
- Data provenance and annotation quality: Construction of CoT datasets (especially for visual steps) may introduce biases or leak solution heuristics. Methods to audit, standardize, and verify interleaved CoT annotations are needed.
- Benchmarks and metrics: Accuracy on final answers dominates evaluation. Benchmarks for step-level correctness, consistency across steps, and “world-model fidelity” under realistic scoring (e.g., 3D IoU, physics consistency) are lacking.
- Combining implicit and explicit world models: The paper suggests implicit models can be sufficient for simple tasks but does not explore hybrid approaches that switch between implicit state tracking and explicit visual sketches as task complexity changes.
- Role of video priors and motion knowledge: Physical tasks (ball tracking, paper folding) likely benefit from motion priors learned from video. The contribution of video vs. image pretraining is not isolated or quantified.
- Transfer learning across tasks: Whether interleaved CoT trained on one world-model capability (simulation vs. reconstruction) transfers to others, and how to compose skills, remains open.
- Human alignment and cognitive plausibility: Dual-coding theory motivates the approach, but there is no direct comparison with human performance or studies of cognitive plausibility (e.g., do models adopt similar viewpoint strategies or sketching behaviors?).
- Reproducibility and openness: While the benchmark is released, full training datasets, interleaved CoT templates, and pre/post-training checkpoints for all tasks are not detailed; reproducibility of the reported gains may be challenging.
- Formal assumptions: Theoretical results depend on assumptions (e.g., optimal CoTs, latent-state associations) that are not validated or stress-tested; practical procedures to approximate the required quantities (entropies, mutual information) are missing.
Practical Applications
Below are practical, real-world applications grounded in the paper’s findings, methods, and innovations. Each item names the main use case, cites relevant sectors, and notes feasibility considerations.
Immediate Applications
The following can be deployed now with current unified multimodal models (UMMs) and existing tooling, especially for offline or human-in-the-loop workflows, benchmarking, and domain-specific fine-tuning.
- Capability benchmarking and procurement audits using VisWorld-Eval (industry, academia, policy)
- Use case: Adopt the released VisWorld-Eval tasks (paper folding, ball tracking, cube 3-view, MMSI positional relations, etc.) to map when visual world modeling helps; integrate into CI/ML-Ops to gate model releases and vendor selection.
- Tools/products/workflows: A “VisWorld-Eval harness” for CI pipelines; model cards with section on “visual-world-modeling gains vs. verbal CoT”; internal dashboards tracking task-level deltas.
- Assumptions/dependencies: Access to the benchmark; reproducible prompting and decoding; task-matched evaluation data; compute budget for interleaved visual generation during tests.
- Visual scratchpad plugin for agentic systems in spatial/physical tasks (software, robotics R&D, education)
- Use case: Enable interleaved visual–verbal chain-of-thought (CoT) for tasks that the paper shows benefit from visual world modeling (e.g., unfolding/packaging steps, basic physics trajectories, camera–object relationships).
- Tools/products/workflows: Agent framework extension that calls a visual generator for intermediate “mental images”; workspace UIs for displaying intermediate frames; a routing flag to switch between pure verbal vs visual-interleaved CoT per task.
- Assumptions/dependencies: UMMs with reliable image generation; content-safety filters; latency budgets for generation; guidance prompts curated per task to avoid off-topic images.
- Task-specific SFT with interleaved visual CoT for higher sample efficiency (industry R&D, academia)
- Use case: Fine-tune models with visual steps on tasks analogous to paper folding (fold/unfold logic, symmetry), multi-hop object manipulation, and ball reflection/trajectory prediction to reach higher accuracy with fewer samples.
- Tools/products/workflows: SFT pipelines that include image tokens in CoT; small curated datasets emphasizing world reconstruction or simulation; lightweight RLVR for verifiable text-answer optimization while KL-regularizing visuals.
- Assumptions/dependencies: Availability of verifiable final answers; curated interleaved CoT data; compute for visual generation losses; careful prompt templates to reduce hallucination.
- Model selection and routing: Decide when to “turn on” visual world modeling (platform providers, enterprise AI teams)
- Use case: Train a meta-policy to detect representational bottlenecks (e.g., rich geometry, symmetries, reflections) and insufficient verbal priors, and activate visual CoT only then; keep verbal/implicit CoT for simple grid or symbolic tasks (maze, Sokoban).
- Tools/products/workflows: Router that uses task tags or lightweight probes; per-request budgeter that considers accuracy-vs-latency trade-offs; A/B tests on downstream KPIs.
- Assumptions/dependencies: Accurate task classification; telemetry on latency/cost; fallback paths when visual generation degrades performance.
- Probing toolkits for implicit world models (academia, ML-Ops)
- Use case: Reproduce the paper’s probe methodology to detect emergent internal state tracking (e.g., in mazes) without explicit coordinate supervision; use for diagnosis/ablation.
- Tools/products/workflows: Probe training scripts (MLPs over hidden states for masked tokens); layer-wise analysis reports; alerts for regressions in internal state fidelity after fine-tunes.
- Assumptions/dependencies: Access to internal activations; careful data partitioning to avoid leakage; security review for model introspection in production.
- Transparent UIs with visual rationales for spatial reasoning (industry, policy, consumer apps)
- Use case: Show intermediate generated images alongside text reasoning to improve auditability, user trust, and error triage in spatial/physical decisions (e.g., safety reviewers, customer support explaining a geometry answer).
- Tools/products/workflows: “Visual rationale pane” in assistant UIs; review workflows that compare intermediate visuals to ground truth (when available); logging for post-hoc analysis.
- Assumptions/dependencies: Controls to prevent sensitive visual content; clear disclaimers that these are model-generated “mental images,” not ground truth.
- STEM tutoring with interleaved visual reasoning (education)
- Use case: Generate step-by-step visuals for geometry, spatial transformations, kinematics; match the paper’s dual-coding motivation to improve understanding and memory.
- Tools/products/workflows: Courseware plugins rendering intermediate frames; teacher dashboards to compare learner CoT vs model CoT; content alignment to curricula (e.g., symmetry, reflections, projections).
- Assumptions/dependencies: Pedagogical validation; guardrails against mistakes and hallucinations; accessibility features for diverse learners.
- Design review aids for packaging/origami-like structures (manufacturing, AEC, product design)
- Use case: Quickly simulate fold/unfold patterns, check symmetry outcomes, and validate hole/feature placement through generated intermediate views before CAD/FEA.
- Tools/products/workflows: “Visual preflight” checks; plug-in for PLM/CAD review that proposes interleaved visual steps; issue trackers with snapshots of the model’s predicted unfolding sequence.
- Assumptions/dependencies: Not a substitute for physics-grade simulation; needs human oversight; domain-specific prompts and exemplars to reduce false visuals.
- Photography/AR scene assistance via camera–object positional reasoning (media, AR/VR)
- Use case: Given multiple views, predict relative camera/object/region relations and propose better vantage points or compositions.
- Tools/products/workflows: Mobile app hints with rough generated previews; studio planning tools for shot lists; AR overlays with suggested camera movement.
- Assumptions/dependencies: Robustness to real-world noise; camera pose estimation integration; latency limits on-device.
Long-Term Applications
These require stronger base UMMs, broader pretraining with multimodal priors, scalable interleaved datasets, or real-time visual generation with safety guarantees.
- Embodied robotic planning with visual scratchpads (robotics, logistics, home assistance)
- Use case: Robots mentally “simulate” manipulation steps via generated visuals to plan grasps, placements, and multi-step rearrangements in cluttered scenes.
- Tools/products/workflows: Visual world model layer integrated with motion planners; failure prediction from visual rollouts; operator monitors for intermediate frames.
- Assumptions/dependencies: Real-time generation; accurate dynamics priors beyond simple scenes; tight sensor-model alignment; safety certifications.
- Autonomy and ADAS scene forecasting with interleaved CoT (automotive, drones)
- Use case: Interleave text policy constraints with generated future scene frames to reason about multi-agent motion, occlusions, and corner cases.
- Tools/products/workflows: Visual rollout modules fused with classical trajectory prediction; uncertainty quantification; regulatory reporting with visual rationales.
- Assumptions/dependencies: High-fidelity, temporally consistent generation; calibrated uncertainty; compliance with safety and interpretability regulations.
- Digital-twin co-pilots for factories and warehouses (manufacturing, supply chain)
- Use case: Plan layouts, flows, and reconfigurations via visual reconstruction and simulation; reason about bottlenecks and collision risks using interleaved visuals.
- Tools/products/workflows: “World-modeling console” showing hypothetical floor plan adjustments; optimization loops that incorporate visual CoT checkpoints.
- Assumptions/dependencies: Accurate CAD-to-visual synchronization; robust domain priors; interoperability with MES/ERP.
- CAD/CAE co-design for foldable, deployable structures and origami robotics (engineering, aerospace)
- Use case: Use visual world modeling to explore design spaces where fold patterns, symmetries, and deployment sequences are critical.
- Tools/products/workflows: Generative “design explorer” that proposes sequences and shows intermediate visuals; downstream structural validation with CAE.
- Assumptions/dependencies: Coupling to physics solvers; governance for model errors; IP protection for design artifacts.
- Medical imaging decision support with visual hypotheses (healthcare)
- Use case: Generate counterfactual/anatomical visual hypotheses to assist radiology or surgical planning, interleaved with textual reasoning.
- Tools/products/workflows: “Reason-and-visualize” assistants; multidisciplinary tumor boards reviewing visual rationales alongside reports.
- Assumptions/dependencies: Strict validation; bias/fairness controls; traceability; regulatory clearance (e.g., FDA/CE); privacy-preserving training data.
- Interior design and facility planning assistants (AEC, real estate)
- Use case: Reconstruct multi-view indoor scenes and simulate reconfigurations; propose layouts with visual CoT steps and constraints (egress, accessibility).
- Tools/products/workflows: Design co-pilots with intermediate visuals; constraint checking pipelines; client approvals with rationale snapshots.
- Assumptions/dependencies: Reliable multi-view geometry; code-compliance checking; realistic rendering under resource limits.
- Scientific assistants that visualize experimental plans (R&D labs)
- Use case: Generate “mental experiments” as visual sequences to reason about apparatus alignment, beam paths, or fluid setups before physical trials.
- Tools/products/workflows: Lab notebooks embedding visual CoTs; LLM-connected ELNs that compare expected vs observed visuals.
- Assumptions/dependencies: Domain priors beyond Internet imagery; integration with simulation codes; careful handling of out-of-distribution setups.
- Education at scale with multimodal mastery learning (education technology)
- Use case: Personalized visual–verbal CoTs that diagnose misconceptions in spatial reasoning and physics; support learners with aphantasia.
- Tools/products/workflows: Adaptive curricula generating visual steps aligned to learner profiles; dashboards for instructors; assistive modes.
- Assumptions/dependencies: Longitudinal efficacy studies; strong content moderation; privacy-first telemetry.
- Policy standards for multimodal reasoning audits (policy, standards bodies)
- Use case: Codify tests where models must pass both final-answer accuracy and intermediate “world model fidelity” checks (as in cube 3-view).
- Tools/products/workflows: Certification suites requiring visual and verbal CoTs; reporting templates showing where visual generation helps vs harms.
- Assumptions/dependencies: Community consensus on metrics; reproducible datasets; governance for chain-of-thought disclosure.
- Cross-modal pretraining and data curation services (AI tooling ecosystem)
- Use case: Build and license large interleaved visual–verbal datasets focused on physical dynamics, symmetries, and spatial priors to improve sample efficiency.
- Tools/products/workflows: Data engines that label tasks as “reconstruction vs simulation” to balance curricula; synthetic data generation targeted at identified bottlenecks.
- Assumptions/dependencies: Data quality controls; licensing/copyright; coverage of edge cases; compute for large-scale training.
Notes on feasibility across applications:
- The paper shows clear gains when verbal CoT faces representational bottlenecks or lacks visual priors (e.g., paper folding, ball tracking, cube 3-view, selected MMSI). Conversely, no gains were found on simple grid/symbolic tasks (maze, Sokoban), suggesting a triage mechanism is essential to realize ROI.
- Visual generation quality, latency, and alignment with domain priors are the main practical constraints; intermediate images can still hallucinate. Human-in-the-loop oversight, verifiable end goals, and KL-regularized training (as used in the paper) help mitigate risks.
- Integrations that require real-time or safety-critical performance (robots, vehicles, medicine) depend on future advances in model fidelity, uncertainty calibration, and domain-specific pretraining.
Glossary
- autoregressive next-token prediction: A modeling paradigm where the next token in a sequence is predicted based on previous tokens, commonly used for language. "While language is predominantly modeled through autoregressive next-token prediction"
- chain-of-thought (CoT) reasoning: A reasoning approach where the model generates intermediate steps or thoughts leading to an answer. "particularly chain-of-thought (CoT) reasoning"
- continuous tokenization: Representing visual data with continuous variables rather than discrete tokens for generative modeling. "to continuous tokenization with diffusion or flow-based modeling"
- diffusion: A generative modeling technique that learns to reverse a gradual noising process to produce samples (e.g., images). "diffusion or flow-based modeling"
- discrete tokenization: Converting images or other modalities into sequences of discrete tokens suitable for sequence models. "from discrete tokenization with autoregressive"
- distribution shift: A mismatch between the data or dynamics seen during pre-training and those encountered in downstream tasks. "the distribution shift between its transition distribution and that learned during large-scale Internet pre-training can vary substantially across modalities"
- dual-coding theory: A cognitive theory positing that information is processed through separate verbal and imagery (often visual) systems. "Dual-coding theory \cite{paivio1990mental} suggests that the mind processes information through two complementary codes"
- emergent internal representations: Latent structures learned by models that implicitly encode task-relevant states without explicit supervision. "we reveal emergent internal representations in UMMs that support implicit world modeling on simple maze tasks."
- flow-based modeling: Generative methods that transform simple distributions into complex ones via invertible flows. "diffusion or flow-based modeling"
- flow-matching loss: A training objective used for flow-based or related continuous-time generative models. "optimized using cross-entropy and flow-matching loss"
- generalization bound: A theoretical guarantee relating training performance and expected performance on new data. "The generalization bound in Theorem~\ref{thm:finetune_nontrivial} of Appendix~\ref{app:theoretical_transfer} suggests"
- GRPO: A reinforcement learning optimization method used to update policies from rollouts. "only the verbal generation component is optimized by GRPO \cite{guo2025deepseek}"
- hallucinations: Incorrect or fabricated intermediate reasoning or outputs produced by a model despite a correct final answer. "exhibit hallucinations along their reasoning trajectories"
- implicit world modeling: Encoding and using internal state representations without explicitly generating observations. "we also consider implicit world modeling, in which no explicit observation is generated"
- interleaved CoT: A reasoning format that alternates between verbal and visual steps within a single chain of thought. "interleaved CoT significantly outperforms purely verbal CoT"
- isometric view: A 3D rendering where dimensions are preserved without perspective distortion. "provides an isometric view and two orthographic views"
- Kullback–Leibler divergence (KL-divergence): A measure of how one probability distribution diverges from another reference distribution. "regularized via the KL-divergence with respect to the SFT-trained reference model"
- LLMs: Large-scale neural networks trained on massive text corpora for language understanding and generation. "especially in LLMs and chain-of-thought (CoT) reasoning"
- latent representations: Hidden vector encodings learned by models to represent underlying structure of data. "since their latent representations are not explicitly defined"
- masked modeling: A pretraining approach where parts of the input are masked and the model learns to reconstruct them. "or masked modeling"
- multi-observable Markov decision process (MOMDP): An MDP framework where the same underlying state can be viewed through multiple observation functions or modalities. "multi-observable Markov decision process (MOMDP)"
- mutual information: A measure of the shared information between random variables. "We use and to denote Shannon entropy and mutual information, respectively."
- novel view generation: Producing images of an object or scene from viewpoints not present in the inputs. "end-to-end novel view generation"
- novel view synthesis: Rendering unseen perspectives of a scene by reconstructing its structure. "world reconstruction, which infers complete structure from partial observations and enables novel view synthesis"
- orthographic views: Projections where depth is not represented via perspective; parallel lines remain parallel. "provides an isometric view and two orthographic views"
- reinforcement learning from verifiable rewards (RLVR): An RL method where rewards are derived from verifiable, automatically checkable outcomes. "We also perform reinforcement learning from verifiable rewards (RLVR) following SFT."
- sample efficiency: The amount of data needed for a model to achieve a given performance level. "reasoning with visual world modeling exhibits substantially higher sample efficiency"
- Shannon entropy: A measure of uncertainty in a probability distribution. "We use and to denote Shannon entropy and mutual information, respectively."
- specular reflections: Ideal mirror-like reflections where the angle of incidence equals the angle of reflection. "ideal specular reflections"
- supervised fine-tuning (SFT): Post-training a model on task-specific labeled data. "Most experiments are conducted by supervised fine-tuning (SFT) on task-specific datasets"
- unified multimodal models (UMMs): Models that jointly understand and generate across multiple modalities (e.g., text and images). "Next-generation multimodal AI systems are evolving to be built upon unified multimodal models (UMMs)"
- verbal world modeling: Representing and tracking states using explicit textual descriptions within the reasoning process. "verbal world modeling produces purely verbal CoTs"
- vision LLMs (VLMs): Models combining vision and language to process and reason over multimodal inputs. "particularly vision LLMs (VLMs)"
- visual world modeling: Using generated images to represent, track, and simulate world states during reasoning. "visual generation for visual world modeling"
- world reconstruction: The capability to infer full underlying state from partial observations and render new views. "The first is called world reconstruction."
- world simulation: The capability to predict how states evolve over time given actions or dynamics. "The second capability is world simulation."
- zero-shot evaluation: Assessing a model on tasks without task-specific fine-tuning or training examples. "Zero-shot evaluation of advanced VLMs on VisWorld-Eval."
Collections
Sign up for free to add this paper to one or more collections.

