Latent Sketchpad: Sketching Visual Thoughts to Elicit Multimodal Reasoning in MLLMs
Abstract: While Multimodal LLMs (MLLMs) excel at visual understanding, they often struggle in complex scenarios that require visual planning and imagination. Inspired by how humans use sketching as a form of visual thinking to develop and communicate ideas, we introduce Latent Sketchpad, a framework that equips MLLMs with an internal visual scratchpad. The internal visual representations of MLLMs have traditionally been confined to perceptual understanding. We repurpose them to support generative visual thought without compromising reasoning ability. Building on frontier MLLMs, our approach integrates visual generation directly into their native autoregressive reasoning process. It allows the model to interleave textual reasoning with the generation of visual latents. These latents guide the internal thought process and can be translated into sketch images for interpretability. To realize this, we introduce two components: a Context-Aware Vision Head autoregressively produces visual representations, and a pretrained Sketch Decoder renders these into human-interpretable images. We evaluate the framework on our new dataset MazePlanning. Experiments across various MLLMs show that Latent Sketchpad delivers comparable or even superior reasoning performance to their backbone. It further generalizes across distinct frontier MLLMs, including Gemma3 and Qwen2.5-VL. By extending model's textual reasoning to visual thinking, our framework opens new opportunities for richer human-computer interaction and broader applications. More details and resources are available on our project page: https://latent-sketchpad.github.io/.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way for AI models that understand both text and images (called Multimodal LLMs, or MLLMs) to “think” visually while they reason. The authors built a tool called Latent Sketchpad that lets these models create simple, internal sketches as they work through problems—much like how people draw diagrams or doodles to plan and solve tricky tasks.
What questions were the researchers trying to answer?
The paper focuses on a few clear questions:
- Can we help AI models reason better about visual and spatial problems (like figuring out paths in a maze) by letting them sketch ideas internally?
- Can we add this sketching ability without breaking what the models already do well?
- Can these internal sketches be turned into real images so humans can see and understand how the model is thinking?
How did they do it?
The researchers added two main parts to existing AI models:
- Context-Aware Vision Head: Think of this like a “mental sketching hand” inside the model. As the model reasons step by step, this part creates hidden visual notes (called “visual latents”) that capture what the model is imagining—like drawing a path through a maze while explaining the steps in words. “Context-aware” means it pays attention to what was sketched before and what has already been said, so the visual ideas stay consistent over time.
- Sketch Decoder: This is like a translator that turns the model’s invisible internal sketches into simple, visible images. It uses a kind of image tool (a VAE, which you can think of as an image compressor/decompressor) to redraw those internal visual latents as human-readable sketches. That makes the model’s thought process easier to inspect and understand.
To test their approach, they made a dataset called MazePlanning, which includes thousands of mazes along with step-by-step reasoning that mixes text and images. They measured:
- Success Rate: How often the model completes the whole path correctly.
- Progress Rate: How far the model gets before making its first mistake.
They also checked the quality of the visualizations using:
- Layout Consistency Rate: Do the sketches keep the maze’s structure (start, goal, walls) correct?
- Visual Success Rate: Does the final sketch show a valid path from start to goal?
What did they find, and why is it important?
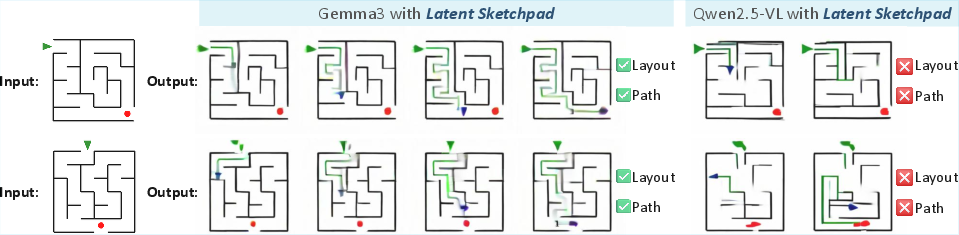
- Better or comparable reasoning: Models using Latent Sketchpad often matched or beat the original models on solving mazes—especially when the task needed careful spatial thinking.
- Works across different models: It helped several strong MLLMs (like Gemma3 and Qwen2.5-VL), and even improved GPT-4o when attached, without changing the main model’s parameters. In simple terms, it’s “plug-and-play,” like installing an app that boosts your phone without replacing the phone.
- More understandable AI: The internal “visual thoughts” can be rendered as sketches, so people can see how the model planned the path. The sketches kept maze structure highly consistent, which helps trust and debugging.
- Robustness in harder settings: On bigger, more difficult mazes (out-of-distribution tests), some models showed improved stability when using the sketchpad, suggesting it can help with generalization.
- Design choices matter: Training the new vision head carefully (for example, using a direct “distance” loss rather than a similarity score) and using smart data augmentation improved both visual accuracy and task performance.
This matters because many real problems—like planning, navigation, and design—require both words and pictures. Giving AI a way to “draw while thinking” can make it smarter and more reliable in these areas.
What could this mean in the future?
- Better human–AI teamwork: When an AI can show its visual reasoning (like a sketch of a plan), it’s easier for people to understand, correct, or build on its ideas.
- Stronger tools for planning and teaching: From robotics route planning and game strategy to classroom explanations, visual thoughts can make complex steps clearer and more engaging.
- Safer, more transparent systems: Seeing how an AI reached an answer—both in text and pictures—helps catch mistakes early and builds trust.
- A path to richer multimodal reasoning: This framework suggests AI shouldn’t rely on language alone; mixing in visual imagination can open new possibilities for solving harder, more dynamic problems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, framed to guide follow-up research:
- External validity beyond mazes: The framework is evaluated almost exclusively on the synthetic MazePlanning dataset; transfer to real-world multimodal reasoning (e.g., diagram/geometry problems, chart/table reasoning, embodied navigation, TextVQA/ChartQA/DocVQA, scientific figures) remains untested.
- Head-to-head comparisons with unified multimodal generators: Claims that unified models prioritize realism over reasoning are not empirically validated; a controlled comparison with Janus/Anole/Emu3/Chameleon (matched data/budgets) on the same tasks is needed.
- Causal role of visual thoughts: It is unclear whether generated latents causally drive improved decisions or merely correlate with them; interventions (e.g., randomized/lesioned latents, counterfactual edits, masking specific latent regions) and downstream impact on answer accuracy should be measured.
- Efficiency and scaling costs: Inference/training latency, memory (KV/cache) footprint, and FLOPs overhead introduced by interleaving visual latents and the Vision Head’s global/local attentions are not reported; scaling laws with number/length of images and visual tokens are unknown.
- Token budget and context-window pressure: The impact of inserting visual latents on effective context utilization (e.g., truncation of long textual CoT) is not analyzed; strategies for compressing or sparsifying visual memory are unexplored.
- Scheduling and policy for when to “draw”: The mechanism deciding when to emit
"<start_of_image>"is supervised by dataset formatting; learned policies for when/how often to generate images, variable-length visual latents, and adaptive early stopping (vs fixedn_v) are unstudied. - Portability conditions of the Vision Head: Attaching a head trained on Qwen2.5-VL to GPT-4o lacks a formal interface specification (hidden-state distributions, dimensions, normalization) and failure-mode analysis; limits to cross-backbone transfer are unclear.
- End-to-end vs frozen training: The work mostly freezes the backbone to protect reasoning, yet ablations show connector adaptation is critical; a principled study of joint/partial fine-tuning (e.g., adapters/LoRA), learning-rate schedules, and forgetting trade-offs is missing.
- Objective design for latent generation: Only L1 vs cosine regression is tested; contrastive, masked-latent modeling, predictive-coding, diffusion/flow priors, or multi-task auxiliary losses (e.g., state prediction) could better align latents with reasoning utility—these are unexplored.
- OOD robustness: Tests are limited to 6×6 mazes; broader OOD shifts (layout styles, distractors, visual noise/occlusion, alternative path conventions, non-grid topologies) and mitigation strategies (curriculum, augmentation, regularization) are not systematically studied.
- Architecture sensitivity across backbones: The explanation for Qwen2.5-VL’s weaker OOD generalization (token concatenation design) is speculative; controlled architectural ablations (token pooling vs concatenation, latent dimensionality, head depth/width) are needed.
- Impact on general capabilities: “No degradation” is shown only on MazePlanning; effects on standard MLLM understanding (e.g., MME/MMBench), text-only reasoning, and instruction-following remain unknown.
- Sketch Decoder domain mismatch and design space: The decoder is trained on Quick, Draw! sketches and SDXL-VAE latents; the impact of this choice on downstream reasoning and its transfer to non-sketch domains is unquantified; vector-graphics decoders, structural decoders, or sketch-specific VAEs are not explored.
- Dependence on foreground masks: The Sketch Decoder’s loss uses a foreground mask
m; the source, quality, and sensitivity to mask errors are unspecified; ablations without masks or with noisy masks are absent. - Interpretability validation with humans: While LCR/VSR quantify structure, there is no human evaluation of whether sketches are readable/useful for users, nor measures of calibrating user trust, debugging speed, or error localization.
- Security/privacy and deployment risks: Rendering and exposing internal visual thoughts could leak sensitive content or amplify prompt leakage; no safety analysis or mitigation strategies (filtering, redaction) are discussed.
- Decision-time robustness: How reliably visual thoughts stay helpful when the model is uncertain, misperceives the maze, or faces adversarial perturbations is unknown; robustness testing and confidence calibration are missing.
- Multi-image memory management: The Vision Head attends over global/local contexts, but long-horizon accumulation and retrieval policies (e.g., selective replay, compression, eviction) are not investigated.
- Interplay with tool use: The framework’s complementarity or redundancy with external tools (cropping/zooming, programmatic planners/simulators) is untested; joint training or routing strategies could yield additive gains.
- Resource footprints and practicality: Parameter counts for the Vision Head/AlignerNet, training compute, and serving costs (especially for large backbones or many visual steps) are not reported; practical deployment constraints are unclear.
- Generalization to video/temporal reasoning: Extending visual thoughts to temporal streams (video, embodied agents) and testing on dynamic tasks (e.g., navigation with changing maps) are open.
- Choice and number of visual tokens (
n_v): Criteria for selectingn_v, trade-offs between fidelity/computation, and effects on reasoning accuracy are not studied; adaptive token budgets are unaddressed. - Evaluation pipeline fragility: Action extraction via pattern matching between
<actions>tags can be brittle; robustness to formatting variance and standardized, parser-free metrics should be considered. - Dataset construction transparency: The generation of interleaved supervision (who decides when to draw, what to draw) may bias models toward scripted behaviors; quantifying such biases and releasing full generation scripts/protocols would improve reproducibility.
- Theoretical account of benefits: There is no analysis of why/when visual latents help (e.g., information-theoretic measures, representational similarity to ground-truth state, mutual information with actions); such analyses could guide principled design choices.
- Cross-lingual and multilingual settings: The framework’s effectiveness across languages (different tokenizations and spatial term ambiguities) is untested.
- Failure-mode taxonomy: While some examples are shown, a systematic taxonomy of errors (layout misperception, path-planning mistakes, instruction misalignment, sketch drift) and targeted remedies is lacking.
- Release artifacts and reproducibility: Exact hyperparameters, training schedules, prompts, dataset splits, and code/models for the Vision Head and Sketch Decoder are not fully detailed here; open-sourcing these artifacts is essential for replication and extension.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s Latent Sketchpad framework, leveraging its plug-and-play Vision Head, pretrained Sketch Decoder, and interleaved text–image reasoning capabilities.
- Visual Chain-of-Thought Assistants for Spatial Tasks
- Sectors: software, education, enterprise support
- Use case: Augment LLM-based assistants (e.g., Qwen2.5-VL, Gemma3, GPT-4o) with step-by-step visual sketches to explain spatial reasoning (paths, layouts, state tracking) alongside text.
- Tools/products/workflows: “Visual CoT” API; UI module that shows <start_of_image> sketches during reasoning; browser extension or IDE plugin to visualize model thoughts.
- Assumptions/dependencies: ViT-based encoder compatibility; connector adaptation improves spatial accuracy; pretrained Sketch Decoder (QuickDraw style) favors schematic sketches over photorealism.
- Interactive Tutoring for Geometry, Graph Traversal, and Mazes
- Sectors: education, edtech
- Use case: Provide students with incremental visual plans for geometric proofs, shortest-path problems, and discrete math exercises; visualize algorithms like BFS/DFS or Dijkstra step-by-step.
- Tools/products/workflows: Classroom apps that render intermediate “visual thoughts”; LMS integrations; practice generators using MazePlanning-like curricula.
- Assumptions/dependencies: Domain-aligned fine-tuning for target curricula; augmentation strategies to emphasize structure over appearance.
- Robotics Teleoperation and Planner Explainability
- Sectors: robotics, manufacturing
- Use case: Show operator-facing visual plans for robot navigation, pick-and-place paths, or obstacle avoidance as the model reasons; reduce operator cognitive load with interpretable sketches.
- Tools/products/workflows: Teleop console plugin showing interleaved plan sketches; “Reasoning Canvas” overlay for simulation software; audit logs for trajectory decisions.
- Assumptions/dependencies: Task/domain-specific fine-tuning; abstraction-level alignment (sketches vs. precise trajectories); integration with existing robot planners.
- Warehouse Routing and Picking Path Guidance
- Sectors: logistics, operations
- Use case: Explain pick-path optimization visually (aisle traversal, bin access) to human workers; provide sanity checks for route recommendations.
- Tools/products/workflows: WMS add-on producing sketch overlays for routes; agent-assist dashboards with visual CoT.
- Assumptions/dependencies: Accurate map/layout models; connector adaptation and data alignment with local warehouse layouts.
- UX/Design Brainstorming with Visual Reasoning Traces
- Sectors: design, software product development
- Use case: Use visual thought traces to co-create wireframes, flow diagrams, and state transitions; improve team communication and ideation by making the model’s reasoning visible.
- Tools/products/workflows: Design tool plugins (Figma/Sketch) that render latent sketches; “Reasoning Canvas” for collaborative sessions.
- Assumptions/dependencies: Sketch-style decoder favors abstract diagrams; requires minimal domain fine-tuning for UI semantics.
- Navigation and Wayfinding Explanations for Consumers
- Sectors: consumer apps, mobility
- Use case: Generate simple, interpretable path sketches for indoor venues (malls, campuses) or outdoor routes; clarify alternatives and constraints visually.
- Tools/products/workflows: Mobile app module that interleaves instructions with sketches; assisted wayfinding in accessibility apps.
- Assumptions/dependencies: Reliable map priors; model familiarity with spatial conventions; careful UI constraints for small screens.
- Debugging and Auditing Multimodal Reasoning
- Sectors: AI engineering, compliance
- Use case: Provide engineers and auditors with transparent visual logs of intermediate decisions for complex multimodal tasks; detect failure modes (e.g., state tracking errors).
- Tools/products/workflows: Observability dashboards; visual thought diff tools across model versions; structured LCR/VSR metrics in CI pipelines.
- Assumptions/dependencies: Storage and privacy controls for intermediate representations; policy around exposing visual CoT traces.
- Document and Diagram Structure Editing
- Sectors: office productivity, software
- Use case: Visualize proposed edits or reflows to tables/diagrams; show step-by-step rearrangements to maintain spatial consistency and avoid layout regressions.
- Tools/products/workflows: Office suite add-on that renders internal layout thoughts; batch-processing workflows for large docs.
- Assumptions/dependencies: Domain-specific fine-tuning for document layouts; alignment between latent sketches and document model.
- Puzzle/Game Level Solving and Design Assist
- Sectors: gaming, entertainment
- Use case: Offer visualized reasoning for puzzle solutions (mazes, Sokoban-like tasks) or generate candidate level layouts with interpretable step-by-step plans.
- Tools/products/workflows: Game editor plugin; player assist mode with visual CoT; level QA tools measuring LCR/VSR.
- Assumptions/dependencies: Game-specific level schema; minimal latency requirements for interactive use.
- Dataset Curation for Spatial Reasoning Research
- Sectors: academia, AI research
- Use case: Use Latent Sketchpad to produce interleaved text–image reasoning traces to build benchmarks and training sets; quantify layout consistency (LCR) and visual success (VSR).
- Tools/products/workflows: Benchmark generation pipelines; visual trace validators; public datasets modeled on MazePlanning.
- Assumptions/dependencies: Clear licensing regimes for generated traces; agreed-upon evaluation protocols.
Long-Term Applications
These applications will benefit from further research, scaling, domain adaptation, and broader ecosystem integration.
- Autonomous Driving Planner Introspection and Safety Cases
- Sectors: automotive, safety-critical systems
- Use case: Record interpretable visual plans for lane changes, merges, and obstacle handling; support post-hoc analysis and safety certification.
- Tools/products/workflows: “Planner Sketch Log” integrated with perception/planning stacks; formalized audit trails.
- Assumptions/dependencies: Domain-grade training on driving scenarios; high-fidelity sketch mappings; regulatory acceptance of visual CoT as evidence.
- Surgical and Clinical Procedure Planning
- Sectors: healthcare
- Use case: Visualize multi-step plans for instrument paths or radiological navigation; document interpretability for clinical review and patient communication.
- Tools/products/workflows: OR planning dashboards with visual reasoning layers; EMR-integrated plan explainers.
- Assumptions/dependencies: Medical-grade validation; privacy and compliance; domain-specific encoders and decoders beyond QuickDraw-style sketches.
- Household and Service Robots with Internal Sketch Memory
- Sectors: robotics, consumer
- Use case: Enable robots to form and audit internal visual plans for navigation, tidying, and task execution; share human-readable sketches on request.
- Tools/products/workflows: “Reasoning Canvas” interfaces for robot UIs; multi-session latent memory replay.
- Assumptions/dependencies: Robust cross-session memory; alignment of internal sketches with real-world sensors; on-device compute constraints.
- Urban Planning and Policy Simulation
- Sectors: policy, government, energy/infrastructure
- Use case: Explore zoning, crowd flows, and emergency egress with visual thought sequences; create interpretable simulations for stakeholder engagement.
- Tools/products/workflows: Civic planning platforms showing step-wise sketches of proposed layouts and flows; deliberation aids.
- Assumptions/dependencies: Scalable data integration (GIS, census); policy frameworks for model transparency; domain-specific fine-tuning.
- AR/VR Visual Reasoning Overlays
- Sectors: consumer tech, industrial training
- Use case: Real-time overlays of the model’s visual thoughts onto physical spaces (assembly lines, classrooms), guiding users step-by-step with sketches.
- Tools/products/workflows: AR app SDK rendering interleaved visual latents; latency-optimized inference pipelines.
- Assumptions/dependencies: Low-latency hardware; robust localization; safe UX for real-world guidance.
- Standardized Interpretable AI Audit Logs
- Sectors: policy/regulation, enterprise governance
- Use case: Formalize visual reasoning logs as standardized artifacts for audits, model cards, and incident investigations.
- Tools/products/workflows: Governance platforms ingesting visual CoT traces; compliance checklists leveraging LCR/VSR metrics.
- Assumptions/dependencies: Legal frameworks permitting and valuing intermediate reasoning disclosure; privacy-safe logging practices.
- Multimodal IDEs and SDKs for Visual Reasoning
- Sectors: software tooling
- Use case: Provide developers with libraries to attach Vision Heads and Sketch Decoders to existing MLLMs; build apps that consume visual latents natively.
- Tools/products/workflows: “Visual Reasoning SDK”; inference servers exposing interleaved text–image endpoints; evaluation harnesses.
- Assumptions/dependencies: Broader encoder compatibility (beyond ViT); performance optimizations; standardized interfaces.
- Scientific Planning and Simulation Explainability
- Sectors: R&D, engineering
- Use case: Visualize step-wise plans in lab automation, materials handling, or microfluidic routing; aid reproducibility through interpretable traces.
- Tools/products/workflows: Lab notebook integrations; simulation tools that render latent plans.
- Assumptions/dependencies: Domain-specific data; precise mapping from sketches to physical actions.
- Drone Mission Planning and Inspection
- Sectors: aerospace, utilities, agriculture
- Use case: Show interpretable path sketches for inspection routes, coverage planning, and waypoint reasoning; improve trust and verification.
- Tools/products/workflows: Mission control software overlaying visual CoT; post-flight analysis with reasoned sketches.
- Assumptions/dependencies: Integration with flight stacks; environment-specific adaptation; scalable handling of large scenes.
- Multi-Agent Collaboration via Shared Visual Latent Space
- Sectors: AI research, complex systems
- Use case: Enable agents to exchange and align visual latents as a compact, structured medium for joint planning; support coordinated tasks.
- Tools/products/workflows: Latent-space communication protocols; alignment modules (e.g., AlignerNet variants) for cross-agent sharing.
- Assumptions/dependencies: Robust latent alignment; security/privacy for inter-agent sharing; standardization of latent formats.
Cross-cutting assumptions and dependencies
- Encoder/decoder compatibility: Current approach is best with ViT-based encoders (CLIP, SigLIP). Extending to other modalities requires additional alignment work.
- Style vs. fidelity: The pretrained Sketch Decoder emphasizes sketch-style reconstructions; domain-specific decoders may be necessary for photorealistic or highly detailed contexts.
- Fine-tuning and connector adaptation: Adapting the connector and using L1 loss improves spatial fidelity; without adaptation, direction and layout errors increase.
- Data needs: Complex, out-of-distribution tasks (larger mazes, high-dimensional visual tokens) need more training data and augmentation to generalize.
- Compute and latency: Real-time interleaved generation and visualization may require optimized inference, especially for AR/robotics.
- Privacy and governance: Intermediate visual thought logs must be handled under clear privacy, security, and regulatory guidelines, especially in healthcare or enterprise settings.
Glossary
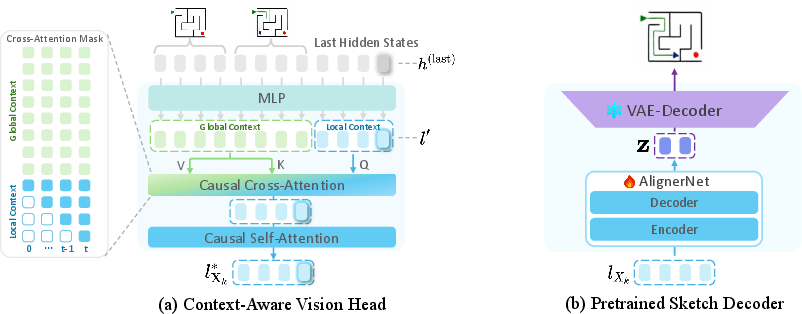
- AlignerNet: A learnable alignment network that maps vision-encoder features to a VAE latent space for rendering. "the core component of the Sketch Decoder is a learnable alignment network (AlignerNet~\cite{pan2024kosmos}), which is implemented as a Transformer-based architecture comprising an encoder and a decoder."
- autoregressive: A generation process where each token (textual or visual) is produced conditioned on previously generated tokens. "integrates visual generation directly into their native autoregressive reasoning process."
- causal cross-attention: Attention where each token attends only to past tokens across contexts, ensuring autoregressive conditioning. "the Vision Head performs causal cross-attention on $L_{\mathrm{X}_k}^{\text{local}$ and $L_{\mathrm{X}_k}^{\text{global}$"
- causal self-attention: Self-attention constrained to attend only to previous positions within the same sequence. "Subsequently, a causal self-attention is applied over the current imageâs local context latents"
- Chain-of-Thought (CoT): A prompting strategy that elicits step-by-step reasoning traces. "reasoning techniques such as Chain-of-Thought (CoT)~\cite{wei2022chain} have enabled models to tackle complex challenges by generating step-by-step textual reasoning traces"
- CLIP: A widely used vision-LLM whose features are compatible with the proposed decoder. "compatible with diverse pretrained vision encoders like CLIP and SigLIP."
- connector-based MLLM: An architecture where a connector projects visual features into the LLM’s embedding space. "In the connector-based MLLM, a pretrained vision encoder encodes an input image ... A connector module ... projects these visual latents into the LLMâs embedding space"
- connector module: The projection component that maps vision features into the language embedding space. "A connector module, as illustrated in \figurename~\ref{fig:overview}, projects these visual latents into the LLMâs embedding space"
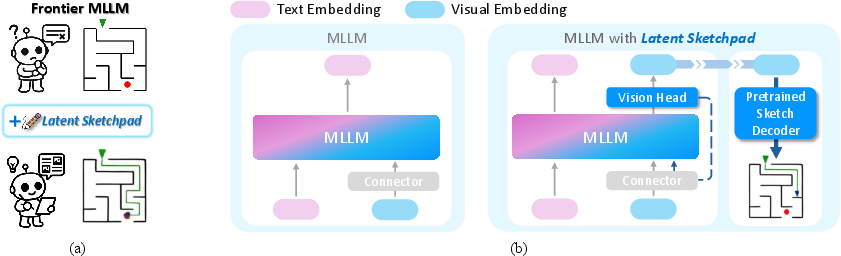
- Context-Aware Vision Head: The module that generates visual latents conditioned on both global and local visual context during reasoning. "we introduce a Context-Aware Vision Head, which is responsible for generating visual latents at each reasoning step."
- embedding space: The vector space in which token or modality representations reside for the LLM. "projects these visual latents into the LLMâs embedding space"
- focal reconstruction loss: A reconstruction loss that emphasizes important (foreground) pixels. "$\mathcal{L}_{\text{rec} = \mathrm{Focal}(\hat{\mathbf{x}, \mathbf{x}, \mathbf{m})$ is a focal reconstruction loss designed to put extra emphasis on foreground pixels"
- foreground mask: A binary mask indicating salient regions to emphasize during reconstruction. "Given a training image and its foreground mask "
- frozen VAE decoder: A fixed (non-trainable) decoder used to render aligned latents into images. "These transformed codes are subsequently fed into a frozen VAE decoder (e.g., from SDXL-VAE~\cite{podell2023sdxl})"
- Gemma3: A frontier pretrained MLLM backbone used to evaluate the framework. "It further generalizes across distinct frontier MLLMs, including Gemma3 and Qwen2.5-VL."
- L1 distance: An element-wise absolute difference metric used for latent regression. "The loss can be instantiated using various similarity or distance measures (e.g., cosine similarity or L1 distance)"
- latent space: The continuous representation space (e.g., of a VAE) where images are encoded and generated. "aligning the feature space of pretrained vision encoder with the latent space of pretrained VAE"
- latent-level regression loss: A supervision objective matching predicted latents to target visual features. "we apply a latent-level regression loss between the predicted context-enriched latent and the target latent"
- Layout Consistency Rate (LCR): A metric assessing whether generated images preserve the maze’s spatial layout. "Layout Consistency Rate (LCR): whether the generated images preserve the spatial configuration of the maze, including the start point, end point, and wall placements"
- Multimodal LLMs (MLLMs): LLMs augmented with vision encoders to process and reason over text and images. "Multimodal LLMs (MLLMs) extend pretrained LLMs with sophisticated vision encoders"
- negative log-likelihood loss: A probabilistic loss encouraging predicted latent distributions to match target posteriors. "$\mathcal{L}_{\text{latent} = \mathrm{NLL}_{\mathcal{N}\left( \boldsymbol{\mu}, \boldsymbol{\sigma}; \mathbf{z} \right)$ is the negative log-likelihood loss"
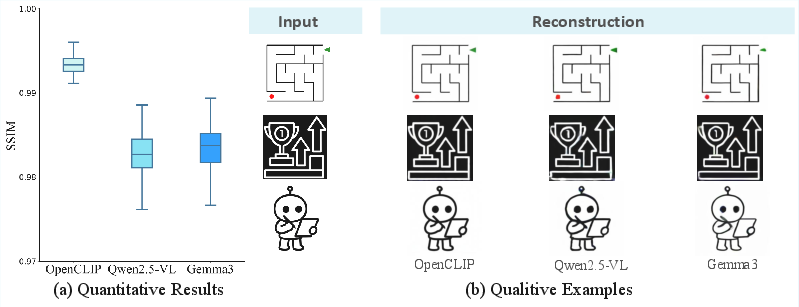
- OpenCLIP: An open-source CLIP variant used as a representative vision encoder in evaluation. "across three representative vision encoders (OpenCLIP, Qwen2.5-VL, and Gemma3)"
- OOD: Short for out-of-distribution, indicating data outside the training distribution. "we construct an OOD test set consisting of 200 mazes of size 6Ã6."
- plug-and-play: A modular capability that can be added without altering the backbone model’s parameters. "retaining plug-and-play modularity and broad applicability across diverse pretrained MLLMs."
- Progress Rate (PR): A metric measuring how far a model progresses with correct actions before the first error. "Progress Rate (PR) quantifies the ratio of consecutively correct actions"
- Qwen2.5-VL: A frontier MLLM backbone with a distinct vision encoder architecture. "It further generalizes across distinct frontier MLLMs, including Gemma3 and Qwen2.5-VL."
- Quick, Draw! dataset: A large-scale sketch dataset used to pretrain the Sketch Decoder. "we use the Quick, Draw! dataset~\cite{quickdraw2016}, which comprises 50 million sketch-style images across 345 categories."
- SDXL-VAE: A high-capacity VAE whose decoder is used for rendering aligned latents. "(e.g., from SDXL-VAE~\cite{podell2023sdxl})"
- SigLIP: A contrastive vision-language pretraining variant referenced as a compatible encoder. "compatible with diverse pretrained vision encoders like CLIP and SigLIP."
- Sketch Decoder: A standalone module that translates visual latents into human-interpretable sketches. "a pretrained Sketch Decoder renders these into human-interpretable images."
- SSIM (Structural Similarity): An image similarity metric used to evaluate reconstruction quality. "the decoder achieves consistently high SSIM (Structural Similarity) scores"
- Success Rate (SR): A metric measuring the proportion of fully correct solutions. "Success Rate (SR) measures the proportion of test cases in which the model generates a complete and correct action sequence."
- Transformer-based architecture: A neural architecture leveraging self-attention, used here in the AlignerNet. "implemented as a Transformer-based architecture comprising an encoder and a decoder."
- VAE: Variational Autoencoder, providing a latent image space for decoding sketches. "the latent space of a pretrained VAE"
- Vision Head: The generation module that produces visual latents from backbone hidden states. "With the Vision Head, the model can interleave textual and visual latent generation"
- ViT-based vision encoder: A Vision Transformer used to extract visual tokens feeding the MLLM. "capable of decoding visual features obtained from pretrained ViT based vision encoder."
- visual grounding: The alignment of reasoning with spatial/visual elements in the image. "those requiring precise spatial reasoning and dynamic visual grounding"
- visual latents: Continuous latent tokens representing images used internally during reasoning. "It allows the model to interleave textual reasoning with the generation of visual latents."
- visual tokens: Tokenized representations of image features processed by the model. "encodes an input image into a sequence of latent visual tokens"
- Visual Success Rate (VSR): A metric assessing whether a valid path is drawn within the correct layout. "Visual Success Rate (VSR): Assesses whether a valid path from the start to the goal is successfully drawn within the correct maze layout."
- window attention: A ViT variant attention mechanism operating within local windows. "Qwen2.5-VLâs encoder employs window attention and is trained from scratch"
- zero-shot: Evaluation without task-specific training on the tested data. "we evaluate its zero-shot reconstruction performance on unseen samples"
Collections
Sign up for free to add this paper to one or more collections.