- The paper introduces a novel modality-agnostic Mull token system that unifies text and image reasoning to enhance spatial understanding.
- The methodology employs a two-stage pre-training and fine-tuning process on paired data, resulting in up to 16% accuracy improvement on complex tasks.
- This approach reduces computational complexity and is adaptable for real-time applications in robotics, autonomous navigation, and interactive AI.
"Mull-Tokens: Modality-Agnostic Latent Thinking" (2512.10941)
Introduction
The paper "Mull-Tokens: Modality-Agnostic Latent Thinking" introduces a novel approach to enhance spatial reasoning in multimodal tasks by utilizing a modality-agnostic latent token system known as Mull. Traditional methods rely heavily on specific tools or interleaved text-image thoughts, which can be cumbersome and inefficient. Mull provides a simplified solution, allowing models to process and represent information in both image and text modalities seamlessly. This approach significantly advances multimodal reasoning by abstractly thinking across modalities, overcoming the limitations of purely text or image-centric reasoning frameworks.
Methodology
Modality-Agnostic Mull
Mull operates on a two-stage processing paradigm inspired by latent reasoning in NLP models. The first stage involves pre-training Mull tokens using paired text-image data, anchoring each token to a relevant concept across these modalities. This enables the tokens to capture essential features required for tasks such as spatial reasoning, symbolic mapping, and visual layout comprehension. Following pre-training, Mull undergoes fine-tuning to optimize latent trajectories, removing explicit supervision constraints and allowing free-form optimization based solely on final answers.
The architecture leverages Qwen2.5-VL, a multimodal LLM, as its backbone, employing discrete Mull tokens embedded within the model's reasoning pathways. This configuration facilitates effective internal computations without necessitating the external decoding of text or images during intermediate processing. The flexibility of this system allows Mull to function as a scratchpad for internal thought processes, aligning well with both the image and text modalities without explicit modality switching.
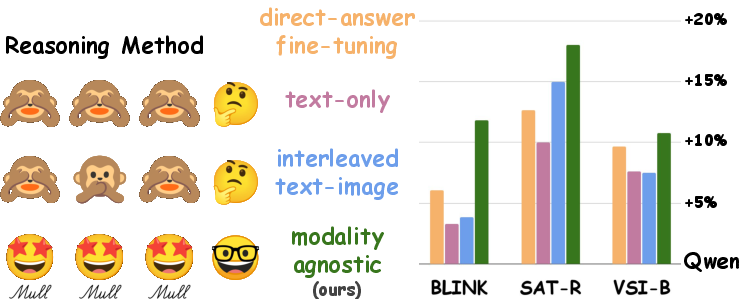
Figure 1: Compared to existing approaches for reasoning in text or interleaving image and text, we offer a simpler alternative - modality-agnostic thinking in the vision-language space using Mull to answer visual queries.
Results and Analysis
The evaluation of Mull across various visual reasoning benchmarks, such as BLINK, SAT-R, and VSI-Bench, demonstrates its superior performance over existing reasoning methods. Mull offers substantial improvements in reasoning accuracy, particularly in complex tasks requiring spatial manipulation and perspective-taking. For instance, Mull showed an increase in accuracy by up to 16% on complex puzzle-solving tasks compared to state-of-the-art baselines like interleaved image-text reasoning models. These results affirm Mull's efficacy in handling reasoning-intensive tasks efficiently with fewer tokens, contrasting with previous models that rely on verbose reasoning chains.
Additionally, the research investigates the effect of token count on performance. It reveals that although increasing the number of Mull tokens can initially enhance task performance, beyond a certain threshold, it may lead to diminishing returns. This emphasizes the importance of optimizing the number of active tokens to balance performance and computational efficiency.
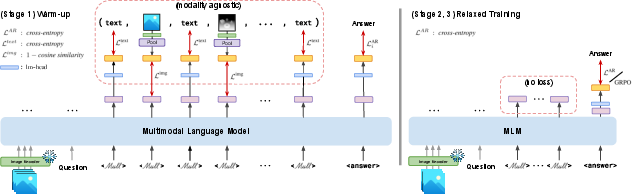
Figure 2: Our Mull training involves two stages inspired by approaches in latent reasoning. We first pre-train/warm-up our Mull to hold both image and text modalities depending on the context image/video and query. Next, the model free-form optimizes these Mull to achieve the final correct answer. We see that pre-training the Mull with to hold both image and text reasoning traces is key, as opposed to using them simply as extra compute without such pretraining or using text alone.
Implications and Speculations
Practically, Mull represents a pioneering step towards developing more efficient and versatile multimodal reasoning systems. By circumventing the need for modality-specific reasoning supervision or large task-specific datasets, Mull reduces computational overhead and promotes broader applicability across diverse task domains. This facilitates the development of models capable of performing complex visual reasoning in real-time, which can be paramount for applications in robotics, autonomous navigation, and interactive AI systems.
Theoretically, Mull opens several avenues for further exploration, such as extending its utility to encompass even more intricate and multidimensional data types like 3D environments and continuous video feeds. Future work could also explore refining the interpretability of Mull tokens to provide more insights into their internal reasoning processes, potentially leading to more transparent AI models.
Conclusion
The paper outlines a significant advancement in multimodal reasoning through the introduction of Mull, a modality-agnostic latent thinking framework. Mull proves to be a formidable alternative to traditional reasoning methods, offering improved accuracy and reduced complexity. As AI continues to evolve, Mull could play a crucial role in bridging the gap between human-like reasoning capabilities and machine intelligence, paving the way for more robust and adaptable AI models.

