- The paper presents a pose-free, trajectory-to-camera framework that decouples camera motion from scene dynamics using a view-conditional inpainting model.
- The paper details a spatiotemporal auto-regressive inference pipeline that employs a spatial-temporal transformer to ensure cross-view coherence and robust video inpainting.
- The paper demonstrates state-of-the-art 4D scene reconstruction performance on real-world datasets, enabling applications in robotics, autonomous driving, and immersive media.
SEE4D: Pose-Free 4D Generation via Auto-Regressive Video Inpainting
Introduction and Motivation
SEE4D addresses the challenge of synthesizing spatiotemporal 4D content from monocular, casually captured videos without requiring explicit 3D or camera pose supervision. Existing video-to-4D methods typically rely on pose annotations or trajectory-conditioned models, which are impractical for in-the-wild footage and often entangle camera motion with scene dynamics, leading to unstable inference and limited scalability. SEE4D introduces a trajectory-to-camera formulation, decoupling camera control from scene modeling by rendering to a bank of fixed virtual cameras and leveraging a view-conditional video inpainting model. This approach eliminates the need for explicit 3D annotations and enables robust, temporally consistent 4D scene generation suitable for immersive applications.
Methodology
SEE4D replaces explicit trajectory prediction with rendering to a set of fixed virtual cameras. This trajectory-to-camera approach simplifies the learning problem by decoupling camera motion from scene dynamics, allowing the model to focus on generating consistent content across a bank of synchronized, fixed-view videos.
View-Conditional Inpainting Model
The core of SEE4D is a view-conditional inpainting model based on a latent diffusion architecture. The model is conditioned on depth-warped images and associated masks, rather than explicit camera poses. The conditioning tensor fuses the warped image, mask, and step-dependent noisy latent, which is then processed by a spatial-temporal transformer backbone to enforce cross-view and cross-frame coherence.
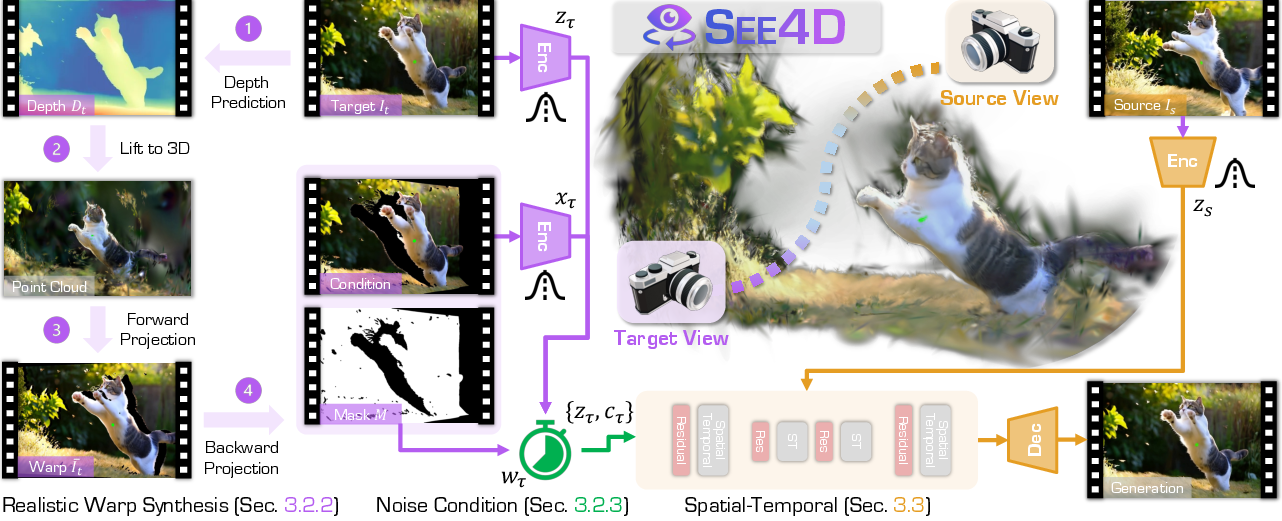
Figure 1: Overview of the view-conditional inpainting model, showing the conditioning on depth-warped images and masks, and the spatial-temporal transformer backbone for denoising and inpainting.
Realistic Warp Synthesis
To simulate test-time artifacts, SEE4D perturbs target views by forward-projecting to randomly sampled virtual camera poses and back-projecting with jitter, introducing realistic warping noise and occlusion patterns. This process generates supervision signals that closely match the distribution of artifacts encountered during inference, improving robustness to depth noise and dynamic scene content.
Noise-Adaptive Conditioning
The informativeness of the warp condition is modulated by the density of the warp mask, with unreliable warps down-weighted via increased noise injection. This prevents the model from overfitting to imperfect geometric cues and encourages robust inpainting, especially in regions with large occlusions or depth errors.
A lightweight spatio-temporal transformer backbone incorporates frame-time embeddings and spatial-temporal attention, enabling the model to maintain temporal consistency and cross-view coherence. This is critical for handling dynamic scenes and ensuring that generated content remains stable across both time and viewpoint changes.
Spatiotemporal Auto-Regressive Inference
SEE4D introduces a dual auto-regressive inference pipeline:
Experimental Results
4D Scene Reconstruction
SEE4D achieves state-of-the-art performance on the iPhone dataset, outperforming prior methods such as TrajectoryCrafter, ReCamMaster, and Shape-of-Motion in PSNR, SSIM, and LPIPS metrics. The model demonstrates robustness to both rigid and deformable content, and its pose-free conditioning enables generalization beyond the training distribution.

Figure 3: Qualitative comparisons for 4D reconstruction on the iPhone dataset, showing sharper geometry and stable parallax.
Cross-View Video Generation
On the VBench protocol, SEE4D leads on five of six metrics, including subject and background consistency, temporal flicker, and image quality, despite using a multi-view synthesis backbone rather than a dedicated video generation model. The spatial-temporal auto-regressive pipeline is critical for maintaining coherence over long sequences and large viewpoint shifts.

Figure 4: Qualitative comparisons with TrajectoryCrafter for 4D generation, highlighting smooth, occlusion-aware synthesis and seamless transitions.
Ablation Studies
Ablations confirm the necessity of each component:
- Replacing realistic warp synthesis with simpler schemes degrades all metrics.
- Omitting noise-adaptive conditioning or the spatial-temporal transformer backbone results in significant drops in reconstruction fidelity.
- Removing spatial or temporal auto-regression leads to noticeable quality declines, underscoring the importance of both progressive view hops and overlapping diffusion windows.
Downstream Applications
SEE4D enables a range of downstream applications by generating temporally aligned, viewpoint-varying video sequences from a single input:
- Robotics: Augments grasp planning with multi-view object sequences, improving surface geometry estimation and approach direction assessment.
- Autonomous Driving: Synthesizes additional perspectives from dash-cam footage, enhancing visual coverage for perception and tracking.
- Interactive Gaming and Virtual Environments: Transforms single-view gameplay into multi-angle sequences for immersive replay and camera switching.
- Cinematic Post-Production: Enables off-axis re-framing and stabilization from handheld footage, filling occlusions and maintaining motion continuity.

Figure 5: Illustrative examples of SEE4D for robotics, driving, games, and movies, demonstrating broad applicability.
Implications and Future Directions
SEE4D demonstrates that pose-free, trajectory-to-camera 4D generation is feasible and effective, removing the reliance on explicit pose annotations and enabling scalable, robust 4D scene modeling from monocular videos. The integration of depth-warped conditioning, noise-adaptive modulation, and spatiotemporal transformers provides a strong geometry prior and temporal consistency, advancing the state of the art in 4D content creation.
Future research directions include:
- Extending the approach to handle even wider baseline changes and more complex dynamic scenes.
- Integrating with downstream 4D representation learning frameworks for end-to-end VR content pipelines.
- Exploring self-supervised or unsupervised depth estimation to further reduce reliance on synthetic data.
Conclusion
SEE4D introduces a pose-free, trajectory-to-camera framework for 4D scene generation from monocular videos, leveraging a view-conditional inpainting model and a spatiotemporal auto-regressive inference pipeline. The method achieves superior reconstruction accuracy and generative quality, with demonstrated benefits across robotics, autonomous driving, gaming, and cinematic applications. The decoupling of camera control from scene modeling, combined with robust geometric and temporal priors, positions SEE4D as a practical solution for scalable 4D world modeling and immersive content creation.