- The paper introduces a dual spatio-temporal conditioning framework that ensures scene-consistent video generation with precise camera control.
- It leverages dynamic SLAM and a dynamic masking pipeline to construct a static-only 3D scene memory, effectively separating static and dynamic elements.
- Experimental results show a 77% reduction in geometric alignment error and superior video quality metrics compared to baseline methods.
3D Scene Prompting for Scene-Consistent Camera-Controllable Video Generation
Introduction and Motivation
This paper introduces a novel framework, termed 3D Scene Prompting, for scene-consistent camera-controllable video generation. The central challenge addressed is the synthesis of future video frames that not only follow user-specified camera trajectories but also maintain spatial and temporal consistency with an arbitrarily long input video. Existing methods typically condition on a single image or a short video clip, which restricts their ability to preserve long-range scene context and geometric consistency, especially when the camera revisits previously observed regions. The proposed approach leverages dual spatio-temporal conditioning, integrating both temporally adjacent frames for motion continuity and spatially adjacent content for scene consistency, while explicitly separating static and dynamic scene elements.
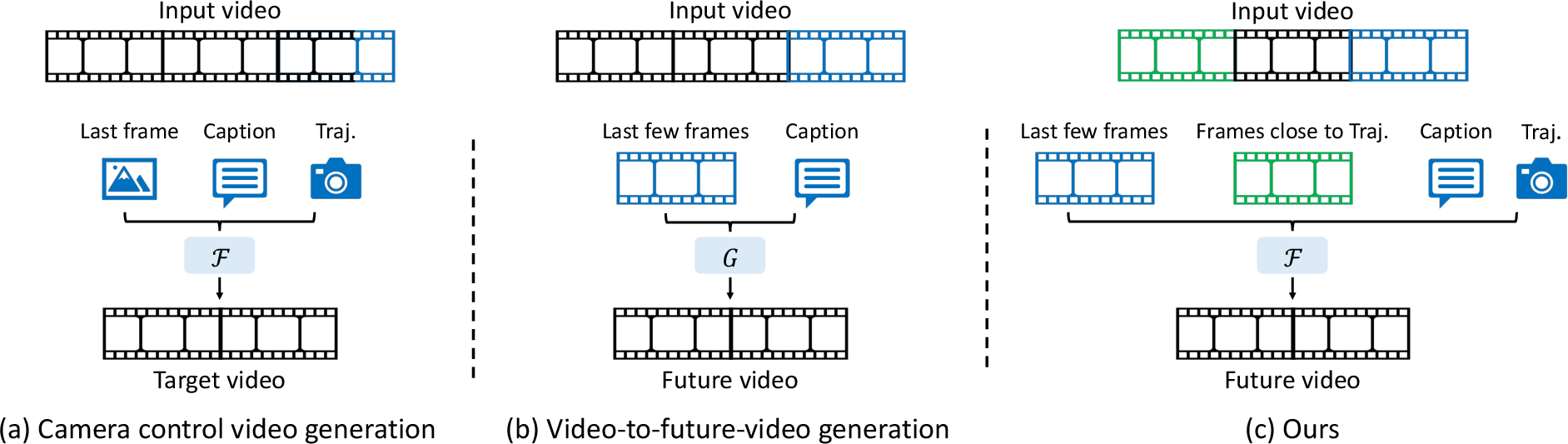
Figure 1: Comparison of architectures: (a) single-frame camera-controllable methods, (b) video-to-future-video methods with short-term conditioning, (c) the proposed dual spatio-temporal conditioning for scene-consistent generation.
Methodology
Dual Spatio-Temporal Conditioning
The framework reformulates context referencing by introducing a dual sliding window strategy. Temporal conditioning utilizes the last w frames of the input video to ensure motion continuity, while spatial conditioning retrieves frames that are spatially adjacent to the target viewpoint, regardless of their temporal distance. This enables the model to maintain scene consistency even when the camera revisits regions observed much earlier in the sequence.
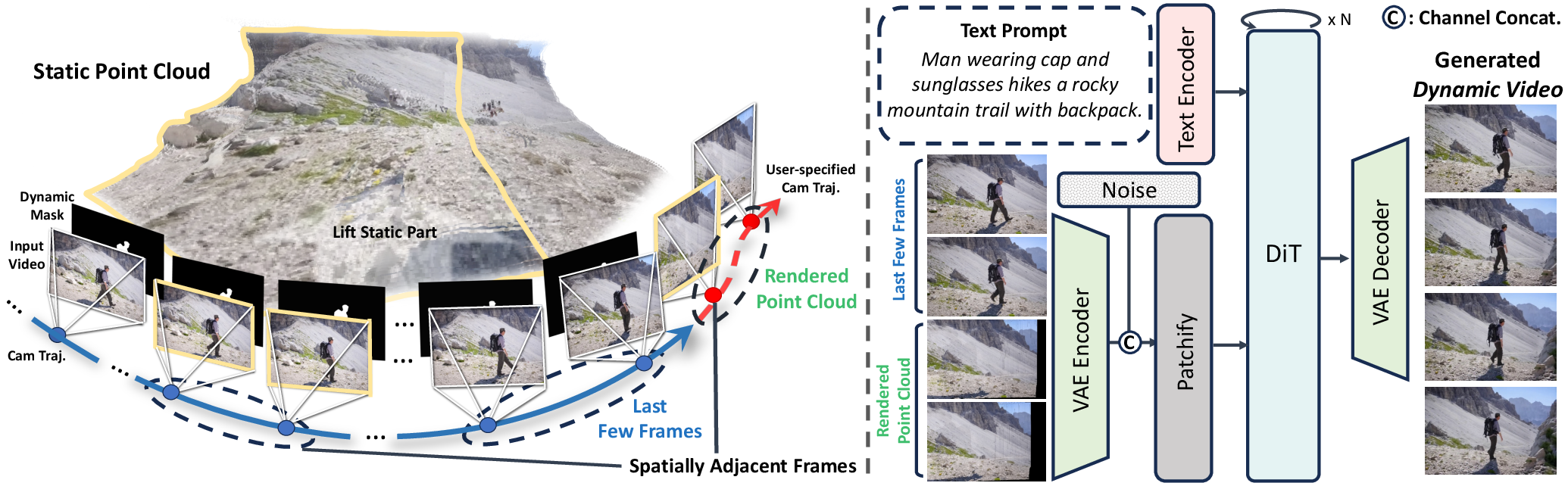
Figure 2: Overview of the dual spatio-temporal conditioning pipeline, combining recent frames for temporal continuity and rendered static point clouds for spatial consistency.
3D Scene Memory Construction
To provide spatial conditioning that is free from outdated dynamic content, the framework constructs a 3D scene memory representing only the static geometry of the input video. This is achieved using dynamic SLAM to estimate camera poses and reconstruct a 3D point cloud. A dynamic masking pipeline is introduced to explicitly separate static elements from moving objects, preventing ghosting artifacts and ensuring that only persistent scene structure is used for spatial prompts.

Figure 3: Dynamic masking for static scene extraction: (a) without masking, dynamic elements cause ghosting; (b) with masking, clean static-only point clouds are obtained.
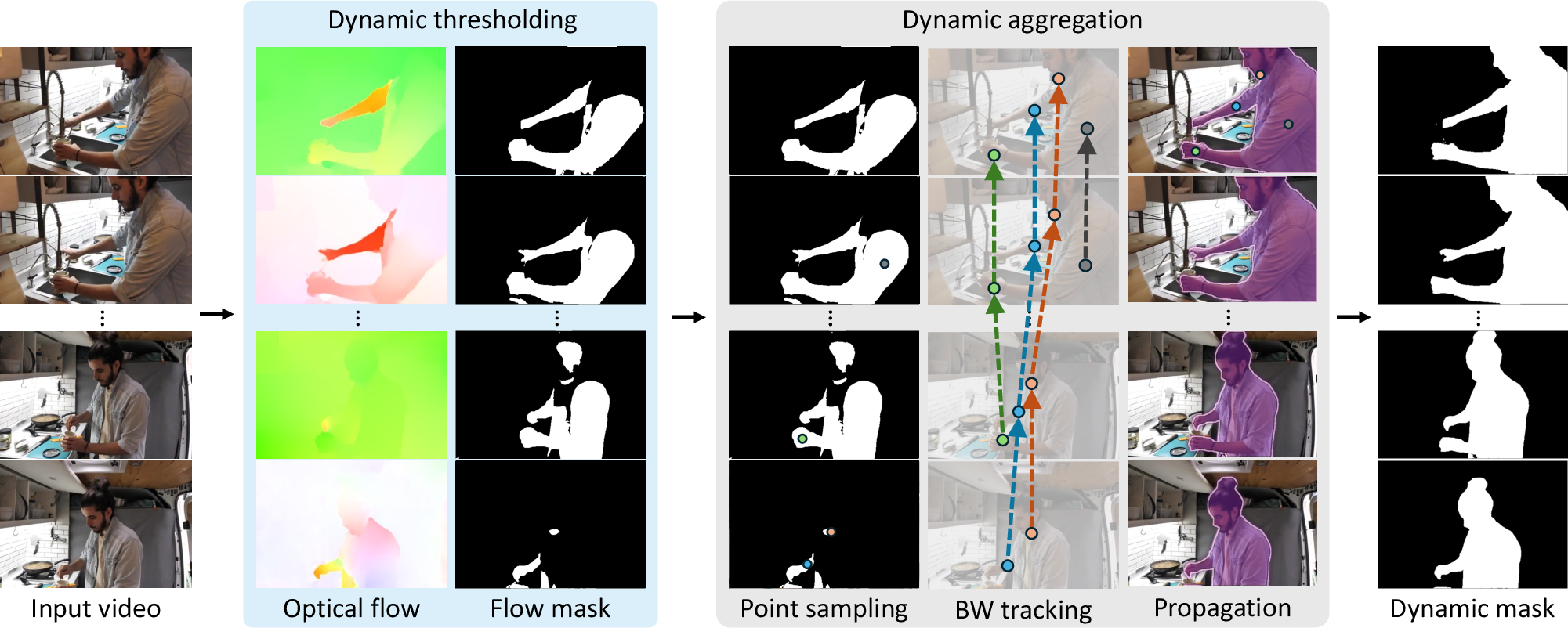
Figure 4: Three-stage dynamic masking pipeline: (1) pixel-level motion detection via optical flow, (2) backward tracking with CoTracker3, (3) object-level mask propagation with SAM2.
3D Scene Prompting
Spatial conditioning is implemented by projecting the static-only 3D point cloud to the target camera poses, synthesizing spatial frames that serve as 3D scene prompts. This approach provides explicit geometric guidance, enabling precise camera control and long-range spatial consistency without the need for additional encoding modules.
Training and Implementation
The model is built upon CogVideoX-I2V-5B, extending its conditioning mechanism to accept both temporal and spatial inputs. Training data is sourced from RealEstate10K (static scenes) and OpenVid-1M (dynamic scenes), with dynamic masking applied only to the latter. The model is fine-tuned for 4K iterations on 4 H100 GPUs, using a batch size of 8 and a learning rate of 1×10−5. Temporal conditioning uses the last 9 frames, while spatial conditioning projects the static point cloud from the top-7 spatially adjacent viewpoints.
Experimental Results
Scene Consistency and Geometric Alignment
Quantitative evaluation on RealEstate10K and DynPose-100K demonstrates that the proposed method significantly outperforms DFoT in PSNR, SSIM, LPIPS, and MEt3R metrics, with a 77% reduction in geometric alignment error. Qualitative results show superior scene consistency when the camera revisits earlier viewpoints, with the model maintaining persistent scene elements and avoiding the reappearance of outdated dynamic content.

Figure 5: Visualization of generated videos following revisited camera trajectories, comparing DFoT and the proposed method.
Camera Controllability and Video Quality
Camera controllability is evaluated using mean rotation error, mean translation error, and mean camera matrix error, with the proposed method achieving the lowest errors among all baselines. Video quality is assessed using FVD and VBench++ metrics, where the framework achieves the best overall scores, subject consistency, background consistency, and imaging quality.
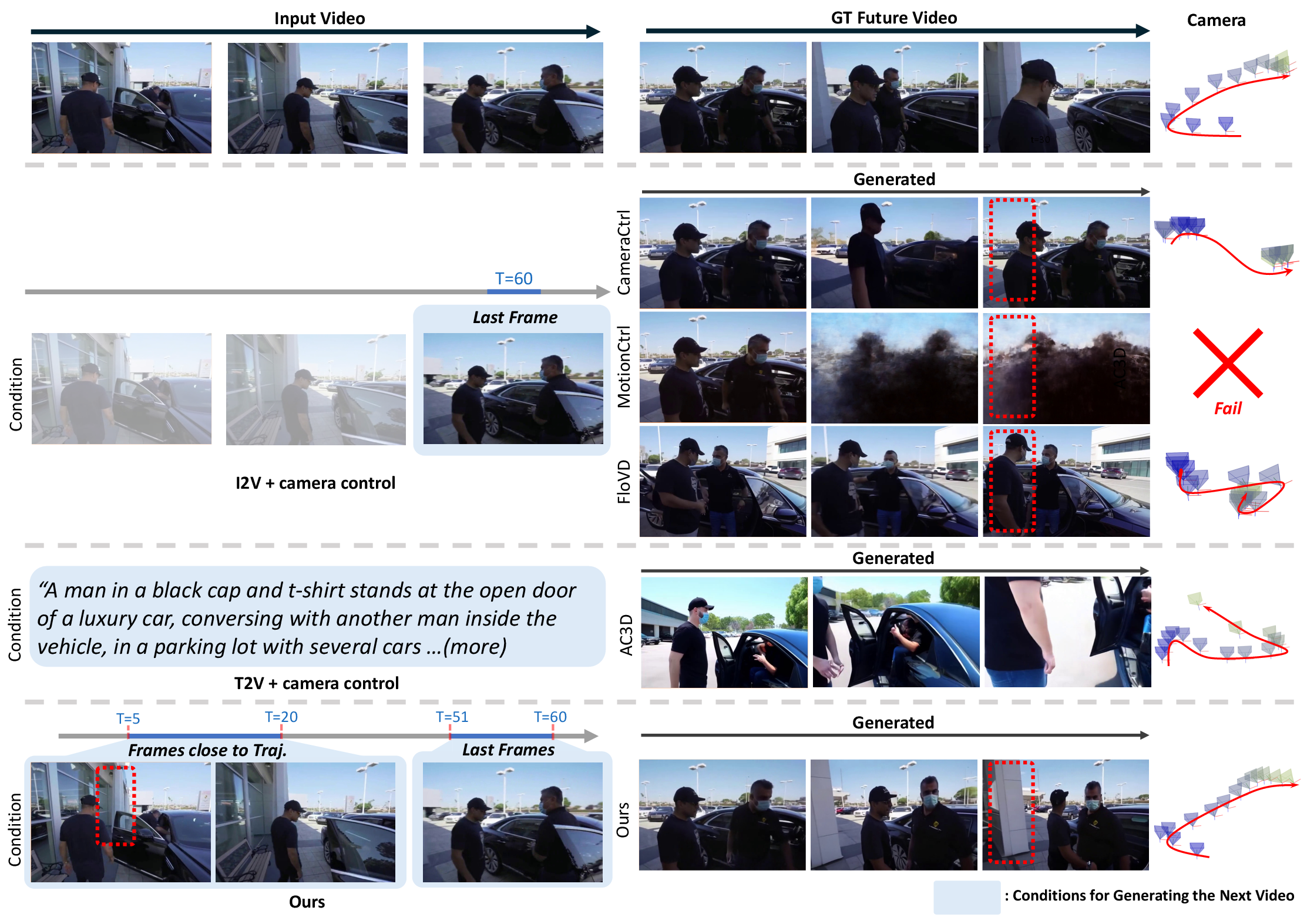
Figure 6: Scene-consistent camera-controllable video generation: comparison with prior methods, highlighting preservation of scene structure and camera trajectory fidelity.
Ablation Studies
Ablation experiments confirm the necessity of dynamic masking for preventing ghosting artifacts and demonstrate that performance stabilizes with 7 spatially adjacent frames for spatial conditioning. Removing dynamic masking results in a substantial drop in PSNR and an increase in geometric error.
Implications and Future Directions
The proposed framework advances the state-of-the-art in camera-controllable video generation by enabling long-horizon scene consistency and precise camera control from arbitrary-length input videos. The explicit separation of static and dynamic elements via dynamic masking and 3D scene memory construction is critical for maintaining geometric fidelity and avoiding temporal contradictions. This approach is computationally efficient, scalable, and compatible with existing pretrained video generators.
Potential future directions include extending the framework to handle more complex dynamic interactions, integrating semantic scene understanding for enhanced prompt control, and exploring memory-efficient architectures for even longer video sequences. The methodology is directly applicable to domains such as film production, virtual reality, and synthetic data generation, where persistent scene context and controllable camera trajectories are essential.
Conclusion
This work presents a robust solution for scene-consistent camera-controllable video generation, leveraging dual spatio-temporal conditioning and static-only 3D scene prompting. The integration of dynamic SLAM and dynamic masking enables the model to generate high-quality, geometrically consistent videos that faithfully follow user-specified camera trajectories. Experimental results substantiate the superiority of the approach over existing methods in both quantitative and qualitative metrics, establishing a new benchmark for long-form video synthesis with precise camera control.