- The paper introduces a feedforward framework for video-to-4D mesh generation that ensures temporal consistency and high geometric fidelity.
- It employs a flow-based latent diffusion transformer with spatiotemporal attention and aligned latents to minimize jitter and enhance mesh quality.
- Quantitative evaluations show improvements over baselines in metrics like Chamfer distance, IoU, and perceptual rendering, confirming its robustness.
ShapeGen4D: High-Quality 4D Shape Generation from Monocular Videos
Introduction and Motivation
ShapeGen4D introduces a feedforward framework for direct video-to-4D shape generation, targeting the synthesis of temporally consistent, high-fidelity mesh sequences from monocular input videos. The method leverages large-scale pretrained 3D generative models, specifically extending the Step1X-3D architecture, to overcome the limitations of prior approaches that either rely on computationally expensive score distillation sampling (SDS) or suffer from accumulated errors in two-stage multi-view diffusion and reconstruction pipelines. ShapeGen4D is designed to natively generate dynamic 3D meshes, capturing non-rigid motion, volume changes, and topological transitions without per-frame optimization.

Figure 1: ShapeGen4D generates high-quality mesh sequences from input monocular videos.
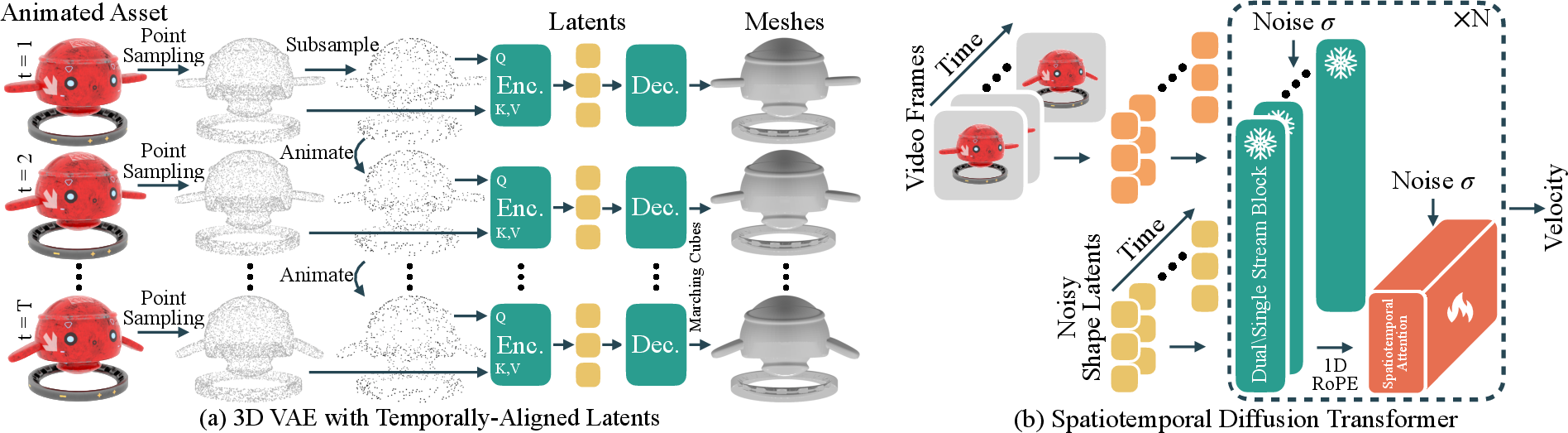
Architecture and Methodology
The core of ShapeGen4D is a flow-based latent diffusion transformer that processes video frames to generate a sequence of temporally aligned mesh latents. The architecture consists of:
Temporally-Aligned Latents
Temporal alignment is achieved by warping the query points from the first frame across the animation sequence, ensuring that each latent corresponds to the same physical surface location over time. This design significantly reduces temporal jitter and improves the smoothness of generated mesh sequences.
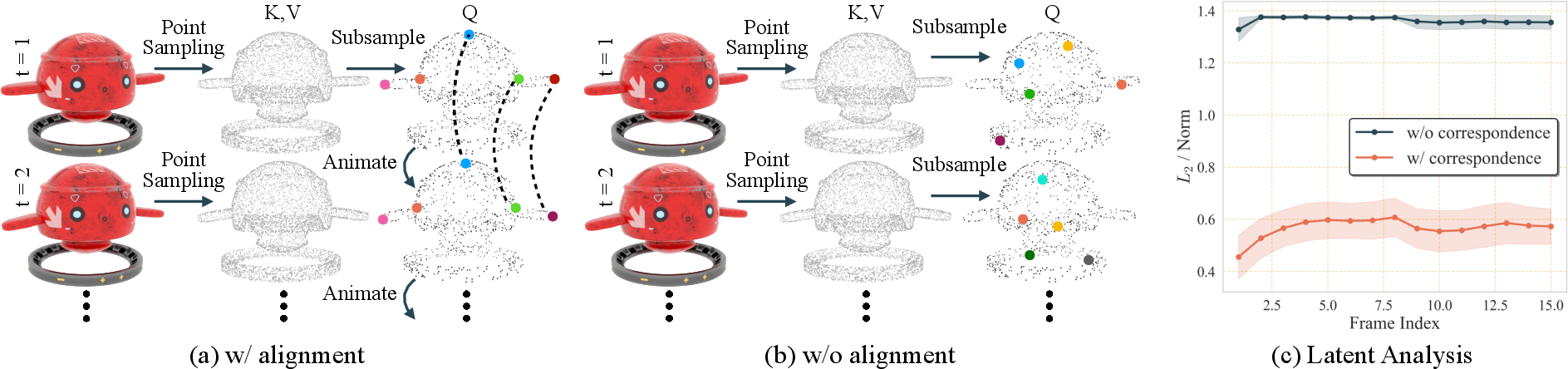
Figure 3: Latents with aligned query points across frames exhibit lower L2 differences, indicating improved temporal consistency.
Noise Sharing Across Frames
To further enhance temporal stability, ShapeGen4D enforces shared noise across all frames during both training and inference. This mitigates pose and scale flickering caused by independent noise sampling, a common issue in 3D generative models lacking explicit positional embeddings.
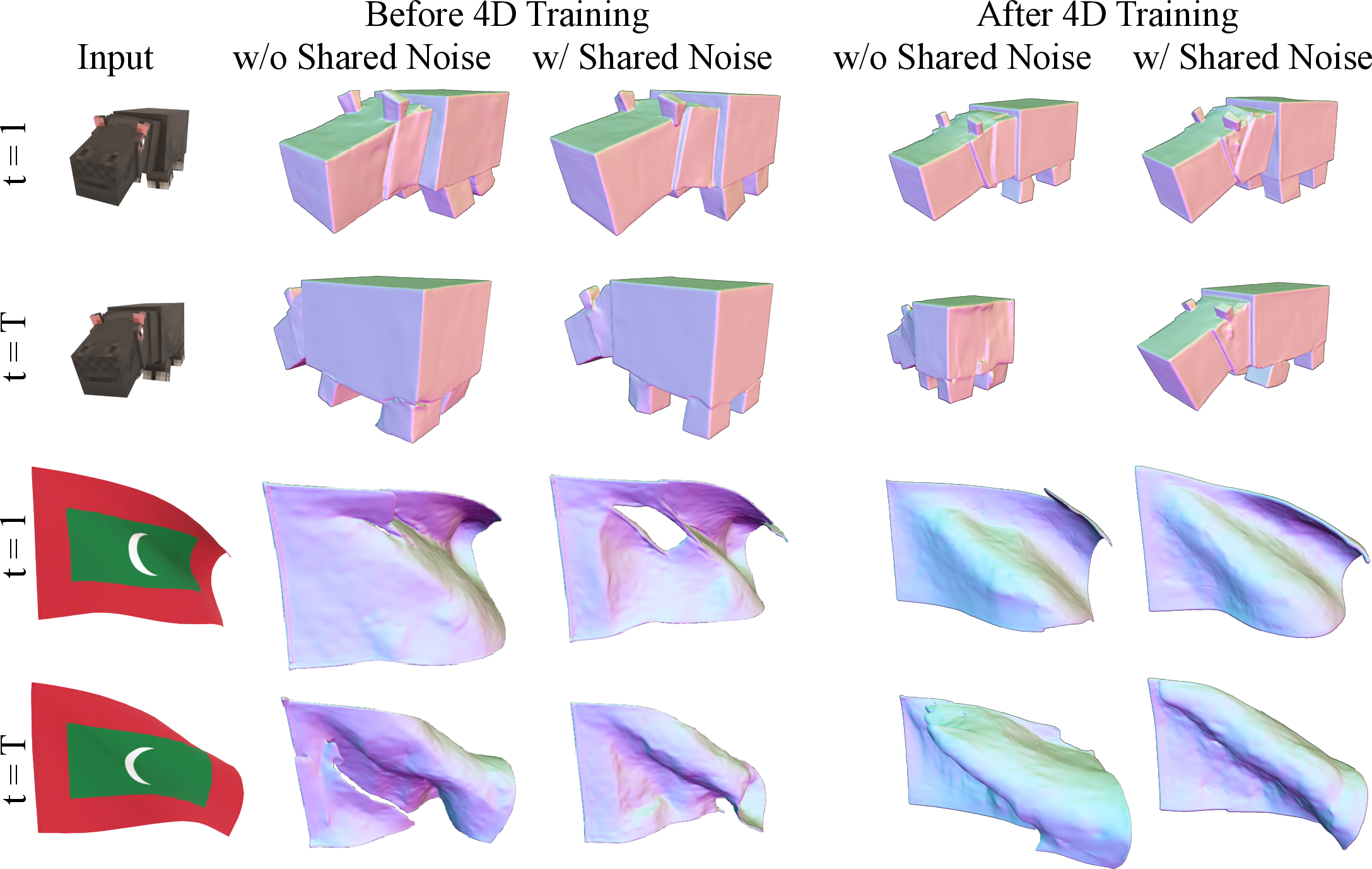
Figure 4: Sharing noise across frames reduces flickering and improves shape quality, especially in challenging cases.
Mesh Registration and Texturization
After mesh sequence generation, a two-stage pipeline is applied:
- Global Pose Registration: Aligns the generated mesh sequence to the input video’s viewpoint using camera pose estimation and transformation.
- Global Texturization: Converts the mesh sequence into a topology-consistent representation and propagates textures from the first frame across all frames, ensuring appearance consistency.
Experimental Evaluation
Datasets and Baselines
ShapeGen4D is evaluated on two test sets: a held-out Objaverse set (33 animated samples) for geometric accuracy, and the Consistent4D set (20 video sequences) for rendering-based metrics. Baselines include L4GM, GVFD, and Step1X-3D (per-frame).
Quantitative Results
ShapeGen4D achieves superior geometric fidelity, as measured by Chamfer distance, IoU, and F-Score, compared to all baselines. Notably, it outperforms L4GM and GVFD, which rely on Gaussian particle representations and deformation fields, respectively. Rendering metrics (LPIPS, CLIP, FVD, DreamSim) also indicate improved perceptual quality and temporal consistency, though L4GM exhibits artificially high scores due to its strong bias toward input view reconstruction.
Qualitative Results
ShapeGen4D produces mesh sequences with consistent poses and minimal temporal jitter, capturing fine-grained motion and topological changes. In contrast, L4GM suffers from ghosting artifacts and poor generalization on complex motions, while GVFD exhibits significant distortion and fails to model fine surface dynamics.

Figure 5: Qualitative comparison with baselines on the held-out Objaverse test set.

Figure 6: Qualitative comparison on Consistent4D test set, highlighting temporal consistency and motion fidelity.
Ablation Studies
Ablations confirm the necessity of each architectural component:
- Aligned Latents: Removing temporal alignment increases flickering and degrades quality.
- Shared Noise: Independent noise leads to pose and scale instability.
- Spatiotemporal Attention: Restricting attention to 1D temporal or removing image hidden states results in catastrophic failures or performance drops.
- Denoise Time Shift: Improves stability at higher noise levels.
Implementation Considerations
- Training: Requires large-scale animated 3D assets (14k from Objaverse), with mesh preprocessing for watertightness and normalization.
- Hardware: Training is performed on 16 A100 GPUs, batch size 64, for 25k iterations.
- Inference: Mesh registration and texturization are post-processing steps, leveraging existing pose estimation and texture propagation methods.
Limitations and Future Directions
ShapeGen4D inherits viewpoint agnosticism from its base 3D model, necessitating additional pose registration for viewpoint-aligned reconstruction. Texture propagation and mesh registration remain post-processing requirements for fully animatable assets. Local temporal jitter persists in some cases; future work may explore spatiotemporal 3D VAEs or more advanced attention mechanisms to further reduce flickering.
Conclusion
ShapeGen4D establishes a robust, feedforward paradigm for direct video-to-4D mesh generation, leveraging pretrained 3D generative models and novel architectural extensions to achieve high geometric and perceptual fidelity. The framework demonstrates strong generalization and temporal consistency, outperforming prior Gaussian-splatting and deformation-based baselines. Future research may focus on integrating viewpoint conditioning, improving texture consistency, and further reducing temporal artifacts for production-grade 4D asset generation.