- The paper introduces a fully native 4D generative model that directly synthesizes dynamic 3D objects from monocular video using a structured spacetime latent representation.
- It leverages a 4D sparse flow transformer with a dedicated temporal layer and 4D compression strategy to achieve high spatial fidelity and temporal consistency with efficient inference.
- Experimental results show significant improvements over baselines, reducing Frechet Video Distance and enhancing metrics such as LPIPS, SSIM, and PSNR while robustly handling real-world artifacts.
SS4D: Native 4D Generative Model via Structured Spacetime Latents
Introduction
SS4D introduces a fully native 4D generative model engineered to produce dynamic 3D objects directly from monocular video input. This contrasts with prior techniques that indirectly optimize for 4D structure via 3D or video generative models, often relying on Score Distillation Sampling (SDS) and incurring significant computational cost and inconsistency. SS4D leverages a structured spacetime latent representation, extending TRELLIS's sparse voxel-based 3D latent space into four dimensions, ensuring strong spatial and temporal consistency. The model is trained end-to-end on curated 4D datasets, supporting efficient synthesis and robust handling of real-world artifacts such as occlusion, motion blur, and long-term sequence generation.
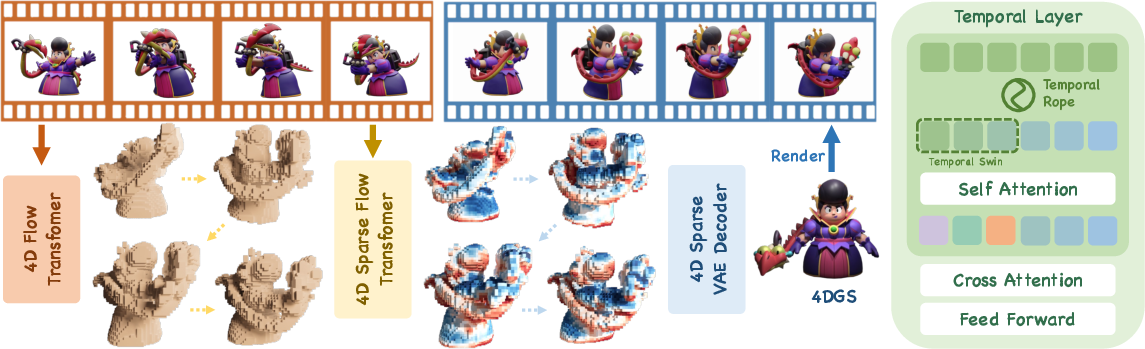
Figure 1: SS4D pipeline overview: input monocular video, coarse voxelized structure extraction, spacetime latent generation via 4D Sparse Flow Transformer, decoding to 3D Gaussians (final 4D content).
Methods
Structured Spacetime Latent Space
SS4D extends TRELLIS's structured latents into spacetime by incorporating time as a fourth dimension. This approach guarantees spatial fidelity by inheriting priors from a pre-trained single-image-to-3D model and achieves temporal coherence through a dedicated temporal layer. The temporal layer employs shifted window self-attention, alternating between local aggregation and global context, while hybrid positional encoding combines absolute spatial embeddings with 1D rotary position embeddings (RoPE) along the temporal axis.
4D Compression and Temporal Downsampling
Long-term video sequence modeling in 4D representation is addressed via a dedicated 4D compression strategy. Factorized 4D convolutions, coupled with temporal downsampling modules, efficiently compress latent sequences without loss of spatio-temporal detail. Sparse 3D convolutions aggregate intra-frame features, and sparse 1D convolutions facilitate inter-frame communication, with temporal blocks actively reducing sequence length and computational burden during generation.
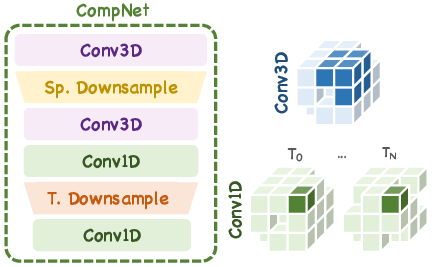
Figure 2: The 4D compression strategy improves efficiency by compressing representations for long-term sequence generation in the 4D Sparse Flow Transformer.
Temporal Alignment and VAE Adaptation
Simple extension of a 3D latent space into 4D introduces flickering and inconsistency due to the lack of temporal reasoning. SS4D applies temporal alignment not only within the diffusion model but also in the VAE autoencoder, systematically reducing inter-frame artifacts and improving the stability of reconstructed Gaussians.

Figure 3: Temporal alignment in VAE reconstruction mitigates flickering and promotes cross-frame consistency.
Augmentation and Training Strategies
Masking augmentation during training, where random occlusions are imposed on conditioning frames, enhances robustness to real-world occlusion and motion blur. Progressive curriculum learning is adopted: training commences with short sequences to internalize latent dynamics and is subsequently fine-tuned on a subset of long-duration, high-quality assets for extrapolation.

Figure 4: Masking augmentation strengthens occlusion robustness and geometric completeness in generated objects.
Latent Feature Aggregation
Visibility-based feature aggregation during voxel activation filters out occluded viewpoints, reducing latent sequence length, facilitating faster encoding, and minimizing multi-view feature noise, while maintaining competitive reconstruction quality.
Experimental Results
Quantitative Metrics
On synthetic datasets (ObjaverseDy, Consistent4D), SS4D significantly reduces Frechet Video Distance (FVD) – 465 and 455 respectively vs. 693/640+/716+ for SDS/feed-forward baselines – and achieves strong improvements in LPIPS, SSIM, PSNR, and CLIP-S. The inference time for generating dynamic objects is reduced to 2 minutes, representing a substantial advance over optimization-heavy baselines (1–1.5 hours). User studies on DAVIS real-world data confirm dramatic superiority in geometry, texture, and motion coherence, with average ratings exceeding those of all preceding models.
Qualitative Analysis
SS4D exhibits spatio-temporally smooth geometry and consistent high-detail texturing, even when challenged by high-speed or complex motions. Baselines show characteristic artifacts: over-saturation (SDS), geometry distortion (L4GM), and noise/inconsistency (STAG4D).

Figure 5: On synthetic data, SS4D yields precise geometry and temporally consistent textures across novel viewpoints.

Figure 6: On DAVIS real-world videos, SS4D maintains robustness under challenging dynamics and viewpoint changes.

Figure 7: SS4D’s qualitative results on benchmark test set demonstrate accurate geometry and temporal fidelity.

Figure 8: SS4D’s outputs on synthetic internet data preserve structural and textural integrity throughout motion.

Figure 9: SS4D’s real-world results evidence preservation of texture and geometry in unconstrained environments.
Ablation Studies
Temporal alignment in the VAE yields a marked reduction in flickering phenomena and FVD (from 403.88 to 157.16) and increases PSNR from 27.11 to 30.58. Masking augmentation is critical for recovery of occluded components, with ablation illustrating significant loss of geometric completeness in its absence.
Limitations

Figure 10: Failure cases: transparent layers, high-frequency detail loss, and degraded performance in rapid motion scenarios.
SS4D inherits a two-stage pipeline, introducing training inefficiencies compared to end-to-end paradigms. Synthetic dataset bias impairs photorealism when deployed on real-world content, leading to over-simplified textures. Model architecture struggles with transparent/multi-layered structures, high-frequency texture detail retention, and extreme motion blur, indicating a need for pixel-space regularization and diversified training frames. Furthermore, ethical concerns must be considered due to dataset and generative bias.
Implications and Future Directions
Practically, SS4D enables rapid and high-fidelity synthesis of dynamic 3D objects from monocular video, facilitating use in scalable animation, VR, and content creation workflows. Theoretically, the structured spacetime latent approach opens avenues for joint generative modeling across spatial and temporal domains, bridging the gap from static content synthesis to true 4D dynamic modeling. Integration with real-world data and end-to-end architectures remains an open research challenge, along with improved handling of transparency, fine-scale detail, and motion blur. SS4D serves as a foundation for advancing native 4D generation and structured representation learning in AI.
Conclusion
SS4D establishes a fundamentally new approach to 4D object generation, extending structured 3D latent modeling into spacetime, coupled with compression and temporal alignment for efficient sequence generation. Comprehensive experiments show strong quantitative and qualitative performance gains over the state of the art, though challenges in photorealism, transparency, and fine-detail consistency remain as future research directions.