- The paper presents a unified feed-forward framework that efficiently reconstructs 4D scenes from monocular video by integrating dense geometry and motion querying in a single pass.
- The methodology leverages a Vision Transformer-based encoder with conditional querying to encode spatiotemporal features, achieving superior tracking performance and temporal consistency on benchmarks like Waymo.
- Empirical results demonstrate significant improvements in metrics such as APD and EPE, enabling robust dynamic scene reconstruction with applications in robotics, AR/VR, and video synthesis.
Unified 4D Reconstruction from Monocular Video: An Analysis of 4RC
Introduction
The paper "4RC: 4D Reconstruction via Conditional Querying Anytime and Anywhere" (2602.10094) introduces a unified, feed-forward framework for 4D scene reconstruction from monocular videos. The method establishes a novel paradigm that integrates dense spatiotemporal representation and flexible per-frame motion and geometry querying, distinguishing itself from staged or pairwise approaches. Unlike prior work which often requires decoupled, multi-stage processing of geometry and motion, or resorts to pairwise or view-centric formulations, 4RC performs holistic, frame-dense 4D prediction in a single pass without dependence on per-scene optimization, iterative matching, or heuristic trackers. This essay details the architecture, training mechanisms, empirical performance, and the broader implications of the 4RC framework.
Methodology
4RC's core innovation is an encode-once, query-anywhere-and-anytime paradigm. Given a monocular RGB video V={Ii}i=1N, the model learns a compact latent representation F which encodes the global spatiotemporal attributes of the scene. This enables querying dense 3D geometry and dense pointwise motion for arbitrary source/target frame pairs, supporting both static reconstruction and dynamic scene tracking.
The encoder utilizes a Vision Transformer (ViT) that augments patchified image tokens with camera and per-frame time tokens. Frame-level tokens are processed through interleaved self- and global-attention layers to obtain the unified latent F, allowing disentanglement of viewpoint and temporal context.
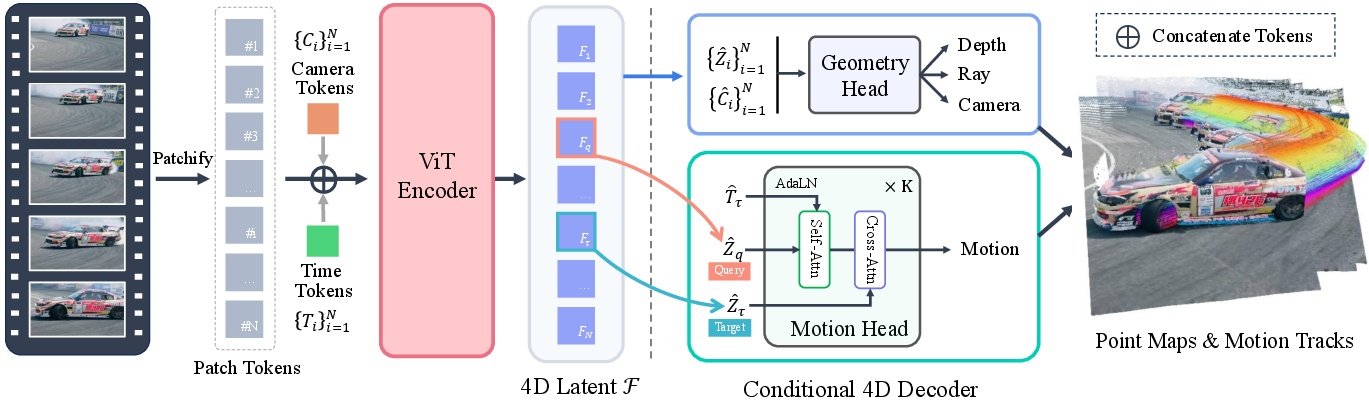
Figure 1: The 4RC architecture—video frames are patchified, augmented with camera/time tokens, and encoded into a compact 4D latent F for conditional per-frame geometry and motion querying.
A factorized attribute representation is used. The system decomposes the 4D output at time τ for source frame i as
Piti→τ=Piti+ΔPiti→τ
where Piti is the base geometry of frame i and ΔPiti→τ is the explicit 3D displacement to the target moment. This avoids recomputation of static geometry and enables temporal continuity.
Decoding is performed using two heads:
- The geometry head Dg predicts per-frame depth, rays, and camera pose.
- The motion head Dm, a lightweight transformer with self- and cross-attention, predicts dense pointwise displacements for arbitrary source-target pairs, conditioned via temporal embedding and cross-frame context.
The model is trained with joint supervision on reconstruction, motion, and camera parameters, including uncertainty estimation and both spatial and temporal gradient constraints for smoothness and realism.
Empirical Results
Dynamic 4D Tracking and Scene Motion
4RC's ability to perform dense 3D tracking is demonstrated on multiple dynamic datasets. On Kubric and Waymo, 4RC achieves best-in-class Average Percentage of Points (APD) and End-Point Error (EPE) among feed-forward 4D reconstruction models, outperforming both staged pipelines and established tracking-specific methods. Notably, on highly dynamic scenes (Waymo), 4RC improves over V-DPM by 36% APD, showcasing the advantage of global spatiotemporal reasoning rather than pairwise aggregation.
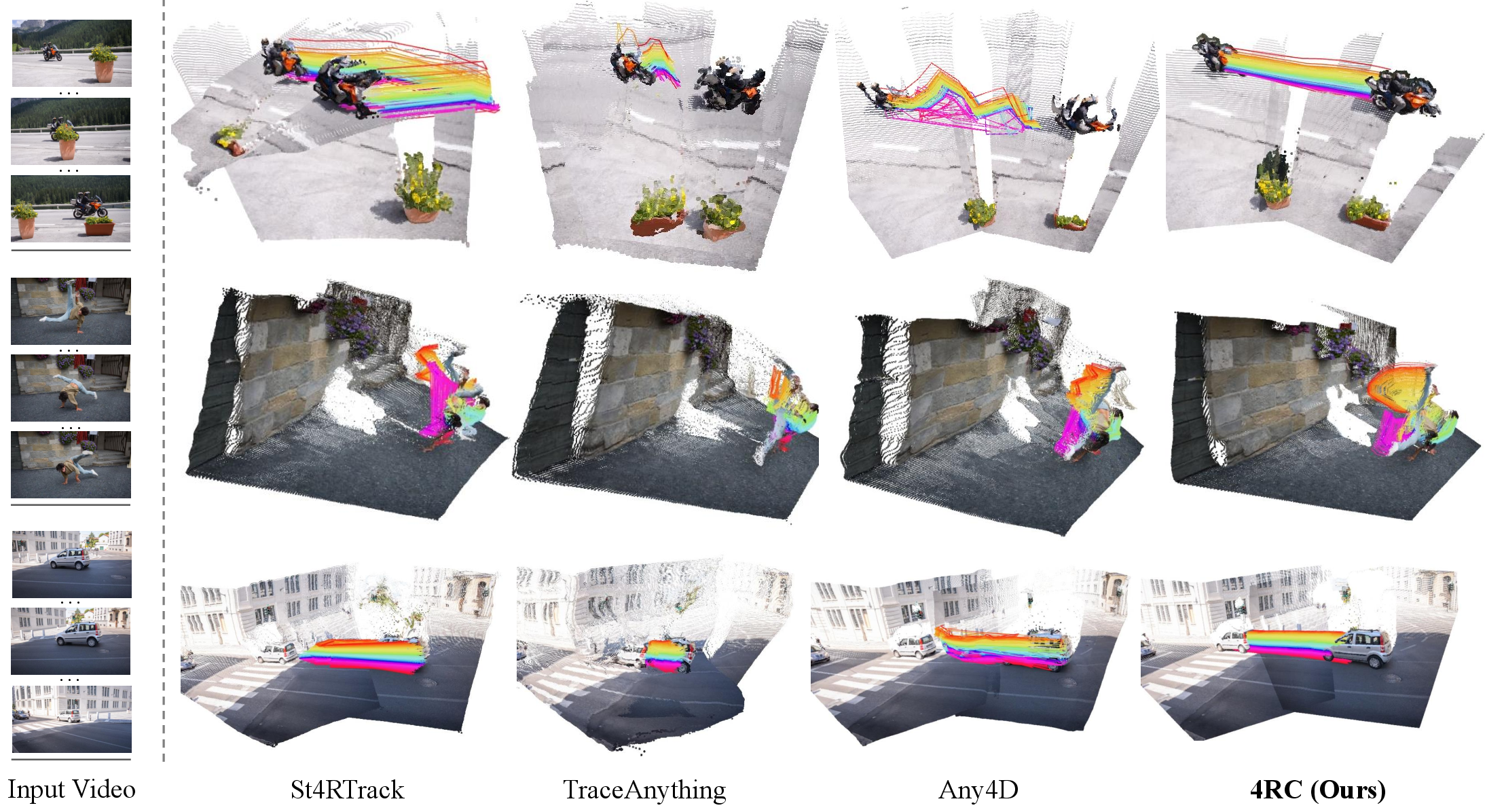
Figure 2: Qualitative reconstruction and tracking on DAVIS. 4RC robustly handles occlusion and long-range, complex motion compared to pairwise and stage-based approaches.
On sparse point tracking benchmarks (such as WorldTrack, ADT, and Panoptic Studio), 4RC delivers performance competitive with dedicated trackers, despite being trained for holistic reconstruction rather than just tracking.
General 3D Perception: Pose, Depth, and Multi-View Reconstruction
4RC achieves strong results in camera pose estimation on TUM-dynamics and ScanNet, attaining lowest ATE and RPE among 4D models and performing comparably with state-of-the-art 3D-only reconstruction networks such as Pi3 and VGGT—even though 4RC is also handling time-varying motion. In multi-view 3D reconstruction (7-Scenes, NRGBD) and monocular depth estimation (Bonn, Sintel), 4RC again matches or exceeds the most capable 4D and many specialist 3D models.

Figure 3: In-the-wild scene reconstructions. 4RC accurately models both static and dynamic objects, reconstructing geometry and dense motion in diverse environments.
Ablations and Model Analysis
Ablation studies confirm the necessity of the full conditional motion head design. Removal of either self-attention, cross-attention, or AdaLN from the motion decoder degrades accuracy in motion modeling. Factorization of motion—explicitly representing displacement separate from base geometry—substantially improves both tracking fidelity and temporal consistency over direct dense point cloud prediction.

Figure 4: Ablation studies—without cross-attention, fine articulated motion is missed; direct point cloud outputs lose temporal coherence.
4RC also supports a streaming online variant ("S-4RC") that processes videos causally with only past context. While there is a modest performance drop, this variant remains competitive and enables applications in real-time robotics and egocentric perception.

Figure 5: S-4RC visualizations of online 4D inference, supporting robotics and framewise scene understanding.
Further visualizations indicate generalization to unconstrained, real-world scenarios, confirming the robustness of the learned representation.

Figure 6: Results on unconstrained videos showing camera poses, static and dynamic reconstructions, and 3D point tracking.
Implications and Future Directions
By unifying dense scene geometry and time-varying motion in a flexible, feed-forward, query-based representation, 4RC demonstrates that holistic 4D perception can be achieved without iterative optimization, heavy post-processing, or decoupled modeling. This paradigm is especially valuable for downstream tasks requiring fine-grained, frame-accurate 4D reasoning, such as robotics motion planning, dynamic scene understanding, video synthesis, and AR/VR content authoring.
The encode-once/query-anytime framework opens up opportunities for:
- Efficient 4D perception with minimal computational or memory overhead for new queries or downstream reasoning.
- Unified handling of static and dynamic scenes, with clear separation of base geometry and motion for transfer, analysis, or editing.
- Scalable 4D learning on large, mixed datasets with both dense and sparse motion annotation.
However, the dependence on geometric supervision limits performance in cases involving complex, transparent, or extremely distant regions, and highly chaotic object motion remains a challenge due to annotation scarcity. Scaling up to broader kinematic distributions, integrating improved monocular depth priors, or leveraging larger synthetic motion corpora represent clear directions for further enhancement.
Conclusion
4RC presents a significant advancement in 4D scene reconstruction, introducing an efficient, conditional querying framework that holistically models both geometry and motion in monocular video. The model consistently achieves best or near-best performance on a comprehensive suite of 4D and 3D tasks, outperforming previous feed-forward and staged approaches. 4RC exemplifies the trend toward unified architectures in perceptual computer vision and signals a move toward genuinely general-purpose, spatiotemporal scene understanding systems.