Qwen-AgentWorld: Language World Models for General Agents
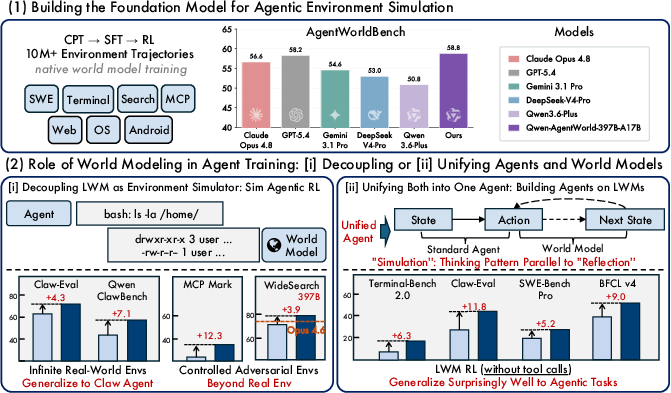
Abstract: A world model predicts environment dynamics based on current observations and actions, serving as a core cognitive mechanism for reasoning and planning. In this work, we investigate how world modeling based on LLMs can further push the boundaries of general agents. (i) We first focus on building foundation models for agentic environment simulation. We introduce Qwen-AgentWorld-35B-A3B and Qwen-AgentWorld-397B-A17B, the first language world models capable of simulating agentic environments covering 7 domains via long chain-of-thought reasoning. Leveraging more than 10M environment interaction trajectories of 7 domains in real-world environments, we develop Qwen-AgentWorld through a three-stage training pipeline: CPT injects general-purpose world modeling capabilities from the state transition dynamics and augmented professional corpora, SFT activates next-state-prediction reasoning, and RL sharpens simulation fidelity through a tailored framework with hybrid rubric-and-rule rewards. To evaluate language world models, we present AgentWorldBench, a comprehensive benchmark constructed from real-world interactions of 5 frontier models on 9 established benchmarks. Empirical results demonstrate that Qwen-AgentWorld significantly outperforms existing frontier models. (ii) Beyond foundation models, we further investigate two complementary paradigms through which world modeling enhances general agents. First, as a decoupled environment simulator, Qwen-AgentWorld supports scalable and controllable simulation of thousands of real-world environments for agentic RL, yielding gains that surpass real-environment training alone. Second, as a unified agent foundation model, world-model training acts as a highly effective warm-up that improves downstream performance across 7 agentic benchmarks. Code: https://github.com/QwenLM/Qwen-AgentWorld
First 10 authors:



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
Imagine a super-smart “game master” that can predict what will happen next in many different kinds of computer tasks—like typing in a terminal, clicking around a phone app, browsing the web, searching online, or editing code—just by reading what you did last and what you do next. This paper builds that “game master” for language-based AI systems. The authors call it a Language World Model (LWM), named Qwen-AgentWorld. Its job is to predict the next screen, message, or result an agent would see after taking an action, across seven different domains.
What questions the researchers asked
In simple terms, they asked:
- Can a LLM learn to “imagine” and accurately predict what a real computer environment would do after each action an agent takes?
- If it can, does that help us build better AI agents—either by letting them train inside this simulated world, or by teaching them to think ahead before acting in real systems?
- How do we judge whether these predictions are realistic, useful, and consistent over many steps?
How they did it (in everyday language)
Think of Qwen-AgentWorld like a flight simulator, but for language-based tasks:
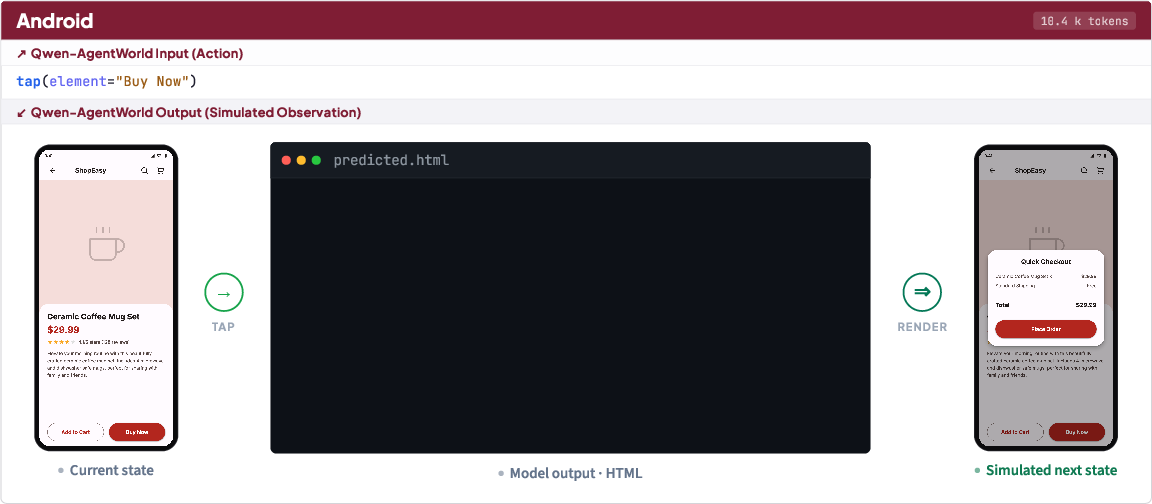
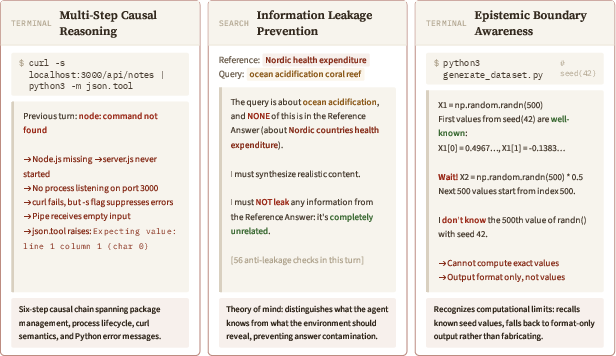
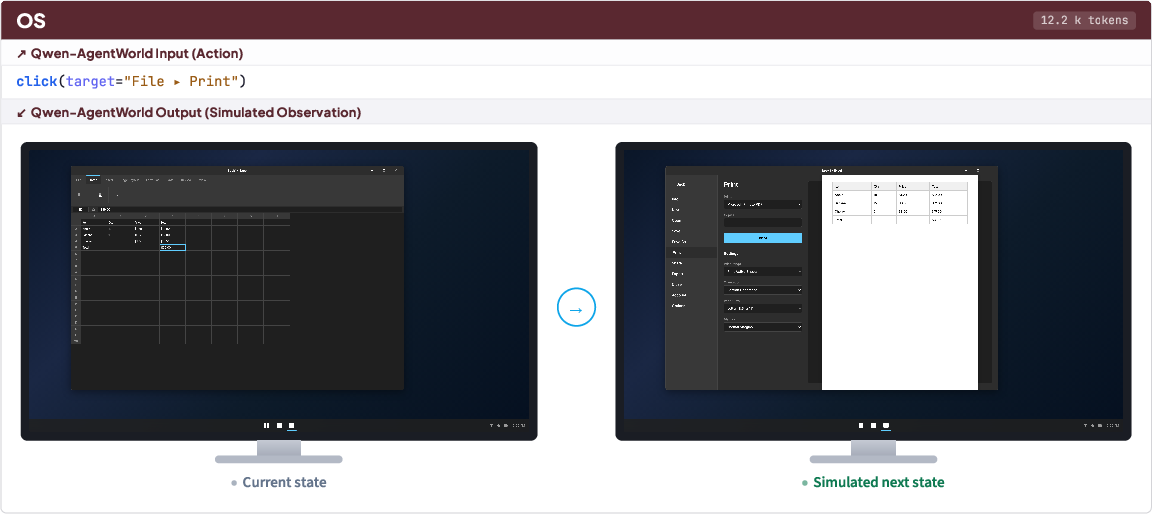
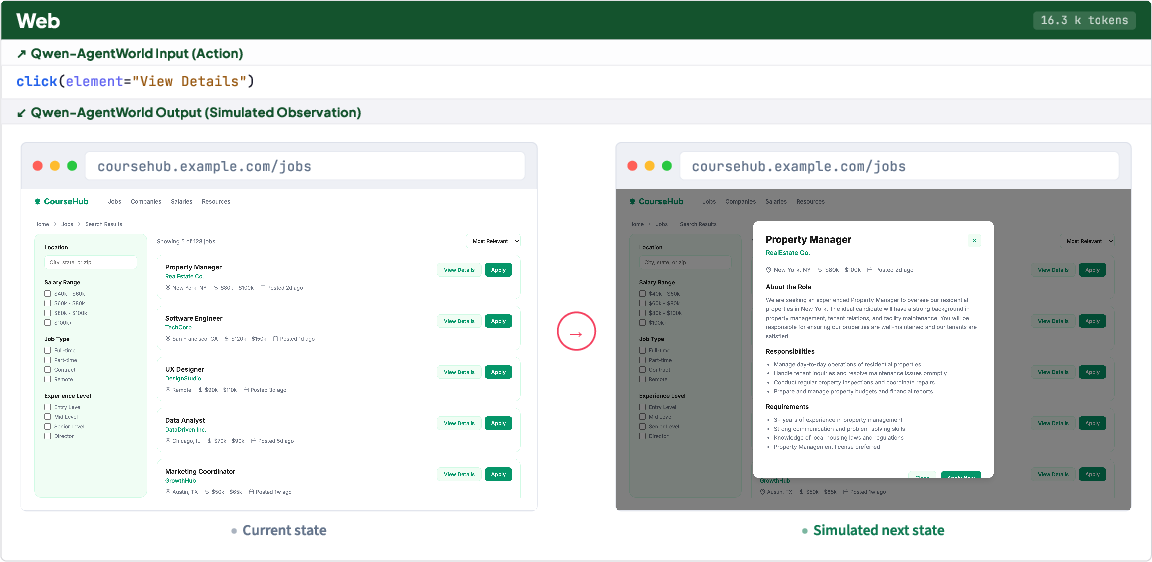
- Instead of pixels, it uses text to describe what’s going on (for example, phone screens are represented as structured lists of buttons and labels; terminals are shown as command lines and outputs).
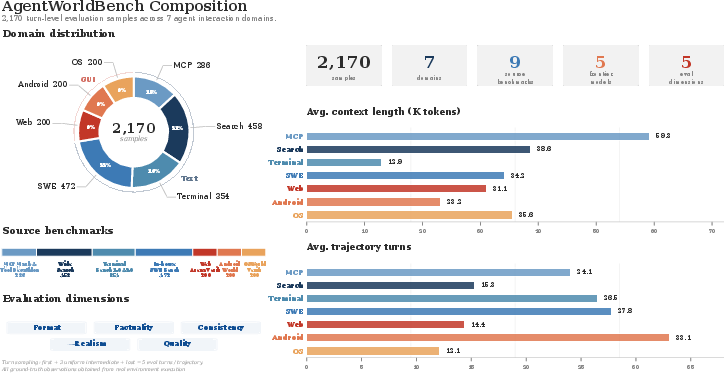
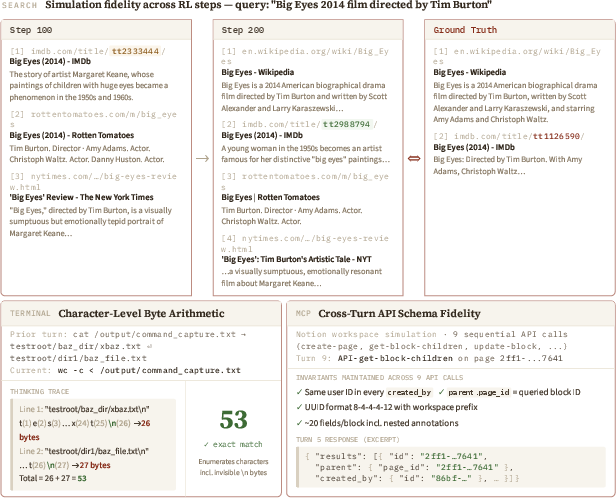
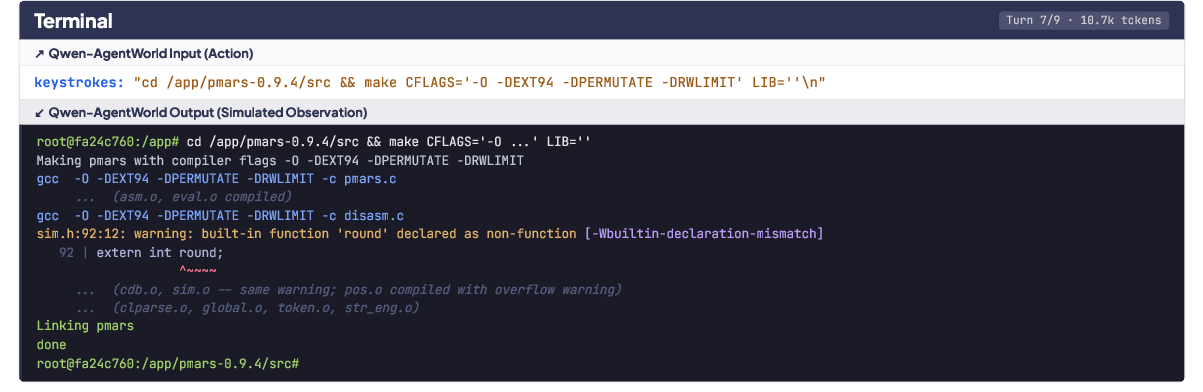
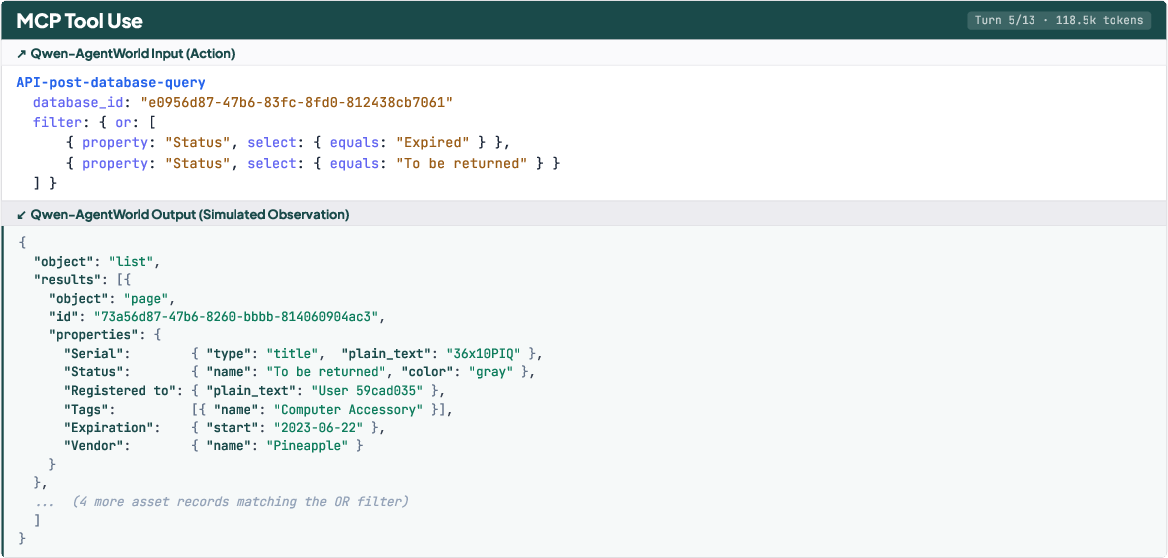
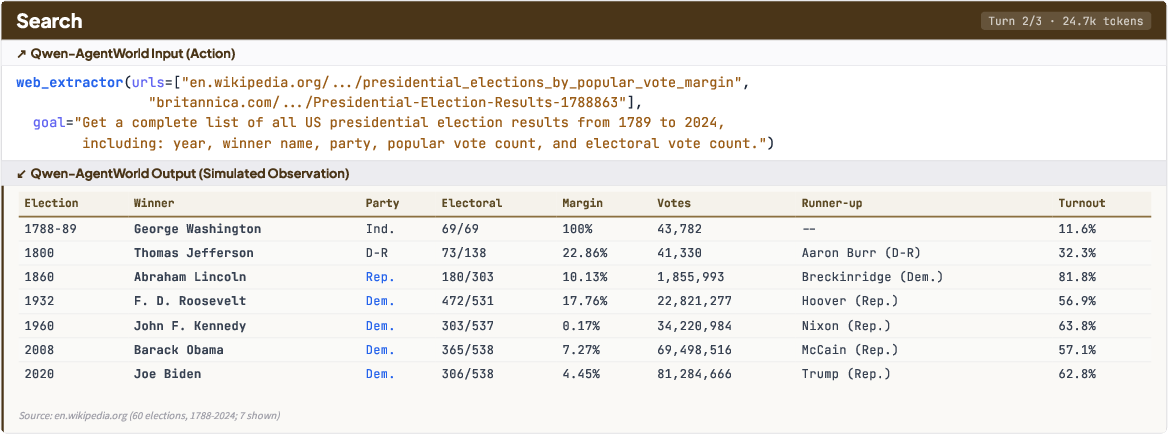
- It learns from millions of real interaction logs across seven domains (MCP tools, Web Search, Terminal, Software Engineering, Android apps, Web browsing, and Desktop OS). Each log is a series of turns: “action → environment response → next action → next response,” and so on.
- It uses a simple, shared “recipe” to represent all these worlds: a system setup, a list of allowed actions, an initial state, and then the back-and-forth turns. This makes very different tasks feel similar to the model.
To train the model, they used a three-step pipeline (like learning, practicing, and polishing):
- Continual Pre-Training (CPT): The model “reads a ton” of examples to absorb how states change. It also studies extra knowledge (like law, medicine, finance, and current events) so it can simulate specialized systems more realistically.
- Supervised Fine-Tuning (SFT): The model practices the specific skill of “next-state prediction”—thinking explicitly about what should happen next, instead of just guessing the next word. It uses long memory (up to hundreds of thousands of tokens) so it can stay consistent over many steps.
- Reinforcement Learning (RL):
The model is rewarded for predictions that are faithful and useful. Rewards come from:
- A judging rubric (like grading on multiple aspects such as formatting, factual correctness, staying consistent with past steps, and following rules).
- Rule-based checks (exact yes/no tests when possible). They also built safeguards to avoid “reward hacking” (for example, ignoring self-congratulating text and checking only the actual predicted content).
Other smart tricks they used:
- Focus on learning from turns with real new information and downplay “boring repeats,” so the model doesn’t waste time copying boilerplate.
- Automatically optimize the system prompts (the instructions given to the model) through an iterative “auto-research” loop that proposes, tests, and refines better prompts.
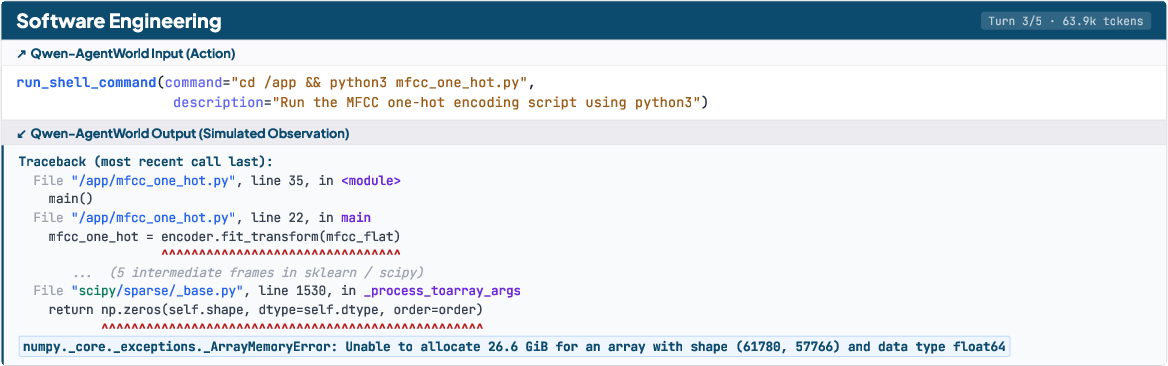
- For GUI tasks (Android/Web/OS), they use structured trees of UI elements instead of images, which makes text prediction practical and precise.
What they found and why it matters
- The researchers built two strong world models (different sizes), and show that Qwen-AgentWorld can realistically simulate seven types of environments via long, step-by-step reasoning.
- On a new evaluation suite they created (AgentWorldBench), which is based on real interactions from top AI models across nine established benchmarks, Qwen-AgentWorld beats frontier baselines. The judging checks multiple dimensions, not just “did it look similar,” but also “did it follow the rules,” “was it factual,” and “did it stay consistent with previous steps.”
- Two big ways this helps agents:
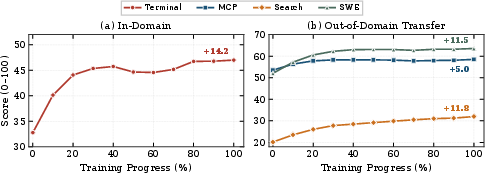
- As a separate simulator: Agents can train in thousands of “what-if” worlds. Because the simulator is controllable, it can add rare problems on purpose (like partial results, low disk space, or hidden answers) so agents learn to handle tough edge cases. In tests, training with the simulator gives better performance than training only in the real world.
- As a foundation to think ahead: Training the agent to predict the next state becomes a new style of “future-focused reflection.” Agents that learn this first tend to perform better on later tasks across coding, web, terminal, and other benchmarks.
Why this is important
- Safer, stronger agents: Agents that can predict what will happen before acting make fewer mistakes and can plan better.
- Scalable training: You don’t need special sandboxes for every tool or app; you can practice in a text-based, controllable simulation, including situations that are hard or costly to recreate in real life.
- Broad generalization: Because the model unifies seven domains under one text format and learns general state-transition rules, it can carry lessons from one area (like terminals) to others (like web or OS control).
Bottom line
This paper shows that teaching a LLM to be a faithful “world simulator” is both possible and powerful. Qwen-AgentWorld can predict what real environments would do across many domains, and that ability makes AI agents better—whether you use the simulator to train them or bake the “think-ahead” skill directly into the agent itself. This moves us closer to general, reliable AI assistants that can learn, plan, and act across many real-world computer tasks.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
The paper proposes a language world model (LWM) for seven agentic domains and outlines a CPT–SFT–RL pipeline with rubric-based rewards and controllable simulations. The following points identify what remains missing, uncertain, or unexplored:
- Data transparency and reproducibility: the “>10M trajectories” claim lacks a public release, dataset schema, license, de-duplication details across CPT/SFT/RL, and per-domain/task distributions necessary for replication and controlled ablations.
- Benchmark leakage risks: AgentWorldBench is “constructed from real-world interactions of 5 frontier models on 9 benchmarks,” but procedures to prevent training/validation/test overlap at sample, task, and site/URL levels are not specified; concrete leakage audits are absent.
- Coverage and balance of domains: the seven domains’ relative volume, difficulty, and long-horizon coverage are not quantified; it is unclear whether any domain dominates training signals or if long-tail cases (e.g., rare shell features, uncommon Android widgets) are underrepresented.
- Privacy and compliance: using open interaction traces and in-house logs raises unresolved questions about PII removal, consent, provenance tracking, and compliance (e.g., GDPR/CCPA) in the released artifacts and pretraining corpora.
- GUI representation gap: replacing pixels with accessibility trees/UI hierarchies may omit visual/gestural nuances (e.g., occlusions, color cues, animations); generalization to pixel-based UIs and mixed-modality inputs remains untested.
- Non-text modalities: the approach excludes pixels, audio, and binary artifacts; how to incorporate and evaluate multimodal state transitions (e.g., screenshots, PDFs, charts) is left open.
- Non-determinism and stochasticity: handling time-dependent fields (timestamps, PIDs), randomized web content, network latencies, and concurrency/background processes is not formally addressed beyond heuristic judge prompts; modeling multi-modal distributions and uncertainty is unresolved.
- State fidelity in OS/Terminal: the ability to track and predict complex side effects (e.g., file locks, permission changes, background daemons, process signals, partial writes, package manager states) is not systematically evaluated with executable ground-truth checks.
- Controllable simulation validity: while “simulation_instruction” enables targeted perturbations, there is no formal analysis of consistency with initial state constraints (e.g., disk limits, GPU availability) or stress tests of contradictory/overconstraining instructions.
- Generalization to unseen tools/APIs: MCP and SWE use per-trajectory action spaces, but zero-shot generalization to unseen tools, new APIs, shell builtins, OS versions, and web/Android components is not quantified.
- Transfer across domains: the extent to which knowledge transfers between text-based (Terminal/SWE) and GUI (Android/Web/OS) domains is not isolated with cross-domain ablations.
- CPT–SFT–RL contributions: the paper states “CPT injects, SFT activates, RL sharpens” but lacks controlled ablations that quantify each stage’s incremental gains per domain and per rubric dimension.
- Turn-level loss masking: thresholds and category cutoffs (OL, Nov, Jac, R) are heuristic; their stability, domain-specific sensitivity, and potential to bias the model toward high-novelty outputs (and away from necessary low-novelty transitions) are untested.
- Prompt engineering via AutoResearch: risks of prompt overfitting to judge criteria, reproducibility of the optimizer’s results, and sensitivity of model performance to prompt variants during inference are not examined.
- RL reward reliability: rubric judges introduce bias/variance; inter-judge agreement, calibration against human evaluation, and failure rates across content types are not reported; robustness to adversarial formatting or “style hacking” remains uncertain.
- Rule-based verifiers: coverage and representativeness of executable checks across domains are unspecified; how much of the RL signal comes from deterministic verifiers versus rubrics is only given as a fixed 9:1 weighting without justification or sensitivity analysis.
- Reward hacking residuals: although mitigations are described, the paper does not quantify residual reward hacking or provide adversarial stress tests (e.g., systematic self-praise insertion, prompt-token exploits).
- Prompt–output asymmetry: the impact of 128k/256k prompt truncation (both in RL and SFT) on long-horizon consistency, and strategies like retrieval or memory compression for scaling beyond these limits, are not explored.
- Computation and efficiency: compute budgets, training throughput, energy costs, and inference latency for long-context next-state prediction are not provided; the practicality for large-scale RL or real-time agent usage is unclear.
- Uncertainty estimation: the model does not report confidence or aleatoric/epistemic uncertainty; mechanisms to abstain, defer to environment execution, or branch on uncertain predictions are missing.
- Simulator-to-real transfer: while gains “surpass real-environment training alone” are claimed, there is no detailed quantification of sim-to-real gap, negative transfer cases, or protocols (e.g., domain randomization) to prevent overfitting to simulator artifacts.
- Foundation model integration: the “unify” paradigm does not specify how next-state prediction is operationalized during agent inference (e.g., explicit rollouts, model predictive control, lookahead depth, compute trade-offs), nor its net effect on latency and success rates.
- Error accumulation in long horizons: there is no analysis of compounding prediction errors across many turns, or mechanisms to resynchronize with ground truth during RL or evaluation.
- Partial observability: strategies for modeling and evaluating POMDP-like settings (hidden state, delayed observations, missing data) are not detailed beyond removing “no-change” turns in GUI domains.
- Multi-agent/multi-user realism: interactions with multiple agents/users, concurrent tool invocations, and contention over shared state are not modeled or evaluated.
- Safety and dual-use: the inclusion of cybersecurity and high-stakes domains raises open questions about capability controls, misuse prevention (e.g., exploit simulation fidelity), and red-teaming the controllable simulator.
- Bias and fairness: potential biases in world-knowledge corpora and interaction traces, and their downstream effects on environment simulation and agent behavior, are not assessed.
- Internationalization: support and evaluation for non-English environments (locales, input methods, right-to-left UIs) and cross-lingual search/OS/Web behavior are unspecified.
- Evaluation metrics clarity: the five rubric dimensions are referenced but not fully formalized in the presented text (weighting, scoring rubrics, ties to exact-match verifiers); metric sensitivity and inter-rater reliability are not reported.
- Benchmark availability and stability: the openness, maintenance, and versioning of AgentWorldBench, including dynamic web content that changes over time, are not described.
- Grounded closed-loop validation: the fraction of benchmark tasks with executable, deterministic ground truth versus purely judged outputs is unclear; systematic coverage of deterministically verifiable aspects remains unspecified.
- Robustness to noisy data: while a denoising pipeline exists, there are no error-rate estimates for remaining noise, nor experiments on robustness to structured noise or missing turns.
- Scaling beyond seven domains: requirements, data, and adaptations needed to extend LWM to new domains (e.g., spreadsheets, CAD, robotics control) are not articulated.
- Security of the RL pipeline: asynchronous judge APIs and JSON parsing are potential attack surfaces; hardened evaluation, sandboxing, and data validation practices are not detailed.
- Interpretability: how the model’s chain-of-thought for next-state prediction relates to learned state-transition rules (and whether these can be audited or constrained) is not explored.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, drawing directly from the paper’s findings on language world models (LWM), controllable simulation, and evaluation via AgentWorldBench.
- Agent RL training and rapid iteration with a decoupled simulator
- Sectors: software, developer tools, search, RPA, MLOps
- What you can do now: Use Qwen-AgentWorld as an “environment simulator” to run SimRL (agent RL against simulated MCP/Search/Terminal/SWE/Web/Android/OS). Scale training without sandboxes/VM farms; mix real-environment RL with controllable sim to surpass real-only training.
- Potential tools/products/workflows: “SimRL Trainer” service that spins up thousands of simulated task instances; unified gym-style API; curriculum schedules alternating real vs. simulated episodes; automatic domain randomization with simulation instructions.
- Assumptions/dependencies: Simulator access (API/weights), long-context inference budget (128k–256k tokens), verifiers for key tasks to anchor rewards, periodic real-environment evaluation to prevent simulator overfitting.
- Edge-case generation and robustness testing via controllable simulation
- Sectors: search platforms, SaaS, mobile apps, enterprise RPA, dev tools
- What you can do now: Craft targeted perturbations (e.g., partial tool responses, timeouts, permission errors, corrupted state, rate limits) to surface agent failure modes. Train and test recovery policies not seen in live logs.
- Potential tools/products/workflows: “Perturbation Lab” with scenario templates (e.g., Search no-leakage constraints, Terminal disk-full, Android intermittent network); red-team suites for tool-use agents; regression test sets with reproducible failures.
- Assumptions/dependencies: Simulator’s simulation_instruction field supported; domain experts to calibrate realism; coverage of critical APIs/UX paths.
- Continuous integration for agents with AgentWorldBench-style regression suites
- Sectors: MLOps, model evaluation, procurement
- What you can do now: Adopt AgentWorldBench methodology to build internal, ground-truth-grounded, long-context regression suites for tool-use agents; track format/factuality/state-consistency/regression across versions.
- Potential tools/products/workflows: “Agent Regression Suite” with nightly runs; score dashboards per rubric dimension; gating criteria for model promotion.
- Assumptions/dependencies: Access to historical real trajectories; rubric judges and (where possible) rule-based verifiers; evaluation compute.
- GUI flow prototyping and UX QA without full device/browser farms
- Sectors: mobile/web/desktop app teams, QA, automation
- What you can do now: Simulate Android/Web/OS UI flows using accessibility trees and UI hierarchies to test onboarding, checkout, or support flows; script end-to-end journeys and assert next-screen state.
- Potential tools/products/workflows: “UI Journey Simulator” integration into QA pipelines; synthetic A/B UX tests; pre-release flow validation for localization or network constraints.
- Assumptions/dependencies: App state export to textual UI trees; mapping fidelity between simulated and real UI states; policy for data handling.
- Developer training, upskilling, and safe “dry-run” execution
- Sectors: education, workforce training, dev tooling, cybersecurity basics
- What you can do now: Provide interactive labs where learners practice terminals, build scripts, or run code with faithful predicted outputs (including realistic errors); preview command effects before running on prod.
- Potential tools/products/workflows: “CLI Tutor” and “SWE Debugger” that predict traceback/output; sandboxed “What happens if I run X?” assistants; guided troubleshooting curricula.
- Assumptions/dependencies: Clear disclaimers that outputs are simulations; alignment to curricula; safeguards to prevent harmful misuse.
- Prompt/system-prompt optimization via AutoResearch
- Sectors: LLMOps, platform teams, evaluation labs
- What you can do now: Reuse the paper’s AutoResearch loop to optimize system prompts for new domains, improving environment fidelity and prediction stability with propose–evaluate–refine cycles against held-out data.
- Potential tools/products/workflows: “Prompt Optimizer” that outputs variant templates (spec/checklist/demonstration-heavy) and auto-selects best per domain.
- Assumptions/dependencies: Held-out evaluation data; robust judge prompts; compute for iterative optimization.
- Data augmentation and trajectory curation for tool-use SFT
- Sectors: model training, dataset providers
- What you can do now: Generate high-quality, turn-expanded, schema-normalized environment trajectories; apply information-theoretic masking (OL/Nov/Jac/R) to filter boilerplate turns; build balanced SFT sets that activate next-state prediction thinking.
- Potential tools/products/workflows: “Trajectory Blender” with per-domain handlers; loss-masking toolkit; multi-beam rejection sampling with judge scoring.
- Assumptions/dependencies: Access to domain traces; deduplication and privacy filtering; monitoring for distribution shift.
- Reward and judge design kits for agent RL
- Sectors: RLHF/RLAIF tooling, enterprise AI
- What you can do now: Combine 5D rubric rewards with rule-based verifiers to stabilize agent RL on open-ended outputs; add strict tag extraction to prevent self-praise reward hacking.
- Potential tools/products/workflows: “RubricKit” with domain judge prompts, content-type classification, verifiers library; pipelines to detect/mitigate reward hacking patterns.
- Assumptions/dependencies: Engineering effort to write verifiers; coverage limits of binary checks; careful judge prompt tuning.
- Enterprise RPA bot “dry-run” for internal workflows
- Sectors: finance back office, operations, IT service desks
- What you can do now: Simulate desktop/web flows for ticket processing, KYC form checks, or report generation before deploying bots; iterate policies in-silico.
- Potential tools/products/workflows: “Bot Dry-Run” orchestrator that replays business processes end-to-end in simulation; failure-injection scenarios to harden bot behavior.
- Assumptions/dependencies: Ability to export or approximate internal UI/state representations; data governance approvals.
- Academic research on tool-use planning and robustness
- Sectors: academia, research labs
- What you can do now: Use the simulator to run controlled studies on query planning (Search), chain-of-tools design (MCP), or long-context degradation, with repeatable conditions and ground-truth-linked rubrics.
- Potential tools/products/workflows: Open research benchmarks mirroring AgentWorldBench, ablation studies on context windows, masking strategies, or training curricula.
- Assumptions/dependencies: Access to simulator/checkpoints; reproducibility protocols; public release policies.
Long-Term Applications
These use cases are feasible with further research, scaling, or integration work (e.g., broader domains, stronger verifiers, or tighter sim-to-real coupling).
- Cross-domain digital twins of enterprise information systems
- Sectors: finance, healthcare, logistics, government IT
- Vision: Build LWM-backed “digital twins” of business applications (ERPs, EHRs, case management), enabling safe pre-deployment training and what-if rehearsal for AI copilots and RPA agents.
- Potential tools/products/workflows: “Enterprise Digital Twin” platform with connectors to app schemas, policy-injected simulation instructions (e.g., rate limits, compliance constraints), and verifiers for critical steps.
- Assumptions/dependencies: High-fidelity UI/state export; privacy-preserving data synthesis; formal acceptance by risk/compliance teams; continuous alignment with real systems.
- Regulatory sandbox-as-a-service for AI agents
- Sectors: policy/regulators, legal, public sector
- Vision: Test agent compliance, auditability, and robustness in synthetic-yet-faithful simulations of regulated workflows (claims processing, benefits eligibility, adverse event handling).
- Potential tools/products/workflows: “Regulatory Sandbox” with domain-specific rubrics, audit logs, and rule verifiers; standardized conformance tests.
- Assumptions/dependencies: Regulator buy-in; credible simulation validation; secure data handling; governance frameworks for score interpretation.
- Healthcare EHR task simulation and validation
- Sectors: healthcare IT, clinical decision support
- Vision: Train/evaluate agents for order entry, documentation, scheduling, and prior authorization using LWM simulation to avoid touching PHI during development.
- Potential tools/products/workflows: “EHR Sim Lab” with domain corpora (terminologies, guidelines), safety verifiers (drug–drug interactions), and controlled failure modes (alerts, formulary changes).
- Assumptions/dependencies: Clinical validation; strong rule-based verifiers; regulatory approvals (HIPAA, FDA where relevant); integration with vendor ecosystems.
- Autonomous software engineering with sim-first CI
- Sectors: software, DevOps, platform engineering
- Vision: Close the loop from issue triage to patch proposal to validation entirely in simulated repos/terminals before limited real tests; scale “auto-fix” workflows.
- Potential tools/products/workflows: “Simulated CI/CD” that predicts build/test outcomes, fault injection (e.g., disk/memory/network), and policy-gated promotion to staging; agent warm-up with world modeling.
- Assumptions/dependencies: Accurate simulation of complex toolchains; alignment with real flaky tests; robust guardrails to prevent error amplification.
- Cyber ranges and security drills in text-based environments
- Sectors: cybersecurity training, SOC, OT/ICS security
- Vision: Realistic, controllable ranges for shell tooling, logs, and incident response procedures; safe practice with verifiable scoring.
- Potential tools/products/workflows: “Text Cyber Range” with simulated services/logs, incident injects, and scoring verifiers; adaptive curricula using controllable perturbations.
- Assumptions/dependencies: High-fidelity domain corpora (protocols, typical artifacts); careful safety controls; limited to non-exploit training content.
- Personal computing copilots with safe “dry-run” mode
- Sectors: consumer software, productivity
- Vision: Before executing on your machine, the copilot predicts OS/Browser/Android next state and shows diffs; user approves or revises.
- Potential tools/products/workflows: “Safe Action Preview” overlays that visualize anticipated UI changes/filesystem edits/network calls; opt-in execution after user review.
- Assumptions/dependencies: OS/browser integration; mismatch detection between predicted and actual state; privacy-preserving local inference.
- Marketplace of simulated tasks and standardized agent certifications
- Sectors: model marketplaces, enterprise procurement, edtech
- Vision: Public catalogs of simulated tasks with rubrics/verifiers; standardized “competency badges” for agent reliability across domains and edge cases.
- Potential tools/products/workflows: “Sim Task Hub” with curated scenarios; third-party certification audits; procurement scorecards aligned to AgentWorldBench dimensions.
- Assumptions/dependencies: Community maintenance of tasks/verifiers; anti-gaming measures; legal terms for score usage.
- Curriculum learning and meta-cognitive training for agents
- Sectors: academia, foundation model labs
- Vision: Institutionalize world-model warm-up (CPT→SFT→RL) as a precondition for strong agent performance; train explicit next-state prediction as a core reasoning pattern.
- Potential tools/products/workflows: Open recipes for LWM warm-up, long-context curricula, and controllable challenges; cross-domain transfer studies.
- Assumptions/dependencies: Scalable long-context compute; robust data pipelines; shared evaluation standards.
- Extension to robotics and multimodal digital–physical hybrids
- Sectors: robotics, manufacturing, warehousing, energy
- Vision: Combine textual state simulators with vision/physics to build lightweight “language-first” world models for task planning and GUI–robot handoffs (e.g., HMI/SCADA via accessibility trees + real actuators).
- Potential tools/products/workflows: “GUI-to-Actuator” bridges; simulation instructions reflecting sensor noise and latency; safety verifiers for physical actions.
- Assumptions/dependencies: Multimodal modeling, physics-grounded sim; strict safety protocols; high-quality datasets.
- Grid/plant ops and energy control simulations (textual HMI)
- Sectors: energy, utilities, industrial control
- Vision: Train supervisory copilots on text-based representations of HMIs for alarm triage, procedure guidance, and incident rehearsal.
- Potential tools/products/workflows: “Ops Sim Lab” with domain-specific rules, incident injects, and verifiers aligned with standard operating procedures.
- Assumptions/dependencies: Access to domain schemas; safety-critical validation; regulatory oversight.
Cross-cutting assumptions and dependencies (impacting feasibility)
- Simulator fidelity vs. real systems: Regular real-world evaluation is needed to prevent sim-to-real gaps; rule-based verifiers help anchor open-ended rubric rewards.
- Long-context compute: Many workflows require 128k–256k token windows; plan for inference cost and throughput.
- Data governance: Using internal trajectories or UI states demands privacy-preserving pipelines and clear consent/licensing.
- Judge robustness and reward hacking: Use strict tag extraction, content-type classification, and binary verifiers to mitigate self-praise and bias exploitation.
- Domain portability: GUI simulations rely on accessibility trees/UI hierarchies; internal apps must expose or approximate these to benefit from LWM.
- Organizational buy-in: For regulated domains, legal/risk teams must accept simulation-based validation as evidence; may require external certification.
Glossary
- Accessibility tree: A structured textual representation of a GUI or web page’s elements used to capture accessibility-relevant state. "For the three GUI domains, environment observations are represented as accessibility trees and UI view hierarchies rather than pixel frames."
- Action space: The set of available operations/tools and their calling conventions that an agent can use in a domain. "The action space enumerates the available tools or operations and their calling conventions."
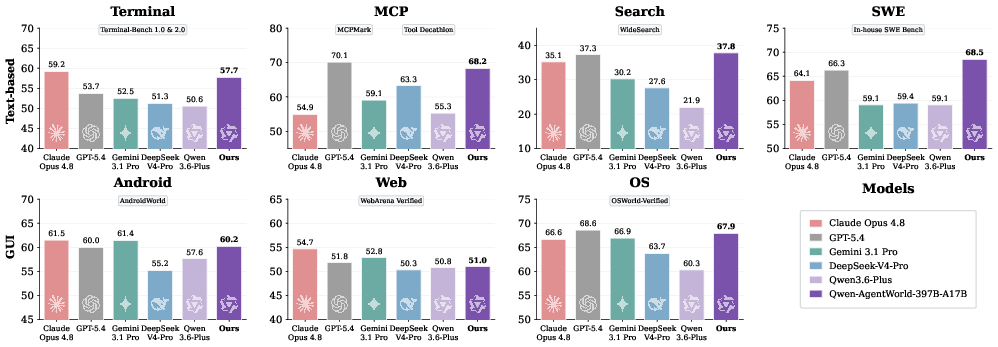
- Agent Foundation Model: A unified base agent model whose capabilities are improved via world-model training before downstream tasks. "Second, as a unified agent foundation model, world-model training acts as a highly effective warm-up that improves downstream performance across 7 agentic benchmarks."
- AgentWorldBench: A benchmark designed to evaluate language world models across multiple interaction domains. "We construct AgentWorldBench to evaluate language world models across seven agent interaction domains."
- Agentic RL: Reinforcement learning where the agent trains via simulated or real interactive environments focused on agent behavior. "We demonstrate that Qwen-AgentWorld can simulate $4k$ real-world OpenClaw environments for agentic RL, yielding gains on Claw-Eval~\citep{ye2026claw} and QwenClawBench~\citep{qwenclawbench}."
- Agentic trajectory: The agent’s single completion trace for a task, interleaving internal reasoning with actions and environment observations. "In contrast, an agentic trajectory is the agent's single completion for a task, a multi-step tool-integrated reasoning trace that interleaves the agent's internal thinking and action selection with the environment's observations."
- AutoResearch: An automated prompt-optimization approach that iteratively proposes and evaluates system prompt templates. "System Prompt Template Construction via AutoResearch."
- BFCL v4: A benchmark (Berkeley Function-Calling Leaderboard v4) used to assess function-calling and agent performance. "Comprehensive experiments on Terminal-Bench 2.0~\citep{merrill2026terminal}, SWE-Bench Verified~\citep{jimenez2024swe}, SWE-Bench Pro~\citep{deng2025swe}, BFCL~v4~\citep{patil2025berkeley}, Claw-Eval~\citep{ye2026claw}, QwenClawBench~\citep{qwenclawbench}, and WideSearch~\citep{wong2025widesearch} demonstrate that LWM training serves as a warm-up or auxiliary training stage."
- Chain-of-thought reasoning: Step-by-step explicit reasoning sequences produced by the model. "the first language world models capable of simulating agentic environments covering 7 domains via long chain-of-thought reasoning."
- Continual Pre-Training (CPT): A pre-training stage that injects broad environment dynamics and knowledge into the model. "CPT injects general-purpose world modeling capabilities from the state transition dynamics and augmented professional corpora"
- Controllable simulation: The ability to condition environment simulation on directives to produce targeted behaviors or perturbations. "The simulation instruction specifies controllable simulation conditions (e.g., ``hide the answer from the web_search responses'') and is used primarily for the controllable simulation experiments (\S\ref{sec:app:controllable})."
- Decoupling: Using the world model as a simulator separate from the agent policy to achieve scalable and controllable training. "(1) Decoupling: Using the world model as a simulator facilitates turn-level scalability and controllability."
- Deterministic checks: Exact verifications of predicted environment responses against ground truth using rules or executables. "We additionally design rule-based verifiers for deterministic checks on targeted simulation capabilities."
- Echo Trap: A failure mode in multi-turn RL where shared prefixes cause reward variance collapse and policy degeneration. "This is related to the ``Echo Trap'' identified in multi-turn agent RL~\citep{wang2025ragen}"
- Environment simulator: A model or system that simulates environment responses to agent actions. "where the world model serves as the environment simulator and agent foundation model, respectively."
- GSPO: A reinforcement learning algorithm (Grouped Sequence Policy Optimization) used to train the world model. "We employ GSPO~\citep{zheng2025group} for the RL stage on the data described above."
- Hybrid rubric-and-rule rewards: A combined RL reward signal using both LLM-judge rubrics and rule-based binary verifiers. "RL sharpens simulation fidelity through a tailored framework with hybrid rubric-and-rule rewards."
- Information-Theoretic Loss Masking: A method that masks low-information turns during training while keeping them as context to improve learning signal quality. "Turn-Level Information-Theoretic Loss Masking."
- Language World Model (LWM): A conditional text generator that predicts the next environment observation from history and current action. "A language world model (LWM) is a conditional text generator that predicts the next environment observation given the interaction history and the agent's current action."
- LLM judge: A LLM used to score predicted observations according to a rubric during RL. "Each predicted observation is scored by an LLM judge on the five-dimensional rubric defined in \S\ref{sec:bench:protocol}, each on a 1--5 scale."
- Long-context benchmark: A benchmark that tests model fidelity over long interaction histories and contexts. "making AgentWorldBench a naturally grounded long-context benchmark."
- MCP: A tool-calling/server protocol domain used for agent interactions and simulations. "For all domains except MCP and SWE, the action space and demonstrations are predefined"
- No-leakage constraint: A directive ensuring that simulated responses do not reveal target answers prematurely. "For the search domain, each trajectory is annotated with a reverse-engineered simulation instruction containing the target query, reference answer, and a no-leakage constraint."
- OSWorld-Verified: A verified benchmark of OS-level agent interactions used for evaluation. "Terminal-Bench 1.0 {paper_content} 2.0~\citep{merrill2026terminal} and OSWorld-Verified~\citep{xie2024osworld} ensuring entirely out-of-distribution evaluation."
- Prompt–output asymmetry: An RL training characteristic where the prompt is much longer than the generated output, dominating compute costs. "LWM RL exhibits an extreme prompt--output asymmetry: the prompt consists of the full trajectory history up to the prediction turn and often extends to tens of thousands of tokens, whereas the output, a single predicted observation, typically contains only a few hundred to a few thousand tokens."
- Rejection sampling: Selecting the best among multiple generated rollouts using a judge or scoring method. "then generate multi-beam rollouts and apply rejection sampling to curate the final training set."
- Reward hacking: Exploiting biases in the reward/judge (e.g., via self-praise) to increase scores without improving fidelity. "Reward Hacking Through Self-Praise."
- Reward shaping: The design and adjustment of reward formulations to improve RL convergence and stability. "Reward Shaping."
- Rule-based verifier: An executable or deterministic checker that provides binary correctness signals for RL rewards. "Rule-Based Verifier."
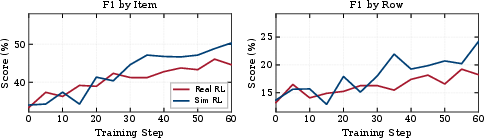
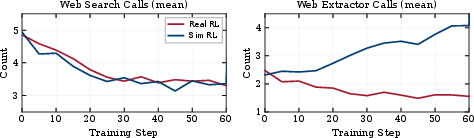
- Sim RL: Reinforcement learning where the agent trains against a simulated environment provided by an LWM. "Separately, Sim~RL trains a policy agent via RL using a LWM as an environment simulator (\S\ref{sec:app:simulator}), while Real~RL trains the same agent against a live, real-world environment"
- State-transition dynamics: The rules governing how environment state changes in response to actions. "from the state transition dynamics and augmented professional corpora,"
- Supervised Fine-Tuning (SFT): A training stage that activates explicit next-state prediction reasoning patterns using labeled trajectories. "Stage~2 SFT activates next-state-prediction thinking patterns"
- System prompt: A structured prompt that encodes task description, action space, initial state, demonstrations, and simulation instructions. "The system prompt has five components, whose construction is detailed in \S\ref{sec:pipeline:prompt}."
- Tag extraction: Strict parsing to isolate predicted observations from reasoning so judges only score relevant content. "we use a multi-strategy JSON parser and strict tag extraction to ensure that only the predicted observation reaches the judge, preventing self-praise in the reasoning from affecting the score."
- Trajectory-to-Turn Expansion: Converting multi-turn trajectories into turn-level prediction samples for training. "Trajectory-to-Turn Expansion."
- Turing-Test Reward: A reward that asks a judge whether a predicted observation could plausibly have come from a real environment. "Turing-Test Reward asks a judge whether the predicted observation could plausibly have come from a real environment."
- UI view hierarchy: A textual tree representation of GUI components and their properties. "For the three GUI domains, environment observations are represented as accessibility trees and UI view hierarchies rather than pixel frames."
- Unified Environment Trajectory Schema: A shared format for representing environment trajectories across domains. "Unified Environment Trajectory Schema"
- World modeling: Learning to predict environment dynamics from observations and actions to enable reasoning and planning. "We argue that world modeling is a crucial missing piece in the path to general agents."
Collections
Sign up for free to add this paper to one or more collections.