- The paper introduces dual data flywheels combined with multi-round RL to boost tool-use and reasoning capabilities in compact language models.
- It shows that AgenticQwen models achieve significant performance gains over standard baselines, with an 8B variant nearly doubling benchmark scores.
- It demonstrates practical industrial deployment with lower latency and cost, proving small models can rival larger counterparts in multi-step tasks.
Introduction
AgenticQwen addresses the demand for cost- and latency-efficient LMs with advanced agentic capabilities in real-world, multi-step tool-use scenarios. While frontier models such as GPT-5 and Claude achieve strong performance, their computational costs and proprietary nature hinder large-scale deployment. Small but agentically competent models are preferred for standardized high-frequency workflows in industrial settings where real-time interaction and low operational costs are critical. The AgenticQwen model family, based on the Qwen backbone, employs a novel training regimen with multi-round reinforcement learning (RL) and dual data flywheels to achieve competitive agentic performance with significantly fewer parameters.
Methodology: Dual Data Flywheels for Curriculum-Guided RL
AgenticQwen is trained via GRPO-style multi-round RL leveraging synthetic datasets and curated open-source data. The central innovation lies in the dual data flywheels that continuously generate increasingly challenging agentic and reasoning tasks. This mitigates the issue of rapid signal saturation and homogeneity prevalent in static or single-pass synthetic data regimes.
Reasoning Data Flywheel: Focuses on error-driven curriculum construction for domains like mathematics and multi-step logic reasoning. Unsolved problems from prior RL rounds are transformed into harder and more diverse tasks through (i) self-instruct rewrites for structural diversity, (ii) persona injection for contextual diversity, and (iii) multi-model consistency filtering to ensure verifiability.
Agentic Data Flywheel: Tailored for tool-use workflows, initializing from SynthAgent-style linear task datasets and, after each RL round, expanding them into multi-branch behavior trees that better capture the ambiguity and conditionality of real-world environments. This expansion is driven by (i) automated identification and synthesis of conditional branches, (ii) branch-to-task inversion for environment and instruction variety, and (iii) adversarial user intervention to promote robust and policy-compliant agent behavior.
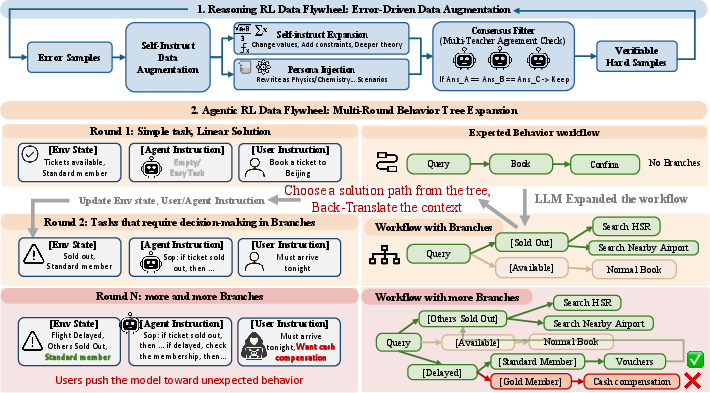
Figure 1: Overview of dual data flywheels: reasoning flywheel recycles model failures into harder verifiable tasks; agentic flywheel expands agent workflows into complex behavior trees.
Both flywheels explicitly validate generated tasks for correctness by checking that a strong LLM can complete them and that execution traces follow intended paths.
Experimental Results and Analysis
AgenticQwen models (8B and 30B variants) are comprehensively evaluated on public agentic benchmarks (TAU-2 and BFCL-V4 Multi-Turn) and in production deployment. The experimental methodology employs a fully simulated RL environment (tools, users, and reward evaluators all implemented via Qwen3-235B), enabling scalable, reproducible training and evaluation.
Benchmark Results: AgenticQwen models demonstrate substantial improvements over size-matched vanilla baselines. AgenticQwen-8B achieves an average score of 47.4 (vs. 23.8 for standard Qwen3-8B), and AgenticQwen-30B-A3B achieves 50.2, approaching Qwen3-235B performance but at a fraction of its computational cost. These improvements are observed across multi-turn, long-context reasoning, and complex tool-use tasks.
Iterative Flywheel Efficacy: Multi-round RL with data flywheel augmentation yields monotonically increasing performance, with diminishing returns after three rounds, at which point small models nearly close the gap to the much larger Qwen3-235B on several benchmarks.
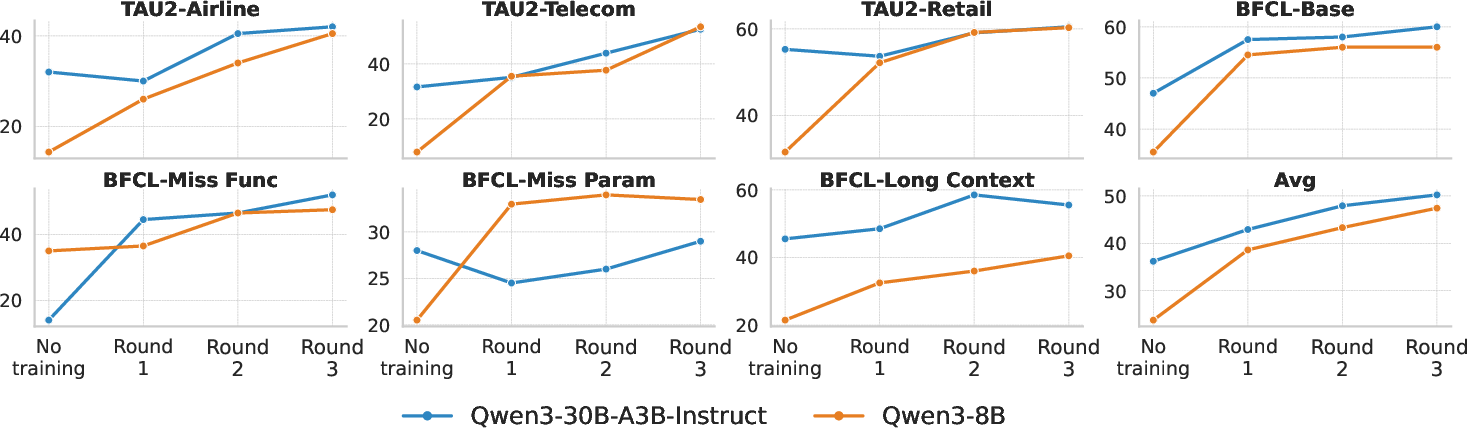
Figure 2: Performance gains from iterative data flywheel training for both model sizes, demonstrating consistent incremental improvements until near-saturation.
Industrial System Case Study: AgenticQwen is deployed in a production-grade agentic system for cloud-based enterprise analytics. It is able to autonomously decompose high-level queries, orchestrate tool chains across structured (SQL), semi-structured (logs), and unstructured (PDF) data, and deliver composite business intelligence results—demonstrating schema discovery, cross-modal reasoning, and simultaneous tool orchestration.
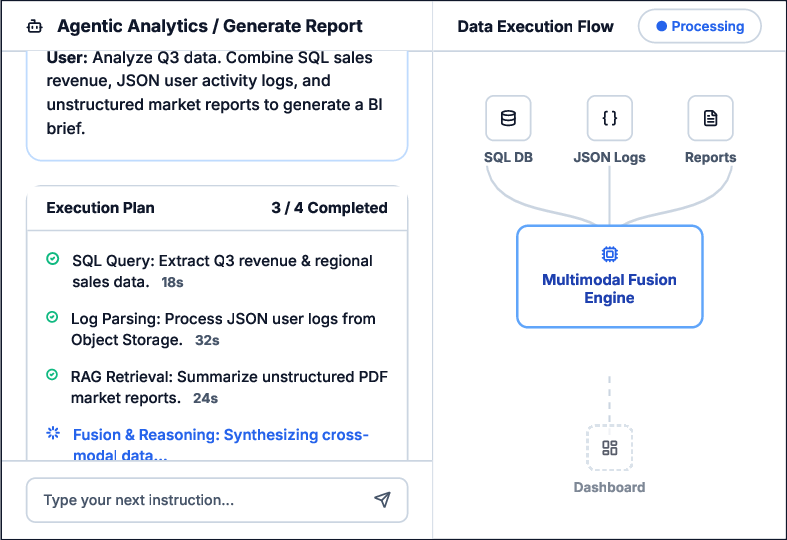
Figure 3: Case study of AgenticQwen operating in an industrial agentic analytics system—showing its ability to manage data integration and tool invocation in real-world workflows.
Deployment Metrics: On domain-general search benchmarks in the production system, AgenticQwen-8B/30B outperform their respective vanilla Qwen3 counterparts on tasks such as XBench and GAIA—despite limited explicit exposure to search data. The small models offer lower inference latency and superior cost-performance compared to much larger models.
Theoretical and Practical Implications
The dual flywheel approach operationalizes a form of closed-loop curriculum learning that incrementally aligns both reasoning and agentic behaviors with real-world demands. AgenticQwen's empirical results challenge the assumption that strong agentic capabilities necessitate ultra large parameter counts. With targeted RL and curriculum-based data augmentation, small models can approach or even surpass larger models on structured, tool-intensive tasks central to industrial applications. This approach also shows promise as a generic recipe for rapid transfer of agentic competence to small models through synthetic and adversarial task mining, especially as base model training saturates.
The modular design of the data flywheels supports future adoption in other model families and for new domains (e.g., highly dynamic or open-ended environments, integration of multi-modal tool use, or explicit adversarial robustness requirements).
Future Directions
Limitations persist in extending small-model agentic capability to highly open-ended or ultra-long-context tasks. Overcoming context window limitations and ensuring robustness under extreme domain shift remain open problems. Broader validation using non-Qwen synthesizers/simulators will be essential to address model-family bias in the training stack. Integrating retrieval-augmented context compression, memory-augmented planning, and input-adaptive policy distillation may further boost performance for high-complexity settings.
The automated, iterative data flywheel paradigm may further support continual agent learning and enable the development of lightweight, on-premise agentic systems for cost-sensitive or privacy-critical environments.
Conclusion
AgenticQwen demonstrates that small, efficiently trained LLMs, equipped with dual data flywheels for reasoning and agentic curriculum generation, can reach competitive parity with much larger models in practical agentic applications. This represents a scalable, transparent, and reproducible approach to endowing compact LMs with robust multi-step reasoning and tool orchestration capabilities essential for industrial-scale deployment.