- The paper proposes a novel adaptive reward gating mechanism integrating SFT and RL to minimize tool calls while guaranteeing correctness.
- It employs multi-stage gating (correctness, tool efficiency, and token efficiency) to filter redundant trajectories and enforce resource efficiency.
- Experiments show up to 58% reduction in tool calls and 33.4% token compression, maintaining or improving accuracy across multiple benchmarks.
SlimSearcher: Training Efficiency-Aware Web Agents via Adaptive Reward Gating
Modern LLM-based web agents achieve high accuracy on complex information-seeking tasks via extensive tool integration (web search, browsing, code execution). However, accuracy-centric training paradigms induce a severe efficiency collapse in both open and proprietary systems, manifesting as blind tool dependency and performative reasoning. These agents invoke tools indiscriminately—even for answerable common-sense queries—and generate redundant chains of reasoning characterized by loops and dead-end branches, leading to excessive computational and time overhead with hundreds of tool calls per query.
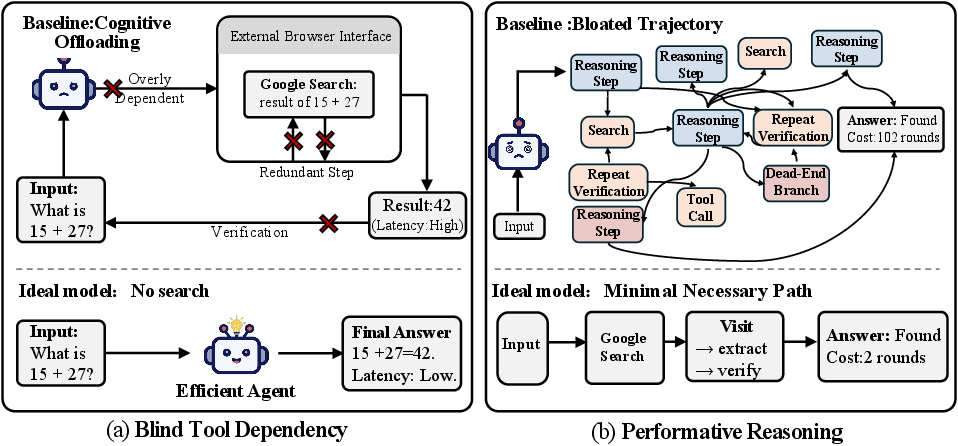
Figure 1: Behavioral analysis highlighting blind tool dependency and performative reasoning in agent trajectories, leading to wasted tool calls and increased latency.
Pareto-optimality between accuracy and resource expenditure is unaddressed: standard SFT admits any correct (including bloated) trajectory, and existing RL approaches focus solely on task completion, thereby internalizing highly redundant behavior. Naive prompt engineering or token-penalty RL fails to systematically prune actions—external tool invocations dominate real agent resource consumption.
SlimSearcher Framework
Multi-Stage Gating: Unified SFT and RL Optimization
SlimSearcher introduces a principled framework to push the efficiency-accuracy Pareto frontier, integrating efficiency optimization at both SFT and RL stages. The central mechanism is a hierarchical Multi-Stage Gating system:
- Gate 1 (Correctness): Strict binary constraint, rcorrect, ensures reward is zero for any trajectory not matching ground-truth, preventing reward hacking and brevity bias.
- Gate 2 (Tool Efficiency): Adaptive reward anchoring (AEA) exponentially penalizes tool overuse relative to the empirically minimal observed path within trajectory cohorts, providing task-adaptive gradients.
- Gate 3 (Token Efficiency): Parallel anchoring mechanism penalizes excessive token usage, further enforcing conciseness and suppressing performative reasoning.
Reward is computed as:
Rfinal(τ)=rcorrect(τ)⋅rtool(τ)⋅rlen(τ)
Efficiency-Aware SFT via Pareto Filtering
SlimSearcher implements reward-guided rejection sampling for SFT, selecting a single trajectory for each query that maximizes joint tool and token efficiency, forming a high-signal corpus that distills the Minimal Necessary Path. This approach directly purges poisoned or redundant trajectories from early model initialization.
RL Policy Optimization
GRPO-based RL is employed, using the group-standardized advantage beneath the Multi-Stage Gating reward to establish policy gradients. Each trajectory is compared to the empirical cohort minimum, anchoring learning to the true resource-optimal path.
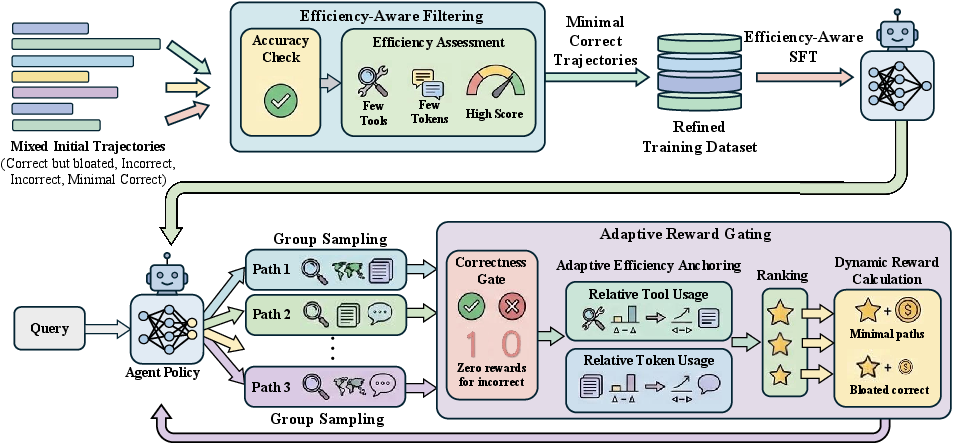
Figure 2: SlimSearcher framework with multi-dimensional filtering in SFT and adaptive reward gating during RL unifying accuracy and efficiency objectives.
Experimental Results
Pareto Frontier Shift: Efficiency Gains Without Accuracy Sacrifice
Extensive evaluation was performed across four benchmarks—XBench-DeepSearch, BrowseComp, GAIA, HLE—using both Tongyi-DeepResearch and Qwen3-30B-A3B-Instruct as backbones. SlimSearcher achieves 17%–58% reduction in tool-call rounds and substantial token compression with equal or higher accuracy compared to baseline SFT or prompt-engineered baselines.
On GAIA, SlimSearcher (SFT+RL) reduces tool-call rounds by 48.4% (from 20.56 to 10.61) and token usage by 33.4%, increasing accuracy from 0.682 to 0.709 on Tongyi backbone. Similar trends are observed for BrowseComp and HLE. Baselines (Prompt Control, DeepSeek-V3) either collapse accuracy or fail to consistently improve efficiency.
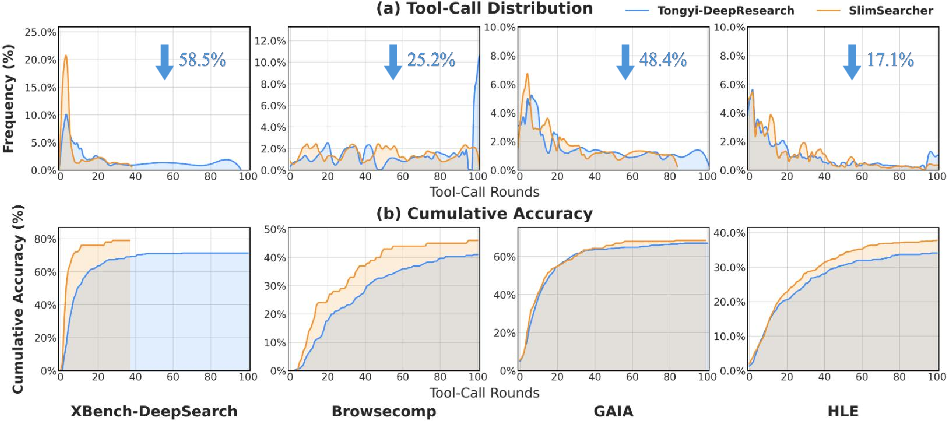
Figure 3: Comparison of tool-call distribution and cumulative accuracy. SlimSearcher achieves steeper accuracy curves with compact action spaces.
Robustness and Ablations
- Reward-Guided Rejection Sampling: Outperforms standard SFT (GAIA: accuracy rise ∼0.665, tool rounds drop).
- Correctness Gate: Its removal destroys accuracy, causing reward hacking and vacuous outputs (GAIA: accuracy plummets, tool-rounds near-zero).
- Adaptive Efficiency Anchoring: Without AEA, brute-force exploration emerges—tool-call rounds inflate, token consumption increases, and accuracy stagnates.
Qualitative case comparisons demonstrate SlimSearcher’s strategic minimal reasoning traces, solving tasks in a few tool invocations, while baselines (e.g., MiroThinker) require up to 50× more tool calls or fail entirely.
Implications and Future Directions
SlimSearcher advances data-driven training protocol design for web agents, representing a scalable solution for discipline in both computational and operational efficiency without accuracy regression. The Adaptive Reward Gating paradigm enables real-time anchoring to empirical minimal paths, an approach extensible to multimodal domains and dynamic action weighting.
Practical implications include tractable deployment of open-source agents at scale, decreased infrastructure cost, and improved latency for long-horizon research scenarios. Theoretical developments may extend toward cost-sensitive reward design, adaptive sampling in RL, and generalization to visual environments with multimodal redundancy.
Future work should tackle multimodal efficiency (visual web tasks), domain adaptation where initial empirical anchors are scarce, and fine-grained tool weighting to align with deployment economics.
Conclusion
SlimSearcher systematically overcomes the efficiency trap in LLM-based web agents, coupling efficiency-aware SFT and adaptive RL under a unified gating objective. This produces agents that are not only accurate, but also computationally disciplined, demonstrating clear Pareto improvements in real-world information-seeking tasks. The framework provides a robust foundation for future agentic training paradigms targeting scalable, efficient, and versatile autonomous web research.