- The paper presents a dynamic search boundary modeling approach that reduces unnecessary and redundant search actions.
- It employs stage-wise optimization and boundary-aware rewards to balance answer correctness with computational efficiency.
- Empirical validation across seven QA benchmarks shows significant reductions in search count and improvements in accuracy compared to baselines.
Self-Aware Reinforcement Learning for Over-Search Mitigation in Agentic Search
Agentic search architectures augment LLMs by coupling iterative reasoning with external retrieval, allowing dynamic invocation of search tools to address knowledge-intensive tasks. However, a central deficiency persists: agents lack explicit self-awareness regarding their knowledge boundaries, resulting in two predominant over-search behaviors—unnecessary search (searching despite sufficient parametric knowledge) and redundant search (continuing to search after sufficient evidence is collected). This produces operational inefficiencies, increased latency, elevated computational cost, and potentially degraded performance due to the introduction of irrelevant evidence.

Figure 1: Illustration of over-search typologies—unnecessary trigger and redundant continuation—in agentic search.
Standard RL-based agentic search approaches optimize for answer correctness, inadvertently incentivizing search activation whenever retrieval might marginally improve reward. Naive penalization via fixed search constraints (e.g., per-action costs or static thresholds) fails, since the search boundary is inherently dynamic—conditioned on the model’s evolving internal knowledge during policy optimization. The mismatch between static penalties and evolving search capability induces reward hacking and optimization collapse.
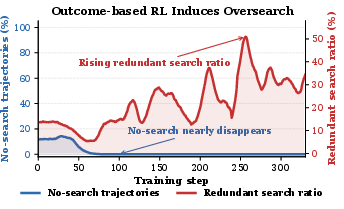
Figure 2: Outcome-based RL exacerbates over-search, driving down "no-search" trajectories and increasing redundant search.
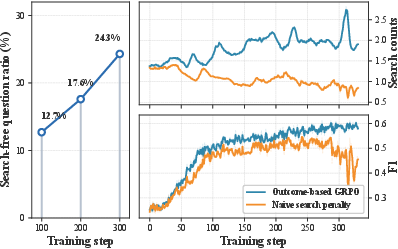
Figure 3: Static search penalties distort the search boundary during optimization, degrading performance and leading to reward hacking.
SAAS Framework: Dynamic Boundary-Aware Agentic Search
To address these pathologies, SAAS (Self-Aware Agentic Search) introduces an RL framework comprising three tightly integrated modules:
- Search Boundary Modeling: SAAS estimates the necessity of search per-question relative to the agent’s current policy by contrasting search-disabled and search-enabled rollouts. This allows on-policy estimation of whether the agent’s parametric knowledge is sufficient or external retrieval is needed. For questions classified as "NoSearch," search actions are penalized; for "NeedSearch," only redundant steps beyond the minimum successful evidence acquisition are penalized.
- Boundary-Aware Reward Assignment: Rewards are constructed at the trajectory level, discriminating between unnecessary and redundant searches. For "NoSearch" instances, a strict penalty is imposed on all search actions; for "NeedSearch," search actions in excess of the minimum required for correct answers are penalized.
- Stage-Wise Optimization: To prevent reward hacking and premature search suppression, training follows a sequential curriculum—initially optimizing only for answer correctness (capability acquisition), then activating boundary-aware reward for efficiency refinement once parametric competence is established.

Figure 4: SAAS pipeline depicting search boundary modeling (contrasting rollouts), boundary-aware reward, and stage-wise curriculum for robust optimization.
This paradigm is agnostic to input modality, enabling straightforward adaptation to multimodal search-augmented reasoning systems.
Empirical Validation and Efficiency Gains
SAAS is evaluated across seven open-domain QA benchmarks spanning single-hop and multi-hop reasoning on multiple LLM backbones. The principal evaluation metrics are answer accuracy (ACC), search count (SC), question-level over-search ratio (QOR), and step-level over-search ratio (SOR).
SAAS achieves best accuracy-efficiency trade-off: For Qwen2.5-3B-Instruct, SAAS produces 45.8% accuracy with an average search count of 1.13, a 40.2% reduction in searches versus the best baseline (HiPRAG), while improving accuracy by 2.2%. On Qwen2.5-7B-Instruct, SAAS reaches 48.7% accuracy with search count reduced by ~67% compared to outcome-based GRPO.
SAAS accomplishes strong suppression of over-search: On multi-hop datasets (e.g., Bamboogle), SAAS drops step-level SOR to 13.3% from >20% (in GRPO) and reduces QOR from 100% (all questions incur search) to 45.9%.
Detailed ablation reveals that on-policy search boundary estimation and stage-wise optimization are crucial; removing either degrades accuracy or reverts search count to baseline levels.
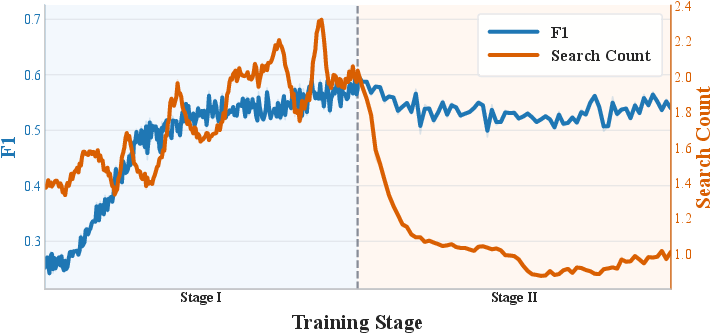
Figure 5: Stage-wise RL training dynamics—search count drops sharply at boundary-aware optimization step, while accuracy remains stable.
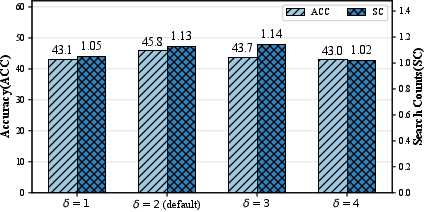
Figure 6: Sensitivity analysis of grouping parameter δ validates the robustness of search boundary estimation.
Case studies confirm qualitative improvements: SAAS agents refrain from unnecessary search when parametric knowledge suffices, and terminate search actions upon collecting sufficient evidence, unlike outcome-only baselines which persist extra tool invocation.
Implications and Future Directions
SAAS establishes a formal mechanism for dynamic, policy-driven search boundary awareness in agentic search, effectively coupling evidence acquisition with self-assessment of knowledge sufficiency. This improves deployability of search-augmented LLM agents by reducing resource consumption and inference latency, enabling scalable integration in practical systems.
The theoretical implication is the decoupling of search invocation from reward-based opportunism, aligning tool use with epistemic necessity. Practically, this methodology generalizes to adaptive search scheduling in multimodal reasoning, scientific information synthesis, and decision-making tasks where cost-sensitive evidence acquisition is critical.
Future developments may refine boundary modeling via meta-learning, adapt SAAS to broader tool-use (beyond retrieval), and incorporate continuous search necessity estimation with unimodal or cross-modal fusion.
Conclusion
SAAS provides a robust, boundary-aware RL framework for mitigating over-search in agentic search. By dynamically modeling the agent’s evolving search boundary and integrating adaptive rewards with stage-wise optimization, SAAS achieves efficient and accurate reasoning, substantially reducing unnecessary and redundant retrieval. This approach offers a concrete foundation for scalable, efficient, and epistemically aligned search-augmented AI systems (2605.29796).

